
Optimization of a Regional Marine Environment Mobile Observation Network Based on Deep Reinforcement Learning


Abstract
:1. Introduction
- Using reinforcement learning, we build a marine environment. Traditional algorithms need to construct a complex ocean environment cost function, while reinforcement learning uses the characteristics of ocean environment elements to build the ocean environment. In the marine environment created by the deep learning network, the agent can learn by interacting with the environment to achieve its goals;
- To cope with the partial observability of the observation environment, we use the Dueling Double Deep Recurrent Q-network (D3RQN) algorithm to approximate the optimal value function. Algorithms based on D3RQN can solve partially observable problems through bidirectional recurrent neural networks. This method is more robust than the Deep Q-network (DQN), Dueling Double Deep Q-network (D3QN), and Deep Recurrent Q-network (DRQN) methods in the ways that the neural network with a bidirectional layer can learn the pre-order environment state and the reverse order environment state at the same time, and thus the sampling results obtained by the platforms are closer to the true value;
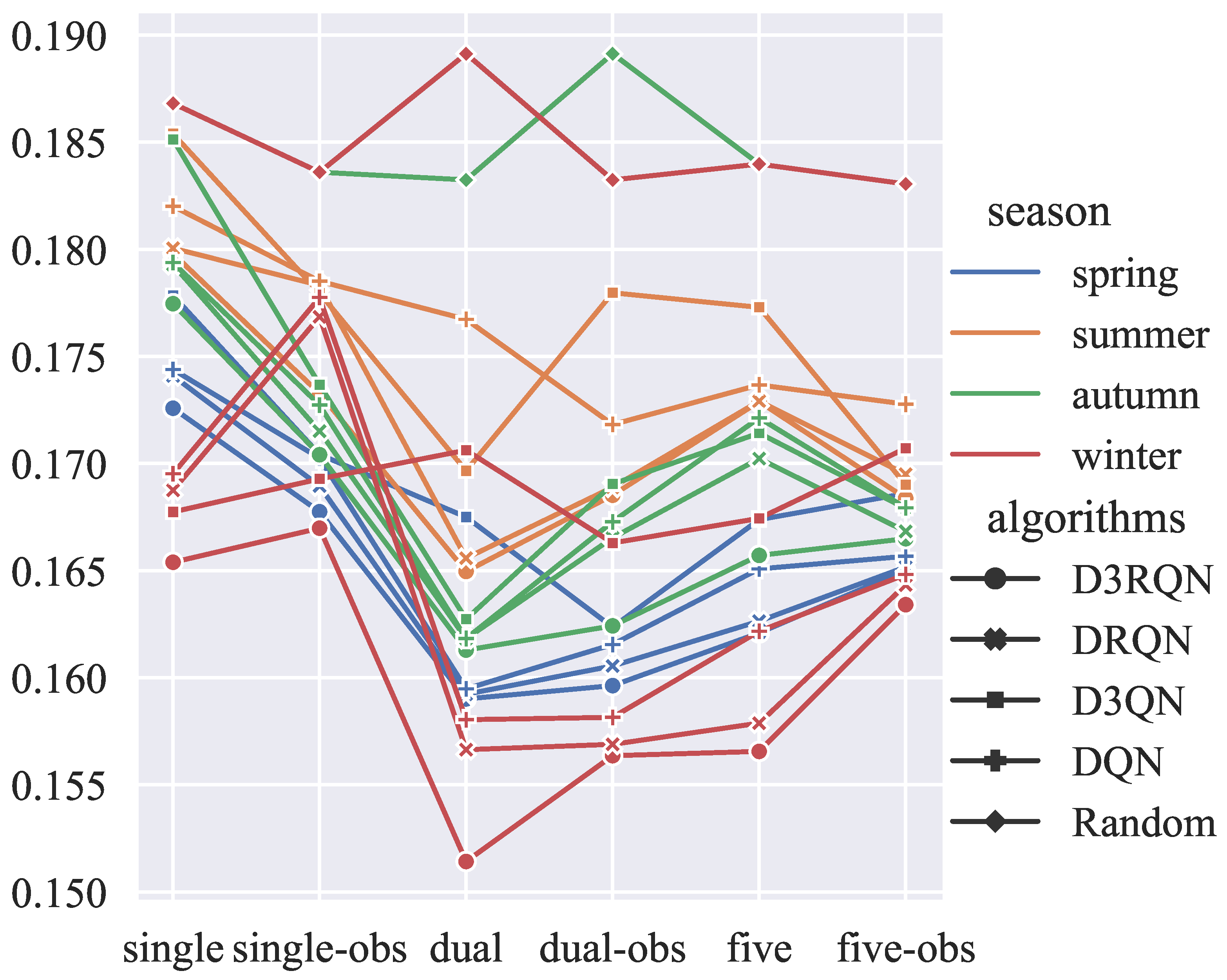
- Planning the observation path of the mobile observation network through deep reinforcement learning can improve the observation efficiency of marine environment elements and the ability to analyze and forecast under the condition of limited observation resources. When the number of observation platforms exceeds 2, the assimilation results will not be significantly improved.
2. Method
2.1. Refined Analysis and Forecast of Regional Coupling Environment
2.2. Regional Marine Environment Mobile Observation Network Model
2.3. Partially Observable Markov Decision Process
2.4. Deep Q-Network
Dueling Double Deep Bidirectional Recurrency Q-Network
3. Design of a Mobile Observation Network for the Marine Environment Based on Deep Bidirectional Recurrent Reinforcement Learning
3.1. Data Collection and Processing
3.2. State Space and Action Space
3.3. Reward Function
4. Experiment and Analysis
4.1. Experimental Settings
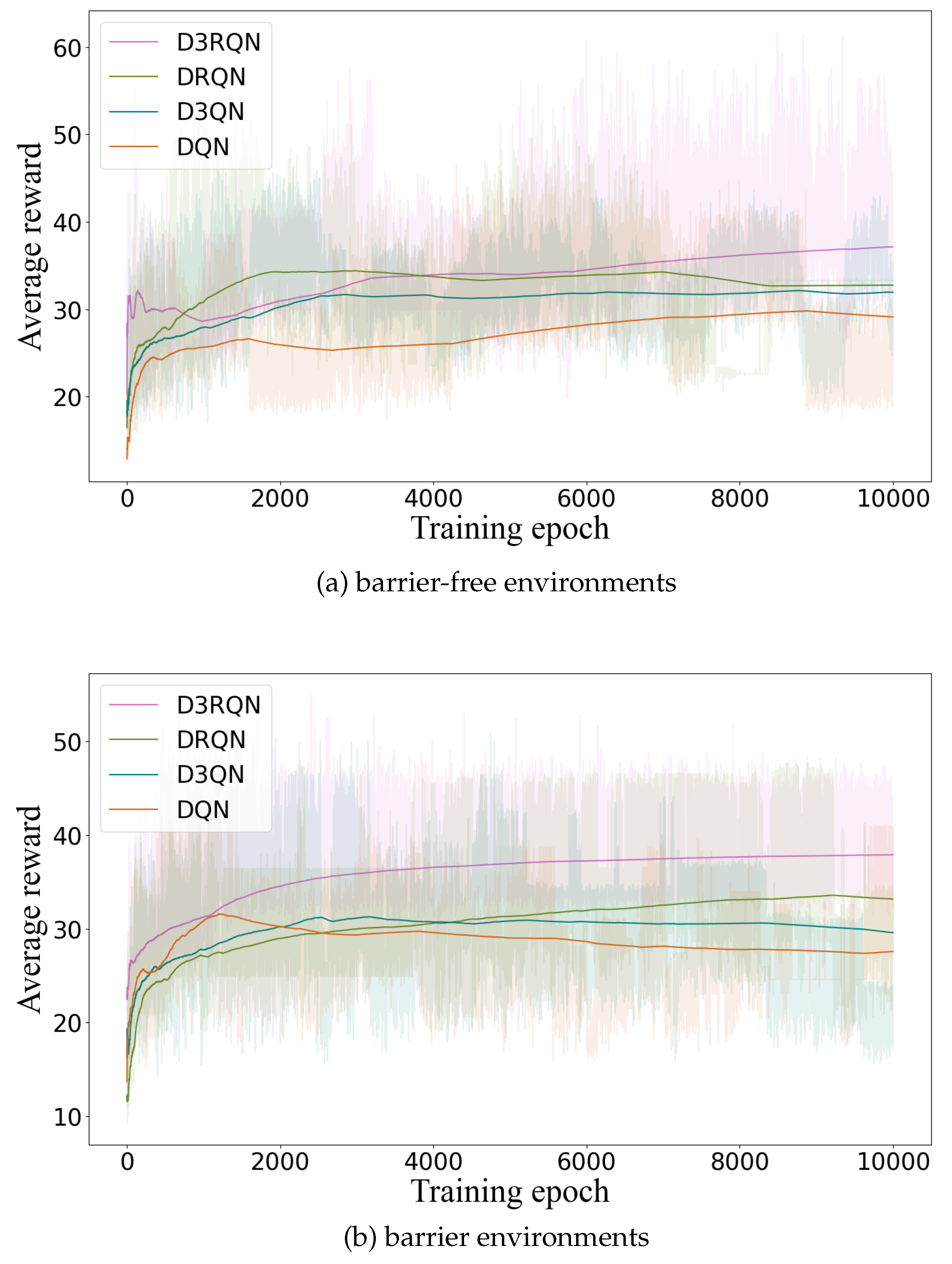
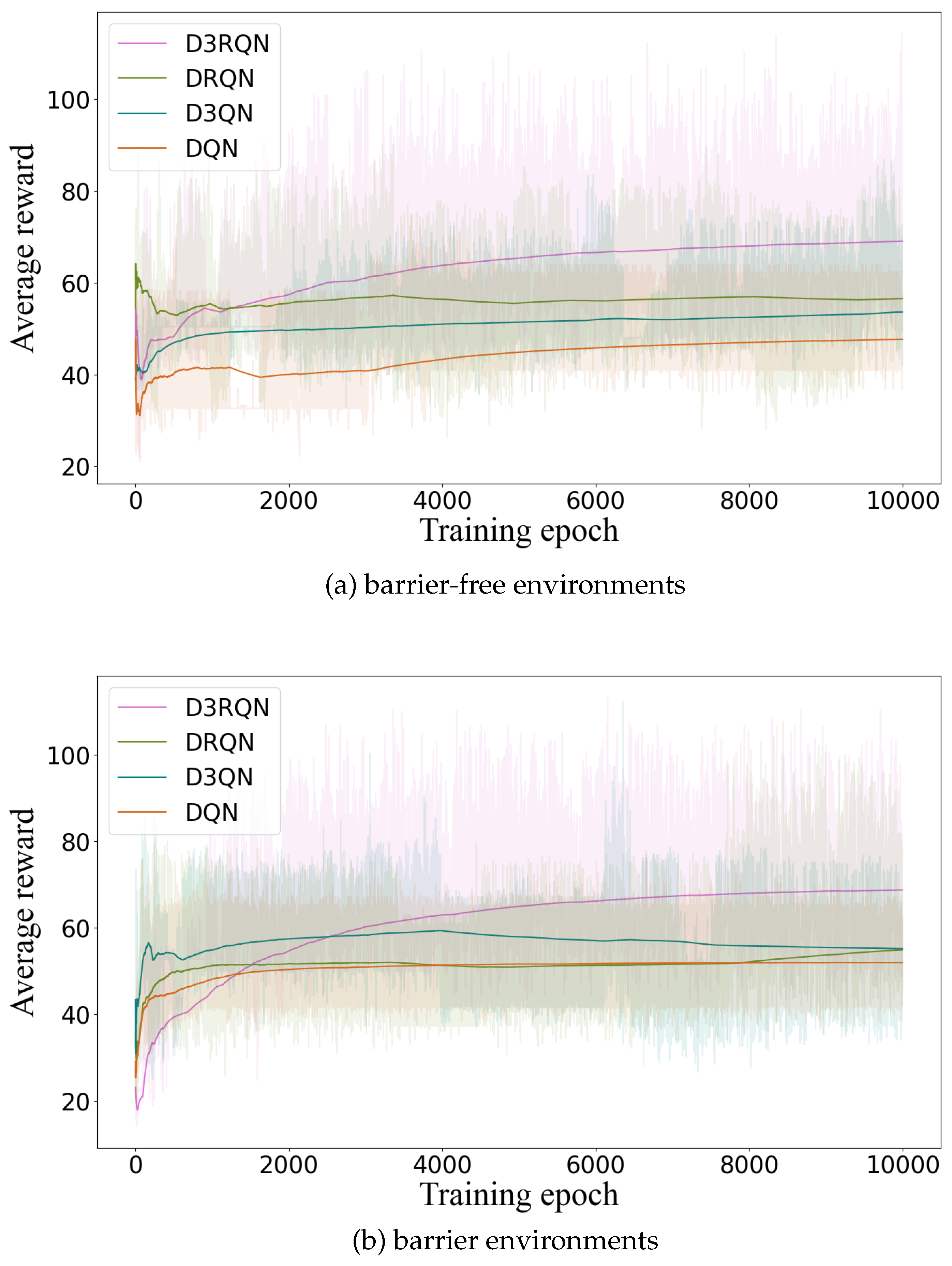
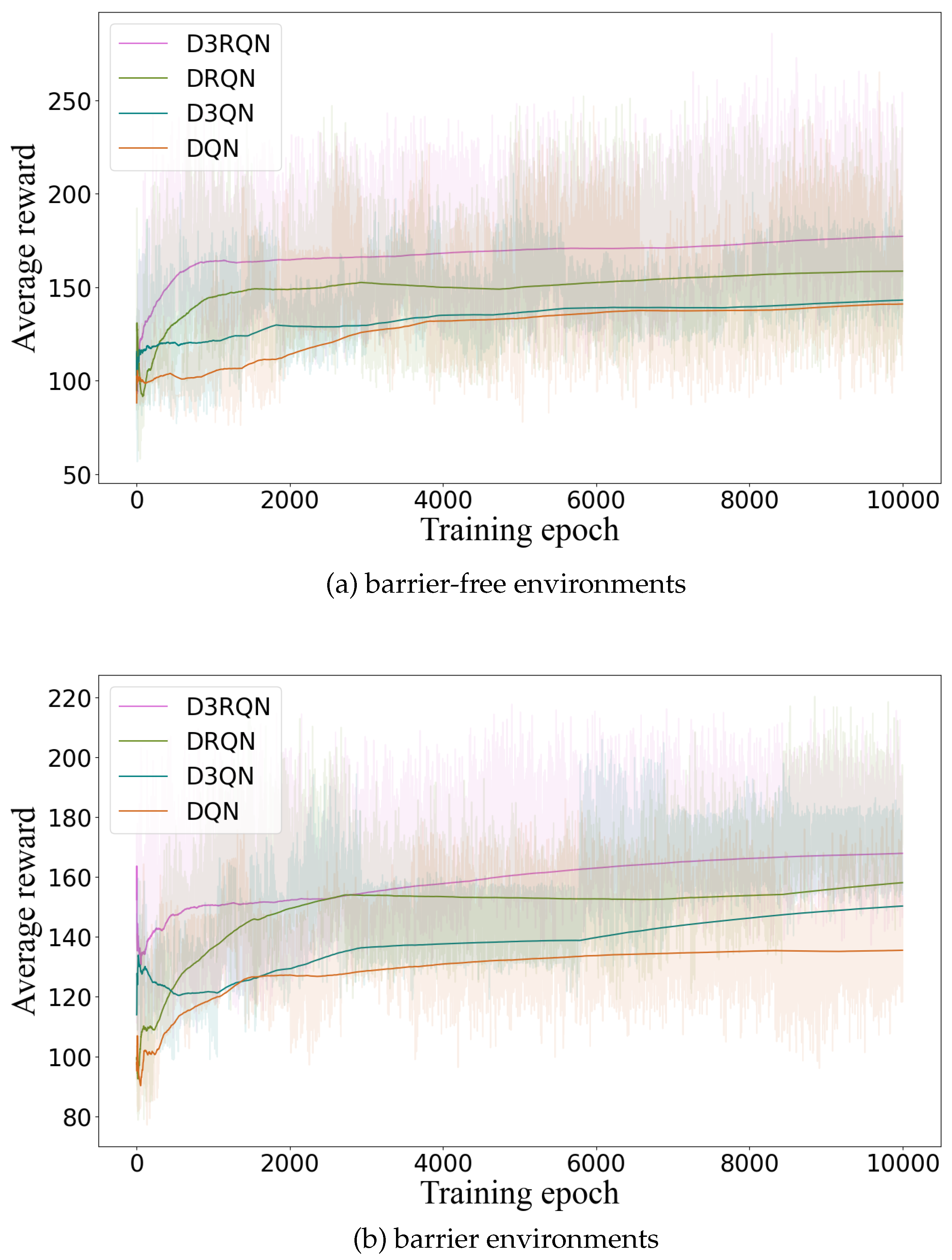
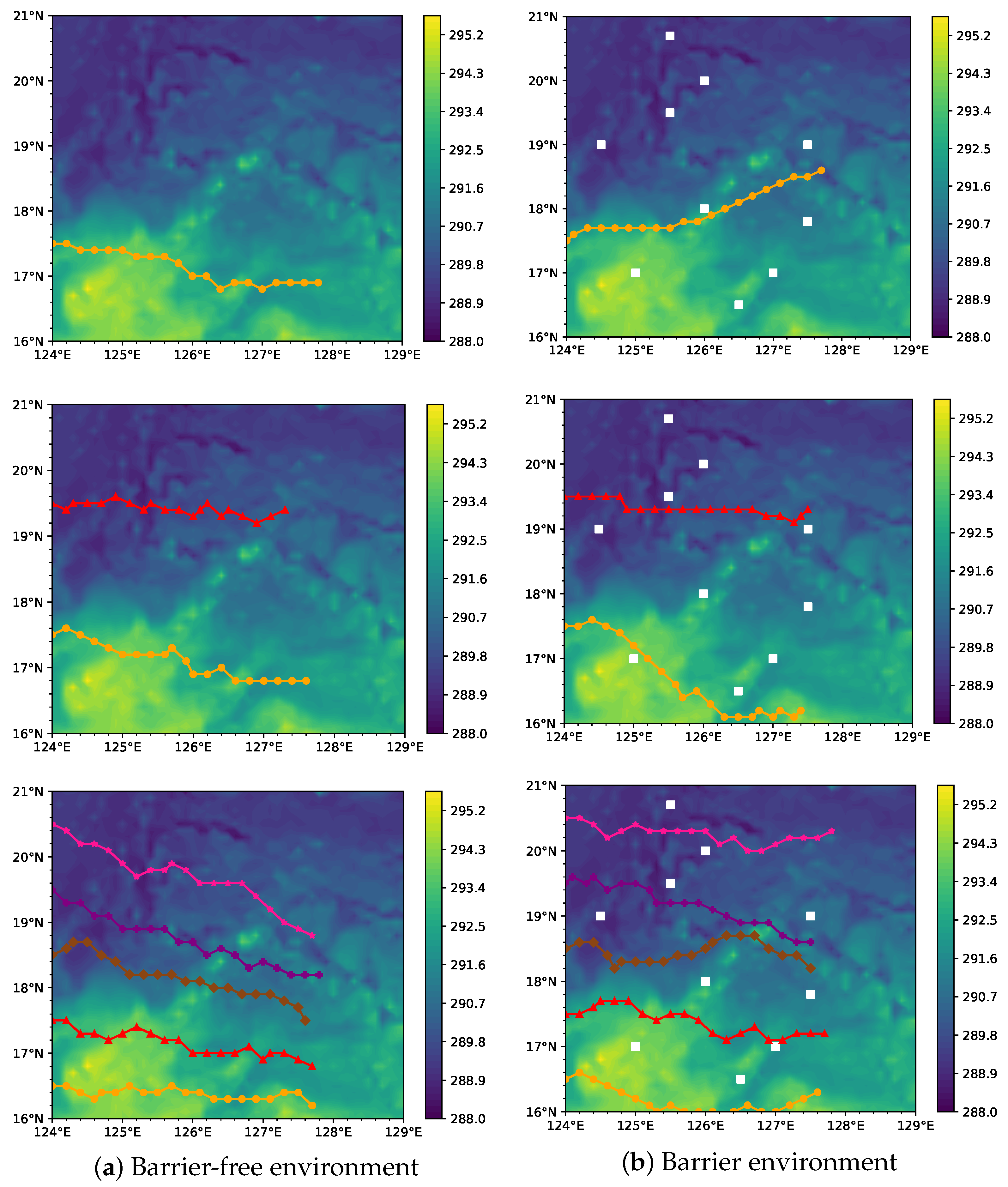
4.2. Observation Platform Sampling Results and Analysis
4.3. Assimilation Results and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cai, S.Q.; Zhang, W.J.; Wang, S.A. An advance in marine environment observation technology. J. Trop. Oceanogr. 2007, 3, 76–81. [Google Scholar]
- Wang, B.D. Autonomous Underwater Vehicle (auv) Path Planning and Adaptive On-Board Routing for Adaptive Rapid Environmental Assessment. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2007. [Google Scholar]
- Thomas, C.; James, B.; Josko, C.; Doug, W. Autonomous oceanographic sampling network. Oceanography 1993, 6, 86–94. [Google Scholar]
- Bellingham, J.G.; Zhang, Y.; Godin, M.A. Autonomous Ocean Sampling Network-ii (aosn-ii): Integration and Demonstration of Observation and Modeling; Technical Report; Monterey Bay Aquarium Research Institute: Moss Landing, CA, USA, 2009. [Google Scholar]
- Ramp, S.R.; Davis, R.E.; Leonard, N.E.; Shulman, I.; Chao, Y.; Robinson, A.R.; Marsden, J.; Lermusiaux, P.; Fratantoni, D.M.; Paduan, J.D. Preparing to predict: The second autonomous ocean sampling network (aosn-ii) experiment in the monterey bay. Deep Sea Res. Part II Top. Stud. Oceanogr. 2009, 56, 68–86. [Google Scholar] [CrossRef]
- Barron, C.N.; Kara, A.B.; Martin, P.J.; Rhodes, R.C.; Smedstad, L.F. Formulation, implementation and examination of vertical coordinate choices in the global navy coastal ocean model (ncom). Ocean. Model. 2006, 11, 347–375. [Google Scholar] [CrossRef]
- Robinson, A.R. Physical processes, field estimation and an approach to interdisciplinary ocean modeling. Earth-Sci. Rev. 1996, 40, 3–54. [Google Scholar] [CrossRef]
- Lermusiaux, P. Adaptive modeling, adaptive data assimilation and adaptive sampling. Phys. D Nonlinear Phenom. 2007, 230, 172–196. [Google Scholar] [CrossRef]
- Heaney, K.D.; Lermusiaux, P.; Duda, T.F.; Haley, P.J. Validation of genetic algorithm-based optimal sampling for ocean data assimilation. Ocean Dyn. 2016, 66, 1209–1229. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.-F.; Liu, K. A novel particle swarm optimization algorithm for global optimization. Comput. Intell. Neurosci. 2016, 2016, 48. [Google Scholar] [CrossRef] [Green Version]
- Yilmaz, N.K.; Evangelinos, C.; Lermusiaux, P.; Patrikalakis, N.M. Path planning of autonomous underwater vehicles for adaptive sampling using mixed integer linear programming. IEEE J. Ocean. Eng. 2008, 33, 522–537. [Google Scholar] [CrossRef] [Green Version]
- Heaney, K.D.; Gawarkiewicz, G.; Duda, T.F.; Lermusiaux, P. Nonlinear optimization of autonomous undersea vehicle sampling strategies for oceanographic data-assimilation. J. Field Robot. 2010, 24, 437–448. [Google Scholar] [CrossRef] [Green Version]
- Lu, R.; Li, Y.C.; Li, Y.; Jiang, J.; Ding, Y. Multi-agent deep reinforcement learning based demand response for discrete manufacturing systems energy management. Appl. Energy 2020, 276, 115473. [Google Scholar] [CrossRef]
- Mynuddin, M.; Gao, W. Distributed predictive cruise control based on reinforcement learning and validation on microscopic traffic simulation. IET Intell. Transp. Syst. 2020, 14, 270–277. [Google Scholar] [CrossRef]
- Prrusquía, A.; Yu, W.; Li, X. Multi-agent reinforcement learning for redundant robot control in task-space. Int. J. Mach. Learn. Cybern. 2021, 12, 231–241. [Google Scholar] [CrossRef]
- Gao, Y.; Yang, J.J.; Yang, M.; Li, Z. Deep reinforcement learning based optimal schedule for a battery swapping station considering uncertainties. IEEE Trans. Ind. Appl. 2020, 56, 5775–5784. [Google Scholar] [CrossRef]
- Yang, Y.; Vamvoudakis, K.G.; Modares, H. Safe reinforcement learning for dynamical games. Int. J. Robust Nonlinear Control 2020, 30, 3706–3726. [Google Scholar] [CrossRef]
- Yan, C.; Xiang, X.; Wang, C. Towards real-time path planning through deep reinforcement learning for a uav in dynamic environments. J. Intell. Robot. Syst. 2020, 98, 297–309. [Google Scholar] [CrossRef]
- Wen, S.; Zhao, Y.; Yuan, X.; Wang, Z.; Manfredi, L. Path planning for active slam based on deep reinforcement learning under unknown environments. Intell. Serv. Robot. 2020, 13, 263–272. [Google Scholar] [CrossRef]
- Yao, Q.; Zheng, Z.; Qi, L.; Yuan, H.T.; Yang, T. Path planning method with improved artificial potential field—A reinforcement learning perspective. IEEE Access 2020, 8, 135513–135523. [Google Scholar] [CrossRef]
- Li, B.; Wu, Y. Path planning for uav ground target tracking via deep reinforcement learning. IEEE Access 2020, 8, 29064–29074. [Google Scholar] [CrossRef]
- Jiang, J.; Zeng, X.; Guzzetti, D.; You, Y. Path planning for asteroid hopping rovers with pre-trained deep reinforcement learning architectures. Acta Astronaut. 2020, 171, 265–279. [Google Scholar] [CrossRef]
- Wang, B.; Liu, Z.; Li, Q.; Prorok, A. Mobile robot path planning in dynamic environments through globally guided reinforcement learning. IEEE Robot. Autom. Lett. 2020, 5, 6932–6939. [Google Scholar] [CrossRef]
- Wei, Y.; Zheng, R. Informative path planning for mobile sensing with reinforcement learning. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020. [Google Scholar]
- Josef, S.; Degani, A. Deep reinforcement learning for safe local planning of a ground vehicle in unknown rough terrain. IEEE Robot. Autom. Lett. 2020, 5, 6748–6755. [Google Scholar] [CrossRef]
- Shchepetkin, A.F.; Mcwilliams, J.C. The regional oceanic modeling system (roms): A split-explicit, free-surface, topography-following-coordinate oceanic model. Ocean. Model. 2005, 9, 347–404. [Google Scholar] [CrossRef]
- Summerhayes, C. Technical tools for regional seas management: The role of the global ocean observing system (goos). Ocean Coast. Manag. 2002, 45, 777–796. [Google Scholar] [CrossRef]
- Surhone, L.M.; Tennoe, M.T.; Henssonow, S.F. Partially Observable Markov Decision Process. 2010. Available online: https://www.morebooks.de/shop-ui/shop/product/978-613-1-26000-1 (accessed on 15 November 2022).
- Ragi, S.; Chong, E.K.P. Uav path planning in a dynamic environment via partially observable markov decision process. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 2397–2412. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; Volume 9, p. 1054. [Google Scholar]
- Hasselt, H.V.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. Comput. Sci. 2016, 30. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Wang, Z.; Freitas, N.D.; Lanctot, M. Dueling network architectures for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning (ICML 2016), New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable mdps. Comput. Sci. 2015, arXiv:1507.06527. [Google Scholar] [CrossRef]
- Wang, X.; Gursoy, M.C.; Erpek, T.; Sagduyu, Y.E. Learning-based uav path planning for data collection with integrated collision avoidance. IEEE Internet Things J. 2022, 9, 16663–16676. [Google Scholar] [CrossRef]
- Jahrer, Preparing Continuous Features for Neural Networks with Gaussrank. Available online: http://fastml.com/preparing-continuous-features-for-neural-networks-with-rankgauss/ (accessed on 22 January 2018).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| minibatch size | 64 |
| episodes | 10,000 |
| replay memory size | 20,000 |
| memory warmup size | 200 |
| discount factor | 0.99 |
| action repeat | 1 |
| learning rate | 0.0005 |
| min squared gradient | 0.01 |
| initial exploration | 1 |
| final exploration | 0.1 |
| 0.005 | |
| tau | 0.003 |
| Parameter | Value |
|---|---|
| observation area | Long:124 E–129 E; Lat:16 N–21 N |
| resolution ratio | 1/10 |
| time interval | 6 h |
| experiment days | 5 days |
| experiment season | spring; summer; autumn; winter |
| number of groups | 100 |
| Platform | D3RQN | DRQN | D3QN | DQN | Random |
|---|---|---|---|---|---|
| 0.17258 | 0.17409 | 0.17784 | 0.17439 | 0.18681 | |
| 0.16775 | 0.16895 | 0.17042 | 0.17025 | 0.18360 | |
| 0.15901 | 0.15923 | 0.16750 | 0.15948 | 0.18324 | |
| 0.15963 | 0.16055 | 0.16236 | 0.16155 | 0.18913 | |
| 0.16209 | 0.16264 | 0.16738 | 0.16508 | 0.18398 | |
| 0.16502 | 0.16517 | 0.16860 | 0.16567 | 0.18305 |
| Platform | D3RQN | DRQN | D3QN | DQN | Random |
|---|---|---|---|---|---|
| 0.17980 | 0.18005 | 0.18539 | 0.18201 | 0.18681 | |
| 0.17327 | 0.17832 | 0.17796 | 0.17851 | 0.18360 | |
| 0.16496 | 0.16558 | 0.16966 | 0.17673 | 0.18324 | |
| 0.16852 | 0.16889 | 0.17797 | 0.17182 | 0.18913 | |
| 0.17289 | 0.17291 | 0.17729 | 0.17367 | 0.18398 | |
| 0.16838 | 0.16950 | 0.16901 | 0.17277 | 0.18305 |
| Platform | D3RQN | DRQN | D3QN | DQN | Random |
|---|---|---|---|---|---|
| 0.17746 | 0.17928 | 0.18513 | 0.17938 | 0.18681 | |
| 0.17041 | 0.17151 | 0.17368 | 0.17273 | 0.18360 | |
| 0.16129 | 0.16182 | 0.16273 | 0.16183 | 0.18324 | |
| 0.16242 | 0.16653 | 0.16904 | 0.16728 | 0.18913 | |
| 0.16571 | 0.17023 | 0.17142 | 0.17213 | 0.18398 | |
| 0.16649 | 0.16683 | 0.16790 | 0.16793 | 0.18305 |
| Platform | D3RQN | DRQN | D3QN | DQN | Random |
|---|---|---|---|---|---|
| 0.16539 | 0.16875 | 0.16774 | 0.16952 | 0.18681 | |
| 0.16698 | 0.17685 | 0.16928 | 0.17775 | 0.18360 | |
| 0.15142 | 0.15664 | 0.17062 | 0.15804 | 0.18913 | |
| 0.15636 | 0.15689 | 0.16629 | 0.15815 | 0.18324 | |
| 0.15656 | 0.15788 | 0.16744 | 0.16217 | 0.18398 | |
| 0.16341 | 0.16433 | 0.17071 | 0.16482 | 0.18305 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Liu, Y.; Deng, X. Optimization of a Regional Marine Environment Mobile Observation Network Based on Deep Reinforcement Learning. J. Mar. Sci. Eng. 2023, 11, 208. https://0-doi-org.brum.beds.ac.uk/10.3390/jmse11010208
Zhao Y, Liu Y, Deng X. Optimization of a Regional Marine Environment Mobile Observation Network Based on Deep Reinforcement Learning. Journal of Marine Science and Engineering. 2023; 11(1):208. https://0-doi-org.brum.beds.ac.uk/10.3390/jmse11010208
Chicago/Turabian StyleZhao, Yuxin, Yanlong Liu, and Xiong Deng. 2023. "Optimization of a Regional Marine Environment Mobile Observation Network Based on Deep Reinforcement Learning" Journal of Marine Science and Engineering 11, no. 1: 208. https://0-doi-org.brum.beds.ac.uk/10.3390/jmse11010208