
EmergEventMine: End-to-End Chinese Emergency Event Extraction Using a Deep Adversarial Network


 ,
,
Abstract
:1. Introduction
- Firstly, this paper simplifies the event extraction with four subtasks as a two-stage task based on the goals of subtasks, and then develops a heterogeneous deep joint model for realizing the end-to-end Chinese emergency event extraction. The argument identification adopts the classic BiLSTM-CRF (Long Short-Term Memory-Conditional Random Fields) model, and the argument role classification is realized as a multi-head selection task. Compared with existing professional event extraction joint models, this model is a lightweight model, which does not depend on external syntactic analysis tools and has a simpler network structure for accelerating the convergence of the model on a small training data set.
- Secondly, this paper integrates adversarial training, based on Free Adversarial Training (FreeAT) [15], into the joint model of event extraction. By adding small and persistent disturbances to the input of joint model, the overfitting of the model caused by the small training data set and simple network structure can be alleviated to improve the robustness and generalization of the model.
- Thirdly, different from existing text mining studies based on the public CEC data set, XML format labels were removed from the standard CEC data set to fit the real application scenario. Experiments were performed on this restored CEC data set. Experimental results show that the proposed model can extract emergency events from online news texts more effectively and comprehensively compared with existing state-of-the-art event extraction models.
2. Related Work
2.1. Text Mining of Emergency Information
2.2. Event Extraction
3. Methods
3.1. Emergency Event Definition
3.2. Data and Pre-Processing
3.3. EmergEventMine
3.3.1. Text Vectorization Layer
3.3.2. Argument Identification Layer
3.3.3. Argument Role Classification Layer
3.3.4. Adversarial Training Mechanism
3.4. Evaluation
4. Experiments and Results
4.1. Experimental Settings
4.2. Result
4.2.1. Baseline Methods
- DMCNN [28]: It is a pipeline-based event extraction model with two-stage tasks, including trigger recognition and argument detection.
- JRNN [32]: It is a joint event extraction model based on RNNS, which enriches sentence representations by capturing the dependence between triggers and parameters.
- dbRNN [33]: It is a joint event extraction model which enriches sentence representations by capturing dependency bridges among words and the potential interactions between arguments.
- BERT-BLMCC [33]: It is a joint event extraction model with the sophisticated network, in which multi-CNN and BiLSTM are integrated to mine the depth features of specialized languages. This model adopts a joint feature vector consisting of the output of the BERT model, POS-feature, and entity-feature, and the output of the semantic coding layer.
- PLMEE [37]: It automatically generates labelled event samples by editing prototypes and screening out generated samples by ranking the quality, in order to solve the problem of insufficient training data.
4.2.2. Results Analysis
4.3. Discussion
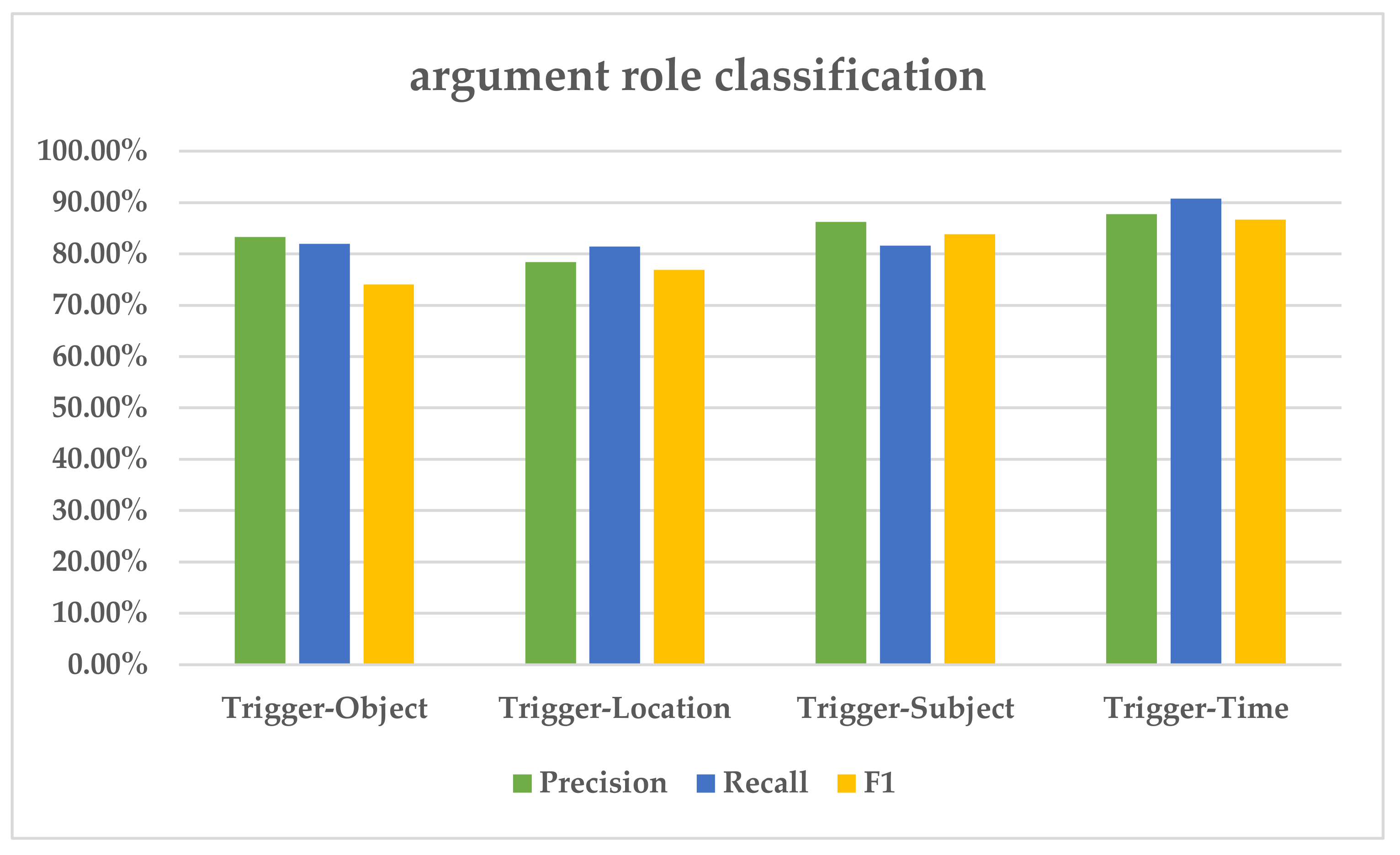
4.3.1. Analysis on the Performance of Subtasks
4.3.2. Analysis on the Effectiveness of Emergency Event Extraction
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shen, H.; Shi, J.; Zhang, Y. CrowdEIM: Crowdsourcing Emergency Information Management Tasks to Mobile Social Media Users. Int. J. Disaster Risk Reduct. 2021, 54, 102024. [Google Scholar] [CrossRef]
- Yan, X. Research on Recognition of Sudden Events on Web Based on Combination of Rules and Statistical Method. Data Anal. Knowl. Discov. 2011, 26, 65–69. [Google Scholar]
- Han, X.; Wang, J. Earthquake Information Extraction and Comparison from Different Sources Based on Web Text. ISPRS Int. J. Geo-Inf. 2019, 8, 252. [Google Scholar] [CrossRef] [Green Version]
- Bai, H.; Yu, H.; Yu, G.; Huang, X. A novel emergency situation awareness machine learning approach to assess flood disaster risk based on Chinese Weibo. Neural Comput. Applic. 2022, 34, 8431–8446. [Google Scholar] [CrossRef]
- Yin, H.; Cao, J.; Cao, L.; Wang, G. Chinese Emergency Event Recognition Using Conv-RDBiGRU Model. Comput. Intell. Neurosci. 2020, 2020, 7090918. [Google Scholar] [CrossRef]
- Sheel, M.; Collins, J.; Kama, M.; Nand, D.; Faktaufon, D.; Samuela, J.; Biaukula, V.; Haskew, C.; Flint, J.; Roper, K.; et al. Evaluation of the early warning, alert and response system after Cyclone Winston, Fiji, 2016. Bull. World Health Organ. 2019, 97, 178–189C. [Google Scholar] [CrossRef]
- Shoyama, K.; Cui, Q.; Hanashima, M.; Sano, H.; Usuda, Y. Emergency flood detection using multiple information sources: Integrated analysis of natural hazard monitoring and social media data. Sci. Total Environ. 2021, 767, 144371. [Google Scholar] [CrossRef]
- Li, D.; Huang, L.; Heng, J.; Han, J. Biomedical Event Extraction based on Knowledge-driven Tree-LSTM. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 1421–1430. [Google Scholar]
- Yu, F. LSLSD: Fusion Long Short-Level Semantic Dependency of Chinese EMRs for Event Extraction. Appl. Sci. 2021, 11, 7237. [Google Scholar]
- Zheng, S.; Cao, W.; Xu, W.; Bian, J. Doc2EDAG: An End-to-End Document-level Framework for Chinese Financial Event Extraction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 337–346. [Google Scholar]
- Wang, P.; Deng, Z.; Cui, R. TDJEE: A Document-Level Joint Model for Financial Event Extraction. Electronics 2021, 10, 824. [Google Scholar] [CrossRef]
- Liu, Z.; Xu, H.; Zhou, D.; Qi, G.; Sun, W.; Shen, S.; Zhao, J. Structural Dependency Self-attention Based Hierarchical Event Model for Chinese Financial Event Extraction. In Knowledge Graph and Semantic Computing: Knowledge Graph Empowers New Infrastructure Construction; Qin, B., Jin, Z., Wang, H., Pan, J., Liu, Y., An, B., Eds.; CCKS 2021; Communications in Computer and Information Science; Springer: Singapore, 2021; Volume 1466. [Google Scholar]
- Kunneman, F.; Van Den Bosch, A. Open-domain extraction of future events from Twitter. Nat. Lang. Eng. 2016, 22, 655–686. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Huang, H.; Zhang, Y. Open Domain Event Extraction Using Neural Latent Variable Models. arXiv 2019, arXiv:1906.06947. [Google Scholar]
- Shafahi, A.; Najibi, M.; Ghiasi, A.; Xu, Z.; Dickerson, J.; Studer, C.; Davin, L.S.; Taylor, G.; Goldstein, T. Adversarial training for free! arXiv 2019, arXiv:1904.12843. [Google Scholar]
- Wang, Y.; Wang, T.; Ye, X.; Zhu, J.; Lee, J. Using Social Media for Emergency Response and Urban Sustainability: A Case Study of the 2012 Beijing Rainstorm. Sustainability 2016, 8, 25. [Google Scholar] [CrossRef]
- Han, X.; Wang, J. Using Social Media to Mine and Analyze Public Sentiment during a Disaster: A Case Study of the 2018 Shouguang City Flood in China. ISPRS Int. J. Geo-Inf. 2019, 8, 185. [Google Scholar] [CrossRef] [Green Version]
- Yu, M.; Huang, Q.; Qin, H.; Scheele, C.; Yang, C. Deep learning for real-time social media text classification for situation awareness using hurricanes sandy, Harvey, and Irma as case studies. Int. J. Digit. Earth 2019, 12, 1230–1247. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, J.P.; Dwivedi, Y.K.; Rana, N.P. A deep multi-modal neural network for informative twitter content classification during emergencies. Ann. Oper. Res. 2020, 1–32. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Z.; Zhou, W. Event Recognition Based on Deep Learning in Chinese Texts. PLoS ONE 2016, 11, e0160147. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Yu, L.; Tian, S.; Tuergen, I.; Zhao, J. Uighur Emergency Recognition Based on DCNNS-LSTM Model. J. Chin. Inf. Sci. Technol. 2018, 6, 52–61. [Google Scholar]
- Anam, M.; Shafiq, B.; Shamail, S.; Chun, S.A.; Adam, N. Discovering Events from Social Media for Emergency Planning. In Proceedings of the 20th Annual International Conference on Digital Government Research, Dubai, United Arab Emirates, 18–20 June 2019; pp. 109–116. [Google Scholar]
- Wang, Z.; Wang, X.; Han, X.; Lin, Y.; Hou, L.; Liu, Z.; Li, P.; Li, J.; Zhou, J. CLEVE: Contrastive Pre-training for Event Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online. 1–6 August 2021; pp. 6283–6297. [Google Scholar]
- Feng, R.; Yuan, J.; Zhang, C. Probing and Fine-tuning Reading Comprehension Models for Few-shot Event Extraction. arXiv 2020, arXiv:abs/2010.11325. [Google Scholar]
- Yu, W.; Yi, M.; Huang, X.; Yi, X.; Yuan, Q. Make it directly: Event Extraction Based on Tree-LSTM and Bi-GRU. IEEE Access 2020, 8, 14344–14354. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, G.; Wang, Y.; Lin, D.; Huang, T. A Question Answering-Based Framework for One-Step Event Argument Extraction. IEEE Access 2020, 8, 65420–65431. [Google Scholar] [CrossRef]
- Xiang, W.; Wang, B. A Survey of Event Extraction from Text. IEEE Access 2019, 7, 173111–173137. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event extraction via dynamic multi-pooling convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 167–176. [Google Scholar]
- Li, Q.; Ji, H.; Huang, L. Joint event extraction via structured prediction with global features. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 73–82. [Google Scholar]
- Nguyen, T.M.; Nguyen, T.H. One for All: Neural Joint Modeling of Entities and Events. arXiv 2018, arXiv:1812.00195. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint event extraction via recur-rent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 300–309. [Google Scholar]
- Sha, L.; Qian, F.; Chang, B.; Sui, Z. Jointly extracting event triggers and arguments by dependency-bridge RNN and tensor-based argument interaction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 5916–5923. [Google Scholar]
- Wang, S.; Rao, Y.; Fan, X.; Qi, J. Joint event extraction model based on multi-feature fusion. Procedia Comput. Sci. 2020, 174, 115–122. [Google Scholar]
- Zhao, W.; Zhang, J.; Yang, J.; He, T.; Li, Z. A novel joint biomedical event extraction framework via two-level modeling of documents. Inf. Sci. 2021, 550, 27–40. [Google Scholar] [CrossRef]
- Ferguson, J.; Lockard, C.; Weld, D.S.; Hajishirzi, H. Semi-Supervised Event Extraction with Paraphrase Clusters. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 359–364. [Google Scholar]
- Chen, Y.; Liu, S.; Zhang, X.; Liu, K.; Zhao, J. Automatically labeled data generation for large scale event extraction. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 409–419. [Google Scholar]
- Yang, S.; Feng, D.; Qiao, L.; Kan, Z.; Li, D. Exploring Pre-trained Language Models for Event Extraction and Generation. In Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5284–5294. [Google Scholar]
- Zeng, Y.; Feng, Y.; Ma, R.; Wang, Z.; Yan, R.; Shi, C.; Zhao, D. Scale up event extraction learning via automatic training data generation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Sang, E.F.; Veenstra, J. Representing text chunks. arXiv 1999, arXiv:cs/9907006. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Li, X.; Wen, Q.; Lin, H.; Jiao, Z.; Zhang, J. Overview of CCKS 2020 Task 3: Named Entity Recognition and Event Extraction in Chinese Electronic Medical Records. Data Intell. 2021, 3, 376–388. [Google Scholar] [CrossRef]
- Giannis, B.; Johannes, D.; Thomas, D.; Chris, D. Joint entity recognition and relation extraction as a multi-head selection problem. Expert Syst. Appl. 2018, 114, 34–45. [Google Scholar]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the Advances in Information Retrieval, Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; pp. 345–359. [Google Scholar]
- Xing, Z.; Su, X.; Liu, J.; Su, W.; Zhang, X. Spatiotemporal Change Analysis of Earthquake Emergency Information Based on Microblog Data: A Case Study of the “8.8” Jiuzhaigou Earthquake. ISPRS Int. J. Geo-Inf. 2019, 8, 359. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Event Category | Articles | Event Sentences | Events | Event Triggers | Event Arguments |
|---|---|---|---|---|---|
| earthquake | 62 | 401 | 1002 | 1002 | 1290 |
| fire | 75 | 433 | 1216 | 1216 | 1609 |
| traffic accident | 85 | 514 | 1802 | 1802 | 2175 |
| terrorist attack | 49 | 323 | 823 | 823 | 1534 |
| food poisoning | 61 | 392 | 1111 | 1111 | 1100 |
| total | 332 | 2064 | 5954 | 5954 | 7708 |
| Annotation Example | ||||||
|---|---|---|---|---|---|---|
| word | 5月 (May) | 1日 (1) | , | 地震局 (seismological bureau) | 工作人员 (staff) | 将 (will) |
| annotation | B-Tim | I-Tim | O | B-Sub | I-Sub | O |
| word | 继续 (continue to) | 在 (be) | 据 | 震中 (epicenter) | 较近的 (near) | 自然村 (natural village) |
| annotation | O | O | O | O | O | B-Loc |
| word | , | 核查 (check) | 有无 (whether) | 灾情 (disaster) | 。 | |
| annotation | O | B-operation | O | B-Obj | O | |
| Position | Word | Event Role | Role Position |
|---|---|---|---|
| 1 | 5月 (May) | ||
| 2 | 1日 (1) | Time | |
| 3 | , | ||
| 4 | 地震局 (seismological bureau) | ||
| 5 | 工作人员 (staff) | Subject | |
| 6 | 将 (will) | ||
| 7 | 继续 (continue to) | ||
| 8 | 在 (be) | ||
| 9 | 据 | ||
| 10 | 震中 (epicenter) | ||
| 11 | 较近的 (near) | ||
| 12 | 自然村 (natural village) | Location | |
| 13 | , | ||
| 14 | 核查 (check) | Trigger | [2,5,12,16] |
| 15 | 有无 (whether) | ||
| 16 | 灾情 (disaster) | Object | |
| 17 | 。 |
| Model | Precision | Recall | |
|---|---|---|---|
| DMCNN (2015) | 71.09% | 76.23% | 73.57% |
| JRNN (2016) | 78.82% | 81.44% | 80.11% |
| dbRNN (2018) | 82.15% | 79.98% | 81.05% |
| PLMEE (2019) | 80.91% | 83.01% | 81.94% |
| BERT-BLMCC (2020) | 88.83% | 90.91% | 89.86% |
| EmergEventMine-NoAT | 90.51% | 88.97% | 89.73% |
| EmergEventMine | 92.73% | 89.91% | 91.81% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, J.; Chen, L.; Yu, Y.; Xu, H.; Gao, Q.; Cao, K.; Chen, J. EmergEventMine: End-to-End Chinese Emergency Event Extraction Using a Deep Adversarial Network. ISPRS Int. J. Geo-Inf. 2022, 11, 345. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi11060345
Yan J, Chen L, Yu Y, Xu H, Gao Q, Cao K, Chen J. EmergEventMine: End-to-End Chinese Emergency Event Extraction Using a Deep Adversarial Network. ISPRS International Journal of Geo-Information. 2022; 11(6):345. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi11060345
Chicago/Turabian StyleYan, Jianzhuo, Lihong Chen, Yongchuan Yu, Hongxia Xu, Qingcai Gao, Kunpeng Cao, and Jianhui Chen. 2022. "EmergEventMine: End-to-End Chinese Emergency Event Extraction Using a Deep Adversarial Network" ISPRS International Journal of Geo-Information 11, no. 6: 345. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi11060345