
Low-Light Image Enhancement with an Anti-Attention Block-Based Generative Adversarial Network


1
School of Electronic and Information Engineering, Liaoning Technical University, Fuxin 123032, China
2
School of Information Science and Engineering, Linyi University, Linyi 276000, China
3
School of Computer Science and Technology, Shandong University of Finance and Economics, Jinan 250014, China
*
Authors to whom correspondence should be addressed.
Electronics 2022, 11(10), 1627; https://0-doi-org.brum.beds.ac.uk/10.3390/electronics11101627
Submission received: 19 April 2022
/
Revised: 12 May 2022
/
Accepted: 17 May 2022
/
Published: 19 May 2022
(This article belongs to the Special Issue Deep Learning for Computer Vision)
Abstract
:High-quality images are difficult to obtain in complex environments, such as underground or underwater. The low performance of images that are captured under low-light conditions significantly restricts the development of various engineering applications. However, existing algorithms exhibit color distortion or under/overexposure when addressing non-uniform illumination images. Furthermore, they introduce high-level noise when processing extremely dark images. In this paper, we propose a novel generative adversarial network (GAN) structure to generate high-quality enhanced images, which is called anti-attention block (AAB)-based generative adversarial networks (AABGAN). Specifically, we propose AAB to suppress undesired chromatic aberrations and establish a mapping relationship between different channels. The deep aggregation pyramid pooling module guides the network when combining multi-scale context information. Furthermore, we design a new multiple loss function to adjust images to the most suitable range for human vision. The results of extensive experiments show that our method outperforms state-of-the-art unsupervised image enhancement methods in terms of noise reduction and has a well-perceived result.
1. Introduction
The underground and underwater environment, which is often illuminated by strong searchlights, has low-light conditions and multiple interferences [1,2]. Thus, high-quality images are difficult to obtain, thus limiting the development of downstream tasks (e.g., coal image segmentation, coal mine video monitoring, underwater rescue, and detecting underwater pipeline leaks). However, in cases where strong searchlights are used, overexposure within the lighting range and underexposure outside the lighting range still occur. In fact, not all pixels in the image have insufficient illumination, and thus focus must be on the overexposed and unexposed areas of an image.
There are three main problems to be solved for low-light image enhancement. First, low-light image enhancement is different from super-resolution [3] or image restoration [4], which has ground truth as a reference comparison. The image should be as close to the ground truth as possible. There is no unique or well-defined highlight ground truth that offers the best result for enhanced images. Second, images taken under dark conditions have a lot of natural noise, which impedes satisfactory results when using the existing depth learning methods. Third, the enhanced hue and color saturation deviate from the real object. The earliest methods of low-light image enhancement were aimed at evenly adjusting light intensity, which can lead easily to overexposure or underexposure. (e.g., Retinex algorithm [5] and LIME [6]). Hence, they failed to achieve satisfactory performance in complex environments. Most existing deep learning methods for solving low-light environment problems rely on pairs of training images. (e.g., RetinexNet [7]). Some of the enhanced images used for training were obtained from normal low-light images, which lead to half of the training data being synthetic images; thus, the model always produces various artifacts when it is applied to real low-light images.
In practical application, this will affect the efficiency of video surveillance, visual detection, and automatic recognition of coal and underwater images. Unsupervised learning is mainly employed to solve this problem. The significant advantage of unsupervised learning is that compared with other methods, it does not require a pair of training datasets to train the model [8]. The need for paired datasets to train images introduces a difficulty: that is, capturing both a low-light image and ground truth image in the same visual scene simultaneously is quite difficult or even impractical, especially in a complex environment, which is affected by many insurmountable factors. Inspired by this, in this study, we used a generative adversarial network GAN [9] model to establish the mapping relationship between unpaired images. This structure allows us to remove the dependence on paired training datasets and to add unpaired real environment images to train the model.
In this study, we propose several innovative techniques. First, we choose a more complex network structure on the GAN generator. Based on U-net [10], we add an anti-attention block (AAB) to our generator. AAB makes the network deeper, learns features in more detail, and focuses more on the dark parts of the picture. Second, we join the DAPPM [11] block, which increases the transmission of the information at different scales. Finally, we design multiple loss functions. The exposure consistency loss function is added to restrain under/overexposed regions. It also adjusts to well-visual image exposure and gives more weight to dark areas. The color consistency loss function is added to minimize color deviations. The space consistency loss function is added to enhance spatial coherence.
We contribute an unpaired real coal low-light image enhancement dataset for evaluation, which we call the RCL dataset. The RCL dataset comes from the coal mine environment. A comparative experiment on the RCL dataset is shown in Figure 1. To further demonstrate the superiority of our method, we also evaluate the performance of our proposed method on the MUED [12] and LOL [7] datasets. We compare our method with the state-of-the-art low-light enhancement methods on these datasets. Extensive experimental results show that our method provides better visual presentation and lower noise levels compared with other methods.
Our contributions are threefold:
1. We propose an anti-attention block-based generative adversarial network (AABGAN) structure to obtain normally exposed high-quality and noise-free coal images.
2. We design a multiple-loss function for the coal low-light images. Hence, our method has good performance in complex coal mining environment conditions.
3. We evaluate our method on the RCL dataset, MUED dataset, and LOL dataset, and the experimental results demonstrate that our method achieves state-of-the-art performance.
2. Related Work
Many low-light image enhancement schemes have been proposed, and coal image processing and underwater image processing have been extensively studied. We discuss related work in this section.
2.1. Traditional Approaches
The traditional low-light image enhancement methods often led to underexposed and overexposed and color distortion problems. Thus, the traditional approaches produce unrealistic images in local exposure conditions. In this approach, an adaptive histogram equalization [13] (AHE) is used to obtain histograms of multiple local regions of the image and redistributes the brightness to change the image contrast. However, over-amplification of noise in uniform local areas of the image is a problem. Contrast-constrained adaptive histogram equalization [14] is based on AHE. It restricts the histogram of each sub-block and controls the noise brought by AHE. Retinex [5] can enhance the brightness information of the image and remove part of the shadow in the image. LIME [6] finds maximum values in R, G, and B channels to estimate individual illumination for each pixel; however, the enhanced image has unqualified color consistency. BPDHE [15] uses a one-dimensional Gaussian filter to smooth the input histogram and dynamically save the image bright. Hence, it obtains better visual quality; DHECE [16] introduces and uses a differential gray histogram. These traditional approaches have proven to have many limitations mainly because they neither achieve satisfactory performance nor enhance complex lighting images.
2.2. Deep Learning Approaches
Deep learning has brought significant advances to many computer vision field tasks as compared to the traditional approach. LL-NET [17] proposes a cascading auto encoder that simultaneously enhances the contrast and the denoising module. RetinexNet [7] is based on the Retinex algorithm. It adopts three steps: image decomposition, brightness adjustment, and image reconstruction to obtain a well-perceived result. MSR [18] provides an end-to-end framework to learn a mapping between low-light images and bright images. Kind [19] proposes a network architecture, including layer decomposition, reflectance restoration, and illumination adjustment. Zhang et al. [20] were inspired by information entropy theory and the Retinex model, proposing a self-supervised learning method based on the maximum entropy Retinex model. Zero-DCE [21] proposed to train a curve that automatically adjusts image brightness, thereby formulating the image enhancement as a curve estimation task. EnlightenGAN [22] adopted the idea of GAN [9] and refers to the model structure of Pix2pix [23], where the authors proposed a single path GAN structure without pair training but with lightweight for training. In general, deep learning approaches have achieved better results than traditional approaches. Nevertheless, most deep learning solutions rely on pairs of training images, which is difficult to obtain from an engineering application environment.
2.3. Coal Image Processing and Underwater Image Processing
The environment of engineering applications space is complex; thus, such an environment is usually affected by coal dust, high noise, and electromagnetic interference. Zhang et al. [24] used low-light infrared imaging to solve the image acquisition problem. Wang et al. [2] proposed a mined image enhancement algorithm based on non-subsampled contour transform, which addresses the deficiency of conventional image enhancement algorithms that cannot care for both contrast enhancement and noise suppression.
Underwater images have low illumination and color deviation because of the attenuation and scattering of light in water. To solve this problem, DDUIE [25] was used for contrast stretching in the approximate frequency band of discrete wavelet transform. Thereafter, it was used to convert an image to HSV (Hue, Saturation and Value) channel to further improve the image color quality. Li et al. [26] proposed an end-to-end network structure including a nonparametric layer for preliminary color correction and an adaptive thinning parameter layer.
Existing methods usually adopt traditional approaches and still have high-level noise and color distortion. The results from these methods are far less than the human visual needs and can hardly be used for practical application conditions. This study will focus on adopting deep learning approaches with the unpaired training dataset. To better complete the enhancement of low-light images, our model is trained by considering specially defined multiple loss functions. This strategy allows the output images to be evaluated and adjusted professionally.
3. Model
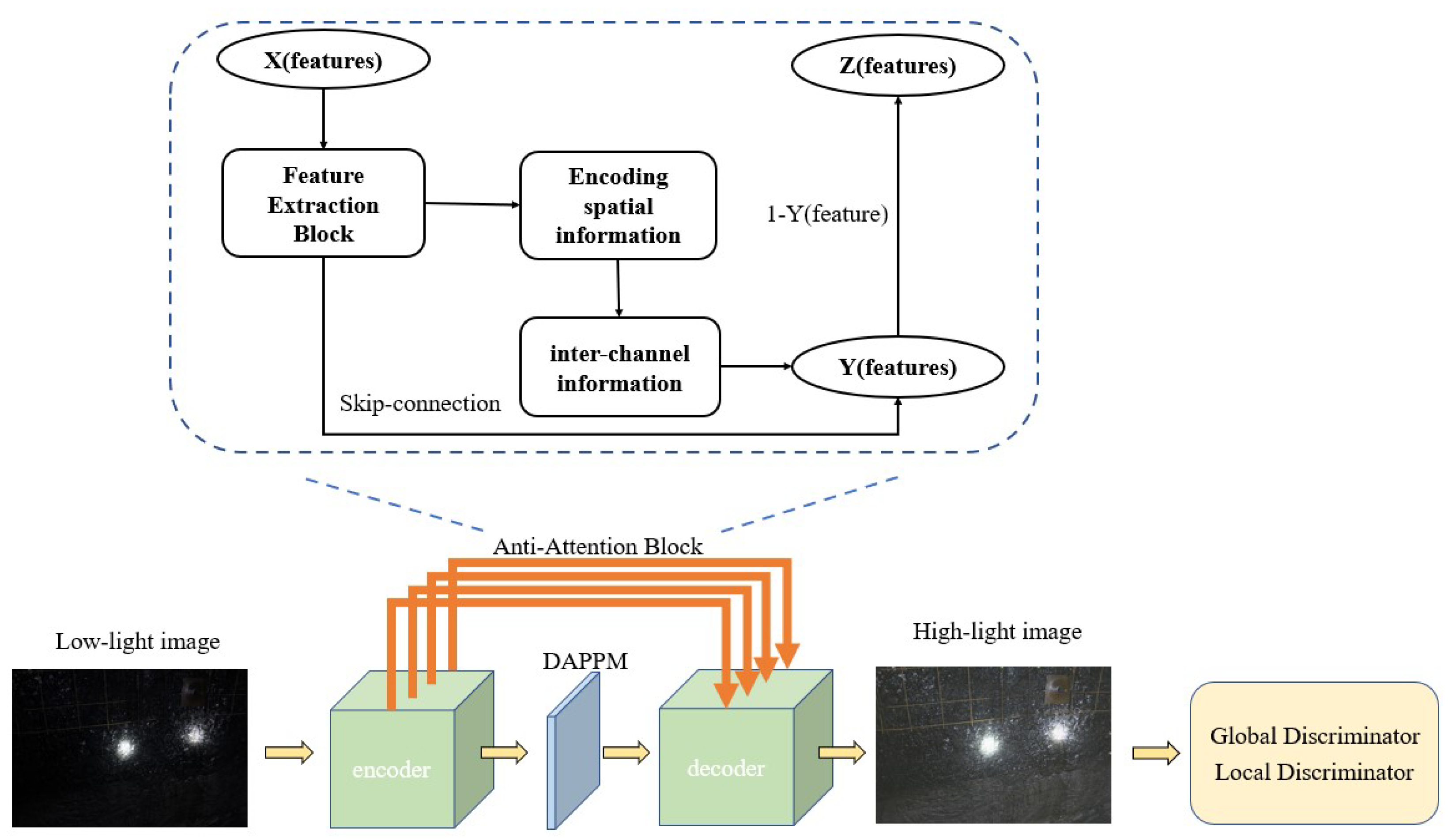
Image enhancement in the low-light condition is a complicated problem. Traditional methods have difficulty eliminating the problems of less vivid color, unnatural visual effects, and high noise levels. Thus, in this paper, we propose a model structure of GAN’s generator in Figure 2. Our model has good visual performance and a low noise level. In this section, we first introduce the structure of the model and then the loss function.
3.1. Anti-Attention Block
In the generator, using AAB to solve the enhanced image problem is unrealistic. In practice, we have found that the dark parts of images have natural noise and poor visual performance. This reduces the image quality after enhancement and brings visual problems (e.g., images underexposure, details missing, or color distortion). AAB is designed to focus and enhance the unattractive parts of the original image. A shallow network does not have enough details of the local features. However, simply increasing the depth of the network leads to critical vanishing and exploding gradient problems. Thus, a residual network has been widely used in many fields and has achieved enormous success. We added the residual structure [27] to our AAB to increase the visual performance and learn more details of the image features. In image enhancement, we found that the feature map of each channel has different contributions to the following network. AAB can obtain the importance of each feature channel as the basis for paying attention to useful information and suppressing useless information. The specific structure is shown in Figure 3. First, the feature extraction structure was used to extract global features and gradient information. Then, like Coordinate Attention Blocks [28], the two global average pooling are set to encode spatial information in one-dimensional horizontal global pooling and one-dimensional vertical global pooling, which are beneficial to remove the color artifacts. We concatenate two representative values and use the 1 × 1 convolution layer to transform the dimension. Through the BatchNorm layer and nonlinear function, the intermediate feature mapping is split into two separate tensors along the spatial dimension. Thereafter, by using the 1 × 1 convolution layer, AAB could change the number of channels. Two sigmoid activation functions follow the convolution layers to reduce the computation. The feature map Y is sent to the next layer of the encoder. To focus on dark places in the images, the feature map Y through 1-Y element-wise subtraction operation obtains feature Z, which is transmitted to the corresponding layer decoder. The proposed AAB is proved to be effective, as discussed in Section 4. The AAB suppresses the invalid information and highlights the beneficial color information.
3.2. U-Net Network Architecture
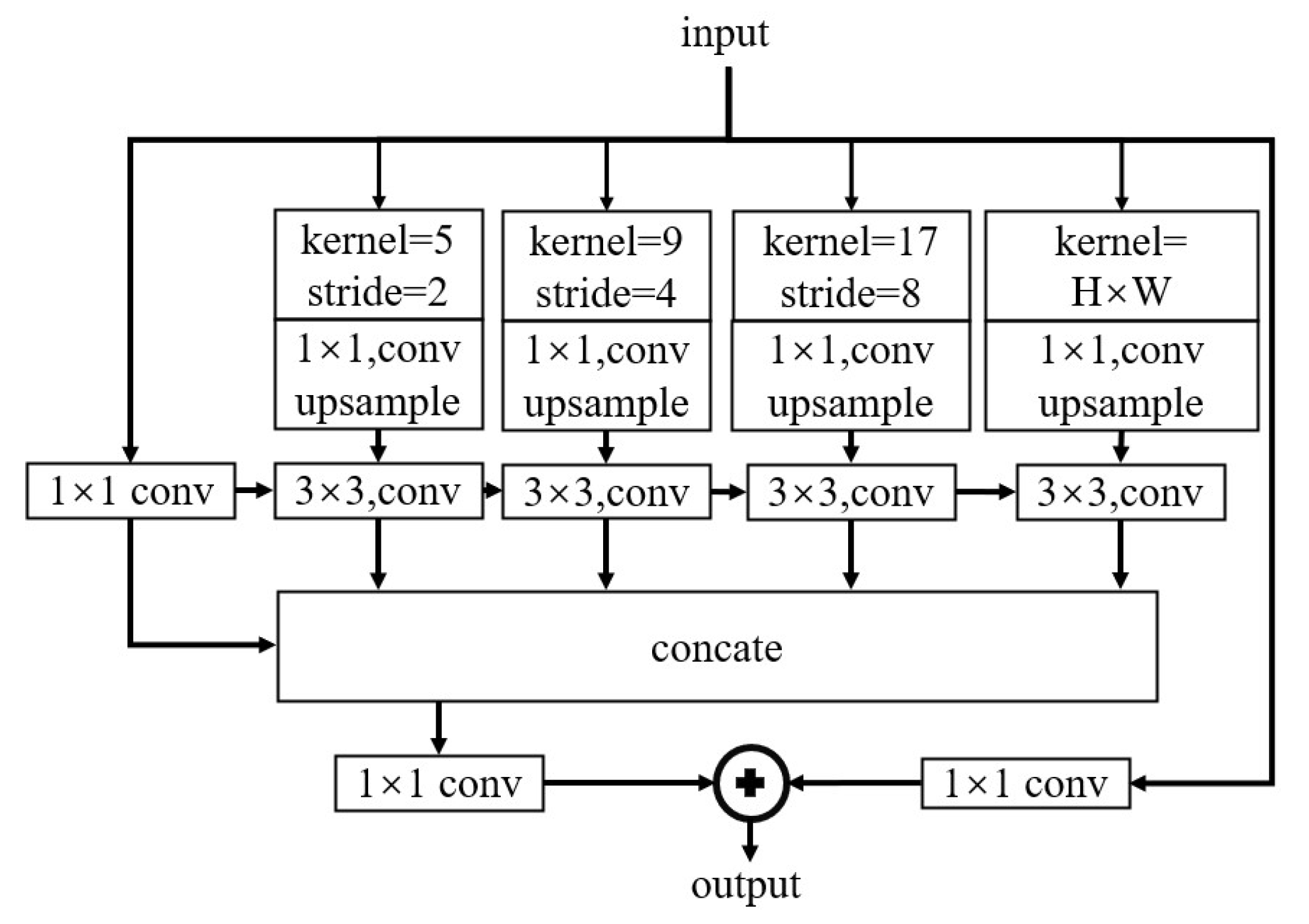
U-Net [10] has many successful applications in the field of computer vision, such as semantic segmentation, image enhancement and GAN. By extracting multi-level features from different network layers, U-Net can recover lost information from the convolutional subsampling, retain rich texture information, and synthesize high-quality images. The U-Net structure is also employed in AABGAN as an encoder and decoder. We used AAB before each max pooling layer and upsampling layer of U-Net. In addition, we use DAPPM [11] in the middle of U-Net. The structure of DAPPM is shown in Figure 4. DAPPM is based on PSPNET’s [29] feature pyramid pooling and RES2NET [30]. It can be observed as multiple feature scale modules and pyramid pooling, thus increasing the acceptance domain and integrating multi-scale feature information. The ablation experimental results show that the DAPPM module can improve the visual performance of images, as described in Section 4.
3.3. Double Discriminant Structure
A double discriminator is similar to the structure of Pix2Pix [23]; however, we have observed that the discriminator structure does not perform well on spatially varying images during the actual operation of low-light image enhancement. When only parts of an image require light enhancement (e.g., the images have shadows when a person’s face or device is backlit) or a small bright region in an overall dark background (e.g., the images only have a few beams of light against a dark background on a wall of coal), a single image-level discriminator does not have the desired adaptivity ability in local details. A double discriminator structure is employed, and both discriminators use PatchGAN for real/fake discrimination. The global discriminator takes the whole image as input and outputs the result of real/fake in the entire image. The local discriminator checks true and false by randomly cropping local patches from enhanced images and authentic normal-light images. In addition, we utilize the relativistic discriminator structure [31]; the structure uses known prior knowledge to improve the probability that the fake data are true while reducing the probability that the real data are true, instructing the generator to synthesize the fake images more natural than the actual images.
3.4. Multiple-Loss Function
Owing to the characteristics of complex illumination condition and multiple disturbances in engineering applications, we proposed a multiple-loss to train our network.
Exposure Consistency Loss: To enhance image exposure and suppress overexposure, we design the exposure consistency loss function to control the exposure degree of the image. From the results of the experiments, we find that the well-exposed range for human vision is from to . Therefore, we adjust the exposure to this range, and we give more attention to the darker areas by activating function.
where and M is the size of local regions, which is set to (i.e., the average value in a region), and represents the ReLU function. We set , and
Color Consistency Loss: We adopt color consistency loss, which corrects the color deviation during the training process. The can be expressed as:
where , and denote the average intensity value of r channel, g channel, and b channel of the image after enhancement, respectively.
Spatial Consistency Loss: To ensure the spatial consistency between the generated images and the original images, we employ the spatial consistency loss, which controlled the average intensity value of the enhanced images in adjacent areas (i.e., top, down, left, and right).
where S is the number of local regions, we set S to is the average intensity value of the local region in enhanced images Similarly, J is the average intensity value of the local region in original images. D is the operation of taking absolute value. calculates the square of the difference between enhanced images and original images. represent the left, right, top, and down of a pixel location.
Global Consistency Loss: We change the relativistic discriminator loss by replacing the sigmoid function with the least-square GAN loss [32]. Finally, the loss functions for the generator G are as follows:
where constants a and b denote the tags of the real image and the generated image. We set and and are sampled from the real and fake distribution, and and are the standard function of the relativistic discriminator.
Local Consistency Loss: To improve local authenticity, we randomly sample five small parts of images each time and employ least-square GAN loss as follows:
where we set a = c = 1 and b = 0.
Preserving Constancy Loss: Perceptual loss [33] is proposed to constrain the perceptual similarity. Unlike common practice, we adopt perceptual loss to limit the VGG-feature distance between the low-light input and the enhanced normal-light output. Loss can be expressed as
where I and denote the input image and the enhanced image, respectively; denotes the output feature map from the pre-trained model; and and are the dimensions of the feature maps. We set i.
The overall loss function is defined as
where and are set to 1 and is set to . In the underground or underwater environment, the light source is limited. To increase the brightness of the working environment and improve the visual performance, strong searchlights and other equipment are often utilized in these environments. However, the problems of center overexposure and edge underexposure due to strong light searchlight, coupled with absorption and reflection effects on light, coal dust, and other interference, motivated us to design a multiple loss. Ablation experiments demonstrate the effectiveness of the loss, as discussed in Section 4.
4. Experiments
4.1. Implementation Details
Taking advantage of our model without paired low/normal light images, we add part of the captured coal images and environment images of coal mine space to our model training set; it is difficult to obtain appropriate low and high light paired images. We assemble a mixture of 1337 low light and 1371 normal light images, including different angles, different content, different quality, different exposure, backlight, etc. The images come from several datasets released in [7,12,34,35,36]. We convert all images to PNG format.
Our model is trained with the PyTorch and trained 200 epochs on an NVIDIA 2080Ti GPU. We use the ADAM optimizer. The learning rate is set to in the first 100 epochs. In the last 100 epochs, the learning rate decreases linearly to 0.
4.2. Benchmark Evaluations
We compare our model with State-of-the-Arts methods including BIMEF [37], NPE [38], LIME [6], MultiscaleRetinex [39], SRIE [40], Dong [41], MF [42], EnlightGAN [22] and Zero-DCE [21], and we adopt the no-reference image quality assessment metrics and full-reference image quality assessment metrics to evaluate the image quality. Our model has been tested on RCL and MUED [12] datasets with no-reference image quality assessment metrics and tested on the LOL [7] dataset with full-reference image quality assessment metrics. It is worth noticing that almost all the comparison methods use publicly available source codes with recommended parameters in the experimental process.
4.2.1. No-Reference Image Quality Assessment Metrics on the Coal Image
As the most economical fossil energy globally, coal plays a decisive role in the world’s energy security and social development. Unmanned mining of coal is the main method to increase coal production and reduce coal mining accidents. However, the environment of coal mine space is complex and usually has heavy dust and unsatisfactory lighting conditions. This environment results in coal images with high noise, low brightness, and low contrast. Therefore, extracting useful information from these images is difficult, which critically restricts the application of image and video technology in coal unmanned.
In the no-reference image experiment, we contribute an unpaired authentic coal low-light image enhancement dataset, which is real coal and the environment images. The dataset we obtain in the coal mine is called the RCL dataset. In particular, the coal image size is 4160 × 4160, and the mine environment image size is 4160 × 2768. Part of the RCL images is added to the training dataset. The low illumination images are randomly chosen and evaluated for test (78 images). Because in the authentic environment of coal mine space, obtaining the same scene with different brightness levels is difficult. The previous approach required training with the paired dataset; we did not retrain these models on the RCL dataset but tested them under their optimal parameters. We employ perceptual index (PI) [34,43,44] and NIQE [44] to evaluate different methods. PI and NIQE are the no-reference image quality assessment metrics to evaluating perceptual quality without ground truth. Lower PI and NIQE values indicate good perceptual quality. Figure 5 shows the performance of the different methods on the RCL dataset.
The local regions of BIMEF [37], Dong [41] and Zero-DCE [21] have been seriously distorted (Figure 5). MF [42] and NPE [38] achieved strong visual performance in the experiment but did not achieve the best brightness recovery. LIME [6] has a bad overall performance due to overexposure. MultiscaleRetinex [39] and EnlightGAN [22] have clear color deviation. SRIE [40] does not have sufficient exposure that can provide distinct coal local details. Experimental data also show that our model has the better visual performance. Thus, the proposed method is superior to other competing methods in terms of the PI and NIQE value (Table 1).
4.2.2. No-Reference Image Quality Assessment Metrics on Underwater Image
Underwater vision plays a crucial role in engineering application and resource exploration [45,46], such as monitoring sea life. However, when light propagates in water, water and various microorganisms have certain absorption and reflection effect on light. This can affect the image quality, resulting in problems such as low brightness, low contrast, blurred contour, color confusion and so on. Therefore, underwater image quality limits the development of underwater detection and recognition.
Quantitative evaluation
We also validate our model on the marine underwater environment database (MUED) [12]. The MUED dataset contains 8600 underwater images with complex backgrounds, illumination, turbidity of the water, etc. The 227 images with poor illumination conditions are stochastically chosen from MUED to test AABGAN. Considering that the MUED dataset is without ground truth, we still adopt NIQE to compare the performance of different methods. In Table 2, AABGAN gains the second-highest score (4.20). Owing to the single background of MUED, the traditional approaches (e.g., MultiscaleRetinex and MF) have achieved good results on NIQE; the newer method cannot achieve the leading score (e.g., EnlightGAN has a lower score). The Table 2 results show that AABGAN not only obtains a good result in an intricate environment and background but also has good performance in a complex environment with a simple background.
Qualitative evaluation
In Figure 6, the red boxes on the right are an enlarged view of the red box area on the left. Because the background structure of MUED is single, the older methods also have good performance. BIMEF [37] enhances the image to an inappropriate visual perception range, leading to dim performance in local image areas. MultiscaleRetinex [39] has serious discoloration when processing complex environment images; that is, the hue of the image becomes white; however, the local details are still enhanced. Dong [41] has the problem of noise amplification and serious color deviation in the entire image. MF [42] is more of a combination of underexposed SRIE and color deviation. Hence, MF also has the problems of insufficient local illumination and color distortion. EnlightGAN [22] does not perform well in the border part of the image. As the latest method, Zero-DCE [21] has poor performance on MUED, and the enhanced images lose local detail information. The local area enhanced by SRIE [40] is darker than the proposed method, which leads to a lower NIQE than AABGAN. The results on MUED show that AABGAN enhances the brightness of the image while maintaining local details and better image structure. Compared with the previous method, AABGAN substantially improves the image illumination and maintains the original hue of the image.
4.2.3. Full-Reference Image Quality Assessment Metrics on the LOL Dataset
To further explore the performance of AABGAN on full-reference image quality assessment, the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) were employed to compare and evaluate the quality of the enhanced images on the LOL dataset [7]. The first 689 (689 pairs) images from LOL were placed into the training dataset, and we reserved 100 pairs of images from 689 to 789 as the test dataset of the comparative experiment. In Table 3, AABGAN is compared to the typical low-light enhancement methods. The results show that AABGAN has achieved better results on both PSNR and SSIM. In addition, the experiments demonstrate the advantages of AABGAN in terms of structure consistency, color consistency, and lower noise level.
Figure 7 provides the visual comparison results of different low-light image enhancement methods. The red boxes highlight the regions where AABGAN performs better than the other methods. BIMEF [37] and SRIE [40] have conservative (weak) enhancement, which obscured the noise in the dark part of the image to improve the visual performance. LIME [6] and MultiscaleRetinex [39] restored the global illumination of the results. However, they are unable to improve the image brightness while maintaining their structural stability. Dong [41], MF [42] and NPE [38] have the problem of noise amplification. EnlightGAN [22] has exhibited local color distortion. Zero-DCE [21] has better overall performance compared with the others; however, it still has local noise. The results show that our method achieves more natural performance results than previous methods. Therefore, the proposed method emphasizes both image brightness enhancement and noise suppression.
4.3. Ablation Study
The study aimed to demonstrate the effectiveness of the components of the proposed model. Here, we design several ablation experiments. Specifically, each design component is removed. First, only a simple U-net structure was employed as our backbone. Then, we added AAB, multiple loss, and DAPPM individually. Table 4 presents the network structure. In the backbone and V1 network, the perceptual loss function, exposure consistency loss function, color consistency loss function, and spatial consistency loss function were removed. To ensure reliability of the results, two well-known full-reference image quality assessments (SSIM and PSNR) were used to evaluate the image quality. Note that the full-reference image quality assessment requires ground truth for contrast. In the environment of the coal mine space and underwater dataset, simultaneously capturing low-light images and ground truth in the same place is clearly quite difficult. Thus, ablation experiments are designed on the LOL dataset [7]. Figure 8 presents the visualization results. These results imply that color distortion and noise are suppressed after adding these components. Backbone is prone to local artifacts due to the unstable network structure. Although V1 has improved the defects of the backbone, it is quite unclear and has color distortion. V2 overcomes local artifacts and noise; however, the resulting brightness is insufficient to achieve the best visual performance. Therefore, the experiments show that each module proposed in our model is effective.
5. Conclusions
In this paper, we proposed a novel AAB-based network structure that can pay more attention to the dark parts of an image. The proposed method was trained end-to-end with unpaired images. Then, we designed a new multiple-loss function, which can be applied to a complex application environment, to suppress color distortion and noise. Furthermore, we formulated a new dataset of coal images and added them to the trained model. The results of the experiments demonstrate that the performance of our model is better than those of state-of-the-art unsupervised image enhancement methods in full-reference image quality assessment metrics.
Based on the current study, in the future, we will investigate how to improve the quality of coal segmentation tasks by using enhanced coal images. In addition, we will attempt to use single-channel images to reduce the number of model parameters and to use a hue channel to guide the coloring of single-channel images.
Author Contributions
Conceptualization, X.W. and M.J.; Data curation, J.C.; Formal analysis, J.Q.; Investigation, J.Q.; Methodology, X.W.; Resources, J.C.; Supervision, X.W. and J.C.; Visualization, J.Q.; Writing—original draft, J.Q.; Writing—review and editing, X.W., J.C. and M.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China (NSFC) (62006107, 61976123, 61402212); Taishan Young Scholars Program of Shandong Province; and Key Development Program for Basic Research of Shandong Province (ZR2020ZD44).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from corresponding authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jian, M.; Qi, Q.; Dong, J.; Yin, Y.; Lam, K.M. Integrating QDWD with pattern distinctness and local contrast for underwater saliency detection. J. Vis. Commun. Image Represent. 2018, 53, 31–41. [Google Scholar] [CrossRef]
- Wang, M.; Tian, Z. Mine image enhancement algorithm based on nonsubsampled contourlet transform. J. China Coal Soc. 2020, 45, 3351–3362. [Google Scholar]
- Dhara, S.K.; Sen, D. Across-scale process similarity based interpolation for image super-resolution. Appl. Soft Comput. 2019, 81, 105508. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Hu, L.; Li, L.; Zhang, W.; Huang, Q. Two-stream deep sparse network for accurate and efficient image restoration. Comput. Vis. Image Underst. 2020, 200, 103029. [Google Scholar] [CrossRef]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Zhuo, J.; Wang, S.; Zhang, W.; Huang, Q. Deep unsupervised convolutional domain adaptation. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 261–269. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Hong, Y.; Pan, H.; Sun, W.; Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of road scenes. arXiv 2021, arXiv:2101.06085. [Google Scholar]
- Jian, M.; Qi, Q.; Yu, H.; Dong, J.; Cui, C.; Nie, X.; Zhang, H.; Yin, Y.; Lam, K.M. The extended marine underwater environment database and baseline evaluations. Appl. Soft Comput. 2019, 80, 425–437. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vision, Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Pisano, E.D.; Zong, S.; Hemminger, B.M.; DeLuca, M.; Johnston, R.E.; Muller, K.; Braeuning, M.P.; Pizer, S.M. Contrast limited adaptive histogram equalization image processing to improve the detection of simulated spiculations in dense mammograms. J. Digit. Imaging 1998, 11, 193. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ibrahim, H.; Kong, N.S.P. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 1752–1758. [Google Scholar] [CrossRef]
- Nakai, K.; Hoshi, Y.; Taguchi, A. Color image contrast enhacement method based on differential intensity/saturation gray-levels histograms. In Proceedings of the 2013 International Symposium on Intelligent Signal Processing and Communication Systems, Naha, Japan, 12–15 November 2013; pp. 445–449. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef] [Green Version]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. Msr-net: Low-light image enhancement using deep convolutional network. arXiv 2017, arXiv:1711.02488. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM international Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Zhang, Y.; Di, X.; Zhang, B.; Wang, C. Self-supervised image enhancement network: Training with low light images only. arXiv 2020, arXiv:2002.11300. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhang, J. Design of image acquisition system in low illumination environment. Coal Mine Mach. 2017, 38, 3. [Google Scholar]
- Mathur, M.; Goel, N. Enhancement of nonuniformly illuminated underwater images. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2154008. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Chen, R. Underwater image enhancement with image colorfulness measure. Signal Process. Image Commun. 2021, 95, 116225. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Gao, S.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P.H. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 23–28 August 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Blau, Y.; Michaeli, T. The perception-distortion tradeoff. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6228–6237. [Google Scholar]
- Dang-Nguyen, D.T.; Pasquini, C.; Conotter, V.; Boato, G. Raise: A raw images dataset for digital image forensics. In Proceedings of the 6th ACM Multimedia Systems Conference, Portland, OR, USA, 18–20 March 2015; pp. 219–224. [Google Scholar]
- Kalantari, N.K.; Ramamoorthi, R. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph. 2017, 36, 144. [Google Scholar] [CrossRef]
- Ying, Z.; Li, G.; Gao, W. A bio-inspired multi-exposure fusion framework for low-light image enhancement. arXiv 2017, arXiv:1711.00591. [Google Scholar]
- Wang, S.; Zheng, J.; Hu, H.M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef]
- Petro, A.B.; Sbert, C.; Morel, J.M. Multiscale retinex. Image Process. Line 2014, 4, 71–88. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2782–2790. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Liao, Y.; Ding, X.; Paisley, J. A fusion-based enhancing method for weakly illuminated images. Signal Process. 2016, 129, 82–96. [Google Scholar] [CrossRef]
- Ma, C.; Yang, C.Y.; Yang, X.; Yang, M.H. Learning a no-reference quality metric for single-image super-resolution. Comput. Vis. Image Underst. 2017, 158, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Kocak, D.M.; Dalgleish, F.R.; Caimi, F.M.; Schechner, Y.Y. A focus on recent developments and trends in underwater imaging. Mar. Technol. Soc. J. 2008, 42, 52–67. [Google Scholar] [CrossRef]
- McLellan, B.C. Sustainability assessment of deep ocean resources. Procedia Environ. Sci. 2015, 28, 502–508. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Visual results of different methods on coal image. Our model will enhance the global illumination, suppresses color distortion and reduces the noise level. (a) Input. (b) LIME. (c) EnlightGAN. (d) Ours.
Figure 1.
Visual results of different methods on coal image. Our model will enhance the global illumination, suppresses color distortion and reduces the noise level. (a) Input. (b) LIME. (c) EnlightGAN. (d) Ours.

Figure 2.
Overview of our generator network.

Figure 3.
Structure of the anti-attention block.

Figure 4.
Structure of DAPPM.

Figure 5.
RCL dataset visual comparisons result on different methods. (a) BIMEF. (b) Dong. (c) LIME. (d) MF. (e) MultiscaleRetinex. (f) Input. (g) NPE. (h) SRIE. (i) EnlightGAN. (j) Zero-DCE. (k) Ours.
Figure 5.
RCL dataset visual comparisons result on different methods. (a) BIMEF. (b) Dong. (c) LIME. (d) MF. (e) MultiscaleRetinex. (f) Input. (g) NPE. (h) SRIE. (i) EnlightGAN. (j) Zero-DCE. (k) Ours.

Figure 6.
Visual comparison results of different methods in the MUED dataset. (a) Input. (b) BIMEF. (c) Dong. (d) MF. (e) MultiscaleRetinex. (f) SRIE. (g) Zero-DCE. (h) EnlightGAN. (i) Ours.
Figure 6.
Visual comparison results of different methods in the MUED dataset. (a) Input. (b) BIMEF. (c) Dong. (d) MF. (e) MultiscaleRetinex. (f) SRIE. (g) Zero-DCE. (h) EnlightGAN. (i) Ours.

Figure 7.
Visual comparison results of different methods on the LOL dataset. (a) Input. (b) BIMEF. (c) Dong. (d) LIME. (e) MF. (f) MultiscaleRetinex. (g) NPE. (h) SRIE. (i) EnlightGAN. (j) Zero-DCE. (k) Ours. (l) Ground Truth.
Figure 7.
Visual comparison results of different methods on the LOL dataset. (a) Input. (b) BIMEF. (c) Dong. (d) LIME. (e) MF. (f) MultiscaleRetinex. (g) NPE. (h) SRIE. (i) EnlightGAN. (j) Zero-DCE. (k) Ours. (l) Ground Truth.

Figure 8.
Visualization of the impact with different modules. (a) Backbone. (b) V1. (c) V2. (d) ALL.
Figure 8.
Visualization of the impact with different modules. (a) Backbone. (b) V1. (c) V2. (d) ALL.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Quantitative results in the RCL dataset. MR (MultiscaleRetinex) EG (EnlightenGAN) ZDCE (Zero-DCE).
Table 1.
Quantitative results in the RCL dataset. MR (MultiscaleRetinex) EG (EnlightenGAN) ZDCE (Zero-DCE).
| Metric | BIMEF [45] | NPE [38] | MR [39] | SRIE [40] | Dong [41] |
| PI ↓ | 2.56 | 2.33 | 2.94 | 2.43 | 2.93 |
| NIQE↓ | 3.55 | 2.95 | 3.37 | 3.35 | 4.31 |
| Metric | MF [42] | LIME [6] | EG [22] | ZDCE [21] | Ours |
| PI↓ | 2.34 | 2.97 | 2.48 | 2.42 | 2.31 |
| NIQE↓ | 3.21 | 3.29 | 3.43 | 3.36 | 3.21 |
Table 2.
Quantitative results in the MUED dataset: MR (MultiscaleRetinex), EG (EnlightenGAN), and ZDCE (Zero-DCE).
Table 2.
Quantitative results in the MUED dataset: MR (MultiscaleRetinex), EG (EnlightenGAN), and ZDCE (Zero-DCE).
| Metric | BIMEF [37] | MR [39] | SRIE [40] | Dong [41] |
|---|---|---|---|---|
| NIQE↓ | 4.08 | 4.33 | 4.27 | 5.27 |
| MF [42] | EG [22] | ZDCE [21] | Ours | |
| 4.22 | 4.83 | 4.41 | 4.20 |
Table 3.
Quantitative results in the LOL dataset: MR (MultiscaleRetinex), EG (EnlightenGAN), and ZDCE (Zero-DCE).
Table 3.
Quantitative results in the LOL dataset: MR (MultiscaleRetinex), EG (EnlightenGAN), and ZDCE (Zero-DCE).
| Metric | BIMEF [37] | NPE [38] | MR [39] | SRIE [40] | Dong [41] |
| SSIM↑ | 0.6486 | 0.4927 | 0.4047 | 0.5418 | 0.5197 |
| PSNR↑ | 17.88 | 17.35 | 11.65 | 14.49 | 17.29 |
| Metric | MF [42] | LIME [6] | EG [22] | ZDCE [21] | Ours |
| SSIM↑ | 0.5398 | 0.4529 | 0.5938 | 0.5926 | 0.6972 |
| PSNR↑ | 18.76 | 15.25 | 18.65 | 18.10 | 19.38 |
Table 4.
Performance of the network.
| AAB | Multiple Loss | DAPPM | SSIM/PSNR | |
|---|---|---|---|---|
| Backbone | 0.556/14.96 | |||
| V1 | √ | 0.614/17.67 | ||
| V2 | √ | √ | 0.655/17.91 | |
| All | √ | √ | √ | 0.697/19.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Qiao, J.; Wang, X.; Chen, J.; Jian, M. Low-Light Image Enhancement with an Anti-Attention Block-Based Generative Adversarial Network. Electronics 2022, 11, 1627. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics11101627
AMA Style
Qiao J, Wang X, Chen J, Jian M. Low-Light Image Enhancement with an Anti-Attention Block-Based Generative Adversarial Network. Electronics. 2022; 11(10):1627. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics11101627
Chicago/Turabian StyleQiao, Junbo, Xing Wang, Ji Chen, and Muwei Jian. 2022. "Low-Light Image Enhancement with an Anti-Attention Block-Based Generative Adversarial Network" Electronics 11, no. 10: 1627. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics11101627
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.