
A Comparison of Deep Learning Methods for Timbre Analysis in Polyphonic Automatic Music Transcription



Abstract
:1. Introduction
1.1. Frame-Level Transcription
1.2. Frame-Level and Note-Level Transcription in Polyphonic Music
1.3. Stream-Level Transcription
1.4. Notation-Level
2. Methods
2.1. Method 1: Monophonic Note-Level Transcription
Note Tracking (NT) Algorithm
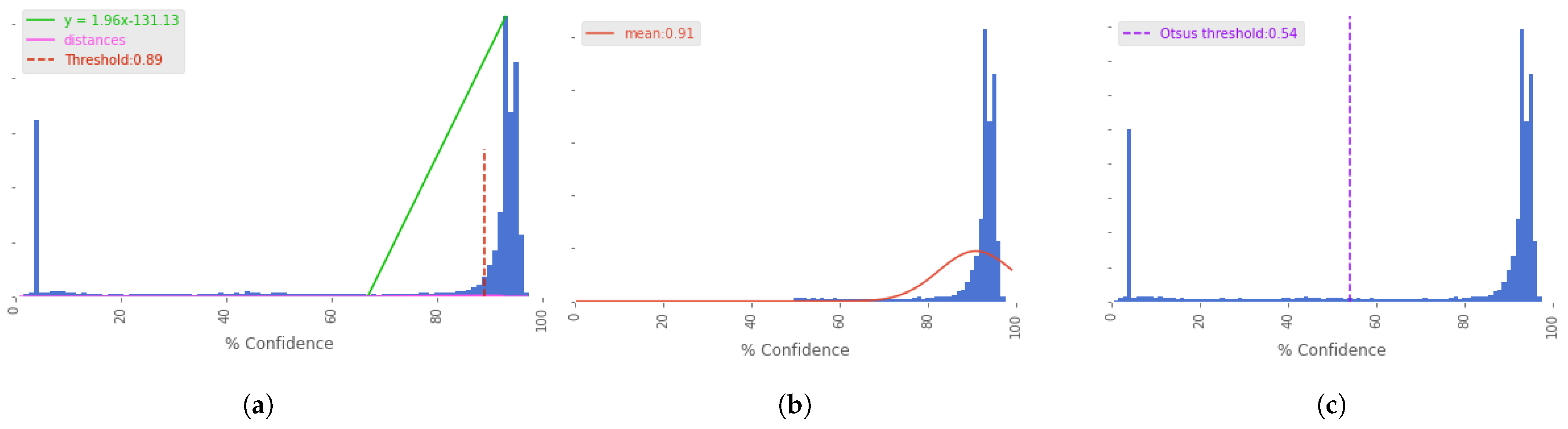
- Triangulation algorithm. To perform the triangulation algorithm we calculate the maximum value of the histogram to its right (close to one) and the nearest minimum value to the maximum at its left. Then, we obtain the line that passes through this maximum and minimum values and we compute the distance from each point of the histogram between the minimum and maximum values to the line. The optimum threshold is equal to the minimum confidence value. This value is the one that maximizes the distance from the histogram points to the line.
- Gaussian distribution. This approach is based on fitting the right part of the histogram (confidences from 0.5 to 1) built from the CREPE output with a gaussian distribution and taking the mean as the minimum confidence value.
- Otsu’s threshold [24]. This method is most often used by the image processing community to perform image thresholding. In these applications the algorithm returns a threshold which separates two classes of pixels by computing the histogram built with the pixel distributions. Here, we use this method to predict the minimum confidence value by taking the minimum confidence histogram of CREPE’s output.
| Algorithm 1: Tracking algorithm. |
 |
2.2. Method 2: Polyphonic Note-Level Transcription
3. Experiments and Results
3.1. Datasets
3.2. Evaluation Metrics
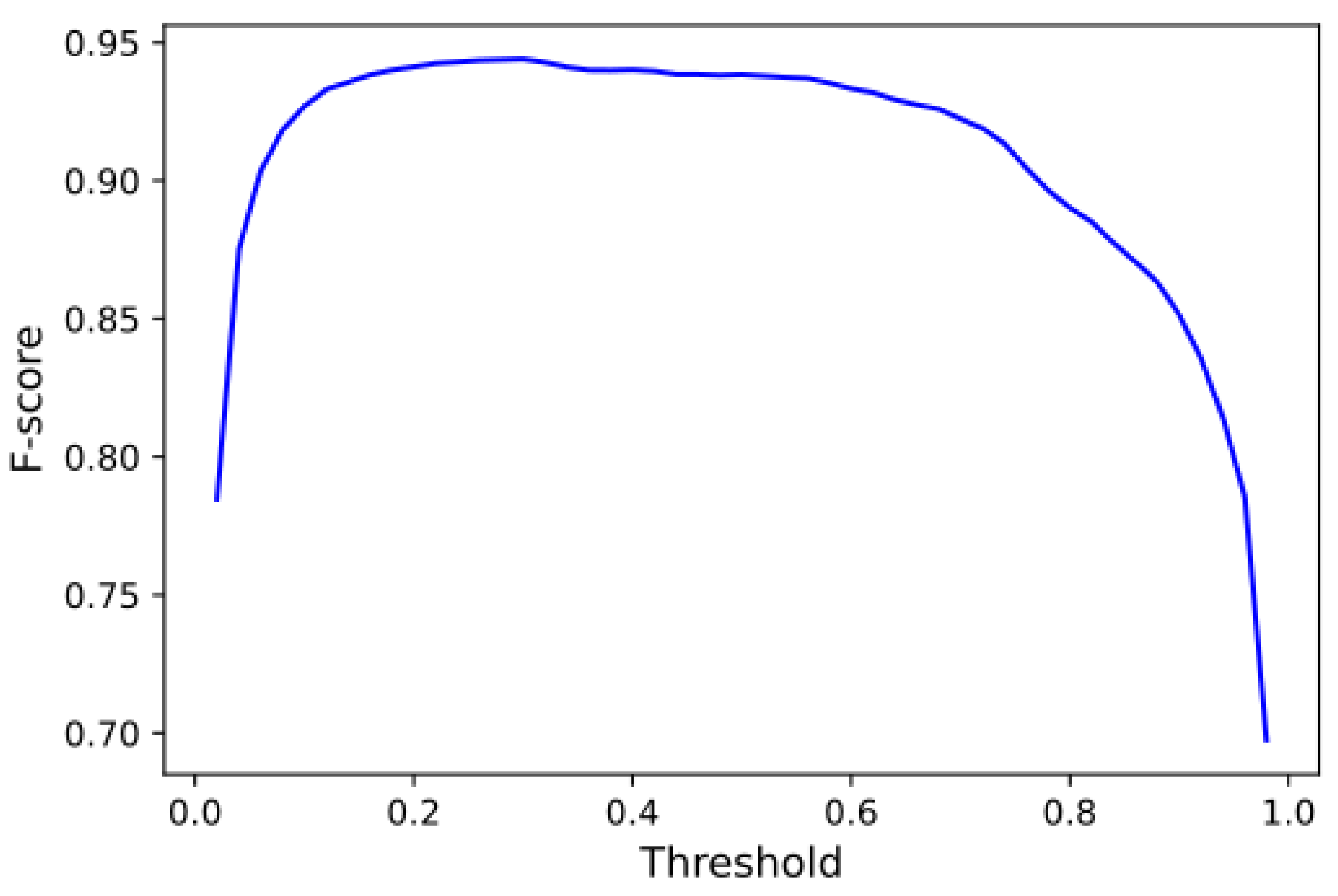
3.2.1. Method 1: Monophonic Note-Level Transcription
3.2.2. Method 2: Polyphonic Note-Level Transcription
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Klapuri, A.; Davy, M. Signal Processing Methods for Music Transcription; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Benetos, E.; Dixon, S.; Giannoulis, D.; Kirchhoff, H.; Klapuri, A. Automatic music transcription: Challenges and future directions. J. Intell. Inf. Syst. 2013, 41, 407–434. [Google Scholar] [CrossRef] [Green Version]
- Benetos, E.; Dixon, S.; Duan, Z.; Ewert, S. Automatic Music Transcription: An Overview. IEEE Signal Process. Mag. 2019, 36, 20–30. [Google Scholar] [CrossRef]
- Hawthorne, C.; Elsen, E.; Song, J.; Roberts, A.; Simon, I.; Raffel, C.; Engel, J.; Oore, S.; Eck, D. Onsets and Frames: Dual-Objective Piano Transcription. In Proceedings of the 19th International Society for Music Information Retrieval Conference, Paris, France, 23–27 September 2018; pp. 50–57. [Google Scholar]
- Cheuk, K.W.; Luo, Y.; Benetos, E.; Herremans, D. The Effect of Spectrogram Reconstruction on Automatic Music Transcription: An Alternative Approach to Improve Transcription Accuracy. arXiv 2020, arXiv:2010.09969. [Google Scholar]
- Manilow, E.; Seetharaman, P.; Pardo, B. Simultaneous Separation and Transcription of Mixtures with Multiple Polyphonic and Percussive Instruments. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, 4–8 May 2020; pp. 771–775. [Google Scholar]
- Wu, Y.; Chen, B.; Su, L. Multi-Instrument Automatic Music Transcription With Self-Attention-Based Instance Segmentation. IEEE ACM Trans. Audio Speech Lang. Process. 2020, 28, 2796–2809. [Google Scholar] [CrossRef]
- Camacho, A.; Harris, J.G. A sawtooth waveform inspired pitch estimator for speech and music. J. Acoust. Soc. Am. 2008, 124, 1638–1652. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Cheveigné, A.; Kawahara, H. YIN, a fundamental frequency estimator for speech and music. J. Acoust. Soc. Am. 2002, 111, 1917–1930. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mauch, M.; Dixon, S. PYIN: A fundamental frequency estimator using probabilistic threshold distributions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2014, Florence, Italy, 4–9 May 2014; pp. 659–663. [Google Scholar]
- Salamon, J.; Gómez, E. Melody Extraction From Polyphonic Music Signals Using Pitch Contour Characteristics. IEEE Trans. Speech Audio Process. 2012, 20, 1759–1770. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.W.; Salamon, J.; Li, P.; Bello, J.P. Crepe: A Convolutional Representation for Pitch Estimation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, 15–20 April 2018; pp. 161–165. [Google Scholar]
- Duan, Z.; Pardo, B.; Zhang, C. Multiple Fundamental Frequency Estimation by Modeling Spectral Peaks and Non-Peak Regions. IEEE Trans. Speech Audio Process. 2010, 18, 2121–2133. [Google Scholar] [CrossRef]
- Bittner, R.M.; McFee, B.; Salamon, J.; Li, P.; Bello, J.P. Deep Salience Representations for F0 Estimation in Polyphonic Music. In Proceedings of the 18th International Society for Music Information Retrieval Conference, ISMIR 2017, Suzhou, China, 23–27 October 2017; pp. 63–70. [Google Scholar]
- Böck, S.; Schedl, M. Polyphonic piano note transcription with recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2012, Kyoto, Japan, 25–30 March 2012; pp. 121–124. [Google Scholar]
- Sigtia, S.; Benetos, E.; Dixon, S. An End-to-End Neural Network for Polyphonic Piano Music Transcription. IEEE ACM Trans. Audio Speech Lang. Process. 2016, 24, 927–939. [Google Scholar] [CrossRef] [Green Version]
- Hawthorne, C.; Stasyuk, A.; Roberts, A.; Simon, I.; Huang, C.A.; Dieleman, S.; Elsen, E.; Engel, J.H.; Eck, D. Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Callender, L.; Hawthorne, C.; Engel, J.H. Improving Perceptual Quality of Drum Transcription with the Expanded Groove MIDI Dataset. arXiv 2020, arXiv:2004.00188. [Google Scholar]
- Cheuk, K.W.; Agres, K.; Herremans, D. The Impact of Audio Input Representations on Neural Network based Music Transcription. In Proceedings of the International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, UK, 19–24 July 2020; pp. 1–6. [Google Scholar]
- Pedersoli, F.; Tzanetakis, G.; Yi, K.M. Improving Music Transcription by Pre-Stacking A U-Net. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, 4–8 May 2020; pp. 506–510. [Google Scholar]
- Grohganz, H.; Clausen, M.; Müller, M. Estimating Musical Time Information from Performed MIDI Files. In Proceedings of the 15th International Society for Music Information Retrieval Conference, ISMIR 2014, Taipei, Taiwan, 27–31 October 2014; pp. 35–40. [Google Scholar]
- Carvalho, R.G.C.; Smaragdis, P. Towards end-to-end polyphonic music transcription: Transforming music audio directly to a score. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, WASPAA 2017, New Paltz, NY, USA, 15–18 October 2017; pp. 151–155. [Google Scholar]
- Hantrakul, L.; Engel, J.H.; Roberts, A.; Gu, C. Fast and Flexible Neural Audio Synthesis. In Proceedings of the 20th International Society for Music Information Retrieval Conference, ISMIR 2019, Delft, The Netherlands, 4–8 November 2019; pp. 524–530. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Hsu, C.; Jang, J.R. On the Improvement of Singing Voice Separation for Monaural Recordings Using the MIR-1K Dataset. IEEE Trans. Speech Audio Process. 2010, 18, 310–319. [Google Scholar]
- Bittner, R.M.; Salamon, J.; Tierney, M.; Mauch, M.; Cannam, C.; Bello, J.P. MedleyDB: A Multitrack Dataset for Annotation-Intensive MIR Research. In Proceedings of the 15th International Society for Music Information Retrieval Conference, ISMIR 2014, Taipei, Taiwan, 27–31 October 2014; pp. 155–160. [Google Scholar]
- Salamon, J.; Bittner, R.M.; Bonada, J.; Bosch, J.J.; Gómez, E.; Bello, J.P. An Analysis/Synthesis Framework for Automatic F0 Annotation of Multitrack Datasets. In Proceedings of the 18th International Society for Music Information Retrieval Conference, ISMIR 2017, Suzhou, China, 23–27 October 2017; pp. 71–78. [Google Scholar]
- Engel, J.H.; Resnick, C.; Roberts, A.; Dieleman, S.; Norouzi, M.; Eck, D.; Simonyan, K. Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; pp. 1068–1077. [Google Scholar]
- Manilow, E.; Wichern, G.; Seetharaman, P.; Roux, J.L. Cutting Music Source Separation Some Slakh: A Dataset to Study the Impact of Training Data Quality and Quantity. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, WASPAA 2019, New Paltz, NY, USA, 20–23 October 2019; pp. 45–49. [Google Scholar]
- Raffel, C.; McFee, B.; Humphrey, E.J.; Salamon, J.; Nieto, O.; Liang, D.; Ellis, D.P.W. MIR_EVAL: A Transparent Implementation of Common MIR Metrics. In Proceedings of the 15th International Society for Music Information Retrieval Conference, ISMIR 2014, Taipei, Taiwan, 27–31 October 2014; pp. 367–372. [Google Scholar]
- Bay, M.; Ehmann, A.F.; Downie, J.S. Evaluation of Multiple-F0 Estimation and Tracking Systems. In Proceedings of the 10th International Society for Music Information Retrieval Conference, ISMIR 2009, Kobe International Conference Center, Kobe, Japan, 26–30 October 2009; pp. 315–320. [Google Scholar]
- Bosch, J.J.; Marxer, R.; Gómez, E. Evaluation and combination of pitch estimation methods for melody extraction in symphonic classical music. J. New Music. Res. 2016, 45, 101–117. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instrument | Train | Validation | Test |
|---|---|---|---|
| Total | 12782 | 3198 | 1893 |
| Piano | 2458 | 634 | 380 |
| Bass | 1578 | 374 | 233 |
| Guitar | 3831 | 991 | 569 |
| Strings | 2381 | 142 | 86 |
| Reed | 550 | 600 | 345 |
| Brass | 627 | 134 | 92 |
| Chromatic Precussion | 317 | 130 | 85 |
| Flute | 514 | 67 | 42 |
| Organ | 526 | 126 | 61 |
| Test Dataset | Instrument | CA | Accuracy | R | P | F |
|---|---|---|---|---|---|---|
| Slakh2100 | Piano | 80.42 | 78.83 | 88.39 | 88.16 | 87.28 |
| Bass | 85.78 | 76.08 | 83.14 | 84.66 | 83.36 | |
| Guitar | 70.85 | 67.50 | 80.07 | 80.34 | 78.67 | |
| Strings | 82.94 | 82.01 | 85.68 | 91.96 | 87.96 | |
| Reed | 75.88 | 75.42 | 82.46 | 88.24 | 84.67 | |
| Brass | 72.55 | 50.66 | 54.72 | 65.61 | 58.44 | |
| Chromatic Percussion | 21.15 | 15.05 | 21.44 | 30.75 | 23.82 | |
| Pipe | 78.80 | 77.04 | 84.95 | 88.27 | 86.49 | |
| Organ | 68.43 | 55.32 | 70.84 | 65.60 | 67.00 | |
| Bach10 | Bach10single | 82.37 | 70.86 | 84.06 | 81.00 | 82.48 |
| Bach10multi | 69.71 | 67.39 | 73.93 | 88.39 | 80.47 | |
| MedleyDB | All | 51.89 | 47.18 | 68.73 | 56.89 | 61.01 |
| Instrument | Threshold | Note without Offset | Note with Offset | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| Piano (CNN) | 0.44 | 65.42 | 78.72 | 67.07 | 30.91 | 39.06 | 33.45 |
| Piano (CREPE + NT) | Gaussian | 39.01 | 26.77 | 30.00 | 19.39 | 13.94 | 15.34 |
| Piano (OaF [4]) | - | 88.47 | 94.73 | 90.68 | 58.48 | 63.93 | 60.49 |
| Bass (CNN) | 0.44 | 68.65 | 85.96 | 74.81 | 53.87 | 65.02 | 57.48 |
| Bass (CREPE + NT) | Otsu | 48.18 | 68.06 | 55.75 | 44.22 | 62.32 | 51.12 |
| Bass (OaF [4]) | - | 65.98 | 78.52 | 71.02 | 62.39 | 73.85 | 66.94 |
| Guitar (CNN) | 0.44 | 55.36 | 73.25 | 59.73 | 36.77 | 45.85 | 40.19 |
| Guitar (CREPE + NT) | Otsu | 28.19 | 43.21 | 31.68 | 14.08 | 23.10 | 16.81 |
| Guitar (OaF [4]) | - | 55.20 | 84.95 | 64.32 | 39.92 | 60.63 | 46.43 |
| Strings (CNN) | 0.44 | 34.24 | 62.32 | 41.70 | 17.91 | 26.27 | 20.29 |
| Strings (CREPE + NT) | Otsu | 3.54 | 8.12 | 4.56 | 13.06 | 29.77 | 16.31 |
| Strings (OaF [4]) | - | 40.16 | 81.03 | 48.88 | 15.78 | 30.25 | 19.72 |
| Reed (CNN) | 0.44 | 66.12 | 75.84 | 69.23 | 51.76 | 57.68 | 53.57 |
| Reed (CREPE + NT) | Otsu | 24.87 | 38.16 | 28.54 | 9.63 | 14.70 | 11.12 |
| Reed (OaF [4]) | - | 42.91 | 75.69 | 52.95 | 24.99 | 43.91 | 30.91 |
| Brass (CNN) | 0.44 | 49.32 | 58.64 | 49.98 | 39.35 | 41.52 | 39.25 |
| Brass (CREPE + NT) | - | 30.17 | 40.12 | 32.15 | 10.75 | 14.34 | 11.79 |
| Brass (OaF [4]) | - | 45.11 | 68.53 | 48.99 | 37.28 | 52.42 | 39.59 |
| Chromatic Perc. (CNN) | 0.44 | 25.77 | 26.07 | 22.97 | 4.99 | 3.98 | 4.04 |
| Chromatic Perc. (CREPE + NT) | Triang. | 26.40 | 26.28 | 23.44 | 13.24 | 13.30 | 11.82 |
| Chromatic Perc. (OaF [4]) | - | 50.31 | 68.79 | 56.27 | 7.84 | 11.38 | 9.11 |
| Pipe (CNN) | 0.44 | 45.55 | 53.51 | 47.86 | 30.89 | 34.36 | 31.88 |
| Pipe (CREPE + NT) | Otsu | 13.30 | 15.60 | 12.64 | 4.58 | 4.38 | 3.71 |
| Pipe (OaF [4]) | - | 20.66 | 59.56 | 29.40 | 4.35 | 11.25 | 6.00 |
| Organ (CNN) | 0.44 | 19.58 | 54.47 | 25.31 | 9.77 | 19.01 | 11.39 |
| Organ (CREPE + NT) | Gaussian | 35.85 | 25.84 | 27.31 | 29.60 | 20.59 | 22.22 |
| Organ (OaF [4]) | - | 20.59 | 57.47 | 27.67 | 15.92 | 30.61 | 19.98 |
| Instrument | Threshold | Test Dataset | Note without Offset | Note with Offset | ||||
|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | |||
| Bass (CNN) | 0.407 | Slakh2100 | 92.91 | 90.78 | 91.54 | 85.54 | 85.41 | 84.99 |
| Bass (OaF [4]) | - | Slakh2100 | 65.98 | 78.52 | 71.02 | 62.39 | 73.85 | 66.94 |
| Brass (CNN) | 0.416 | Slakh2100 | 57.26 | 76.05 | 61.07 | 42.76 | 50.32 | 44.10 |
| Brass (OaF [4]) | - | Slakh2100 | 45.11 | 68.53 | 48.99 | 37.28 | 52.42 | 39.59 |
| Reed (CNN) | 0.302 | Slakh2100 | 76.34 | 84.26 | 79.02 | 61.12 | 65.12 | 62.31 |
| Reed (OaF [4]) | - | Slakh2100 | 42.91 | 75.69 | 52.95 | 24.99 | 43.91 | 30.91 |
| Pipe (CNN) | 0.334 | Slakh2100 | 64.98 | 74.47 | 66.58 | 48.20 | 51.78 | 48.02 |
| Pipe (OaF [4]) | - | Slakh2100 | 20.66 | 59.56 | 29.40 | 4.35 | 11.25 | 6.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez-Olivan, C.; Zay Pinilla, I.; Hernandez-Lopez, C.; Beltran, J.R. A Comparison of Deep Learning Methods for Timbre Analysis in Polyphonic Automatic Music Transcription. Electronics 2021, 10, 810. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10070810
Hernandez-Olivan C, Zay Pinilla I, Hernandez-Lopez C, Beltran JR. A Comparison of Deep Learning Methods for Timbre Analysis in Polyphonic Automatic Music Transcription. Electronics. 2021; 10(7):810. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10070810
Chicago/Turabian StyleHernandez-Olivan, Carlos, Ignacio Zay Pinilla, Carlos Hernandez-Lopez, and Jose R. Beltran. 2021. "A Comparison of Deep Learning Methods for Timbre Analysis in Polyphonic Automatic Music Transcription" Electronics 10, no. 7: 810. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10070810