1. Introduction
The travel industry is a well-known industry for entertainment. More than one billion international tourists travel around the world [
1]. During traveling from one place to another, we can have fun; we can enjoy a new culture, make relationships, and grow our opportunities. With the rapid development of portable applications and trip accession technologies, a personalized trip recommender that recommends sequential POIs to the visitors has emerged and received popularity recently. Traditional trip recommendation uses the popularity and user inclination to assess the fascination of every POI and suggests consecutive POIs with increasing user experience [
2,
3]. Jiang et al. [
4] suggested customized travel arrangements in various seasons by consolidating text-based information and perspective data removed from pictures. Lu et al. [
5] mined user check-in information, and a priori-based measures were proposed to discover ideal trips under different requirements, regardless of the high computational expenses. The quick urbanization of urban communities has led to an increase in the number of Points of Interest (POIs) on a trip. These POIs can be restaurants, hotels, beaches, events, cinemas, parks, matches, or even a viewpoint on the road. Location-Based Social Networks (LBSNs) have been a quickly developing field in recent years. The volume of data created by LBSNs permits researchers to take out precise user data to offer superior support in end-user applications. Compared with a single POI recommendation, the POIs sequence recommendation is challenging. There are only a couple of studies focusing on POIs sequence recommendations. To display the POIs sequence recommendation task, a few analysts proposed popularity-based methodologies [
6,
7], which means discovering a POIs sequence that expands POI popularity. In these ways, all users will receive a similar recommendation.
Additionally, other personalization-based methodologies [
2,
8] have been developed to suggest a fantastic visit plan for every traveler, depending on their advantages and inclinations. In the recent trip recommendation model, the time factor was under concentration [
9]. One location recommendation objective is to suggest the next POI for the users at an exact time given the users’ recorded history of traveling [
10].
The trip recommendation has the following challenging issues: (1) How to address the cold-start problem in the trip recommendation? (2) How to address the fact that recommending the exact and accurate location results is sometimes boring? Users become bored when we recommend locations accurately and relevant to their previous locations. Looking at the same kind of POIs, again and again, is sometimes irritating and tedious. (3) How to improve personalized trip recommendations by considering serendipity?
Our Motivation: To address the challenges in a trip recommendation, we propose a Serendipity-Oriented Personalized Trip Recommendation (SOTR). Some past precision goals, particularly variety, novelty, and serendipity, have been underscored in the new literature since they focus on permitting users to find new and diverse trips to expand their viewpoints.
Diversity mentions the contrast between the current recommendation and the user’s profile. Novelty describes whether the trip is unknown to the user. Trips new to a user are typically unpopular, as popular trips are frequently seen by the users, where popularity can be estimated by the number of ratings in the system. The serendipitous suggestion assists the user in discovering a fascinating thing that he/she probably will not have in any case found (or it would not have been intended to find). Serendipity cannot occur if the user realizes what is prescribed to his/her because, by definition, something new is happening. Along these lines, the less likely a user is to notice a thing, the more likely a particular item can bring a good proposal [
11]. The serendipitous recommendation is progressively seen as being similarly significant to the other past precision goals (such as novelty and variety) in wiping out the personalized recommendation systems’ “filter bubble” phenomenon. Our commitments are as per the following:
As far as we know, we are the first to investigate the serendipity in deep detail in the personalized trip recommendation. SOTR discovers the POI from the travel history of users and will recommend a sequence of POIs using serendipity.
SOTR addresses the cold-start problem: the framework cannot draw any inductions for users or trips about which it has not yet accumulated adequate data.
We appraise the performance of SOTR with real-world datasets from Foursquare and compare it with some baselines. Experimental results show that SOTR is superior to other trip recommendation techniques.
The rest of this paper is assembled as follows:
Section 2 of this paper surveys the related work.
Section 3 describes the problem statement and solution overview.
Section 4 describes the proposed model.
Section 5 displays the experimental results. At the last,
Section 6 concludes this advanced research.
2. Related Work
This section will discuss previous studies on Trip Recommendation and different approaches used for Trip Recommendation. Trip Recommendation is a classical detection problem. Various methods have been introduced to improve performance. Recently, deep learning techniques have demonstrated the different conceivable outcomes of the solutions to this issue. We describe some previous traveling recommendation work: Long- and Short-term Preference Learning for Next POI Recommendation, Recommending Reforming Trip to a Group of Users, SNPR: A Serendipity-Oriented Next POI Recommendation Model, and HAES: A New Hybrid Approach for Movie Recommendation with Elastic Serendipity.
Long- and Short-term Preference Learning for Next POI Recommendation: The next POI idea has been focused on an extensively new approach [
10]. The goal is to propose the next POI for the users at a specific time, given the users’ recorded history of traveling. This way shows users’ general taste and progressive approaches to visiting fascinated POIs. Furthermore, the setting information, such as the order and registration time, is vital for catching user tendencies. The Long- and Short-term Preference Learning (LSPL) model has been proposed to resolve this issue considering the similar and repeated information. The drawn-out module becomes comfortable with the essential components of POIs and impacts the thought framework to catch users’ tendencies. The short module utilizes LSTM to become comfortable with users’ repeated information of interest. Specifically, to learn the different effects of regions and classes of POIs, two LSTM models were utilized for region-based progression and arrangement-based gathering independently. Then, the long and short outcomes were analyzed to recommend the next POI for the users. At last, the proposed model was surveyed on two real-world datasets. The trial results show that the methodology performs better than other benchmark strategies for the next POI recommendation.
This work suggests just one next POI, while we suggest a sequence of POIs. One more contrast between their work and ours is that we use serendipitous POIs to accomplish users’ fulfillment.
Recommending Reforming Trip to a Group of Users: An advanced dynamic trip recommendation model has been implemented in this research work [
12]. With the fast advancement of versatile applications and trip direction innovations, a trip recommender that suggests consecutive Points of Interest (POIs) to explorers has arisen. For example, when somebody needs to organize a schedule, they look forward not to a single POI idea but rather to a suggestion for the sequence of POIs. A sequence of POIs contains numerous POIs and follows the legitimate travel request. Schedule arranging is a phenomenally dismal and tedious activity since users reliably need to think about the time objectives, distance limits, and cost necessities diverged from just a single POI idea. A sequence of POIs is more challenging for the accompanying critical reasons: (I) an arrangement of POI proposals requires a suitable and fascinating succession of POIs that unequivocally relate to the user’s benefit and tendencies, contrasted with basically a single POI; (II) users’ tendencies might change during the trip, which extends the requirement of dynamic ideas; and (III) the arranged series of POI ideas relies on various factors (e.g., reliance, time, and other conditions) [
13].
In order to show the POI succession suggestion task, a couple of investigators have proposed notoriety-based methodologies [
6,
7], which means finding a POI sequence that grows POI fame. Gavalas et al. [
14] demonstrated that all the proposed time-sensitive user premiums exhibited benefits over the utilization of recurrence-based popularity measures in trip itineraries. Following these ways, all users can have a similar proposal. Contrasted with other trip recommenders, which recommend a single POI, their proposed trip proposition research is based on the trip suggestion. A high-level arrangement of the POI proposal framework named Recommending Reforming Trip (RRT) is introduced, prescribing a unique succession of POIs to a group of users. A beneficial arrangement is executed by relying on the Deep Neural Network (DNN) to deal with this issue. Beginning at the end of the work cycle, RRT can allow the sequence of POIs to change after some time by flawlessly suggesting a unique arrangement of POIs. In addition, two new assessments, Adjusted Precision (AP) and Sequence-Mindful Precision (SMP), are acquainted with the suggested accuracy of a sequence of POIs. These two measures will ensure the reliable sequence of POIs in recommending a trip to a group of users. They used the travel histories from the weeplaces dataset.
This work recommends reforming trips to a group of users. That is different from our work because we recommend personalized trips using serendipity.
SNPR: A Serendipity-Oriented Next POI Recommendation Model: SNPR: The Serendipitous POI proposal [
15] for travelers to suggest the next Point of Interest (POI) to the users. The issue that a large portion of the Point of Interest (POI) systems are facing is that suggesting the specific and similar area makes the user exhausted. Recommending similar sorts of POIs, over and over, is now and then bothering and boring. This work created a methodology and planned the Serendipitous POI Recommendation model. The proposed Serendipitous POI Recommendation model is introduced in this work to manage the difficulties of revelation and assessment of personal fulfillment. A convincing suggestion calculation should not simply endorse what we are likely to appreciate but also prescribe irregular yet genuine components to help keep an open window to different places and discoveries. To assess the calculation utilizing data procured from a real dataset and user travel chronicles removed from a Foursquare dataset. The effects of serendipity on expanding user fulfillment and social point have been confirmed. In light of that, SNPR suggests the next POI with high user fulfillment to amplify a user’s experience. As of now, their calculation outflanks different proposal techniques by fulfilling a user’s interests in the location recommendation.
Reference [
15] recommends just a single next POI. Compared to this work, we are recommending a complete trip using serendipity. The trip consists of a reliable sequence of POIs. It is a challenge to generate a reliable sequence of POIs. The two consecutive POIs in the sequence of POIs should not be similar or from the same category.
HAES: A New Hybrid Approach for Movie Recommendation with Elastic Serendipity: HAES: [
15] gives excellent instruction to users to track down their favorite films from an enormous amount of choices. Most frameworks seek the suggestion precision and lead to over-specialization, which helps to introduce the development of serendipity. They present another model called HAES, a Hybrid Approach for film suggestion with Elastic Serendipity, to suggest serendipitous films. In particular, they (1) propose a more accurate meaning of serendipity, content contrast, and type precision, as per the examination of a real dataset, (2) propose another calculation named JohnsonMax to moderate the information sparsity and fabricate weak ties advantageous to tracking down serendipitous films, and (3) characterize a new idea of flexibility in the suggestion, to change the degree of serendipity deftly and obtain a trade-off between serendipity and accuracy. Broad tests on real-world datasets show that HAES improves the serendipitous proposals while saving suggestion quality, contrasted with a few generally utilized strategies.
This work is different from ours as we recommend trips using serendipity while HAES recommends movies using serendipity.
All the mentioned trip recommendation frameworks use accumulation strategies to recommend exciting visiting locations. If we compare, our methodology recommends the serendipitous trip to a user.
3. Problem Statement and Solution Overview
In this section, we explain the problem we solve. Although a lot of work has been undertaken on trip recommendations, a few things are still missing to obtain users’ satisfaction. Primarily, trip recommendation systems work on collaborative filtering and content-based filtering, in which the system recommends a trip by checking location similarity and users’ similarity. The serendipity-oriented personalized trip recommendation model addresses the cold-start problem. Some trip recommendation systems recommend trips according to relativity and accuracy. Suggesting appropriate and accurate location is not good sometimes. Users feel bored and lose excitement. Therefore, to address that problem, we have introduced serendipity into our trip recommendation system. We define the essential concepts of modeling trips using serendipity. Then, we formulate the problem we resolve and provide a brief overview of our solution. Serendipity is the event and improvement of occasions by chance. It is the achievement of things that were not in the expectation [
16]. Serendipity helps us to excite users and satisfy them efficiently. Notations are summarized in
Table 1.
3.1. The Key Concepts
An enthusiastic dimension that incorporates serendipity is a troublesome idea to contemplate. However, an agreement regarding recommender systems should be serendipitous for a user, and trips should be unexpected and relevant. A lot of previous works demonstrate unexpectedness and relevance are significant to serendipity [
17,
18,
19,
20,
21,
22]. Most papers incorporate these two parts to the meaning of serendipity. In one model, the definition is introduced by Chen et al. [
22].
Serendipity highlights checking that the user feels excited when a user perceives a suggestion to be relevant, suggesting that the trip should not be perfectly suitable for the user yet and be unexpected and not purposefully searched by the user.
In light of the literature survey on the meaning of serendipitous recommendations, we can assume that trips should meet the necessities of being unexpected by a specific user and relevant to their interests. The above-related works frequently have not characterized the substantial ideas about “relevance” and “unexpectedness”, which may create uncertainty. Thus, we describe the definitions of trip novelty, relevance, unexpectedness, and serendipity.
In the trip recommendation system, let U= denote a group of LBSN users, while O = is a group of POIs.
The formal definitions of user preference and the serendipity vector are presented as follows.
Definition 1 (POI). A POI o ∈ O is presented by a triplet of ID, POI category, and geographic location, i.e., (o,,) determine the POI class connected with o, and indicates the area of o on the geographic surface demonstrated by a longitude and latitude scope pair .
Definition 2 (Trip). Given a trip is orderly composed of one or several POIs denoted by tp = , which is also denoted as a trip and indicates the number of POIs in a trip (i.e., = s).
Definition 3 (User Interest). We characterize the interest score Int (u; o) of a user u to a trip tp as the similarity between trip tp and the previous visiting record of the user.
Definition 4 (Check-in and User Profile). A check-in I is a visit log including three credits: a user, an outing, and the hour of visit. User profile decides the arrangement of seen check-ins visited by user decides the visited trip tp showing up in the check-ins in , and demonstrates the trip showing up in .
Definition 5 (Serendipity). Serendipity, the most firmly related idea to unexpected quality, includes a positive, passionate reaction of the user about a formerly obscure (novel) suggestion, and serendipitous suggestions are by definition likewise novel [23]. According to the most usual definition, serendipity consists of three elements: relevance, novelty, and unexpectedness. Definition 6 (Trip Relevance). We regard a trip tp as relevant to a user u if she/he has visited most of the recommended POIs o in the recorded history. Therefore, we define the trip tp relevance as:where is the group of users who have visited POIs. For the representation of the relevance, we indicate the relevance of tp to u as . Definition 7 (Trip Novelty). We regard a trip tp as novel to a user u if she/he has visited most of the recommended POIs o in previous recorded history. Therefore, we define the trip novelty as:where is the group of users who have visited POIs. For the representation of the relevance, we indicate the novelty of to u as . Definition 8 (Trip Unexpectedness). We denote a trip tp as unforeseen to a user if it is not comparative from the user profile . Many examinations [24,25,26] think about class as one of key credits of contrast assessment. Moreover, even though two POIs and have a place with a similar classification, there is likewise a distinction between them. In this manner, we incorporate classification similarities and outing similarities to introduce a fine-grained meaning of incredible trip quality as:where [0, 1] is a compromise constraint between the classification distinction and POI contrast components. Definition 9 (Trip Serendipity). We personify the relevance as prediction accuracy and the unexpectedness as the difference from the user profile. Then, at that point, we see a trip as serendipitous to a user, assuming it is both suitable and unforeseen. Thus, we characterize the serendipitous trip as:where [0, 1] is a compromise limit between the pertinence and unexpected parts. We demonstrate the serendipitous trip tp to u as . 3.2. Problem Formulation
This part will describe how we can obtain a reliable serendipitous sequence of POI. We will obtain three data lists Record, POI Sim (POI Similarity) and Cat Diff (Category Difference) by loading the dataset. From the Record, we will obtain user profile . We will extract the user genres list, POI visited novelty, relevance, and unexpectedness. For each user u ∈ UP, we can obtain a direction addressed by from the user profile , where n is the record of the current direction. Every direction contains a sequence of POIs visited by the user with a back to back arrangement, i.e., (o has a place with O). In this work, we treat all of the user’s check-ins in a single day as a solitary trajectory. In order to generate the trip, it is necessary to make sure that consecutive POIs should not be similar or from the same category.
POI Sim and Cat Diff from the loaded dataset can be used to find consecutive POIs similarities and category differences. To make sure consecutive POIs are not similar or from the same category, we will generate a sequence of POIs using POI Sim and Cat Diff. We will normalize the user genres list and POI visited. In order to address the cold-start problem, POI novelty received from the Record of the loaded dataset can be used. The POI with fewer ratings will be considered a Novel POI. Given the trajectory sequence J, the serendipitous trip tp suggestion problem is described as follows. For a target user u∈UP, along with the user’s historical trajectory sequence and current trajectory = = where is the most recent POI that u has visited, the aim is to suggest the serendipitous trip tp to user u at the next timestamp t. In our experiment, we will input GRU network, train data, optimizer, and epoch. In order to train a network, different uid have different numbers of train sessions, and to test a network, different uid have different numbers of the test sessions. For example, for , we will obtain a user matrix with 288 category sets, 10 train sessions, and 3 test sessions. We will input user matrix A to a network and obtain matrix B. Then, with the category set, we will recommend the trip tp, a sequence of a maximum of five serendipitous POIs, to user u.
3.3. Solution Overview
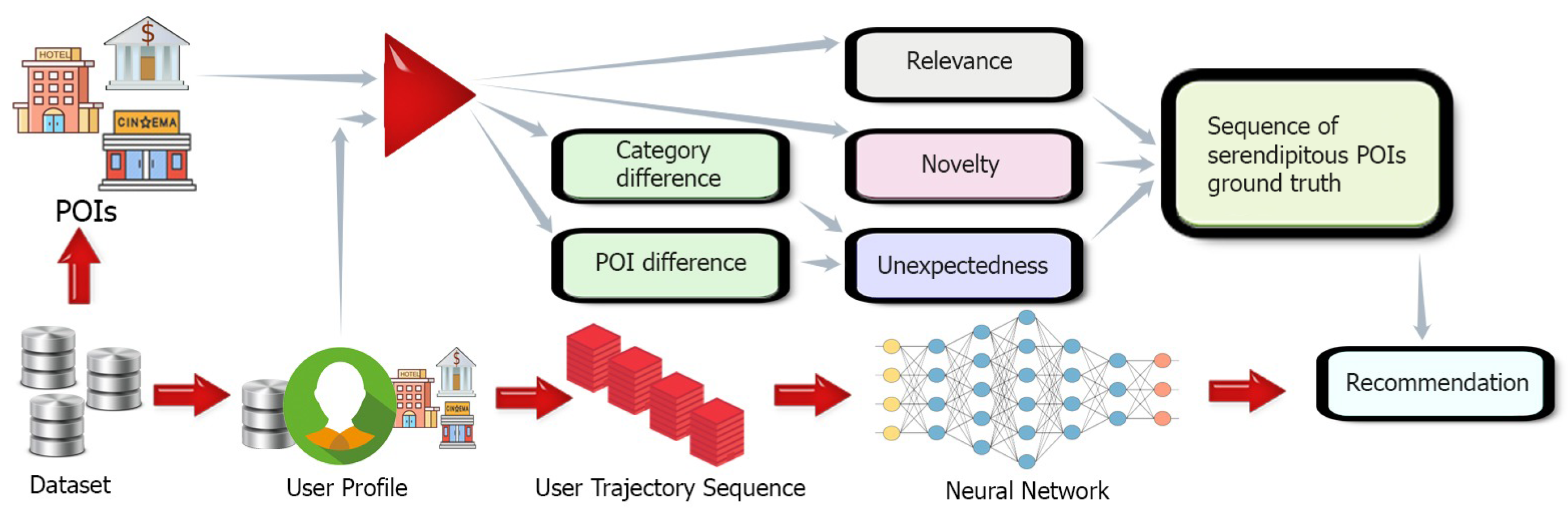
We present a brief overview of the designed SOTR, whose framework is illustrated in
Figure 1. I
Serendipitous trip tp ground truth. Given a user
u and a trip
tp, this component calculates the serendipity ground truth of
tp to
u as per the model characterized in
Section 3.1. II
Delicate neural network designing. To predict how serendipitous a trip
tp is to a user, we design a delicate neural network model, which will be explained in
Section 4. III
Recommendation. We train the network model using the computed ground truth and recommend the serendipitous trip to users.
4. The Proposed Model
In this part, we explain a delicately designed neural network model for the trip
tp recommendation.
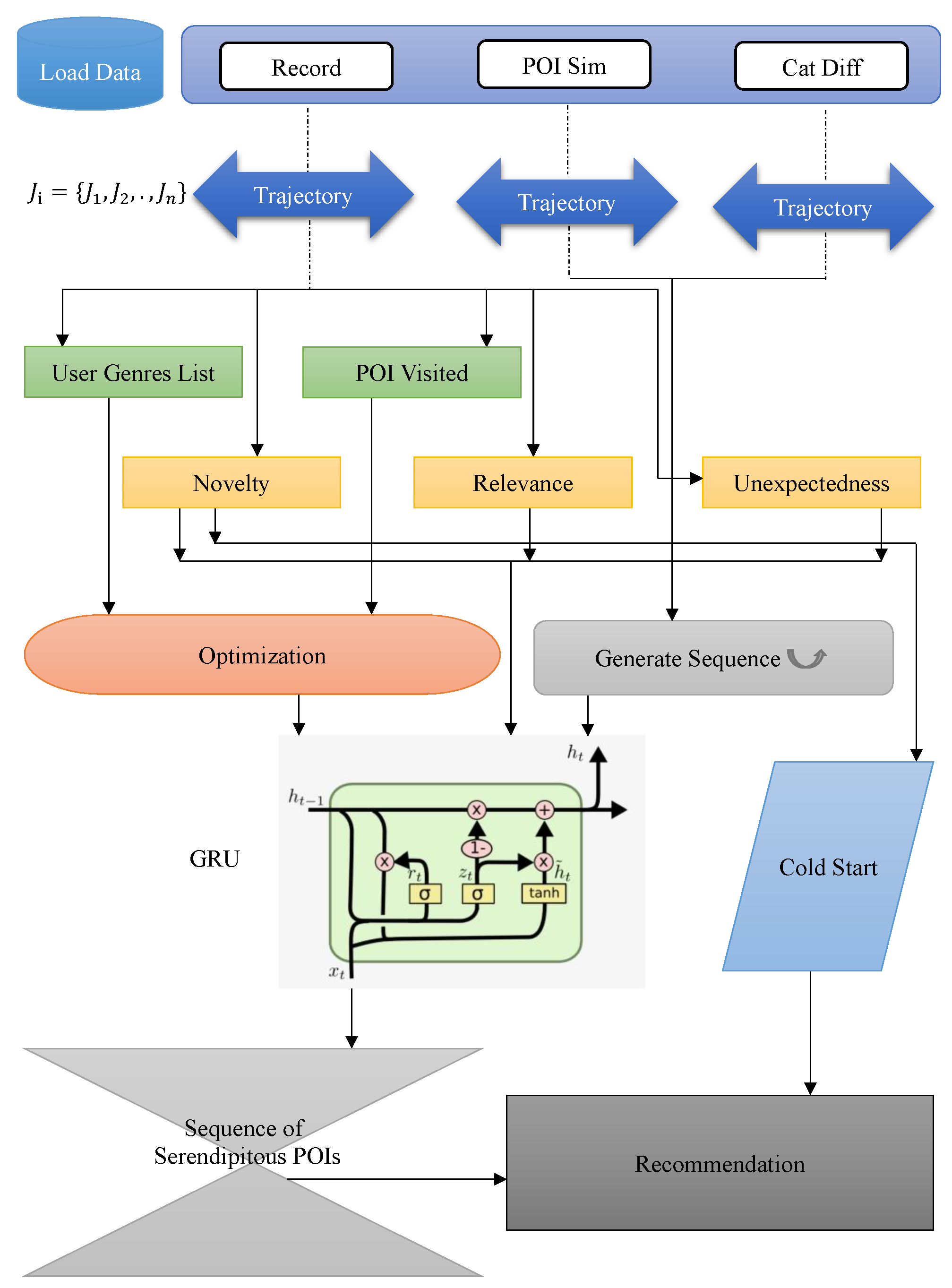
Figure 2 represents the architecture of SOTR. It consists of eight components: (a) Trajectory Encoding: it encodes every POI in each direction of a user by transformer encoder; (b) Generate Sequence: it demonstrates the creation of the sequence of a user’s POIs to ensure sequential POIs should not be similar or from same the category for a trip
tp to
u; (c) Relevance: it displays how the user will foresee the importance of a trip
tp to
u; (d) Novelty: it shows the user anticipating the oddity of a trip
tp to
u; (e) Unexpectedness: it demonstrates the user anticipating the unexpectedness of a trip
tp to
u; (f) Optimization: it enhances the user’s genres list and POI novelty utilizing an Adam streamlining optimizer; (g) GRU Network: it will receive data related to optimization, generated sequence, relevance, novelty, and unexpectedness from the GRU network to obtain a serendipitous trip
tp to
u; (h) Sequence of Serendipitous POIs Recommendation: it produces up to five POIs for the user as indicated by the arrangement of serendipitous POIs
to
u.
4.1. Trajectory Encoding
In trip
tp for every POI
o ∈ O and every class
cat ∈ CAT, we initially introduce their portrayals by uniform conveyance. Then, we acquire the underlying vector (meant by
o) of every POI
o in trip
tp by linking its base portrayal and the basic portrayal of its classification. Given a user,
J =
is their direction succession. We want to gain proficiency with the streamlined portrayals of all POIs
for all of their directions
, as delineated in
Figure 2.
Recent studies used RNNs to study POI representations for trip
tp recommendations and obtain promising results [
27,
28,
29,
30]. Recent research depended on RNNs, motivated by focused areas of strength for RNNs in displaying sequential information. For instance, CARA [
29] caught users’ dynamic inclinations by taking advantage of GRU’s gate system. DeepMove [
31] planned a multi-modular RNN to catch the successive change. TMCA [
28] took on the LSTM-based system and STGN [
30] embraced the gated LSTM structure to separately learn spatial-transient settings. LSTPM [
27] planned geo widened RNN to take advantage of the geological relations among non-successive POIs completely. They can model sequential activities in the user’s check-in sequence. However, non-consecutive POIs are mutually dependent because of some factors, such as their geographical distance. Such characteristics will be challenging to catch via RNN-based approaches [
27]. Being distinct from RNNs, Transformer [
32] does not require that the consecutive information be handled altogether and can catch the circumstances between portrayal sets regardless of their distance in the sequences. Consequently, we leverage the transformer encoder to embed the POIs.
4.2. Generate Sequence
In trip tp for every POI o ∈ O and every class cat ∈ CAT, we initially introduce their portrayals by uniform appropriation. Then, we acquire the consecutive sequence of POIs . To make sure two consecutive POIs are not similar and from the same category, we used POI Sim and Cat Diff. It is necessary to address this issue in the trip recommendation. In a sequence of POIs, two consecutive POIs should not be hotels. We need to check this by generating a sequence. POI Sim and Cat Diff will be obtained by loading the dataset. Therefore, to make sure that two consecutive POIs and are not similar, we will check the POIs using POI Sim and Cat Diff. For example, after visiting a hotel, we should not recommend a hotel in the trip recommendations. It is better to check the category difference and suggest a cinema for a movie after dinner at a restaurant.
4.3. Relevance
Given a user, this part models their profile
to a vector
as in
Figure 2, fully intent on anticipating the
relevance of a trip
tp to
u.
Relevance stresses whether the trip is relevant to the user. Trips relevant to a user are generally similar to the user’s recorded history. Users are frequently acquainted with relevant trips, where relevance can be estimated by the number of ratings in the user’s recorded history.
We regard a trip
tp 1 as relevant to a user
u if she/he has not visited it. Therefore, we define the trip
tp relevance as:
where
is the user’s visited trip
tp. For the representation of the relevance, we indicate the relevance of trip
tp to
u as
.
4.4. Novelty
Given a user, this part models their profile
to a vector
as in
Figure 2, fully intent on foreseeing the
novelty of a trip
tp to
u.
Novelty stresses whether the trip is obscure to the user. Trips unfamiliar to a user are generally unpopular. Users are frequently acquainted with popular trips, where popularity can be estimated by the number of ratings in the system.
We regard a trip
tp 1 as novel to a user
u if she/he has not visited it. Therefore, we define the POI novelty as:
where
is the user’s visited trip
tp. For the representation of the relevance, we indicate the novelty of trip
tp to
u as
.
4.5. Unexpectedness
Given a user, this part models their profile
to a vector
as in
Figure 2, fully intent on foreseeing the
unexpectedness of a trip
tp to
u.
As indicated by Equation (
3), POI startling quality to a user is superfluous to the fleeting and topographical data of user’s check-ins. Along these lines, we just address every direction as:
where
GELU is the initiation work, and
,
,
are learnable parameters.
Given a user, we can acquire every one of their direction portrayals (1 ≤ I ≤ cur). Then, at that point, we model the unexpectedness situated vector (i.e., ) for a user by utilizing their direction embedding .
4.6. Optimization
We used an Adam optimizer to optimize the user genres and POI novelty. It is a substitution optimization algorithm for training stochastic gradient descent with deep learning models. The Adam optimizer is used amongst the finest properties of the AdaGrad and RMSProp algorithms to give an optimization algorithm that can deal with inadequate slopes associated with noise issues. Setting the value to none rather than zero, and setting the .grads to none, will have a lower memory impression and a reasonably further development of execution. However, it changes specific practices—for example, (1) When the user attempts to obtain a gradient and perform a manual surgical operation on it, a none attribute will interact dissimilarly. (2) If the user requests zero_grad(set_to_none=True) followed by a backward pass, .grads are guaranteed to be none for params that did not receive a gradient. (3) torch.optim optimizers have a different behavior if the gradient is zero or none.
opt = torch.optim.Adam(filter(lambda p: p.requires_grad, network.parameters()), lr = 0.0001, weight_decay = 1 × 1 × 10−6).
4.7. GRU Network
To enhance the memory volume of a recurrent neural network and give the simplicity of training a model, a Gated Recurrent Unit can be used. We will add the data received from optimization, generated sequence, relevance, novelty, and unexpectedness to GRU to obtain a serendipitous trip. The hidden unit can also solve the vanishing gradient issue in recurrent neural networks.
network = GRU(cat_dif_matrix)
opt = torch.optim.Adam(filter(lambda p: p.requires_grad, network.parameters()), lr = 0.0001, weight_decay = 1 × 1 × 10−6)
network(network, data, opt, epoch = 1)
user_max_poi_dict = test_network(network, data, user_poi_relevance_matrix,
user_poi_elasticity_matrix, predict_number = 5)
ser_ground_truth_dict = get_ground_truth(data)
results, results_novelty = evaluate_network(user_max_poi_dict, user_ground_truth_dict, poi_novelty_list, poi_sim_matrix, cat_dif_matrix).
4.8. Sequence of Serendipitous POIs Recommendation
Given a user, we can acquire their relevance representation
,
and
in
Section 4.3 and unexpectedness representation
in
Section 4.5. Then, given a trip
tp, we apply it to the final user representation
u. Finally, we compute the rating score for trip
tp as:
where
represents the anticipated serendipity of a trip to user and is modeled by the inner product of
u and
tp. The model will recommend the trip
tp to the target user.
In consideration of training efficiency, we adopt a negative sampling strategy to learn the parameters of our network model. To be more specific, given a user
u at time step
t, we take the only relevant trip
tp as the positive training instance. In addition, we take trip
tp with the highest unexpectedness and trip
tp with the lowest unexpectedness as negative training instances. In this work, we set N = 10. The objective function was defined as the mean squared error with L2 norm regularization:
where it signifies the parameters in the network model, and
Tr is the arrangement of all training occurrences. The model was trained via an Adam optimizer.
5. Experiments
This section presents the data collection, annotation, and pre-processing needed to train the dataset. This section focuses on the Serendipity-Oriented Trip Recommendation (SOTR) model. We (1) present the necessary experimental arrangement, including datasets, baselines, and evaluation metrics; (2) contrast our technique with benchmarks showing its upgrades; (3) investigate the impacts of hyper-parameters in the proposed model; (4) confirm the viability of every part in the proposed model and ablation analysis.
5.1. Experimental Setup
5.1.1. Datasets and Data Preprocessing
The check-in datasets of two cities (i.e., New York in the U.S. and Tokyo in Japan) from perhaps the most delegated real LBSNs (i.e., Foursquare) are utilized in our experiment. This information was gathered from April 2012 to February 2013 [
33].
We pre-processed both datasets. For POIs, we discarded the less-rated ones visited by under ten users. For users, we treated their check-ins as a single direction made in one day, which is addressed in
Section 4.1. Basic measurements of datasets after pre-handling are displayed in
Table 2.
Following [
27,
31], we held the previous 80% of trajectories for the training set and used the rest for testing for each user.
5.1.2. Evaluation Metrics
The evaluation metrics were used to estimate every element of serendipity in various ways. We initially received three broadly utilized metrics for relevance evaluation: Precision, Recall, and Normalized Discounted Cumulative Gain (NDCG), which indicates recommending a top-ranked sequence of POIs for the trip.
The most utilized measures for evaluating trips are
precision,
recall, and
F1 score [
30,
34,
35,
36]. However, the main disadvantage of these measures is that they all fail to acknowledge the order of POI in the arrangement. In contrast, the order is a critical component of POIs sequence recommendation for a trip. To resolve the issue, we will implement a summation of
precision,
recall,
uex,
ndcg, and
ru. We will consider up to five POIs sequences to recommend the trip. We will add the
precision,
recall,
uex,
ndcg, and
ru of each trip and divide them with the number of POIs sequence.
Given a number of top predicted serendipitous POIs sequences to recommend as a trip for user
u, represented as
, and their real visited POIs in the test set, denoted as
, the first two metrics are computed by:
Total Precision for
k POIs sequence is computed as:
Total Recall for
k POIs sequence is computed as:
Intuitively,
Precision denotes what percentage of the recommended trip is actually visited by users, and
Recall denotes what percentage of the users’ actually visited POIs will end up in the top recommended list. The
NDCG is defined as follows.
Total
NDCG for
k POIs sequence is computed as:
where
is an indicator equal to one if the trip at rank
i is actually visited by
u, and zero otherwise.
In general, Precision and Recall do not consider the order in the recommendation list, while NDCG is a full position-mindful metric, which allots bigger loads on higher positions. They reflect different aspects of recommendation relevance quality. For all of them, higher metric values indicate better ranking quality.
Then, at that point, we characterize a metric
UNE for unexpectedness assessment as follows.
Total
UNE for
k POIs sequence is computed as:
where
is the unexpectedness of the
i-th prescribed trip to the user and is determined by Equation (
3).
As for the serendipity measure, an extensive metric is required considering the goals of serendipitous recommendation are both relevance and unexpectedness. Instinctively, it is similar to the
F-measure from the document retrieval problem, which is regularly used to assess the trading-off performances. Subsequently, we defined a metric
RU by adopting
F-measure to balance relevance and unexpectedness.
Total
RU for
k POIs sequence is computed as:
where
Precision and
UNE are defined above for relevance and unexpectedness, respectively.
5.1.3. Baselines
To assess the performance of the designed model, we have chosen these four recommendation models.
POP. The popularity-based recommendation strategy produces results as per POIs, where we receive the number of check-ins that POIs need to quantify their popularity.
RAND. The random-based strategy arbitrarily suggests POIs to the applicants randomly.
KFN. This is [
37] a vanilla serendipity-oriented suggestion technique. Beginning with the center thought of KNN and turning KNN back to front, this methodology creates neighbors from maximally divergent users and afterward suggests trips that a user’s neighbors are well on the way to disdain.
HAES. This is [
38] also a serendipitous suggestion model. HAES characterizes a novel idea of versatility both for users and items to change the degree of serendipity and obtain a trade-off between accuracy and serendipity.
5.2. Overall Comparison
This part pursues a series of experiments. The exhibitions of different serendipitous trip recommendation approaches in terms of Total
Precision, Total
Recall, Total
NDCG, Total
UNE, and Total
RU are presented in
Table 3 and
Table 4. The difference between
Table 3 and
Table 4 is that
Table 3 represents the results for Tokyo City, and
Table 4 illustrates the results for New York City. It is apparent in
Table 3 and
Table 4 that SOTR significantly outperforms the other baselines when measured with Total
Precision, Total
Recall, Total
NDCG, Total
UNE, and Total
RU in both cities. In order to assess the execution of the proposed method more effectively, each experiment is repeated ten times, and the mean and variance of numerous outcomes are used to quantify the model’s performance.
The RAND technique gives the trip suggestion just by randomly irregular determination without extra data; thus, its precision is low yet steady. The POP popularity-based trip proposal technique produces results as per the well-known POIs. The POIs with which the user is not familiar are non-popular. We can find these POIs by the number of how many ratings are given to them in the dataset. If the number of ratings given to POI A is less than the number assigned to POI B, then we can predict that POI B is more popular than POI A. The KFN starts with the center thought of KNN and turns KNN back to front. This methodology makes neighbors of maximally different users and later suggests trips that a user’s neighbors generally choose to despise. The HAES performs much better than other baselines. The RAND has the highest Total
UNE. In
Table 3 and
Table 4, we will see the performance of these baselines and compare the performance with SOTP.
According to the results, SOTR can perform much better from all the baselines when estimated with Total Precision, Total Recall, Total NDCG, Total UNE, and Total RU for Tokyo and New York City. It shows that SOTR is decisive for the serendipitous trip recommendation.
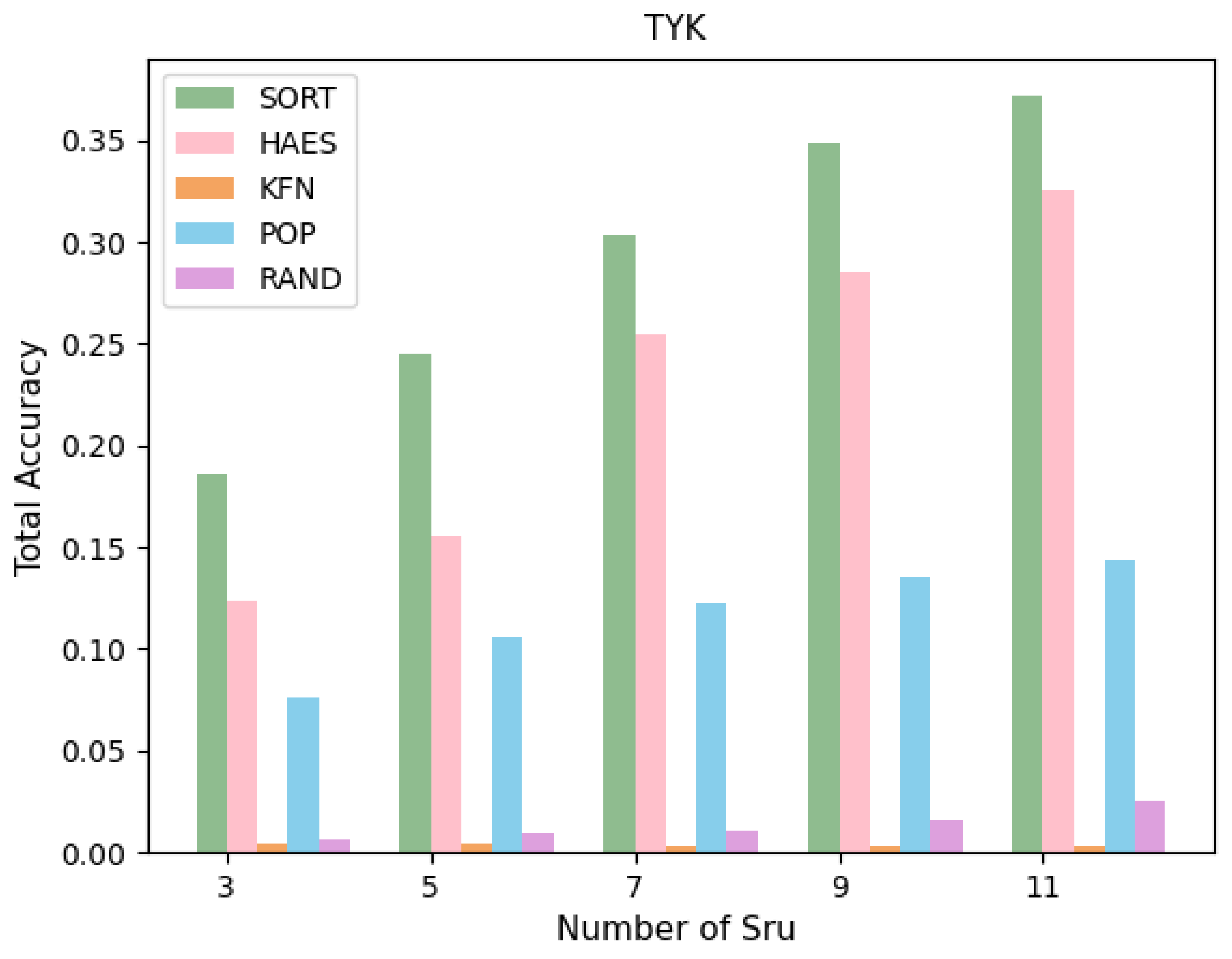
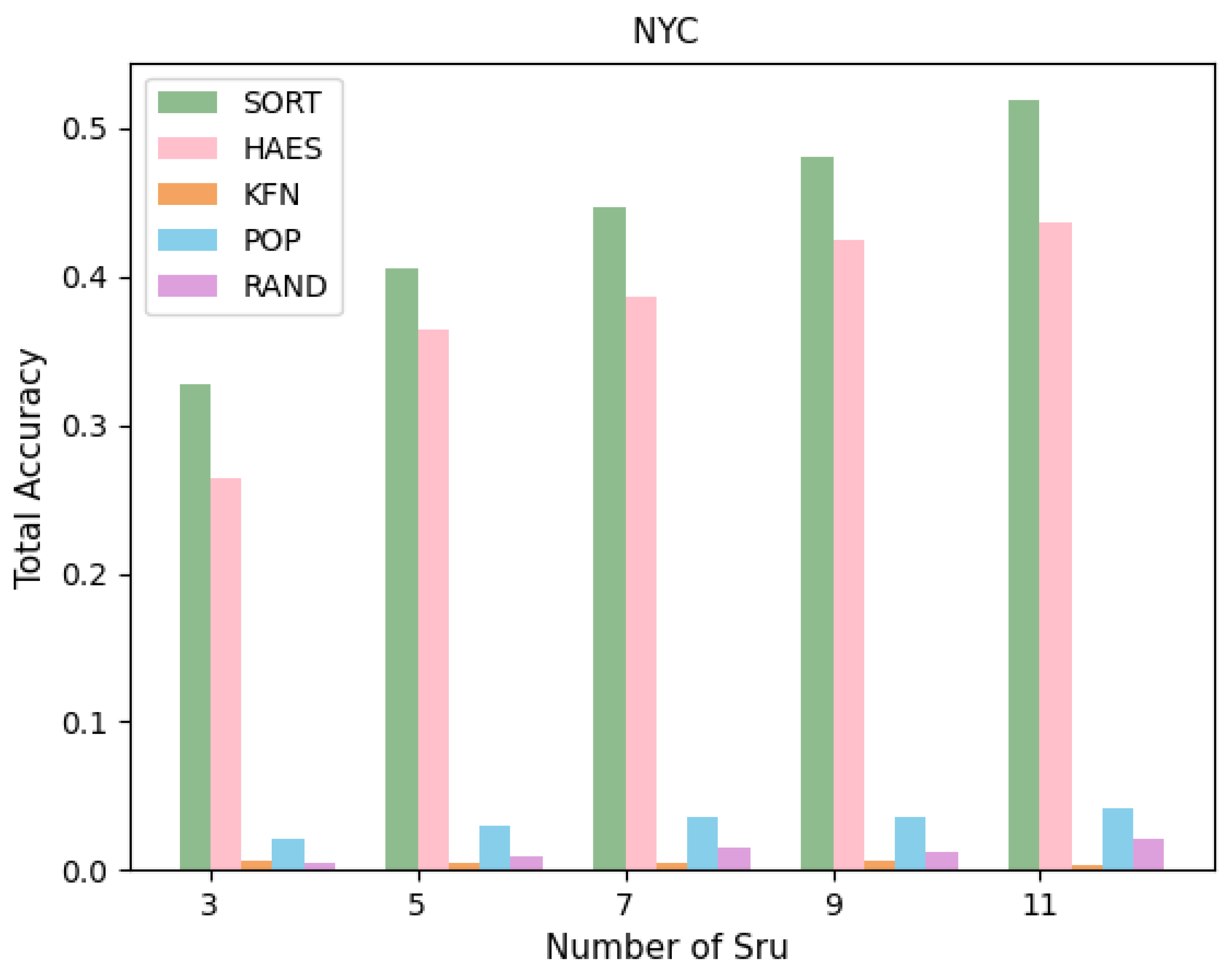
5.3. Effects of Hyperparameters
We have three hyperparameters in our experiments. The first hyperparameter is the number of POIs generated in the trip using serendipity features, such as relevance and unexpectedness Sru. The second hyperparameter is the number of POIs generated in the trip using the third feature of serendipity, a novelty Sn. The third hyperparameter is the support of novel POIs in the trip, which Ns characterizes. The support is the number of ratings given to POIs in the system. The maximum Ns of a POI in Tokyo City is 9493, and the maximum Ns of a POI in New York City is 496. From the number of ratings, we can know how much a specific POIs is popular. For novel POIs, we will select unpopular POIs because most users are not familiar with unpopular POIs, so we suggest them as novel POIs.
This part focuses on exploring the consequence of each of these hyperparameters on the results of experiments. We will change the value of these hyperparameters, respectively, to reveal the impact of the corresponding hyperparameters. The experimental outcomes have been represented in
Table 5 and
Table 6. We compare the results of
Table 5 with
Table 3 for Tokyo City and the results of
Table 6 with
Table 4 for New York City.
According to the results presented in
Table 5, when the value of
Sru decreases,
Sn increases, and
Ns increases. The Total
Precision and Total
RU comparatively obtain higher values, while Total
Recall, Total
NDCG, and
UNE comparatively obtain lower values. According to the results presented in
Table 6, when the value of
Sru decreases,
Sn increases, and
Ns decreases. The Total
Precision and Total
RU comparatively obtain higher values, while Total
Recall, Total
NDCG, and
UNE comparatively obtain lower values. This means that POIs
Sru and
Sn are the most valuable features in the serendipitous trip recommendation. Meanwhile, the
Ns is also effective at improving the model performance. The
Sru is the feature of serendipity. When we recommend an item using serendipity, it should not be relevant to users, and it must be an unexpected item. That is the reason why Total
UNE decreases when
Sru decreases and Total
Precision decreases when
Sru increases. Users should not be expecting that he/she will receive that recommendation. They must receive it unintentionally. It is challenging to characterize what serendipity is in recommender frameworks, what sort of trips are serendipitous, and why serendipity is a fantastic idea [
11,
39]. As indicated by dictionary1, serendipity is “the staff of making serendipitous disclosures unintentionally”. Conversely, Maksai et al. demonstrated that serendipitous items should be unexpected (astonishing) yet additionally valuable to a user: “Serendipity is the nature of being both surprising and helpful” [
39].
Cold-Start Scenario: The “cold-start” means that the situation is not yet suitable for the trip recommendation system to provide the best possible results. Trip suggestion frameworks consistently face the cold-start problem, where the trip proposal frameworks are inconvenienced by suggesting solid outcomes on account of the underlying absence of information. To solve that problem, we have introduced a novelty in our model.
Basically, serendipity consists of relevance, novelty, and unexpectedness. We have already explained the relevance and unexpectedness of our above experimental results. In novelty, we will check the users’ profiles that have no recorded history, and then we will recommend POIs that will be novel to them. Regarding addressing the cold-start problem here, novelty stresses whether the trip is obscure to the user. Trips unfamiliar to a user are generally unpopular. Users are frequently acquainted with popular trips, where popularity can be estimated by the number of ratings in the system. Basically, we can address the cold-start problem using novelty to recommend novel trips to the new users. It has been seen that the results of all baselines instead of RAND in a cold-start scenario are inadequate. We can see that POP is performing significantly worse in the cold-start problem because POP recommends the trip using the popularity of POIs. The KFN and HAES are better than POP because they also use serendipity to address the cold-start problem. However, SOTR is still remarkably worthier than the other baselines. Results of addressing the cold-start problem are presented in
Table 7 for Tokyo City and
Table 8 for New York City.
5.4. Ablation Analysis
As discussed above, serendipity is the combination of three elements—relevance, novelty, and unexpectedness. We have included serendipity in our trip recommendation to achieve user satisfaction.
The question arises of how we can achieve user satisfaction using serendipity in the trip recommendation. Serendipity has already been implemented in online shopping platforms. Serendipity is gaining popularity by recommending items according to users’ satisfaction. Therefore, we decided to implement serendipity in the trip recommendation system. Serendipity has been used in recommendation systems because of its remarkable features.
Serendipity recommends trips that can be relevant, novel, and unexpected to the users. Suggesting the appropriate and accurate location is not good sometimes. Users feel bored and lose excitement. Therefore, to address that problem, we have introduced serendipity in our trip recommendation system. What serendipity can achieve is finding trips that can make users surprisingly happy. Serendipity is the event and improvement of occasions by chance. It is the achievement of things that were not in the expectation [
16]. Serendipity helps us to make users excited and obtain users’ satisfaction efficiently.
Another element of serendipity is novelty. By using novelty, we can recommend novel trips to users. They are designated to permit users to find new and diverse trips to expand their perspectives. We address the cold-start problem using novelty. We recommend novel POIs to users having no recorded history. We define the essential concepts of modeling trips using serendipity.
In
Figure 3 and
Figure 4, we check the importance of serendipity by estimating the performance of SOTR compared with other baselines.
6. Conclusions
In this thesis, we have implemented trip recommendations for users using serendipity. We implemented a novel method named SOTR for personalized trip recommendation using serendipity. SOTR discovers users’ satisfaction based on relevance, novelty, and unexpectedness. We proposed a recommendation algorithm to efficiently plan the trip, maximizing the user experience. As far as we know, this is the first work on the personalized trip recommendation that considers the serendipity in deep detail with users’ satisfaction. Trip recommendation challenges lie in searching for the relevant, novel, and unexpected (with high satisfaction) Points of Interest (POIs) to plan a personalized trip. We have used serendipity in our trip recommendation. To deal with the challenges of discovering and evaluating user satisfaction, we proposed a Serendipity-Oriented Personalized Trip Recommendation (SOTR). A compelling recommendation algorithm should not just prescribe what we are probably going to appreciate yet additionally recommend random yet objective elements to assist with keeping an open window to different worlds and discoveries. Serendipity complements if the user feels astounded when he/she sees an appropriate proposal, which derives that the thing should not only be similar to the user’s benefits but also not intentionally looked at by a user. The serendipitous recommendation is progressively seen as being similarly significant to the other past precision goals (such as novelty and variety) in wiping out the personalized recommendation systems’ “filter bubble” phenomenon. We have checked the impact of serendipity on increasing the accuracy by ablation analysis. Some past precision goals, particularly variety, novelty, and serendipity, have been underscored in the new literature since they focus on permitting users to find unique and diverse trips to expand their viewpoints. The check-in datasets of two cities (i.e., New York in the U.S. and Tokyo in Japan) from perhaps the most delegated genuine LBSNs (i.e., Foursquare) are utilized in our experiment. This information was gathered from April 2012 to February 2013. We pre-handled both datasets. For POIs, we discarded the non-popular ones visited by under ten users. We treated their check-ins as a single trajectory made in one day for users. Then, we eliminated directions having under three check-ins and eliminated the new users with under five recorded histories. We show that our algorithm outperforms various benchmarks by satisfying user interests in the trips.
Future Work: We can extend future work to include the group of users and the bond among group members. We will check the bond or linkage among the group users and recommend a trip based on dynamicity and serendipity. An advanced sequence of the POIs recommendation model named Recommending Reforming Serendipitous Trip (RRST) model is proposed, suggesting a dynamic serendipitous trip to a group of users.
(1) A POIs sequence proposal intends to suggest a logically sound POIs succession that precisely meets the user’s advantage and inclination, rather than simply a solitary POIs; (2) users’ inclinations may change with time, which expands the trouble of dynamic suggestion; (3) POI succession proposal is more sensitive to different elements (e.g., spatial, fleeting, unmitigated, and so forth); (4) recommending the exact and accurate location makes the users bored. Looking at the same kind of POIs, again and again, is sometimes irritating and tedious.
The experimental outcomes will show that the proposed technique is compelling for POIs sequence recommendation tasks. We will compare the performance of RSTR with benchmark approaches such as LORE, LSTM-Seq2Seq, SNPR, SOTR, RRT, and Additive Markov Chain. In addition, overall experiments will be carried out using TensorFlow.
Author Contributions
Conceptualization, R.A. and G.A.A.; methodology, R.A. and G.M.H.; software, R.A., G.A.A. and A.A.A.B.; validation, H.A.-S., G.M.H. and G.A.A.; formal analysis, R.A. and G.A.A.; investigation, R.A., S.M.M.R. and M.A.-R.; resources, H.A.-S., T.A. and A.A.A.B.; data curation, R.A., T.A. and A.A.A.B.; writing—original draft preparation, R.A. and G.A.A.; writing—review and editing, R.A., G.A.A., M.A.-R. and H.A.-S.; visualization, R.A.; supervision, M.Z.; project administration, R.A.; funding acquisition, R.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Acknowledgments
This research was supported by the Researchers Supporting Project number (RSP-2021/206), King Saud University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no known competing financial interests or personal relationships that could have influenced the work reported in this advanced research.
References
- UNWTO. United Nations World Tourism Organization (UNWTO) Annual Report. 2015. Available online: http://www2.unwto.org/annual-reports (accessed on 10 March 2022).
- Lim, K.H.; Chan, J.; Leckie, C.; Karunasekera, S. Personalized trip recommendation for tourists based on user interests and points of interest visit durations and visit recency. Knowl. Inf. Syst. 2011, 54, 375–406. Available online: https://0-link-springer-com.brum.beds.ac.uk/article/10.1007/s10115-017-1056-y (accessed on 10 March 2022). [CrossRef]
- Lim, K.H. Recommending tours and places-of-interest based on user interests from geo-tagged photos. In Proceedings of the 2015 ACM SIGMOD on PhD Symposium, Melbourne, VIC, Australia, 31 May 2015; pp. 33–38. [Google Scholar] [CrossRef]
- Jiang, S.; Qian, X.; Mei, T.; Fu, Y. Personalized Travel Sequence Recommendation on Multi-Source Big Social Media. IEEE Trans. Big Data 2016, 2, 43–56. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/7444160 (accessed on 10 March 2022). [CrossRef]
- Lu, E.H.C.; Chen, C.Y.; Tseng, V.S. Personalized trip recommendation with multiple constraints by mining user check-in behaviors. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 209–218. [Google Scholar] [CrossRef]
- Choudhury, M.D.; Feldman, M.; Amer-Yahia, S.; Golbandi, N.; Lempel, R.; Yu, C. Automatic construction of travel itineraries using social breadcrumbs. In Proceedings of the 21st ACM Conference on Hypertext and Hypermedia, Toronto, ON, Canada, 13–16 June 2010; pp. 35–44. [Google Scholar] [CrossRef]
- Bolzoni, P.; Helmer, S.; Wellenzohn, K.; Gamper, J.; Andritsos, P. Efficient itinerary planning with category constraints. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 203–212. [Google Scholar] [CrossRef] [Green Version]
- Bin, C.; Gu, T.; Sun, Y.; Chang, L.; Sun, W.; Sun, L. Personalized Pois Travel Route Recommendation System Based on Tourism Big Data. 2018, pp. 290–299. Available online: https://www.springerprofessional.de/en/personalized-pois-travelroute-recommendation-system-based-on-to/15986358 (accessed on 10 March 2022).
- Porras, C.; Pérez-Cañedo, B.; Pelta, D.A.; Verdegay, J.L. A Critical Analysis of a Tourist Trip Design Problem with Time-Dependent Recommendation Factors and Waiting Times. Electronics 2022, 11, 357. Available online: https://0-www-mdpi-com.brum.beds.ac.uk/2079-9292/11/3/357 (accessed on 10 March 2022). [CrossRef]
- Wu, Y.; Li, K.; Zhao, G.; Qian, X. Long- and Short-Term Preference Learning for Next POI Recommendation. In Proceedings of the CIKM ’19 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2301–2304. [Google Scholar] [CrossRef] [Green Version]
- Iaquinta, L.; Semeraro, M.D.; Lops, P.; Semeraro, G.; Molino, P. Can a Recommender System Induce Serendipitous Encounters? INTECH. 2010. Available online: https://www.semanticscholar.org/paper/Can-a-Recommender-System-Induce-Serendipitous-Iaquinta-Gemmis/3f3c4a40ffeba4dde1d59a425f2729e1af072246 (accessed on 10 March 2022).
- Abbas, R.; Amran, G.A.; Alsanad, A.; Ma, S.; Almisned, F.A.; Huang, J.; Al Bakhrani, A.A.; Ahmed, A.B.; Alzahrani, A.I. Recommending Reforming Trip to a Group of Users. Electronics 2022, 11, 1037. [Google Scholar] [CrossRef]
- Baral, R.; Li, T. Exploiting the roles of aspects in personalized POI recommender systems. Data Min. Knowl. Discov. 2018, 32, 320–343. [Google Scholar] [CrossRef]
- Gavalas, D.; Konstantopoulos, C.; Mastakas, K.; Pantziou, G.; Vathis, N. Heuristics for the time dependent team orienteering problem: Application to tourist route planning. Comput. Oper 2015, 62, 36–50. Available online: https://0-www-sciencedirect-com.brum.beds.ac.uk/science/article/abs/pii/S0305054815000817 (accessed on 10 March 2022). [CrossRef]
- Zhang, M.; Yang, Y.; Abbas, R.; Deng, K.; Li, J.; Zhang, B. SNPR: A Serendipity-Oriented Next POI Recommendation Model. In Proceedings of the CIKM ’21: Proceedings of the 30th ACM International Conference on Information and Knowledge Management, Virtual Event, 1–5 November 2021. [Google Scholar] [CrossRef]
- Remer, T.G. Serendipity and the Three Princes. From the Peregrinaggio of 1557, Norman, U., Oklahoma P. 1965. Available online: https://www.worldcat.org/title/serendipity-and-the-three-princes-from-the-peregrinaggio-of-1557/oclc/1573702 (accessed on 10 March 2022).
- Iaquinta, L.; de Gemmis, M.; Lops, P.; Semeraro, G.; Filannino, M.; Molino, P. Introducing serendipity in a content-based recommender system. In Proceedings of the CIKM ’21: Proceedings of the 30th ACM International Conference on Information and Knowledge Management, Barcelona, Spain, 10–12 September 2008; pp. 168–173. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/4626624 (accessed on 10 March 2022).
- Adamopoulos, P.; Tuzhilin, A. On unexpectedness in recommender systems: Or how to better expect the unexpected. Acm Trans. Intell. Syst. Technol. 2014, 5, 1–32. [Google Scholar] [CrossRef]
- Gemmis, M.D.; Lops, P.; Semeraro, G.; Musto, C. An investigation on the serendipity problem in recommender systems. Inf. Process. Manag. 2015, 51, 695–717. Available online: https://0-linkinghub-elsevier-com.brum.beds.ac.uk/retrieve/pii/S0306457315000837 (accessed on 10 March 2022). [CrossRef]
- Kotkov, D.; Veijalainen, J.; Wang, S. Challenges of serendipity in recommender systems. In Proceedings of the 12th International Conference on Web Information Systems and Technologies, Rome, Italy, 23–25 April 2016; pp. 251–256. Available online: https://www.scitepress.org/Link.aspx?doi=10.5220/0005879802510256 (accessed on 10 March 2022).
- Kotkov, D.; Wang, S.; Veijalainen, J. A survey of serendipity in recommender systems. Knowl. Based Syst. 2016, 111, 180–192. Available online: https://0-linkinghub-elsevier-com.brum.beds.ac.uk/retrieve/pii/S0950705116302763 (accessed on 10 March 2022). [CrossRef]
- Chen, L.; Yang, Y.; Wang, N.; Yang, K.; Yuan, Q. How serendipity improves user satisfaction with recommendations? A large-scale user evaluation. In Proceedings of the WWW ’19: The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 240–250. [Google Scholar] [CrossRef]
- Zhang, C.; Liang, H.; Wang, K.; Sun, J. Personalized trip recommendation with poi availability and uncertain traveling time. In Proceedings of the CIKM ’15: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, VIC, Australia, 18–23 October 2015; pp. 211–220. [Google Scholar] [CrossRef] [Green Version]
- Choi, S.; Han, Y. A content recommendation system based on category correlations. In Proceedings of the 2010 Fifth International Multi-conference on Computing in the Global Information Technology, Valencia, Spain, 20–25 September 2010; pp. 66–70. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/5628890 (accessed on 10 March 2022).
- Vargas, S.; Baltrunas, L.; Karatzoglou, A.; Castells, P. Coverage and redundancy and size-awareness in genre diversity for recommender systems. In Proceedings of the RecSys ’14: Proceedings of the 8th ACM Conference on Recommender Systems, Silicon Valley, CA, USA, 6–10 October 2014; pp. 209–216. [Google Scholar] [CrossRef]
- Han, J.; Yamana, H. Geographic diversification of recommended pois in frequently visited areas. ACM Trans. Inf. Syst. 2020, 38, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Sun, K.; Qian, T.; Chen, T.; Liang, Y.; Yin, Q.V.H.N.A. Where to go next: Modeling long and short term user preferences for point-of-interest recommendation. AAAI 2020, 34, 214–221. Available online: https://ojs.aaai.org//index.php/AAAI/article/view/5353 (accessed on 10 March 2022). [CrossRef]
- Ranzhen Li, Y.S.; Zhu, Y. Next Point-of-Interest Recommendation with Temporal and Multi-level Context Attention. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1110–1115. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/8594953/ (accessed on 10 March 2022).
- Jarana Manotumruksa, C.M.; Ounis, I. A Contextual Attention Recurrent Architecture for Context-Aware Venue Recommendation. In Proceedings of the SIGIR ’18: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 555–564. [Google Scholar] [CrossRef] [Green Version]
- Zhao, P.; Zhu, H.; Liu, Y.; Li, Z.; Xu, J.; Sheng, V.S. Where to go next: A spatio-temporal lstm model for next poi recommendation. arXiv 2015, arXiv:1806.06671. [Google Scholar]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting human mobility with attentional recurrent networks. In Proceedings of the WWW ’18: Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1459–1468. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I.; Luxburg, U.V.; Bengio, S.; Wallach, H.M.; Fergus, R.; Vishwanathan, S.V.N.; Garnett, R. Advances in neural information processing systems. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Available online: https://www.bibsonomy.org/bibtex/2f57bdabad72b13b3aa06ce45107c62f7/lanteunis (accessed on 10 March 2022).
- Yang, D.; Zhang, D.; Zheng, V.W.; Yu, Z. Modeling user activity preference by leveraging user spatial temporal characteristics in lbsns. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 129–142. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/6844862/ (accessed on 10 March 2022). [CrossRef]
- Baral, R.; Iyengar, S.S.; Li, T.; Zhu, X. Hicaps: Hierarchical contextual poi sequence recommender. In Proceedings of the SIGSPATIAL ’18: Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 436–439. [Google Scholar] [CrossRef]
- Lin, I.-C.; Lu, Y.S.; Shih, W.Y.; Huang, J.L. Successive poi recommendation with category transition and temporal influence. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; pp. 57–62. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/8377830/ (accessed on 10 March 2022).
- Zhang, J.D.; Chow, C.Y.; Li, Y. Lore: Exploiting sequential influence for location recommendations. In Proceedings of the SIGSPATIAL ’14: Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2018; pp. 103–112. [Google Scholar] [CrossRef]
- Jain, B.J.; Albayrak, S. Usercentric evaluation of a k-furthest neighbor collaborative filtering recommender algorithm. In Proceedings of the CSCW ’13: Proceedings of the 2013 Conference on Computer Supported Cooperative Work, San Antonio, TX, USA, 23–27 February 2013; pp. 1399–1408. [Google Scholar] [CrossRef]
- Li, X.; Jiang, W.; Chen, W.; Wu, J.; Wang, G. HAES: A New Hybrid Approach for Movie Recommendation with Elastic Serendipity. In Proceedings of the CIKM ’19: Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Maksai, A.; Garcin, F.; Faltings, B. Predicting Online Performance of News Recommender Systems Through Richer Evaluation Metrics. In Proceedings of the RecSys ’15: Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2018; pp. 179–186. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}