Benchmarking Daily Line Loss Rates of Low Voltage Transformer Regions in Power Grid Based on Robust Neural Network

 ,
,  ,
,
Abstract
:1. Introduction
- (1)
- As the number of researches that focus on benchmarking daily line loss rates is limited, a supervised regression method is proposed in this study to obtain benchmark values of daily line loss rates in different transformer regions. In the proposed supervised method, various influencing factors of line loss rates are considered, where a high computation accuracy can be thus ensured.
- (2)
- A novel RNN model is proposed in this study. It possess a multi-path architecture with denoising auto-encoders (DAEs). Moreover, L2 regularization, dropout layer and Huber loss function are also applied in RNN. The robustness and reliability of the proposed regression model are greatly improved when compared with conventional machine learning models according to the testing datasets in the case study.
- (3)
- Based on the multiple outputs of the RNN, a method is proposed to calculate benchmark values and reasonable intervals for line loss rate samples. It can precisely evaluate the quality of sampled datasets and eliminate outliers of line loss rates, increasing the stability of data monitoring.
2. Materials and Methods
2.1. Theoretical Computation Equations of Line Losses
2.2. Datasets
2.2.1. Data Quality Analysis
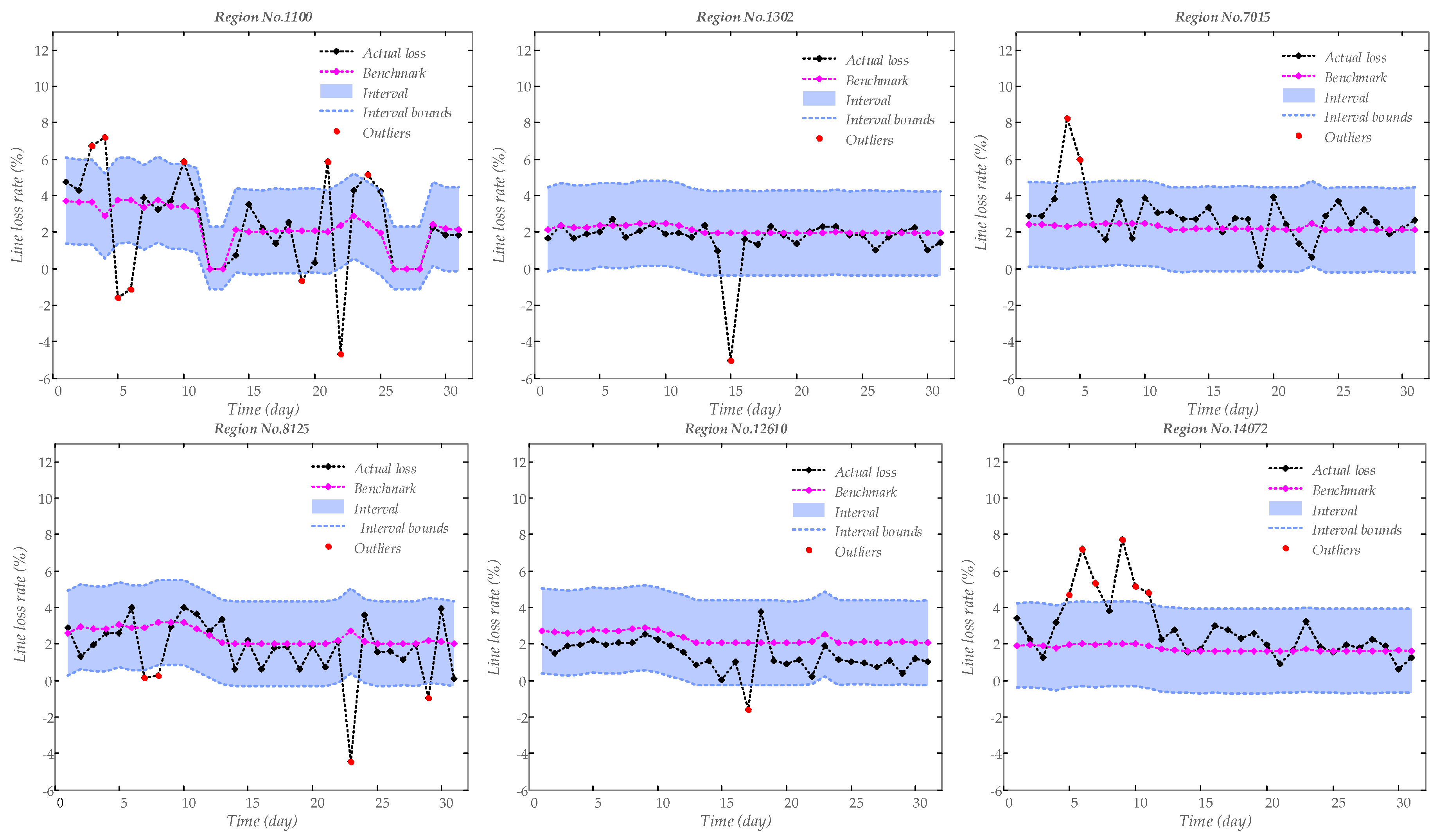
- The line loss rate data possess few daily regularity and show high fluctuation. From Figure 1, the curves of line loss rates in different regions change greatly over the days, where historical line loss rates can be hardly used to estimate the further values. Thus, it is vital in this study to select influencing factors of line loss rate.
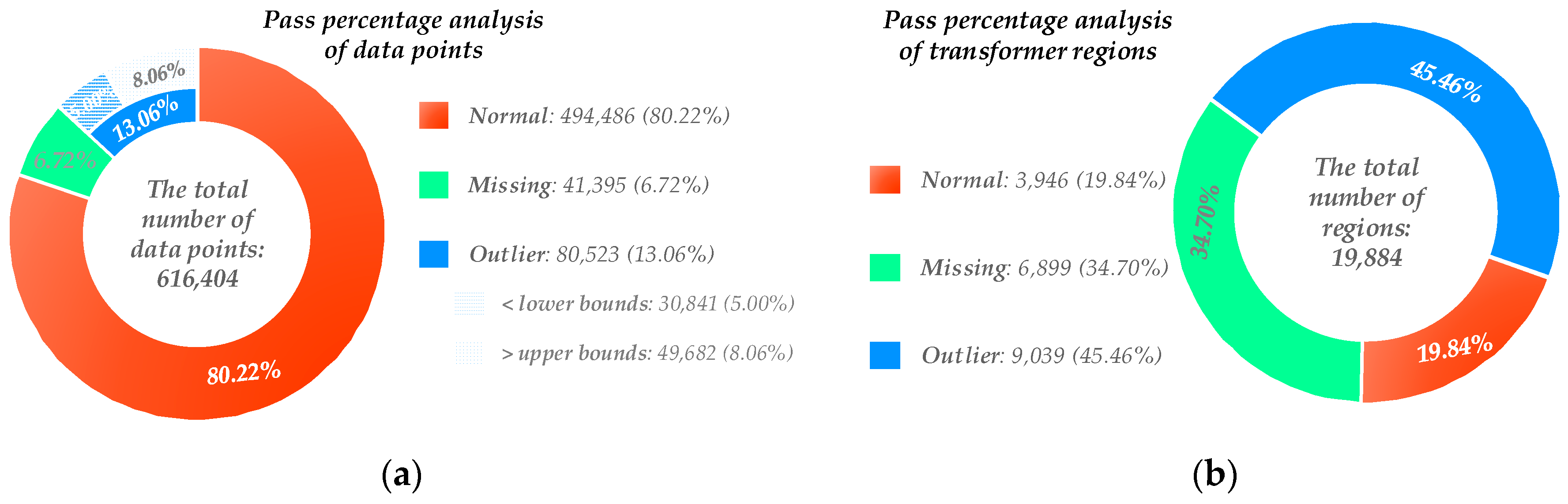
- The deviations of outliers in the dataset are sometimes extremely away from normal values, indicating the low dependability of the acquisition and communication equipment. According to Table 1 and Figure 2, the lower and upper bounds of the original dataset in the box-plot are −1.57% and 5.22%, respectively, which is quite close to the project standard (−1% and 5%). However, the maximum and minimum of the collected line loss rates are 100% and −1.69 × 106%, respectively; greatly different from the bounds. In this case, benchmarking line loss rates is still necessary nowadays in practicable applications.
- The quality of the dataset is poor to be used directly. As the component analysis of the dataset is presented in Figure 3, there are a large number of outliers and missing values, constituting 8.67% and 6.72% of the overall dataset. In this study, the spline interpolation method is utilized to fill the missing values. From Table 1 and Figure 2, the dataset after interpolation holds a similar distribution comparing to that of the original dataset. On the contrary, although the outliers can be eliminated directly based on la and ua, the distribution will change and it will be difficult to calculate an accurate reasonable intervals.
2.2.2. Influencing Factors of Line Loss Rate
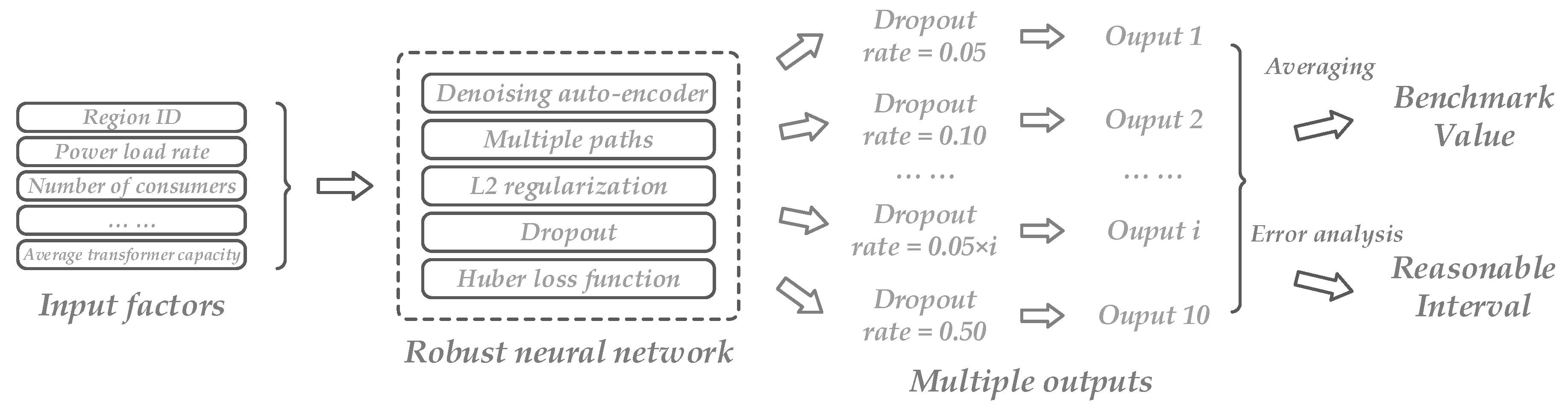
2.3. Calculation of Benchmark Values and Reasonable Intervals
- Build a RNN. In order to fully expand its robustness, DAE, multi-path architecture, L2 regularization, dropout layer and Huber loss function are applied. It is noted that a RNN possesses ten output nodes, where each node is connected to one layer with a dissimilar dropout rate (from 0.05 to 0.50).
- Calculate an average value according to the ten different outputs, which is the final benchmark value of line loss rate, as:where is the ith benchmark value, and is the nth output of the ith line loss rate.
- Operate error analysis to acquire a reasonable interval. Not only the absolute error between the benchmark value and the actual line loss rates is computed, the variance of different outputs is calculated as well. According to the interval result, data points that are not involved between the bounds of the interval are considered as outliers. The operation can be described under the following equations:where e1 and e2 are the results of error analysis. e1 is a constant and e2 changes according to the number i. ns is the number of training samples; is the ith actual line loss rate; li and ui are the lower and upper bounds of the reasonable interval, respectively. Furthermore, as outliers exist in the actual line loss rate values, which may influence the result of e1, a two-tailed test is utilized to eliminate the possibly abnormal values that are smaller than 0.7 percentile and bigger than 99.3 percentile, as shown in Figure 6:
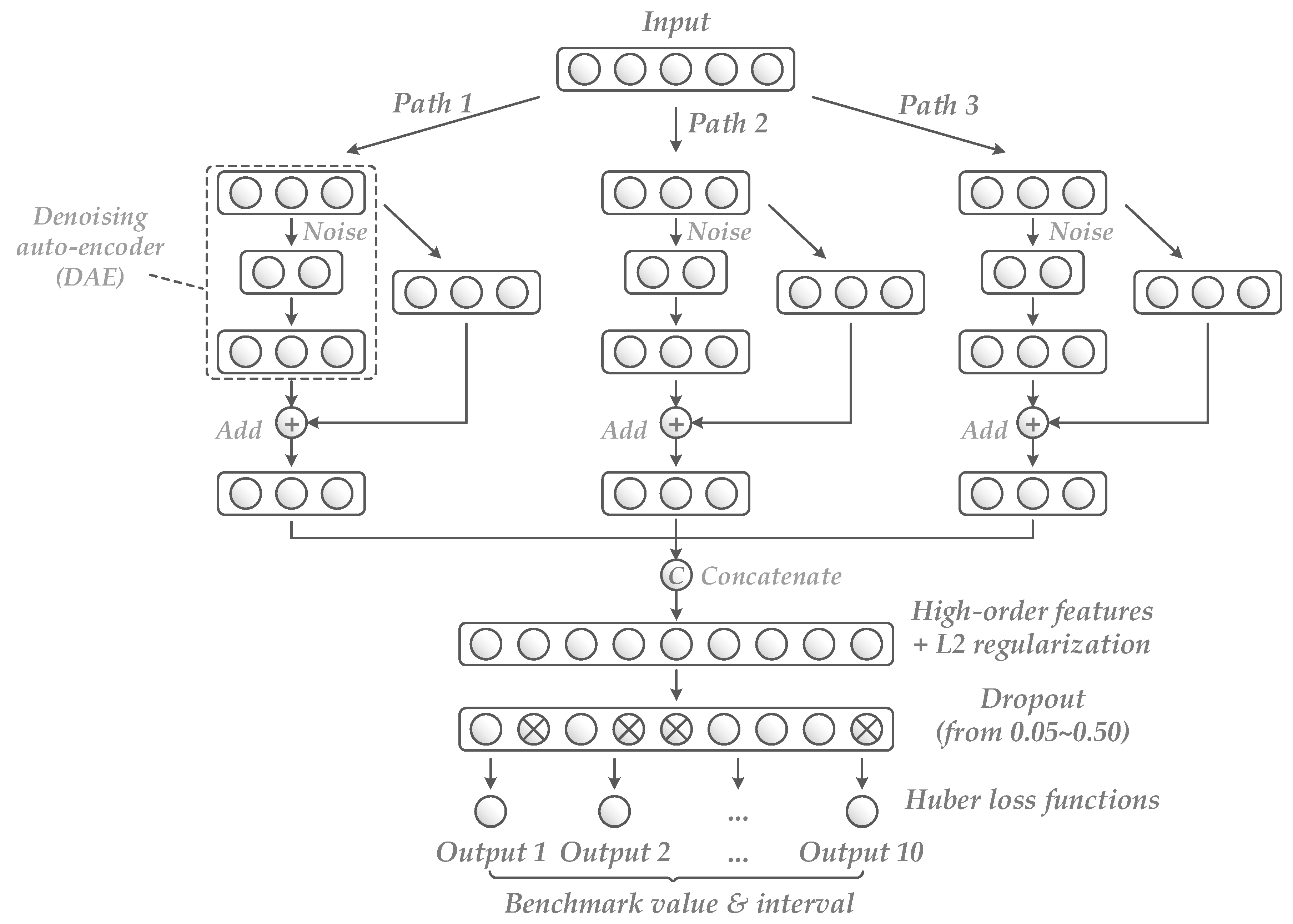
2.4. Robust Neural Network
2.4.1. Denoising Auto-Encoder
2.4.2. Multiple Paths Combined by Addition and Concatenation
2.4.3. Dropout
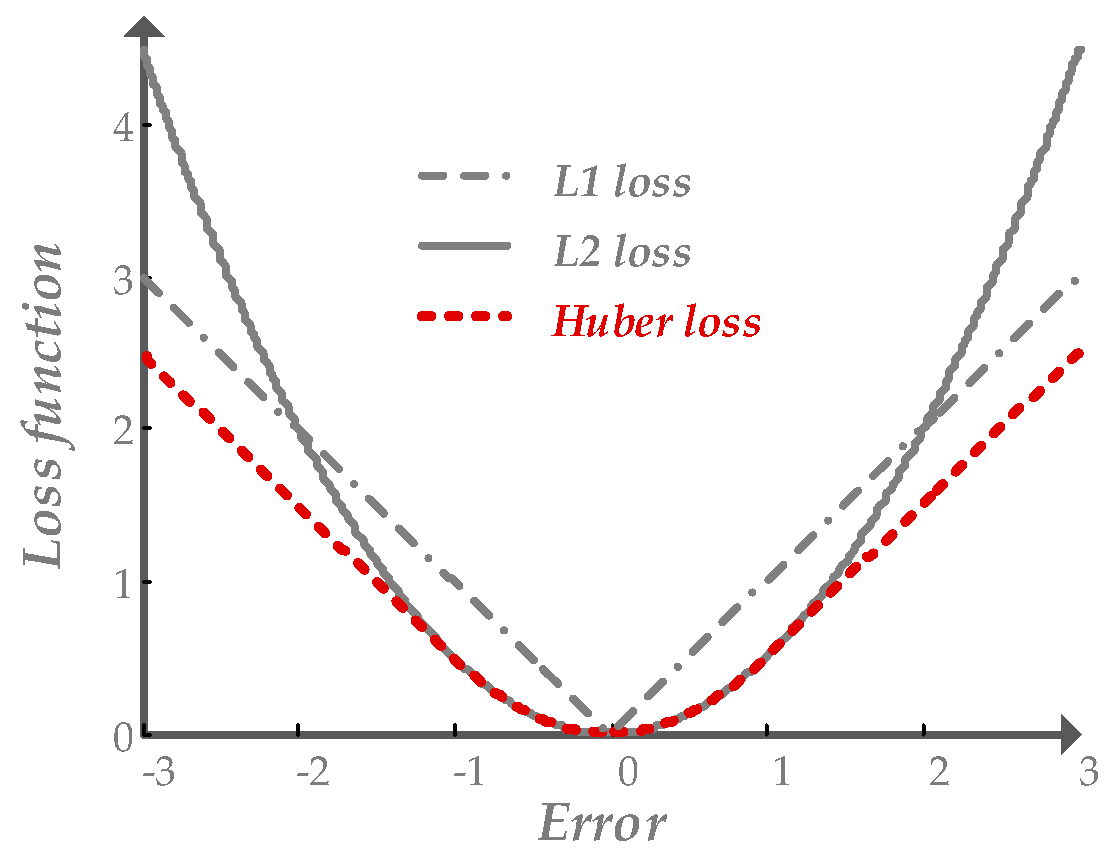
2.4.4. Huber Loss Function
2.4.5. L2 Regularization
3. Results and Discussion
3.1. Calculation Results
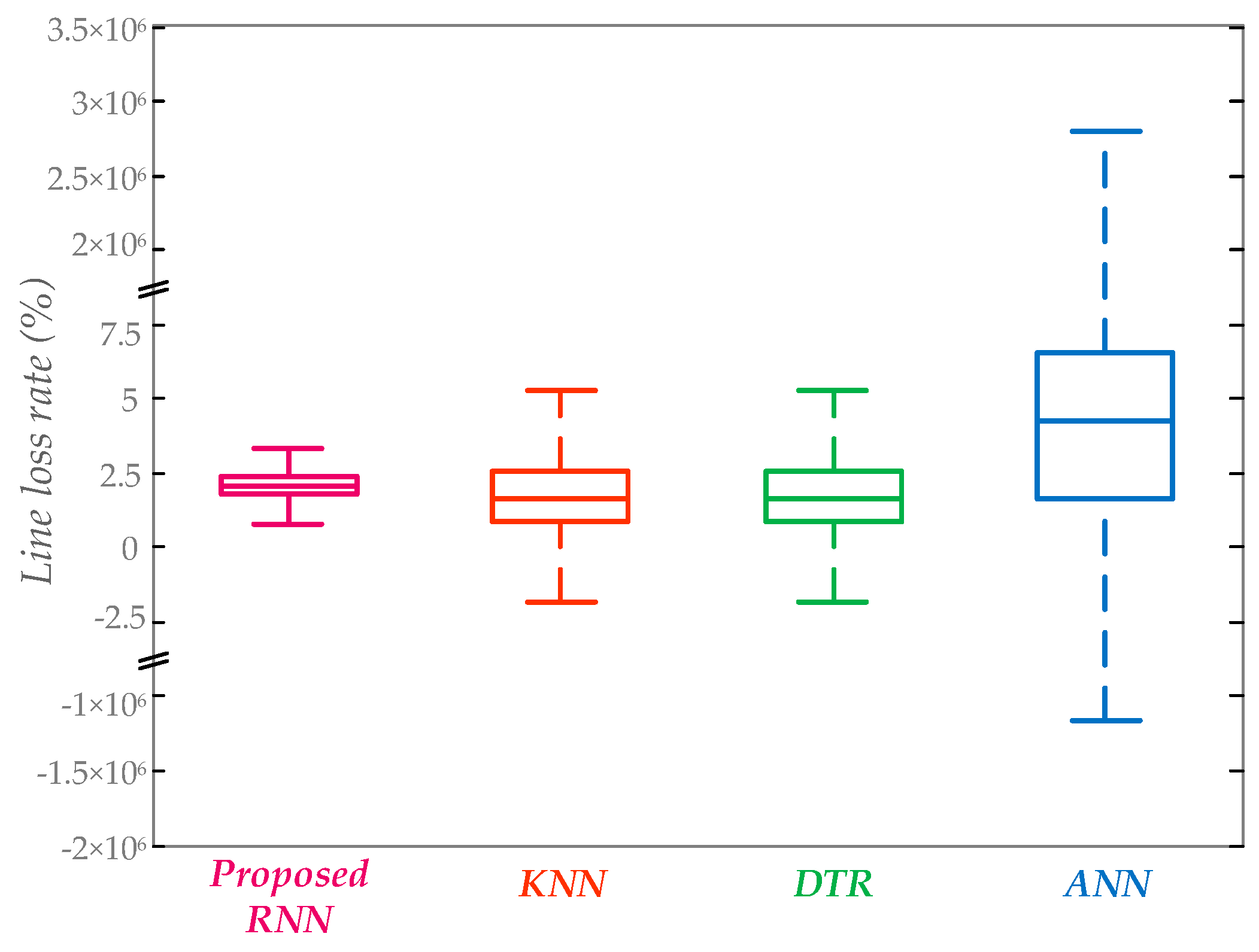
3.2. Comparsions and Disscussion
3.2.1. The Robustness of the Proposed Method
3.2.2. Accuracy Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, B.J.; Xiang, K.L.; Yang, L.; Su, Q.M.; Huang, D.S.; Huang, T. Theoretical Line Loss Calculation of Distribution Network Based on the Integrated electricity and line loss management system. In Proceedings of the China International Conference on Electricity, Tianjing, China, 17–19 September 2018; pp. 2531–2535. [Google Scholar]
- Yang, F.; Liu, J.; Lu, B.B. Design and Application of Integrated Distribution Network Line Loss Analysis System. In Proceedings of the 2016 China International Conference on Electricity Distribution (CICED), Xi’an, China, 10–13 August 2016. [Google Scholar]
- Hu, J.H.; Fu, X.F.; Liao, T.M.; Chen, X.; Ji, K.H.; Sheng, H.; Zhao, W.B. Low Voltage Distribution Network Line Loss Calculation Based on The Theory of Three-phase Unbalanced Load. In Proceedings of the 3rd International Conference on Intelligent Energy and Power Systems (IEPS 2017), Hangzhou, China, 10 October 2017; pp. 65–71. [Google Scholar] [CrossRef] [Green Version]
- Campos, G.O.; Zimek, A.; Sander, J.; Campello, R.J.G.B.; Micenkova, B.; Schubert, E.; Assent, I.; Houle, M.E. On the evaluation of unsupervised outlier detection: Measures, datasets, and an empirical study. Data Min. Knowl. Disc. 2016, 30, 891–927. [Google Scholar] [CrossRef]
- Paulheim, H.; Meusel, R. A decomposition of the outlier detection problem into a set of supervised learning problems. Mach. Learn. 2015, 100, 509–531. [Google Scholar] [CrossRef]
- Daneshpazhouh, A.; Sami, A. Entropy-based outlier detection using semi-supervised approach with few positive examples. Pattern Recogn. Lett. 2014, 49, 77–84. [Google Scholar] [CrossRef]
- Bhattacharya, G.; Ghosh, K.; Chowdhury, A.S. Outlier detection using neighborhood rank difference. Pattern Recogn. Lett. 2015, 60–61, 24–31. [Google Scholar] [CrossRef]
- Domingues, R.; Filippone, M.; Michiardi, P.; Zouaoui, J. A comparative evaluation of outlier detection algorithms: Experiments and analyses. Pattern Recogn. 2018, 74, 406–421. [Google Scholar] [CrossRef]
- Dovoedo, Y.H.; Chakraborti, S. Boxplot-Based Outlier Detection for the Location-Scale Family. Commun. Stat.-Simul. Comput. 2015, 44, 1492–1513. [Google Scholar] [CrossRef]
- Pranatha, M.D.A.; Sudarma, M.; Pramaita, N.; Widyantara, I.M.O. Filtering Outlier Data Using Box Whisker Plot Method For Fuzzy Time Series Rainfall Forecasting. In Proceedings of the 2018 4th International Conference on Wireless and Telematics (ICWT), Nusa Dua, Indonesia, 12–13 July 2018. [Google Scholar]
- Campello, R.J.G.B.; Moulavi, D.; Zimek, A.; Sander, J. Hierarchical Density Estimates for Data Clustering, Visualization, and Outlier Detection. ACM Trans. Knowl. Discov. Data 2015, 10, 5. [Google Scholar] [CrossRef]
- Huang, J.L.; Zhu, Q.S.; Yang, L.J.; Cheng, D.D.; Wu, Q.W. A novel outlier cluster detection algorithm without top-n parameter. Knowl.-Based Syst. 2017, 121, 32–40. [Google Scholar] [CrossRef]
- Jiang, F.; Liu, G.Z.; Du, J.W.; Sui, Y.F. Initialization of K-modes clustering using outlier detection techniques. Inf. Sci. 2016, 332, 167–183. [Google Scholar] [CrossRef]
- Todeschini, R.; Ballabio, D.; Consonni, V.; Sahigara, F.; Filzmoser, P. Locally centred Mahalanobis distance: A new distance measure with salient features towards outlier detection. Anal. Chim. Acta 2013, 787, 1–9. [Google Scholar] [CrossRef]
- Jobe, J.M.; Pokojovy, M. A Cluster-Based Outlier Detection Scheme for Multivariate Data. J. Am. Stat. Assoc. 2015, 110, 1543–1551. [Google Scholar] [CrossRef]
- An, W.J.; Liang, M.G.; Liu, H. An improved one-class support vector machine classifier for outlier detection. Proc. Inst. Mech. Eng. C J. Mech. 2015, 229, 580–588. [Google Scholar] [CrossRef]
- Chen, G.J.; Zhang, X.Y.; Wang, Z.J.; Li, F.L. Robust support vector data description for outlier detection with noise or uncertain data. Knowl.-Based Syst. 2015, 90, 129–137. [Google Scholar] [CrossRef]
- Zou, C.L.; Tseng, S.T.; Wang, Z.J. Outlier detection in general profiles using penalized regression method. IIE Trans. 2014, 46, 106–117. [Google Scholar] [CrossRef]
- Peng, J.T.; Peng, S.L.; Hu, Y. Partial least squares and random sample consensus in outlier detection. Anal. Chim. Acta 2012, 719, 24–29. [Google Scholar] [CrossRef]
- Ni, L.; Yao, L.; Wang, Z.; Zhang, J.; Yuan, J.; Zhou, Y. A Review of Line Loss Analysis of the Low-Voltage Distribution System. In Proceedings of the 2019 IEEE 3rd International Conference on Circuits, Systems and Devices (ICCSD), Chengdu, China, 23–25 August 2019; pp. 111–114. [Google Scholar]
- Yuan, X.; Tao, Y. Calculation method of distribution network limit line loss rate based on fuzzy clustering. IOP Conf. Ser. Earth Environ. Sci. 2019, 354, 012029. [Google Scholar] [CrossRef]
- Bo, X.; Liming, W.; Yong, Z.; Shubo, L.; Xinran, L.; Jinran, W.; Ling, L.; Guoqiang, S. Research of Typical Line Loss Rate in Transformer District Based on Data-Driven Method. In Proceedings of the 2019 IEEE Innovative Smart Grid Technologies-Asia (ISGT Asia), Chengdu, China, 21–24 May 2019; pp. 786–791. [Google Scholar]
- Yao, M.T.; Zhu, Y.; Li, J.J.; Wei, H.; He, P.H. Research on Predicting Line Loss Rate in Low Voltage Distribution Network Based on Gradient Boosting Decision Tree. Energies 2019, 12, 2522. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Dong, X.; Xing, Y.; Wang, Y. Analysis of Influencing Factors of Transmission Line Loss Based on GBDT Algorithm. In Proceedings of the 2019 International Conference on Communications, Information System and Computer Engineering (CISCE), Haikou, China, 5–7 July 2019; pp. 179–182. [Google Scholar]
- Wang, S.X.; Dong, P.F.; Tian, Y.J. A Novel Method of Statistical Line Loss Estimation for Distribution Feeders Based on Feeder Cluster and Modified XGBoost. Energies 2017, 10, 2067. [Google Scholar] [CrossRef] [Green Version]
- Radovanovic, M.; Nanopoulos, A.; Ivanovic, M. Reverse Nearest Neighbors in Unsupervised Distance-Based Outlier Detection. IEEE Trans. Knowl. Data Eng. 2015, 27, 1369–1382. [Google Scholar] [CrossRef]
- Yosipof, A.; Senderowitz, H. k-Nearest Neighbors Optimization-Based Outlier Removal. J. Comput. Chem. 2015, 36, 493–506. [Google Scholar] [CrossRef]
- Wang, X.C.; Wang, X.L.; Ma, Y.Q.; Wilkes, D.M. A fast MST-inspired kNN-based outlier detection method. Inf. Syst. 2015, 48, 89–112. [Google Scholar] [CrossRef]
- Yang, J.H.; Deng, T.Q.; Sui, R. An Adaptive Weighted One-Class SVM for Robust Outlier Detection. Lect. Notes Electr. Eng. 2016, 359, 475–484. [Google Scholar] [CrossRef]
- Feng, N.; Jianming, Y. Low-Voltage Distribution Network Theoretical Line Loss Calculation System Based on Dynamic Unbalance in Three Phrases. In Proceedings of the 2010 International Conference on Electrical and Control Engineering, Wuhan, China, 25–27 June 2010; pp. 5313–5316. [Google Scholar]
- Hubert, M.; Vandervieren, E. An adjusted boxplot for skewed distributions. Comput. Stat. Data Anal. 2008, 52, 5186–5201. [Google Scholar] [CrossRef]
- Lamb, A.; Binas, J.; Goyal, A.; Serdyuk, D.; Subramanian, S.; Mitliagkas, I.; Bengio, Y. Fortified Networks: Improving the Robustness of Deep Networks by Modeling the Manifold of Hidden Representations. arXiv 2018, arXiv:1804.02485. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Cheng, L.L.; Zang, H.X.; Ding, T.; Sun, R.; Wang, M.M.; Wei, Z.N.; Sun, G.Q. Ensemble Recurrent Neural Network Based Probabilistic Wind Speed Forecasting Approach. Energies 2018, 11, 1958. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Esmaeili, A.; Marvasti, F. A Novel Approach to Quantized Matrix Completion Using Huber Loss Measure. IEEE Signal Proc. Lett. 2019, 26, 337–341. [Google Scholar] [CrossRef]
- Shah, P.; Khankhoje, U.K.; Moghaddam, M. Inverse Scattering Using a Joint L1-L2 Norm-Based Regularization. IEEE Trans. Antennas Propag. 2016, 64, 1373–1384. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator | Original Dataset | Original Dataset (Without Outliers) | Dataset after Interpolation |
|---|---|---|---|
| mean (%) | −5.16 | 1.78 | −10.96 |
| std (%) | 2.47 × 103 | 1.16 | 3.19 × 103 |
| min (%) | −1.69 × 106 | −1.57 | −1.69 × 106 |
| max (%) | 100 | 5.22 | 100 |
| la (%) | −1.57 | −1.10 | −1.50 |
| ua (%) | 5.22 | 4.57 | 5.26 |
| q1 (%) | 1.02 | 1.02 | 1.03 |
| q2 (%) | 1.74 | 1.67 | 1.76 |
| q3 (%) | 2.70 | 2.44 | 2.72 |
| No. | Factor | Remarks |
|---|---|---|
| 1 | Date | - |
| 2 | Capacity of the transformer | - |
| 3 | Type of the transformer | Public transformer (=0); special transformer (=1) |
| 4 | Type of the gird that the region belongs to | City grid (=0); country gird (=1) |
| 5 | Monthly line loss rate | Three inputs, including the last three months |
| 6 | Daily load rate | Daily load rate = daily power supply/(transformer capacity × 24) |
| 7 | Daily maximum load rate | - |
| 8 | Daily average power factor | - |
| 9 | Number of customers | - |
| 10 | Average transformer capacity per customer | Average capacity = transformer capacity/number of customers |
| 11 | Rate of residential capacity | Rate = residential capacity/transformer capacity |
| 12 | Power supply duration | - |
| Path | Layer | Hyper-Parameter |
|---|---|---|
| DAE sub-path (1~3) | FC layer 0 | Node number: 64 Activation: ReLU (Rectified Linear Unit) |
| DAE sub-path (1~3) | Noise layer | Standard deviation: 0.05 |
| DAE sub-path (1~3) | FC layer 1 (encoder) | Node number: 8 Activation: ReLU |
| DAE sub-path (1~3) | FC layer 2 (decoder) | Node number: 64 |
| Fully connected (FC) sub-path (1~3) | FC layer 3 | Node number: 64 |
| Main path (1~3) | Add layer | Inputs: FC layer 2 and FC layer 3 |
| - | Concatenate layer | Inputs: Add layers Node number: 192 Activation: ReLU Activity regularization: L2, λ = 1 × 10−3 |
| - | Dropout layer (1~10) | Dropout rate: 0.05~0.50 (0.05 step) |
| - | FC layer 4 (output 1~10) | Node number: 1 Activation: ReLU |
| Hyper-Parameters | Searching Space | Result |
|---|---|---|
| σ (standard error of noise in DAE) | [0.00:0.05:0.50] | 0.05 |
| δ (coefficient in Huber loss) | [0.00:0.10:0.50] | 0.10 |
| λ (penalty coefficient of L2) | 1 × 10[−4:1:0] | 1 × 10−3 |
| Number of nodes in a sub-path | {16, 32, 64, 128} | 64 |
| Number of sub-paths | [2:1:5] | 3 |
| Training optimizer | {Adadelta, Adam} | Adam |
| Number of epochs | [50:50:200] | 100 |
| Batch size | {64, 128, 256, 512, 1024, 2048} | 1024 |
| Learning rate | 1 × 10[−5:1:0] | 1 × 10−4 |
| Model | Hyper-Parameter |
|---|---|
| KNN | Number of neighbors: 10 Method of weighting: based on distance |
| DTR | Method of splitter: choose the best spilt |
| ANN | Node number in the hidden layer: 64 Activation: logistic |
| Indicator | Proposed RNN | KNN | DTR | ANN |
|---|---|---|---|---|
| mean (%) | 2.03 | 1.03 | −4.81 | −5.83 × 106 |
| std (%) | 0.80 | 185.69 | 194.78 | 1.87 × 107 |
| min (%) | 0.00 | −8.13 × 104 | −8.13 × 104 | −8.26 × 107 |
| max (%) | 33.61 | 100.00 | 100.00 | 4.49 × 106 |
| la (%) | 0.81 | −1.80 | −1.80 | −1.17 × 106 |
| ua (%) | 3.36 | 5.25 | 5.24 | 2.80 × 106 |
| q1 (%) | 1.76 | 0.84 | 0.84 | 3.23 × 105 |
| q2 (%) | 2.09 | 1.65 | 1.65 | 8.47 × 105 |
| q3 (%) | 2.40 | 2.60 | 2.60 | 1.32 × 106 |
| Indicator | Proposed RNN | KNN | DTR | ANN |
|---|---|---|---|---|
| Mean absolute error (MAE, %) | 1.46 | 0.70 | 5.01 | 7.26 × 106 |
| Mean squared error (MSE, %2) | 13.70 | 574.58 | 3.90 × 103 | 3.54 × 1014 |
| Huber loss | 4.44 | 5.90 | 48.19 | 7.26 × 107 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Cheng, L.; Zhou, Y.; Xu, B.; Zang, H.; Xu, G.; Lu, X. Benchmarking Daily Line Loss Rates of Low Voltage Transformer Regions in Power Grid Based on Robust Neural Network. Appl. Sci. 2019, 9, 5565. https://0-doi-org.brum.beds.ac.uk/10.3390/app9245565
Wu W, Cheng L, Zhou Y, Xu B, Zang H, Xu G, Lu X. Benchmarking Daily Line Loss Rates of Low Voltage Transformer Regions in Power Grid Based on Robust Neural Network. Applied Sciences. 2019; 9(24):5565. https://0-doi-org.brum.beds.ac.uk/10.3390/app9245565
Chicago/Turabian StyleWu, Weijiang, Lilin Cheng, Yu Zhou, Bo Xu, Haixiang Zang, Gaojun Xu, and Xiaoquan Lu. 2019. "Benchmarking Daily Line Loss Rates of Low Voltage Transformer Regions in Power Grid Based on Robust Neural Network" Applied Sciences 9, no. 24: 5565. https://0-doi-org.brum.beds.ac.uk/10.3390/app9245565