
Infrared and Visible Image Fusion Methods for Unmanned Surface Vessels with Marine Applications

Abstract
:1. Introduction
- (1)
- A novel calibration board was designed to calibrate infrared and visible cameras. To avoid the loss of detailed texture in infrared images that is induced by the thermal diffusion between high- and low-temperature regions, all heating elements of the calibration board are processed to be insulated, which makes the accuracy of the calibration able to be improved. Moreover, a major part of the calibration board is made of lightweight thermal insulation material. Thus, the designed calibration board not only possesses high contrast for both visible images and infrared images, but it also enjoys high portability in USV field applications.
- (2)
- Three novel fusion strategies, adaptive weight fusion (AWF), cross bilateral filtering fusion (CBF), and guided filtering fusion (GFF), are proposed in this paper. The AWF calculates the weight of each sub-block, rather than roughly calculating the feature maps’ weights, such that the fusion result can be more accurate. The CBF considers intensity re-semblance and geometric closeness for the computation of fusion weights. The GFF utilizes a guided filter for edge preservation in the fusion results. Compared to the previous fusion strategies [28,29], the proposed fusion strategies make more effective use of the texture features in infrared images.
- (3)
- The proposed algorithms are compared with two widely accepted algorithms, average weighted fusion (AVE) [29] and L1 norm weighted fusion (L1) [28], under the optoelectronic system of ‘Tianxing-1’ USV. The experiment results indicate that the proposed AWF strategy can be applied to the USV and show superior performance on water surface images.
2. Camera Calibration
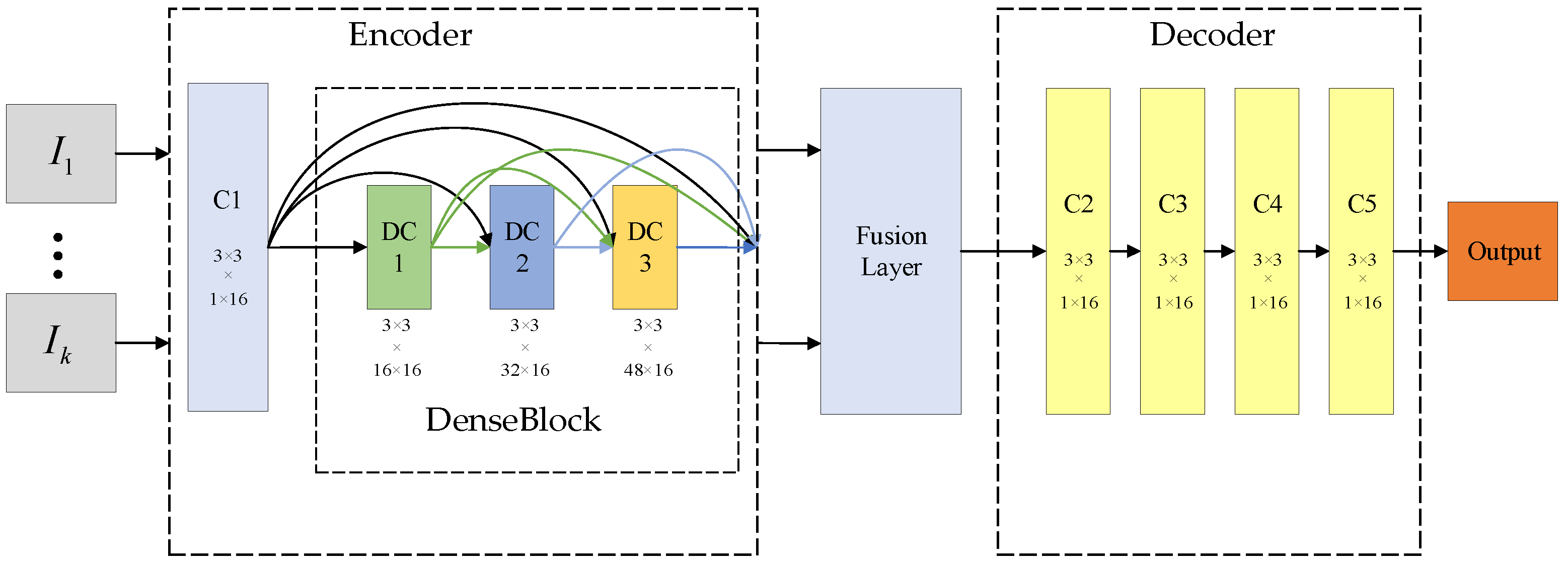
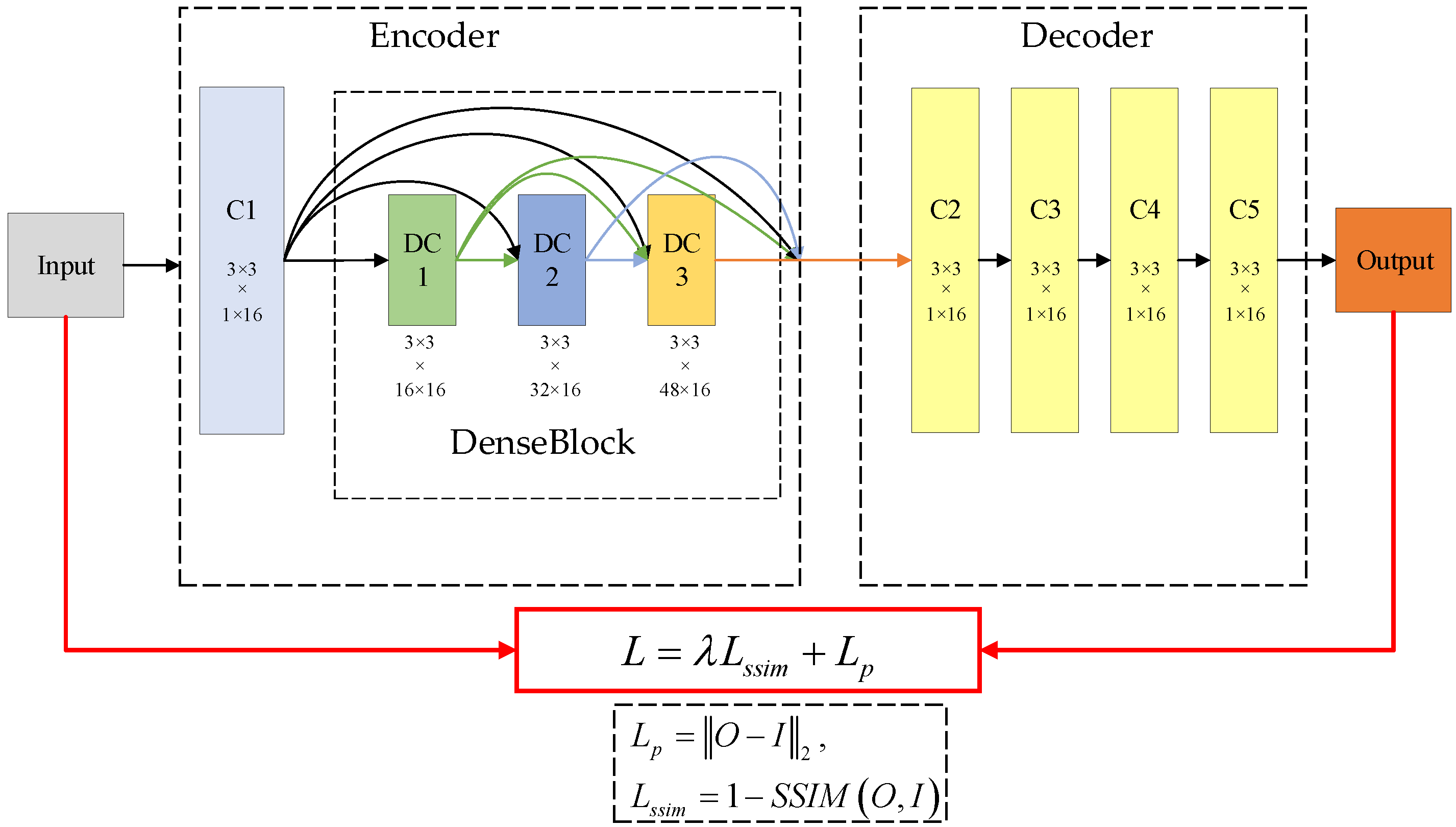
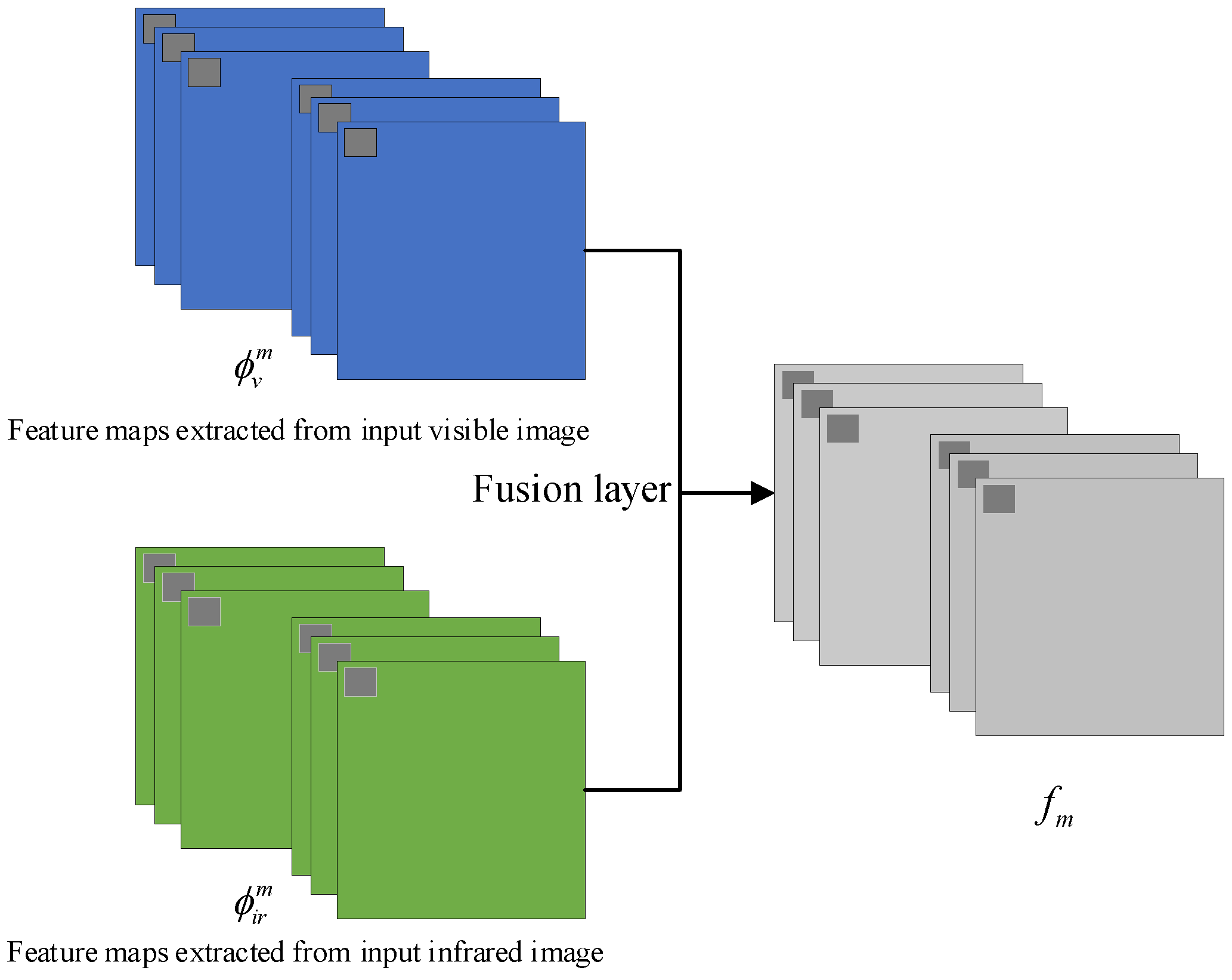
3. Improvement of Fusion Network
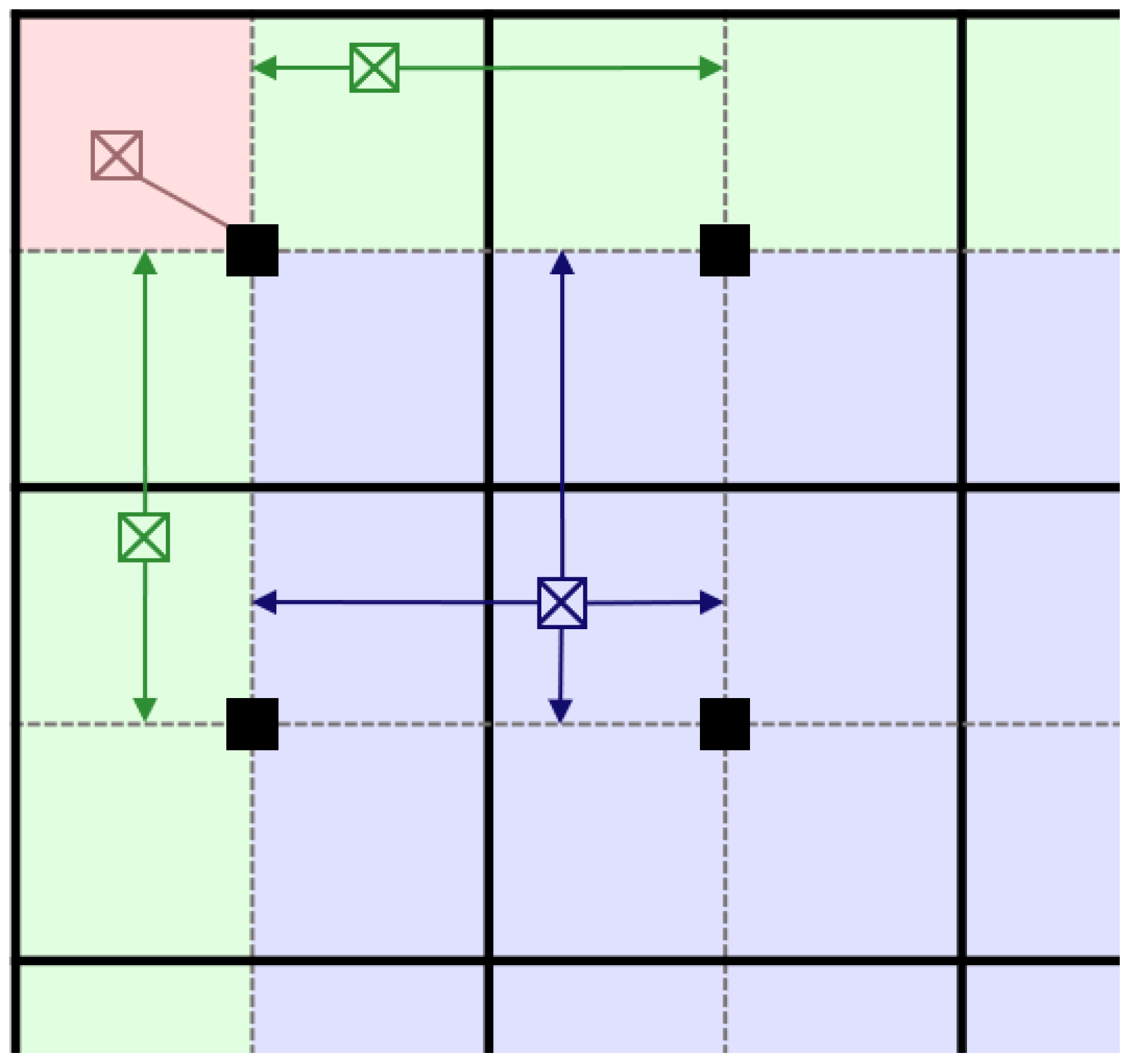
3.1. Adaptive Weight Strategy
3.2. Cross Bilateral Filtering
- (1)
- CBF
- (2)
- Pixed-based fusion rule
3.3. Guided Filtering
4. Experimental Results and Analysis
4.1. Qualitative Image Quality Assessment
4.2. Quantitative Image Quality Assessment
- (1)
- Quantitative assessment compared to baselines
- (2)
- Quantitative assessment over proposed algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Method |
Quantitative Analysis (Percentage Change) | |||||
|---|---|---|---|---|---|---|---|
| AG | EN | SD | SSIM | MI | SNR | ||
| Image 1 | AVE | 1.618 | 7.128 | 59.94 | 0.869 | 6.256 | 21.883 |
| L1 | 1.985 (22.7%) | 7.181 (0.7%) | 50.74 (−15.3%) | 0.855 (−1.6%) | 6.185 (−1.1%) | 22.783 (4.1%) | |
| AWF | 1.995 (23.3%) | 7.183 (0.8%) | 50.594 (−15.6%) | 0.86 (−1.0%) | 6.167 (−1.4%) | 23.182 (5.9%) | |
| CBF | 1.452 (−10.3%) | 6.073 (−14.8%) | 32.446 (−45.9%) | 0.841 (−3.2%) | 5.713 (−8.7%) | 20.439 (−6.6%) | |
| GFF | 1.91 (18.0%) | 7.227 (1.4%) | 64.736 (8.0%) | 0.849 (−2.3%) | 6.349 (1.5%) | 20.904 (−4.5%) | |
| Image 2 | AVE | 2.163 | 7.192 | 56.704 | 0.851 | 6.111 | 18.096 |
| L1 | 2.321 (7.3%) | 7.232 (0.6%) | 55.569 (−2.0%) | 0.847 (−0.5%) | 6.165 (0.9%) | 21.218 (17.3%) | |
| AWF | 2.349 (8.6%) | 7.275 (1.2%) | 57.362 (1.2%) | 0.849 (−0.2%) | 6.146 (0.6%) | 21.177 (17.0%) | |
| CBF | 2.029 (−6.2%) | 6.748 (−6.2%) | 43.31 (−23.6%) | 0.797 (−6.3%) | 6.049 (−1.0%) | 20.695 (14.4%) | |
| GFF | 2.514 (16.2%) | 7.206 (0.2%) | 57.344 (1.1%) | 0.816 (−4.1%) | 6.439 (5.4%) | 18.801 (3.9%) | |
| Image 3 | AVE | 2.533 | 7.454 | 63.037 | 0.842 | 6.387 | 19.255 |
| L1 | 2.6 (2.6%) | 7.411 (−0.6%) | 60.157 (−4.6%) | 0.835 (−0.8%) | 6.426 (0.6%) | 20.015 (3.9%) | |
| AWF | 2.639 (4.2%) | 7.41 (−0.6%) | 61.285 (−2.8%) | 0.842 (0.0%) | 6.361 (−0.4%) | 20.288 (5.4%) | |
| CBF | 2.103 (−17.0%) | 6.708 (−10.0%) | 53.082 (−15.8%) | 0.781 (−7.2%) | 6.074 (−4.9%) | 20.073 (4.2%) | |
| GFF | 2.386 (−5.8%) | 7.485 (0.4%) | 62.147 (−1.4%) | 0.805 (−4.4%) | 6.619 (3.6%) | 18.244 (−5.3%) | |
| Image 4 | AVE | 1.063 | 6.574 | 39.043 | 0.86 | 5.414 | 14.011 |
| L1 | 0.975 (−8.3%) | 6.569 (−0.1%) | 32.592 (−16.5%) | 0.858 (−0.2%) | 5.857 (8.2%) | 15.28 (9.1%) | |
| AWF | 1.121 (5.5%) | 6.859 (4.3%) | 40.939 (4.9%) | 0.854 (−0.7%) | 5.759 (6.4%) | 12.976 (−7.4%) | |
| CBF | 1.195 (12.4%) | 5.794 (−11.9%) | 18.555 (−52.5%) | 0.815 (−5.2%) | 5.383 (−0.6%) | 27.403 (95.6%) | |
| GFF | 1.092 (2.7%) | 5.631 (−14.3%) | 15.599 (−60.0%) | 0.819 (−4.8%) | 5.016 (−7.4%) | 28.412 (102.8%) | |
| Image 5 | AVE | 1.451 | 6.391 | 47.17 | 0.805 | 5.717 | 15.075 |
| L1 | 1.621 (11.7%) | 6.538 (2.3%) | 56.349 (19.5%) | 0.79 (−1.9%) | 5.941 (3.9%) | 11.539 (−23.5%) | |
| AWF | 1.624 (11.9%) | 6.595 (3.2%) | 58.361 (23.7%) | 0.799 (−0.7%) | 5.736 (0.3%) | 11.368 (−24.6%) | |
| CBF | 1.347 (−7.2%) | 6.258 (−2.1%) | 25.079 (−46.8%) | 0.771 (−4.2%) | 5.492 (−3.9%) | 23.133 (53.5%) | |
| GFF | 1.642 (13.2%) | 6.729 (5.3%) | 28.733 (−39.1%) | 0.777 (−3.5%) | 5.549 (−2.9%) | 18.601 (23.4%) | |
| Image 6 | AVE | 1.462 | 6.474 | 44.204 | 0.751 | 5.607 | 16.286 |
| L1 | 1.556 (6.4%) | 6.44 (−0.5%) | 51.687 (16.9%) | 0.749 (−0.3%) | 5.676 (1.2%) | 14.312 (−12.1%) | |
| AWF | 1.474 (0.8%) | 6.401 (−1.1%) | 49.625 (12.3%) | 0.755 (0.5%) | 5.574 (−0.6%) | 14.928 (−8.3%) | |
| CBF | 1.679 (14.8%) | 5.964 (−7.9%) | 25.7 (−41.9%) | 0.745 (−0.8%) | 5.409 (−3.5%) | 26.396 (62.1%) | |
| GFF | 1.576 (7.8%) | 6.807 (5.1%) | 41.737 (−5.6%) | 0.707 (−5.9%) | 5.963 (6.3%) | 16.149 (−0.8%) | |
| Image 7 | AVE | 1.505 | 6.236 | 29.377 | 0.854 | 5.305 | 16.729 |
| L1 | 1.389 (−7.7%) | 6.147 (−1.4%) | 34.116 (16.1%) | 0.849 (−0.6%) | 5.563 (4.9%) | 14.587 (−12.8%) | |
| AWF | 1.564 (3.9%) | 6.309 (1.2%) | 31.24 (6.3%) | 0.863 (1.1%) | 5.532 (4.3%) | 15.696 (−6.2%) | |
| CBF | 1.92 (27.6%) | 6.638 (6.4%) | 57.972 (97.3%) | 0.587 (−31.3%) | 5.72 (7.8%) | 8.832 (−47.2%) | |
| GFF | 1.656 (10.0%) | 6.312 (1.2%) | 38.344 (30.5%) | 0.808 (−5.4%) | 5.496 (3.6%) | 12.878 (−23.0%) | |
| Image 8 | AVE | 1.491 | 6.368 | 87.179 | 0.802 | 5.876 | 8.436 |
| L1 | 1.377 (−7.6%) | 6.462 (1.5%) | 78.577 (−9.9%) | 0.813 (1.4%) | 5.796 (−1.4%) | 9.98 (18.3%) | |
| AWF | 1.42 (−4.8%) | 6.389 (0.3%) | 82.771 (−5.1%) | 0.81 (1.0%) | 5.577 (−5.1%) | 9.245 (9.6%) | |
| CBF | 1.217 (−18.4%) | 5.943 (−6.7%) | 40.586 (−53.4%) | 0.803 (0.1%) | 5.681 (−3.3%) | 12.365 (46.6%) | |
| GFF | 1.222 (−18.0%) | 7.091 (11.4%) | 65.273 (−25.1%) | 0.789 (−1.6%) | 6.153 (4.7%) | 11.501 (36.3%) | |
References
- Liu, Z.; Zhang, Y.; Yu, X.; Yuan, C. Unmanned surface vehicles: An overview of developments and challenges. Annu. Rev. Control. 2016, 41, 71–93. [Google Scholar] [CrossRef]
- Huang, B.; Zhou, B.; Zhang, S.; Zhu, C. Adaptive prescribed performance tracking control for underactuated autonomous underwater vehicles with input quantization. Ocean. Eng. 2021, 221, 108549. [Google Scholar] [CrossRef]
- Campbell, S.; Naeem, W.; Irwin, G.; Campbell, S.; Naeem, W.; Irwin, G. A review on improving the autonomy of unmanned surface vehicles through intelligent collision avoidance manoeuvres. Annu. Rev. Control. 2012, 36, 267–283. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Wen, J.; Zhang, C.; Liu, Q.; Yan, D. An effective fusion defogging approach for single sea fog image. Neurocomputing 2016, 173, 1257–1267. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Singh, R.; Vatsa, M.; Noore, A. Integrated multilevel image fusion and match score fusion of visible and infrared face images for robust face recognition. Pattern Recognit. 2008, 41, 880–893. [Google Scholar] [CrossRef] [Green Version]
- Zhu, C.; Zeng, J.; Huang, B.; Su, Y.; Su, Z. Saturated approximation-free prescribed performance trajectory tracking control for autonomous marine surface vehicle. Ocean. Eng. 2021, 237, 109602. [Google Scholar] [CrossRef]
- Zhou, B.; Huang, B.; Su, Y.; Zheng, Y.; Zheng, S. Fixed-time neural network trajectory tracking control for underactuated surface vessels. Ocean. Eng. 2021, 236, 109416. [Google Scholar] [CrossRef]
- Kumar, P.; Mittal, A.; Kumar, P. Fusion of Thermal Infrared and Visible Spectrum Video for Robust Surveillance. In Computer Vision, Graphics and Image Processing; Springer: Berlin/Heidelberg, Germany, 2006; pp. 528–539. [Google Scholar]
- Simone, G.; Farina, A.; Morabito, F.C.; Serpico, S.B.; Bruzzone, L. Image fusion techniques for remote sensing ap-plications. Inf. Fusion 2002, 3, 3–15. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Wen, J.; Liang, X. Video Image Clarity Algorithm Research of USV Visual System under the Sea Fog. In Proceedings of the International Conference in Swarm Intelligence, Harbin, China, 12–15 June 2013; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2013; Volume 7929, pp. 436–444. [Google Scholar]
- Zabolotskikh, E.V.; Mitnik, L.; Chapron, B. New approach for severe marine weather study using satellite passive microwave sensing. Geophys. Res. Lett. 2013, 40, 3347–3350. [Google Scholar]
- Zhu, C.; Huang, B.; Zhou, B.; Su, Y.; Zhang, E. Adaptive model-parameter-free fault-tolerant trajectory tracking control for autonomous underwater vehicles. ISA Trans. 2021, 114, 57–71. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Wang, X.; Luo, X.; Xie, S.; Zhu, S. Unmanned surface vehicle adaptive decision model for changing weather. Int. J. Comput. Sci. Eng. 2021, 24, 18–26. [Google Scholar] [CrossRef]
- Liu, Y.; Jin, J.; Wang, Q.; Shen, Y.; Dong, X. Region level based multi-focus image fusion using quaternion wavelet and normalized cut. Signal. Process. 2014, 97, 9–30. [Google Scholar] [CrossRef]
- Toet, A. Image fusion by a ratio of low-pass pyramid. Pattern Recognit. Lett. 1989, 9, 245–253. [Google Scholar] [CrossRef]
- Choi, M.; Kim, R.Y.; Nam, M.-R.; Kim, H.O. Fusion of Multispectral and Panchromatic Satellite Images Using the Curvelet Transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 136–140. [Google Scholar] [CrossRef]
- Wang, J.; Peng, J.; Feng, X.; He, G.; Fan, J. Fusion method for infrared and visible images by using non-negative sparse representation. Infrared Phys. Technol. 2014, 67, 477–489. [Google Scholar] [CrossRef]
- Li, S.; Yin, H.; Fang, L. Group-sparse representation with dictionary learning for medical image denoising and fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef]
- Wang, Z.; Cui, Z.; Zhu, Y. Multi-modal medical image fusion by Laplacian pyramid and adaptive sparse representation. Comput. Biol. Med. 2020, 123, 103823. [Google Scholar] [CrossRef]
- Zhu, Z.; Yin, H.; Chai, Y.; Li, Y.; Qi, G. A novel multi-modality image fusion method based on image decomposition and sparse representation. Inf. Sci. 2018, 432, 516–529. [Google Scholar] [CrossRef]
- Xing, C.; Wang, M.; Dong, C.; Duan, C.; Wang, Z. Using Taylor Expansion and Convolutional Sparse Representation for Image Fusion. Neurocomputing 2020, 402, 437–455. [Google Scholar] [CrossRef]
- Wu, C.; Chen, L. Infrared and visible image fusion method of dual NSCT and PCNN. PLoS ONE 2020, 15, e0239535. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Z.; Gao, W.; Khattak, A.M.; Wang, M. A novel multi-source image fusion method for pig-body multi-feature detection in NSCT domain. Multimed. Tools Appl. 2020, 79, 26225–26244. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. Multi-focus Image Fusion Using Dictionary Learning and Low-Rank Representation. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2017; pp. 675–686. [Google Scholar]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image Fusion With Convolutional Sparse Representation. IEEE Signal. Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- An, G.H.; Lee, S.; Seo, M.-W.; Yun, K.; Cheong, W.-S.; Kang, S.-J. Charuco Board-Based Omnidirectional Camera Calibration Method. Electronics 2018, 7, 421. [Google Scholar] [CrossRef] [Green Version]
- Ch, M.M.I.; Riaz, M.M.; Iltaf, N.; Ghafoor, A.; Ahmad, A. Weighted image fusion using cross bilateral filter and non-subsampled contourlet transform. Multidimens. Syst. Signal. Process. 2019, 30, 2199–2210. [Google Scholar] [CrossRef]
- Hayat, N.; Imran, M. Ghost-free multi exposure image fusion technique using dense SIFT descriptor and guided filter. J. Vis. Commun. Image Represent. 2019, 62, 295–308. [Google Scholar] [CrossRef]

















| Layer | Size | Stride | Channel (Input) | Channel (Output) | Activation | |
|---|---|---|---|---|---|---|
| Encoder | Conv (C1) | 3 | 1 | 1 | 16 | ReLU |
| Dense | ||||||
| Decoder | Conv (C2) | 3 | 1 | 64 | 64 | ReLU |
| Conv (C3) | 3 | 1 | 64 | 32 | ReLU | |
| Conv (C4) | 3 | 1 | 32 | 16 | ReLU | |
| Conv (C5) | 3 | 1 | 16 | 1 | ReLU | |
| Dense (DenseBlock) | Conv (DC1) | 3 | 1 | 16 | 16 | ReLU |
| Conv (DC1) | 3 | 1 | 32 | 16 | ReLU | |
| Conv (DC1) | 3 | 1 | 48 | 16 | ReLU |
| AVE | L1 | AWF | CBF | GFF | |
|---|---|---|---|---|---|
| Average gradient | 1.063 | 0.957 | 1.121 | 1.195 | 1.092 |
| Percentage change for AVE | - | - | +5.5% | +12.4% | +2.7% |
| Percentage change for L1 | - | - | +14.9% | +22.6% | +12% |
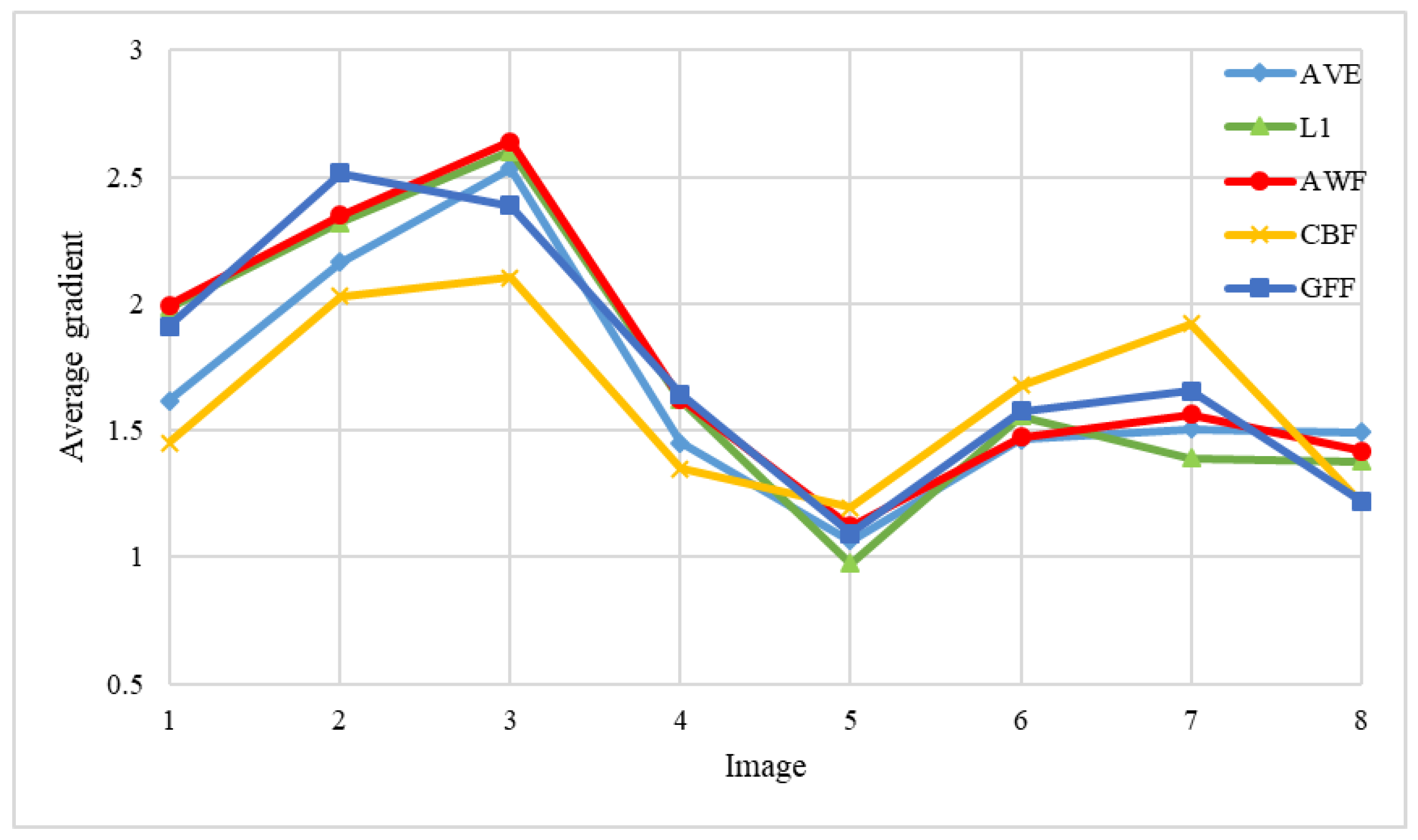
| Image | Average Gradient of Results (Percentage Change) | ||||
|---|---|---|---|---|---|
| AVE | L1 | AWF | CBF | GFF | |
| Figure 13a | 1.618 | 1.985 (22.7%) | 1.995 (23.3%) | 1.452 (−10.3%) | 1.91 (18.0%) |
| Figure 13b | 2.163 | 2.321 (7.3%) | 2.349 (8.6%) | 2.029 (−6.2%) | 2.514 (16.2%) |
| Figure 13c | 2.533 | 2.6 (2.6%) | 2.639 (4.2%) | 2.103 (−17.0%) | 2.386 (−5.8%) |
| Figure 13d | 1.451 | 1.621 (11.7%) | 1.624 (11.9%) | 1.347 (−7.2%) | 1.642 (13.2%) |
| Figure 13e | 1.063 | 0.975 (−8.3%) | 1.121 (5.5%) | 1.195 (12.4%) | 1.092 (2.7%) |
| Figure 13f | 1.462 | 1.556 (6.4%) | 1.474 (0.8%) | 1.679 (14.8%) | 1.576 (7.8%) |
| Figure 13g | 1.505 | 1.389 (−7.7%) | 1.564 (3.9%) | 1.92 (27.6%) | 1.656 (10.0%) |
| Figure 13h | 1.491 | 1.377 (−7.6%) | 1.42 (−4.8%) | 1.217 (−18.4%) | 1.222 (−18.0%) |
| Average | - | - (3.4%) | - (6.7%) | - (−0.5%) | - (5.5%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Su, Y.; Li, Y.; Zhang, L.; Feng, J. Infrared and Visible Image Fusion Methods for Unmanned Surface Vessels with Marine Applications. J. Mar. Sci. Eng. 2022, 10, 588. https://0-doi-org.brum.beds.ac.uk/10.3390/jmse10050588
Zhang R, Su Y, Li Y, Zhang L, Feng J. Infrared and Visible Image Fusion Methods for Unmanned Surface Vessels with Marine Applications. Journal of Marine Science and Engineering. 2022; 10(5):588. https://0-doi-org.brum.beds.ac.uk/10.3390/jmse10050588
Chicago/Turabian StyleZhang, Renran, Yumin Su, Yifan Li, Lei Zhang, and Jiaxiang Feng. 2022. "Infrared and Visible Image Fusion Methods for Unmanned Surface Vessels with Marine Applications" Journal of Marine Science and Engineering 10, no. 5: 588. https://0-doi-org.brum.beds.ac.uk/10.3390/jmse10050588