Discrimination between Modal, Breathy and Pressed Voice for Single Vowels Using Neck-Surface Vibration Signals

 , and
, and
Abstract
:1. Introduction
2. Experimental Setup and Data Acquisition
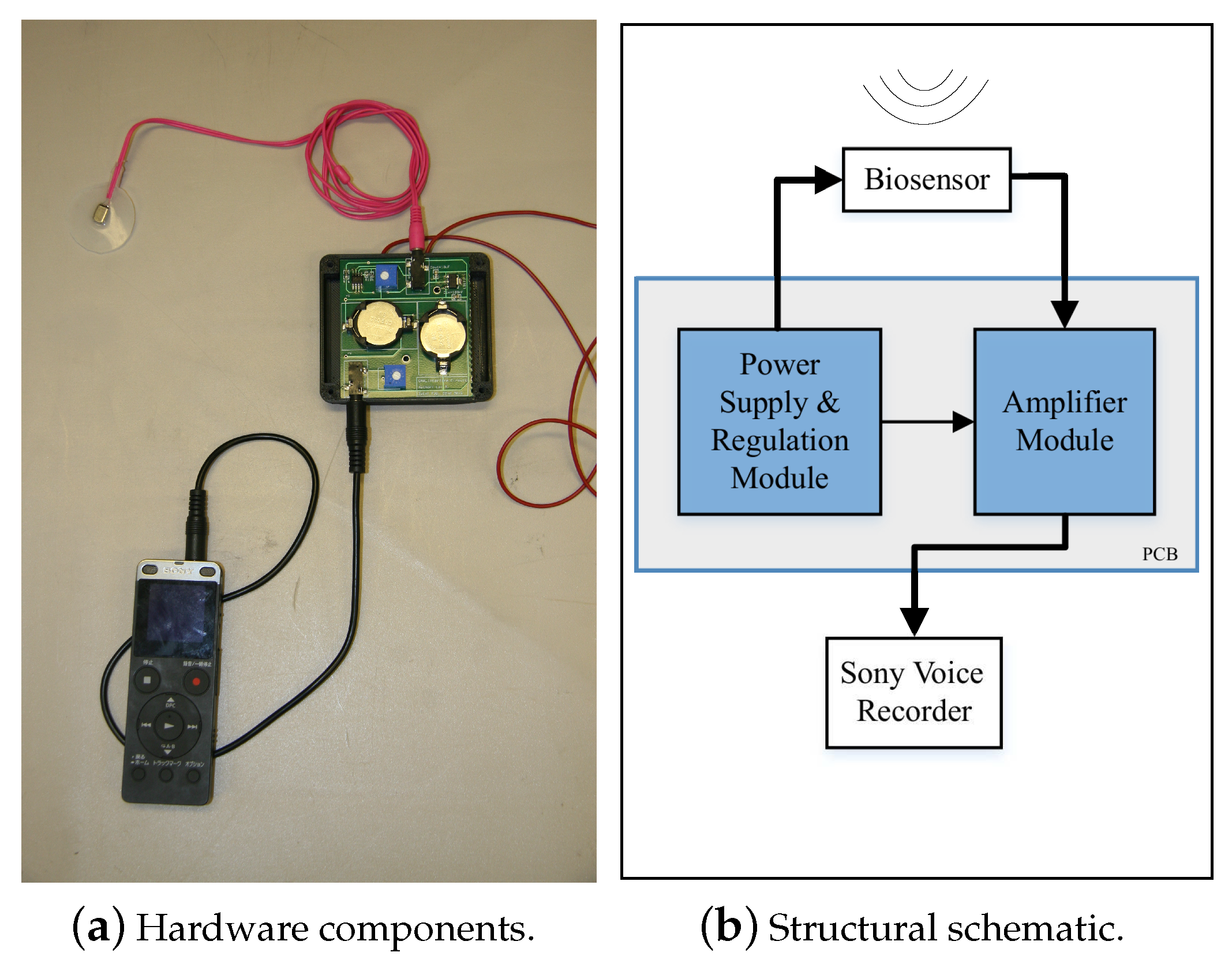
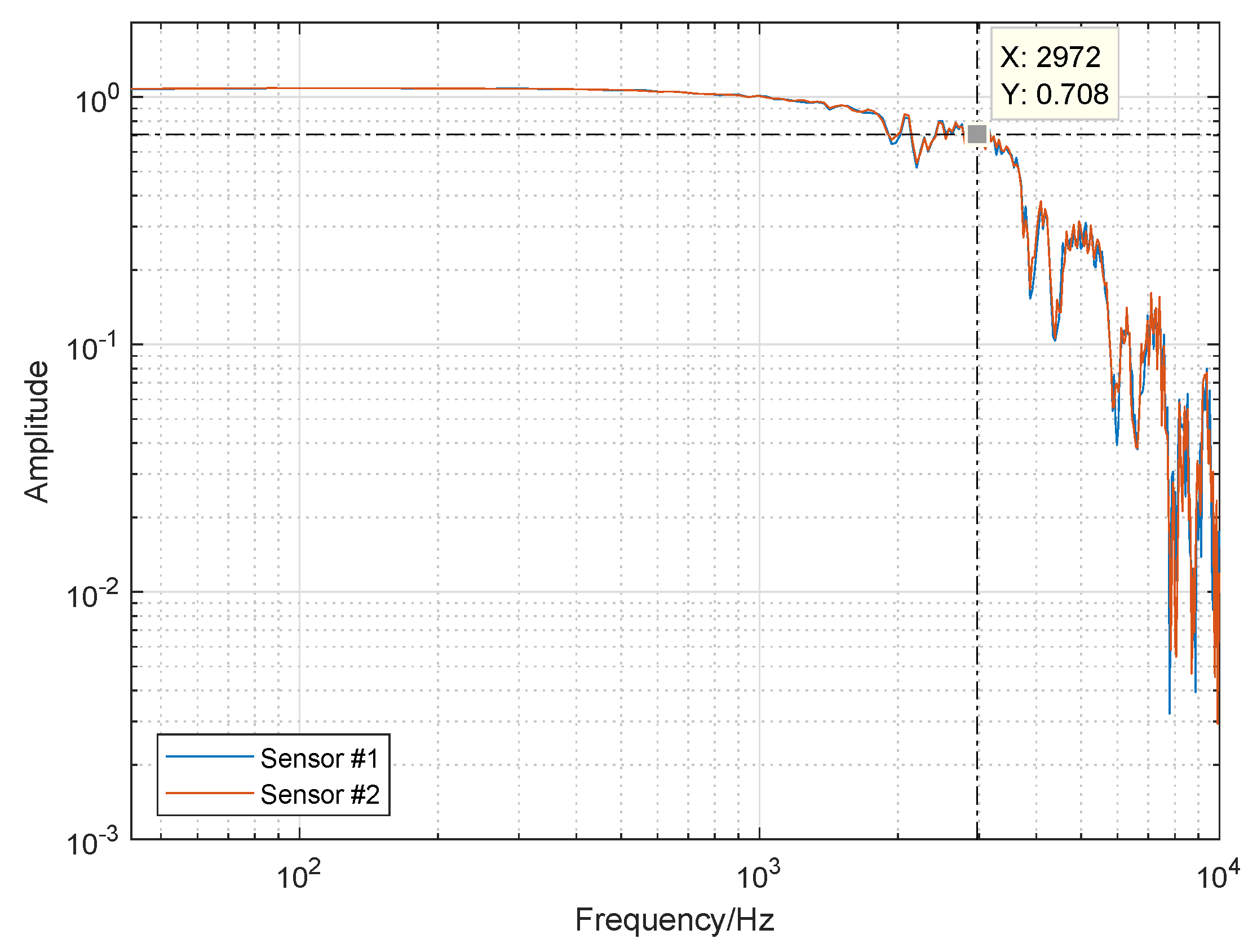
2.1. Hardware Platform Description
2.2. Voice Recording Process
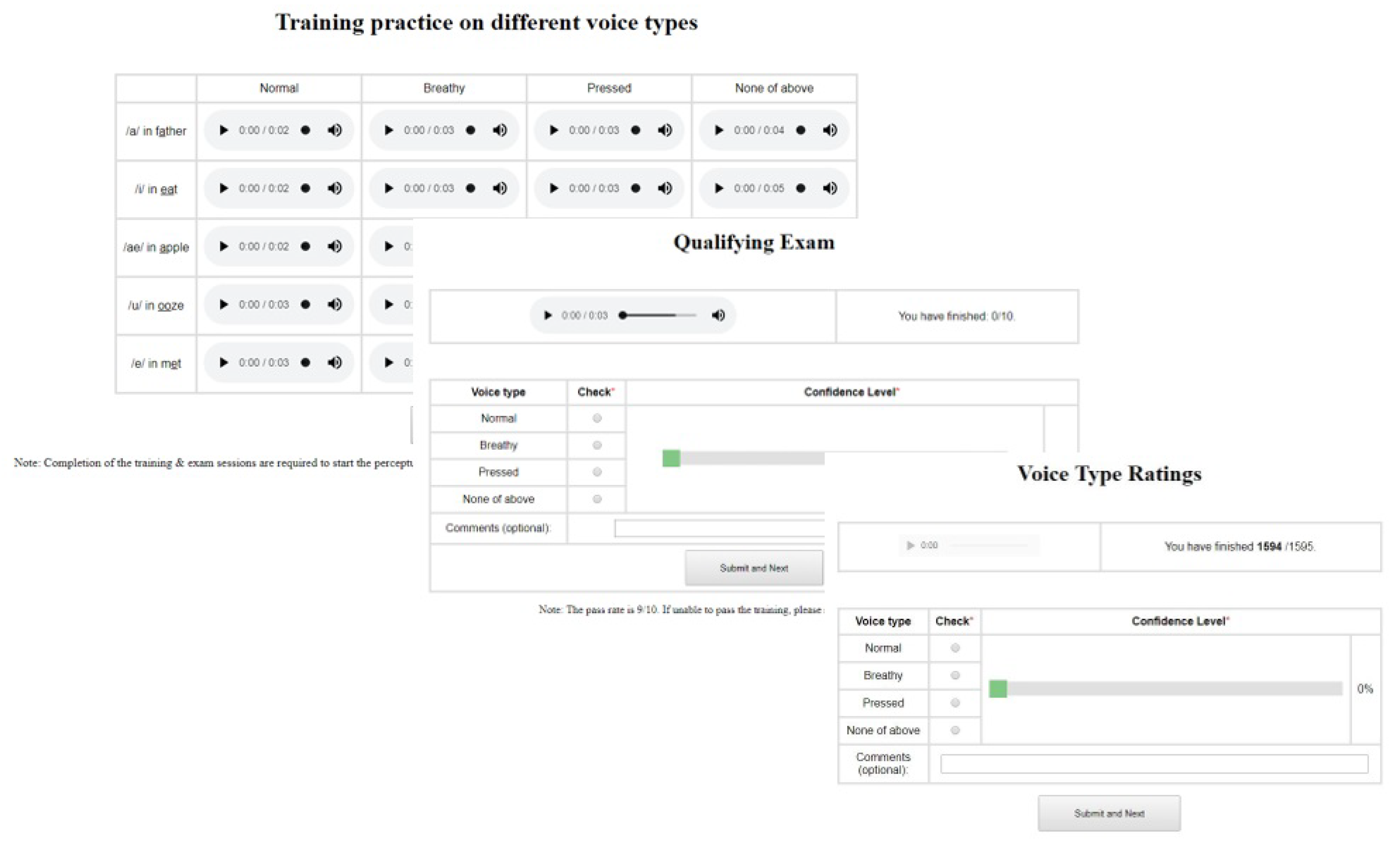
3. Auditory-Perceptual Screening
4. Classification
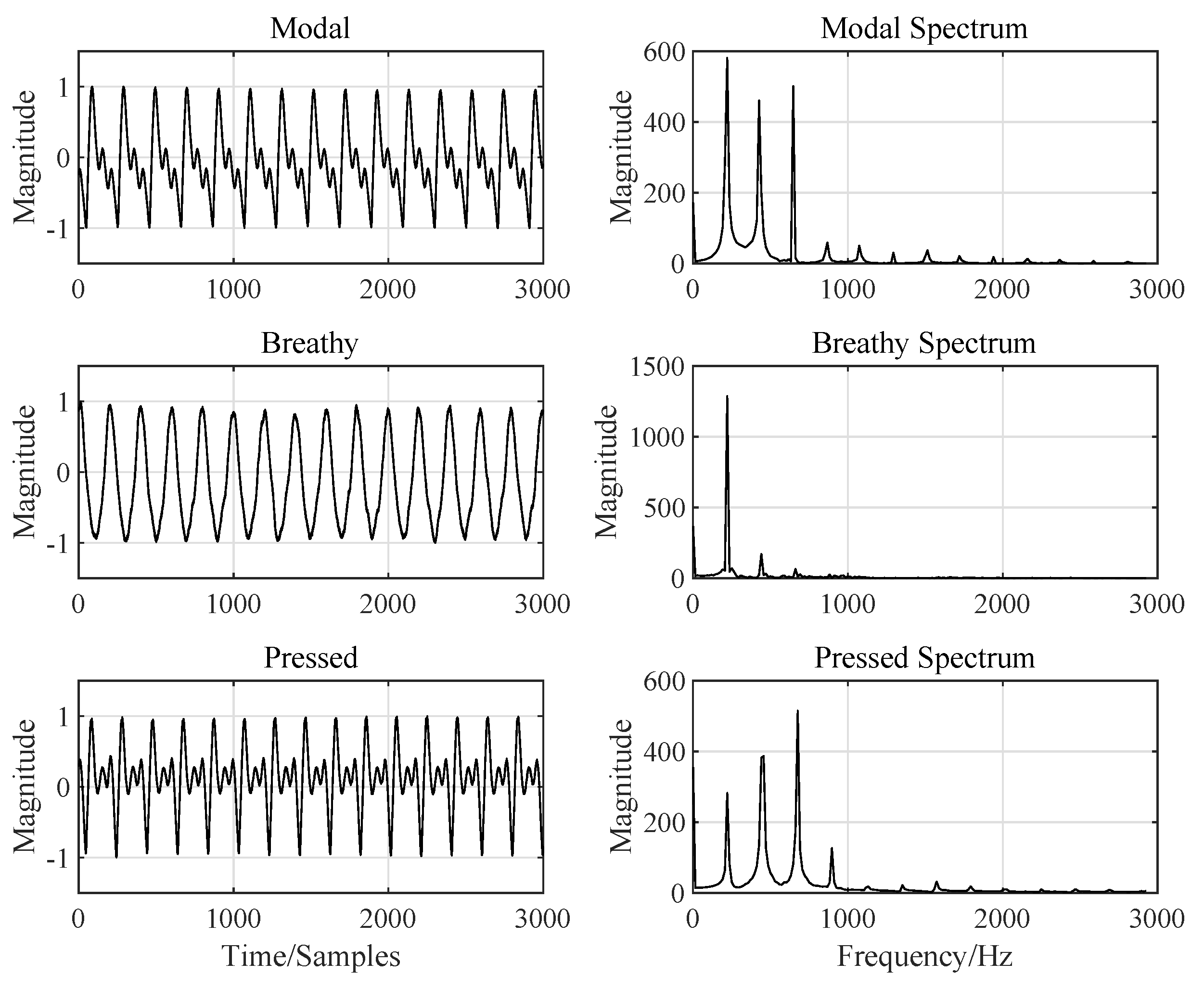
4.1. Feature Extraction
4.2. Machine Learning Classification Using Multiple Features
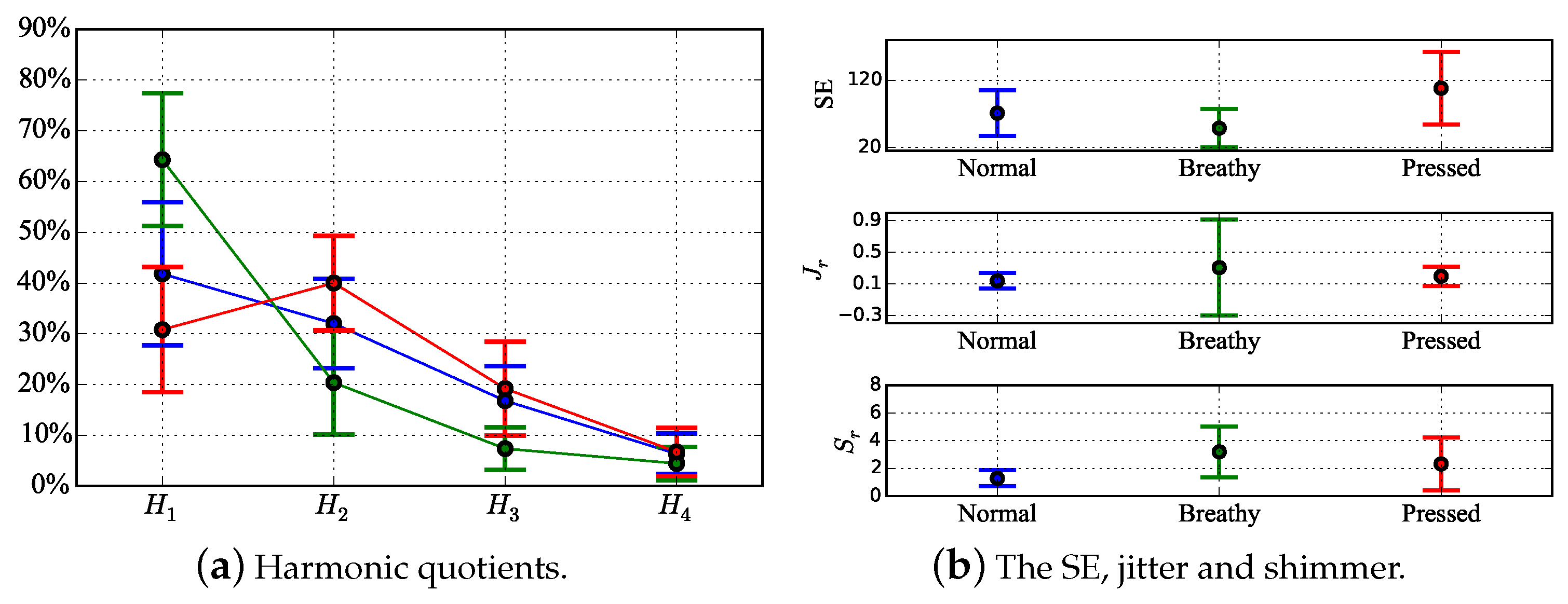
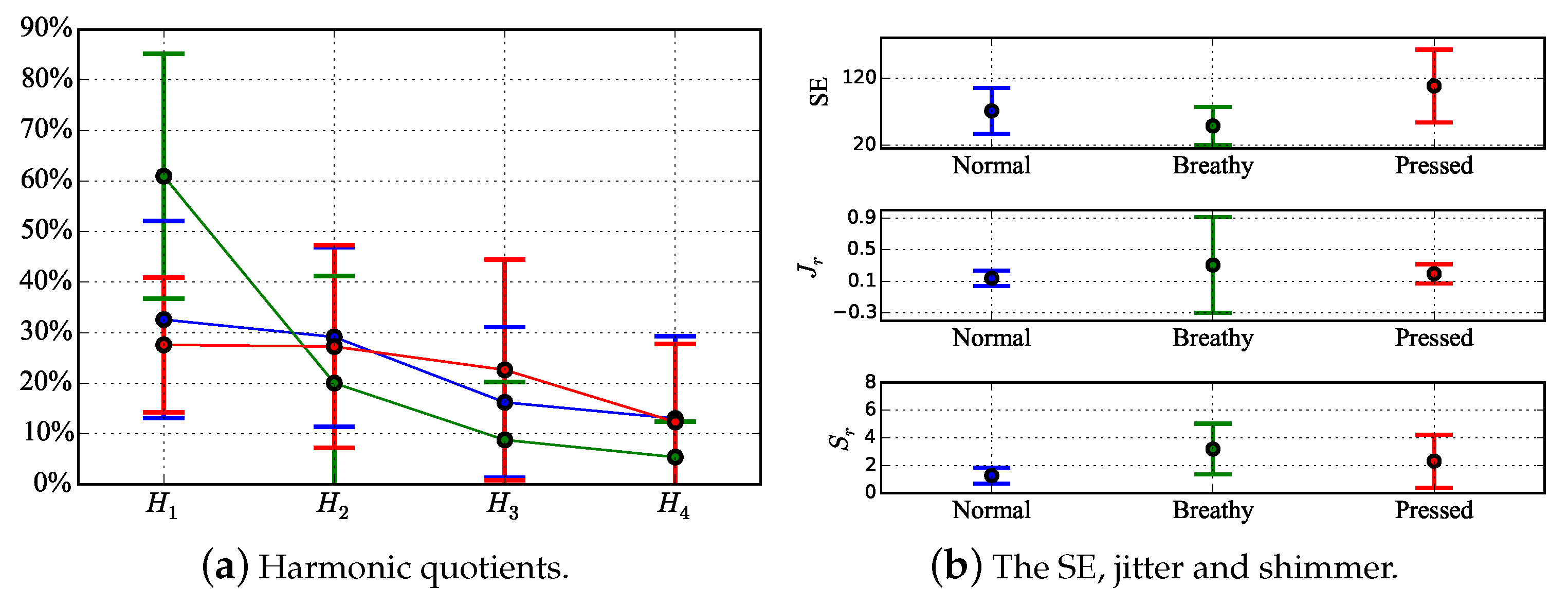
5. Results and Discussion
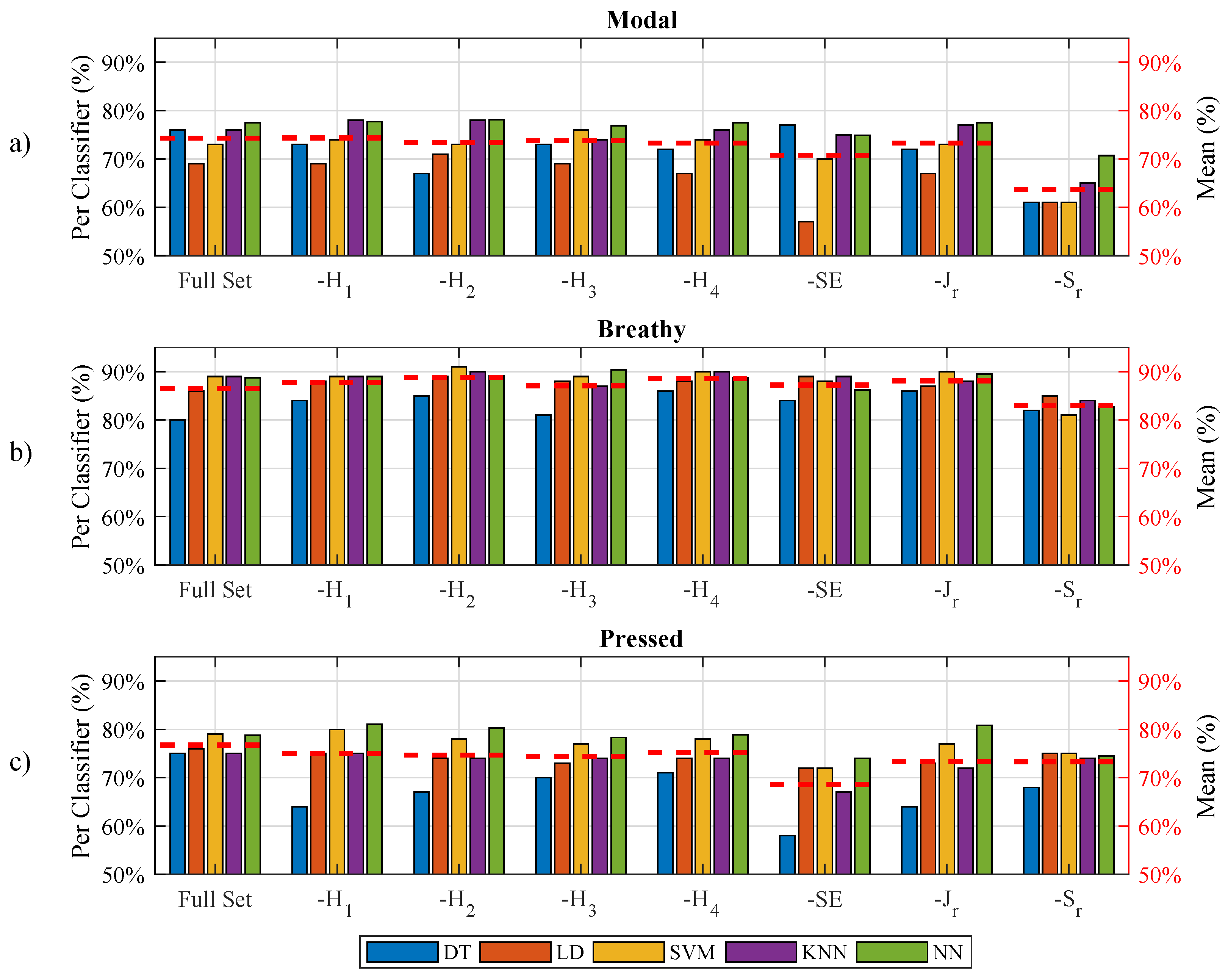
5.1. Full Set versus LOFO Subsets
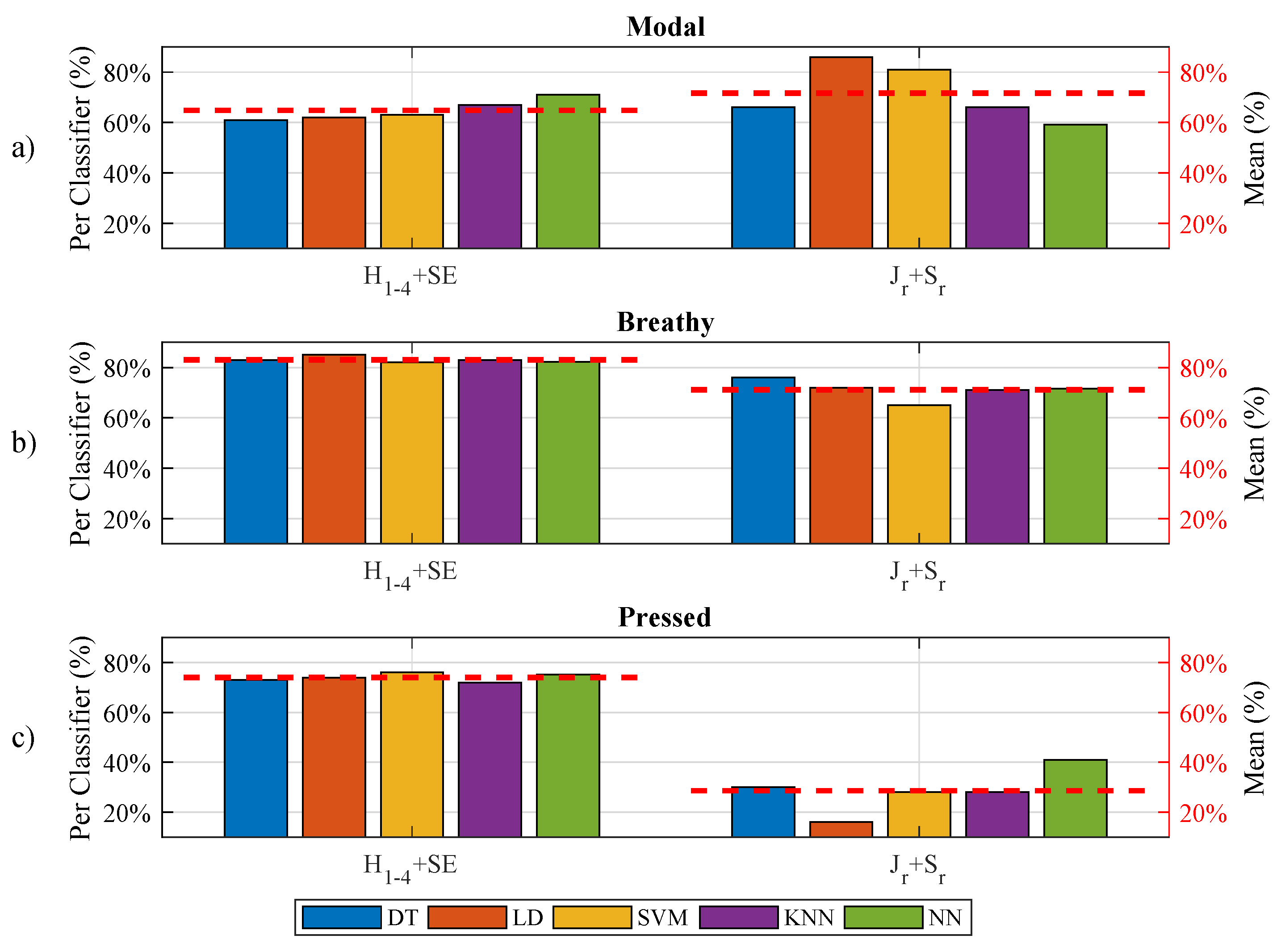
5.2. Full Set versus Spectral Set versus Stability Set
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| NSA | Neck Skin Accelerometer |
| SLP | Speech Language Pathologist |
| GRABAS | Grade of Roughness, Breathiness, Asthenia, Strain |
| CAPE-V | Consensus Auditory-Perceptual Evaluation of Voice |
| GIF | Glottal Inverse Filtering |
| MFDR | Maximum Flow Declination Rate |
| MFCC | Mel-Frequency Spectral Coefficients |
| CPP | Cepstral Peak Prominence |
| SVM | Support Vector Machine |
| GMM | Gaussian Mixture Modal |
| NN | Neural Network |
| DT | Decision Tree |
| KNN | K-Nearest Neighbours |
| LOFO | Left-One-Feature-Out |
| SAL | Surface Acceleration Level |
| SPL | Sound Pressure Level |
| PCB | Printing Circuit Board |
| LDV | Lase Doppler Velocimetry |
| ICC | Intra-class Correlation Coefficient |
| VAD | Vocal Activity Detection |
| SE | Spectral Entropy |
| LD | Linear Discriminant |
| TP | True Pressed |
| PP | Predicted Pressed |
| TB | True Breathy |
| PB | Predicted Breathy |
| TM | True Modal |
| PM | Predicted Modal |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
| AUC | Area Under the receiver operating characteristic Curve |
References
- Kreiman, J.; Vanlancker-Sidtis, D.; Gerratt, B.R. Perception of Voice Quality. In The Handbook of Speech Perception; Pisoni, D.B., Remez, R.E., Eds.; Wiely: Hoboken, NJ, USA, 2008; pp. 338–363. [Google Scholar]
- Childers, D.G.; Lee, C.K. Vocal quality factors: Analysis, synthesis, and perception. J. Acoust. Soc. Am. 1991, 90, 2394–2410. [Google Scholar] [CrossRef]
- Grillo, E.U.; Verdolini, K. Evidence for distinguishing pressed, normal, resonant, and breathy voice qualities by laryngeal resistance and vocal efficiency in vocally trained subjects. J. Voice 2008, 22, 546–552. [Google Scholar] [CrossRef]
- Kreiman, J.; Gerratt, B.R. Perceptual evaluation of voice quality: Review, tutorial, and a framework for future research. J. Acoust. Soc. Am. 1996, 100, 1795–1987. [Google Scholar] [CrossRef]
- Kempster, G.B.; Gerratt, B.R.; Verdolini Abbott, K.; Barkmeier-Kraemer, J.; Hillman, R.E. Consensus auditory-perceptual evaluation of voice: Development of a standardized clinical protocol. Am. J. Speech-Lang. Pathol. 2009, 18, 124–132. [Google Scholar] [CrossRef]
- Zraick, R.I.; Kempster, G.B.; Connor, N.P.; Thibeault, S.; Klaben, B.K.; Bursac, Z.; Thrush, C.R.; Glaze, L.E. Establishing validity of the consensus auditory-perceptual evaluation of voice (cape-v). Am. J. Speech-Lang. Pathol. 2001, 20, 14–22. [Google Scholar] [CrossRef]
- Helou, L.B.; Solomon, N.P.; Henry, L.R.; Coppit, G.L.; Howard, R.S.; Stojadinovic, A. The role of listener experience on consensus auditory-perceptual evaluation of voice (cape-v) ratings of postthyroidectomy voice. Am. J. Speech-Lang. Pathol. 2010, 19, 248–258. [Google Scholar] [CrossRef]
- Kreiman, J.; Gerratt, B.R. Sources of listener disagreement in voice quality assessment. J. Acoust. Soc. Am. 2000, 108, 1867–1876. [Google Scholar] [CrossRef] [Green Version]
- Kreiman, J.; Gerratt, B.R. When and why listeners disagree in voice quality assessment tasks. J. Acoust. Soc. Am. 2007, 122, 2354–2364. [Google Scholar] [CrossRef]
- Bhuta, T.; Patrick, L.; Garnett, J.D. Perceptual evaluation of voice quality and its correlation with acoustic measurements. J. Voice 2004, 18, 299–304. [Google Scholar] [CrossRef]
- Borsky, M.; Mehta, D.D.; Stan, J.H.V.; Gudnason, J. Modal and nonmodal voice quality classification using acoustic and electroglottographic features. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2281–2291. [Google Scholar] [CrossRef]
- Gobl, C.; Chasaide, A.N. Acoustic characteristics of voice quality. Speech Commun. 1992, 11, 481–490. [Google Scholar] [CrossRef]
- Hillenbrand, J.; Cleveland, R.A.; Erickson, R.L. Acoustic correlates of breathy vocal quality. J. Speech Lang. Hear. Res. 1994, 37, 769–778. [Google Scholar] [CrossRef]
- Cheyne, H.A. Estimating Glottal Voicing Source Characteristics By Measuring and Modeling the Acceleration of the Skin on the Neck. Ph.D. Thesis, Harvard University–MIT Division of Health Sciences and Technology, Cambridge, MA, USA, 2002. [Google Scholar]
- Hillman, R.E.; Heaton, J.T.; Masaki, A.; Zeitels, S.M.; Cheyne, H.A. Ambulatory monitoring of disordered voices. Ann. Otol. Rhinol. Laryngol. 2006, 115, 795–801. [Google Scholar] [CrossRef]
- Van Stan, J.H.; Gustafsson, J.; Schalling, E.; Hillman, R.E. Direct comparison of three commercially available devices for voice ambulatory monitoring and biofeedback. SIG 3 Perspect. Voice Voice Disord. 2014, 24, 80–86. [Google Scholar] [CrossRef]
- Mehta, D.D.; Stan, J.H.V.; Hillman, R.E. Relationships between vocal function measures derived from an acoustic microphone and a subglottal neck-surface accelerometer. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 659–668. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehta, D.D.; Zañartu, M.; Feng, S.W.; Cheyne, H.A., 2nd; Hillman, R.E. Mobile voice health monitoring using a wearable accelerometer sensor and a smartphone platform. IEEE Trans. Biomed. Eng. 2012, 59, 3090–3096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lien, Y.-A.S.; Calabrese, C.R.; Michener, C.M.; Heller Murray, E.; Van Stan, J.H.; Mehta, D.D.; Hillman, R.E.; Noordzij, J.P.; Stepp, C.E. Voice relative fundamental frequency via neck-skin acceleration in individuals with voice disorders. J. Speech Lang. Hear. Res. 2015, 58, 1482–1487. [Google Scholar] [CrossRef] [PubMed]
- Švec, J.G.; Titze, I.R.; Popolo, P.S. Estimation of sound pressure levels of voiced speech from skin vibration of the neck. J. Acoust. Soc. Am. 2005, 117, 1386–1394. [Google Scholar] [CrossRef]
- Zañartu, M.; Ho, J.C.; Mehta, D.D.; Hillman, R.E.; Wodicka, G.R. Subglottal impedance-based inverse filtering of voiced sounds using neck surface acceleration. IEEE/ACM Trans. Audio Speech Lang. Process. 2003, 21, 1929–1939. [Google Scholar] [CrossRef] [PubMed]
- Patel, R.R.; Awan, S.N.; Barkmeier-Kraemer, J.; Courey, M.; Deliyski, D.; Eadie, T.; Paul, D.; Švec, J.G.; Hillman, R. Recommended protocols for instrumental assessment of voice: American speech-language-hearing association expert panel to develop a protocol for instrumental assessment of vocal function. Am. J. Speech-Lang. Pathol. 2018, 27, 887–905. [Google Scholar] [CrossRef]
- Shrivastav, R.; Sapienza, C.M. Objective measures of breathy voice quality obtained using an auditory model. J. Acoust. Soc. Am. 2003, 114, 2217–2224. [Google Scholar] [CrossRef]
- Klatt, D.H.; Klatt, L.C. Analysis, synthesis, and perception of voice quality variations among female and male talkers. J. Acoust. Soc. Am. 1990, 87, 820–857. [Google Scholar] [CrossRef]
- Pabon, J.P.H. Objective acoustic voice-quality parameters in the computer phonetogram. J. Voice 1991, 5, 203–216. [Google Scholar] [CrossRef]
- Heman-Ackah, Y.D.; Michael, D.D.; Baroody, M.M.; Ostrowski, R.; Hillenbrand, J.; Heuer, R.J.; Horman, M.; Sataloff, R.T. Cepstral peak prominence: A more reliable measure of dysphonia. Ann. Otol. Rhinol. Laryngol. 2003, 112, 324–333. [Google Scholar] [CrossRef]
- Koike, Y.; Markel, J. Application of inverse filtering for detecting laryngeal pathology. Ann. Otol. Rhinol. Laryngol. 1975, 84, 117–124. [Google Scholar] [CrossRef]
- Alku, P. Glottal inverse filtering analysis of human voice production—A review of estimation and parameterization methods of the glottal excitation and their applications. Sadhana 2011, 36, 623–650. [Google Scholar] [CrossRef]
- Godino-Llorente, J.I.; Gomez-Vilda, P.; Blanco-Velasco, M. Dimensionality reduction of a pathological voice quality assessment system based on gaussian mixture models and short-term cepstral parameters. IEEE Trans. Biomed. Eng. 2006, 53, 1943–1953. [Google Scholar] [CrossRef]
- Ritchings, R.; McGillion, M.; Moore, C. Pathological voice quality assessment using artificial neural networks. Med. Eng. Phys. 2002, 24, 561–564. [Google Scholar] [CrossRef]
- Borsky, M.; Cocude, M.; Mehta, D.D.; Zañartu, M.; Gudnason, J. Classification of voice modes using neck-surface accelerometer data. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Stevens, K.N. Acoustic Phonetics; The MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Rabiner, L.R.; Ronald, W.S. Digital Processing of Speech Signal; Prentice-Hall: Englewood Cliffs, NJ, USA, 1978; pp. 130–135. [Google Scholar]
- Titze, I.R.; Švec, J.G.; Popolo, P.S. Vocal Dose MeasuresQuantifying Accumulated Vibration Exposure in Vocal Fold Tissues. J. Speech Lang. Hear. Res. 2003, 46, 919–932. [Google Scholar] [CrossRef]
- Švec, J.G.; Popolo, P.S.; Titze, I.R. Measurement of vocal doses in speech: Experimental procedure and signal processing. Logop. Phoniatr. Vocol. 2003, 28, 181–192. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | PM | PB | PP | Overall Accuracy | |
|---|---|---|---|---|---|
| TM | 35% | 31% | 34% | 64.7% | |
| TB | 12% | 84% | 4% | ||
| TP | 26% | 6% | 68% | ||
| TM | 35% | 37% | 28% | 61.7% | |
| TB | 12% | 82% | 7% | ||
| TP | 29% | 10% | 61% | ||
| TM | 24% | 35% | 41% | 59.3% | |
| TB | 7% | 92% | 2% | ||
| TP | 17% | 33% | 50% | ||
| TM | 2% | 74% | 24% | 44.7% | |
| TB | 2% | 87% | 11% | ||
| TP | 1% | 71% | 28% | ||
| SE | TM | 0% | 88% | 12% | 54.1% |
| TB | 0% | 93% | 7% | ||
| TP | 0% | 46% | 54% | ||
| TM | 54% | 46% | 0% | 47.4% | |
| TB | 25% | 75% | 0% | ||
| TP | 42% | 58% | 0% | ||
| TM | 92% | 2% | 6% | 60.6% | |
| TB | 18% | 72% | 10% | ||
| TP | 56% | 33% | 11% |
| DT | LD | SVM | KNN | NN | Per-Set | |
|---|---|---|---|---|---|---|
| Full Set | 77.4 | 78.3 | 81.3 | 81.0 | 82.5 | 80.1 ± 2.1 |
| − | 74.9 | 78.4 | 82.1 | 81.7 | 83.3 | 80.1 ± 3.4 |
| − | 74.4 | 79.0 | 82.0 | 81.7 | 83.3 | 80.1 ± 3.5 |
| − | 75.4 | 78.0 | 81.5 | 79.9 | 82.7 | 79.5 ± 2.9 |
| − | 77.6 | 78.0 | 81.5 | 81.5 | 82.5 | 80.2 ± 2.3 |
| -SE | 74.4 | 74.3 | 78.3 | 78.5 | 77.9 | 76.7 ± 2.1 |
| − | 75.4 | 76.8 | 81.1 | 80.1 | 83.3 | 79.3 ± 3.2 |
| − | 71.8 | 74.9 | 73.2 | 75.3 | 76.8 | 74.4 ± 1.9 |
| Per-Classifier | 75.2 ± 1.8 | 77.3 ± 2.5 | 80.1 ± 2.9 | 79.9 ± 2.2 | 81.5 ± 2.6 |
| DT | LD | SVM | KNN | NN | ||
|---|---|---|---|---|---|---|
| Modal | TPR | 0.73 | 0.70 | 0.79 | 0.77 | 0.81 |
| FPR | 0.14 | 0.13 | 0.11 | 0.11 | 0.10 | |
| AUC | 0.85 | 0.89 | 0.92 | 0.92 | 0.93 | |
| Breathy | TPR | 0.84 | 0.87 | 0.89 | 0.89 | 0.90 |
| FPR | 0.10 | 0.10 | 0.09 | 0.09 | 0.08 | |
| AUC | 0.89 | 0.95 | 0.96 | 0.96 | 0.97 | |
| Pressed | TPR | 0.69 | 0.75 | 0.74 | 0.75 | 0.91 |
| FPR | 0.10 | 0.10 | 0.08 | 0.08 | 0.16 | |
| AUC | 0.86 | 0.91 | 0.92 | 0.93 | 0.94 |
| DT | LD | SVM | KNN | NN | Per-Set | |
|---|---|---|---|---|---|---|
| Full Set | 77.4 | 78.3 | 81.3 | 81.0 | 82.5 | 80.1 ± 2.1 |
| 73.5 | 75.2 | 74.9 | 75.1 | 76.7 | 75.1 ± 1.1 | |
| + | 59.8 | 60.0 | 59.0 | 57.1 | 61.5 | 59.5 ± 1.6 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, Z.; Kennedy, E.; Fasanella, L.; Li-Jessen, N.Y.-K.; Mongeau, L. Discrimination between Modal, Breathy and Pressed Voice for Single Vowels Using Neck-Surface Vibration Signals. Appl. Sci. 2019, 9, 1505. https://0-doi-org.brum.beds.ac.uk/10.3390/app9071505
Lei Z, Kennedy E, Fasanella L, Li-Jessen NY-K, Mongeau L. Discrimination between Modal, Breathy and Pressed Voice for Single Vowels Using Neck-Surface Vibration Signals. Applied Sciences. 2019; 9(7):1505. https://0-doi-org.brum.beds.ac.uk/10.3390/app9071505
Chicago/Turabian StyleLei, Zhengdong, Evan Kennedy, Laura Fasanella, Nicole Yee-Key Li-Jessen, and Luc Mongeau. 2019. "Discrimination between Modal, Breathy and Pressed Voice for Single Vowels Using Neck-Surface Vibration Signals" Applied Sciences 9, no. 7: 1505. https://0-doi-org.brum.beds.ac.uk/10.3390/app9071505