1. Introduction
Face recognition algorithms are traditionally split into two specific tasks by the computer vision community: verification and identification [
1]. Different from face identification, face verification is a one-to-one comparison task; given a pair of images as input, a face verification system should predict if the input items contain faces of the same person or not [
2]. The computer vision community has broadly addressed the problem in both the 2D RGB and 3D domains [
3]. However, ordinary RGB cameras cannot obtain effective images in the case of a large variation of illumination. In addition, 2D RGB images lack stereo information and are more susceptible to interference from head pose and partial occlusion.
Recently, the computation of geometric descriptors of 3D shapes has played an important role in many 3D computer vision applications [
4]. In general, 3D objects are mainly represented by the following four methods: mesh, voxel grid, octree, and point cloud. However, the expression of mesh is complex, the voxel grid makes the space redundant, and the octree is complicated to use. In contrast, the point cloud can be directly used to represent 3D information, and the mathematical expression is very concise. With the improvement of depth map devices, obtaining effective point clouds has become easier. Depth maps have two main advantages. Firstly, the devices are stable with illumination changes. Secondly, depth maps can be easily exploited to manage the scale of the target object in detection tasks [
5]. However, compared with point clouds, depth maps have two disadvantages. First, depth maps are expressed in the form of single-channel 2D images, which cannot directly reflect the geometric characteristics of objects in a 3D space. Second, the contours of depth maps overlap with the surrounding pixels, which makes the contours unclear, and some important information will be lost. Relying on a simple coordinate transformation, depth maps can be converted into point clouds; therefore, point clouds inherit the above two advantages of depth maps and also keep clearer geometric characteristics. Furthermore, since the pioneering work of Charles et al. [
6], who constructed Pointnet, which solves the sparsity and disorder of point clouds, many deep learning models have been proposed, and point clouds now have more abundant applications.
In this paper, in order to reduce interference from head pose and partial occlusion, we rely on point clouds to construct a novel Siamese network for 3D face verification. In our method, we first obtain face information from depth maps and convert it to point clouds. Secondly, we construct a Siamese network to extract features. In this step, we adopt the farthest point sampling algorithm to sample points and employ two set abstractions to extract local-to-global face features hierarchically. Thirdly, in order to reduce the influence of the self-generated point clouds, we employ the chamfer distance to constrain the original point clouds and design a new energy function to measure the difference between two features.
In order to verify the performance of our method, we conduct experiments on two public datasets—the Pandora dataset and the Curtin Faces dataset. We also split the Pandora dataset into groups for cross-training and testing to verify the effectiveness of our method under pose interference and partial occlusion.
The main contributions of this paper are summarized as follows:
We propose an end-to-end 3D face verification network, which, to the best of our knowledge, is the first attempt to construct a Siamese network with point clouds for face verification.
We employ the charm distance to constrain the original point clouds, which can effectively improve the accuracy, and enables our network to better cope with the interference from head pose and partial occlusion.
The experimental results on public datasets show that our network has good real-time performance, and the verification accuracy outperforms the latest methods, especially under pose interference and partial occlusion.
2. Related Works
In recent years, the most widely used face verification methods have mainly been based on intensity images [
7]. Before neural networks became widely used for image tasks, most of the methods were based on hand-crafted features [
8]. With the improvement of hardware such as GPUs, more deep learning methods in neural networks have been applied to computer vision. Benefiting from the perceptual power of deep learning, most methods outperform humans on the LFW dataset [
9]. Among them, Schroff et al. [
10] constructed a network, FaceNet, which takes pairs of images as inputs and introduces a triplet loss to calculate the difference between images. In [
11], Phillips et al. designed a VGG-face algorithm to recognize faces as variables. Richardson et al. [
12] combined CoarseNet and FineNet and introduced an end-to-end CNN framework that derives the shape in a coarse-to-fine fashion. In order to avoid noise and degradation, Deng et al. [
13] explored a robust binary face descriptor, compressive binary patterns (CBP). Wu et al. [
14] proposed a center invariant loss and added a penalty to the differences between each center of classes to generate a robust and discriminative face representation method. Wang et al. [
15] introduced a more interpretable additive angular margin for the softmax loss in face verification and discussed the importance of feature normalization. To combat the data imbalance, Ding et al. [
16] combined generative adversarial networks and a classifier network to construct a one-shot face recognition network. Likewise, in order to deal with the imbalance problem, based on margin-aware reinforcement learning, Liu et al. [
17] introduced a fair loss, in which deep Q-learning is used to learn an appropriate adaptive margin for each class. Targeting racial and gender differences in face recognition, Zhu et al. [
18] combined NAS technology and the reinforcement learning strategy into a face recognition task and proposed a novel deep neural architecture search network. In order to deal with low-resolution face verification, Jiao et al. [
19] constructed an end-to-end low-resolution face translation and verification framework which improves the accuracy of face verification while improving the quality of face images. Recently, Lin et al. [
20] proposed a novel similarity metric, called explainable cosine, which can be plugged into most of the verification models to provide meaningful explanations. Aimed at facial comparison in a forensic context, Verma et al. [
21] employed an automatic approach to detect facial landmarks, and selected independent facial indices extracted from a subset of these landmarks. Cao et al. [
22] introduced two descriptors and one composite operator to construct a framework named GMLM-CNN for face verification between short-wave infrared and visible light.
Compared to RGB images, depth maps lack texture detail, but they cope well with dramatic light changes. Based on the depth maps, Guido et al. [
23] generated other types of pictures using a GAN network for head pose estimation. In [
7,
24], Ballota et al. utilized convolutional neural networks for head detection, marking the first time CNN was leveraged for head detection based on depth images. In recent years, many face verification methods based on depth maps have been proposed. Borghi et al. [
3] constructed JanusNet, which is a hybrid Siamese network composed of depth and RGB images. Subsequently, Borghi et al. [
2] used two fully convolutional networks to build a Siamese network, which only relies on deep images for training and testing and achieved very good results. Afterwards, Wang et al. [
25] adopted a one-shot Siamese network for depth face verification which significantly improved the accuracy. In order to reduce the interference from the head pose, Zou et al. [
26] projected the face features onto a 2D plane and introduced the attention mechanism to reduce interference from facial expressions. Rajagopal et al. [
27] introduced a CDS feature vector and proposed three levels of networks for face expression categorization. Wang et al. [
28] used
L2 to constrain facial features and constructed an L2–Siamese network for depth face verification.
Most of the proposed related 3D methods have achieved excellent performance. In order to solve the photometric stereo for non-Lambertian surfaces and a disordered and arbitrary number of input features, Chen et al. [
29] proposed a deep fully convolutional network PS-FCN to predict a normal map of the object in a fast feed-forward pass. Aiming at 3D geometry reconstruction and avoiding blurred reconstruction, Ju et al. [
30] proposed a self-learning conditional network with multi-scale features for photometric stereo. Similar to depth maps, surface normal maps can also provide 3D information for relevant tasks. The pioneers Woodham et al. [
31] proposed photometric stereo, which varies the direction of incident illumination between successive images while holding the viewing direction constant to recover the surface normal of each of the image points. Recently, Ju et al. [
32] presented a normalized attention-weighted photometric stereo network NormAttention-PSN, which significantly improved surface orientation prediction for complicated structures.
In the field of 3D point cloud vision, building on the innovation of Pointnet, Qi et al. [
6] solved the disorder and application in deep learning of point clouds; although many point cloud methods are proposed, this work only considered the global features and missed local features. Subsequently, Charles et al. [
33] improved Pointnet by extracting local features from a group of Pointnets. In order to solve the application of point clouds in convolutional neural networks, Li et al. [
34] proposed Pointcnn to learn
X-transformation, which is the generalization of typical CNNs into learning features. Guerrero et al. [
35] changed the first transformation of Pointnet and proposed PCPNet, which avoids the quality defects of the point clouds and reduces the interference of invalid points. The above works [
33,
34,
35] optimize the feature extraction of point clouds and maintain good real-time performance, but they did not consider the spatial geometric characteristics of original points. In PPFNet, Deng et al. [
36] applied a four-dimensional feature descriptor to describe the geometric characteristics of original point pairs. Zhou et al. [
4] constructed a Siamese point network for feature extraction and measured the difference between the original point clouds. Both [
4] and [
36] considered the spatial geometric characteristics of the original point clouds, but they adopted a matrix for registration, which is computationally intensive and time-consuming.
As mentioned above, many point-cloud-based networks have been proposed, and they have their own advantages. Due to these advantages, many face analysis methods are proposed. Recently, Xiao et al. [
37] constructed a classification network to guide the regression process of Pointnet++ for head pose estimation. Ma et al. [
38] combined a deep regression forest and Pointnet for predicting head pose. Cao et al. [
39] proposed a local descriptor to describe the projection of point clouds for 3D face recognition.
Face verification is a one-to-one comparison task taking into account both the effectiveness of feature extraction and real-time performance. Based on Pointnet, we construct a novel Siamese network and adopt the chamfer distance to constrain the geometric characteristics of the original point clouds.
3. Methods
For face verification with 3D point clouds, we convert the depth maps into point clouds, construct a Siamese network to extract the features of a pair of faces, and employ the chamfer distance to design the energy function to predict the similarity between the two faces.
3.1. Point Cloud Extraction
As described above, we transform depth maps to point clouds. This means converting depth data from an image coordinate system to the world coordinate system. Each pixel of a depth map represents the distance from the target to the sensor (in mm). In this step, we assume that the whole head information and head center
with its depth value
has been obtained (head detection and center localization are not the focus of our work). Firstly, removing the background, we set the pixel value, which is greater than
+
L to 0, where
L is the general amount of space for a real head [
24] (300 mm in our method). Secondly, according to Equation (1), we convert depth data to point clouds.
where (
x,
y,
z) is the point location in the world coordinate system, and
is the pixel position in the image.
and
are camera internal parameters which represent the horizontal and the vertical focal length, respectively. As shown in Equation (1), a point cloud is a list of points (represent in position (
x, y, z)) in a 3D space.
3.2. Siamese Neural Network
Siamese neural networks were first proposed and applied to the signature and verification certificate tasks by Bromley et al. [
40]. A Siamese network consists of two shared weight networks which accept distinct inputs and are joined by an energy function at the end. This energy function computes a metric between two high-level features. The parameters between the twin networks are tied, which can guarantee network consistency, and ensures that a pair of very similar features are not mapped to very different locations in feature space by the respective networks [
41].
The structure of the Siamese neural network is shown in
Figure 1. The input layer sends an object to the hidden layer which extracts object features. The ends of two networks are connected by an energy function in the distance layer which computes certain metrics between features based on task requirements. Output layers predict the result of the Siamese network.
3.3. Feature Extraction
As mentioned above, the essence of a point cloud is a list of points (
matrix, where
n is the number of points, and 3 represents (
x,
y,
z) in the world coordinates). Geometrically, the order of points does not affect its representation of the overall shape in 3D space. As shown in
Figure 2, the same point clouds can be represented by completely different matrices. In order to deal with the disorder of point clouds and their application in deep learning, Chen et al. [
6], based on the idea of symmetric function, constructed a deep learning model called Pointnet. The idea is to approximate a general function by applying a symmetric function:
where
f is a general function, which maps all independent variables
to a new feature space
.
h is another general function used to map each independent variable
to feature space
, and
g is a symmetric function (the input order does not affect the result).
r is also a general function which maps the result of function
g to the specific feature space
. According to Equation (2), the left part of the equation can be approximated by the right part. As described above, we adopt Pointnet to approximate the right part.
The structure of the network is shown in
Figure 3.
As shown in
Figure 3, where
n is the total number of points. We adopt three convolutional layers as the function
h in Equation (2) (convolution kernel is
, the filter is
k,
l,
m, respectively), which is used to map the feature of each point to the feature space
. Finally, according to [
6,
29,
30], a max pooling layer is adopted as the symmetric function,
g, which can solve the disorder of the features and extract the global feature in
.
As described above, only the global feature of the object can be obtained by Pointnet. There is no step to extract local features. Because point clouds lack a detailed texture, only global features lead to a limited generalization ability of the network, especially in complex scenarios. In order to improve the cognitive ability of the network, according to [
33], we adopt the set abstraction to extract the local-to-global features. The structure of a set abstraction is shown in
Figure 4. A set abstraction consists of the following three parts: sampling, grouping, and local feature extraction. For a point cloud
(the feature dimension of these points is
C), in order to sample uniformly, we first use the
farthest point sampling method to sample the points. In this step, we arbitrarily select a point
as the starting point and find the farthest point
from the point cloud, and put
into a new point set. Next, we regard
as a new starting point and find the farthest point in the rest of the points. We iterate the above steps until we obtain a new point set
with a fixed number
. Compared with random sampling,
farthest point sampling can cover the whole point set [
42].
Secondly, we group these points in ; in this step, we regard each point as the center of a sphere with radius K (our network contains two set abstractions with a K of 0.2 and 0.4, respectively), and points in the same sphere are grouped into one group. After this step, we obtain a new grouping set , and each group represents a local region of its own central point.
Finally, we use a Pointnet, as shown in
Figure 3, to extract features of each group, and obtain a set of local features
(the dimension of these features is
). We regard
as a new point set for the abstraction of the next step.
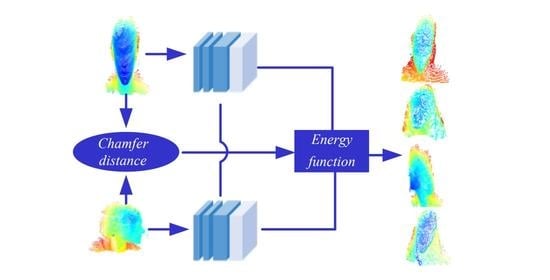
The process of our method is shown in
Figure 5, and we use a pair of completely parallel branches to extract head features separately. Each branch contains two set abstractions. The first set abstraction adopts Pointnet1 to extract local features, which has three convolutional layers, and the filter of each layer is 64, 64, 128, respectively. The second set abstraction adopts Pointnet2 to extract local features, which also has three convolutional layers, and the filter of each layer is 128, 128, 256, respectively. After the second set abstraction, each branch employs Pointnet3 (The filters of three convolutional layers are 256, 512, 1024) to extract the local-to-global features of the object.
In practice, although the furthest point sampling method samples uniformly, due to the unevenness of the point cloud, some groups have fewer points. During the grouping process, the density and sparseness of points will affect the feature extraction. Therefore, we use multi-resolution grouping to obtain the features of each layer.
As shown in
Figure 6, the features of a set abstraction are composed of two vectors. The left vector is the features of each group in this set abstraction. The right vector is the features of the original points of the previous layer for groups with sparse points which makes the first vector less reliable. Therefore, the second vector learns a higher weight during training. On the other hand, for groups with dense points, the networks obtain finer feature information, and the first vector learns a higher weight. In the training process, the network adjusts the weights in the above way to find the optimal weights for different point densities [
42].
3.4. Feature Constraint
Siamese networks measure the difference between high-dimensional features but lack a description of the difference between original point clouds. The chamfer distance can represent the original differences of point clouds and is widely used in point cloud reconstruction [
4]. In order to reduce the influence of the self-generated point clouds, we adopt chamfer distance (CD) to constrain their features. It is defined as follows:
where
represent two sets of point clouds.
measures the
L2 distance between points
p and
q. The first term represents the sum of the minimum distances from any points in
to
, whereas the second term represents the sum of the minimum distances from any points in
to
. If the chamfer distance is greater, two sets of point clouds are more distinct, and vice versa.
As mentioned above, the ends of the Siamese network are connected by an energy function which measures the difference between a pair of objects. Based on the chamfer distance, we design a new energy function to measure features, which is as follows:
where
C is a set of correspondence point clouds, which has a low chamfer distance (the threshold is 0.02 in our method).
is the feature extracted by our network, and
D is the Euclidean distance.
m is the margin value (the threshold is 0.7 in our method). The first term constrains the same objects closer in the feature space, and the second term leads different objects to have a large distance (greater than the margin value).
In face verification tasks, the
L2 distance is commonly used to measure the difference between two features. The whole energy function of our network is shown below:
where
is the
L2 distance between two objects.
is the ratio of the contribution of the
.
According to Equation (6), we adopt
sigmoid to map the value of energy function to probability distribution between (0, 1).
Face verification can be regarded as a classification task; our network uses cross-entropy as the loss function:
where
p(
x) represents the ground truth, when
p(
x) is 1, the pair of objects belong to the same object, and when
p(
x) is 0, the pair of objects belong to different objects. The
q(
x) represents the predicted value. The whole structure of our network is shown in
Figure 5; the chamfer distance is used to constrain the features of original point clouds, and a new energy function is used to measure the difference between objects.
In the selection of hyperparameters, the batch size is 64, the learning rate is 0.001, the decay rate is 0.99, and the decay step size is 500.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}