1. Introduction
Language is a fundamental and intricate facet of human communication, playing a crucial role in the exchange of thoughts, emotions, and information [
1,
2,
3,
4]. Linguistics is the scientific study of language, aiming to objectively examine its structure, use, and societal role, thus addressing a broad range of questions about human language [
5,
6,
7,
8]. Linguistic diversity, reflecting intricate variations in language structures and patterns, is a dynamic area of study within linguistics [
9,
10,
11,
12]. For example, linguistic preferences for carbonated beverages vary significantly across the U.S.: it is commonly referred to as a “soft drink” in general parlance, termed “pop” in the Midwest, dubbed “soda” in the Northeast, and colloquially called “Coke” in the South—a term applied irrespective of the brand [
13,
14]. Linguistic diversity paints a fascinating mosaic, reflecting the unique histories, geographies, and sociocultural contexts of various populations [
15,
16]. Studying linguistic diversity has profound implications for our understanding of human cognition and the broader societal landscape. Linguistic diversity highlights the dynamic interplay between language and identity, fostering cultural preservation, intercultural dialogue, and global connections [
17,
18].
The increased emphasis on language and culture preservation has expanded research on linguistic diversity, especially within diverse linguistic and cultural terrain in China [
19,
20]. Previous research predominantly used statistics and surveys, employing oral interviews, questionnaires, and field investigations for data collection and analysis [
21,
22,
23]. Although these methods are valuable, they also have inherent limitations. Due to resource and time constraints, these studies are often smaller in scale, focusing on specific regions or communities. Additionally, such studies may have a limited scope, possibly prioritizing certain languages or dialects over others. This narrow focus might result in research outcomes that do not fully capture the linguistic diversity in Chinese urban contexts. Moreover, traditional research methods may be prone to biases. For instance, researchers might favor languages or dialects they are familiar with or find interesting, overlooking others.
The rise of big data from social media has significantly evolved the methods and focus of linguistic diversity research [
24,
25,
26,
27,
28,
29,
30]. Blodgett, Green [
31] used Twitter geolocation data to explore dialectal variations in African-American English. Using a distant supervision model, they identified texts linked to African-Americans and verified their alignment with known African-American English patterns. Sadat, Kazemi [
32] sought to bridge the gap between Modern Standard Arabic (MSA) and Arabic Dialects (AD) with a translation framework for social media texts. The study used linguistic tools, such as a bilingual AD-MSA lexicon and grammatical mapping rules, to convert Tunisian dialect sentences to MSA. Although these studies provide valuable insights, their limitations should be acknowledged. Primarily, current research has not deeply delved into environmental and public crises domains, such as linguistic diversity related to rainfall and floods, underscoring the need for thorough exploration. Secondly, many research methodologies focus on internal linguistic analysis, neglecting the integration of data from various sources.
The public crisis domain stands as a pivotal area of investigation in linguistic research [
33,
34,
35,
36]. Many researchers utilize social media data, as a medium of language, to detect crises [
37,
38,
39], analyze resilience [
40,
41,
42,
43,
44], gauge situational awareness [
29,
45,
46], and define crisis thresholds [
47,
48]. A foundational step in these studies involves extracting and identifying microblogs related to rainfall and flood, typically using two approaches: bag-of-words filtering and machine learning-based annotation prediction. For example, Wang, Loo [
49] utilized five key terms such as “雨” (rain in Chinese) and “洪水” (flood in Chinese), derived from media reports on urban flooding and trial data runs, to extract flood-related microblogs. Said, Ahmad [
50] employed an Italian version of BERT, training the model with labeled samples for text classification. Despite these advancements in integrating linguistic perspectives into disaster analysis and the effective extraction of social media data related to specific regions and events, there are several limitations. First, the keywords for rainfall and flood are often used interchangeably as linguistic representations of flood disasters, but terms such as rainfall only stand for weather and meteorological conditions. Only terms such as flood and inundation are the direct indicators of the affected areas. Second, the selection of keywords or labeled sample texts is manually performed, leading to incomplete selection and potential extraction bias due to the lack of automation, ultimately causing regional biases and disparities. Lastly, while some keywords have global usage, some others are region-specific, limited to certain dialectical areas. Although such globally recognized keywords are frequently used [
51], treating it as a proxy for the entire rainfall or flood term may lead to biased results. In other words, the approach does not adequately account for linguistic diversity.
Rainstorms and floods serve as an ideal context for linguistic diversity studies due to their significant financial impacts, especially in countries such as China [
52,
53]. As the effects of climate change intensify, areas previously untouched by floods now face increased threats, with expectations of amplified risks from more frequent extreme precipitation events [
54,
55,
56,
57,
58]. Using Typhoon Doksuri as a case study, this event brought numerous rainstorms and floods. The typhoon affected over a third of China’s provinces, ranging from southern provinces such as Guangdong and Fujian to northern ones such as Beijing and Heilongjiang. Spanning over 9.6 million km
2, China’s vastness encompasses over 80 dialects [
59]. Therefore, neglecting linguistic diversity in research or disaster management could lead to regional biases and cause inequalities.
Our study sets out to provide a comprehensive quantification of rainfall- and flood-related keywords. This research offers three major contributions to the discipline. First, we introduce a novel quantitative algorithm that captures expressions related to rainfall and floods by considering the nexus between precipitation observations and linguistic phrases. Implementing this approach on 210 million social media entries from 2017, we identified 594 keywords associated with rainfall and flooding. This count is 20-fold higher than the manually created bag-of-words, thereby significantly enriching the keyword library. Second, we delve into a thorough analysis of these keywords’ semantic attributes, exploring aspects such as popularity, credibility, and time delay. Third, we dissect spatial characteristics from dual viewpoints: the keyword perspective (considering each keyword’s regional applicability and its global or local nature) and the city-centric perspective (assessing keyword diversity within individual cities). Furthermore, we discuss the driving forces behind these distributions, enabling us to offer insights that can guide local authorities and residents in formulating nuanced strategies and fostering a sustainable habitat. Our findings serve as a robust foundation for future studies leveraging social media data to gauge public perception of rainfall and flooding, offering enhanced accuracy and completeness especially in linguistically diverse settings such as China.
3. Method
The methodological framework of the study is organized into four main components, as illustrated in
Figure 1. Initially, the focus was on preprocessing rainfall and flood-related microblogs, which included filtering out characters, advertisements, and applying spatial filtering. Following this, precipitation data and microblog content were transformed into daily count vectors. In the third phase, the similarity between each pair of vectors was evaluated to identify all precipitation-related expressions, which were then classified into three categories: rainfall, flood, and other related terms, utilizing a Large Language Model. The final component of our framework involved a spatial analysis of rainfall and flood-related keywords, which encompassed assessing spatial correlations and identifying central locations.
3.1. Preprocessing Rainfall and Flood Microblogs
We began by isolating microblogs from the 210 million posted across China in 2017 that contained characters associated with rainfall or flooding, specifically “洪/涝/雨/水/海/汛” (equivalent to rainfall and flood in English). We utilized the jieba toolkit—a prevalent Chinese word segmentation technology—to transform the Chinese text into word sequences, also labeling the part-of-speech for each term.
Our filtering methodology encompassed two primary stages. Initially, we targeted and eliminated users primarily posting advertisements. Such users often exhibit a high posting frequency with substantial content consistency. We identified them by seeking any two microblogs with over 80% similarity in their postings. Detected users were deemed as advertising accounts, and their associated microblogs were excluded from our dataset.
Subsequently, we refined our dataset to exclude microblogs originating outside of China. Utilizing the spatial join functionality in ArcGIS, we matched each microblog’s longitude and latitude which were reported by user to a China basemap encompassing 369 cities, retaining only the corresponding entries.
Ultimately, we obtained a refined dataset comprising 35,521,272 microblogs, ready for further keyword analysis. The distribution of microblog counts across cities is illustrated in
Figure S1. The number of microblogs from various cities all exceed 100, demonstrating regional representativeness.
3.2. Constructing Daily Count Vectors for Precipitation and Microblogs
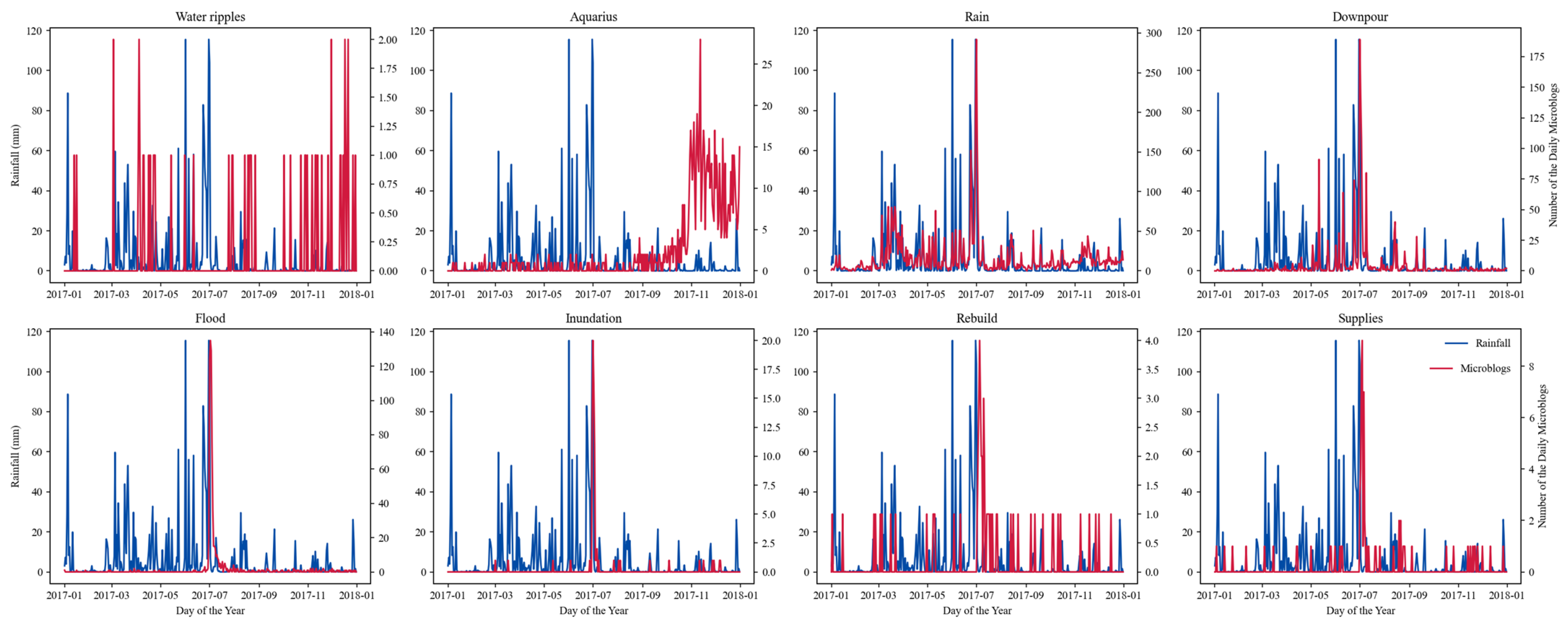
Prior to assessing similarity, our initial step involved constructing daily count vectors for both precipitation and the microblogs linked to each keyword (MBk). For the precipitation data, we resampled the half-hourly GPM data to a daily metric, subsequently computing the average daily rainfall across each city. This yielded a 365-element vector denoting precipitation for every city. In the realm of microblog data, we began by isolating every MBk. We had over 500,000 candidate keywords after filtering. To expedite computation, we employed feature engineering as an alternative to direct text matching. Using the outcomes from the jieba word segmentation, we formulated a feature engineering model. In this model, individual rows signify distinct microblogs, columns stand for keywords, and cells highlight the occurrence count of a particular keyword within a given microblog. To optimize storage efficiency, we saved this matrix using a sparse matrix configuration. For every keyword, we extracted the microblog indices containing that keyword from the sparse matrix, thus pinpointing MBk. Conclusively, we consolidated the timestamps associated with MBk to a daily scale, producing a daily MBk tally. This process culminated in generating a 365-element vector showcasing microblog counts tailored for each city and keyword.
3.3. Extracting Precipitation-Related Keywords
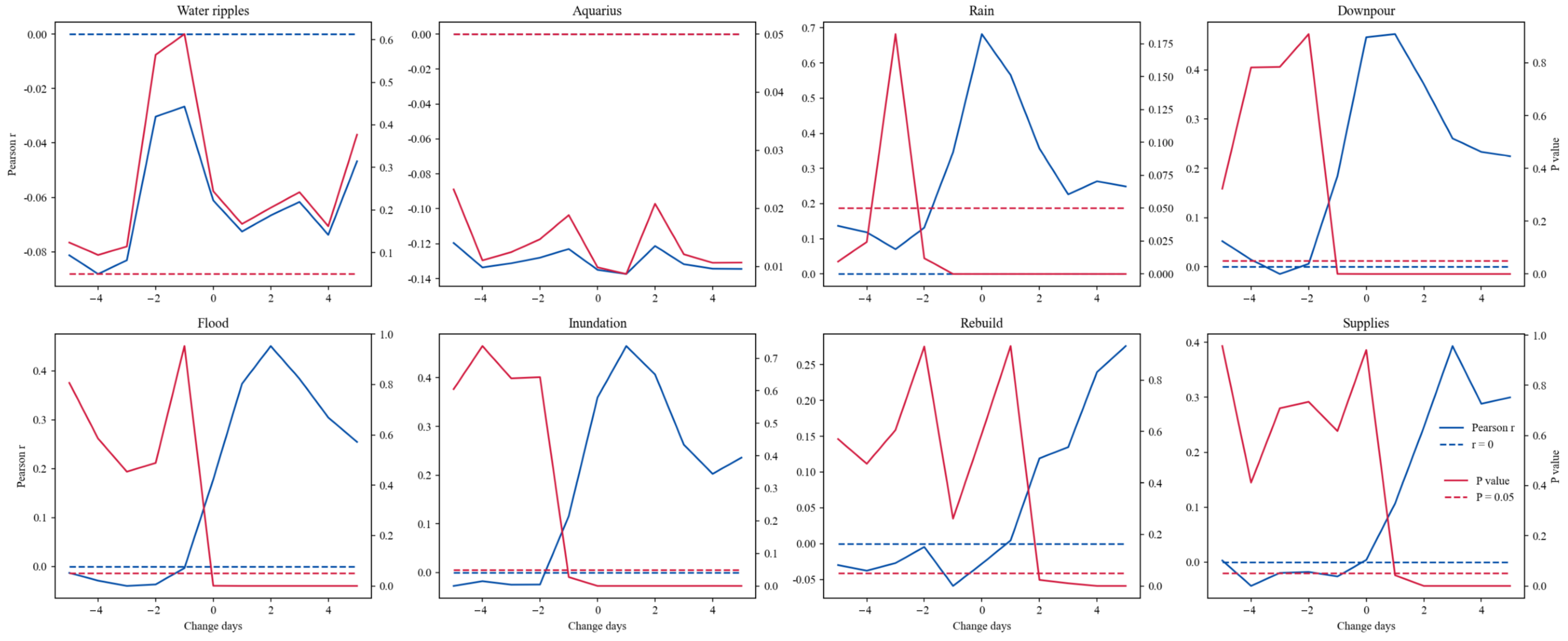
Theoretically, when precipitation leads to flooding, subsequent relief and aid activities ensue post the precipitation peak. To holistically identify linguistic expressions tied to rainfall and flooding, we devised an algorithm dedicated to filtering precipitation-related keywords. Initially, we employed the sliding correlation algorithm [
63], a method prevalent in time series analysis and signal processing, to discern the correlation between the precipitation and WB
K time series. This method identifies time lags or delays between sequences by pinpointing the highest similarity between two-time sequences and establishing their time difference. The essence of sliding correlation is determining the correlation coefficient of two sequences; one remains static while the other slides, enabling correlation coefficient calculation at diverse time junctures. For our research, our sliding window encompassed 11 distinct categories, spanning from −5 to 5 days. Our comprehensive empirical observations indicated that keywords tied to precipitation or with a delayed correlation exhibited a
p-value curve resembling either an L or U shape. These started as non-significant but soon became significant, persisting for a minimum of three consecutive units (days). Drawing from these insights, we formulated a rule-based algorithm to pinpoint keywords intrinsically linked to actual precipitation. The precise steps for screening encompassed the following: We analyzed the slide points in ascending order. If the
p-value at a particular slide point exceeded 0.05 and the subsequent three
p-values were all below 0.05, the keyword was deemed precipitation-related for the city. To characterize such keywords, we introduced two metrics: the Maximum Coefficient of Correlations (MCC) and the Optimal Latency (OL). We determined the MCC by finding the highest correlation coefficient among points with a
p-value below 0.05, where the x-coordinate of this point indicated the OL. Upon identifying all relevant keywords, we utilized Large Language Model ChatGPT to categorize these keywords into rainfall, flood, and other related terms.
3.4. Spatial Analysis of Rainfall and Flood Related Keywords
After filtering precipitation-related keywords, we identified the significant keywords associated with each city. In other words, we could map the city distribution for each of these significant keywords. To conduct a rigorous analysis of the spatial characteristics of cities that are significantly correlated with each keyword, we employed two methodologies: the Global Moran’s I index [
64] for spatial correlation assessment and the median center algorithm [
65] for pinpointing central locations. The Global Moran’s I index requires two critical inputs: attribute values and a spatial weight matrix. In our setup, cities significantly related to a particular keyword were assigned a value of “1”, while all other cities were marked “0”. We derived our spatial weight matrix from the Queen’s contiguity matrix [
66], which accounts for both shared vertices and edge connections. For the computational aspects, we leveraged the spatial exploratory data analysis libraries esda and libpysal [
67]. We used the median center algorithm to determine the central location of corresponding cities which had a value equal to “1” for each significant keyword. This algorithm calculates the median position across all cities significantly related to a particular keyword, providing a robust measure for understanding distribution patterns and identifying optimal locations within geographical regions.
5. Discussion
The goal of this study is to measure the diversity of urban linguistic expressions by creating new techniques to capture expressions related to rainfall and flooding. By doing so, we provide a more comprehensive and detailed description of the public’s perception and expression when facing rainfall or floods and analyze the regional heterogeneity of this expression. In this section, we will further reveal the mechanisms behind these heterogeneities and variations by discussing the possible factors that may influence the choice of specific public language, as well as the potential factors that enrich urban linguistic expression, and provide some insights and ideas for leveraging language diversity for urban resilience.
5.1. Potential Influencing Factors of the Public Choice of Specific Terms
Overall, the potential factors that might influence the public’s language choices can be divided into two levels: natural and social (
Table 6). The natural level includes two dimensions: rainfall characteristics and weather conditions, while the social level includes education and dialect habits.
Rainfall characteristics are divided into singular rainfall features and multi-dimensional rainfall features. Singular refers mainly to rainfall intensity, different intensities may bring different perceptions and expressions to the public, such as using different terms such as “Light rain”, “Moderate rain”, “Heavy rain”, and “Flood” to describe varying intensities. Multi-dimensional rainfall features include not only rainfall intensity but also rainfall duration, timing, etc. Terms such as “Continuous rain” (连阴雨) and “Prolonged rain” (久雨) are expressions of long-duration, low-intensity rainfall, while phrases such as after the “Rain” (雨后) or “Rainy night” (雨夜) focus more on the timing of the rain.
Temperature, humidity, and other meteorological factors are also important elements influencing the public’s language choices under rainy conditions. For example, “Autumn rain” (秋雨) often appears in expressions such as “A cold snap following autumn rain” (一场秋雨一场寒), representing the combined sensation of rainfall and sudden temperature drop. Such temperature changes are mainly found in northern China, so these expressions are also concentrated there. The term “Plum rain” (梅雨) is commonly used by the public during rainy and highly humid weather because it often feels stuffy and muggy. This humidity condition mainly occurs in southern China, so these expressions are also concentrated there.
Education level is also an important factor affecting the public language choices [
68]. For example, the phrase “Torrential rain pours down” (暴雨如注) mainly appears in large cities such as Beijing, Shanghai, Guangzhou, and Shenzhen. Residents in these cities have higher cultural education levels, leading to more metaphorical expressions and idioms.
Local dialect habits are also an important factor influencing the public language choices [
69]. For example, while “Accumulated water” (积水) is a common term to describe floods, people in Nanchang might say “The water has risen” (涨水), and Cantonese speakers might use “Soaked” (水浸) as in “Heavy rain, waterlogged streets” (落雨大,水浸街). People in the northern dialect areas might say something such as “where did all this water come from?” (哪来这么多水?)
5.2. Potential Influencing Factors of the Richness of Urban Language Expressions
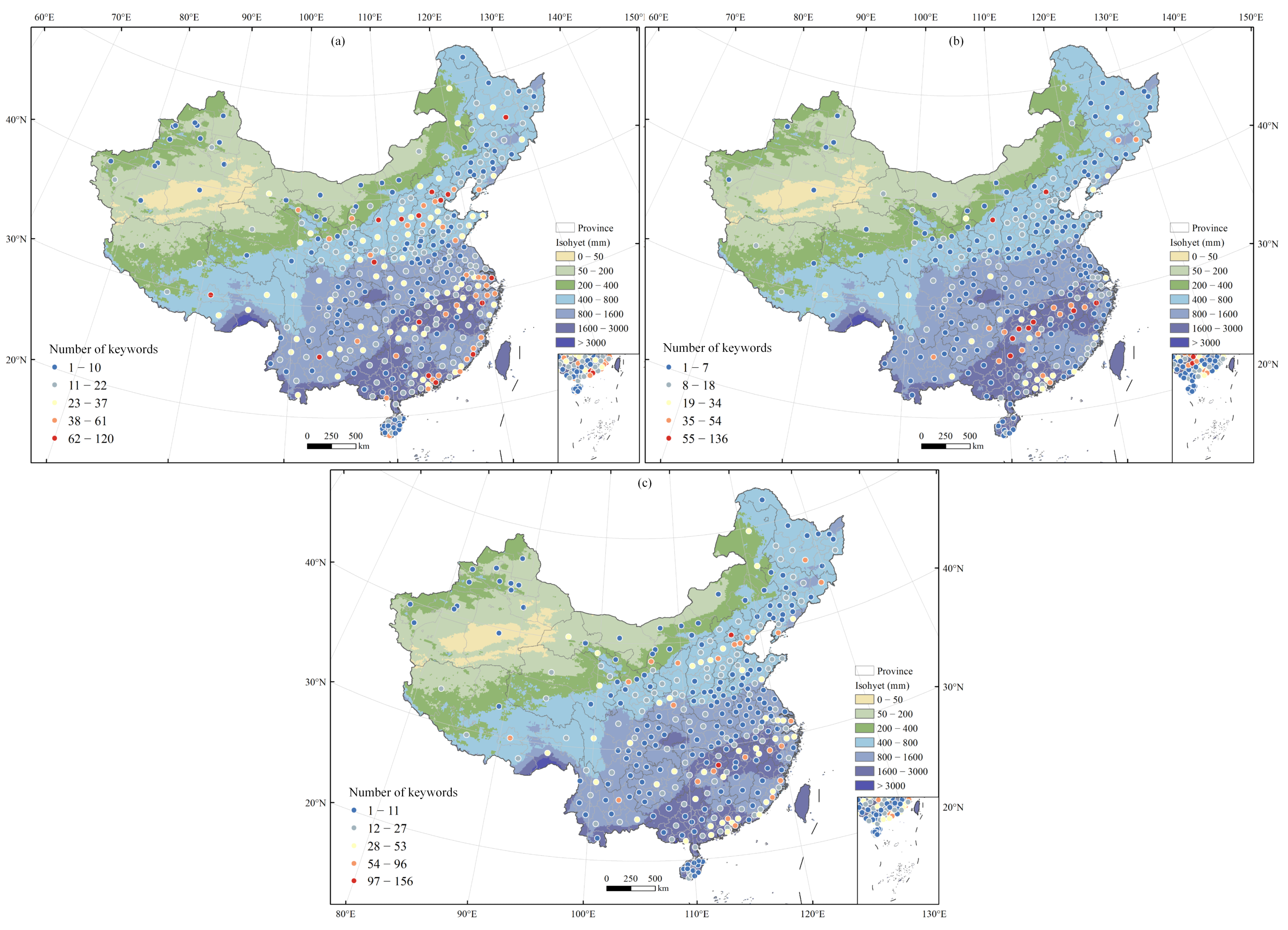
Regarding the expression of rainfall, the selection of terminology in large cities is more diverse (
Figure 6), possibly due to the following reasons:
Population migration: large cities typically attract more outsiders, who come from various regions and backgrounds, each bringing their unique language and expressions [
70]. This cultural blend results in a more varied and enriched language expression in big cities.
Education level: The educational standard in big cities is generally higher. People have received better education, making their understanding and use of language more accurate and precise [
71]. This high level of education leads to more enriched language expression in large cities.
Media communication: large cities are often hubs for media, including newspapers, magazines, television, and radio [
72]. These media spread information and language expressions that are more diverse and richer. Exposure to various vocabulary and expressions through media also enhances the richness of language expression in large cities.
Social networks: Social networks in big cities are well-developed, enabling people to easily connect with others from various backgrounds and professions, thus promoting the diversity and richness of language communication and expression [
73].
In conclusion, the increased richness in language expression in large cities may result from the combined influence of factors such as population migration, educational standards, media communication, and social networks.
5.3. Leveraging Language Diversity for Urban Resilience
Our research introduces a nuanced perspective on urban management by demonstrating how language diversity can sharpen the accuracy and sensitivity of public perceptions regarding rainfall and flood events. This approach fosters a more resilient and sustainable model of urban governance, encapsulated in three key phases: precise rainfall assessment, effective disaster response, and comprehensive post-disaster recovery.
First, leveraging the variety of languages in describing rainfall events enables a more accurate public understanding, enhancing the classification of rainfall intensity beyond simple physical measurements. This nuanced perception is crucial for issuing targeted weather alerts and services that meet the specific needs of diverse demographic groups, thereby improving public preparedness and safety.
Second, recognizing and understanding localized language expressions are vital in crafting effective disaster response strategies, especially in regions with multiple dialects. This ensures that emergency planning is inclusive, preventing the oversight of local needs and promoting more efficient, community-focused responses.
Third, the rich diversity of language expressions in the aftermath of disasters provides insights into the public’s emotional states and needs, enabling the development of more grounded and effective recovery strategies. Such strategies support urban resilience by ensuring that recovery efforts are closely aligned with the actual experiences and preferences of affected communities [
74].
Incorporating language diversity into urban management and environmental policy-making results in more effective and nuanced strategies across all disaster management stages. This approach marks a significant advancement in urban governance, promising enhanced growth and resilience for cities. By catering to the linguistic needs of diverse communities, we can foster a more informed, prepared, and resilient urban populace, contributing significantly to global efforts against climate change and its impacts.
5.4. Limitations and Future Directions
The study, while offering valuable insights, has room for enhancement in its demographic representation. According to the “2020 Weibo User Development Report”, a significant portion of Weibo’s user base skews younger, with about 80% being from the post-90s and post-00s cohorts [
75]. Consequently, the findings primarily reflect linguistic practices among young and middle-aged urbanites, leaving a gap in understanding the language use among other critical demographic groups such as the elderly, children, and residents of rural areas. This demographic skew may limit the generalizability of the study’s conclusions across broader populations. Future research should aim to diversify sample populations to include these underrepresented groups, thereby offering a more comprehensive view of linguistic patterns and preferences. Expanding the demographic reach would not only enrich the dataset but also enhance the applicability and relevance of the research findings to a wider audience, providing deeper insights into language evolution and usage across different age groups and living environments.
Moreover, the study overlooks the influence of climatic conditions on the interpretation of weather-related keywords, which can vary significantly across different regions. For instance, the term “Downpour” might be perceived differently by residents of arid areas, who may use it to describe less severe precipitation events, compared to those living in humid regions. Research by Qian, Du [
36] highlights substantial spatial differences in the perception thresholds of heavy rain across China, with higher thresholds observed in southern cities compared to northern ones, and even surpassing the standard 50 mm heavy rain warning criteria. Coastal cities, especially in the southeast, exhibit lower perception thresholds due to the compounded risks of heavy rains and storm surges, leading to potential disruptive flooding. Future research endeavors should delve into the complex interactions between climatic conditions and the usage of specific keywords, particularly those related to extreme weather phenomena. Such investigations would provide nuanced insights into how language adapts to environmental conditions, enriching the discourse on linguistic practices within the context of climate change.
6. Conclusions
The study constructs the keyword library connected to rainfall and floods, and analyzes the semantic characteristics and regional variations of various keywords. By using social media Weibo data in 2017, the study offers the following insights:
Firstly, we present a novel algorithm that identifies linguistic expressions related to rainfall and floods, taking into account the connection between precipitation observations and linguistic expressions. Implementing this algorithm on 210 million social media entries from 2017, we identified 594 keywords related to rainfall and flooding. This count is 20 times higher than the typical manually created bag-of-words used in many studies, significantly enriching the keyword library. These results lay a robust foundation for research that employs social media data to explore public perceptions of rainfall and flood events. Particularly in linguistically diverse regions such as China, our algorithm enhances the comprehensiveness and precision of such studies.
Secondly, we conduct a comprehensive analysis of three types of keywords’ semantic attributes, including popularity, credibility, time delay, and part-of-speech. Among the three categories, rainfall-related keywords are the most widely used, notably “Rainy” (下雨), “Rain” (雨), “Downpour” (暴雨); flood-related keywords often have the longest delay, with perceptions of flood damage typically delayed by about a day from the actual peak rainfall. Specifically, for keywords such as “Flooding”, “Post-disaster” (灾后), and “Supplies” (物资), the delay can extend beyond 2 days. There are significant differences in the part-of-speech for keywords across different categories; KWrainfall is primarily a noun, whereas both KWflood and KWother consist of verbs and nouns, but with completely opposite primary and secondary roles.
Thirdly, we analyze spatial characteristics from two perspectives: the keyword viewpoint (considering regional applicability and global or local nature) and the city-centric view (evaluating keyword diversity within cities). Among the 594 keywords, 49.5% show significant spatial correlation, reflecting potential regional variations in expression. For instance, “Autumn rain” (秋雨) refers mainly to precipitation in northern China, while “Plum rain” (梅雨) pertains to the rainy season in the Yangtze River’s middle and lower reaches and southern China. Major urban centers, such as Beijing-Tianjin-Hebei, Yangtze River Delta, Pearl River Delta, and cities such as Shijiazhuang, Xi’an, Changsha, Guangzhou, and Kunming, show a higher concentration of rainfall-related keywords. Conversely, areas with varied flood-related expressions are mainly found in regions with over 1600 mm of annual rainfall and a historical prevalence of flood disasters.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}