
Crime Prediction and Monitoring in Porto, Portugal, Using Machine Learning, Spatial and Text Analytics


Abstract
:1. Introduction
2. Machine Learning, Sentiment Analysis and Topic Modelling in Crime Hot-Spotting and Prediction
3. Data and Methods
3.1. Case-Study Context
3.2. Data Sources
3.3. Methodology
4. Porto’s Crime Pattern between 2016 and 2018
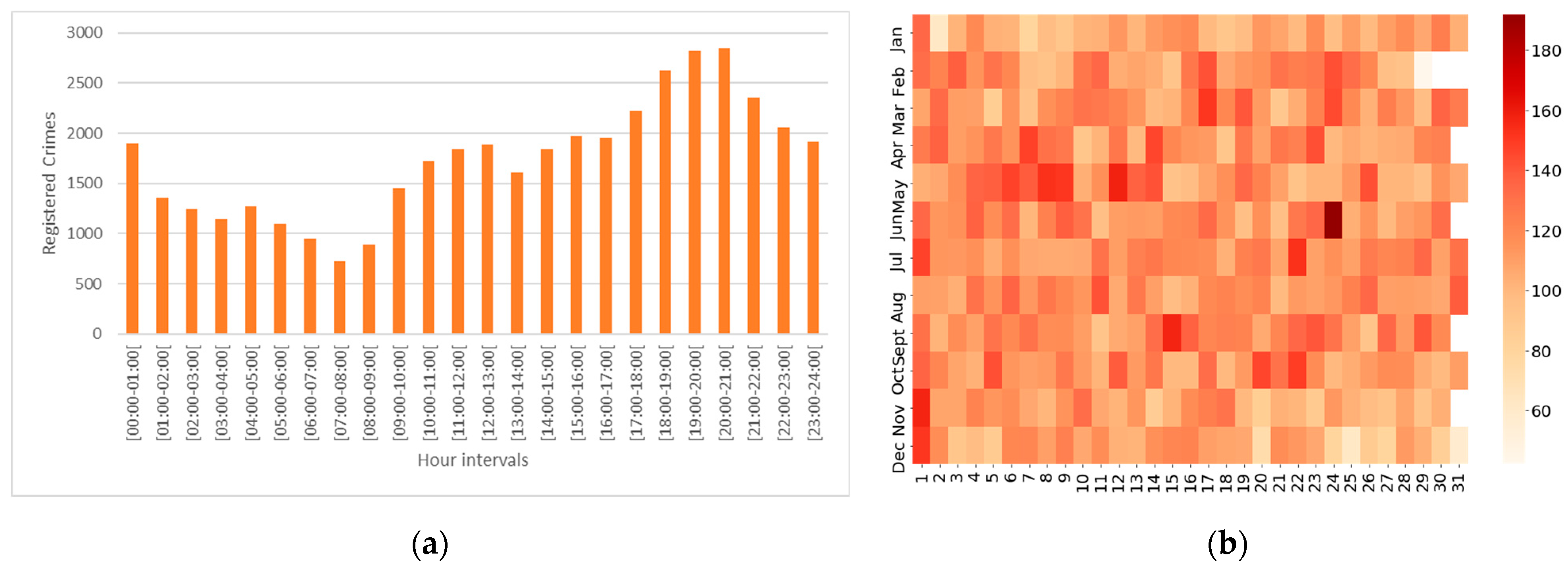
4.1. Statistical Pattern
4.2. Spatial and Temporal Pattern
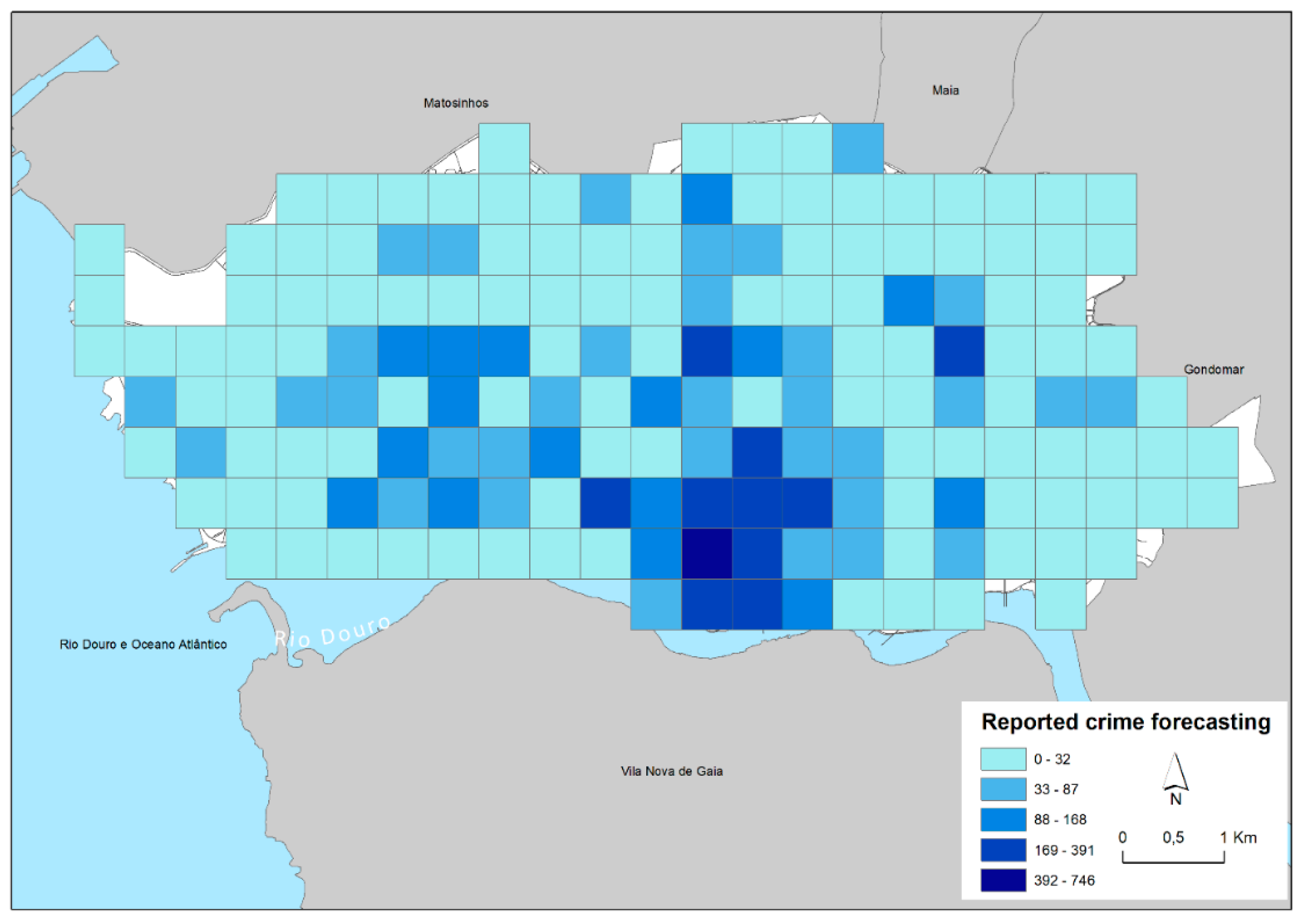
4.3. Forecasting
5. Machine Learning for Crime Prediction
5.1. Feature Selection with Lasso Regression
5.2. Classification
5.3. Natural Language Processing (NLP)
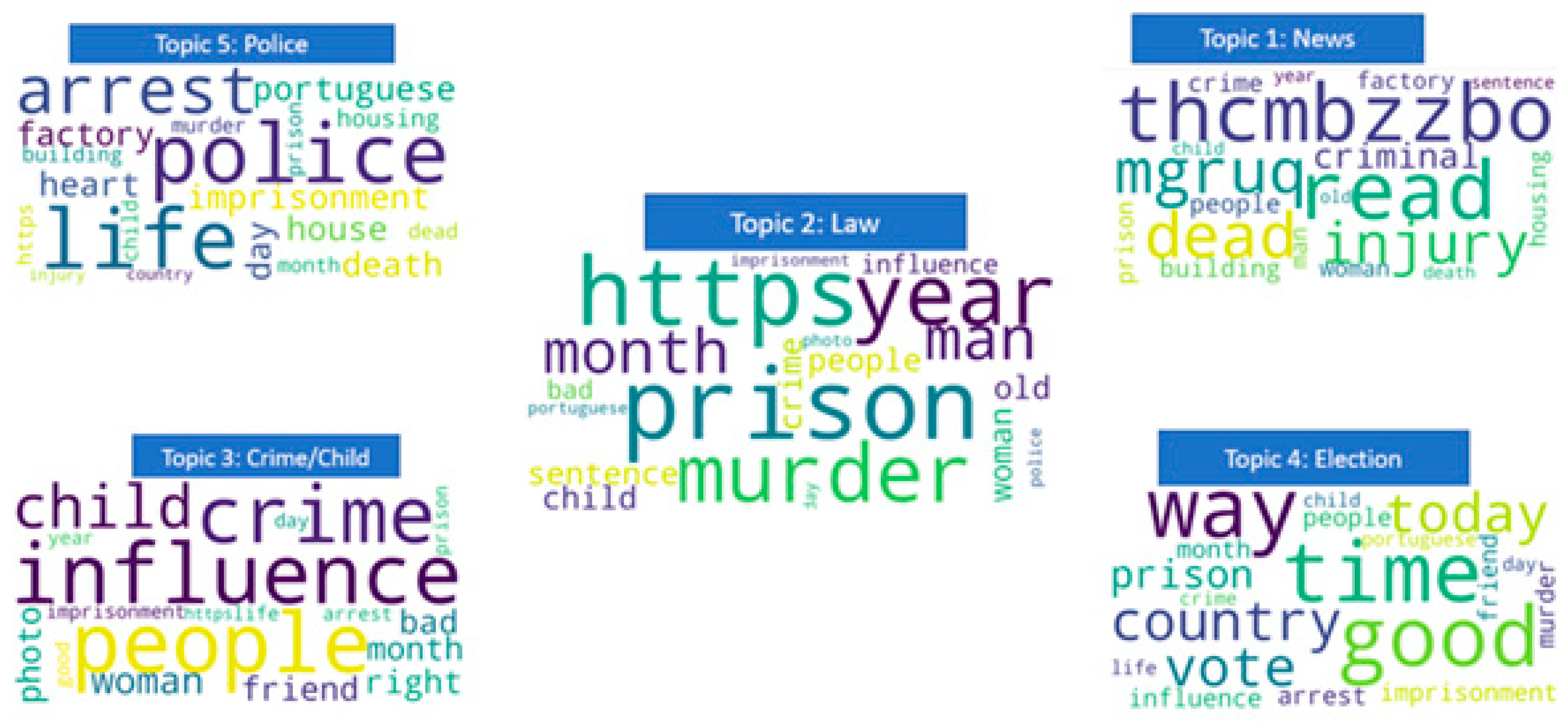
5.3.1. Topic Modeling (LDA)
5.3.2. Sentiment Analysis
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Organisation for Economic Co-operation and Development. How’s Life? OECD Publishing: Paris, France, 2020. [Google Scholar]
- My Region, My Europe, Our Future—Seventh Report on Economic, Social and Territorial Cohesion; European Commission: Luxembourg, 2017.
- Brantingham, P.L.; Brantingham, P.J. Situational crime prevention in practice. Can. J. Criminol. 1990, 32, 17. [Google Scholar] [CrossRef]
- Andresen, M.A. Environmental Criminology: Evolution, Theory, and Practice; Routledge: New York, NY, USA, 2014. [Google Scholar]
- Weisburd, D.; Eck, J.; Braga, A.; Telep, C.W.; Cave, B. Place Matters: Criminology for the Twenty-First Century; Cambridge University Press: New York, NY, USA, 2016. [Google Scholar]
- Wortley, R.; Townsley, M. Environmental Criminology and Crime Analysis; Routledge: New York, NY, USA, 2016. [Google Scholar]
- Leitner, M. Crime Modeling and Mapping Using Geospatial Technologies; Springer Science & Business Media: Berlin, Germany, 2013; Volume 8. [Google Scholar]
- Chainey, S.; Ratcliffe, J. GIS and Crime Mapping; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Kannan, M.; Singh, M. Geographical Information System and Crime Mapping; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Braga, A.; Papachristos, A.; Hureau, D. Hot spots policing effects on crime. Campbell Syst. Rev. 2012, 8, 1–96. [Google Scholar] [CrossRef]
- Weisburd, D.; Telep, C.W. Hot spots policing: What we know and what we need to know. J. Contemp. Crim. Justice 2014, 30, 200–220. [Google Scholar] [CrossRef]
- Andresen, M.A.; Weisburd, D. Place-based policing: New directions, new challenges. Polic. Int. J. 2018, 41, 310–313. [Google Scholar] [CrossRef] [Green Version]
- Elmes, G.A.; Roedl, G.; Conley, J. Forensic GIS: The Role of Geospatial Technologies for Investigating Crime and Providing Evidence; Springer: Dordrecht, The Netherlands, 2014; Volume 11. [Google Scholar]
- Coldren, J.R.; Huntoon, A.; Medaris, M. Introducing smart policing: Foundations, principles, and practice. Police Q. 2013, 16, 275–286. [Google Scholar] [CrossRef]
- Attig, S. The Organic Pattern of Space: A Space Syntax Analysis of Natural Streets and Street Segments for Measuring Crime and Traffic Accidents (Dissertation). 2019. Available online: http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-264938 (accessed on 1 April 2022).
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Tang, J. Modeling temporal-spatial correlations for crime prediction. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 497–506. [Google Scholar]
- Babakura, A.; Sulaiman, M.N.; Yusuf, M.A. Improved method of classification algorithms for crime prediction. In Proceedings of the 2014 International Symposium on Biometrics and Security Technologies (ISBAST), Kuala Lumpur, Malaysia, 26 August 2014; IEEE: Piscataway, NJ, USA; pp. 250–255. [Google Scholar]
- Alves, L.G.; Ribeiro, H.V.; Rodrigues, F.A. Crime prediction through urban metrics and statistical learning. Phys. A Stat. Mech. Its Appl. 2018, 505, 435–443. [Google Scholar] [CrossRef] [Green Version]
- Ivan, N.; Ahishakiye, E.; Omulo, E.O.; Taremwa, D. Crime Prediction Using Decision Tree (J48) Classification Algorithm. Int. J. Comput. Inf. Technol. 2017, 6, 188–195. [Google Scholar]
- Nasridinov, A.; Ihm, S.Y.; Park, Y.H. A decision tree-based classification model for crime prediction. In Information Technology Convergence; Springer: Dordrecht, The Netherlands, 2013; pp. 531–538. [Google Scholar]
- Tayal, D.K.; Jain, A.; Arora, S.; Agarwal, S.; Gupta, T.; Tyagi, N. Crime detection and criminal identification in India using data mining techniques. AI Soc. 2015, 30, 117–127. [Google Scholar] [CrossRef]
- Sivaranjani, S.; Sivakumari, S.; Aasha, M. Crime prediction and forecasting in Tamilnadu using clustering approaches. In Proceedings of the 2016 International Conference on Emerging Technological Trends (ICETT), Kollam, India, 21–22 October 2016; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Kianmehr, K.; Alhajj, R. Effectiveness of support vector machine for crime hot-spots prediction. Appl. Artif. Intell. 2008, 22, 433–458. [Google Scholar] [CrossRef]
- Memon, Q.A.; Mehboob, S. Crime investigation and analysis using neural nets. In Proceedings of the 7th International Multi Topic Conference, 2003. INMIC 2003, Islamabad, Pakistan, 8–9 December 2003; IEEE: Piscataway, NJ, USA; pp. 346–350. [Google Scholar]
- Bannister, J.; O’Sullivan, A.; Bates, E. Place and time in the Criminology of Place. Theor. Criminol. 2019, 23, 315–332. [Google Scholar] [CrossRef]
- Saraiva, M.; Amante, A.; Marques, T.; Ferreira, M.; Maia, C. Perfis territoriais de criminalidade em Portugal (2009–2019). Finisterra 2021, 56, 49–73. [Google Scholar] [CrossRef]
- Freilich, J.D.; Newman, G.R. Situational Crime Prevention Oxford Research Encyclopedia of Criminology and Criminal Justice; Oxford University Press: Oxford, UK, 2017. [Google Scholar]
- Individualized Education Program. Global Peace Index 2021: Measuring Peace in a Complex World. 2021. Available online: https://www.visionofhumanity.org/wp-content/uploads/2021/06/GPI-2021-web-1.pdf (accessed on 1 April 2022).
- Grangeia, H.; Cruz, O.; Teixeira, R.; Alves, P. Vulnerabilidades urbanas: O caso da criminalidade associada às ourivesarias na cidade do Porto. Rev. Latit. 2013, 7, 69–89. [Google Scholar]
- Country Security Report. 2020. Available online: https://www.osac.gov/Country/Portugal/Content/Detail/Report/3e50b674-78b2-4997-8950-188df6d2cadf (accessed on 1 April 2022).
- Tulumello, S. Segurança urbana: Tendências globais, contradições portuguesas e tempos de crise. Cid. Em Reconstrução. Leituras Círitcas 2018, 2008–2018, 73–80. [Google Scholar]
- Eurostat. Crime and Criminal Justice Statistics. 2016. Available online: http://ec.europa.eu/eurostat/statistics-explained/index.php/MainPage (accessed on 1 April 2022).
- Ferreira, J.; João, P.; Martins, J. GIS for crime analysis-geography for predictive models. Electron. J. Inf. Syst. Eval. 2012, 15, 36–49. [Google Scholar]
- João, P. Modelo Preditivo de Criminalidade: Georeferenciação ao Concelho de Lisboa. Master’s Thesis, Universidade Nova de Lisboa, Lisboa, Portugal, 2009. [Google Scholar]
- Rodrigues, T.M.F.; Inácio, A.A.; Araújo, D.; Painho, M.; Henriques, R.; Cabral, P.d.C.B.; Oliveira, T.H.; Neto, M.d.C. SIM4SECURITY. In V Congresso Português de Demografia; A forecast and spatial analysis model for homeland security. Portugal 2030; Fundação Calouste Gulbenkian: Lisbon, Portugal, 2016. [Google Scholar]
- Innes, M.; Roberts, C.; Preece, A.; Rogers, D. Ten “Rs” of social reaction: Using social media to analyse the “post-event” impacts of the murder of Lee Rigby. Terror. Political Violence 2018, 30, 454–474. [Google Scholar] [CrossRef] [Green Version]
- Hu, S.; Gao, S.; Wu, L.; Xu, Y.; Zhang, Z.; Cui, H.; Gong, X. Urban function classification at road segment level using taxi trajectory data: A graph convolutional neural network approach. Comput. Environ. Urban Syst. 2021, 87, 101619. [Google Scholar] [CrossRef]
- Wu, H.; Lin, A.; Xing, X.; Song, D.; Li, Y. Identifying core driving factors of urban land use change from global land cover products and POI data using the random forest method. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102475. [Google Scholar] [CrossRef]
- Abouheaf, M.; Qu, S.; Gueaieb, W.; Abielmona, R.; Harb, M. Responding to illegal activities along the Canadian coastlines using reinforcement learning. In Proceedings of the IEEE Instrumentation & Measurement Magazine, Catania, Italy, 12 April 2021; Volume 24, pp. 118–126. [Google Scholar] [CrossRef]
- Petrossian, G.A. Preventing illegal, unreported and unregulated (IUU) fishing: A situational approach. Biol. Conserv. 2015, 189, 39–48. [Google Scholar] [CrossRef]
- Lin, Y.L.; Chen, T.Y.; Yu, L.C. Using machine learning to assist crime prevention. In Proceedings of the 2017 6th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), Hamamatsu, Japan, 9–13 July 2017; IEEE: Piscataway, NJ, USA; pp. 1029–1030. [Google Scholar]
- Zhang, X.; Liu, L.; Xiao, L.; Ji, J. Comparison of machine learning algorithms for predicting crime hotspots. IEEE Access 2020, 8, 181302–181310. [Google Scholar] [CrossRef]
- Matijosaitiene, I.; McDowald, A.; Juneja, V. Predicting safe parking spaces: A machine learning approach to geospatial urban and crime data. Sustainability 2019, 11, 2848. [Google Scholar] [CrossRef] [Green Version]
- Pinto, M.; Wei, H.; Konate, K.; Touray, I. Delving into factors influencing New York crime data with the tools of machine learning. J. Comput. Sci. Coll. 2020, 36, 61–70. [Google Scholar]
- Mittal, M.; Goyal, L.M.; Sethi, J.K.; Hemanth, D.J. Monitoring the impact of economic crisis on crime in India using machine learning. Comput. Econ. 2019, 53, 1467–1485. [Google Scholar] [CrossRef]
- Bogomolov, A.; Lepri, B.; Staiano, J.; Oliver, N.; Pianesi, F.; Pentland, A. Once upon a crime: Towards crime prediction from demographics and mobile data. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Türkiye, 12–16 November 2014; pp. 427–434. [Google Scholar]
- Zhou, J.; Li, Z.; Ma, J.J.; Jiang, F. Exploration of the hidden influential factors on crime activities: A big data approach. IEEE Access 2020, 8, 141033–141045. [Google Scholar] [CrossRef]
- Al Boni, M.; Gerber, M.S. Area-specific crime prediction models. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; IEEE: Piscataway, NJ, USA; pp. 671–676. [Google Scholar]
- Weisburd, D. The law of crime concentration and the criminology of place. Criminology 2015, 53, 133–157. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, P.; Zhou, Q.; Yang, Z. Mixed spatial-temporal characteristics based crime hot spots prediction. In Proceedings of the 2016 IEEE 20th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Nanchang, China, 4–6 May 2016; IEEE: Piscataway, NJ, USA; pp. 97–101. [Google Scholar]
- Bappee, F.K.; Junior, A.S.; Matwin, S. Predicting crime using spatial features. In Proceedings of the Canadian Conference on Artificial Intelligence, Toronto, Canada, 8–11 May 2018; Springer: Cham, Switzerland; pp. 367–373. [Google Scholar]
- Chen, Y. Crime Mapping Powered by Machine Learning and Web GIS. Ph.D. Thesis, California State University, Northridge, CA, USA, 2019. [Google Scholar]
- He, L.; Páez, A.; Jiao, J.; An, P.; Lu, C.; Mao, W.; Long, D. Ambient population and larceny-theft: A spatial analysis using mobile phone data. ISPRS Int. J. Geo-Inf. 2020, 9, 342. [Google Scholar] [CrossRef]
- Gerber, M. Predicting crime using Twitter and kernel density estimation. Decis. Support Syst. 2014, 61, 115–125. [Google Scholar] [CrossRef]
- Vo, T.; Sharma, R.; Kumar, R.; Son, L.H.; Pham, B.T.; Tien Bui, D.; Priyadarshini, I.; Sarkar, M.; Le, T. Crime rate detection using social media of different crime locations and Twitter part-of-speech tagger with Brown clustering. J. Intell. Fuzzy Syst. 2020, 38, 4287–4299, (Preprint). [Google Scholar] [CrossRef]
- Wang, X.; Gerber, M.S.; Brown, D.E. Automatic crime prediction using events extracted from twitter posts. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling, and Prediction, College Park, MD, USA, 3–5 April 2012; Springer: Berlin, Heidelberg; pp. 231–238. [Google Scholar]
- Siriaraya, P.; Zhang, Y.; Wang, Y.; Kawai, Y.; Mittal, M.; Jeszenszky, P.; Jatowt, A. Witnessing crime through Tweets: A crime investigation tool based on social media. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 568–571. [Google Scholar]
- El Hannach, H.; Benkhalifa, M. WordNet based implicit aspect sentiment analysis for crime identification from twitter. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 150–159. [Google Scholar] [CrossRef]
- Pandey, R.; Mohler, G.O. Evaluation of crime topic models: Topic coherence vs. spatial crime concentration. In Proceedings of the 2018 IEEE International Conference on Intelligence and Security Informatics (ISI), Miami, FL, USA, 9–11 November 2018; IEEE: Piscataway, NJ, USA; pp. 76–78. [Google Scholar]
- Kuang, D.; Brantingham, P.J.; Bertozzi, A.L. Crime topic modeling. Crime Sci. 2017, 6, 12. [Google Scholar] [CrossRef]
- Tompson, L.; Johnson, S.; Ashby, M.; Perkins, C.; Edwards, P. UK open source crime data: Accuracy and possibilities for research. Cartogr. Geogr. Inf. Sci. 2015, 42, 97–111. [Google Scholar] [CrossRef] [Green Version]
- Instituto Nacional de Estatistica. Main Indicators. Instituto Nacional de Estatistica (INE), Lisbon, Portugal. 2012. Available online: http://www.ine.pt/xportal/xmain?xpid=INE&xpgid=inemain (accessed on 1 April 2022).
- Saraiva, M.; Amante, A. Geografia do bem-estar: Insegurança: O caso dos crimes contra as pessoas no Grande Porto. In Geografia do Porto; Fernandes, R., Ed.; Book Cover: Porto, Portugal, 2020; pp. 202–211. ISBN 9789898898517. [Google Scholar]
- GitHub—JustAnotherArchivist/Snscrape: A Social Website. Available online: www.github.com/JustAnotherArchivist/snscrape (accessed on 1 April 2022).
- Chainey, S.; Tompson, L.; Uhlig, S. The utility of hotspot mapping for predicting spatial patterns of crime. Secur. J. 2008, 21, 4–28. [Google Scholar] [CrossRef]
- Kalinic, M.; Krisp, J.M. Kernel density estimation (KDE) vs. hot-spot analysis–detecting criminal hot spots in the city of San Francisco. In Proceedings of the 21 Conference on Geo-Information Science, Lund, Sweden, 12–15 June 2018. [Google Scholar]
- Eck, J.; Chainey, S.; Cameron, J.; Wilson, R. Mapping Crime: Understanding Hotspots; U.S. Department of Justice Office of Justice Programs: Washington, DC, USA, 2005.
- Jansenberger, E.M.; Staufer-Steinnocher, P. Dual kernel density estimation as a method for describing spatio-temporal changes in the upper Austrian food retailing market. In Proceedings of the 7th AGILE Conference on Geographic Information Science, Heraklion, Crete, Greece, 29 April – 1 May 2004. [Google Scholar]
- Chainey, S.P. Examining the influence of cell size and bandwidth size on kernel density estimation crime hotspot maps for predicting spatial patterns of crime. Bull. Geogr. Soc. Liege 2013, 60, 7–19. [Google Scholar]
- Hu, Y.; Wang, F.; Guin, C.; Zhu, H. A spatio-temporal kernel density estimation framework for predictive crime hotspot mapping and evaluation. Appl. Geogr. 2018, 99, 89–97. [Google Scholar] [CrossRef]
- Meneses, B.M.; Reis, E.; Reis, R.; Vale, M.J. The effects of land use and land cover geoinformation raster generalization in the analysis of LUCC in Portugal. ISPRS Int. J. Geo-Inf. 2018, 7, 390. [Google Scholar] [CrossRef] [Green Version]
- Ord, J.K.; Getis, A. Local spatial autocorrelation statistics: Distribution issues and an application. Geogr. Anal. 1995, 27, 286–306. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Du, W.; Zhan, Z. Building Decision Tree Classifier on Private Data. Electrical Engineering and Computer Science. 2002. Available online: https://surface.syr.edu/eecs/8 (accessed on 1 April 2022).
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; IEEE: Piscataway, NJ, USA; Volume 1, pp. 278–282. [Google Scholar]
- Ho, T.K. The random subpace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Wang, L. (Ed.) Support Vector Machines: Theory and Applications; Springer Science & Business Media: Berlin, Germany, 2005; Volume 177. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Liu, B. Sentiment analysis and subjectivity. Handb. Nat. Lang. Processing 2010, 2, 627–666. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Lasierra, F.G. Detecting and tackling the different levels of subjective security1. In The Dimensions of Insecurity in Urban Areas; Barabás, A.T., Ed.; National Institute of Budapest: Budapest, Hungary, 2018. [Google Scholar]
- Solymosi, R.; Bowers, K.; Fujiyama, T. Mapping fear of crime as a context-dependent everyday experience that varies in space and time. Leg. Criminol. Psychol. 2015, 20, 193–211. [Google Scholar] [CrossRef]
- LeBeau, J.L.; Leitner, M. Introduction: Progress in research on the geography of crime. Prof. Geogr. 2011, 63, 161–173. [Google Scholar] [CrossRef]
- Bunting, R.J.; Chang, O.Y.; Cowen, C.; Hankins, R.; Langston, S.; Warner, A.; Yang, X.; Louderback, E.R.; Roy, S.S. Spatial patterns of larceny and aggravated assault in Miami–Dade County, 2007–2015. Prof. Geogr. 2018, 70, 34–46. [Google Scholar] [CrossRef]
- Hunt, P.; Kilmer, B.; Rubin, J. Development of a European Crime Report: Improving Safety and Justice with Existing Crime and Criminal Justice Data; RAND Europe: Cambridge, UK, 2011. [Google Scholar]
- Partnership on Security in Public Spaces (PSPS). Action Plan Urban Agenda Partnership Security in Public Spaces. 2021. Available online: https://ec.europa.eu/futurium/en/system/files/ged/final_action_plan_security_in_public_spaces.pdf (accessed on 1 April 2022).
- Weisburd, D.; White, C.; Wooditch, A. Does collective efficacy matter at the micro geographic level?: Findings from a study of street segments. Br. J. Criminol. 2020, 60, 873–891. [Google Scholar] [CrossRef] [PubMed]
- Weisburd, D.; White, C.; Wire, S.; Wilson, D.B. Enhancing informal social controls to reduce crime: Evidence from a study of crime hot spots. Prev. Sci. 2021, 22, 509–522. [Google Scholar] [CrossRef]
- Foster, S.; Giles-Corti, B.; Knuiman, M. Neighbourhood design and fear of crime: A social-ecological examination of the correlates of residents’ fear in new suburban housing developments. Health Place 2010, 16, 1156–1165. [Google Scholar] [CrossRef]
- Weisburd, D.; Groff, E.R.; Yang, S.M. Understanding and controlling hot spots of crime: The importance of formal and informal social controls. Prev. Sci. 2014, 15, 31–43. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Recall | Precision | F1 Score |
|---|---|---|---|---|
| Logistic Regression (L1 penalty = 0.151) | 0.65 | 0.84 | 0.64 | 0.72 |
| Decision Tree (criterion = entropy, max depth = 3) | 0.61 | 0.56 | 0.70 | 0.63 |
| Random Forest (max. features = 2, number of trees = 100, max depth = 5) | 0.83 | 0.99 | 0.79 | 0.89 |
| SVM (kernel = rbf, C = 1, gamma = 0.1) | 0.80 | 0.87 | 0.82 | 0.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saraiva, M.; Matijošaitienė, I.; Mishra, S.; Amante, A. Crime Prediction and Monitoring in Porto, Portugal, Using Machine Learning, Spatial and Text Analytics. ISPRS Int. J. Geo-Inf. 2022, 11, 400. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi11070400
Saraiva M, Matijošaitienė I, Mishra S, Amante A. Crime Prediction and Monitoring in Porto, Portugal, Using Machine Learning, Spatial and Text Analytics. ISPRS International Journal of Geo-Information. 2022; 11(7):400. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi11070400
Chicago/Turabian StyleSaraiva, Miguel, Irina Matijošaitienė, Saloni Mishra, and Ana Amante. 2022. "Crime Prediction and Monitoring in Porto, Portugal, Using Machine Learning, Spatial and Text Analytics" ISPRS International Journal of Geo-Information 11, no. 7: 400. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi11070400