A Deep Belief Network Combined with Modified Grey Wolf Optimization Algorithm for PM2.5 Concentration Prediction


Abstract
:1. Introduction
- An advanced deep learning model, so-called DBN, is introduced to predict the PM2.5 concentration, which establishes the close relationship between the influencing factors and pollutant.
- A modified grey wolf optimization (MGWO) algorithm is proposed to determine the DBN structure parameters, which improves the prediction accuracy of PM2.5 concentration and reduces the computation time.
- The proposed model is successfully applied to the PM2.5 concentration prediction of Baoding city in China where air pollution is particularly serious.
2. PM2.5 Concentration Prediction Approach
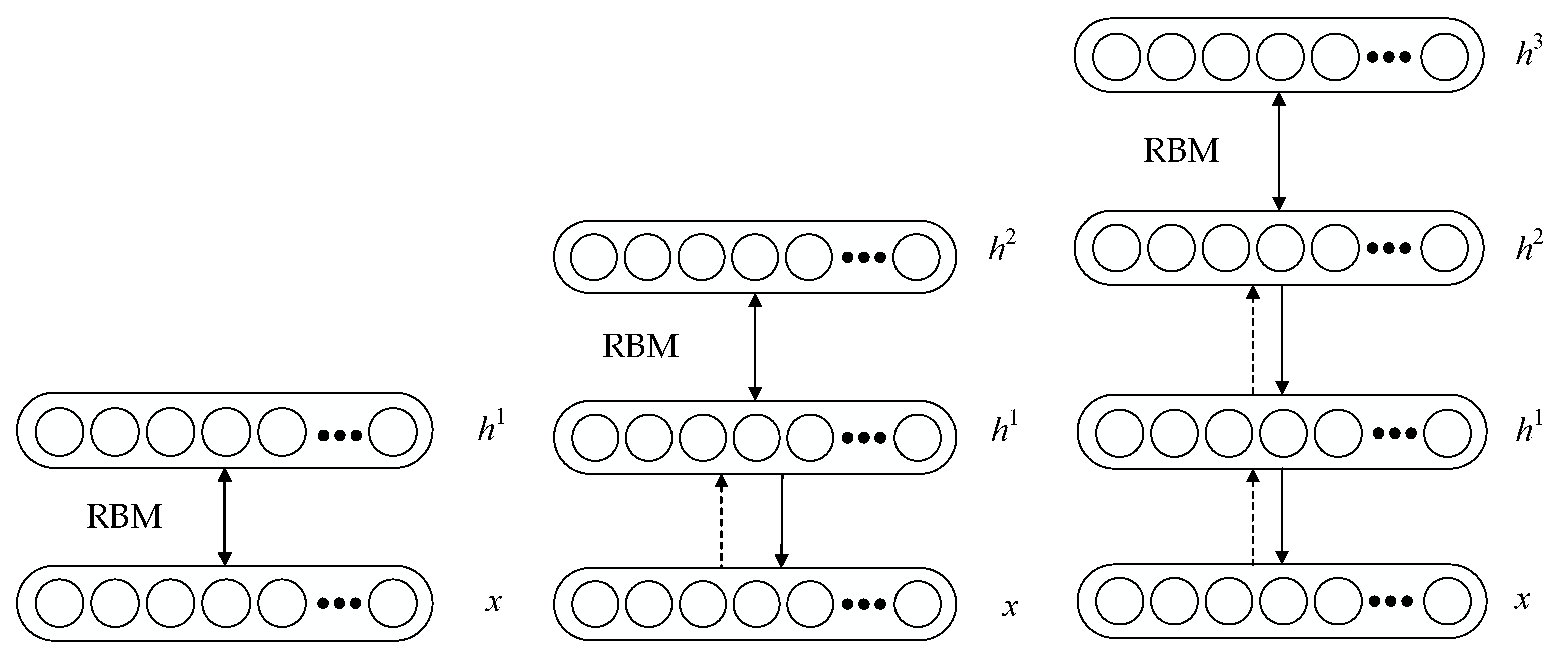
2.1. Deep Belief Network
2.2. Modified Grey Wolf Optimization Algorithm
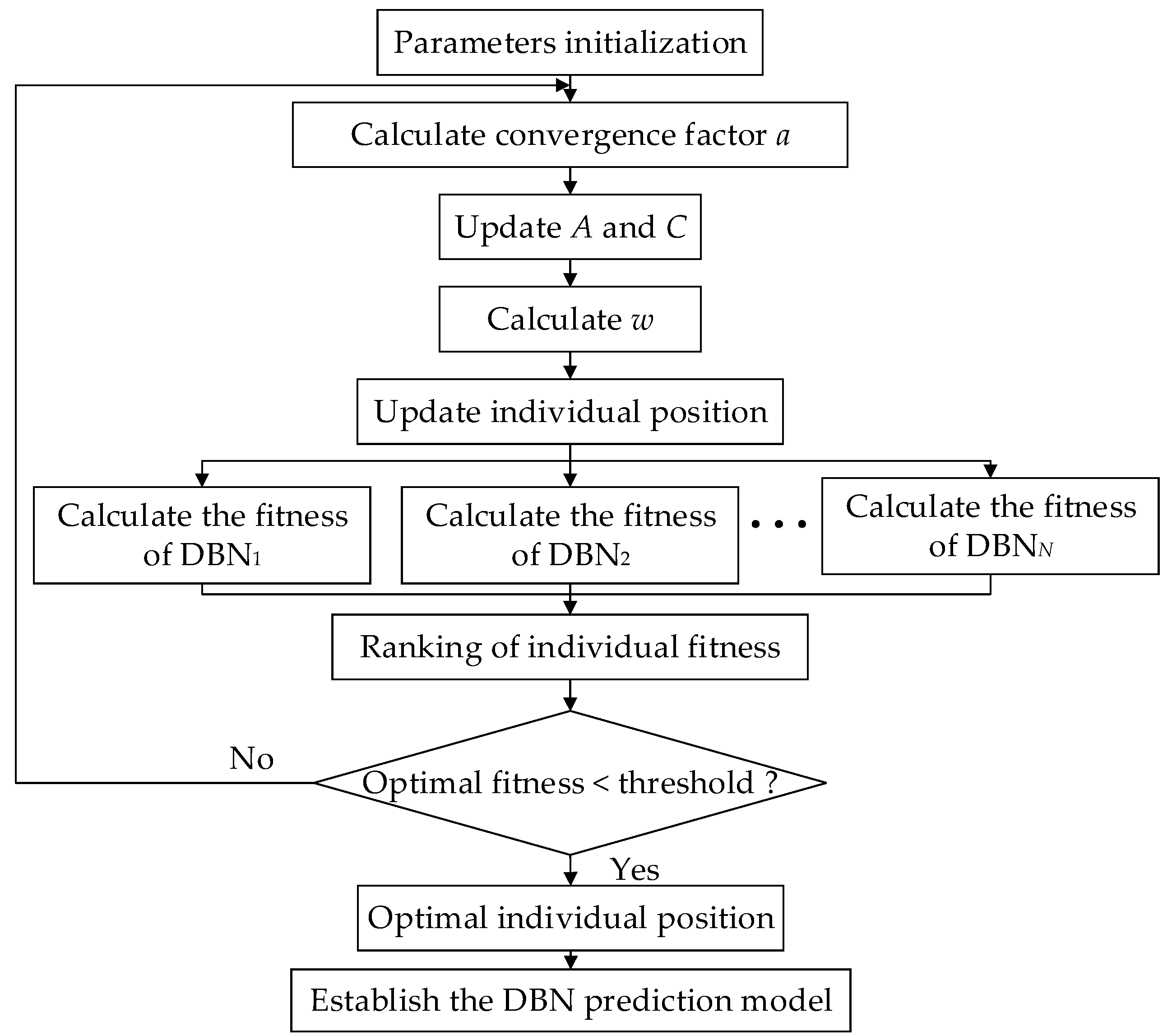
2.3. DBN Structure Parameters Determined by MGWO Algorithm
3. Real Application Case
3.1. Data Source
- PM2.5 data—The PM2.5 data come from the monitoring station for air pollution particles in Baoding city. Its unit is μg/m3. The data are sourced from the china meteorological website (http://www.tianqihoubao.com/lishi/), and the selection duration is 2014–2016.
- Aerosol optical depth—Aerosol is the general term of solid and liquid particulate matter suspended in the atmosphere. AOD, one of the optical properties of atmospheric aerosols, is equal to the integral of aerosol extinction coefficient from the ground to the top of the atmosphere. It is used to characterize the degree of extinction caused by the aerosol scattering in cloudless atmospheric vertical columns. AOD data are derived from MODIS aerosol products. MODIS offers two AOD products with resolutions of 10 km and 3 km. Considering the small ground coverage in Baoding city, the MOD04_3K product with the resolution of 3 km is chosen. The data are sourced from the official website of MODIS products, and the selection duration is 2014–2016.
- Meteorological parameters—Monitoring stations in Baoding city provide 9 meteorological parameters, including average temperature, maximum temperature, minimum temperature, air pressure, average relative humidity, total precipitation, average visibility, average wind speed, and maximum continuous wind speed. The data are sourced from the global weather data website (https://en.tutiempo.net/climate), and the selection duration is 2014–2016.
3.2. Model Establishment and Verification
- MGWODBN predicts all trained data, and the linear fitting equation of the observed and predicted values is obtained as , where is the actual observed value; is the predicted value of the model. The root mean square error (RMSE) is 18.532 μg/m3, and the coefficient of determination (R2) is 0.713. Figure 6a shows the verification results. It can be seen that the sample points are roughly distributed on both sides of the diagonal line and are more aggregated, indicating that the model has a better fitting effect.
- Cross-validation—90% data are randomly selected to train the model, and the remaining 10% data are used as the verification points. Repeated 10 experiments showed that the linear fitting equation of the observed and predicted values is obtained as . The RMSE is 19.815 μg/m3, and the R2 is 0.677. Figure 6b shows the verification results. It can be seen that the sample points are roughly distributed on both sides of the diagonal line. The less sample points deviate from the diagonal line, which satisfies the law of error distribution. These results show that the verification results are good.
3.3. Compared with Other Prediction Models
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pipal, A.S.; Kulshrestha, A.; Taneja, A. Characterization and morphological analysis of airborne PM2.5 and PM10 in Agra located in north central India. Atmos. Environ. 2011, 45, 3621–3630. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, N.; Liu, Z.; Sun, Y.; Ji, N.; Wang, Y. The influence of climate factors, meteorological conditions, and boundary-layer structure on severe haze pollution in the Beijing-Tianjin-Hebei Region during January 2013. Adv. Meteorol. 2014, 2014, 1–14. [Google Scholar] [CrossRef]
- Sawant, A.A.; Na, K.; Zhu, X.; Cocker, K.; Butt, S.; Song, C.; Cocker, D.R., III. Characterization of PM2.5 and selected gas-phase compounds at multiple indoor and outdoor sites in Mira Loma, California. Atmos. Environ. 2004, 38, 6269–6278. [Google Scholar] [CrossRef]
- Akyüz, M.; Cabuk, H. Meteorological variations of PM2.5/PM10 concentrations and particle-associated polycyclic aromatic hydrocarbons in the atmospheric environment of Zonguldak, Turkey. J. Hazard. Mater. 2009, 170, 13–21. [Google Scholar] [CrossRef] [PubMed]
- Gupta, P.; Christopher, S.A. Particulate matter air quality assessment using integrated surface, satellite, and meteorological products: Multiple regression approach. J. Geophys. Res. Atmos. 2009, 114, 1–13. [Google Scholar] [CrossRef]
- Chen, Y. Prediction algorithm of PM2.5 mass concentration based on adaptive BP neural network. Computing 2018, 100, 825–838. [Google Scholar] [CrossRef]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5, pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Sun, W.; Sun, J. Daily PM2.5 concentration prediction based on principal component analysis and LSSVM optimized by cuckoo search algorithm. J. Environ. Manag. 2016, 188, 144–152. [Google Scholar] [CrossRef] [PubMed]
- Song, L.; Pang, S.; Longley, I.; Olivares, G.; Sarrafzadeh, A. Spatio-temporal PM2.5 prediction by spatial data aided incremental support vector regression. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 623–630. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Shao, H.; Jiang, H.; Zhang, H.; Liang, T. Electric locomotive bearing fault diagnosis using a novel convolutional deep belief network. IEEE Trans. Ind. Electron. 2017, 65, 2727–2736. [Google Scholar] [CrossRef]
- Wang, H.Z.; Wang, G.B.; Li, G.Q.; Peng, J.C.; Liu, Y.T. Deep belief network based deterministic and probabilistic wind speed forecasting approach. Appl. Energy 2016, 182, 80–93. [Google Scholar] [CrossRef]
- Abdel-Zaher, A.M.; Eldeib, A.M. Breast cancer classification using deep belief networks. Expert Syst. Appl. 2016, 46, 139–144. [Google Scholar] [CrossRef]
- Li, K.; Wang, M.; Liu, Y.; Yu, N.; Lan, W. A novel method of hyperspectral data classification based on transfer learning and deep belief network. Appl. Sci. 2019, 9, 1379. [Google Scholar] [CrossRef]
- Furqan Qadri, S.; Ai, D.; Hu, G.; Ahmad, M.; Huang, Y.; Wang, Y.; Yang, J. Automatic deep feature learning via patch-based deep belief network for vertebrae segmentation in CT images. Appl. Sci. 2019, 9, 69. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, G.; Liu, H.; Liu, F.; Du, P. A hybrid forecasting method for solar output power based on variational mode decomposition, deep belief networks and auto-regressive moving average. Appl. Sci. 2018, 8, 1901. [Google Scholar] [CrossRef]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef] [PubMed]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Jayabarathi, T.; Raghunathan, T.; Adarsh, B.R.; Suganthan, P.N. Economic dispatch using hybrid grey wolf optimizer. Energy 2016, 111, 630–641. [Google Scholar] [CrossRef]
- Precup, R.E.; David, R.C.; Petriu, E.M. Grey wolf optimizer algorithm-based tuning of fuzzy control systems with reduced parametric sensitivity. IEEE Trans. Ind. Electron. 2016, 64, 527–534. [Google Scholar] [CrossRef]
- Sultana, U.; Khairuddin, A.B.; Mokhtar, A.S.; Zareen, N.; Sultana, B. Grey wolf optimizer based placement and sizing of multiple distributed generation in the distribution system. Energy 2016, 111, 525–536. [Google Scholar] [CrossRef]
- Ma, Z.; Hu, X.; Huang, L.; Bi, J.; Liu, Y. Estimating ground-level PM2.5 in China using satellite remote sensing. Environ. Sci. Technol. 2014, 48, 7436–7444. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.Y.; Olives, C.; Sheppard, L.; Sampson, P.D.; Larson, T.V.; Keller, J.P.; Kaufman, J.D. Historical prediction modeling approach for estimating long-term concentrations of PM2.5 in cohort studies before the 1999 implementation of widespread monitoring. Environ. Health Perspect. 2016, 125, 38–46. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Xia, X.; Liu, X.; Qian, Z. Combining DMSP/OLS night time light with echo state network for prediction of daily PM2.5 average concentrations in Shanghai, China. Atmosphere 2015, 6, 1507–1520. [Google Scholar] [CrossRef]
- Pai, T.Y.; Ho, C.L.; Chen, S.W.; Lo, H.M.; Sung, P.J.; Lin, S.W.; Lai, W.J.; Tseng, S.C.; Ciou, S.P.; Kuo, J.L.; et al. Using seven types of GM (1, 1) model to forecast hourly particulate matter concentration in Banciao city of Taiwan. Water Air Soil Pollut. 2011, 217, 25–33. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Ding, S.; Su, C.; Yu, J. An optimizing BP neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Yu, X.; Wang, X. A novel hybrid classification framework using SVM and differential evolution. Soft Comput. 2017, 21, 4029–4044. [Google Scholar] [CrossRef]
- Chen, G.; Li, S.; Knibbs, L.D.; Hamm, N.A.S.; Cao, W.; Li, T.; Guo, J.; Ren, H.; Abramsona, M.J.; Guo, Y. A machine learning method to estimate PM2.5 concentrations across China with remote sensing, meteorological and land use information. Sci. Total. Environ. 2018, 636, 52–60. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Data | Acquisition Time | Resolution | Source |
|---|---|---|---|---|
| Ground PM2.5 | PM2.5 (μg/m3) | 8:00 a.m. | N/A | Tianqihoubao website |
| Remote sensing data | Terra MODISAOD products | 8:00 a.m. | 3 km | NASA, MODIS |
| Meteorological data | Temperature/°C | 8:00 a.m. | 0.125° | Global climate data |
| Air pressure/hPa | ||||
| Relative humidity/% | ||||
| Precipitation/mm | ||||
| visibility/km | ||||
| Wind speed/(m/s) |
| Model | Hidden Nodes | Learning Rate | Momentum Coefficient | MAE (μg/m3) | MSE (μg2/m6) | R2 | Optimization Time (s) | |
|---|---|---|---|---|---|---|---|---|
| PSODBN | 324 | 340 | 0.896 | 0.959 | 18.437 | 463.176 | 0.844 | 726.362 |
| DEDBN | 5 | 61 | 0.569 | 0.273 | 18.568 | 476.006 | 0.857 | 623.746 |
| GWODBN | 8 | 33 | 0.106 | 0.645 | 18.162 | 442.553 | 0.879 | 286.254 |
| MGWODBN | 6 | 5 | 0.077 | 0.807 | 17.604 | 410.266 | 0.884 | 293.367 |
| Model | MAE (μg/m3) | MSE (μg2/m6) | R2 |
|---|---|---|---|
| GABP | 20.318 | 551.859 | 0.708 |
| DESVM | 18.623 | 492.428 | 0.758 |
| Random Forest | 18.957 | 498.668 | 0.863 |
| MGWODBN | 17.604 | 410.266 | 0.884 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, Y.; Yue, J.; Chen, C.; Xiang, Y.; Chen, Y.; Shi, M. A Deep Belief Network Combined with Modified Grey Wolf Optimization Algorithm for PM2.5 Concentration Prediction. Appl. Sci. 2019, 9, 3765. https://0-doi-org.brum.beds.ac.uk/10.3390/app9183765
Xing Y, Yue J, Chen C, Xiang Y, Chen Y, Shi M. A Deep Belief Network Combined with Modified Grey Wolf Optimization Algorithm for PM2.5 Concentration Prediction. Applied Sciences. 2019; 9(18):3765. https://0-doi-org.brum.beds.ac.uk/10.3390/app9183765
Chicago/Turabian StyleXing, Yin, Jianping Yue, Chuang Chen, Yunfei Xiang, Yang Chen, and Manxing Shi. 2019. "A Deep Belief Network Combined with Modified Grey Wolf Optimization Algorithm for PM2.5 Concentration Prediction" Applied Sciences 9, no. 18: 3765. https://0-doi-org.brum.beds.ac.uk/10.3390/app9183765