
Data Management in Collaborative Interdisciplinary Research Projects—Conclusions from the Digitalization of Research in Sustainable Manufacturing

Abstract
:1. Introduction
2. Characteristics of the CRC 1026—Sustainable Manufacturing
2.1. Mission and Structure of the CRC 1026
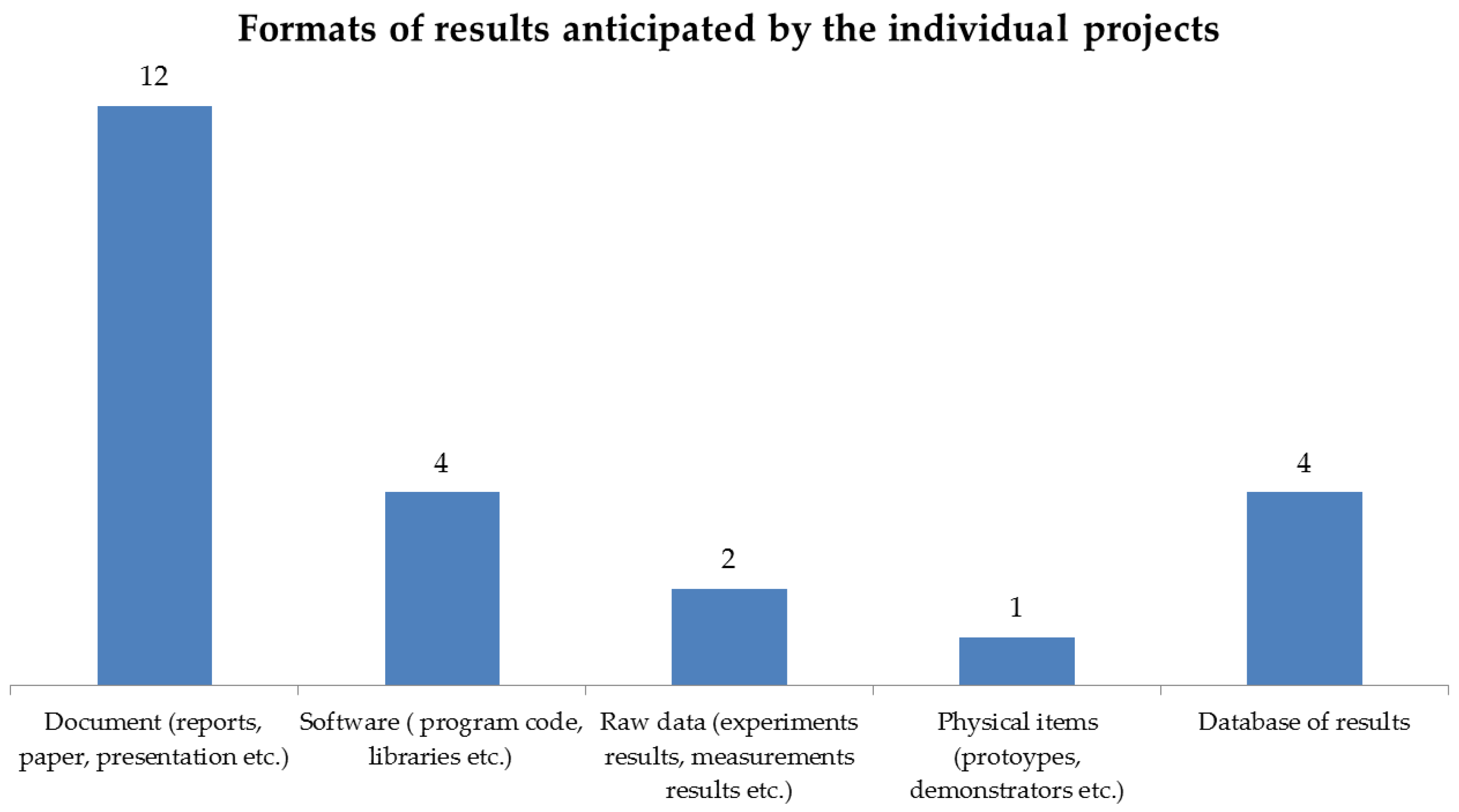
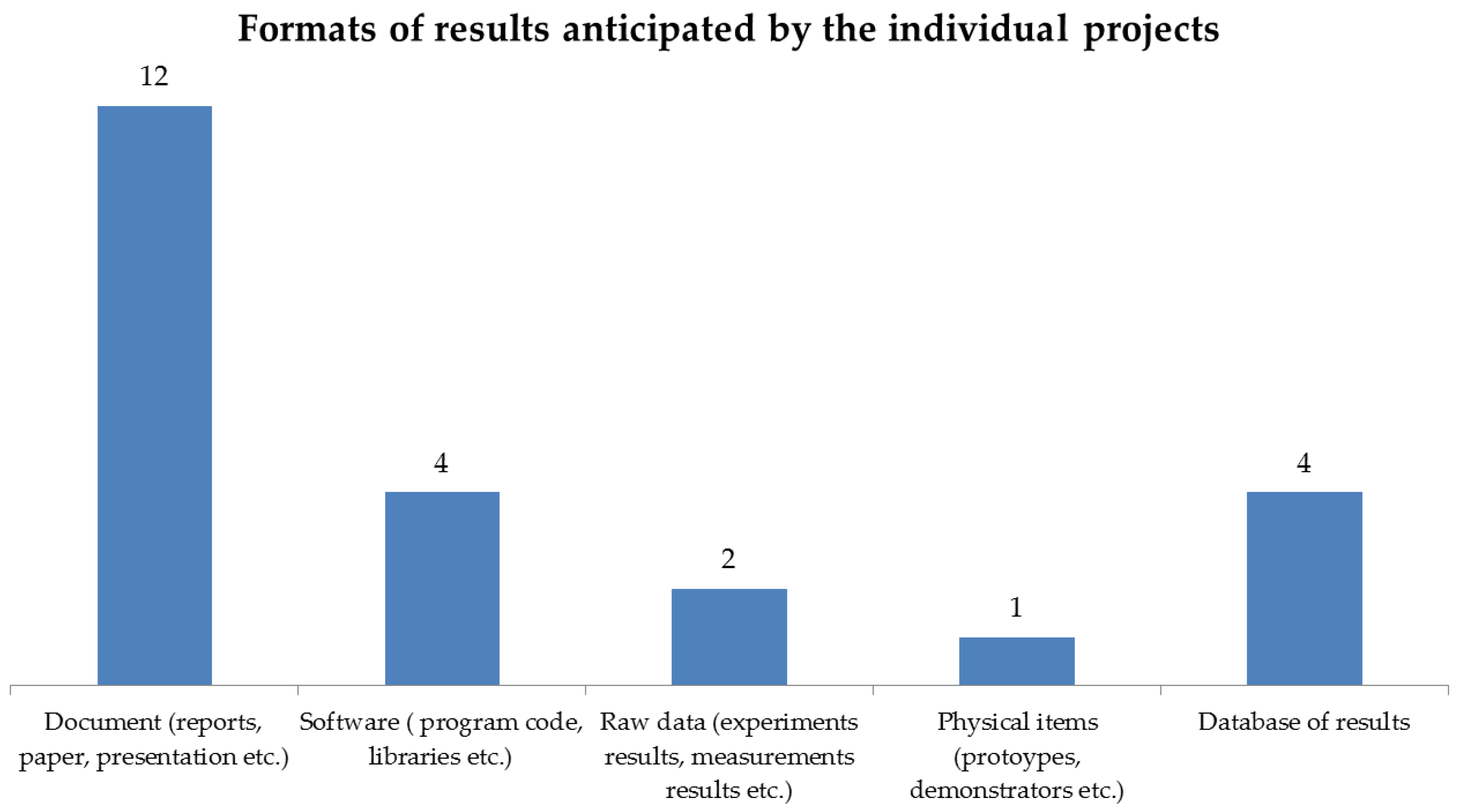
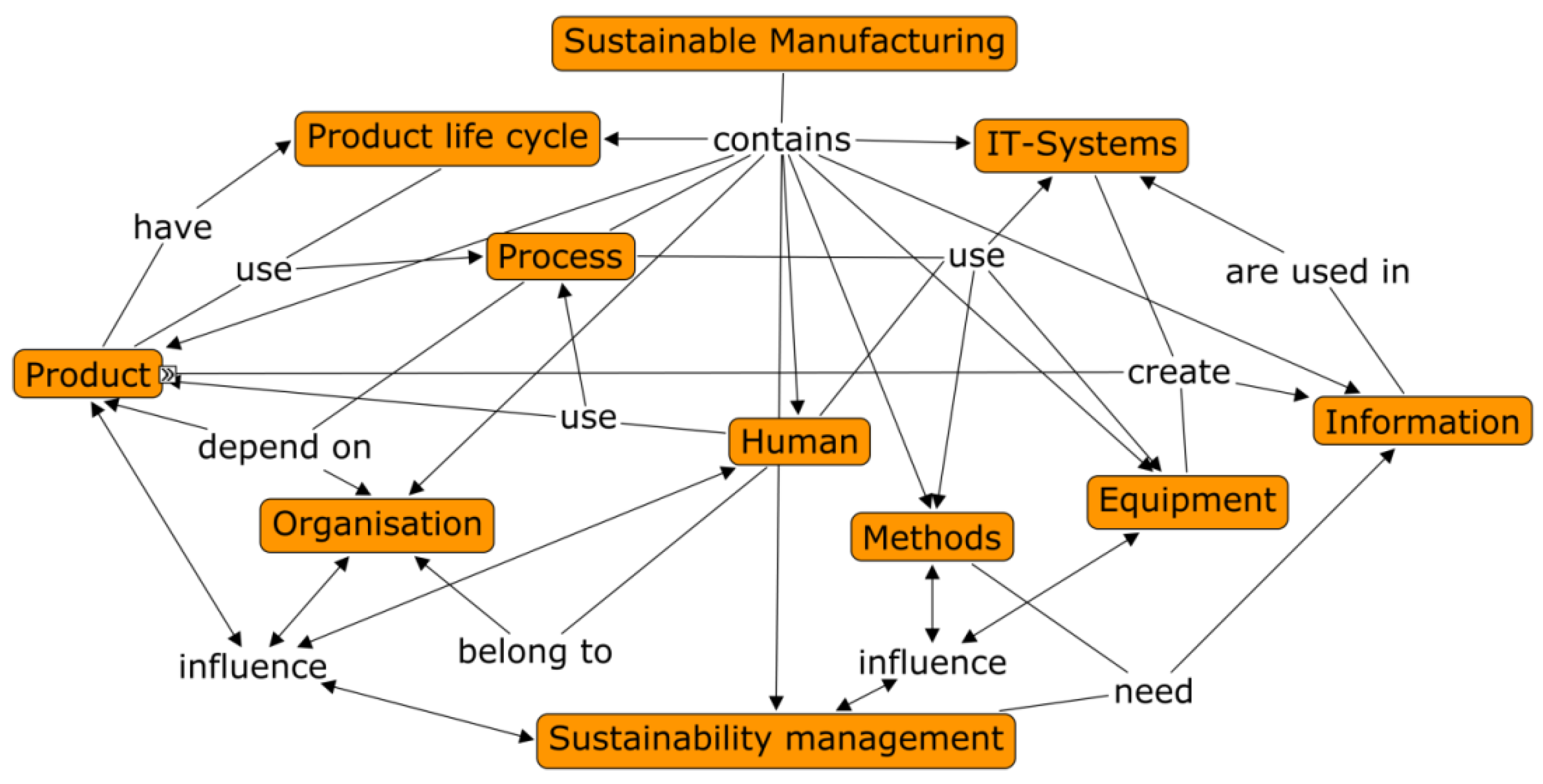
2.2. Expected Outcomes and Data Formats
2.3. Definition of User Requirements for IT Support
3. Results from the Implementation in the CRC 1026
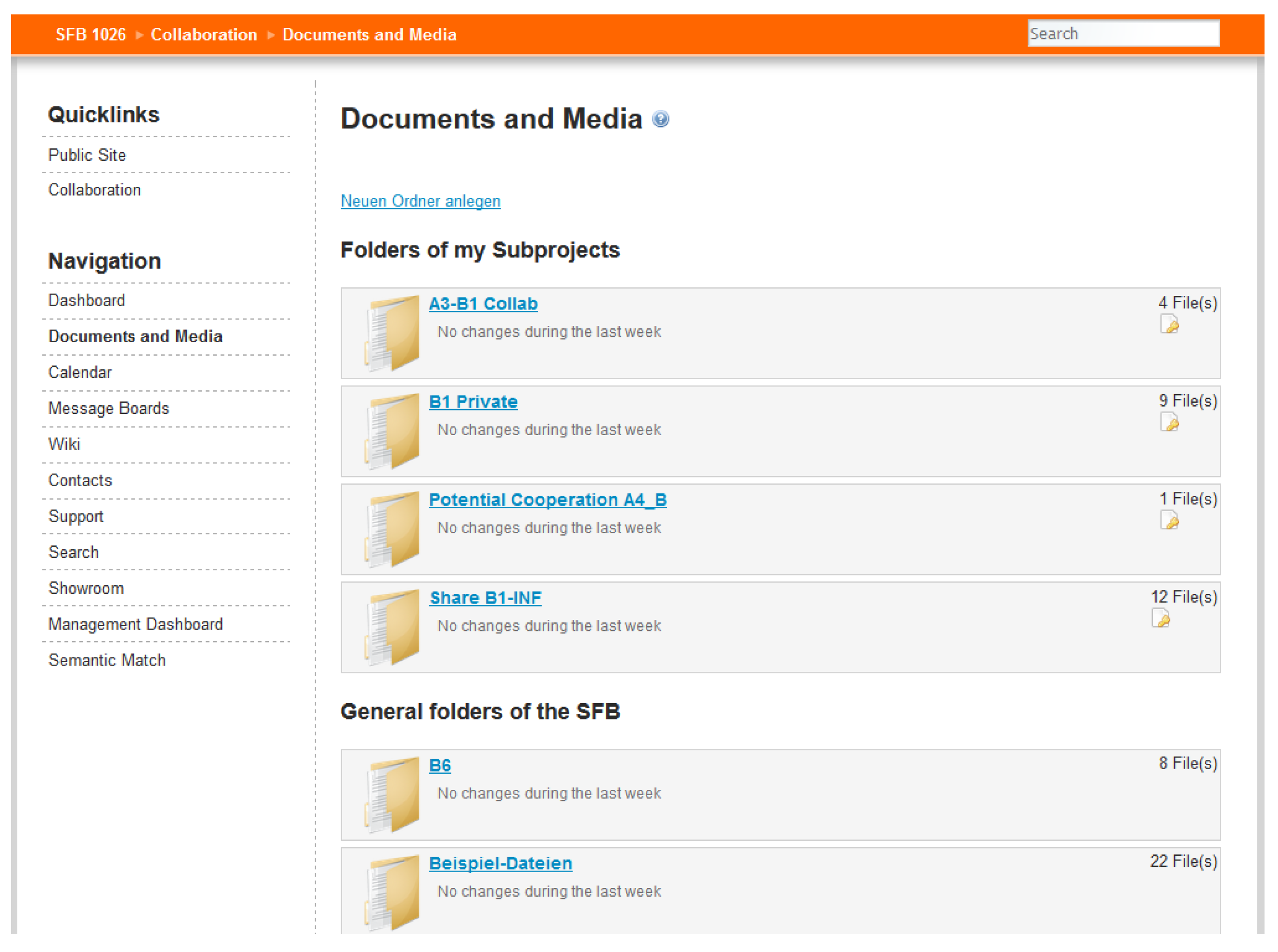
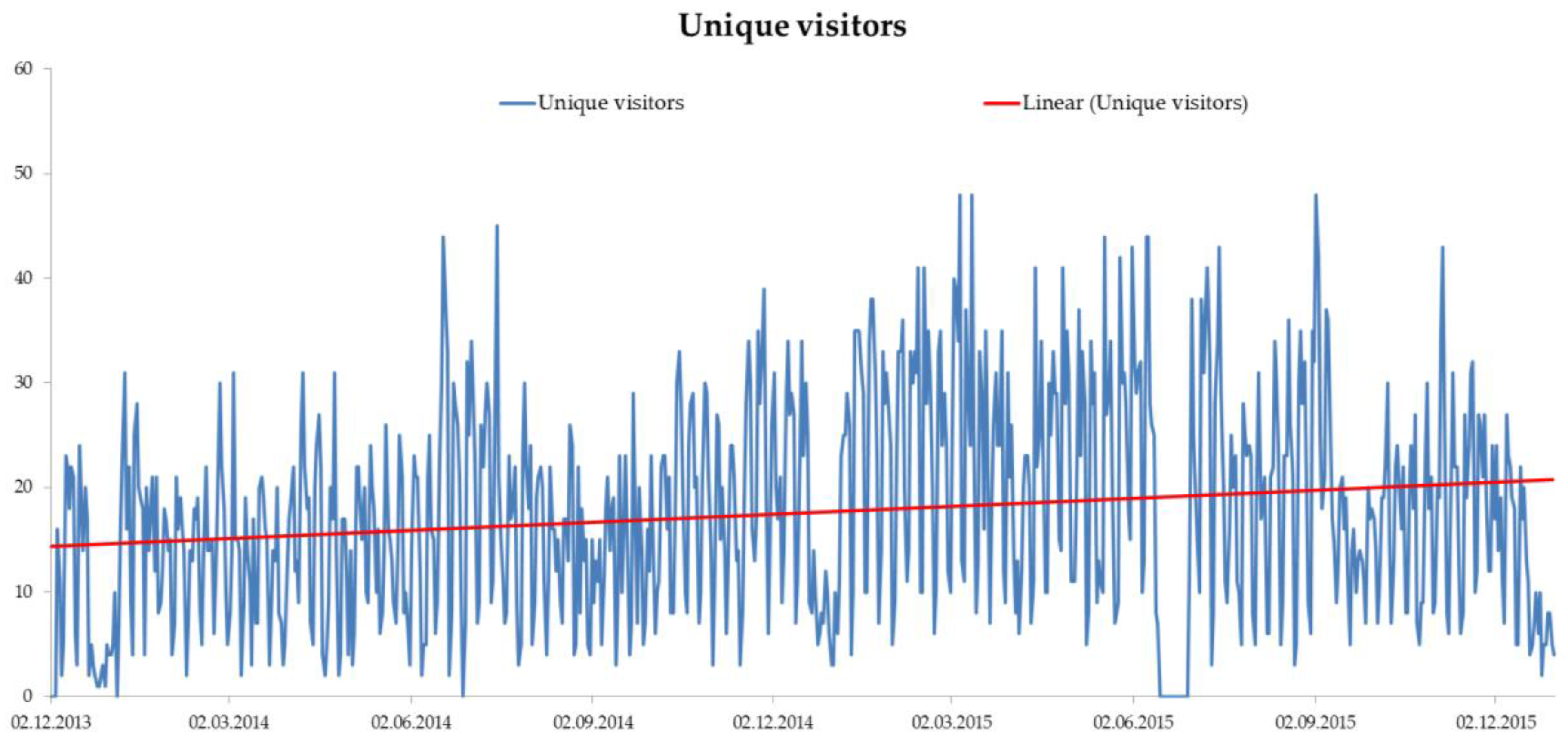
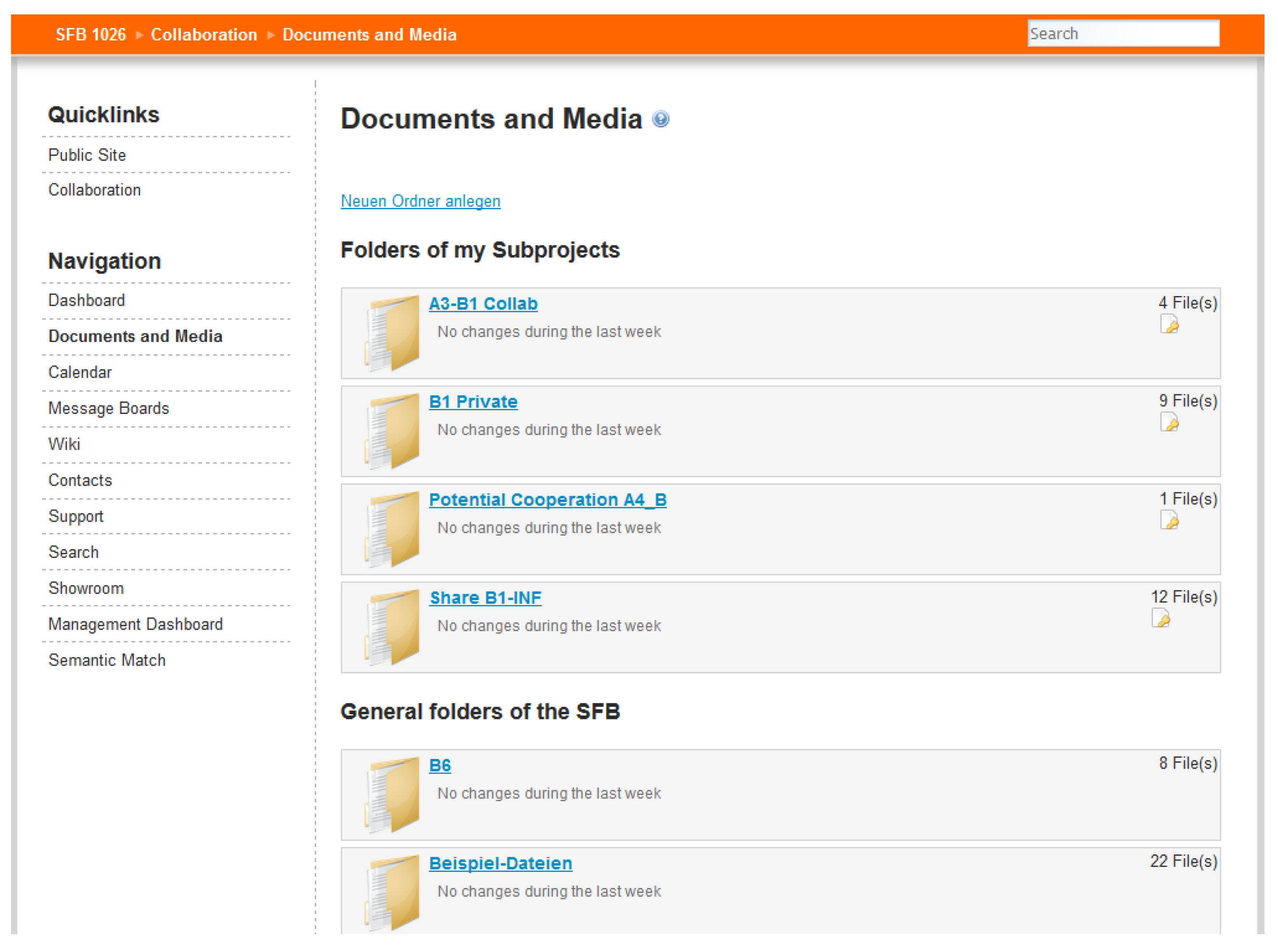
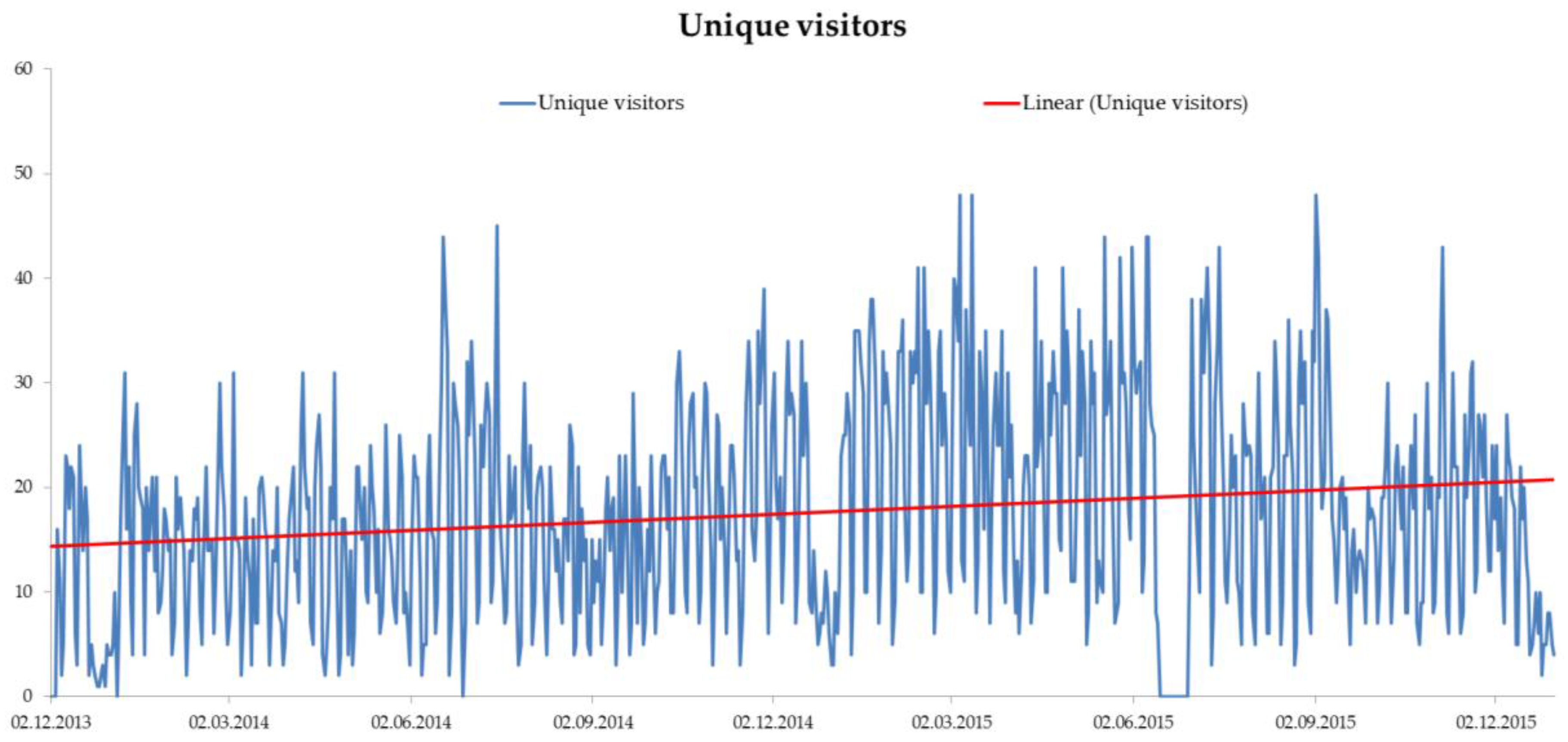
3.1. Foundation of the Information Infrastructure—The CRC Collaboration Platform
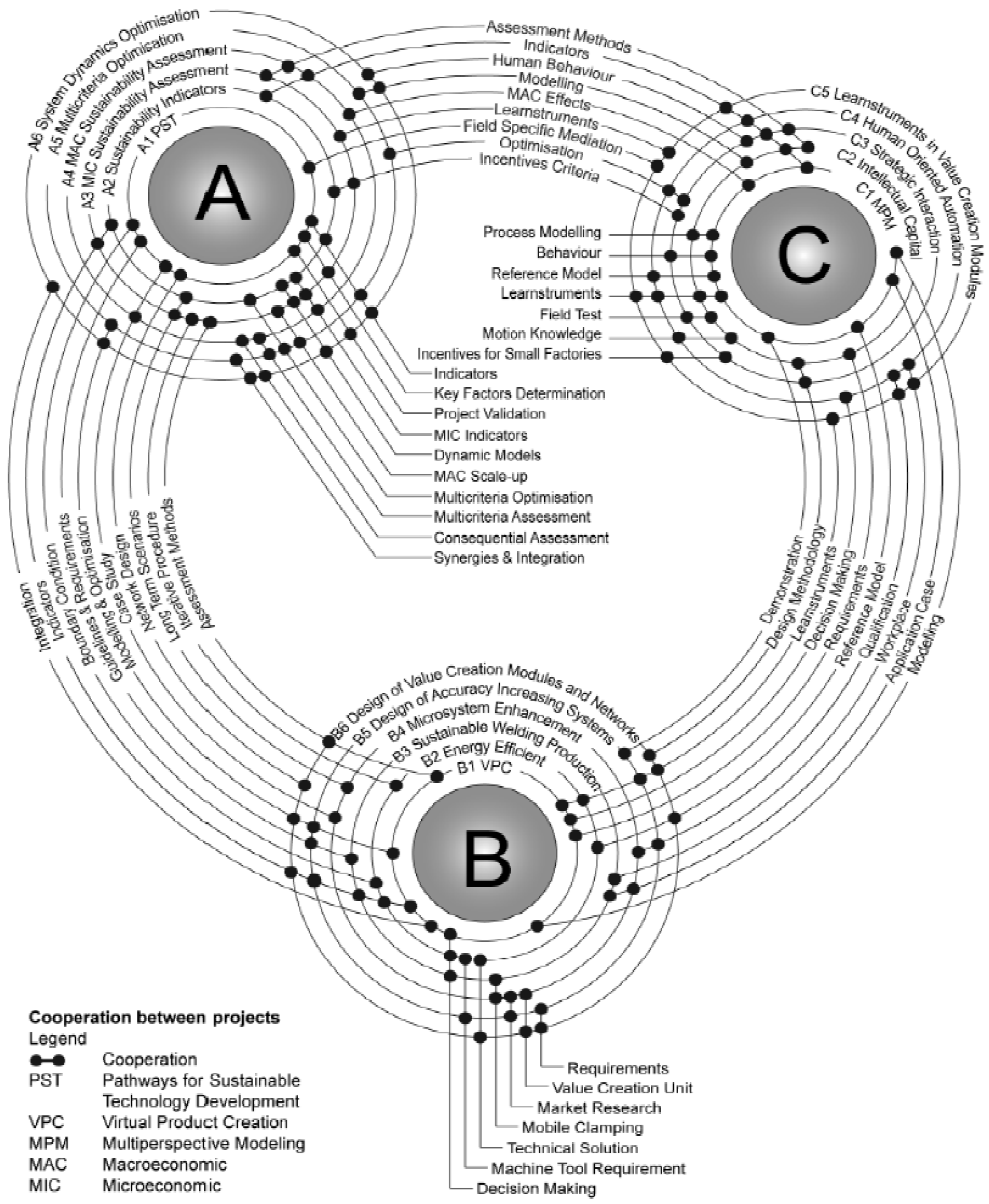
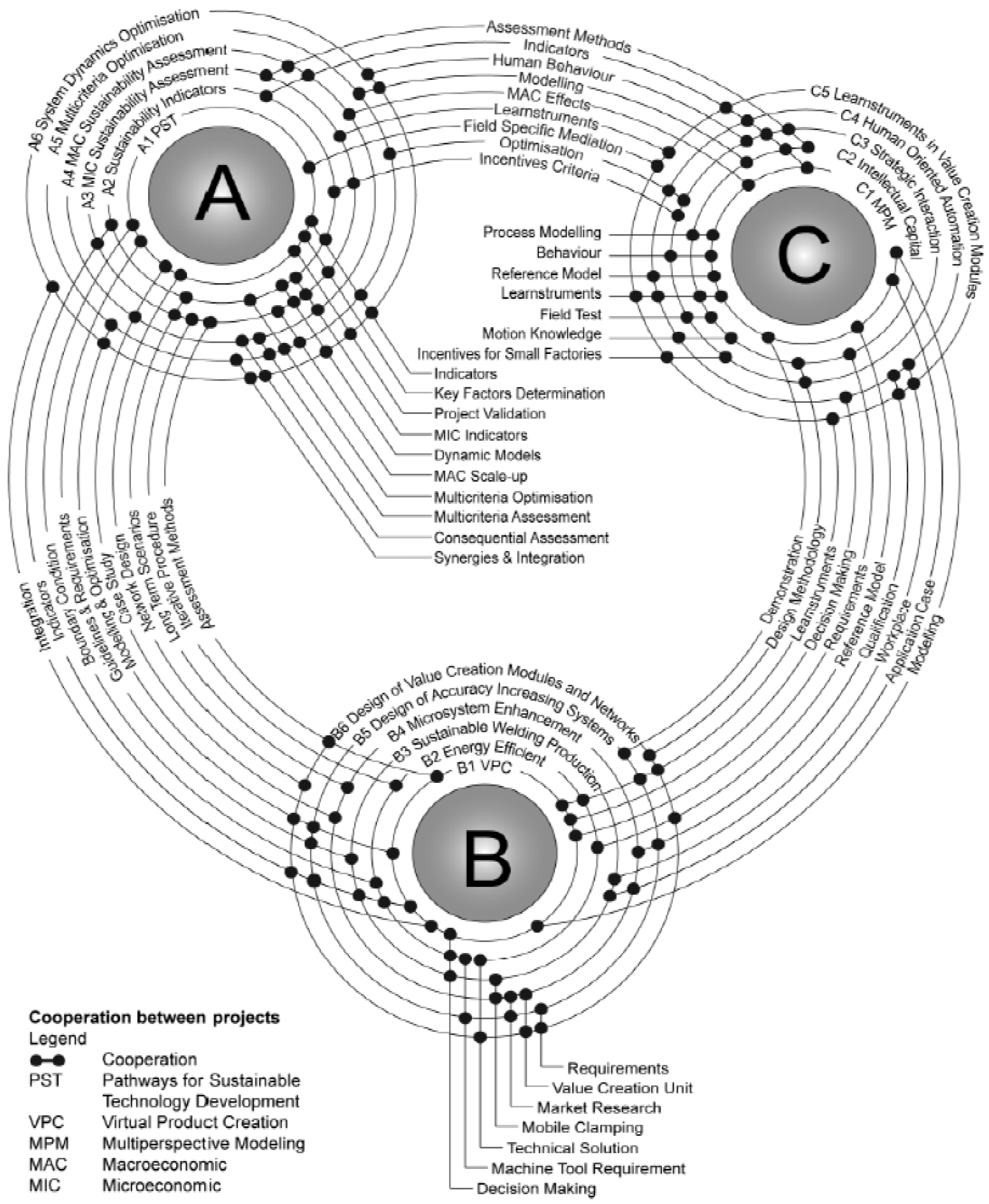
3.2. Management of Task Related Data within Large Groups
3.3. Ontology Based Data Management Concept and Prototype
- Semantic children: Sub-concepts of the evaluated concept
- Semantic siblings: Sub-concepts of a super-concept of the evaluated concept
- Semantic neighbors: Concepts with any other direct semantic connection to the evaluated concept
4. Discussion of the Solution Deployment
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| CRC | Collaborative Research Center |
| DFG | Deutsche Forschungsgemeinschaft (German Science Foundation) |
| INF | Service Project for Information Infrastructure |
| GHG | Greenhouse gas |
| RDF-S | Resource Description Framework Schema |
| OWL | Web-Ontology Language |
| SZF | Servicezentrum für Forschungsdaten und –publikationen (Service Center for Research Data and Publications) |
References
- Haythornthwaite, C. Learning and knowledge networks in interdisciplinary collaborations. J. Am. Soc. Inf. Sci. Technol. 2006. [Google Scholar] [CrossRef]
- Raasch, C.; Lee, V.; Spaeth, S.; Herstatt, C. The rise and fall of interdisciplinary research: The case of open source innovation. Res. Policy 2013. [Google Scholar] [CrossRef]
- Corley, E.A.; Boardman, P.C.; Bozeman, B. Design and the management of multi-institutional research collaborations: Theoretical implications from two case studies. Res. Policy 2006. [Google Scholar] [CrossRef]
- Katz, J.S.; Martin, B.R. What is research collaboration? Res. Policy 1997, 26, 1–18. [Google Scholar] [CrossRef]
- Pennington, D.D. Cross-Disciplinary Collaboration and Learning. Available online: http://www.ecologyandsociety.org/vol13/iss2/art8/ (accessed on 6 January 2016).
- Williams, P. The Competent Boundary Spanner. Public Adm. 2002. [Google Scholar] [CrossRef]
- Patel, H.; Pettitt, M.; Wilson, J.R. Factors of collaborative working: A framework for a collaboration model. Appl. Ergon. 2012. [Google Scholar] [CrossRef] [PubMed]
- Van Rijnsoever, F.J.; Hessels, L.K. Factors associated with disciplinary and interdisciplinary research collaboration. Res. Policy 2011. [Google Scholar] [CrossRef]
- Nooteboom, B. Learning by Interaction: Absorptive Capacity, Cognitive Distance and Governance. J. Manag. Gov. 2000. [Google Scholar] [CrossRef]
- Büttner, S.; Hobohm, H.; Müller, L. Research Data Management. In Handbuch Forschungsdatenmanagement; Büttner, S., Hobohm, H., Eds.; Bock + Herchen: Bad Honnef, Germany, 2011; pp. 13–24. [Google Scholar]
- Dallmeier-Tiessen, S. Strategien bei der Veröffentlichung von Forschungsdaten. In Handbuch Forschungsdatenmanagement; Büttner, S., Hobohm, H., Eds.; Bock + Herchen: Bad Honnef, Germany, 2011; pp. 169–190. [Google Scholar]
- Effertz, E. The funder‘s perspective: Data management in coordinated programmes of the German Research Foundation (DFG). In Proceedings of the Data Management Workshop, Cologne, Germany, 29–30 October 2009.
- Rümpel, S. Der Lebenszyklus von Forschungsdaten. In Handbuch Forschungsdatenmanagement; Büttner, S., Hobohm, H., Eds.; Bock + Herchen: Bad Honnef, Germany, 2011; pp. 25–34. [Google Scholar]
- Huschka, D.; Oellers, C.; Ott, N. Datenmanagement und Data Sharing: Erfahrungen in den Sozial- und Wirtschaftswissenschaften. In Handbuch Forschungsdatenmanagement; Büttner, S., Hobohm, H., Eds.; Bock + Herchen: Bad Honnef, Germany, 2011; pp. 35–48. [Google Scholar]
- Wolter, L.; Wang, W.M.; Rainer, S. Information Systems to Support Collaboration in Large Research Projects. IJMO 2014. [Google Scholar] [CrossRef]
- Parent-Thirion, A.; Vermeylen, G.; van Houten, G.; Lyly-Yrjänäinen, M.; Biletta, I.; Cabrita, J. 5th European Working Conditions Survey. Available online: http://www.eurofound.europa.eu/surveys/2010/fifth-european-working-conditions-survey-2010 (accessed on 8 January 2016).
- Lapillonnee, B.; Pollier, K.; Samci, N. Energy Efficiency Trends in the EU—Lessons from the ODYSSEE MURE Project. Available online: http://www.odyssee-mure.eu/publications/br/synthesis-energy-efficiency-trends-policies.pdf (accessed on 14 January 2016).
- European Commission - Directorate-Genaral for Energy (op. 2013): EU energy in figures. Statistical pocketbook 2013. Luxembourg. Available online: https://ec.europa.eu/energy/sites/ener/files/documents/2013_pocketbook.pdf (accessed on 18 January 2016).
- Duflou, J.R.; Sutherland, J.W.; Dornfeld, D.; Herrmann, C.; Jeswiet, J.; Kara, S.; Hauschild, M.; Kellens, K. Towards energy and resource efficient manufacturing: A processes and systems approach. CIRP Ann. Manuf. Technol. 2012. [Google Scholar] [CrossRef]
- Diallo, Y.; Etienne, A.; Mehran, F. Global Child Labour Trends 2008 to 2012; ILO: Geneva, Switzerland, 2013. [Google Scholar]
- Steckel, J.C.; Edenhofer, O.; Jakob, M. Drivers for the renaissance of coal. Proc. Natl. Acad. Sci. USA 2015. [Google Scholar] [CrossRef] [PubMed]
- Edmund, A.S. Geschichte der Nachhaltigkeit: Vom Werden und Wirken Eines Beliebten BEGRIFFES. 2012. Available online: http://www.nachhaltigkeit.info/media/1326279587phpeJPyvC.pdf (accessed on 21 April 2014).
- Wissenschaftliche Dienste des Deutschen Bundestages. Nachhaltigkeit: Wissenschaftliche Dienste des Deutschen Bundestages. 2004. Available online: http://webarchiv.bundestag.de/archive/2008/0506/wissen/analysen/2004/2004_04_06.pdf (accessed on 21 April 2014).
- Giddings, B.; Hopwood, B.; O’Brien, G. Environment, economy and society: fitting them together into sustainable development. Sustain. Dev. 2002. [Google Scholar] [CrossRef]
- Uschold, M.; Grüninger, M. Ontologies: Principles, methods and applications. Knowl. Eng. Rev. 1996, 11, 93–136. [Google Scholar] [CrossRef]
- Neher, G.; Ritschel, B. Semantische Vernetzung von Forschungsdaten. In Handbuch Forschungsdatenmanagement; Büttner, S., Hobohm, H., Eds.; Bock + Herchen: Bad Honnef, Germany, 2011; pp. 169–190. [Google Scholar]
- Wang, W.M.; Pförtner, A.; Lindow, K.; Hayka, H.; Stark, R. Using ontology to support scientific interdisciplinary collaboration within joint sustainability research projects. In Proceedings of the 11th Global Conference on Sustainable Manufacturing: Innovative Solutions, Berlin, Germany, 23–15 September 2013; pp. 612–617.
- Göpfert, T. Matching Ontological Concepts with Documents: A Semantic Matching Approach in Context of Bibliometric Community Detection. Mater’s Thesis, Humboldt–Universität zu Berlin, 2016. [Google Scholar]
- Giunchiglia, F.; Kharkevich, U.; Zaihrayeu, I. Concept Search. Lect. Notes Comput. Sci. 2009, 5554, 429–444. [Google Scholar]
- Navigli, R.; Velardi, P. An Analysis of Ontology-based Query Expansion Strategies. Cavtat-Dubrovnik. In Proceedings of the Conference on Machine Learning (ECML 2003), Dubrovnik, Croatia, 22–26 September 2003.
- Khan, L.; McLeod, D.; Hovy, E. Retrieval effectiveness of an ontology-based model for information selection. VLDB J. 2004, 13, 71–85. [Google Scholar] [CrossRef]
- Anyanwu, K.; Sheth, A. ρ-Queries: Enabling Querying for Semantic Associations on the Semantic Web. In Proceedings of the 12th International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003.
- Zhou, Q.; Wang, C.; Xiong, M.; Wang, H.; Yu, Y. SPARK: Adapting Keyword Query to Semantic Search. Lect. Notes Comput. Sci. 2007, 4825, 694–707. [Google Scholar]
- Rocha, C.; Schwabe, D.; de Aragao, M.P. A Hybrid Approach for Searching in the Semantic Web. In Proceedings of the 13th International Conference on World Wide Web, New York, NY, USA, 17–22 May 2004.
- Cheng, G.; Ge, W.; Qu, Y. Falcons: Searching and Browsing Entities on the Semantic Web. In Proceedings of the 17th International World Wide Web Conference, Beijing, China, 21–25 April 2008.
- Fernandez, M.; Lopez, V.; Sabou, M.; Uren, V.; Vallet, D.; Motta, E.; Castells, P. Semantic Search Meets the Web. In Proceedings of the 2008 IEEE International Conference on Semantic Computing, Santa Clara, CA, USA, 4–7 August 2008; pp. 253–260.
- Wang, W.M.; Wolter, L.; Lindow, K.; Stark, R. Graphical Visualization of Sustainable Manufacturing Aspects for Knowledge Transfer to Public Audience. Proced. CIRP 2015. [Google Scholar] [CrossRef]
- Fuchs-Kittowski, K.; Heinrich, L.J.; Rolf, A. Information entsteht in Organisationen—In Kreativen Unternehmen—Wissenschaftstheoretische und methodologische Konsequenzen für die Wirtschaftsinformatik. In Wirtschaftsinformatik und Wissenschaftstheorie; Springer: Berlin, Germany, 1999; pp. 329–361. [Google Scholar]
- Wenger, E.C.; Snyder, W.M. Communities of practice: The organizational frontier. Harv. Bus. Rev. 2000, 78, 139–146. [Google Scholar]
- Pickett, S.T.; Burch, W.R., Jr.; Grove, J.M. Interdisciplinary research: Maintaining the constructive impulse in a culture of criticism. Ecosystems 1999, 2, 302–307. [Google Scholar] [CrossRef]
- Cox, A.; Milsted, A.J.; Gutteridge, C.J. Linked Data Technology Making Autodiscovery of Data a Reality. In Proceedings of the 2nd Data management Workshop, Cologne, Germany, 28–29 November 2014.
- Decker, B.; Politze, M. Ontology Based Semantic Data Management for Pandisciplinary Research Projects. In Proceedings of the 2nd Data management Workshop, Cologne, Germany, 28–29 November 2014.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Average Rating | Feature Name | Description |
|---|---|---|---|
| 1 | 3.24 | Documents management | Online workspace for sharing documents |
| 2 | 3.23 | Wiki | Common wiki for a shared knowledge base |
| 3 | 3.18 | Mailing lists | E-Mail distribution list for automated notifications |
| 4 | 3.18 | Offline Access | “Dropbox”-like functionality for offline synchronizing of files |
| 5 | 3.07 | Ontology | Tool to create formalized representation of shared knowledge |
| 6 | 3.03 | Document comparison | Feature to compare different document versions |
| 7 | 3.03 | Web content management | Feature to present content on a website |
| 8 | 2.93 | Yellow Pages | Register of CRC researchers and their skills |
| 9 | 2.87 | Literature management | Feature to manage publications |
| 10 | 2.87 | Document versioning | Automated version control feature |
| 11 | 2.85 | Mind mapping | Feature allowing for collaborative creation of mind maps |
| 12 | 2.8 | Semantic Web | Capabilities for enriching data on the platform with semantic information |
| 13 | 2.73 | Tagging | Possibility of adding keywords to files, discussion threads etc. |
| 14 | 2.67 | Polls | Simple and short surveys |
| 15 | 2.58 | Mobile access | Access to the platform via mobile devices |
| 16 | 2.57 | Task management | Management of CRC internal tasks |
| 17 | 2.57 | Access control | Control of access privileges to platform contents |
| 18 | 2.57 | Calendar | Shared calendar |
| 19 | 2.51 | Management Dashboard | Feature to summarize project progress for principal investigators |
| 20 | 2.5 | Online surveys | Feature allowing for conduction of online surveys |
| 21 | 2.5 | Process modelling | Feature supporting collaborative modelling of process |
| 22 | 2.49 | Chat (Text, Voice, Video) | Instant communication features |
| 23 | 2.43 | RSS-Feeds/Newsletter | Automated user notification of content updates and changes |
| 24 | 2.41 | Blog | Feature allowing users to share information to a wide audience |
| 25 | 2.4 | Workflow Management | IT support for CRC internal workflows |
| 26 | 2.33 | Single Sign on | Access all IT services from one single source and with one user account |
| 27 | 2.3 | Reporting | Features to support reporting of the project’s progress |
| 28 | 2.3 | Virtual Reality | Features allowing for immersive experience of research results |
| 29 | 2.23 | Document digitalization | Features supporting digitalization of analogue documents |
| 30 | 2.23 | Personal Dashboard | Customizable personal landing page, which summarizes news relevant to a specific user |
| 31 | 2.23 | Plugins/Viewer | Platform add-ons which allow for viewing of different data types, e.g., CAD models |
| 32 | 2.22 | Augmented Reality | cf. “Virtual Reality” |
| 33 | 2.17 | Shared database | Common data base to store content created in the CRC |
| 34 | 2.1 | Forum | Shared discussion space for the CRC |
| 35 | 2.04 | Tangible User Interfaces | Devices and methods allowing for interaction with digital contents in a tangible way, e.g., by using physical objects |
| 36 | 2.03 | Formula editors | Web-based editors supporting mathematical formulas |
| 37 | 2.03 | Location Awareness | Feature indicating the presence of researchers in the shared work space |
| 38 | 2.03 | Shared Screen | Web conferencing-like feature allowing for sharing of user’s screen |
| 39 | 2 | Enterprise Service Bus | Central feature, which combines and coordinates all available IT-services |
| 40 | 1.94 | Cloud Computing Access | Ubiquitous access to the shared workspace and its services |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.M.; Göpfert, T.; Stark, R. Data Management in Collaborative Interdisciplinary Research Projects—Conclusions from the Digitalization of Research in Sustainable Manufacturing. ISPRS Int. J. Geo-Inf. 2016, 5, 41. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5040041
Wang WM, Göpfert T, Stark R. Data Management in Collaborative Interdisciplinary Research Projects—Conclusions from the Digitalization of Research in Sustainable Manufacturing. ISPRS International Journal of Geo-Information. 2016; 5(4):41. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5040041
Chicago/Turabian StyleWang, Wei Min, Tobias Göpfert, and Rainer Stark. 2016. "Data Management in Collaborative Interdisciplinary Research Projects—Conclusions from the Digitalization of Research in Sustainable Manufacturing" ISPRS International Journal of Geo-Information 5, no. 4: 41. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5040041