
Automatic Building Detection with Polygonizing and Attribute Extraction from High-Resolution Images


Abstract
:1. Introduction
- Proposing a modified version of U-Net architecture for building detection;
- Determining the effect of image pre-processing using image-enhancing algorithms for the building detection accuracy of DL models;
- Developing a post-processing technique that makes the building output directly ready to use for different applications by polygonizing the building detection results with more regularized building footprint boundaries; and
- Extracting different attribute categories into the building footprint polygon layer by incorporating other data sources and basing it on the building geometry.
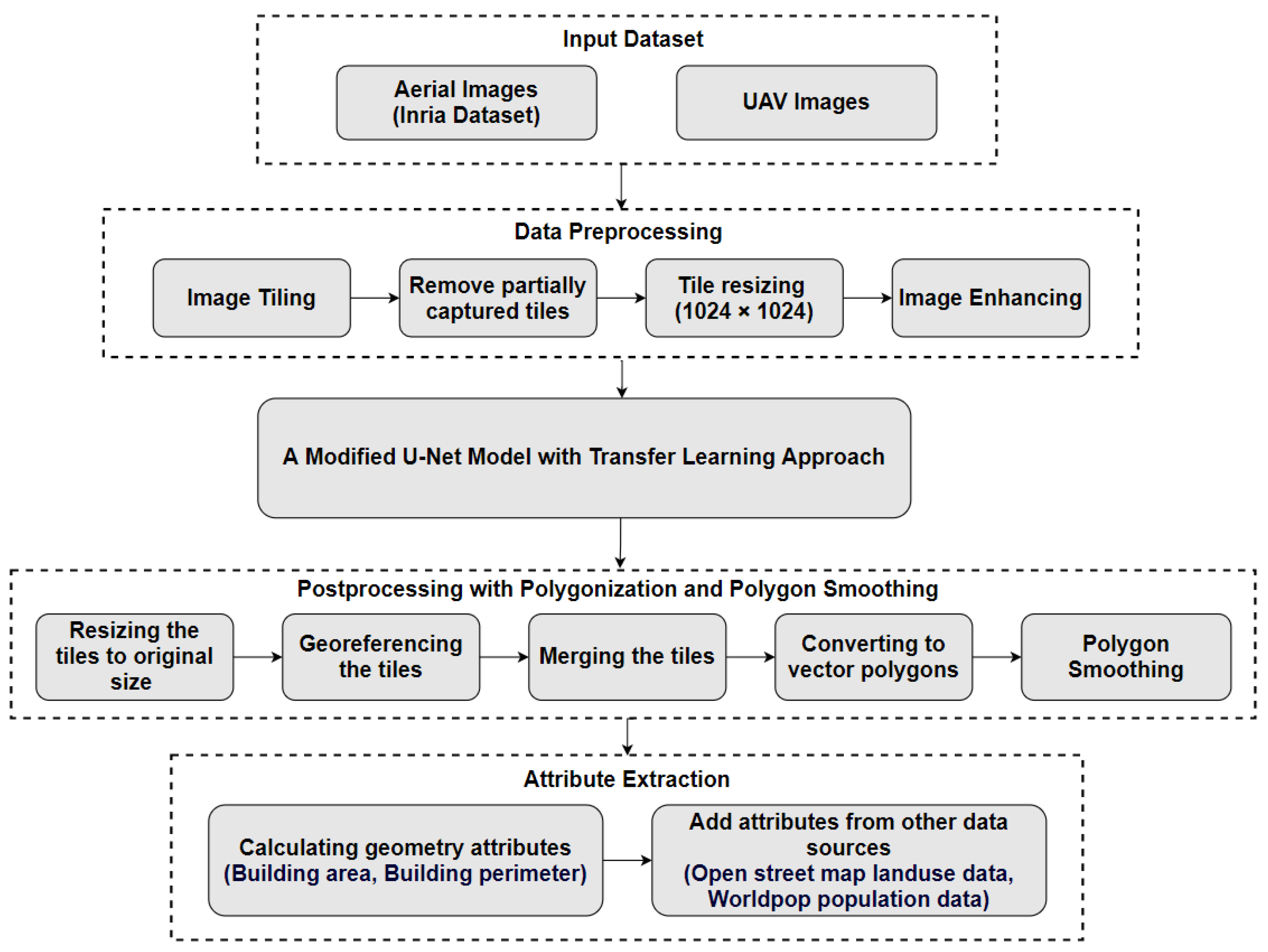
2. Materials and Methods
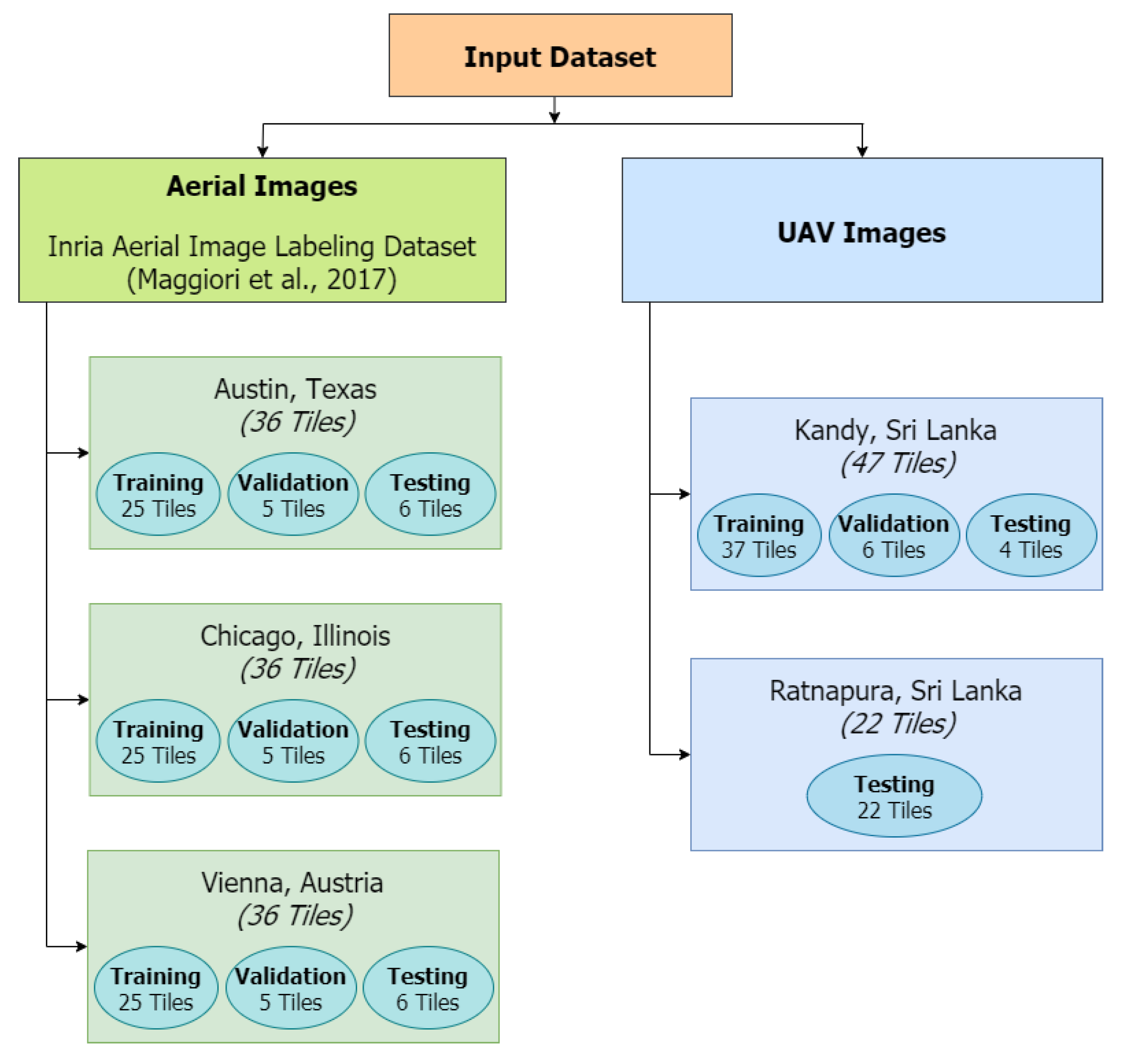
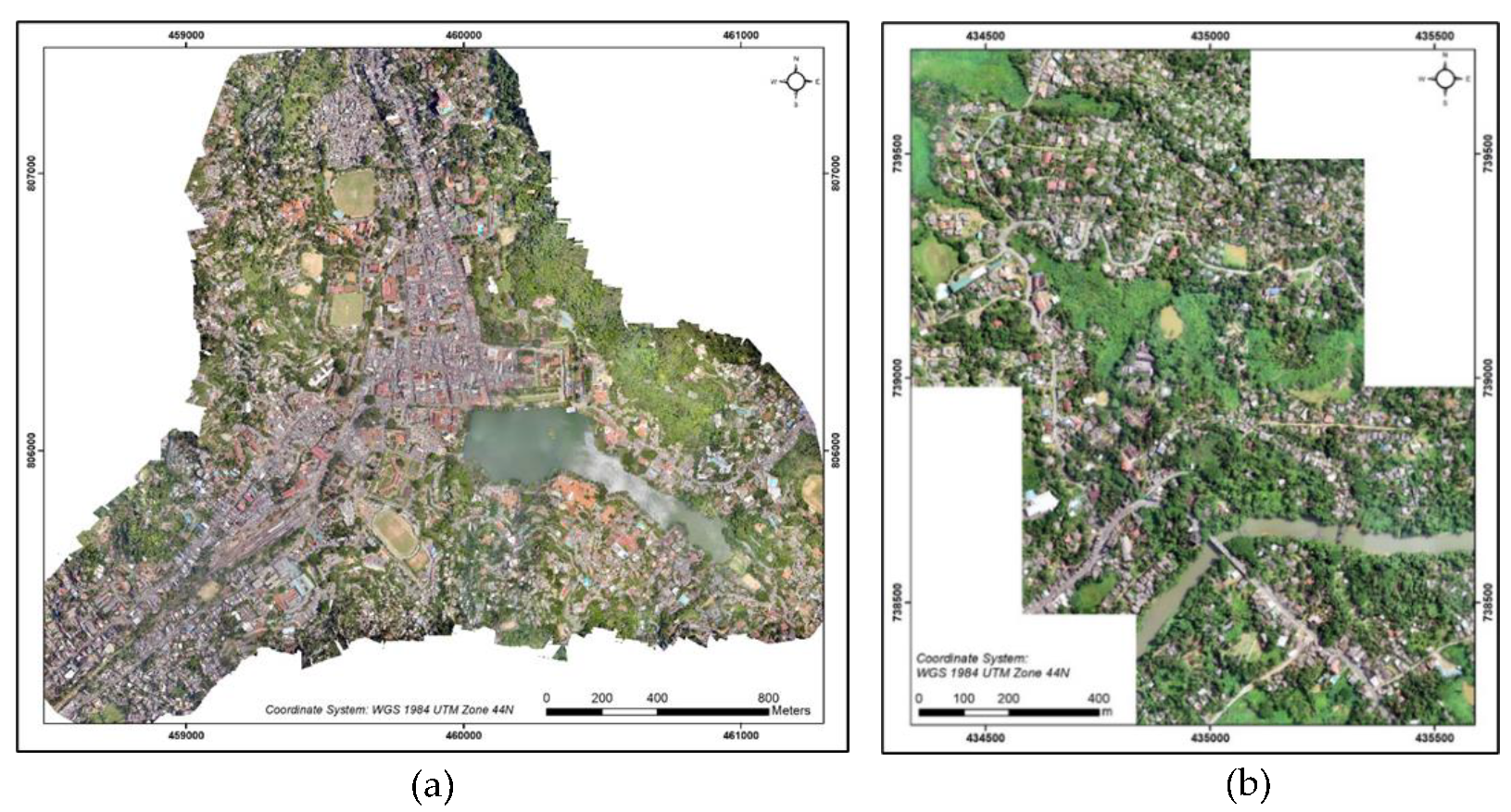
2.1. Dataset Selection and Study Area
2.2. Data Pre-processing
- Tiling the two UAV Orthomosaics of Kandy and Rathnapura into 5000 × 5000 pixel tile sizes;
- Removing partially captured images from the two UAV datasets;
- Converting the building polygon shapefiles of the above two areas into raster data corresponding to image tiles;
- Resizing all the tiles of both aerial images and UAV images into a 1024 × 1024 pixel size; and
- Creating four training datasets by applying four different image-enhancing algorithms: gamma correction [32], histogram equalization [33], contrast limited adaptive histogram equalization (CLAHE) [33], and logarithmic correction [34]. These techniques were selected because they are widely used for remote sensing images to enhance brightness, contrast, and color adjustments.
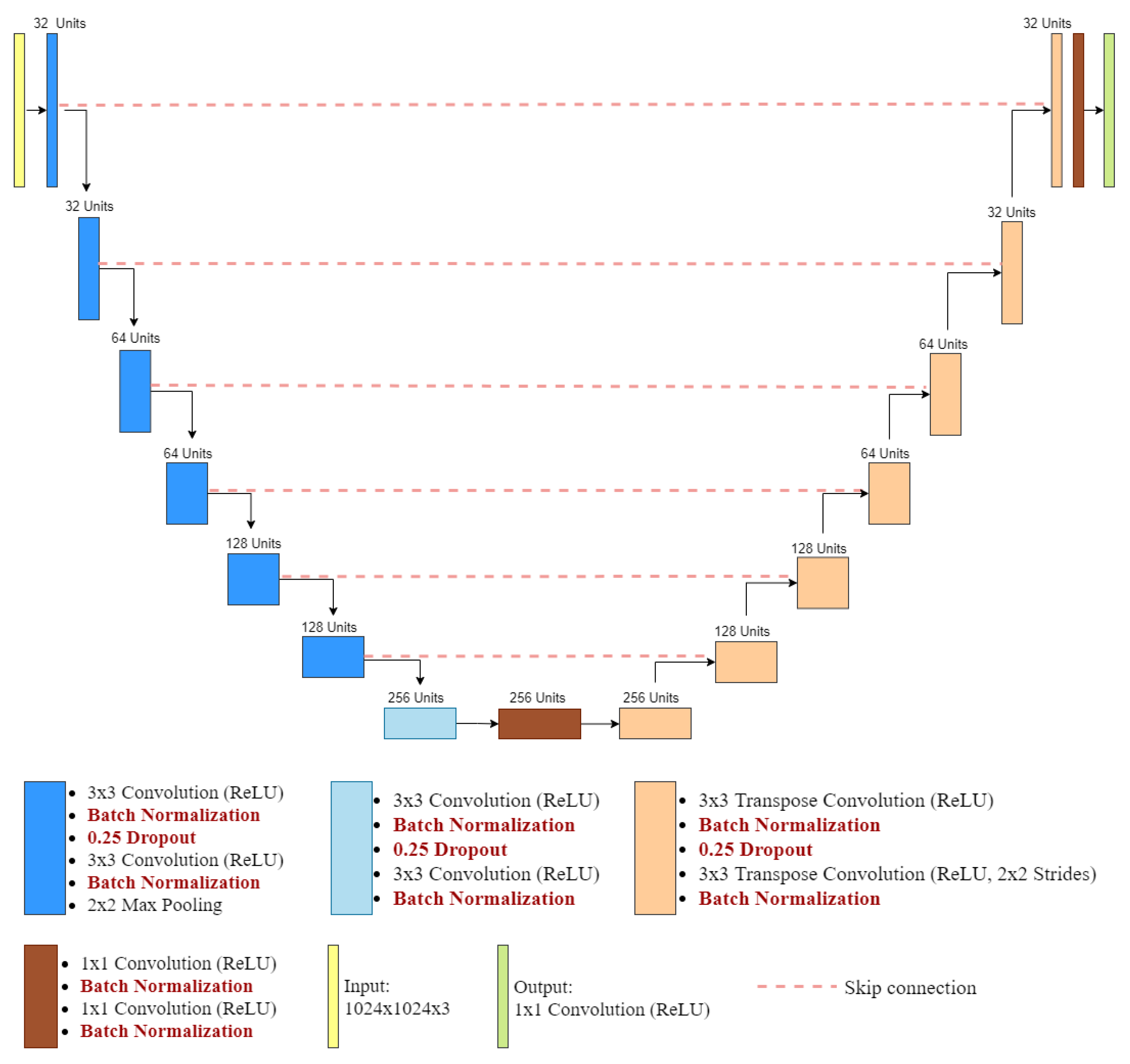
2.3. Proposed Neural Network Architecture: A Modified U-Net Model
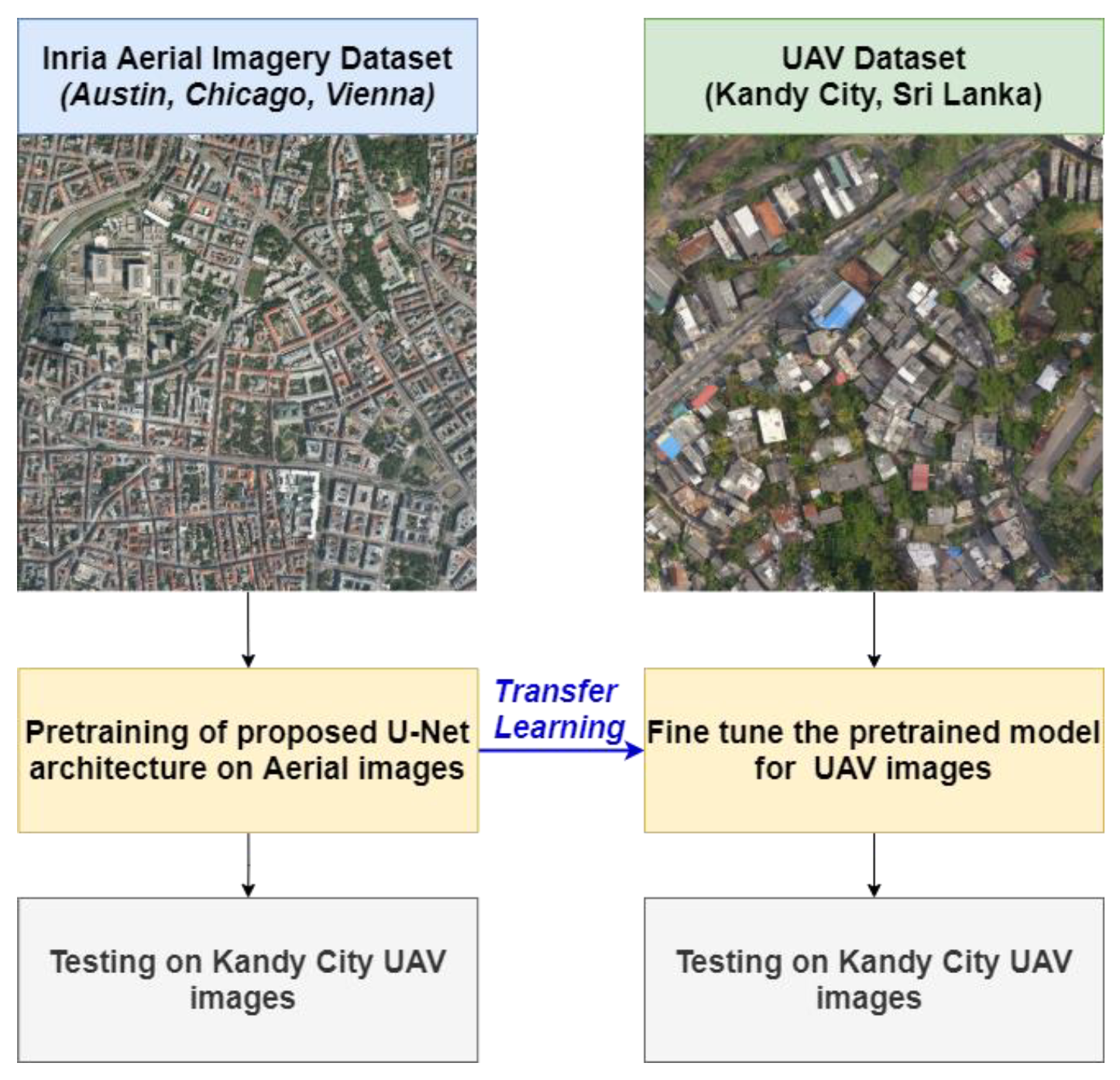
2.4. Transfer Learning Approach for Building Footprint Extraction from Different Data Sources
2.5. Post-Processing with Polygonization and Polygon Smoothing
- Georeferencing building prediction raster tiles using coordinate information of the corresponding input tiles;
- Merging the georeferenced building prediction tiles city-wise to create a complete building mask raster layer for each city;
- Converting merged raster layers into a building polygon shapefile format; and
- Testing with three polygon smoothing algorithms with different smoothing ratios to determine which smoothing algorithm yields the best results:
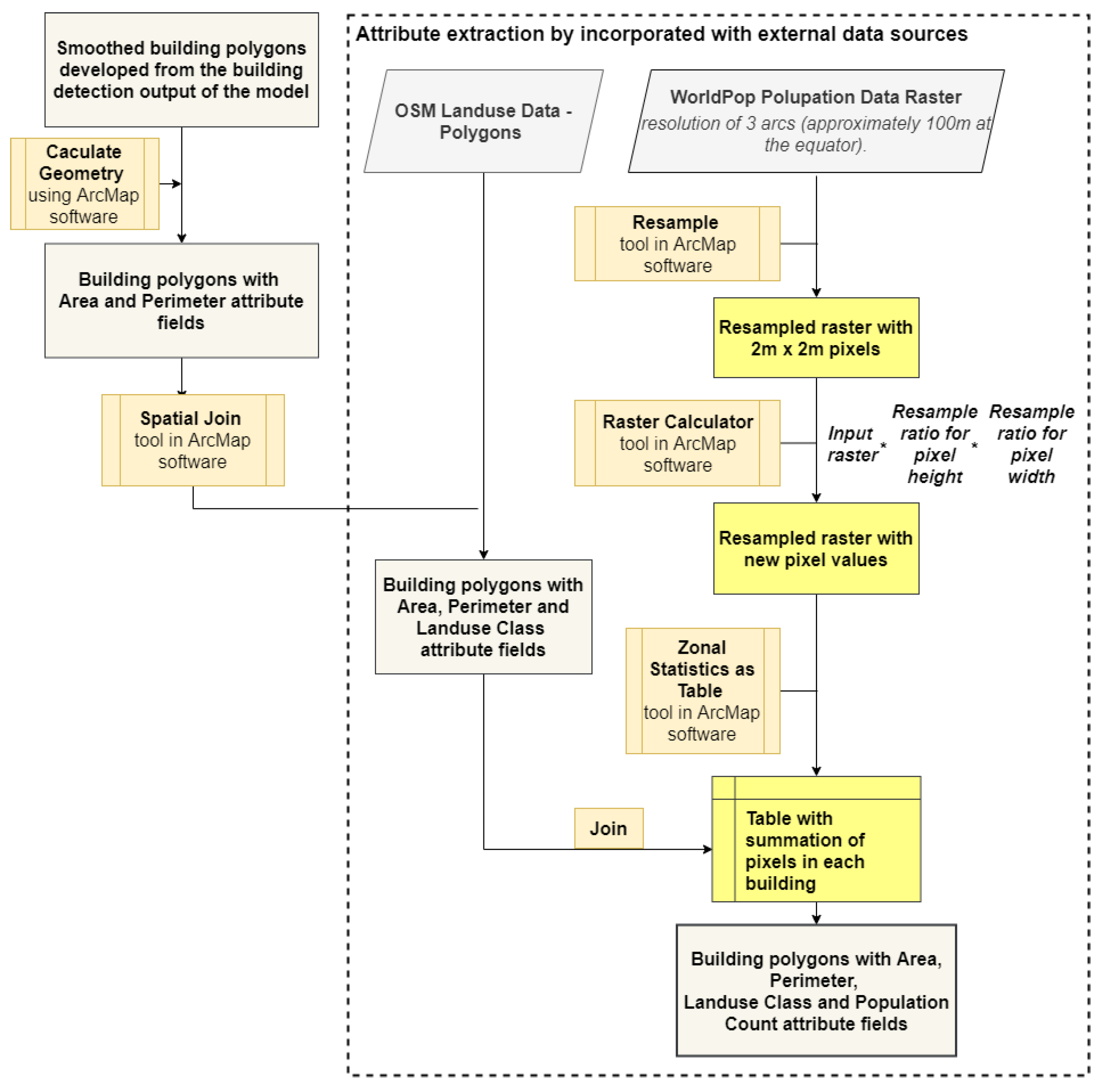
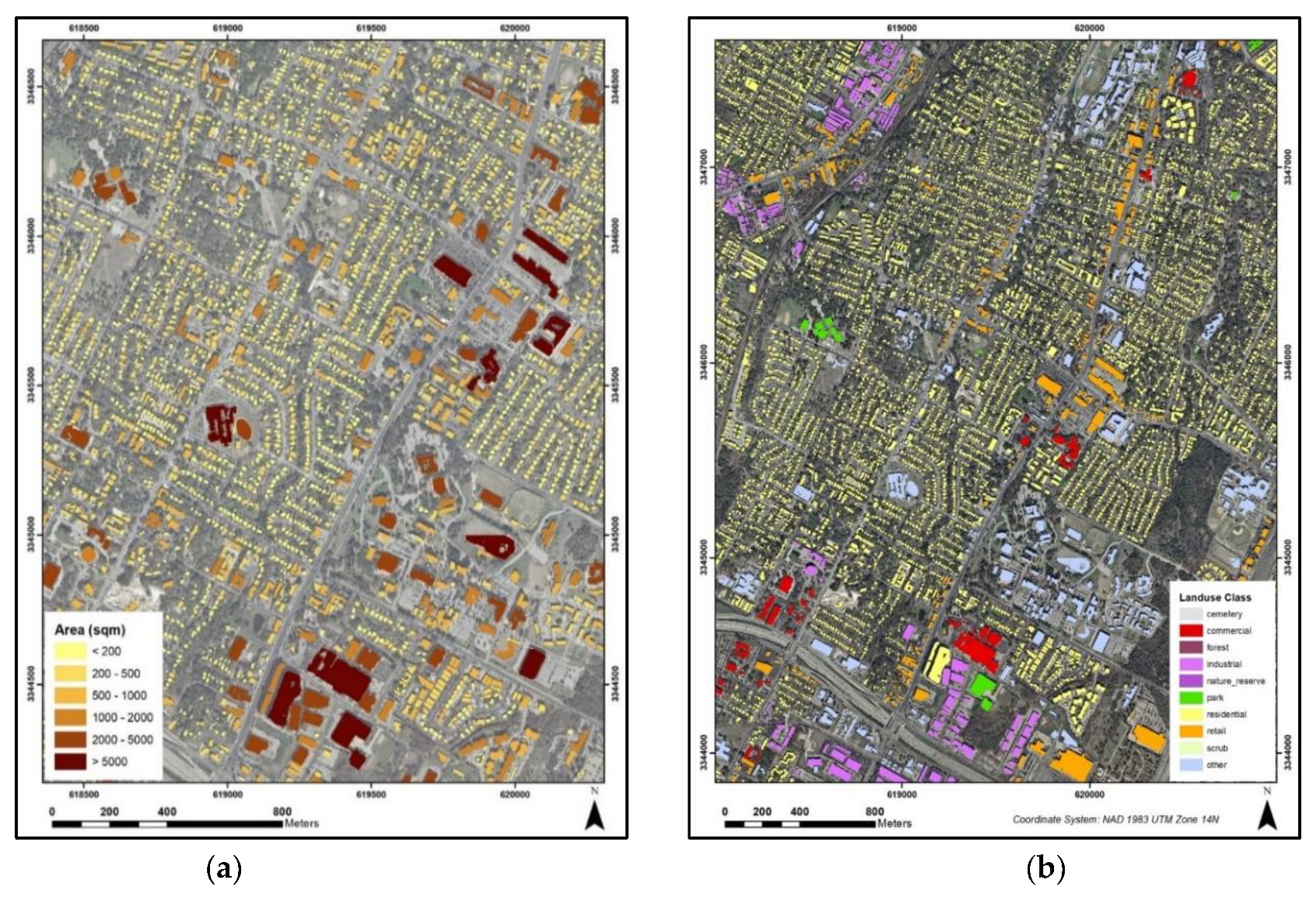
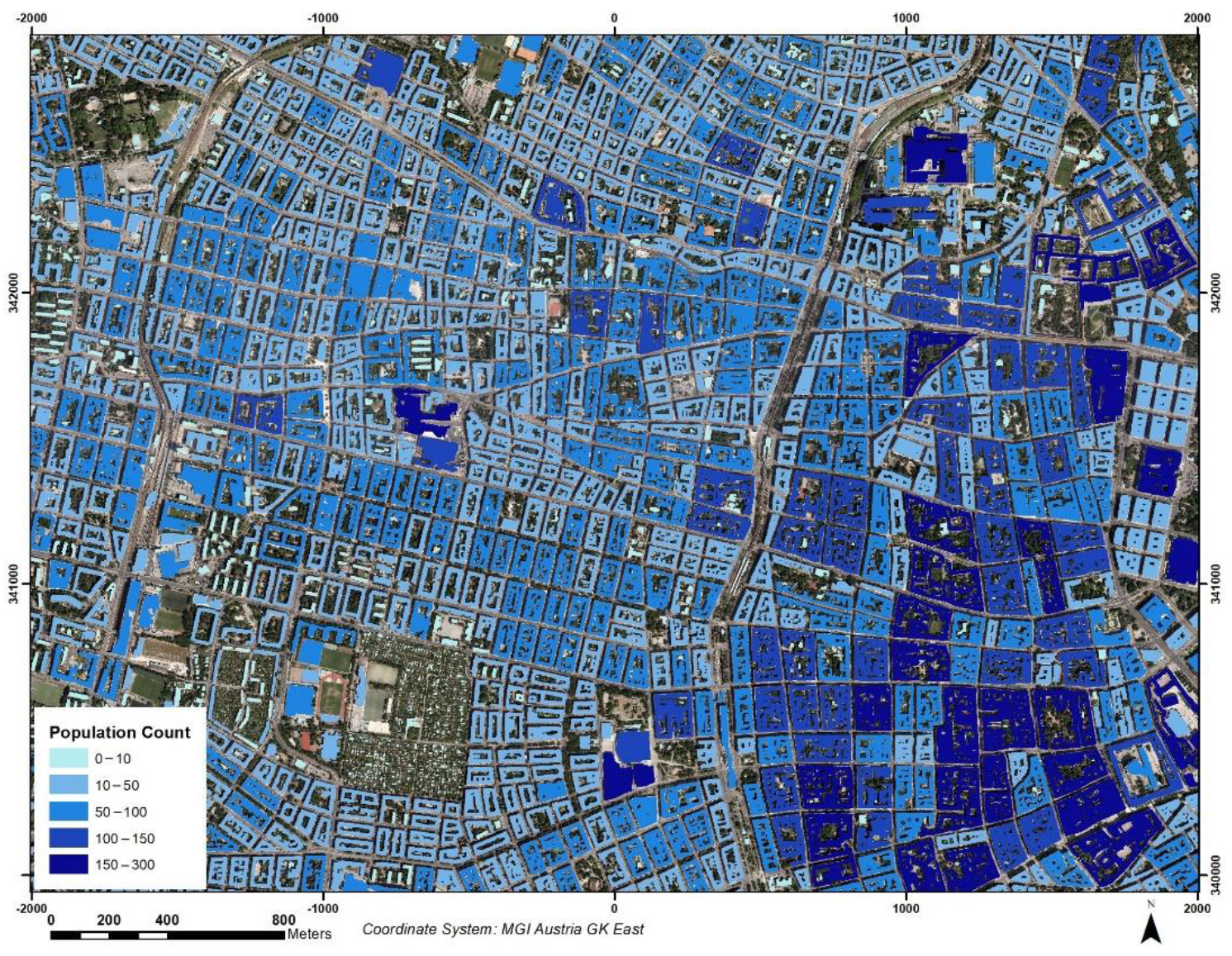
2.6. Attribute Extraction
3. Results
- Total training time: 124 min;
- Number of epochs: 200;
- Batch size: 2;
- Loss function: weighted root mean square error;
- Optimizer: Adam;
- Total parameters of the model: 4,241,089;
- Input image size: 1024 × 1024 RGB images;
- Output image size: 1024 × 1024 building mask images;
- Total images: 155.
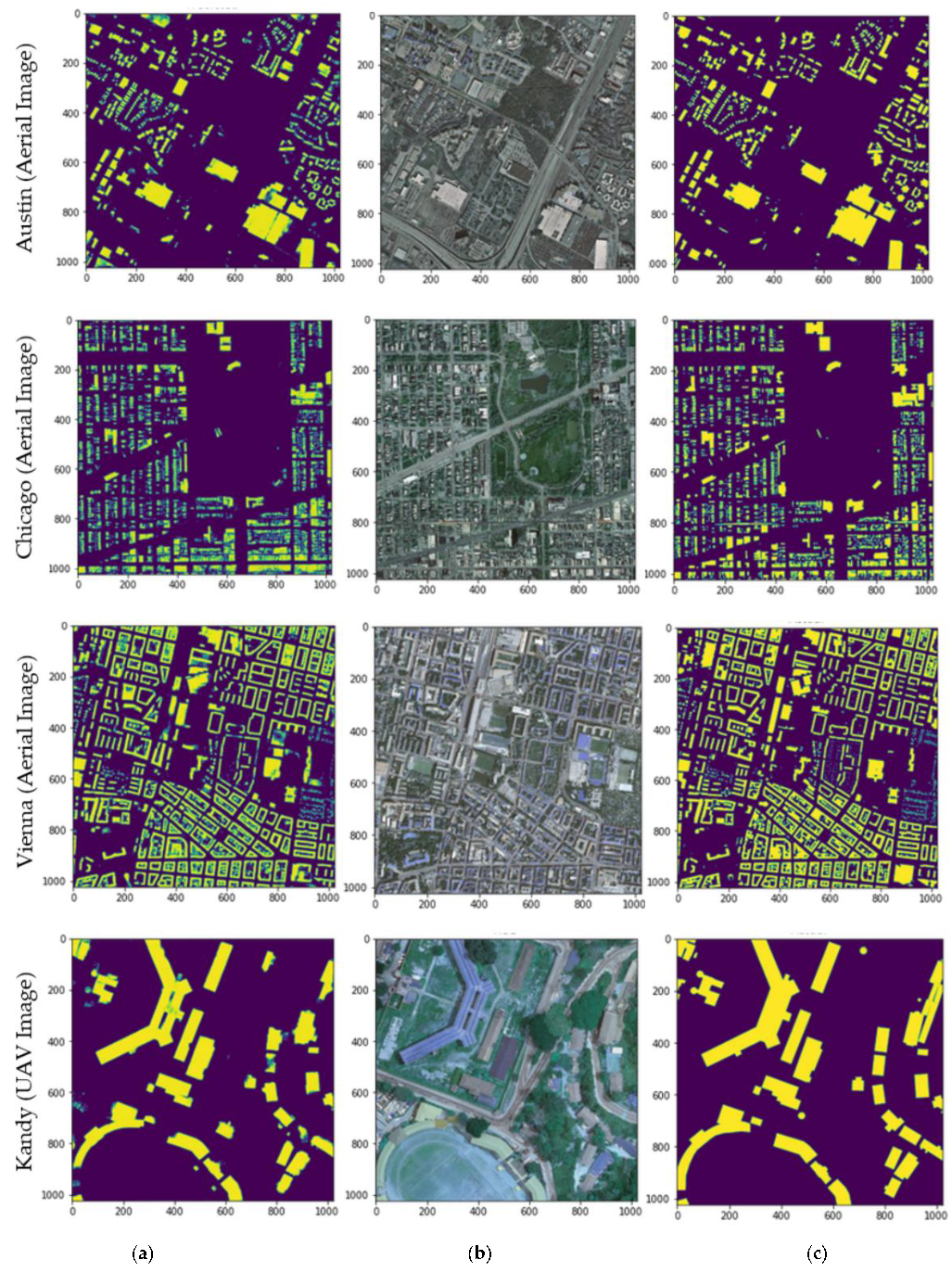
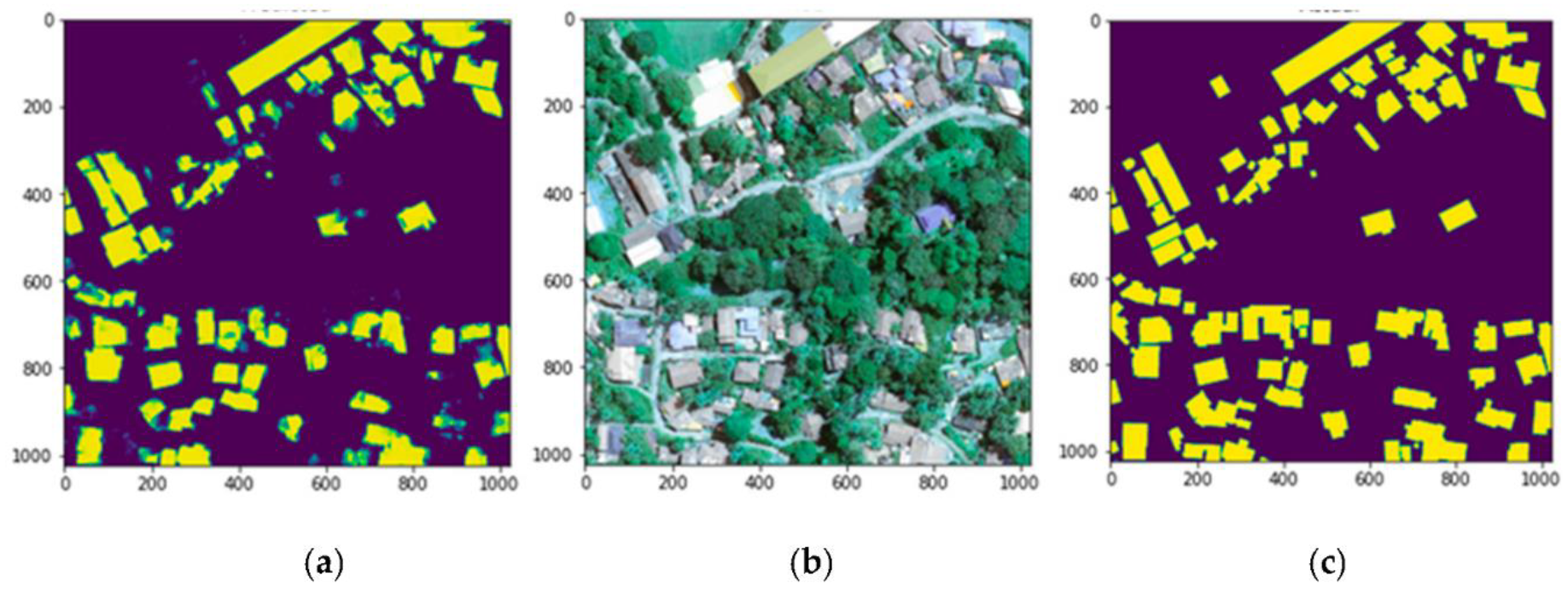
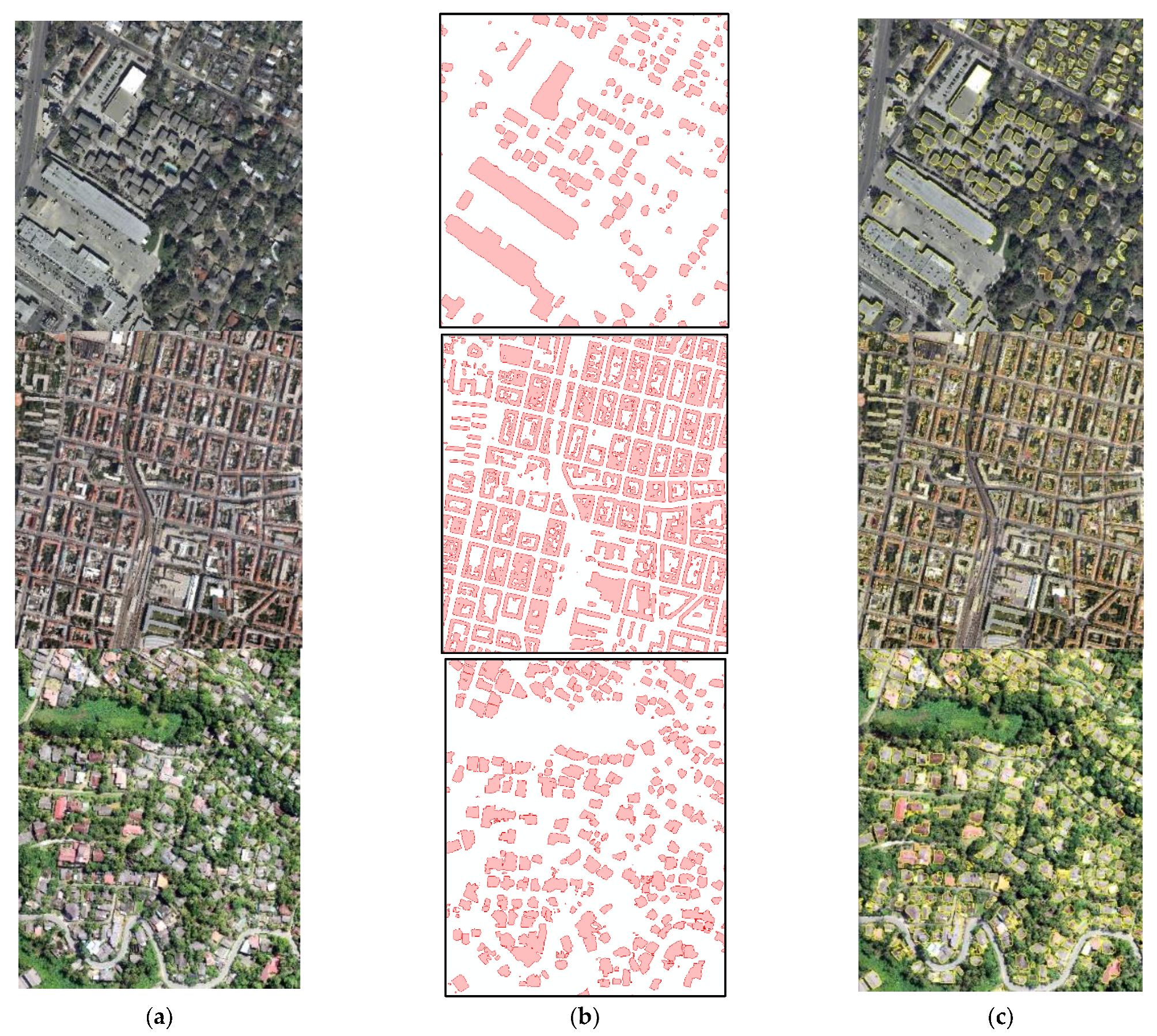
3.1. Building Detection Results of the Model
3.2. Results of the Transfer Learning Approach
3.3. Building Detection Accuracy of the Model with Image Pre-Processing
3.4. Post-Processing: Polygonizing and Polygon Smoothing
3.5. Attribute Extraction
4. Discussion
4.1. Model Limitations
- When the size of the buildings became minor compared to the other buildings in the area, the minor buildings tended to go undetected;
- When buildings were partially covered with trees, such buildings were undetected;
- The shapes of some detected buildings were odd because, in those areas, it was difficult to distinguish the building’s edge from the surrounding area.
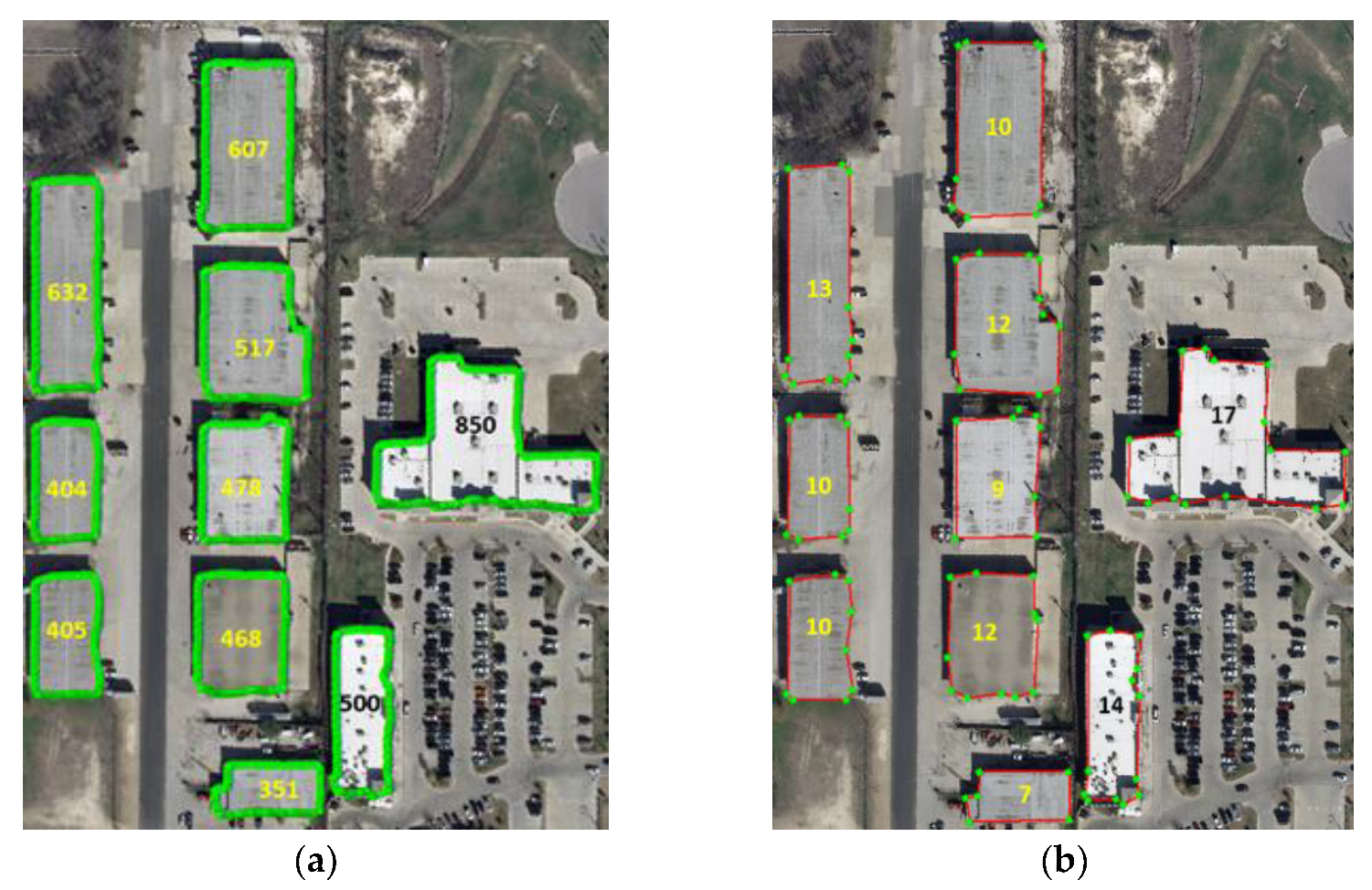
4.2. Effect of Polygon Smoothing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Hui, J.; Du, M.; Ye, X.; Qin, Q.; Sui, J. Effective Building Extraction From High-Resolution Remote Sensing Images With Multitask Driven Deep Neural Network. IEEE Geosci. Remote Sens. Lett. 2018, 16, 786–790. [Google Scholar] [CrossRef]
- Huang, Z.; Cheng, G.; Wang, H.; Li, H.; Shi, L.; Pan, C. Building extraction from multi-source remote sensing images via deep deconvolution neural networks. Proc. IEEE Int. Geosci. Remote Sens. Symp. 2016, 1835–1838. [Google Scholar] [CrossRef]
- Guo, Z.; Shao, X.; Xu, Y.; Miyazaki, H.; Ohira, W.; Shibasaki, R. Identification of Village Building via Google Earth Images and Supervised Machine Learning Methods. Remote Sens. 2016, 8, 271. [Google Scholar] [CrossRef] [Green Version]
- Lateef, F.; Ruichek, Y. Survey on semantic segmentation using deep learning techniques. Neurocomputing 2019, 338, 321–348. [Google Scholar] [CrossRef]
- Ghanea, M.; Moallem, P.; Momeni, M. Building extraction from high-resolution satellite images in urban areas: Recent methods and strategies against significant challenges. Int. J. Remote Sens. 2016, 37, 5234–5248. [Google Scholar] [CrossRef]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Zhang, X.; Zhao, X.; Xin, Q. Extracting Building Boundaries from High Resolution Optical Images and LiDAR Data by Integrating the Convolutional Neural Network and the Active Contour Model. Remote Sens. 2018, 10, 1459. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2020, 169, 114417. [Google Scholar] [CrossRef]
- Chen, X. Image Enhancement Effect on the Performance of Convolutional Neural Networks. Master’s Thesis, Blekinge Institute of Technology, Karlshamn, Sweden, 2019. [Google Scholar]
- Deshapriya, L. Deep Instance Segmentation and Polygonization. Master’s Thesis, Asian Institute of Technology, Pathum Thani, Thailand, May 2020. [Google Scholar]
- Prathap, G.; Afanasyev, I. Deep learning approach for building detection in satellite multispectral imagery. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal, Portugal, 25–27 September 2018; pp. 461–465. [Google Scholar]
- Stiller, D.; Stark, T.; Wurm, M.; Dech, S.; Taubenböck, H. Large-scale building extraction in very high-resolution aerial imagery using Mask R-CNN. In Proceedings of the Joint Urban Remote Sensing Event (JURSE), Vannes, France, 22–24 May 2019; pp. 1–4. [Google Scholar]
- Alshehhi, R.; Marpu, P.R.; Wei, L.W.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network: Mapping of the United States. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef] [Green Version]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. Electron. Imaging 2016, 60. [Google Scholar] [CrossRef]
- Bittner, K.; Cui, S.; Reinartz, P. Building extraction from remote sensing data using fully convolutional networks. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, ISPRS Hannover Workshop, Hannover, Germany, 6–9 June 2017; pp. 481–486. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building extraction based on U-Net with an attention block and multiple losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Pan, X.; Yang, F.; Gao, L.; Chen, Z.; Zhang, B.; Fan, H.; Ren, J. Building extraction from high-resolution aerial imagery using a generative adversarial network with spatial and channel attention mechanisms. Remote Sens. 2019, 11, 917. [Google Scholar] [CrossRef] [Green Version]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The Inria aerial image labeling benchmark. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-task learning for segmentation of building footprints with deep neural networks. arXiv 2017, arXiv:1709.05932. Available online: https://arxiv.org/abs/1709.05932 (accessed on 10 January 2021).
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–3288. [Google Scholar]
- Khalel, A.; El-Saban, M. Automatic pixelwise object labeling for aerial imagery using stacked u-nets. arXiv 2018, arXiv:1803.04953. Available online: https://arxiv.org/abs/1803.04953 (accessed on 10 January 2021).
- Marcu, A.; Costea, D.; Slusanschi, E.; Leordeanu, M. A Multi-stage Multi-task neural network for aerial scene interpretation and geolocalization. arXiv 2018, arXiv:1804.01322v1. Available online: https://arxiv.org/abs/1804.01322 (accessed on 11 January 2021).
- OpenCV. Available online: https://docs.opencv.org/3.4/d3/dc1/tutorial_basic_linear_transform.html (accessed on 20 December 2020).
- OpenCV. Available online: https://docs.opencv.org/master/d5/daf/tutorial_py_histogram_equalization.html (accessed on 20 December 2020).
- Scikit-Image. Available online: https://scikit-image.org/docs/dev/api/skimage.exposure.html#skimage.exposure.adjust_log (accessed on 20 December 2020).
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef] [Green Version]
- Visvalingam, M.; Whyatt, J.D. Line Generalisation by Repeated Elimination of the Smallest Area; Discussion Paper, CISRG; The University of Hull: Hull, UK, 1992; Available online: https://hydra.hull.ac.uk/assets/hull:8338/content (accessed on 28 January 2021).
- Visvalingam, M.; Whelan, J.C. Implications of Weighting Metrics for Line Generalization with Visvalingam’s Algorithm. Cartogr. J. 2016, 53, 253–267. [Google Scholar] [CrossRef]
- OSM Landuse Landcover. Available online: https://osmlanduse.org/#9.707203470991995/9.12579/49.34246/0/ (accessed on 10 February 2021).
- WorldPop. Available online: https://www.worldpop.org/ (accessed on 12 February 2021).





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | Country | Data Source | IoU % | Pixel Accuracy | Precision | Recall |
|---|---|---|---|---|---|---|
| Vienna | Austria | Inria Aerial Images | 67.73 | 0.89 | 0.88 | 0.87 |
| Chicago | USA | Inria Aerial Images | 54.32 | 0.91 | 0.81 | 0.78 |
| Austin | USA | Inria Aerial Images | 52.29 | 0.93 | 0.84 | 0.78 |
| Kandy | Sri Lanka | UAV Images | 70.85 | 0.89 | 0.89 | 0.79 |
| Evaluation Metric | Validation Data | Test Data |
|---|---|---|
| IoU (%) | 61.89 | 61.90 |
| Overall Pixel Accuracy | 0.92 | 0.91 |
| Precision | 0.86 | 0.86 |
| Recall | 0.83 | 0.82 |
| IOU % | Pixel Accuracy | Precision |
|---|---|---|
| 60.56 | 0.92 | 0.83 |
| Metrics | Initial Model by Training Only with Aerial Images | Fine-Tuned Model by Retraining with UAV Images |
|---|---|---|
| IoU (%) | 11.31 | 69.86 |
| Accuracy | 0.66 | 0.90 |
| Epochs | 150 | 80 |
| Training Time | 60.9 min | 37.8 min |
| Original Images | Gamma Corrected | Histogram Equalized | CLAHE Applied | Logarithmic Corrected | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| City | IoU % | Pixel Accu. | IoU % | Pixel Accu | IoU % | Pixel Accu. | IoU % | Pixel Accu. | IoU % | Pixel Accu. |
| Vienna (Aerial) | 67.73 | 0.89 | 64.86 | 0.88 | 68.68 | 0.89 | 67.42 | 0.89 | 71.39 | 0.88 |
| Austin (Aerial) | 52.29 | 0.93 | 46.98 | 0.93 | 51.21 | 0.94 | 50.66 | 0.93 | 55.21 | 0.94 |
| Chicago (Aerial) | 54.32 | 0.91 | 52.42 | 0.91 | 54.38 | 0.91 | 52.91 | 0.91 | 56.88 | 0.91 |
| Kandy (UAV) | 70.85 | 0.89 | 63.23 | 0.85 | 70.92 | 0.89 | 71.07 | 0.89 | 69.72 | 0.89 |
| Ratnapura (UAV) | 60.56 | 0.92 | 52.13 | 0.88 | 65.64 | 0.93 | 68.0 | 0.94 | 57.04 | 0.92 |
| Model | IoU (%) | Overall Pixel Accuracy |
|---|---|---|
| Original U-Net [24] with same dataset | 28.48 | 0.89 |
| Proposed U-Net | 61.90 | 0.91 |
| Proposed U-Net with pre-processed images by Logarithmic corrected | 63.30 | 0.91 |
| FCN [27] * | 53.82 | 92.79 |
| Mask R-CNN [29] * | 59.53 | 92.49 |
| 2-Levels-U-Nets [30] * | 74.55 | 96.05 |
| GAN-SCA [26] * | 77.75 | 96.61 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daranagama, S.; Witayangkurn, A. Automatic Building Detection with Polygonizing and Attribute Extraction from High-Resolution Images. ISPRS Int. J. Geo-Inf. 2021, 10, 606. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10090606
Daranagama S, Witayangkurn A. Automatic Building Detection with Polygonizing and Attribute Extraction from High-Resolution Images. ISPRS International Journal of Geo-Information. 2021; 10(9):606. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10090606
Chicago/Turabian StyleDaranagama, Samitha, and Apichon Witayangkurn. 2021. "Automatic Building Detection with Polygonizing and Attribute Extraction from High-Resolution Images" ISPRS International Journal of Geo-Information 10, no. 9: 606. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10090606