1. Introduction
OpenStreetMap (OSM), initiated in 2004, is a collaborative mapping project aimed at providing a map of the world in the form of a freely available database of geographic features that can be edited by anyone. OSM data resembles both volunteered geographic information (VGI), i.e., voluntarily contributed by members of the public, and crowdsourced data, i.e., obtained by enlisting the services of a large number of people, typically via the Internet [
1]. The OSM project came about to overcome issues with spatial data availability and restrictions on the use of proprietary data sets imposed by data producers such as national mapping agencies. To a large extent, OSM was prompted by the success of Wikipedia [
2]. With over 7 million registered users in 2021 [
3], the OSM database is quite impressive and hosts a vast amount of geographic information contributed by users from all over the world. It is one of the most well-known and successful examples of crowdsourcing and volunteered geographic information so that OSM data, as well as its contributors, have become focal points of research [
4,
5,
6,
7,
8,
9]. However, only very few studies have focussed on OSM data in Africa [
10,
11].
OSM makes it possible for anyone to contribute geographic information, regardless of their level of experience or skills. In developing countries, where geospatial data is often scarce, OSM can be valuable for filling data gaps, e.g., during a disaster response [
6,
10,
12]. Since the task of creating geographic information is no longer exclusively performed by trained professionals, data quality can be a concern and has been cited as a hindrance to its use [
12,
13]. OSM data quality has often been assessed extrinsically by comparing it to other reference datasets (see
Section 2.2). However, such reference data is not always available [
14] and some feature definitions (e.g., wetlands) are subjective. Therefore, intrinsic assessment methods have been employed to study OSM data quality, where the data itself or metadata about it is analysed.
For example, knowledge about contribution characteristics in a specific area can provide a better understanding of how volunteers contribute data and, therefore, insight into data quality. Analysing contributors and their contributions can answer questions, such as: What kind of contributors (e.g., experienced vs newcomers) have worked on the data in the area? In which areas should the data be validated, e.g., where have many newcomers or older non-recurring contributors worked? Several studies have analysed and characterised OSM contributors [
5,
15,
16], but none of these focussed on Africa. As the number of OSM contributors continues to grow, knowledge about their characteristics and the kind of data they contribute is increasing in importance, especially in Africa where reference datasets are typically not available.
In this study, contributions to OSM data in Mozambique were analysed. Mozambique lies in the south-eastern part of Africa (see
Figure 1) and has a sizable coastline of roughly 2700 km on the Indian ocean [
17]. Mozambique covers an area of 801,537 km
2, which makes it the world’s 36th-largest country, comparable in size to Turkey [
18]. Even though Mozambique’s rate of economic growth has shown significant increase over the past two decades, the country still faces development challenges and is ranked as one of the world’s most underdeveloped nations. The population is among the poorest and most vulnerable to climate conditions. Over 60% of the population lives in low-lying flood prone zones with poor drainage, inadequate sanitation and flimsy infrastructure (e.g., rural and informal dwellings). Due to its geography—namely, a vast coastline, low-lying terrain and tropical climate—Mozambique is often faced with droughts, tropical cyclones and flooding near the coast and in river basins [
17,
19].
In 2019, cyclones Idai and Kenneth caused significant flood damage and a subsequent humanitarian crisis in Mozambique. In response, the Humanitarian OpenStreetMap Team (HOT) initiated a large number of mapping projects in support of relief operations, which resulted in a significant amount of attention in the OSM community. Smaller OSM mapping projects, aimed at filling gaps in spatial data coverage in the country, have also taken place over the years. We chose Mozambique for our study because we expected many new and recurring users to have contributed OSM data over a relatively short and recent timespan in the aftermaths of cyclones Idai and Kenneth.
In order to get a better understanding of OSM data quality in Mozambique, we applied principal component analysis and k-means clustering, an unsupervised machine learning (also referred to as statistical learning) technique, to characterize contributors of OSM data in Mozambique. Based on the contributor characterization, conclusions are presented about the quality of the data in Mozambique. To our knowledge, this is the first contributor-focussed intrinsic assessment of OSM data quality for an African country that makes use of unsupervised machine learning.
In the next section of this paper, we review data quality and how it can be assessed, specifically if the data is contributed by volunteers. Then we explain how we analysed OSM contributors in Mozambique and present the results of our analysis. The paper is concluded with a discussion of the results and potential future work.
3. Method
The analysis was conducted in Python, making use of various Python libraries; namely, Pyosmium, Pandas, Numpy, and Scikit-learn. Pyosmuim provides a range of functions for handling OSM data (e.g., reading and writing). Pandas has a range of tools to load, prepare, manipulate and analyse data. The data was analysed in a Pandas dataframe. Numpy provides mathematical functions and the efficient handling of multi-dimensional arrays. Scikit-learn has machine learning functionalities and a set of data analysis capabilities; it was used for the principal component analysis and cluster analysis. The Matplotlib and Seaborn libraries were used for data visualization. The analysis was conducted on a Packard Bell Laptop with an Intel® Core™ i3-5005U CPU and 8GB RAM.
3.1. Step 1: Extracting Contribution Data from OSM History Data
First, OSM history data was downloaded and contribution data extracted. OSM data is available in two formats: eXtensible Markup Language (XML), published as BZIP2 compressed file; Protocolbuffer Binary Format (PBF). The complete copy of the OSM data contains the latest version of all features. The history file also includes any older versions of features and deleted features since the inception of OSM. The files are updated weekly on the Planet OSM website (
https://planet.openstreetmap.org, accessed on 9 March 2021). Due to the large size of the history file, it is advisable to work with a subset, provided by third parties. For this study, we downloaded the history file for Mozambique (in PBF format) from the Geofabrik website (
https://www.geofabrik.de/, accessed on 9 March 2021) where it is available to registered OSM users only. The file was downloaded in June 2019. The first contribution to Mozambique is dated 1 January 2006 and the most recent contribution has a date of 3 June 2019.
In OSM, geographic features are represented as nodes, ways and relations. For each feature, a set of attributes is stored: id (unique identifier), uid (last user to modify the feature), user (display name of uid), timestamp (time of last modification), visible (false means the feature is deleted), version (edit version of the object, initialized to 1 when the feature is created), and changeset (number of the changeset in which the feature was created or updated). Any edit to the feature results in an increment in the feature’s version number. A changeset consists of a set of changes made by a single user over a short period of time [
45].
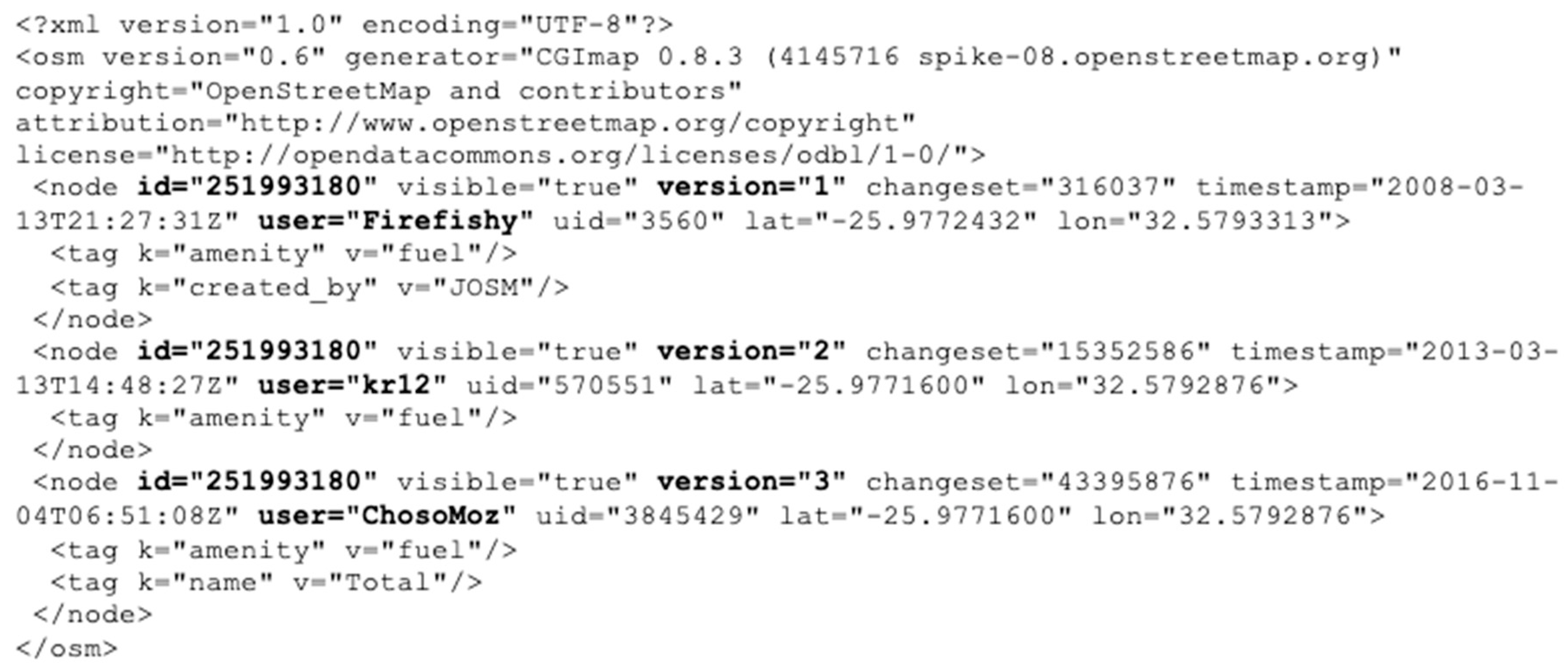
Figure 2 provides an example of three records for the same node (id = 251993180) in the OSM history file. A total of three contributors (Firefishy, kr12 and ChosoMoz) edited the feature in 2008, 2013 and 2016, respectively, each as part of a different changeset.
We followed the framework developed by Rehrl and Gröchenig [
40] for transforming OSM history data into user- and feature-centred actions that can be analysed for various research goals (e.g., change detection, contribution profiling, etc.) [
40,
46]. It describes how database changes (i.e., changes performed on OSM features) can be aggregated to construct information about how volunteers contributed (user-centred) and how features were impacted by these contributions (feature-centred). Aggregation is based on CRUD (create, read, update and delete): the changes (i.e., creating, updating and deleting features) performed on OSM features by contributors provide information about the editing actions of contributors.
We prepared three sets of attributes for analysing contributions. Firstly, contribution lifespan was determined from the first and last timestamp among all the feature edits by a specific contributor (user) in the Mozambique data. The lifespan reveals how long a user has been contributing to OSM. Users with a longer lifespan are likely to be more familiar and experienced with OSM contributions.
Secondly, information to provide insight into a user’s contribution intensity was prepared: the number of changesets (quantity) a contributor has worked on, the average contribution time spent on editing map features (based on the first and last timestamp associated with a changeset) and the number of mapping days (derived from the timestamp attributes of features edited by a specific user). Note that the changeset timestamps and, therefore, the value for time spent on editing map features, depends on the application used for contributing data. These attributes describe how active or involved someone is in OSM contributions.
Thirdly, the contribution actions of each contributor were determined based on the specific feature editing quantities (for nodes, ways and relations, respectively) and the feature editing preferences, i.e., the types of edits (creating, modifying or deleting features). These attributes describe how someone contributes to OSM, e.g., one can distinguish between a contributor who added a few points of interest (nodes) and a contributor who repeatedly edited ways and relations to improve the quality of a road network in an area.
Table 2,
Table 3 and
Table 4 show the 29 attributes prepared from the Mozambique history data, describing the contribution lifespan, contribution intensity and contributor actions of user 32,744, one of the most active users. For example, user 32,744 prefers to work mostly on nodes and tends to modify existing features more than creating new ones. The user has worked on 319 changesets with an average contribution time of approximately 18 min per changeset (as noted above, contribution times vary depending on the application used to make contributions). The user has contributed data in Mozambique for more than a decade on 176 mapping days. In total, 132,390 contributions were made.
3.2. Step 2: Classification of Contributors
In this step, contributors were clustered based on their contribution lifespan, contribution intensity and contributor actions.
Cluster analysis is an unsupervised machine learning technique for finding structure or revealing patterns in large, unexplored datasets [
47,
48]. It is frequently used for customer segmentation, i.e., to group customers based on the similarity of their purchasing habits and demographic characteristics [
49]. ‘Unsupervised learning’ refers to the fact that the algorithm works with unlabelled data (no predefined groupings) and attempts to ‘learn’ some sort of structure from the input data. This knowledge is used to partition the data into clusters or groups. The k-means clustering algorithm is one of the most favoured and efficient clustering algorithms [
47,
50,
51]. It groups a set of observations into k clusters, each with similar attributes, thereby measuring the similarity between observations and segmenting them based on similarities [
47,
50,
52].
In this study, k-means clustering was used to group contributors based on their contribution lifespan, intensity and actions in the Mozambique area. The next three paragraphs explain how feature scaling, principal component analysis and the elbow method were used as part of the k-means clustering.
Feature scaling is the process of normalizing ranges of data values to the same scale [
48,
53]. This has to be done before implementing a distance-based machine learning algorithm, such as k-means clustering, which is affected by scale [
53]. Feature scaling is also required before principal component analysis can be done.
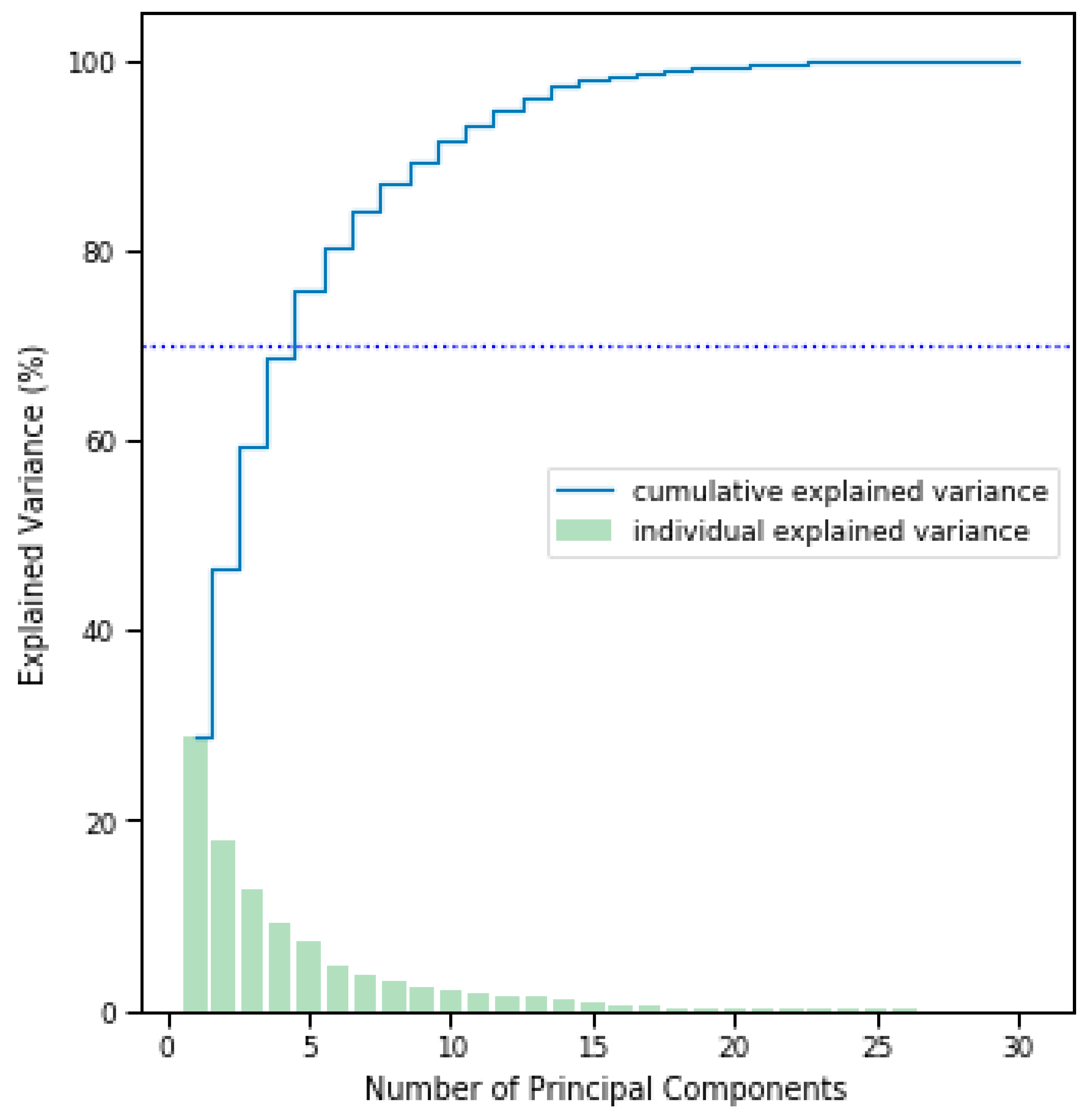
Clustering algorithms tend to struggle with high dimensional data, i.e., data described by many attributes [
54,
55,
56], because it increases computation time; the task of clustering becomes complex so that it is difficult to visualize and interpret clusters; data properties are not preserved because one cannot clearly differentiate between similar and dissimilar objects. To overcome these challenges, a dimensionality reduction technique, which describes the data in fewer attributes, was applied in our study prior to clustering [
50,
54,
55,
57].
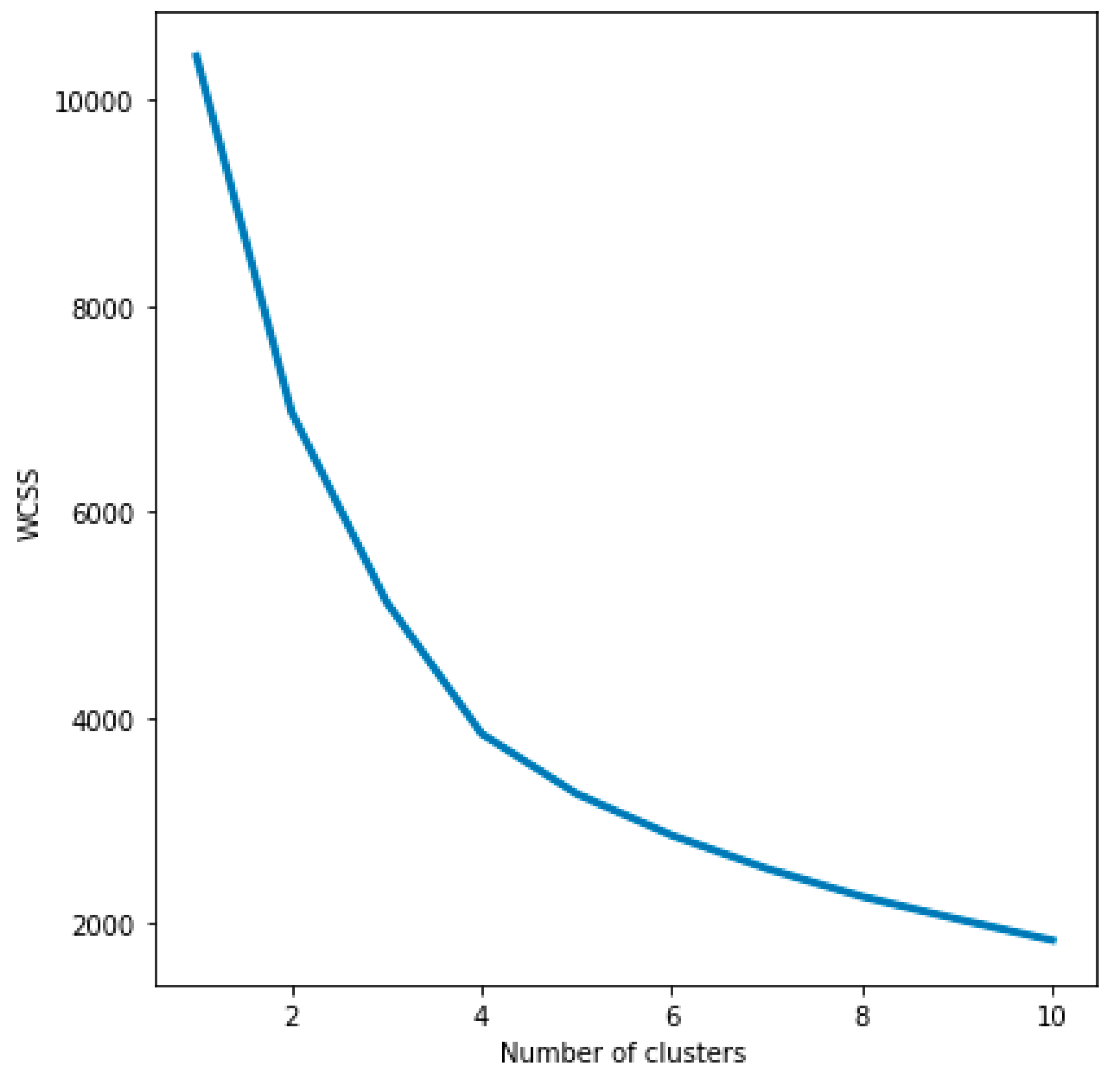
Selecting a suitable number of clusters for k-means clustering can be challenging [
55]. There are different ways of doing this and the researcher has to decide on a method [
57]. We decided to use the elbow method, one of the most widely adopted methods for determining an optimal number of clusters for k-means clustering. It uses the within-cluster sum of squares or WCSS (i.e., the distance between points in a cluster) to determine an optimal number of clusters for a dataset. To achieve an optimal clustering solution, the WCSS needs to be minimized. The WCSS tends to decrease as the number of clusters increases, however, the goal is not to have each data point in a separate cluster, i.e., where the number of clusters is equal to the number of observations, meaning WCSS = 0. The elbow method aims to find some sort of compromise (or middle ground), where WCSS is low enough but the number of clusters is also not too large. This value of WCSS is referred to as the “elbow” point: after the elbow point, the WCSS no longer decreases by a substantial amount as the number of clusters increases. That is, after the elbow point, a significantly better solution for WCSS would not be reached by increasing the number of clusters. By this logic, the optimal number of clusters lies at the elbow point [
58,
59].
5. Discussion
Senaratne et al. [
60] proposed the use of machine learning techniques for intrinsic data-focused quality assessment, e.g., cluster analysis to assess the thematic accuracy of volunteered geographic information. Kaur and Singh [
61] describe a solution for intrinsic detection and correction of OSM data errors that is based on supervised machine learning. Similar to our study, Jacobs and Mitchell [
33] applied the k-means clustering algorithm, an unsupervised machine learning technique, for classifying OSM contributors.
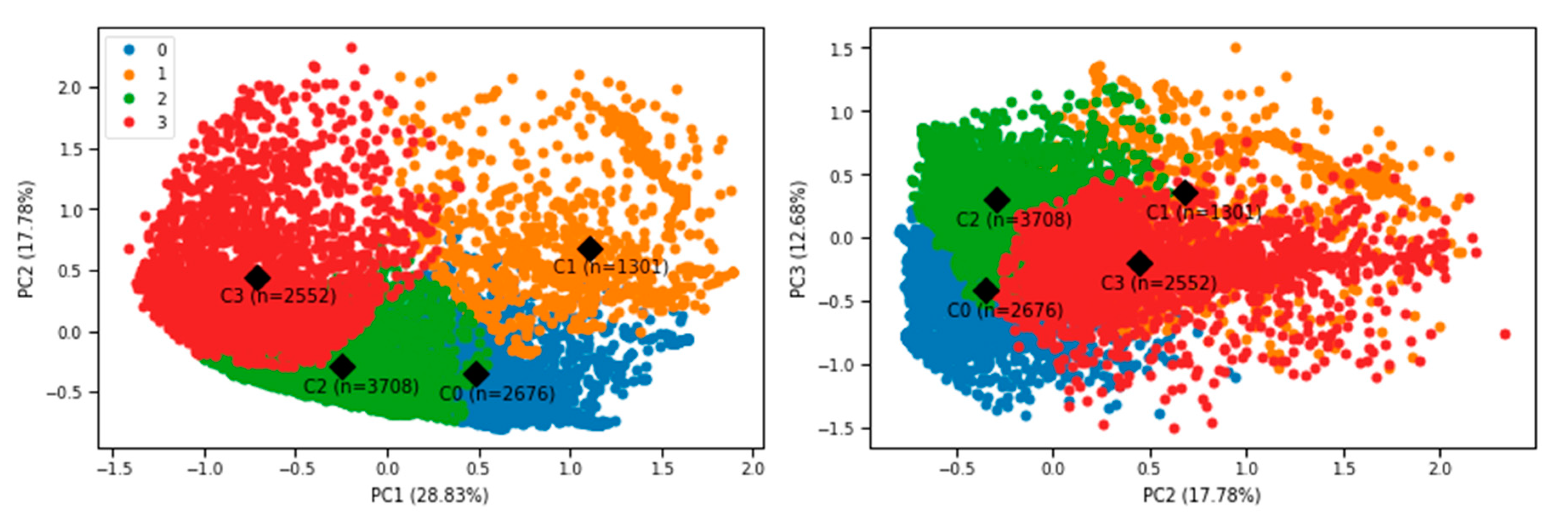
The patterns witnessed through clustering contributors in Mozambique show that most of the work (93%) is done by a small percentage (25%) of active contributors in cluster 3. These results are consistent with similar OSM contributor studies in other countries, e.g., in Canada [
4] and the United Kingdom [
35]. They display the “participation inequality” pattern that is often witnessed in online peer production systems, not only for OSM [
5,
14,
15], but also for others, such as Wikipedia [
62]. The active contributors in other studies tend to account for a much smaller portion of the total contributors (around 10 to 15%) [
5,
15], compared to the 25% in our study. Cluster 2 contributed 5%, while clusters 0 and 1 have virtually no impact (2%) on contributions.
Disasters tend to attract large numbers of new contributors who produce large amounts of data in a short amount of time and assist to satisfy informational needs of disaster relief services [
14,
23]. The contributions in clusters 2 and 3 are likely to have been influenced by the disaster mapping efforts following cyclones Idai and Kenneth. High numbers of contributions were observed mostly during the disaster activation mapping period in early 2019. Some contributors managed to produce thousands of contributions in a short span of time. The same is true for the contributors in cluster 2, the newcomers. This confirms what others have found; namely, that disaster events influence contribution patterns [
14].
However, it is important to note that not every contributor that is categorized as a new contributor in this study is new to OSM; some contributors could just be new to contributing in the Mozambique area, since this study is limited to Mozambique. Their contribution characteristics in other parts of the world could be very different, and future work could determine whether there are significant differences in contribution behaviour inside vs outside Mozambique.
Understanding the behaviour of a small group of active contributors makes it possible to characterize the quality of an entire dataset [
4]. Since most of the data in Mozambique originates from active contributors in cluster 3, who have on average worked on 90 changesets, confidence in the quality of the data is strengthened. Moreover, the small number of active contributors in cluster 3 tend to make a lot of modifications and are often the last user to edit a feature. This could be an indication of their desire to improve the quality of the data.
The majority of buildings (99.6%) and ways (84%) in Mozambique have been edited twice at most. This may reflect that any data contributed through projects in the HOT task manager is generally subjected to a validation process by experienced mappers. Most of the buildings appeared in areas for which mapathons were conducted, outside larger cities. Interestingly, Li et al. [
9] also analysed OSM data for Mozambique following the cyclones. They identified 13 built-up areas that were not yet included in OSM, suggesting that more mapping is required to improve completeness of the Mozambique data.
Almost all the contributors in the first three clusters had between one and three total mapping days. Contributors with only one mapping day make up the majority of these clusters (70% or more in each cluster). In contrast, only 22% of contributors in cluster 3 have only one mapping day. The contributors in cluster 3 with one mapping day could represent data imports, as they are associated with a significantly high number of changesets and contributions in a short span of time. This type of contribution needs to be approved (the process is described here [
63]); therefore, these kinds of contributions need further investigation. The nature of changesets and the set-up of a contributor’s application could affect how they submit changesets and, thus, the timestamps in the history file. Therefore, relying solely on time related metrics can skew the results, especially when focusing on a specific day or a short period of time. However, our analysis covered more than a decade of contributions (2006 to 2019); therefore, the uncertainty about changeset timestamps has a small effect on the results.
Some of the clusters revealed in this study align with categories that have been described in other studies, e.g., cluster 0 (non-recurring contributors) is comparable to the Non-recurring Mappers in Neis and Zipf [
15] and cluster 3 (active contributors) has similarities with the Power Mapper/Validator in Jacobs and Mitchell [
33]. Unproductive contributors (cluster 1) are identified in various studies (e.g., [
4,
5,
14]). Our results reveal a new category, namely, the newcomer contributors (cluster 2) who were most likely attracted to mapping in Mozambique by the HOT mapping projects. Understanding contributor behaviour in one geographic area can be used to assess data created by those contributors in another region [
4]. Analysing the characteristics of these Mozambique-newcomers in their ‘home’ regions could provide further insight into the quality of OSM data in Mozambique.
On average, the active contributors (cluster 3) in our study mapped in Mozambique for nine days on 90 changesets. Compared to OSM contributors generally, this is rather low. The OSM Foundation defines active contributors as those who edit on 42 days over a period of 365 days. To become an intermediate mapper in the OSM Tasking Manager, one should have worked on 250 changesets. It would be interesting to know how active Mozambique contributors are in other parts of OSM. This could provide further insight into the quality of their Mozambique contributions.
One could further characterise the individual contributors in cluster 3 based on descriptive statistics, e.g., for lifespan, mapping days and contributions. This would further refine the understanding of who contributed what, when and how in Mozambique. Analysing the contribution characteristics of cluster 3 users in the whole of OSM would also help to improve the understanding of OSM quality in Mozambique.
Determining a suitable cluster solution can be a challenging task. The final cluster solution can be affected by several factors, including the data pre-processing techniques chosen (e.g., dimensionality reduction, normalization), the number of clusters selected, the method used to determine the number of clusters and the spread of the data. One would have to repeat this study with different pre-processing techniques, a different method for choosing the number of clusters and a different number of clusters to assess whether this would lead to differently characterized clusters. A limitation of our study is that we only used k-means clustering. A visual inspection of the four clusters shows that not all the clusters are spherical around the centroid. Other clustering algorithms should be explored to establish whether they are more suitable.
In this study, individual contributors were clustered; however, the nature of contributions depends on the types of features in an area and changes over time as the map matures [
14]. It would, therefore, be interesting to cluster changesets to understand contribution behaviour across different changesets. The study by Budhathoki and Haythornwaite [
5] is one of few that involves contributor input through a questionnaire; most contributor-focused intrinsic assessments are based on history data only. Combining questionnaires with an analysis of OSM history data could help to explain the results of contributor-focused intrinsic assessments and could guide the development of more reliable contributor-focused intrinsic assessment metrics. Another avenue of future work would be to analyse the spatial collective intelligence [
64] of contributors in Mozambique.
6. Conclusions
In this study, we applied unsupervised machine learning to get a better understanding of who contributed when and how to OSM data in Mozambique. The results of the k-means cluster analysis revealed four distinct classes of contributors: active contributors (n = 2552); older non-returning contributors (2676); least productive contributors (n = 1301); new contributors (n = 3708). This is the first segmentation of OSM contributors for an African country using unsupervised machine learning.
Similar to the results of other OSM contribution analyses, most of the data generated in Mozambique (93%) was contributed by a small group of active contributors (25%). Studies have suggested that such active contributors are more likely to be experienced and knowledgeable about the project and are, therefore, more likely to produce data that is of good quality [
16,
23]. Compared to other contributor classifications, our cluster analysis revealed a new kind of contributor class, namely, the new contributors. Active and new contributors were most likely attracted by HOT mapping events during the cyclone-related disaster relief operations in Mozambique in 2019.
Even though no absolute statements can be made about the quality of the Mozambique OSM data, the results of our contributor-focused intrinsic quality assessment strengthen confidence in the quality of the data because it is mostly contributed by experienced users who seem to have a desire to improve the quality of the data. Most features in Mozambique were edited at least twice, suggesting that they have been quality checked at least once. Initiatives to improve the quality of OSM data in Mozambique should prioritize data edited only once and contributed by those classified into clusters 0, 1 and 2.
More studies in different parts of Africa would contribute to understanding whether the patterns observed in Mozambique are unique or also found in other parts of the African continent and/or in developing countries in other parts of the world. One could also analyse contribution inequality between different (African) developing countries, similar to Yang et al. [
65], who found that the level of contribution inequality increases in countries without huge imports.
The results of this study show how one can gain a better understanding of the community that contributes data in a specific area by inspecting history data with machine learning techniques, and we have provided some suggestions for further work. Intrinsic methods should not replace ground truthing or extrinsic methods, but rather complement them by providing alternative ways to gain insight about data quality. Results of intrinsic quality assessments can also be used to inform efforts to further improve the quality.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}