Deep-Learning-Based Defective Bean Inspection with GAN-Structured Automated Labeled Data Augmentation in Coffee Industry

 , , , , , , , , ,
, , , , , , , , ,  , and
, and
Abstract
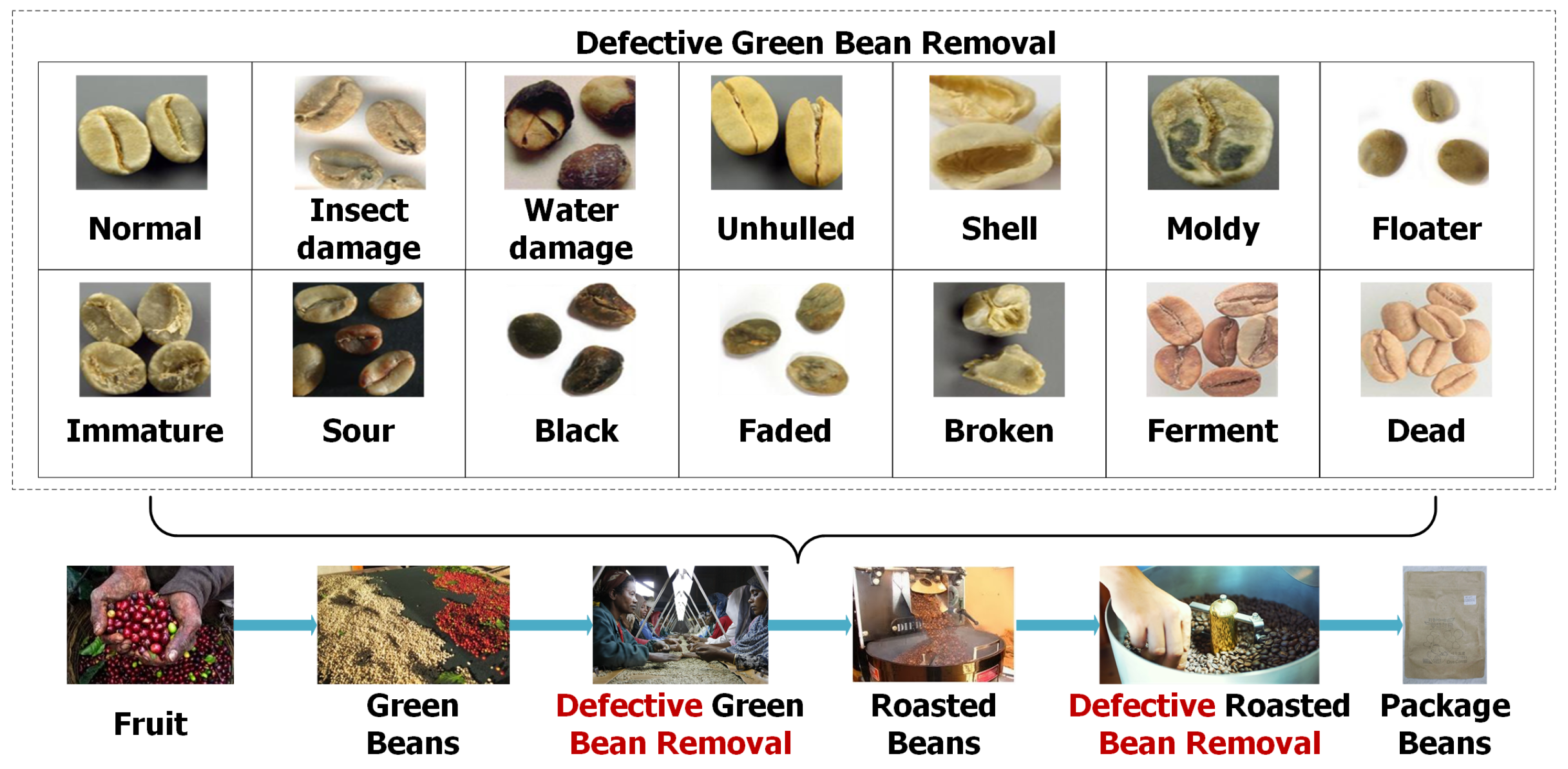
:1. Introduction
2. Related Work
2.1. Survey of Deep Learning Technologies
2.2. Generating Deep-Learning Models for Defective Coffee Bean Inspection
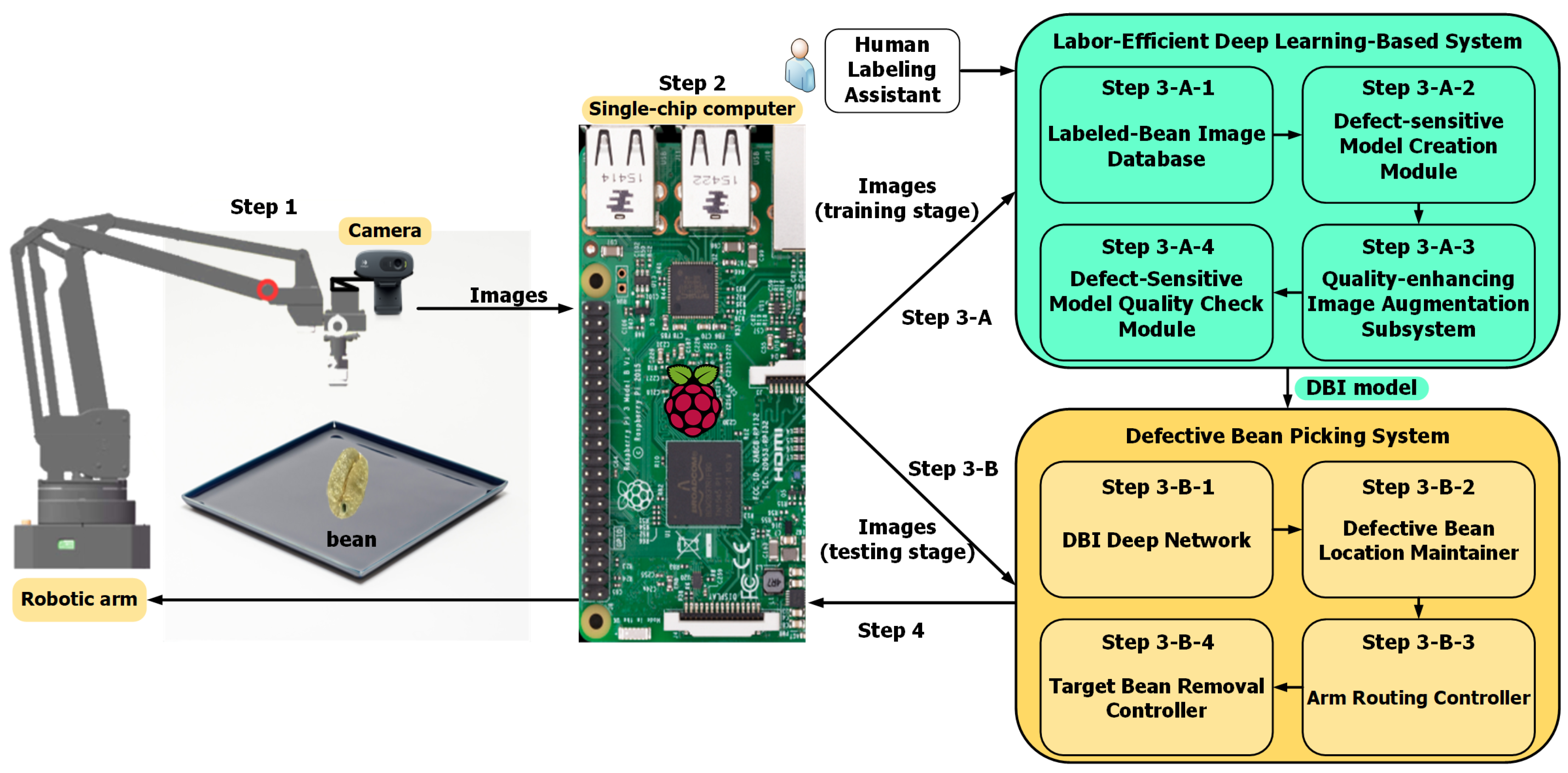
3. Proposed Deep-Learning-Based Defective Bean Inspection Scheme (DL-DBIS)
- Step 1:
- Use a robotic arm equipped with a camera to capture bean images.
- Step 2:
- These images, divided into training images and testing images, are transmitted to the computer through the single-chip computer.
- Step 3-A-1:
- On receiving training image data, a Labeled-Bean Image Database is used to store these bean images, including bean labels.
- Step 3-A-2:
- Then, the Defect-sensitive Model Creation Module creates a defect-sensitive model based on the GAN technique.
- Step 3-A-3:
- The Quality-enhancing Image Augmentation Subsystem is used to automatically generate new bean images for training better defective bean inspection models.
- Step 3-A-4:
- The Defect-Sensitive Model Quality Check Module checks quality of the defect-sensitive model. If quality is good enough, output the DBI model.
- Step 3-B-1:
- When receiving the test image data, DBPS uses the DBI deep network to check the beans in the tray.
- Step 3-B-2:
- Once the defective beans in the tray are detected, the Defective Bean Location Maintainer gets the position of the coffee beans.
- Step 3-B-3:
- The Arm Routing Controller establishes routing and control of the Robotic arm for removing the defective beans.
- Step 3-B-4:
- Finally, the Target Bean Removal Controller is of the final step in the Defective Bean Picking System, which has the ability to remove defective beans.
- Step 4:
- After implementation of the Defective Bean Picking System is complete, the Target Bean Removal Controller transmits commands to the Single-chip computer by network and controls the robotic arm to remove the defective beans.
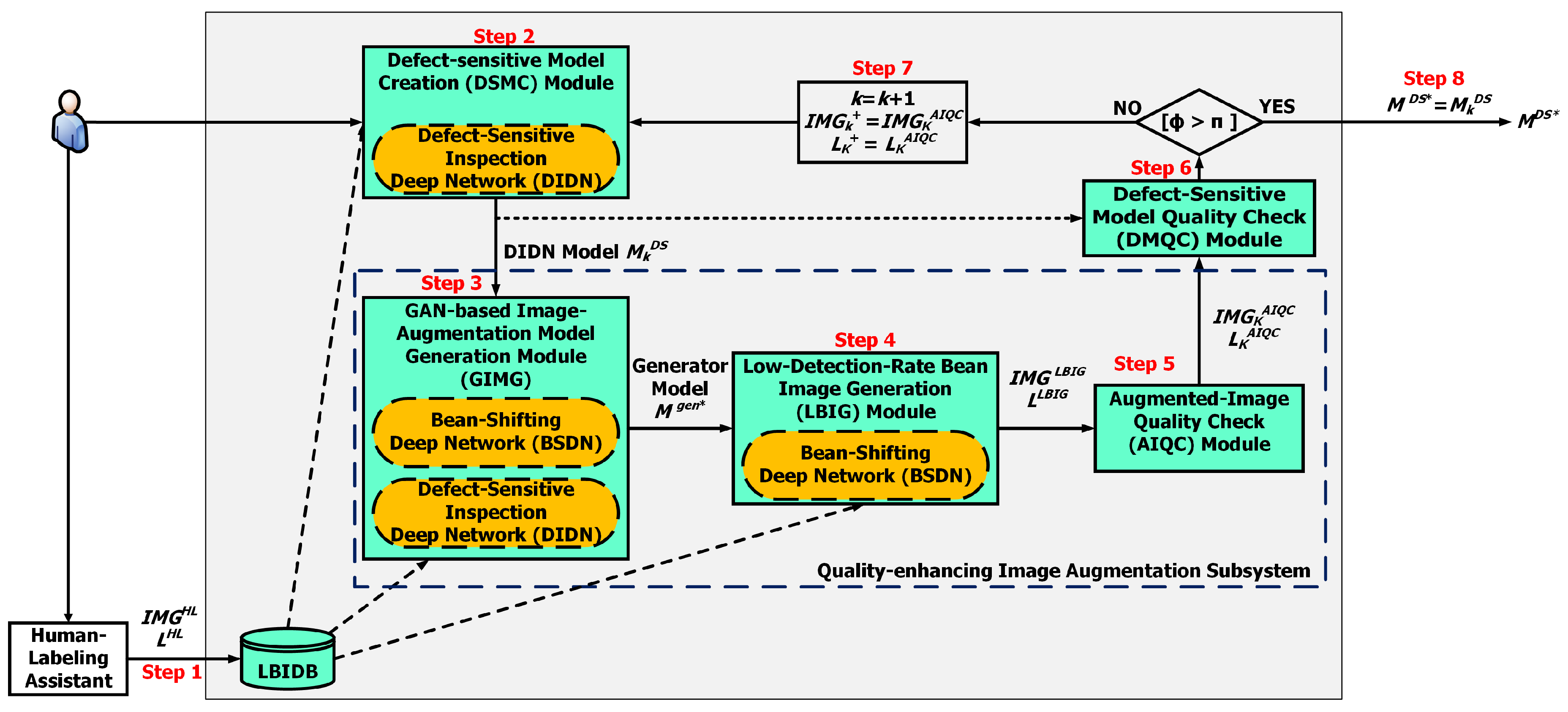
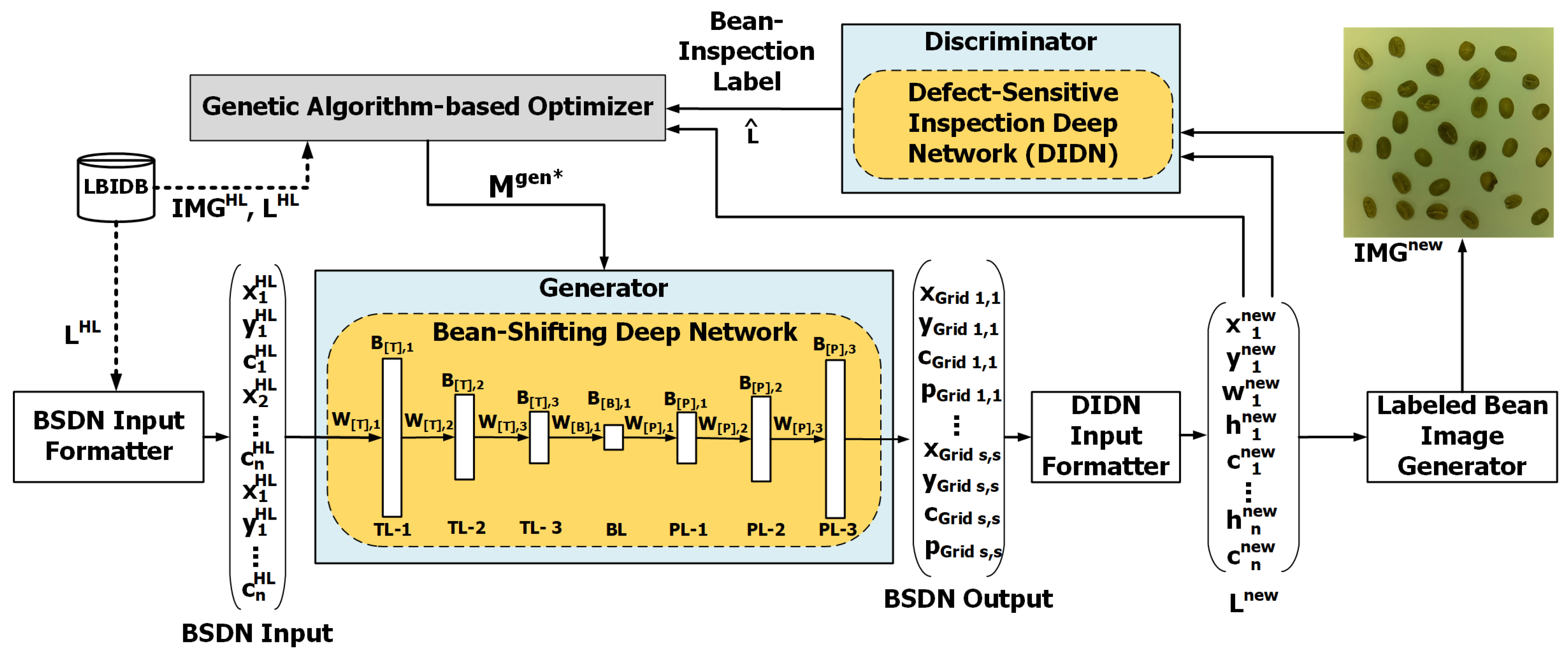
GAN-Based Automated Labeled Data Augmentation Method (GALDAM)
- Step 1:
- The user labels only a few amounts of sparse defective bean images and stores the labeled bean images in the LBIDB.
- Step 2:
- The DSMC module creates a defect-sensitive model for the DIDN based the GAN technique.
- Step 3:
- The GIMG module creates a generative network model for the BSDN and the DIDN.
- Step 4:
- The LBIG module generates the augmented labeled defective bean image set (denoted by and ).
- Step 5:
- The AIQC module verifies whether the augmented labeled bean image set is qualified for being used in training the model .
- Step 6:
- The DMQC module verifies the quality of generated defect-sensitive model with the augmented image and label sets and .
- Step 7:
- Some above augmented bean images that pass the following two quality checks (AIQC and DMQC, presented later) will be used in the next iteration () of training the DSMC module for improving the DIDN model.
- Step 8:
- The GALDAM outputs the optimal DIDN model, denoted as , which implements the general DBI model in the DL-DBIS (see Figure 3).
4. Proposed Defect Inspection Models Created from Two Critical Deep Networks and Associated GAN-Structured Data Augmentation with GA-Based Optimizer
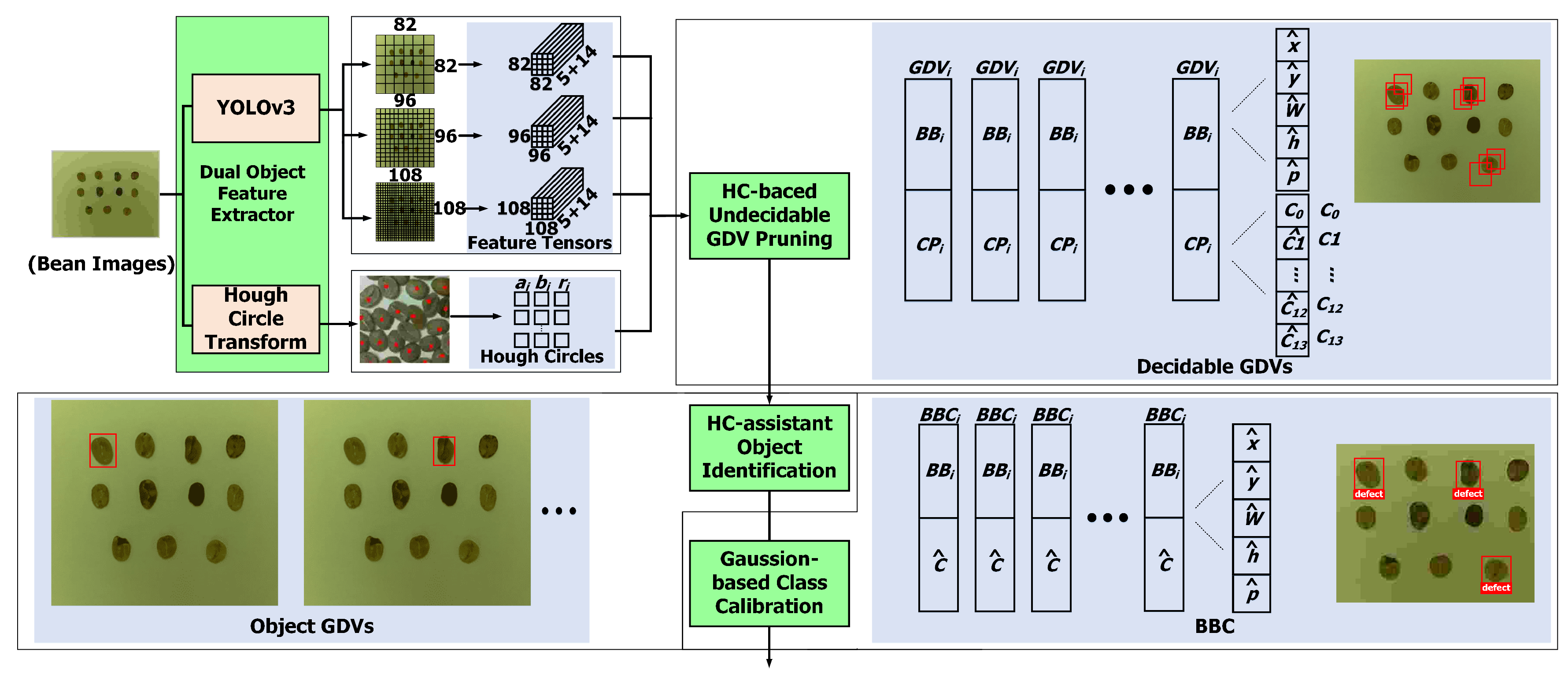
4.1. Design of Defect-Sensitive Inspection Deep Network (DIDN)
4.2. Design of Bean-Shifting Deep Network
4.3. GAN-Based Framework for Labeled Data Augmentation for the GIMG Module
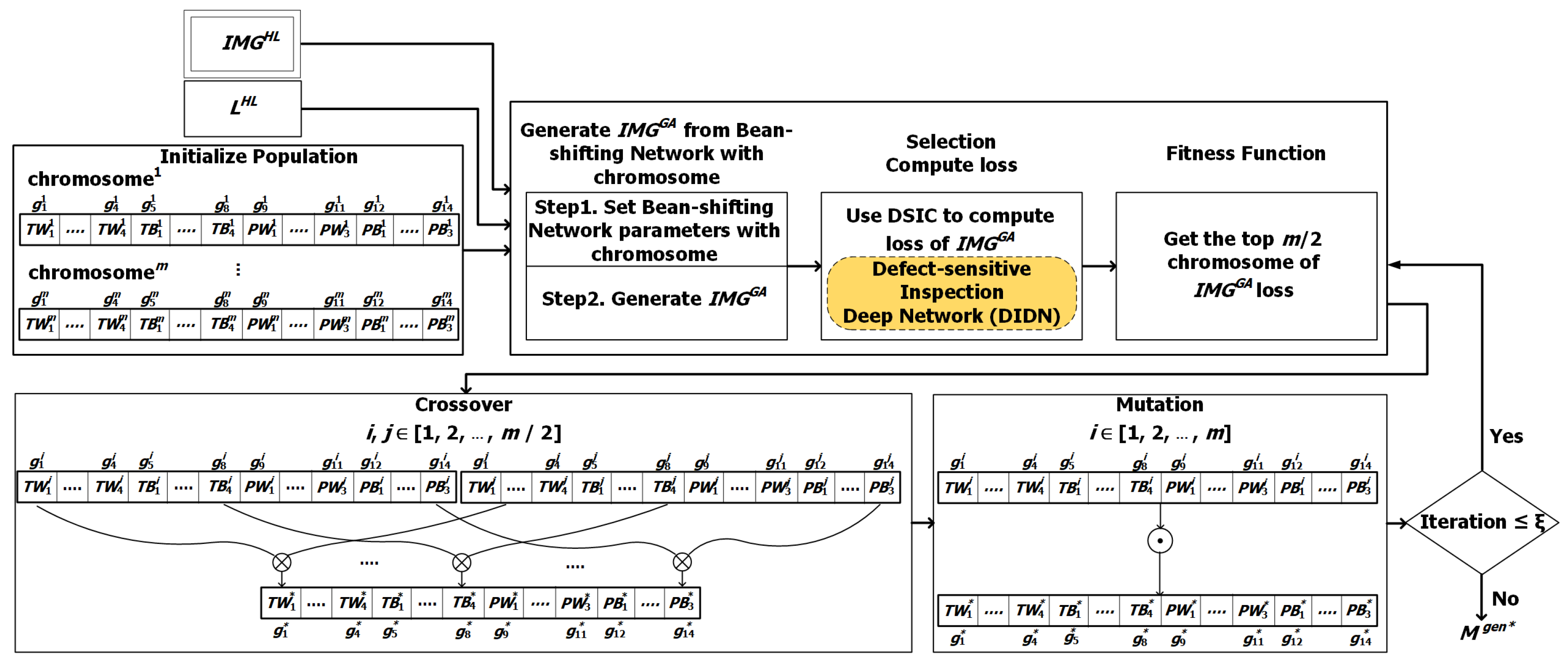
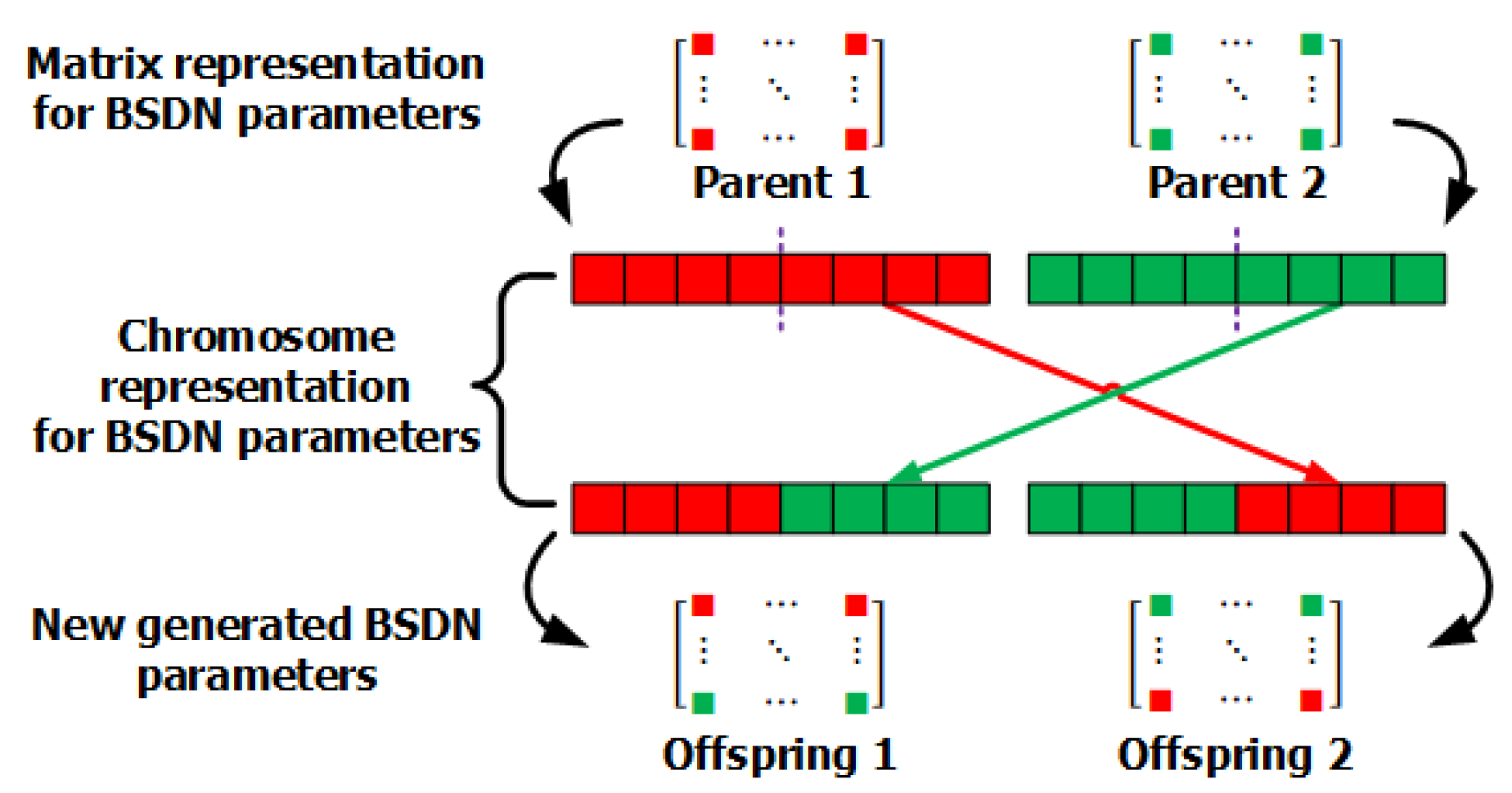
4.4. GA-based Optimizer for the Proposed GAN Framework
| Algorithm 1: GA-based GAN Optimizer. |
 |
4.5. Low-Detection-Rate Bean Image Generation for the LBIG Module
5. Proposed Model Quality Control in the GALDAM
5.1. Augmented-Image Quality Checking for Filtering Heavily Bean-Overlapping Images
- Step 1:
- Set image counter , bean label set , and bean image set .
- Step 2:
- Determine whether image i is qualified to be reserved. If the criterion () holds, then the i-th bean image is qualified and reserves its information as the following substeps:Add into ;Add into ;
- Step 3:
- Prepare the next image. If i is less than the number of training images, then increase the image counter by one, i.e., and go to Step 2.
- Step 4:
- Return the qualified images and associated labels, ().
5.2. Model Quality Checking for Continuously Improving Inspection Capability
- Step 1:
- Calculate in Equation (8): .
- Step 2:
- Check model quality by computing the criterion: .
- Step 2.1:
- If the condition holds, then the current model is the best model, which is the output of this algorithm. That is, two following steps is performed in this subcase: ;Return ;
- Step 2.2:
- Otherwise, the whole model training process shall continue with preparing new data set for the following iteration: ;;;go back to the DSMC module; (see Figure 4).
6. Case Study
6.1. Experimental Settings and Performance Metrics
6.2. Visualization of Data-Augmentation Results
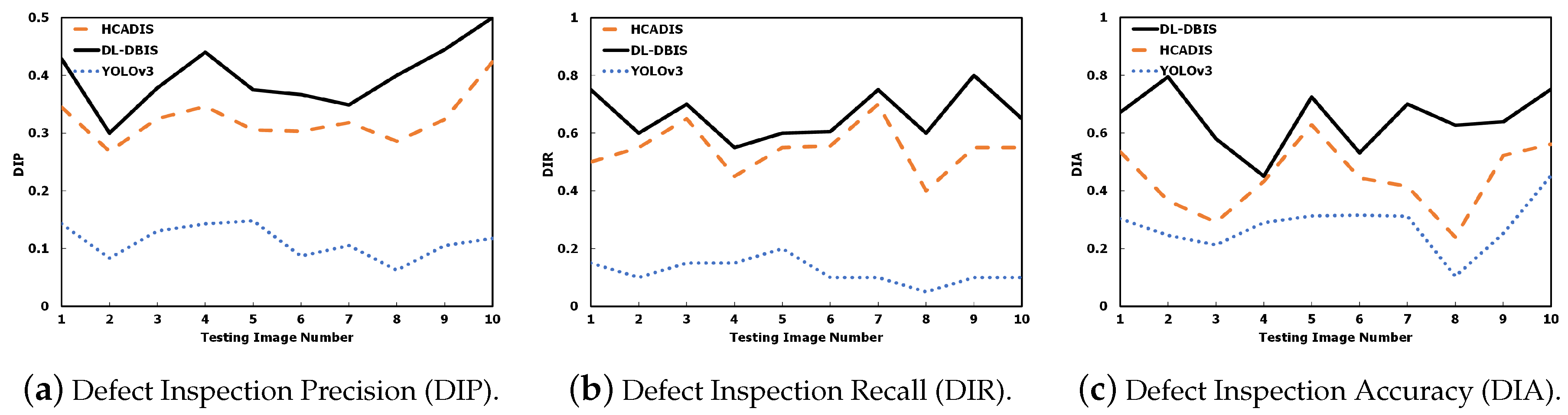
6.3. Performance Study of the Optimal Model in the DIDN
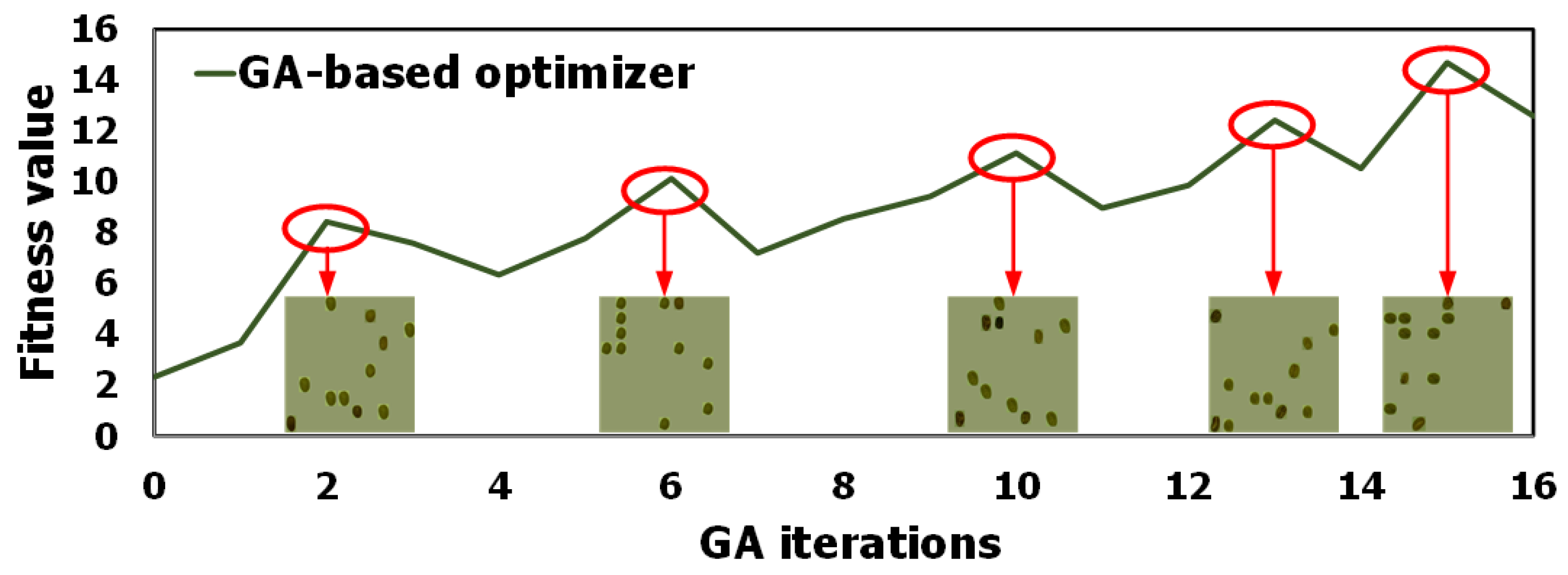
6.4. Efficiency of the GA-Based Optimizer
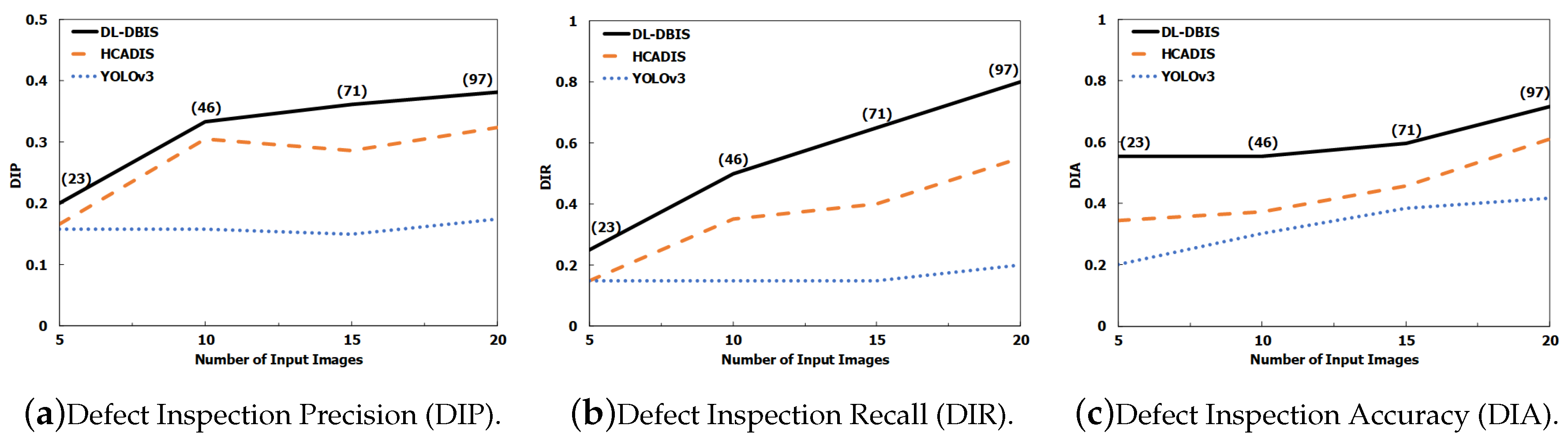
6.5. Performance Comparisons of Various Schemes to Different Number of Human-Labeled Images
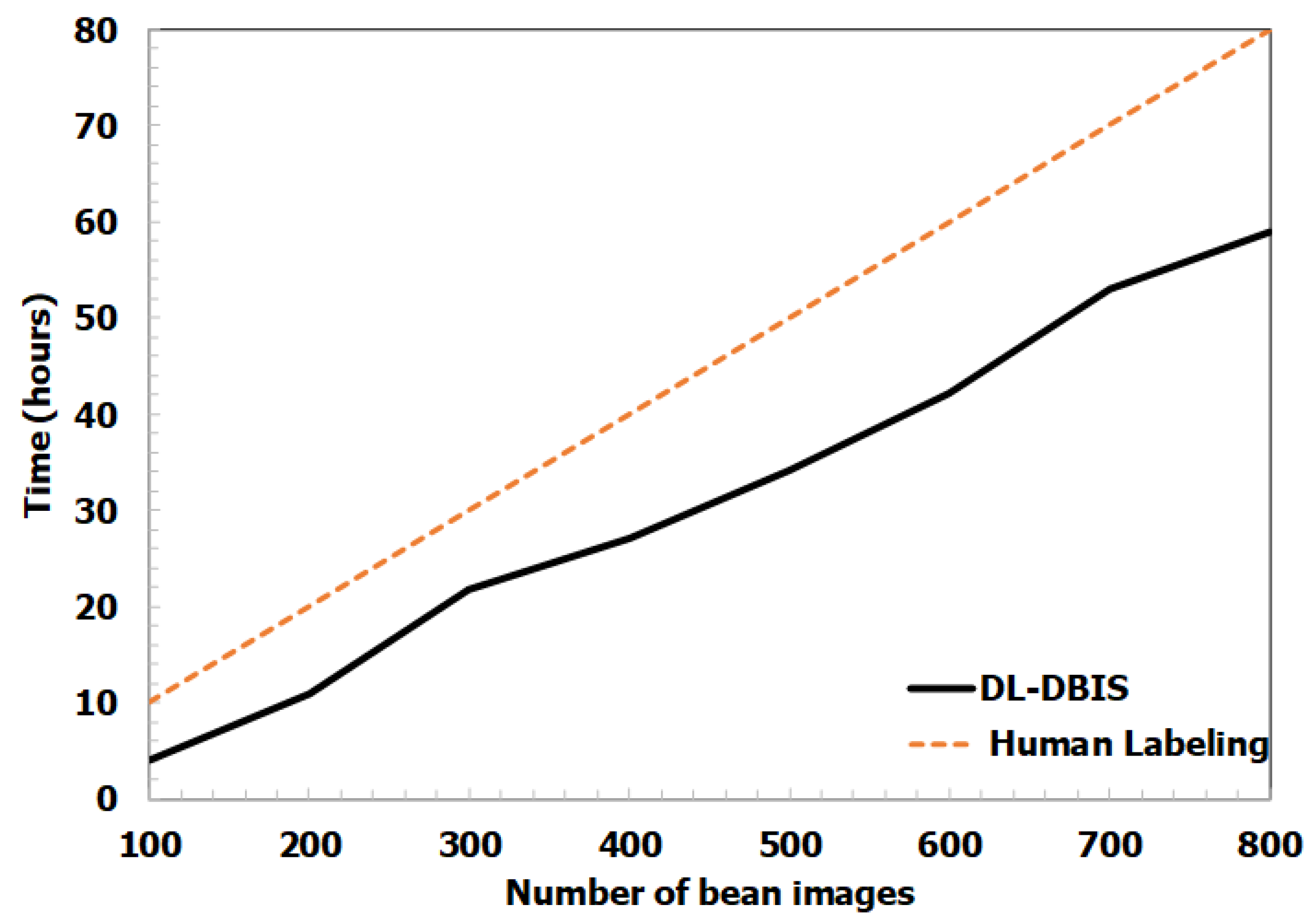
6.6. Efficiency of the Proposed DL-DBIS
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AIQC | augmented-image qualify check |
| BB | bounding box |
| BBC | bounding box class |
| BSDN | bean-shifting deep network |
| CP | class probability |
| DIA | Defect Inspection Accuracy |
| DIDN | defect-sensitive inspection deep network |
| DIP | Defect Inspection Precision |
| DIR | Defect Inspection Recall |
| DMQC | defect-sensitive model quality check |
| DSMC | defect-sensitive model creation |
| GDV | grid-description vector |
| GIMG | GAN-based image-augmentation model generation |
| LBIDB | labeled-bean image database |
| LBIG | low-detection-rate bean image generation |
| SPCOM | single-point crossover over matrix |
References
- Caporaso, N.; Whitworth, M.B.; Cui, C.; Fisk, I.D. Variability of single bean coffee volatile compounds of Arabica and Robusta roasted coffees analysed by SPME-GC-MS. Food Res. Int. 2018, 108, 628–640. [Google Scholar] [CrossRef] [PubMed]
- Belay, A.; Bekele, Y.; Abraha, A.; Comen, D.; Kim, H.; Hwang, Y.H. Discrimination of Defective (Full Black, Full Sour and Immature) and Nondefective Coffee Beans by Their Physical Properties. J. Food Process Eng. 2014, 37. [Google Scholar] [CrossRef]
- Ye, R.; Pan, C.S.; Chang, M.; Yu, Q. Intelligent defect classification system based on deep learning. Adv. Mech. Eng. 2018, 10, 1–7. [Google Scholar] [CrossRef]
- Setoyama, D.; Iwasa, K.; Seta, H.; Shimizu, H.; Fujimura, Y.; Miura, D.; Wariishi, H.; Nagai, C.; Nakahara, K. High-Throughput Metabolic Profiling of Diverse Green Coffea arabica Beans Identified Tryptophan as a Universal Discrimination Factor for Immature Beans. PLoS ONE 2013, 8, e70098. [Google Scholar] [CrossRef] [PubMed]
- Thazin, Y.; Pobkrut, T.; Kerdcharoen, T. Prediction of Acidity Levels of Fresh Roasted Coffees Using E-nose and Artificial Neural Network. In Proceedings of the 2018 10th International Conference on Knowledge and Smart Technology (KST), Chiang Mai, Thailand, 31 January–3 February 2018; pp. 210–215. [Google Scholar]
- Arboleda, E.R.; Fajardo, A.C.; Medina, R.P. An image processing technique for coffee black beans identification. In Proceedings of the 2018 IEEE International Conference on Innovative Research and Development (ICIRD), Bangkok, Thailand, 11–12 May 2018; pp. 1–5. [Google Scholar]
- Livio, J.; Hodhod, R. AI Cupper: A Fuzzy Expert System for Sensorial Evaluation of Coffee Bean Attributes to Derive Quality Scoring. IEEE Trans. Fuzzy Syst. 2018, 26, 3418–3427. [Google Scholar] [CrossRef]
- Rutayisire, J.; Markon, S.; Raymond, N. IoT based Coffee quality monitoring and processing system in Rwanda. In Proceedings of the 2017 International Conference on Applied System Innovation, Sapporo, Japan, 13–17 May 2017; pp. 1209–1212. [Google Scholar] [CrossRef]
- De Araujo, S.A.; Pessota, J.H.; Kim, H.Y. Beans quality inspection using correlation-based granulometry. Eng. Appl. Artif. Intell. 2015, 40, 84–94. [Google Scholar] [CrossRef]
- Portugal-Zambrano, C.E.; Gutiérrez-Cáceres, J.C.; Ramirez-Ticona, J.; Beltran-Castañón, C.A. Computer vision grading system for physical quality evaluation of green coffee beans. In Proceedings of the 2016 XLII Latin American Computing Conference, Valparaiso, Chile, 10–14 October 2016; pp. 1–11. [Google Scholar]
- Apaza, R.G.; Portugal-Zambrano, C.E.; Gutiérrez-Cáceres, J.C.; Beltrán-Castañón, C.A. An approach for improve the recognition of defects in coffee beans using retinex algorithms. In Proceedings of the 2014 XL Latin American Computing Conference, Montevideo, Uruguay, 15–19 September 2014; pp. 1–9. [Google Scholar]
- Turi1, B.; Abebe1, G.; Goro, G. Classification of Ethiopian Coffee Beans Using Imaging Techniques. East Afr. J. Sci. 2013, 7, 1–10. [Google Scholar]
- Gan, W.; Lin, J.C.W.; Fournier-Viger, P.; Chao, H.C.; Yu, P.S. A Survey of Parallel Sequential Pattern Mining. ACM Trans. Knowl. Discov. Data 2019, 13, 25. [Google Scholar] [CrossRef]
- Gan, W.; Lin, J.C.W.; Fournier-Viger, P.; Chao, H.C.; Yu, P.S. A Survey of Utility-Oriented Pattern Mining. IEEE Trans. Knowl. Data Eng. 2019. accepted and to appear. [Google Scholar] [CrossRef]
- Gan, W.; Lin, J.C.W.; Fournier-Viger, P.; Chao, H.C.; Yu, P.S. HUOPM: High Utility Occupancy Pattern Mining. IEEE Trans. Cybern. 2019. accepted and to appear. [Google Scholar] [CrossRef]
- Baeta, R.; Nogueira, K.; Menotti, D.; dos Santos, J.A. Learning Deep Features on Multiple Scales for Coffee Crop Recognition. In Proceedings of the 30th SIBGRAPI Conf. on Graphics, Patterns and Images, Niteroi, Brazil, 17–20 October 2017; pp. 262–268. [Google Scholar]
- Pinto, C.; Furukawa, J.; Fukai, H.; Tamura, S. Classification of Green coffee bean images based on defect types using convolutional neural network (CNN). In Proceedings of the International Conference on Advanced Informatics, Concepts, Theory, and Applications, Denpasar, Indonesia, 16–18 August 2017; pp. 1–5. [Google Scholar]
- Winjaya, F.; Rivai, M.; Purwanto, D. Identification of cracking sound during coffee roasting using neural network. In Proceedings of the 2017 International Seminar on Intelligent Technology and Its Applications, Surabaya, Indonesia, 28–29 August 2017; pp. 271–274. [Google Scholar]
- Mesin, L.; Alberto, D.; Pasero, E.; Cabilli, A. Control of coffee grinding with Artificial Neural Networks. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–5. [Google Scholar]
- Kuo, C.J.; Wang, D.C.; Lee, P.X.; Chen, T.T.; Horng, G.J.; Tsai, Z.J.; Guo, G.M.; Lin, Y.C.; Hung, M.H.; Chen, C.C. Quad-Partitioning-based Robotic Arm Guidance based on Image Data Processing with Single Inexpensive Camera for Precisely Picking Bean Defects in Coffee Industry. In Proceedings of the 11th Asian Conference on Intelligent Information and Database Systems, Yogyakarta, Indonesia, 8–11 April 2019; pp. 152–164. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Widrow, B.; Lehr, M. 30 years of adaptive neural networks: perceptron, Madaline, and backpropagation. Proc. IEEE 1990, 78, 1415–1442. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; MIT Press Cambridge, Inc.: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based Generative Adversarial Network. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Denton, E.; Chintala, S.; Szlam, A.; Fergus, R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. arXiv 2015, arXiv:1506.05751. [Google Scholar]
- Alec Radford, L.M.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Zhu, J.Y.; Krähenbühl, P.; Shechtman, E.; Efros, A.A. Generative Visual Manipulation on the Natural Image Manifold. arXiv 2016, arXiv:1609.03552. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Mathieu, M.; Zhao, J.; Sprechmann, P.; Ramesh, A.; LeCun, Y. Disentangling factors of variation in deep representation using adversarial training. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: NewYork, NY, USA, 2016; pp. 5040–5048. [Google Scholar]
- Tang, Y.; Tang, Y.; Xiao, J.; Summers, R.M. XLSor: A Robust and Accurate Lung Segmentor on Chest X-Rays Using Criss-Cross Attention and Customized Radiorealistic Abnormalities Generation. In Proceedings of the 2019 International Conference on Medical Imaging with Deep Learning, London, UK, 8–10 July 2019. [Google Scholar]
- Nie, D.; Trullo, R.; Petitjean, C.; Ruan, S.; Shen, D. Medical Image Synthesis with Context-Aware Generative Adversarial Networks. In Proceedings of the 2017 Medical Image Computing and Computer Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017. [Google Scholar]
- Tang, Y.; Tang, Y.; Sandfort, V.; Xiao, J.; Summers, R.M. TUNA-Net: Task-oriented UNsupervised Adversarial Network for Disease Recognition in Cross-Domain Chest X-rays. In Proceedings of the 2019 International Conference on Medical Image Computing and Computer Assisted Intervention, Shenzhen, China, 13–17 October 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
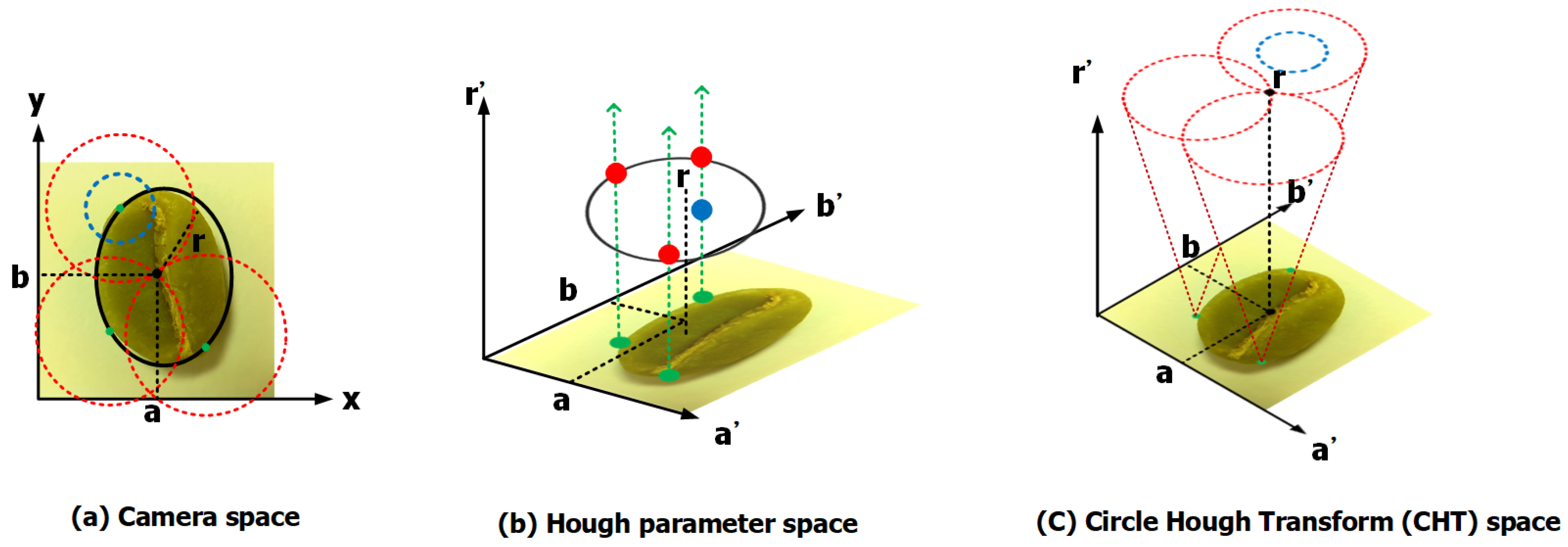
- Kuo, C.J.; Wang, D.C.; Chen, T.T.; Chou, Y.C.; Pai, M.Y.; Horng, G.J.; Hung, M.H.; Lin, Y.C.; Hsu, T.H.; Chen, C.C. Improving Defect Inspection Quality of Deep-Learning Network in Dense Beans by Using Hough Circle Transform for Coffee Industry. In Proceedings of the IEEE International Conference on System, Man, and Cybernetics (IEEE SMC), Bari, Italy, 6–9 October 2019. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Cha, Y.J.; You, K.; Choi, W. Vision-based detection of loosened bolts using the Hough transform and support vector machines. Autom. Constr. 2016, 71, 181–188. [Google Scholar] [CrossRef]
- Chiu, S.H.; Liaw, J.J.; Lin, K.H. A Fast Randomized Hough Transform for Circle/Circular Arc Recognition. Int. J. Pattern Recognit. Artif. Intell. 2010, 24, 457–474. [Google Scholar] [CrossRef]
- Pulli, K.; Baksheev, A.; Kornyakov, K.; Eruhimov, V. Real-Time Computer Vision with OpenCV. Commun. ACM 2012, 55, 61–69. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Interaction with related modules |
| LBIDB | provides the human-labeling training data to DSMC, GIMG, and low-detection-rate bean image generation (LBIG). |
| DSMC | creates a defect-sensitive model for GIMG and DMQC. |
| GIMG | creates a generative network model for LBIG. |
| LBIG | generates and via BSDN for AIQC. |
| AIQC | verifies the quality of and from LBIG and produces and for DMQC. |
| DMQC | verifies the quality of from DSMC with and and activates DSMC for the next |
| model training iteration if current model is not qualified. |
| Layer | # of Neurons | : Weighting Matrix Size | : Bias Vector Size |
|---|---|---|---|
| (Weights of Two Consecutive Layers.) | (Bias of the Linear Function.) | ||
| T-Layer 1 | |||
| T-Layer 2 | |||
| T-Layer 3 | |||
| Bean-Location Layer | |||
| P-Layer 1 | |||
| P-Layer 2 | |||
| P-Layer 3 |
| Layer | Linear Function | Activation Function |
|---|---|---|
| : See Equation (4). | ||
| T-Layer 1 | ||
| T-Layer 2 | ||
| T-Layer 3 | ||
| Bean-Location Layer | ||
| P-Layer 1 | ||
| P-Layer 2 | ||
| P-Layer 3 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chou, Y.-C.; Kuo, C.-J.; Chen, T.-T.; Horng, G.-J.; Pai, M.-Y.; Wu, M.-E.; Lin, Y.-C.; Hung, M.-H.; Su, W.-T.; Chen, Y.-C.; et al. Deep-Learning-Based Defective Bean Inspection with GAN-Structured Automated Labeled Data Augmentation in Coffee Industry. Appl. Sci. 2019, 9, 4166. https://0-doi-org.brum.beds.ac.uk/10.3390/app9194166
Chou Y-C, Kuo C-J, Chen T-T, Horng G-J, Pai M-Y, Wu M-E, Lin Y-C, Hung M-H, Su W-T, Chen Y-C, et al. Deep-Learning-Based Defective Bean Inspection with GAN-Structured Automated Labeled Data Augmentation in Coffee Industry. Applied Sciences. 2019; 9(19):4166. https://0-doi-org.brum.beds.ac.uk/10.3390/app9194166
Chicago/Turabian StyleChou, Yung-Chien, Cheng-Ju Kuo, Tzu-Ting Chen, Gwo-Jiun Horng, Mao-Yuan Pai, Mu-En Wu, Yu-Chuan Lin, Min-Hsiung Hung, Wei-Tsung Su, Yi-Chung Chen, and et al. 2019. "Deep-Learning-Based Defective Bean Inspection with GAN-Structured Automated Labeled Data Augmentation in Coffee Industry" Applied Sciences 9, no. 19: 4166. https://0-doi-org.brum.beds.ac.uk/10.3390/app9194166