Diagnosis and Prediction of Large-for-Gestational-Age Fetus Using the Stacked Generalization Method

 , , , , , and
, , , , , and
Abstract
:1. Introduction
2. Related Work
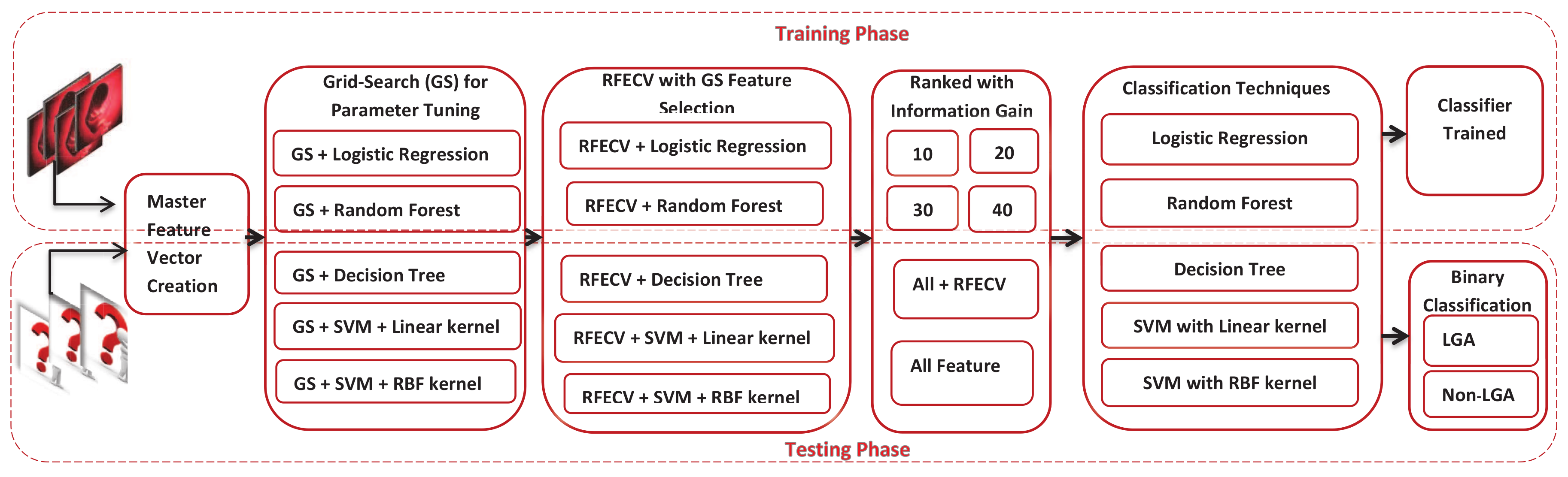
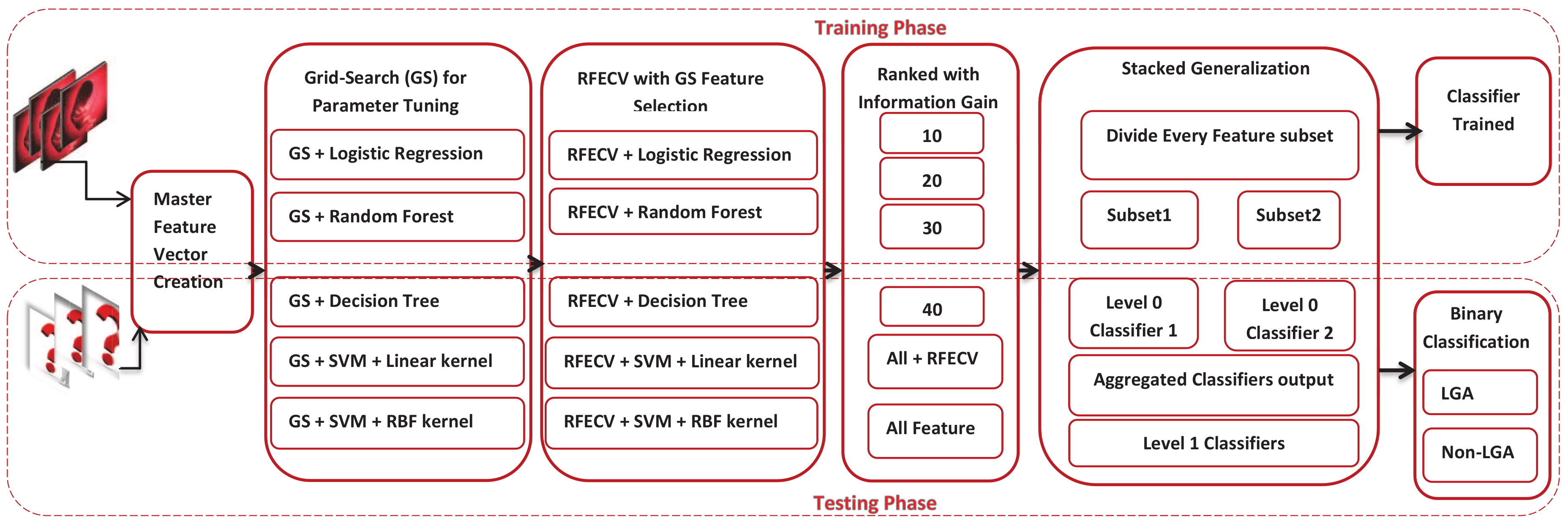
3. Materials and Methods
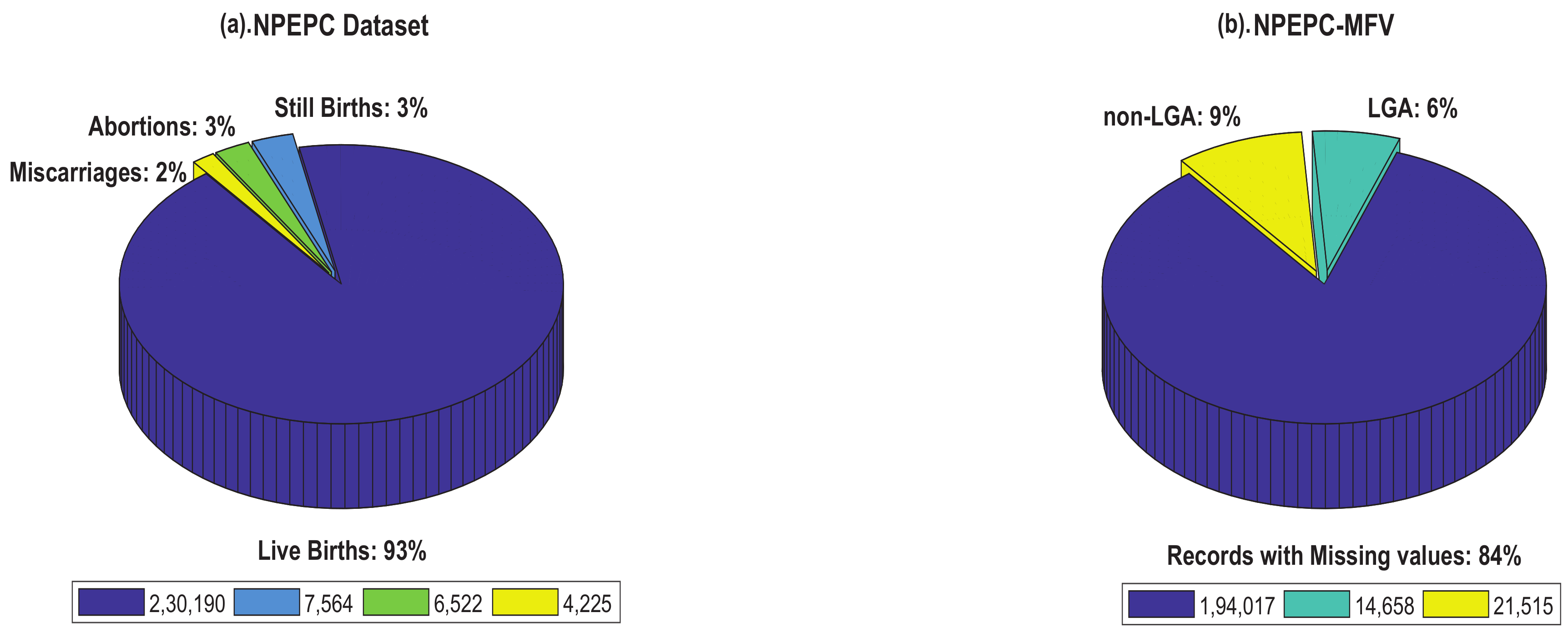
3.1. Dataset Collection
3.2. Preparation of the Master Feature Vector
Algorithm 1: Creates a Master Feature Vector with an intention to impute and remove missing values with a certain threshold to improve classification and feature selection and extraction process performance on the obtained LGA dataset Input: LGA dataset with features and records. Output: LGA dataset L with f features and n records |
1: For each row in , add classification column c, following [27] infant classification guidelines. 2: Discritize each -th feature of with literature and pediatrician’s expertise. 3: Impute in missing value of each record of . 4: Remove record from with missing threshold of from controls and from the cases 5: Impute discrete value with mode of every -th feature. 6: return LGA dataset L with f features and n records. |
3.3. Preparation of the Principal Feature Vector
3.3.1. GridSearch-Based RFECV + IG Feature Selection Scheme
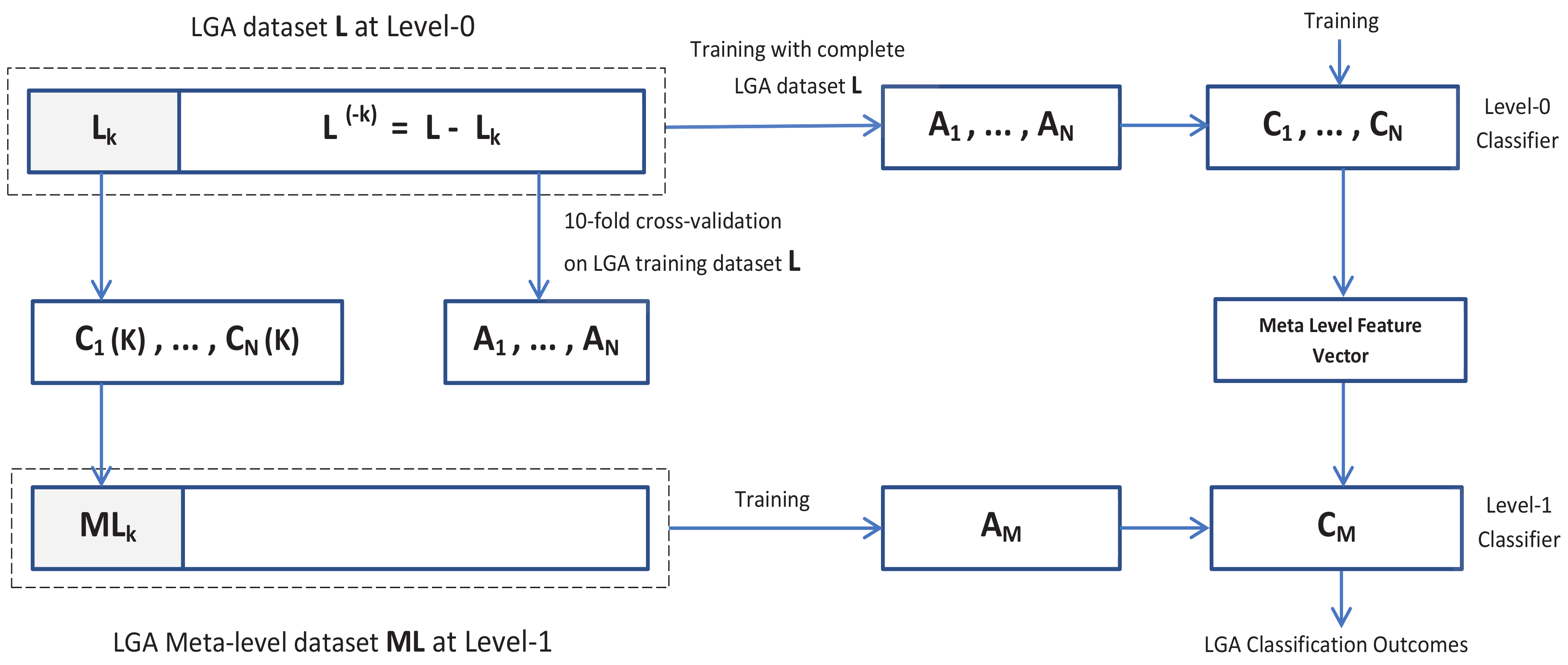
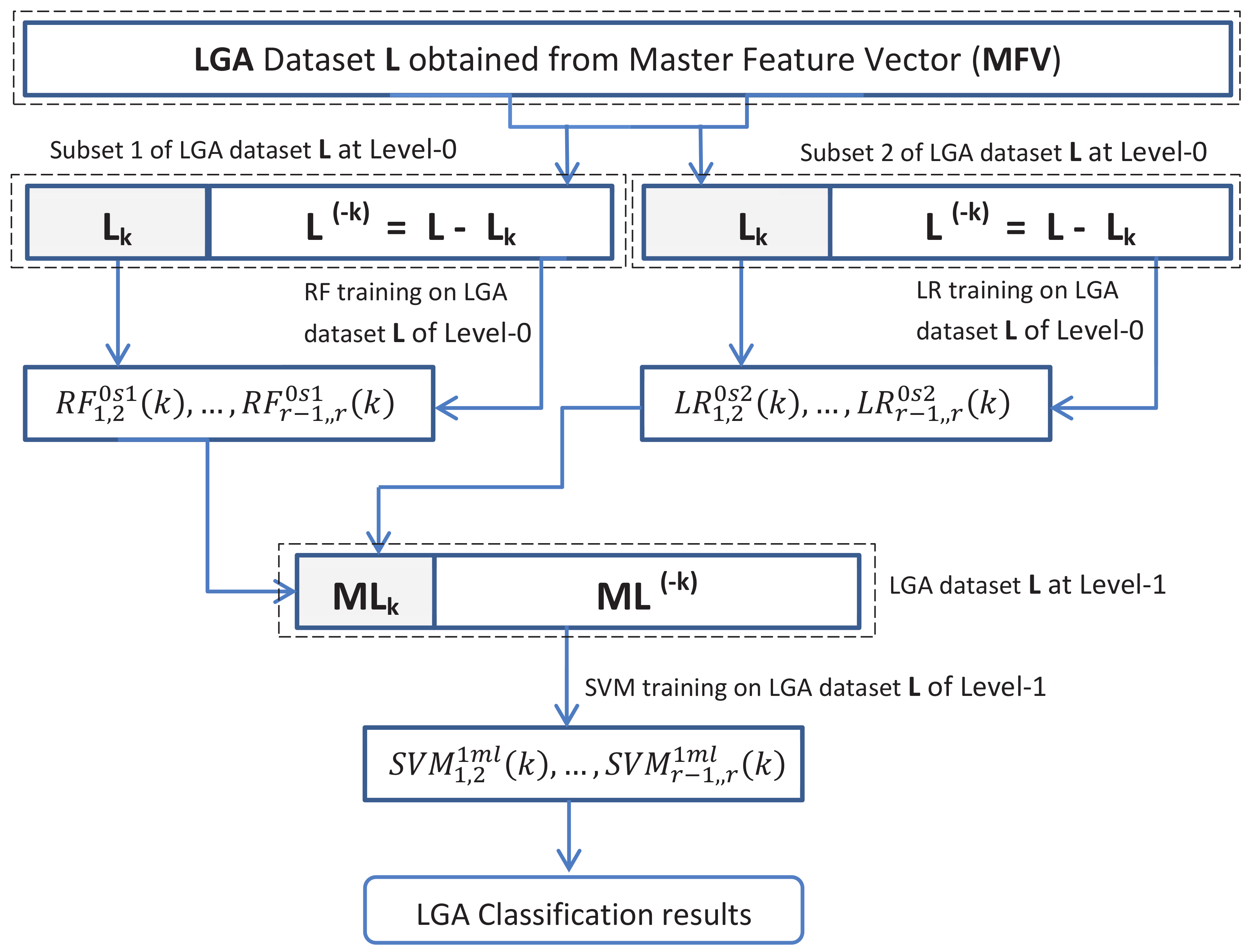
3.3.2. Feature Extraction and Dimension Reduction with Stacked Generalization
3.4. LGA Classification Tools and Schemes
3.5. Performance Evaluation Metrics
4. Experiment Results
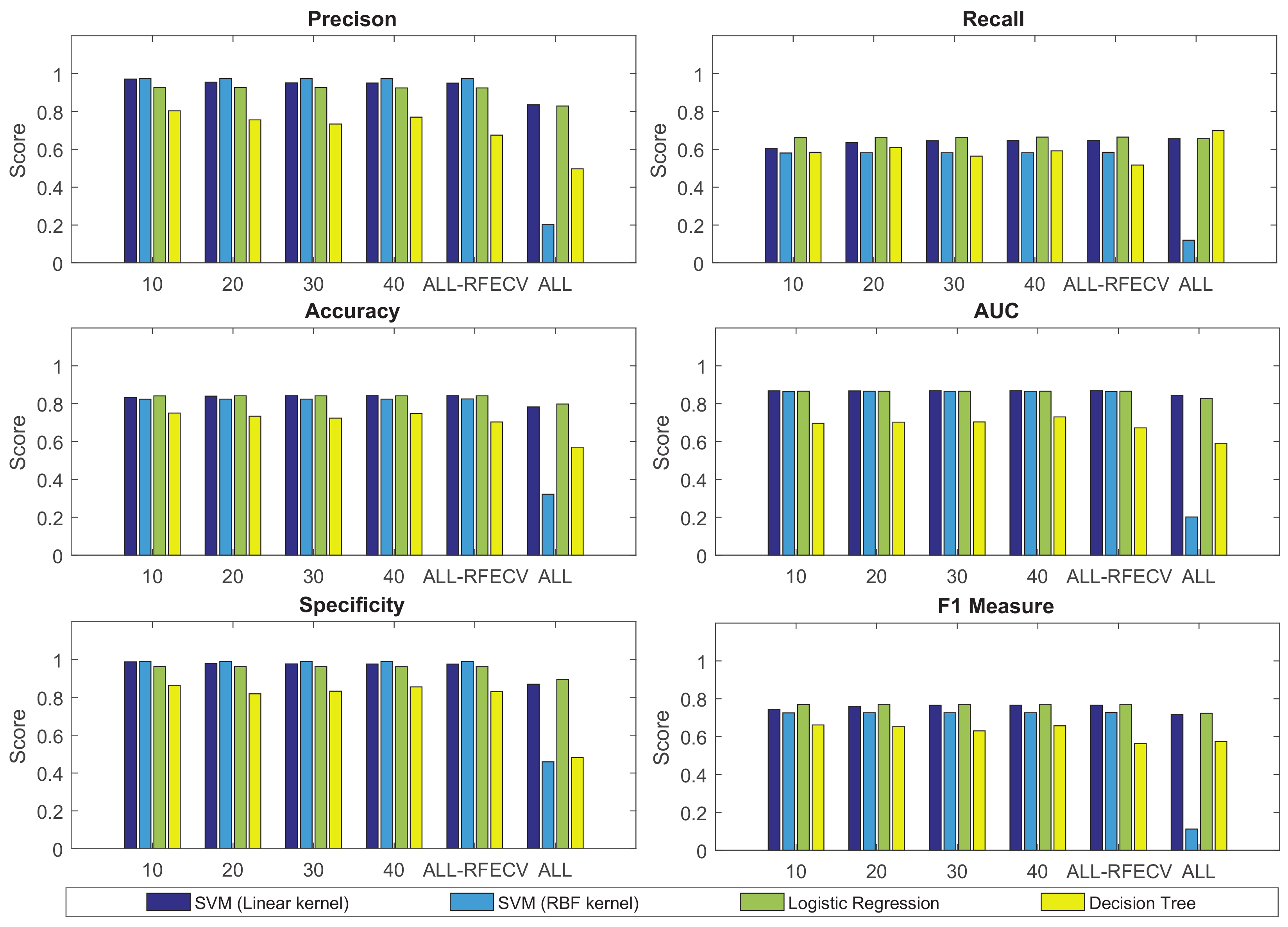
4.1. Results of GridSearch Based RFECV + IG Feature Selection Scheme for LGA Prediction
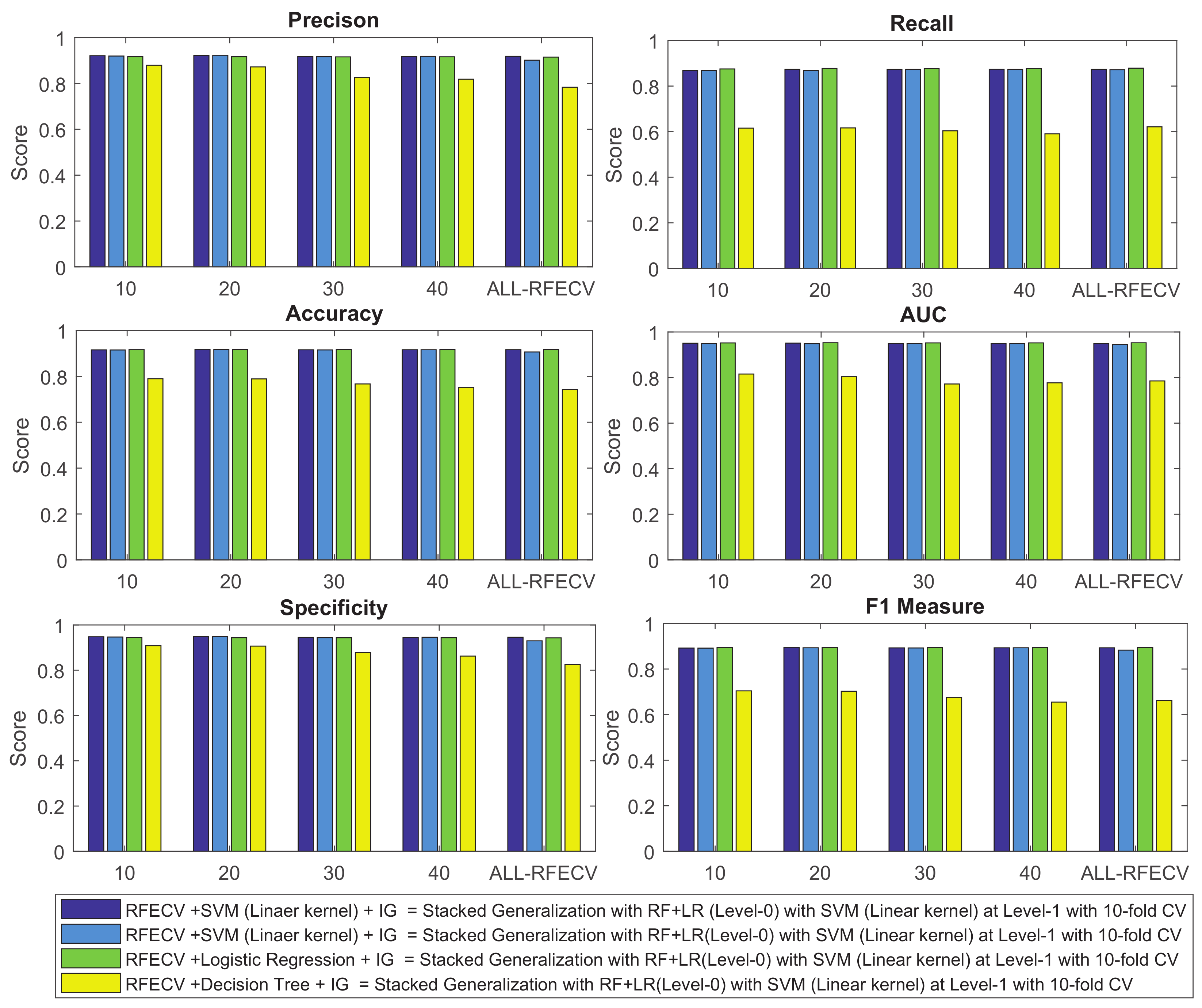
4.2. Results of GridSearch Based RFECV + IG Feature Selection Scheme with Stacking for LGA Prediction
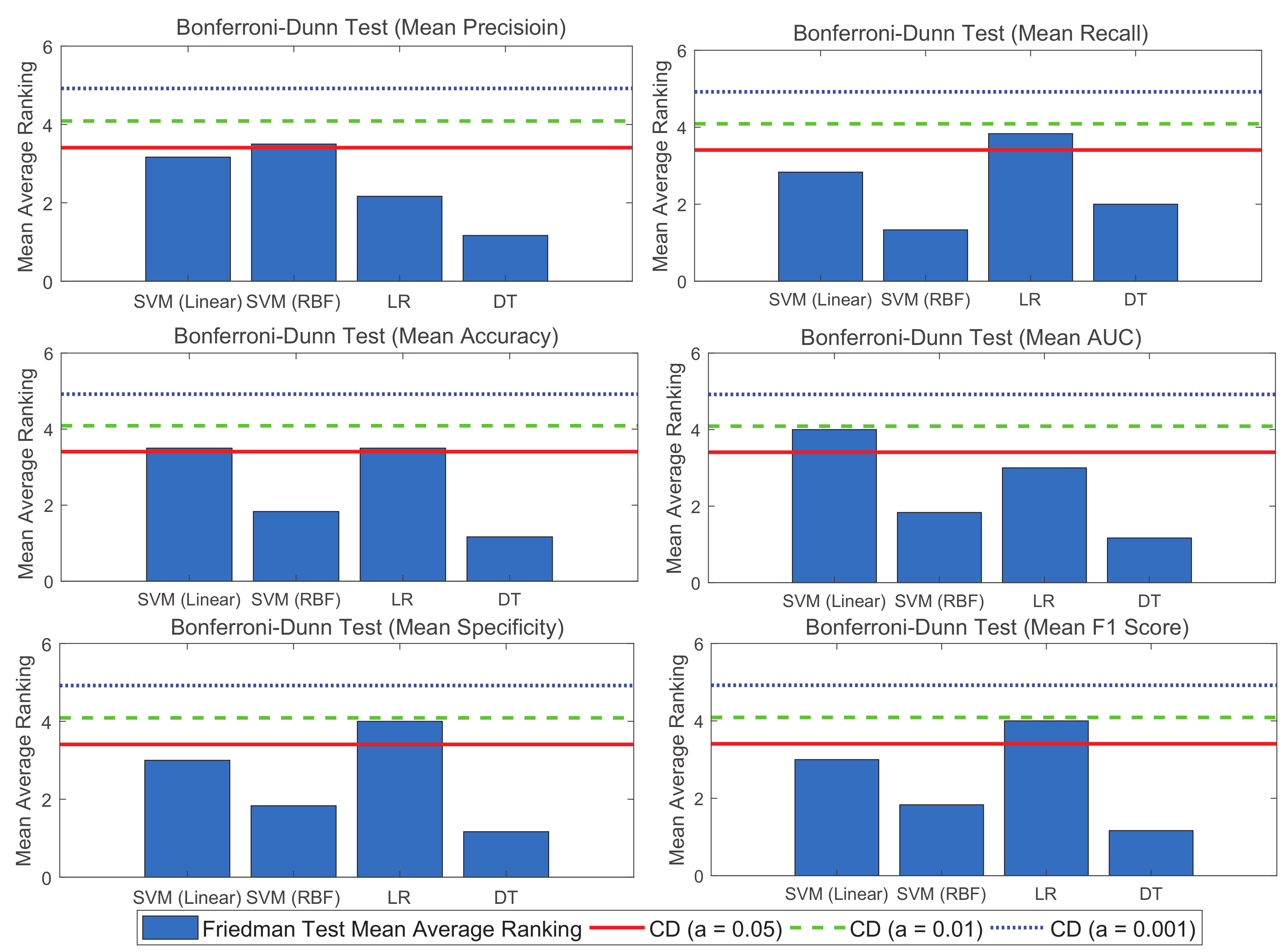
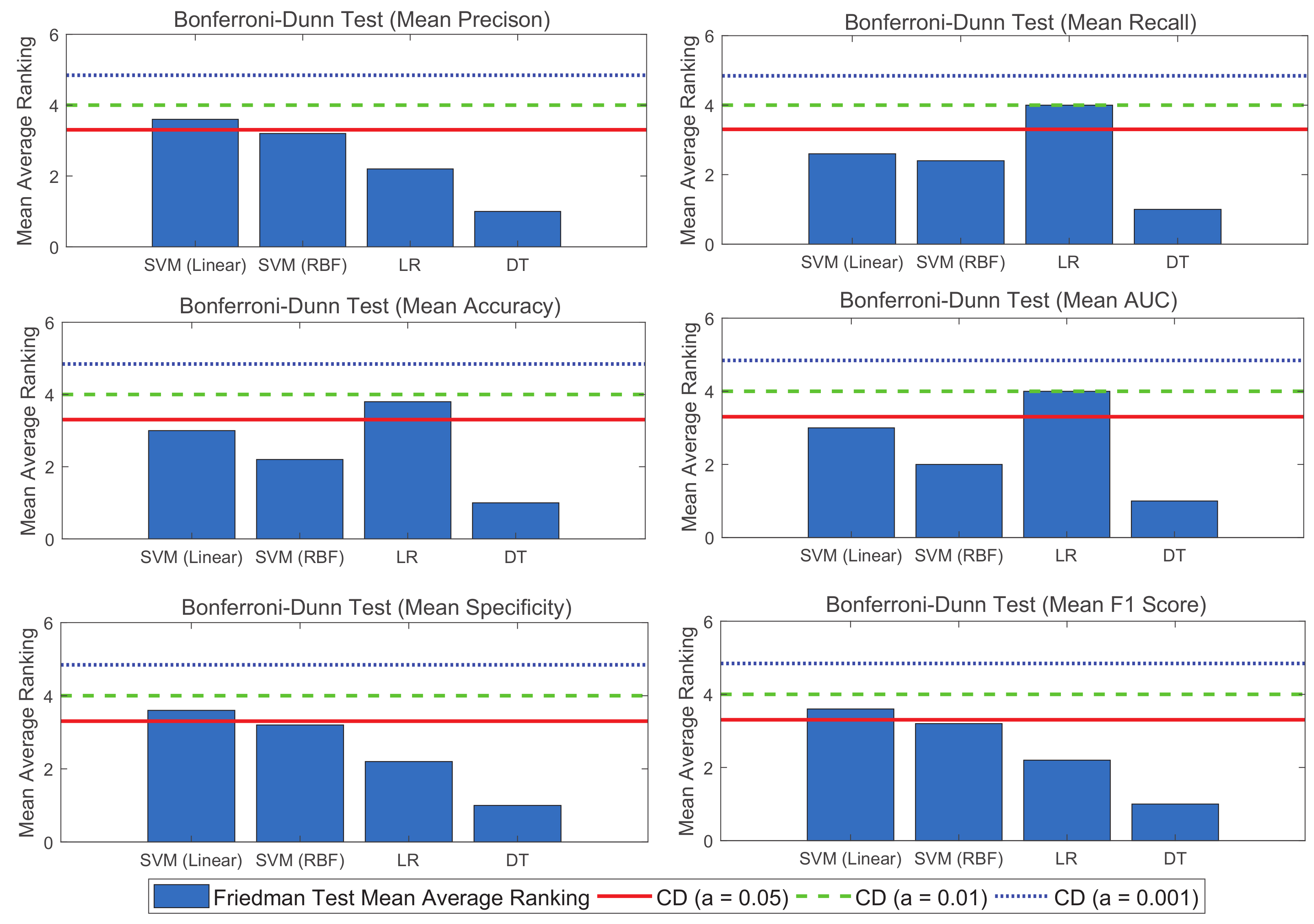
5. Discussions and Comparative Analysis with Existing State-of-the-Art LGA Classifications
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Chiavaroli, V.; Castorani, V.; Guidone, P.; Derraik, J.B.; Liberati, M.; Chiarelli, F.; Mohn, A. Incidence of infants born small- and large-for-gestational-age in an Italian cohort over a 20-year period and associated risk factors. Ital. J. Pediatr. 2016, 42, 42. [Google Scholar] [CrossRef] [Green Version]
- Mendez-Figueroa, H.; Truong, V.T.; Pedroza, C.; Chauhan, S.P. Large for gestational age infants and adverse outcomes among uncomplicated pregnancies at term. Am. J. Perinatol. 2017, 34, 655–662. [Google Scholar] [PubMed]
- Battaglia, F.C.; Lubchenco, L.O. A practical classification of newborn infants by weight and gestational age. J. Pediatr. 1967, 71, 159–163. [Google Scholar] [CrossRef]
- Lazer, S.; Biale, Y.; Mazor, M.; Lewenthal, H.; Insler, V. Complications associated with the macrosomic fetus. J. Reprod. Med. 1986, 31, 501–505. [Google Scholar] [PubMed]
- Meshari, A.A.; Silva, S.D.; Rahman, I. Fetal macrosomia, maternal risks and fetal outcome. Int. J. Gynecol. Obstet. 1990, 32, 215–222. [Google Scholar] [CrossRef]
- Boney, C.M.; Verma, A.; Tucker, R.; Vohr, B.R. Metabolic syndrome in childhood: Association with birth weight, maternal obesity, and gestational diabetes mellitus. Pediatrics 2005, 115, 290–296. [Google Scholar] [CrossRef] [PubMed]
- Dyer, J.S.; Rosenfeld, C.R.; Rice, J.; Rice, M.; Hardin, D.S. Insulin resistance in Hispanic large-for-gestational-age neonates at birth. Early Hum. Dev. 2007, 83, S138. [Google Scholar] [CrossRef]
- Ingrid, W.M.D.; Axelsson, O.; Bergstrom, R. Maternal factors associated with high birth weight. Acta Obstet. Gynecol. Scand. 2011, 70, 55–61. [Google Scholar]
- Dietz, W.H. Overweight in childhood and adolescence. N. Engl. J. Med. 2004, 350, 855–857. [Google Scholar] [CrossRef]
- Van Assche, F.A.; Devlieger, R.; Harder, T.; Plagemann, A. Mitogenic effect of insulin and developmental programming. Diabetologia 2010, 53, 1243. [Google Scholar] [CrossRef]
- Xu, H.; Simonet, F.; Luo, Z.C. Optimal birth weight percentile cut-offs in defining small- or large-for-gestational-age. Acta Paid. 2010, 99, 550–555. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Wang, A.; Shen, H. Design implementation and significance of Chinese free pre-pregnancy eugenics checks projec. Natl. Med. J. China 2015, 95, 162–165. [Google Scholar]
- Shen, Y.; Zhao, W.; Lin, J.; Liu, F. Accuracy of sonographic fetal weight estimation prior to delivery in a Chinese han population. J. Clin. Ultrasound 2017, 45, 465–471. [Google Scholar] [CrossRef] [PubMed]
- Blue, N.R.; Jmp, Y.; Holbrook, B.D.; Nirgudkar, P.A.; Mozurkewich, E.L. Abdominal circumference alone versus estimated fetal weight after 24 weeks to predict small or large for gestational age at birth: A meta-analysis. Am. J. Perinatol. 2017, 34, 1115–1124. [Google Scholar] [PubMed]
- Harper, L.M.; Jauk, V.C.; Owen, J.; Biggio, J.R. The utility of ultrasound surveillance of fluid and growth in obese women. Am. J. Obstet. Gynecol. 2014, 211, 524.e1–524.e8. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Wei, J.; Tong, M.; Yu, L.; Lee, A.C.; Gao, Y.F.; Zhao, M. Associations between body mass index and maternal weight gain on the delivery of LGA infants in Chinese women with gestational diabetes mellitus. J. Diabetes Its Complicat. 2015, 29, 1037–1041. [Google Scholar] [CrossRef]
- Moore, G.S.; Kneitel, A.W.; Walker, C.K.; Gilbert, W.M.; Xing, G. Autism risk in small- and large-for-gestational-age infants. Am. J. Obstet. Gynecol. 2012, 206, 314.e1–314.e9. [Google Scholar] [CrossRef]
- Luangkwan, S.; Vetchapanpasat, S.; Panditpanitcha, P.; Yimsabai, R.; Subhaluksuksakorn, P.; Loyd, R.A.; Uengarporn, N. Risk factors of small for gestational age and large for gestational age at Buriram hospital. J. Med. Assoc. Thai 2015, 98, S71–S78. [Google Scholar]
- Khanolkar, A.R.; Hanley, G.E.; Koupil, I.; Janssen, P.A. 2009 IOM guidelines for gestational weight gain: How well do they predict outcomes across ethnic groups. Ethn. Health 2017, 1–16. [Google Scholar] [CrossRef]
- Kominiarek, M.A.; Grobman, W.; Adam, E.; Buss, C.; Culhane, J.; Entringer, S.; Simhan, H.; Wadhwa, P.D.; Kim, K.Y.; Keenan-Devlin, L.; et al. Stress during pregnancy and gestational weight gain. J. Perinatol. 2018, 38, 462–467. [Google Scholar] [CrossRef]
- Shepherd, E.; Gomersall, J.C.; Tieu, J.; Han, S.; Crowther, C.A.; Middleton, P. Combined diet and exercise interventions for preventing gestational diabetes mellitus. Cochrane Libr. 2017, 11. [Google Scholar] [CrossRef] [PubMed]
- Faheem Akhtar, J.L.; Guan, Y. Monitoring bio-chemical indicators using machine learning techniques for an effective large for gestational age prediction model with reduced computational overhead. In Proceedings of the 7th International Conference on Frontier Computing (FC 2018) - Theory, Technologies and Applications, Kuala Lumpur, Malaysia, 3–6 July 2018. [Google Scholar]
- Akhtar, F.; Li, J.; Azeem, M.; Chen, S.; Pan, H.; Wang, Q.; Yang, J.J. Effective LGA prediction using ML techniques monitoring biochemical indicators. J. Supercomput. 2019. [Google Scholar] [CrossRef]
- Akhtar, F.; Li, J.; Pei, Y.; Azeem, M. A semi-supervised technique for lGA prognosis. In Proceedings of The International Workshop on Future Technology FUTECH 2019; Korean Institute of Information Technology: Daejeon, Korea, 2018; pp. 36–37. [Google Scholar]
- Park, D.; Lee, M.; Park, S.; Seong, J.K.; Youn, I. Determination of optimal heart rate variability features based on SVM-recursive feature elimination for cumulative stress monitoring using ECG sensor. Sensors 2018, 18, 2387. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Wang, C.; Wang, R. Using stacked generalization to combine SVMs in magnitude and shape feature spaces for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2193–2205. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, R.; Zhang, S.; Shi, W.; Yan, W.; Wang, X.; Lyu, Q.; Liu, L.; Zhou, Q.; Qiu, Q. Chinese neonatal birth weight curve for different gestational age. Zhonghua Er Ke Za Zhi 2015, 53, 97–103. [Google Scholar]
- Li, J.; Liu, L.; Zhou, M.C.; Yang, J.J.; Chen, S.; Liu, H.T.; Wang, Q.; Pan, H.; Sun, Z.H.; Tan, F. Feature selection and prediction of small-for-gestational-age infants. J. Ambient Intell. Humaniz. Comput. 2018, 1–15. [Google Scholar] [CrossRef]
- Li, J.; Liu, L.; Sun, J.; Mo, H.; Yang, J.; Chen, S.; Liu, H.; Wang, Q.; Pan, H. Comparison of different machine learning approaches to predict small for gestational age infants. IEEE Trans. Big Data 2016, 1–14. [Google Scholar] [CrossRef]
- Yang, J.J.; Li, J.; Mulder, J.; Wang, Y.; Chen, S.; Wu, H.; Wang, Q.; Pan, H. Emerging information technologies for enhanced healthcare. Comput. Ind. 2015, 69, 3–11. [Google Scholar] [CrossRef]
- Miao, J.; Niu, L. A survey on feature selection. Procedia Comput. Sci. 2016, 91, 919–926. [Google Scholar] [CrossRef]
- Li, J.; Wang, F. Semi-supervised learning via mean field methods. Neurocomputing 2016, 177, 385–393. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Cunningham, J.P.; Ghahramani, Z. Linear dimensionality reduction: Survey, insights, and generalizations. J. Mach. Learn. Res. 2015, 16, 2859–2900. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Springer: Berlin, Germany, 1998. [Google Scholar] [CrossRef]
- Adankon, M.M.; Cheriet, M.; Biem, A. Semisupervised least squares support vector machine. IEEE Trans. Neural Netw. 2009, 20, 1858–1870. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Bammann, K. Statistical models: Theory and practice. Biometrics 2006, 62, 943. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Ting, K.M.; Witten, I.H. Issues in stacked generalization. J. Artif. Intell. Res. 1999, 10, 271–289. [Google Scholar] [CrossRef]
- Shmueli, A.; Nassie, D.; Hiersch, L.; Ashwal, E.; Wiznitzer, A.; Yogev, Y.; Aviram, A. 241: Prerecognition of large for gestational age (LGA) fetus and its consequences. Am. J. Obstet. Gynecol. 2017, 216, S150–S151. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, COLT’92, Pittsburgh, PA, USA, 27–29 July 1992; ACM: New York, NY, USA, 1992; pp. 144–152. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Zar, J.H. Biostatistical Analysis, 4th ed.; Pearson Education: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust physical-world attacks on deep learning visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1625–1634. [Google Scholar]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Jafari Meimandi, K.; Gerber, M.S.; Barnes, L.E. HDLTex: Hierarchical deep learning for text classification. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 364–371. [Google Scholar] [CrossRef]
- Kowsari, K.; Heidarysafa, M.; Brown, D.E.; Meimandi, K.J.; Barnes, L.E. Rmdl: Random multimodel deep learning for classification. In Proceedings of the 2nd International Conference on Information System and Data Mining, Lakeland, FL, USA, 9–11 April 2018; pp. 19–28. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Birth Week | Boys Weight (g) | Girls Weight (g) | Birth Week | Boys Weight (g) | Girls Weight (g) |
|---|---|---|---|---|---|
| 24 | 846 | 740 | 34 | 2843 | 2768 |
| 25 | 1031 | 939 | 35 | 3114 | 3028 |
| 26 | 1212 | 1132 | 36 | 3386 | 3286 |
| 27 | 1390 | 1321 | 37 | 3637 | 3515 |
| 28 | 1566 | 1504 | 38 | 3828 | 3691 |
| 29 | 1742 | 1686 | 39 | 3979 | 3803 |
| 30 | 1925 | 1872 | 40 | 4030 | 3872 |
| 31 | 2122 | 2071 | 41 | 4092 | 3921 |
| 32 | 2341 | 2285 | 42 | 4148 | 3963 |
| 33 | 2584 | 2519 | - | - | - |
| RFECV + Machine Learning Classifier | Selected Features | Time (s) |
|---|---|---|
| SVM (Linear kernel) | 53 | 25537 |
| SVM (RBF kernel) | 99 | 201331 |
| Logistic Regression | 38 | 40386 |
| Decision Tree | 270 | 118 |
| Scheme | Feature Subset | Metrics | SVM (Linear) | SVM (rbf) | Logistic Regression | Decision Tree |
|---|---|---|---|---|---|---|
| Master Featuer Vector | All | Precision | 0.8352 | 0.2025 | 0.8289 | 0.4970 |
| All | AUC | 0.8447 | 0.2014 | 0.8281 | 0.5907 | |
| All | Recall | 0.6560 | 0.1198 | 0.6569 | 0.6991 | |
| All | F1-Score | 0.7166 | 0.1117 | 0.7236 | 0.5746 | |
| GridSearch + RFECV | GridSearch + RFECV(All) | Precision | 0.9498 | 0.9691 | 0.9200 | 0.4961 |
| GridSearch + RFECV(All) | AUC | 0.8690 | 0.8606 | 0.8659 | 0.5899 | |
| GridSearch + RFECV(All) | Recall | 0.6461 | 0.6059 | 0.6686 | 0.7008 | |
| GridSearch + RFECV(All) | F1-Score | 0.7663 | 0.7433 | 0.7716 | 0.5745 |
| Experiment Type | Best Classifier | Size | Precision | AUC | Recall | Accuracy | Specificity | F1 |
|---|---|---|---|---|---|---|---|---|
| GirdSearch with | SVM | All | 0.949 | 0.843 | 0.646 | 0.842 | 0.976 | 0.766 |
| tunned parameters | (linear kernel) | |||||||
| GirdSearch + RFECV | SVM | 10 | 0.971 | 0.868 | 0.606 | 0.833 | 0.987 | 0.744 |
| + Information Gain | (linear kernel) | |||||||
| GridSearch + RFECV + IG | Stacked SVM | 10 | 0.920 | 0.950 | 0.8683 | 0.9156 | 0.9478 | 0.8921 |
| + Stack generalization | (linear kernel) |
| Baseline | Scheme | Precision | AUC | Recall | Accuracy | Specificity | F1 |
|---|---|---|---|---|---|---|---|
| Akhtar et al. [22] | IG + ML | 0.71 | 0.71 | - | - | - | - |
| Classifier | - | - | - | - | |||
| Akhtar et al. [23] | Proposed Ensemble Technique | 0.85 | 0.72 | - | - | - | - |
| + ML Classifiers | - | - | - | - | |||
| Akhtar et al. [24] | Proposed Expert Driven | 0.95 | 0.86 | - | 0.85 | - | - |
| + ML Classifiers | - | - | - | ||||
| This Research | GridSearch + RFECV + | 0.92 | 0.95 | 0.87 | 0.92 | 0.95 | 0.89 |
| + IG + Stack Generalization |
| Number | GridSearch + RFECV | GridSearch + RFECV | GridSearch + RFECV | GridSearch + RFECV |
|---|---|---|---|---|
| + IG + SVM(Linear) | + IG + SVM(RBF) | + IG + LR | + IG + DT | |
| 1 | Pregnancy History | Pregnancy History | Pregnancy History | Pregnancy History |
| 2 | Smoking (m) | Smoking (m) | Contraception Used | Contraception Used |
| 3 | Contraception Used | Toxic Pesticide | # Full Term Birth | Normal Birth |
| 4 | # Full Term Birth | Contraception Used | # of Pregnancies | # Full Term Birth |
| 5 | # of Pregnancies | # Full Term Birth | Evaluation Result | # of Pregnancies |
| 6 | Evaluation Result | # of Pregnancies | High Risk Fetus ? | Region Name |
| 7 | High Risk Fetus ? | Evaluation Result | Delivery Week | Follow-up Institution |
| 8 | Delivery Week | High Risk Fetus ? | Normal Birth | Delivery Week |
| 9 | Normal Birth | Delivery Week | Induced Labour | Child Birth Province |
| 10 | # of Fetuses | Premature Delivery | # of Fetuses | Child Birth Town |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akhtar, F.; Li, J.; Pei, Y.; Imran, A.; Rajput, A.; Azeem, M.; Wang, Q. Diagnosis and Prediction of Large-for-Gestational-Age Fetus Using the Stacked Generalization Method. Appl. Sci. 2019, 9, 4317. https://0-doi-org.brum.beds.ac.uk/10.3390/app9204317
Akhtar F, Li J, Pei Y, Imran A, Rajput A, Azeem M, Wang Q. Diagnosis and Prediction of Large-for-Gestational-Age Fetus Using the Stacked Generalization Method. Applied Sciences. 2019; 9(20):4317. https://0-doi-org.brum.beds.ac.uk/10.3390/app9204317
Chicago/Turabian StyleAkhtar, Faheem, Jianqiang Li, Yan Pei, Azhar Imran, Asif Rajput, Muhammad Azeem, and Qing Wang. 2019. "Diagnosis and Prediction of Large-for-Gestational-Age Fetus Using the Stacked Generalization Method" Applied Sciences 9, no. 20: 4317. https://0-doi-org.brum.beds.ac.uk/10.3390/app9204317