
How They Move Reveals What Is Happening: Understanding the Dynamics of Big Events from Human Mobility Pattern


Abstract
:1. Introduction
2. Related Work
3. Proposed Methodology
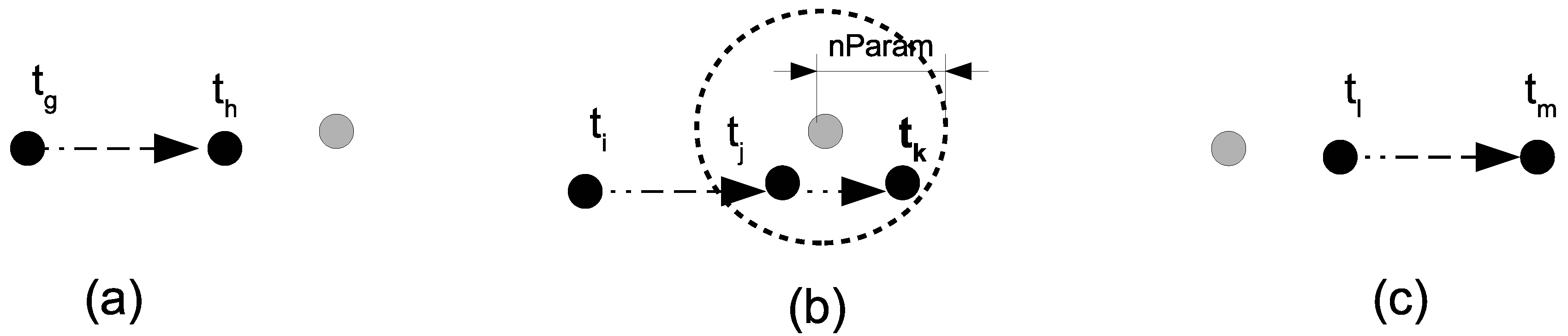
3.1. Basic Concepts and Definitions
3.2. Methods
3.2.1. Extracting Interactions
3.2.2. Spatio-Temporal Analysis of Interactions
4. Experimental Evaluation
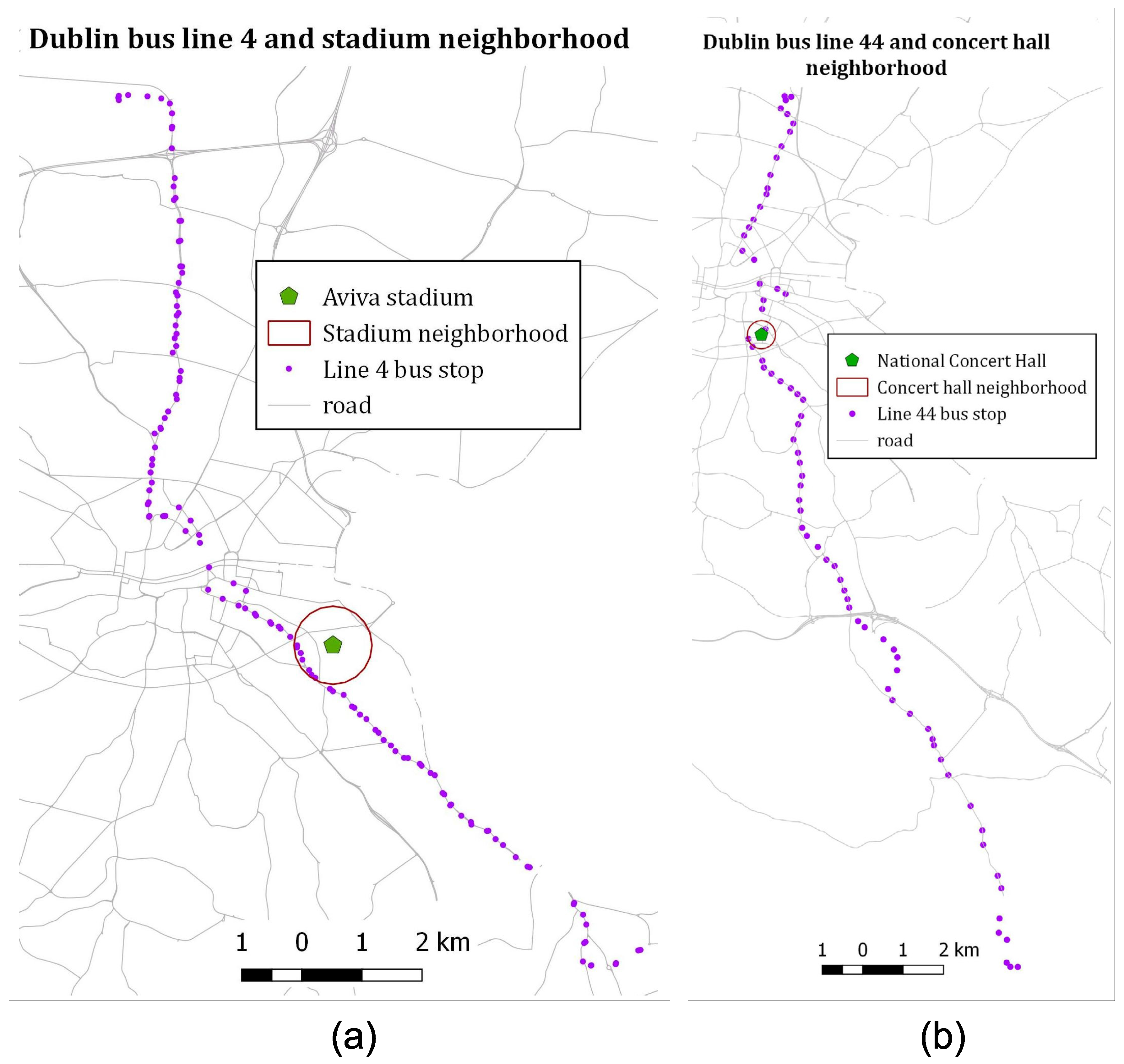
4.1. Data Description and Pre-Processing
4.1.1. Data Description
4.1.2. Data Pre-Processing
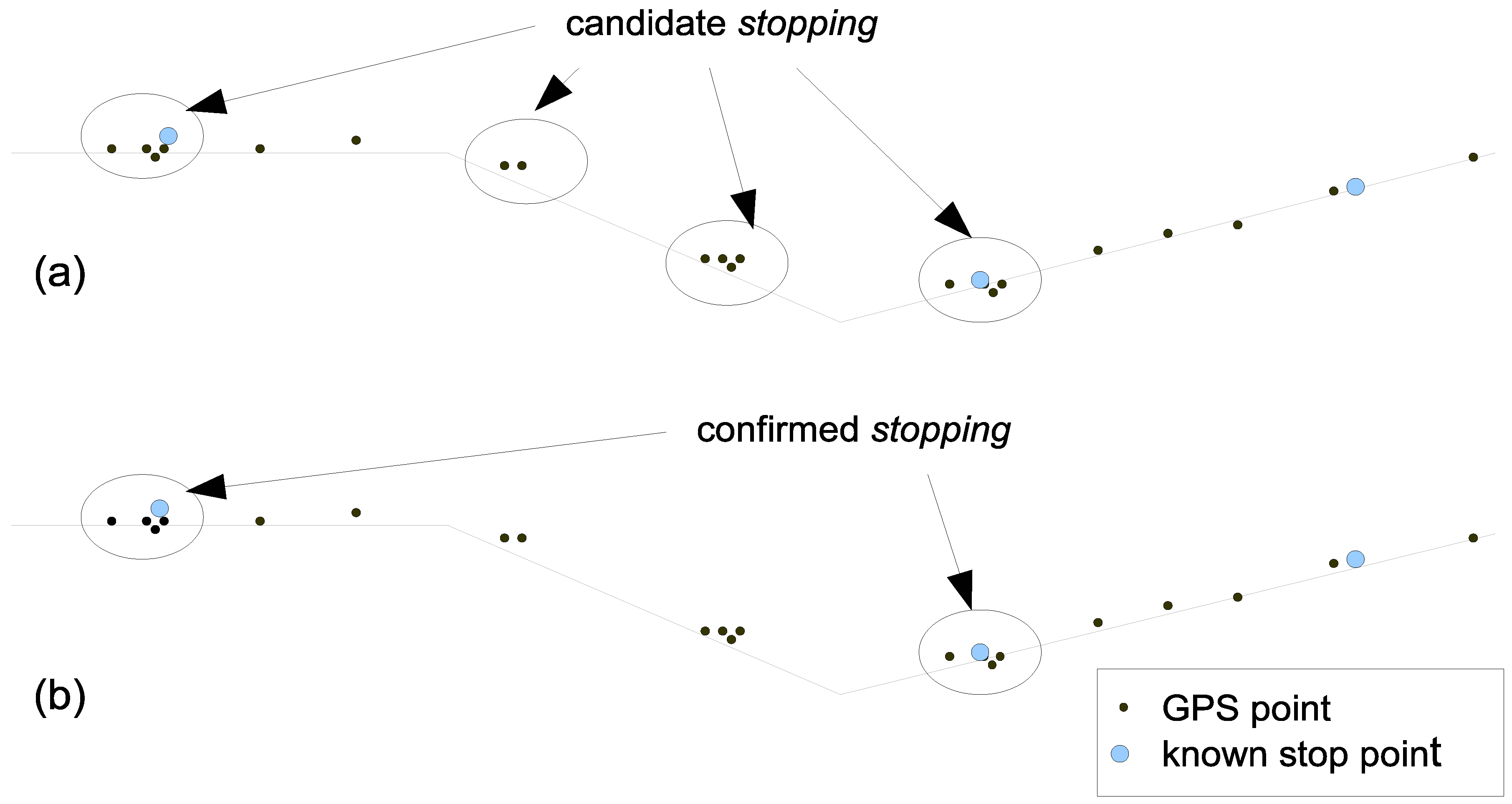
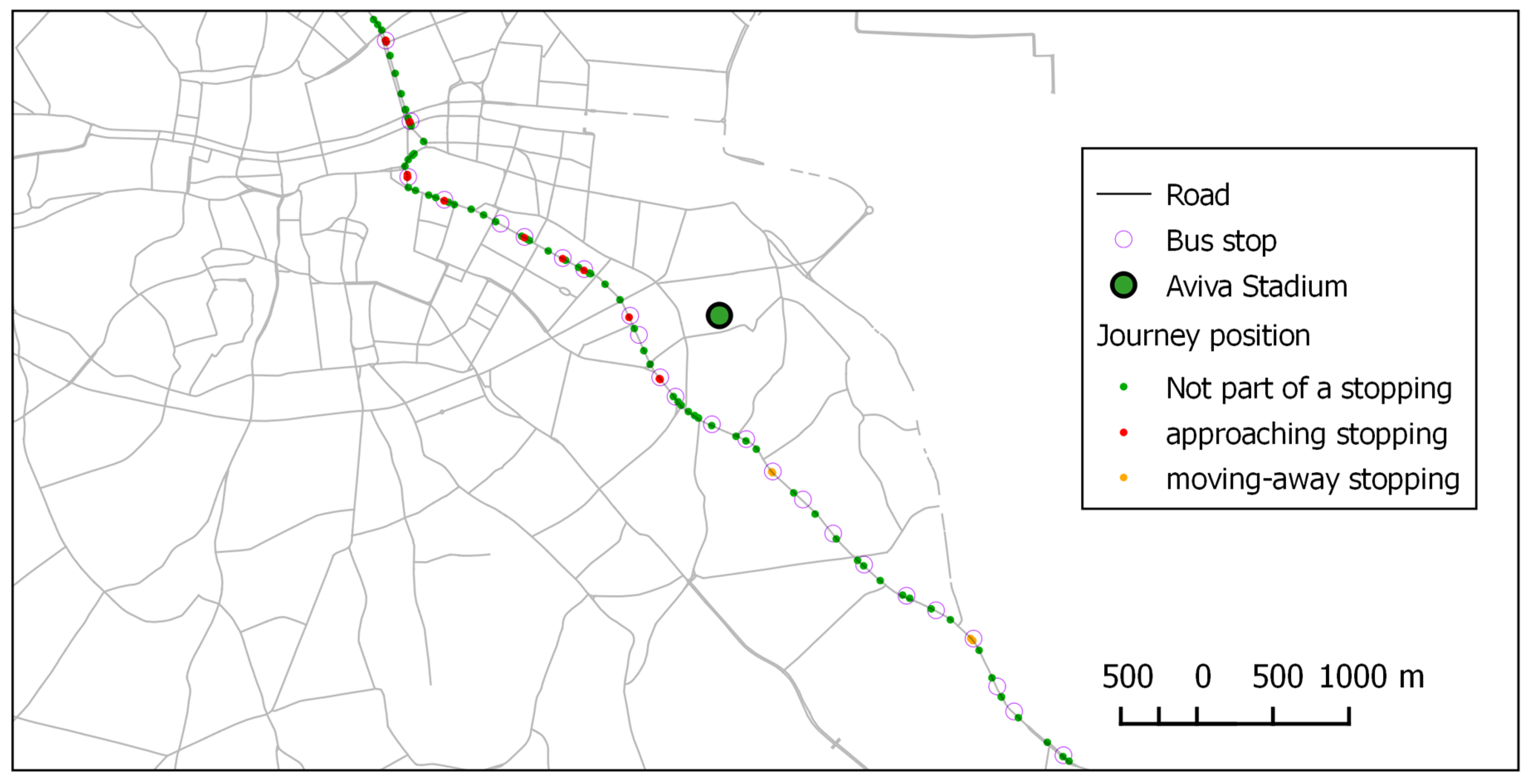
4.2. Extracting Interactions from Mobility Data and the Context of Large-Scale Events in the Aviva Stadium
4.3. Spatio-Temporal Analysis of Interactions for the Context of Large Scale Events on Aviva Stadium
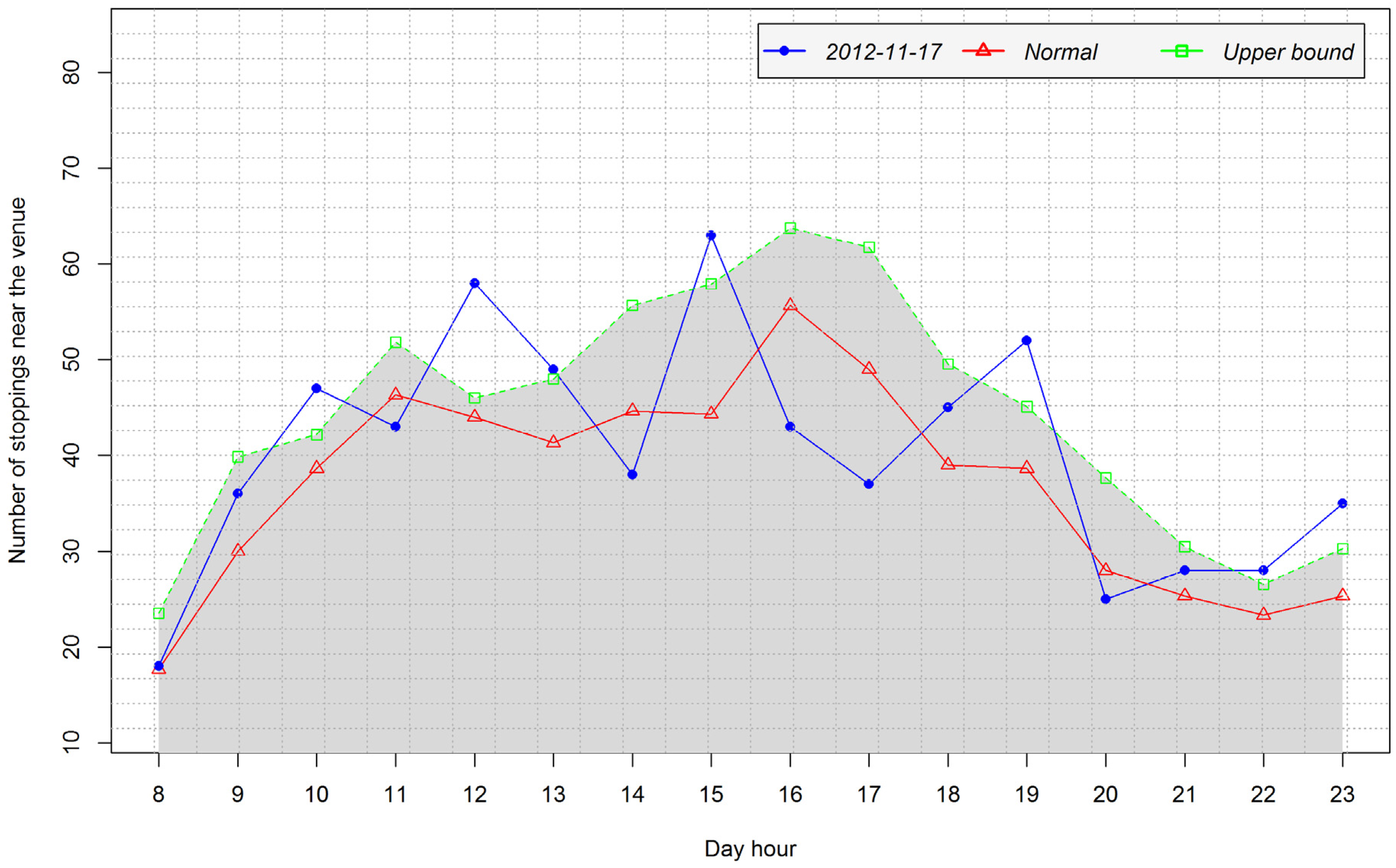
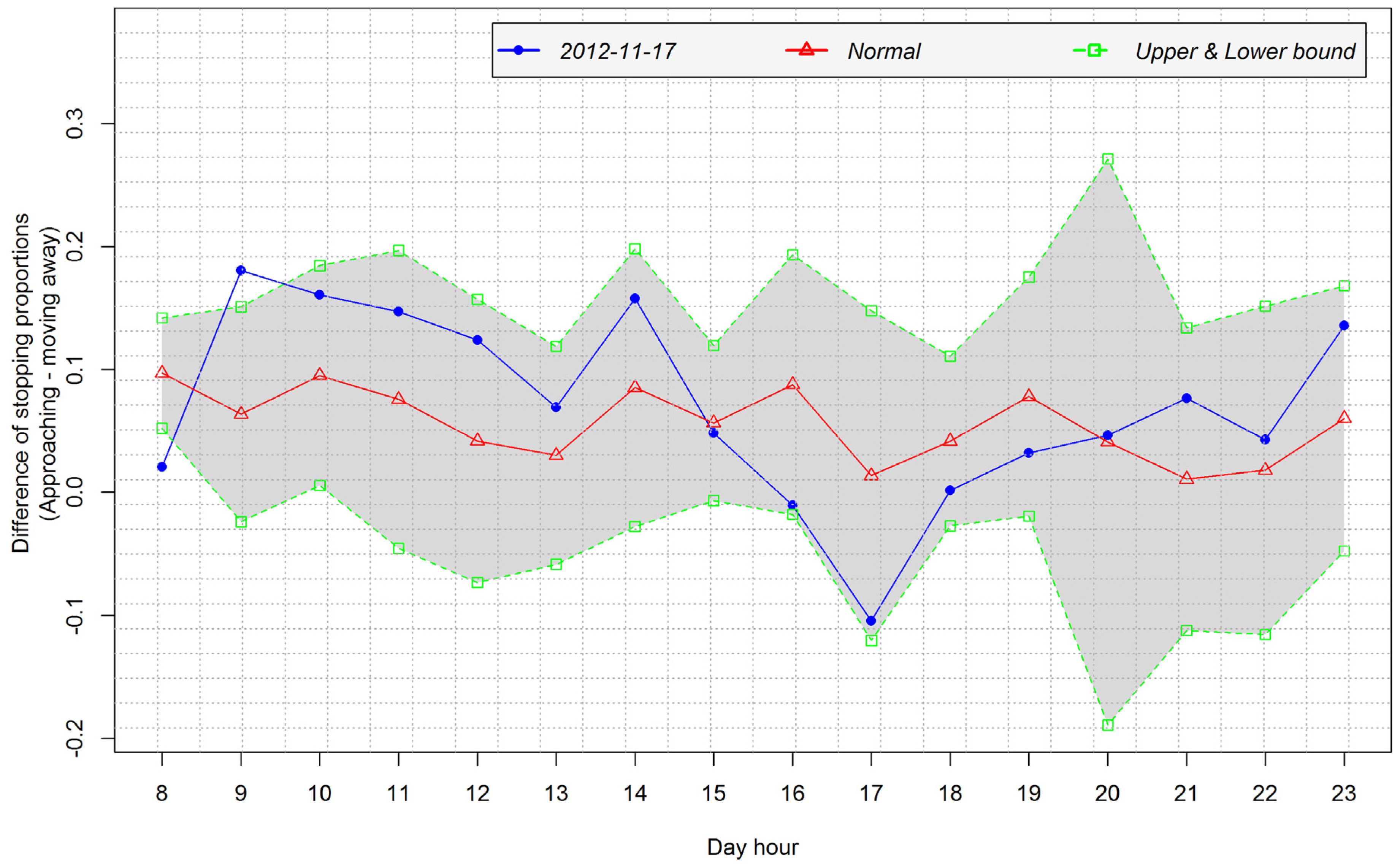
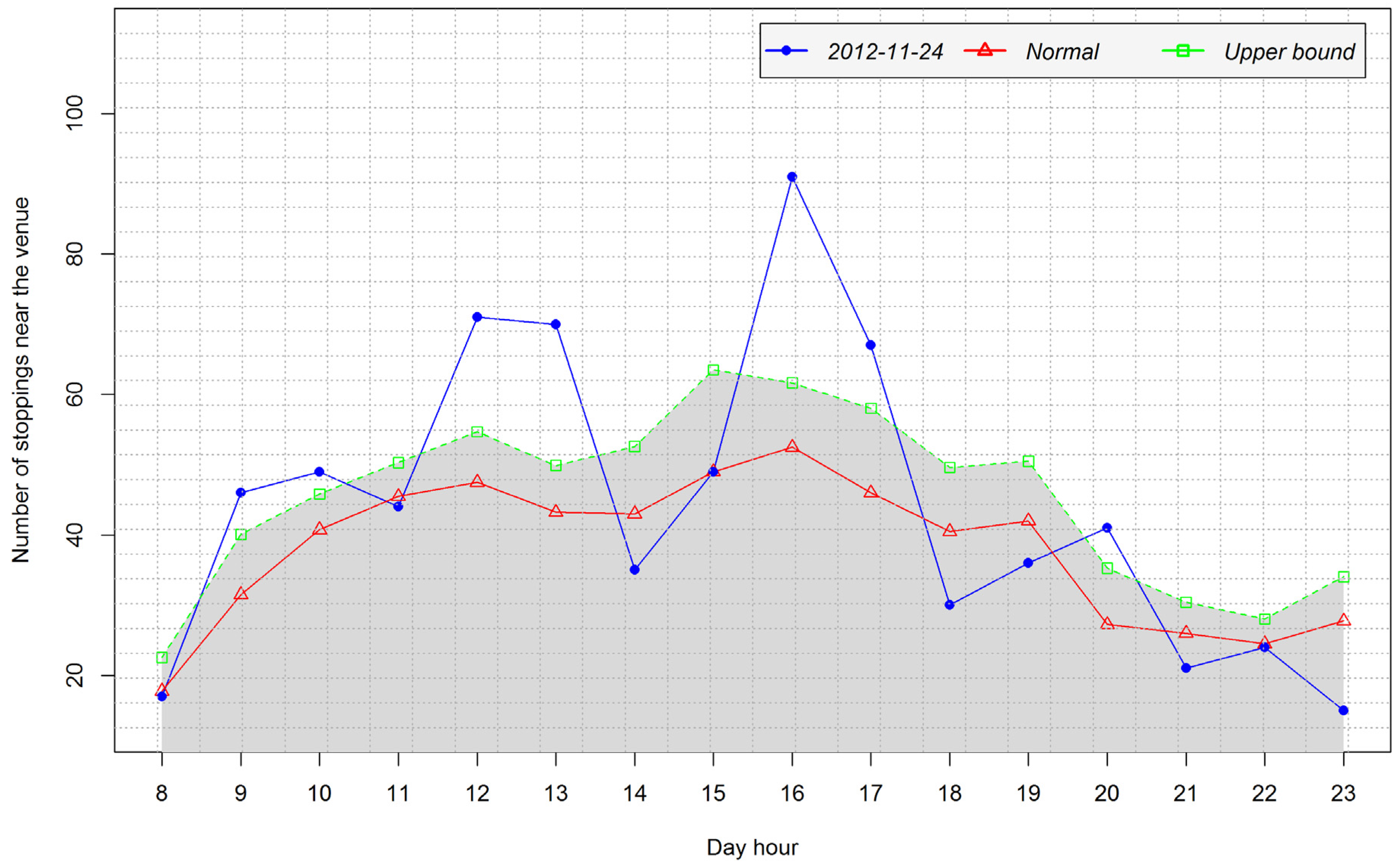
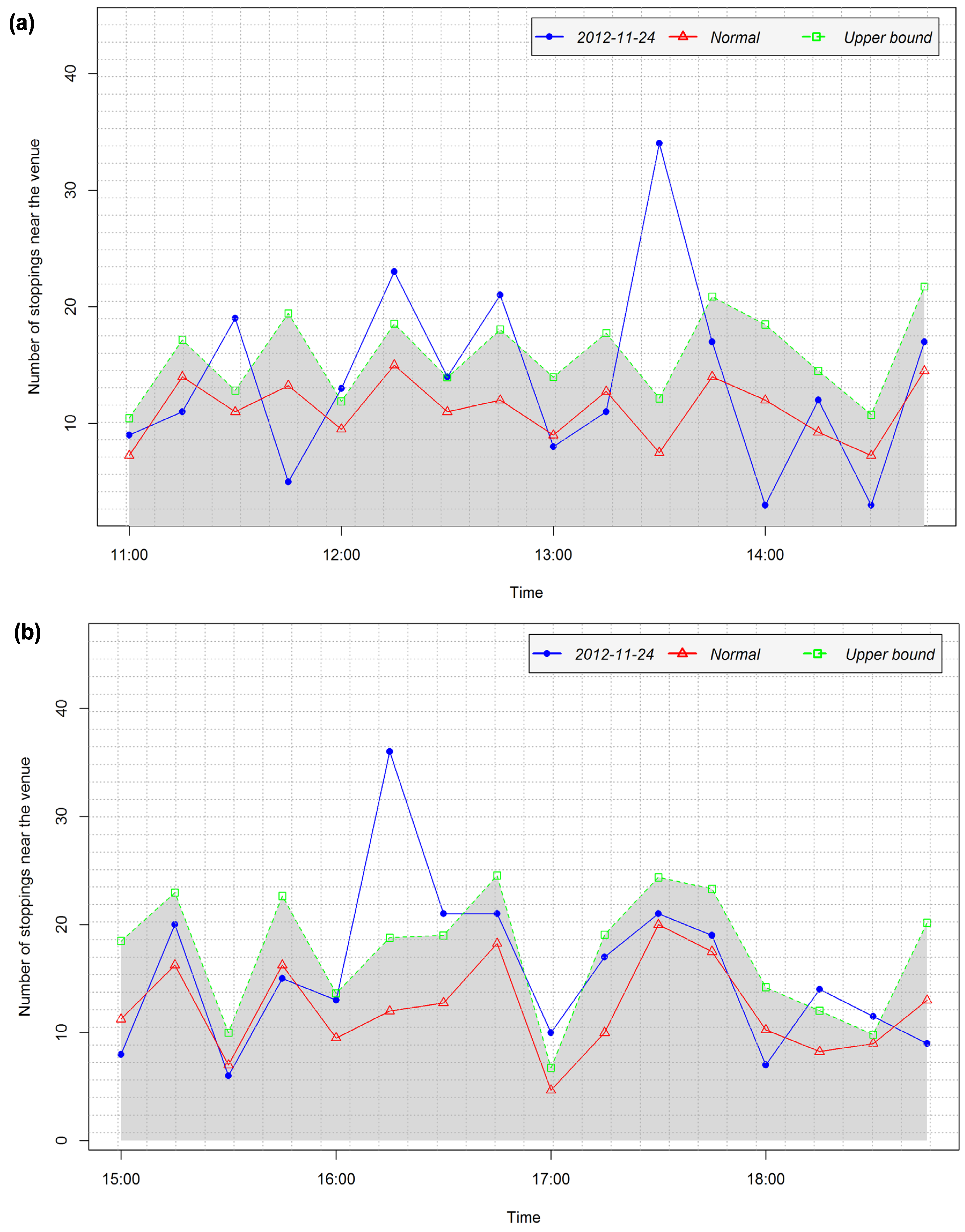
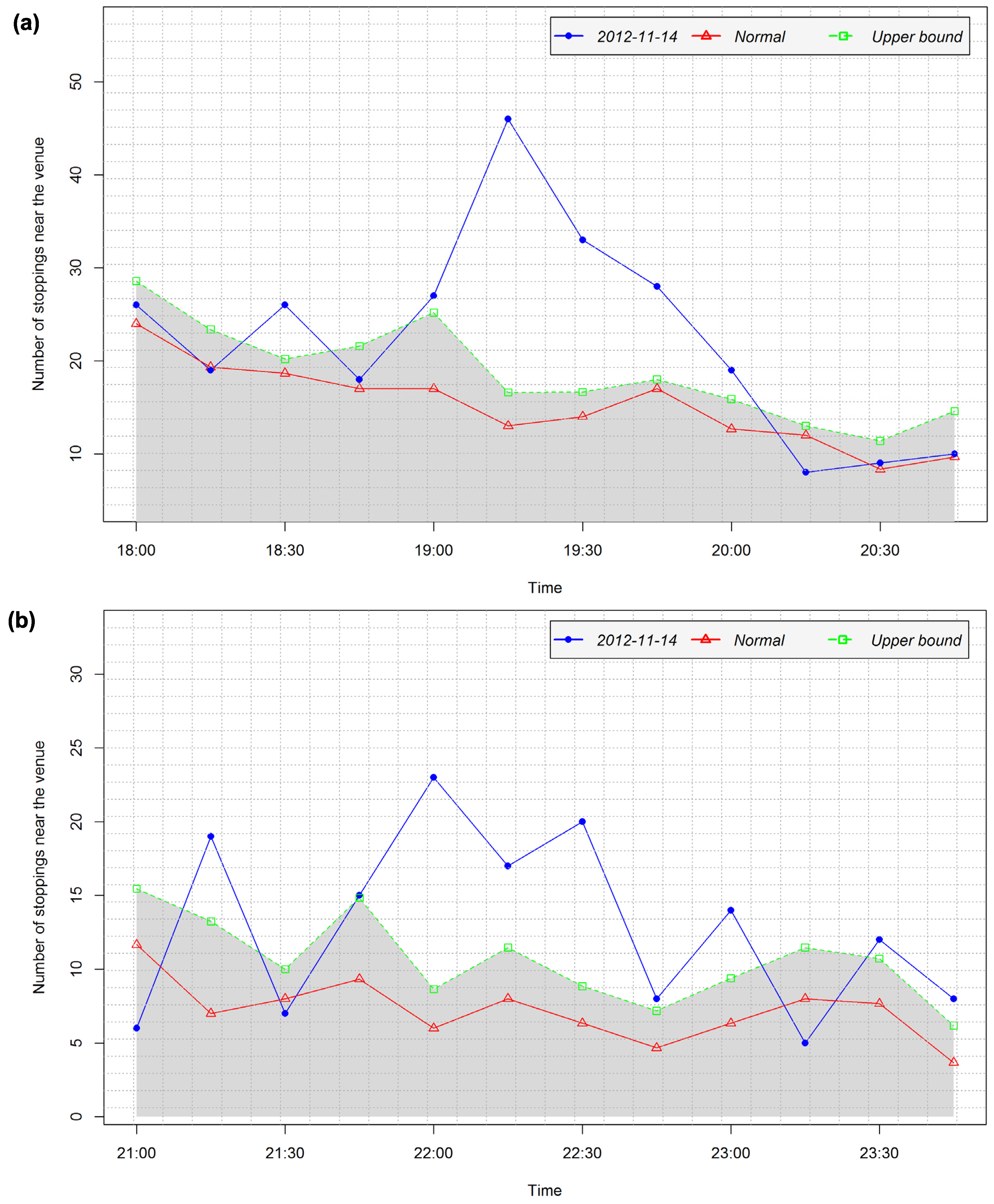
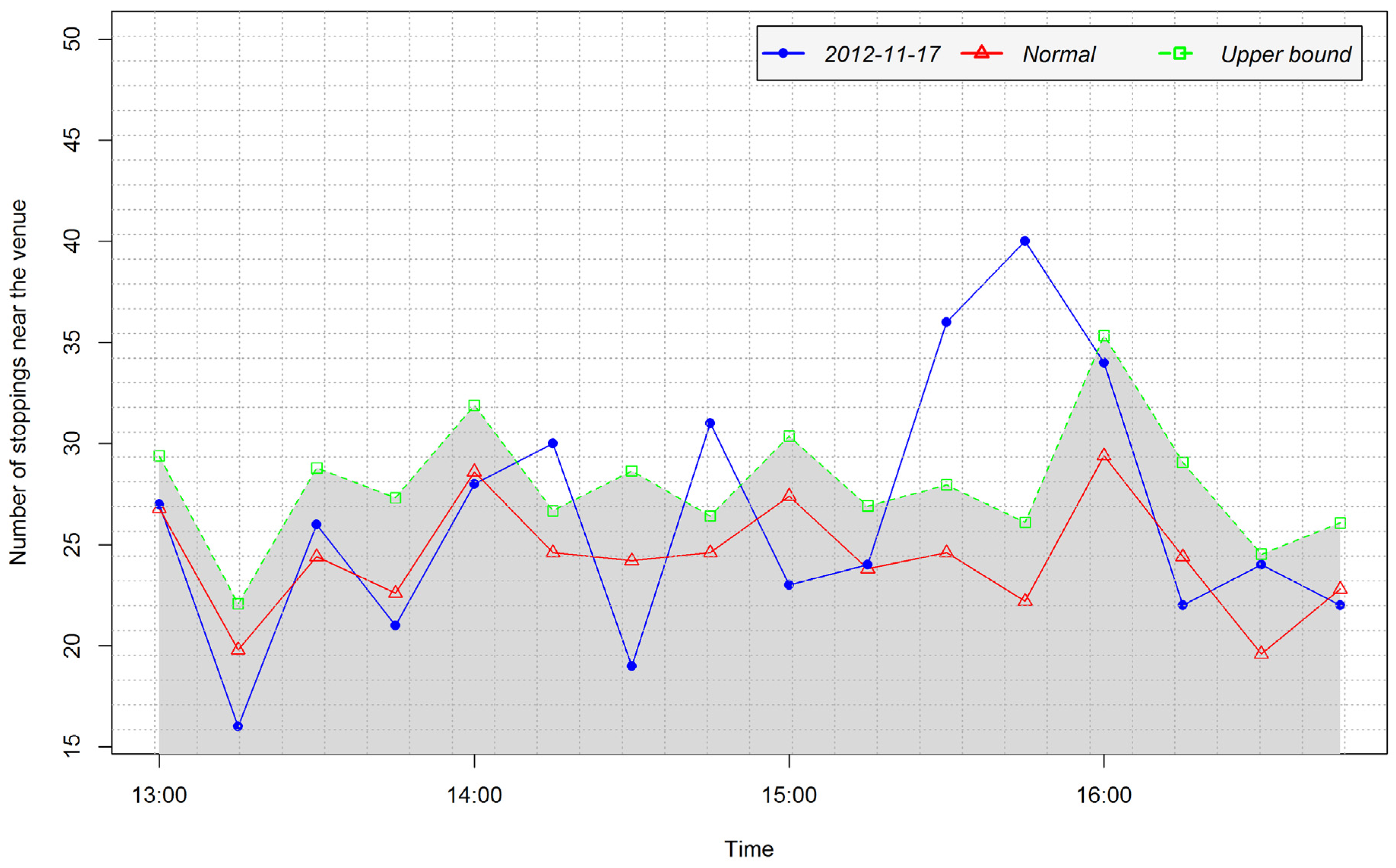
4.3.1. Detection of Arrival and Departure Times
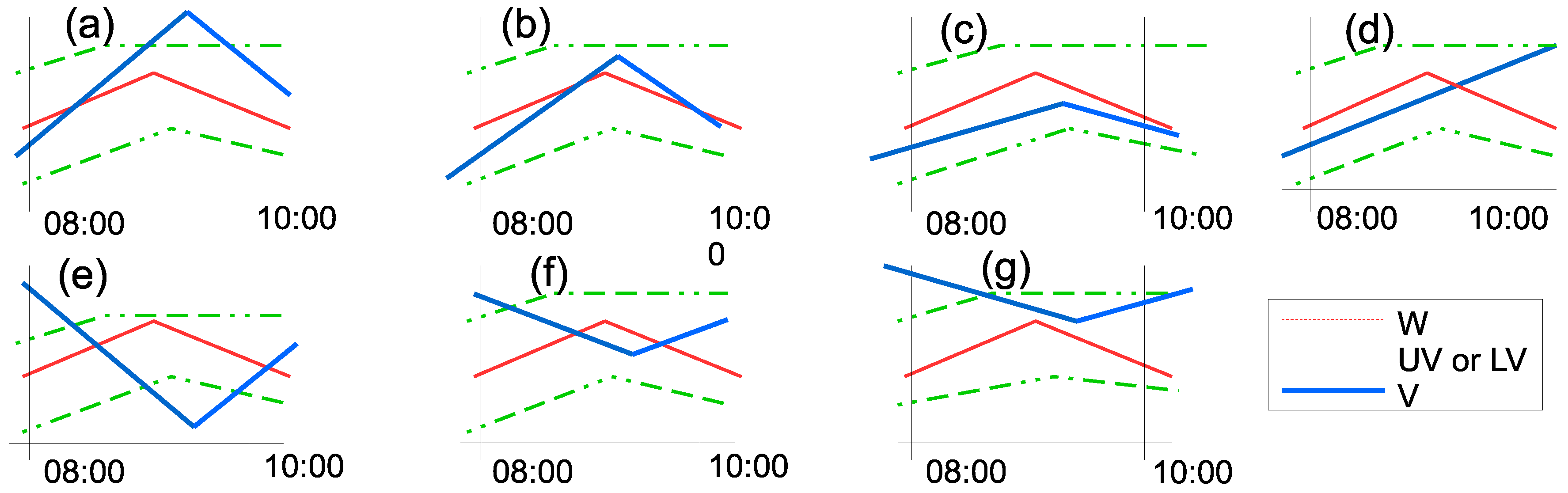
- No peak is found (see Figure 7d). The peak type is set to 0.
- A “positive peak” is found. The peak type is set to 1.
- (a)
- (b)
- The value b at the peak is such that Wi < b ≤ UVi (see Figure 7b). The peak level is proportionally calculated based on the relation between UV and W (see Equation 4).
- (c)
- A “negative peak” is found. The peak type is set to −1.
- (a)
- (b)
- The value b at the peak is such that LVi ≤ b < W (see Figure 7f). The peak level is proportionally calculated based on the relation between LV and W (see Equation (4)).
- (c)
- Peak at 9:00 in the interval 8:00–11:00, peak type: −1, peak level: 0.667
- Peak at 13:00 in the interval 11:00–14:00, peak type: 1, peak level: 1
- Peak at 16:00 in the interval 15:00–18:00, peak type: −1, peak level: 1
- Peak at 20:00 in the interval 19:00–21:00, peak type: 0
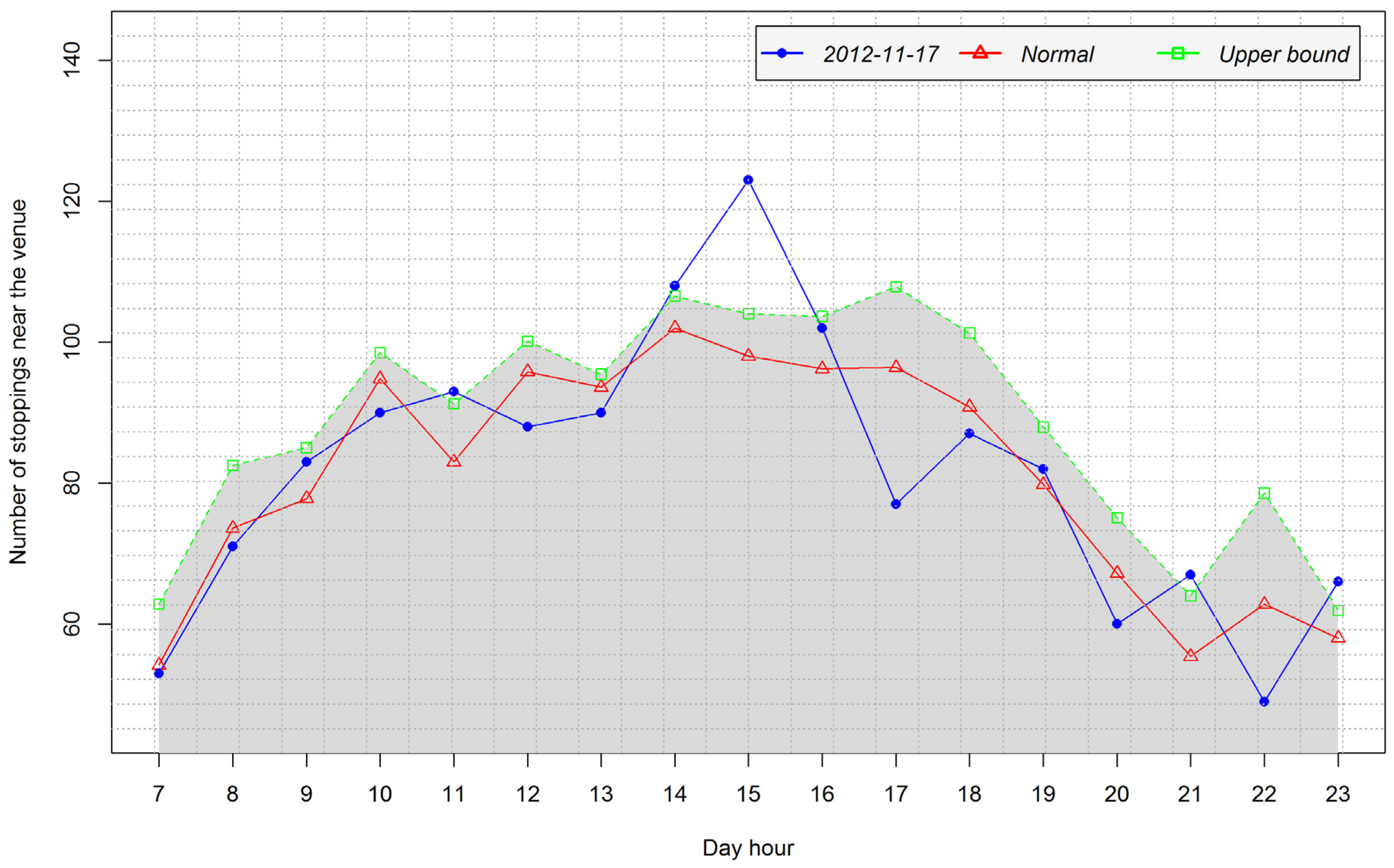
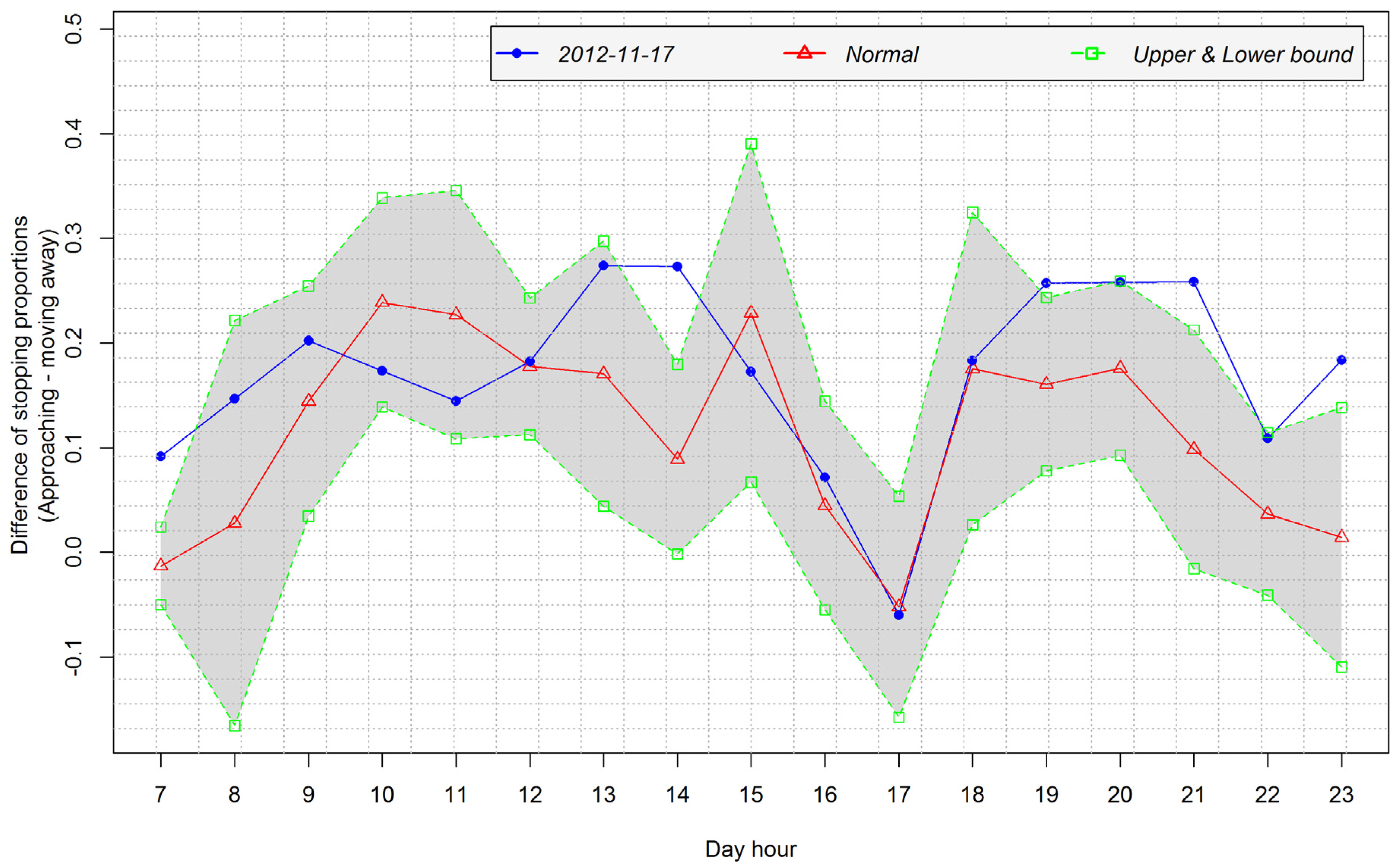
4.3.2. Analysis of Temporal Patterns of Arrival and Departure
4.4. Case Study 2: Human Mobility and the Context of Medium Scale Events at the National Concert Hall
5. Discussion
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Dodge, S.; Weibel, R.; Ahearn, S.C.; Buchin, M.; Miller, J.A. Analysis of movement data. Int. J. Geogr. Inf. Sci. 2016, 30, 825–834. [Google Scholar] [CrossRef]
- Laube, P. Computational Movement Analysis; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Baglioni, M.; Fernandes de Macêdo, J.A.; Renso, C.; Trasarti, R.; Wachowicz, M. Towards Semantic Interpretation of Movement Behavior. In Advances in GIScience; Sester, M., Lars, B., Volker, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 271–288. [Google Scholar]
- Orellana, D.; Wachowicz, M. Exploring patterns of movement suspension in pedestrian mobility. Geogr. Anal. 2011, 43, 241–260. [Google Scholar] [CrossRef] [PubMed]
- Dodge, S.; Bohrer, G.; Bildstein, K.; Davidson, S.C.; Weinzierl, R.; Bechard, M.J.; Barber, D.; Kays, R.; Brandes, D.; Han, J.; et al. Environmental drivers of variability in the movement ecology of turkey vultures (Cathartes aura) in North and South America. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2014. [Google Scholar] [CrossRef] [PubMed]
- Bagrow, J.P.; Wang, D.; Barabási, A.-L. Collective response of human populations to large-scale emergencies. PLoS ONE 2011, 6, e17680. [Google Scholar] [CrossRef] [PubMed]
- Calabrese, F.; Pereira, F.C.; Lorenzo, G.D.; Liu, L.; Ratti, C. The Geography of Taste: Analyzing Cell-Phone Mobility and Social Events. In Pervasive Computing; Floréeni, P., Krüger, A., Spasojevic, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 22–37. [Google Scholar]
- Ying, J.J.; Lee, W.; Tseng, V.S. Mining geographic-temporal-semantic patterns in trajectories for location prediction. ACM Trans. Intell. Syst. Technol. 2013, 5, 1–33. [Google Scholar] [CrossRef]
- Parent, C.; Spaccapietra, S.; Renso, C.; Andrienko, G.; Andrienko, N.; Bogorny, V.; Damiani, M.L.; Gkoulalas-Divanis, A.; Macedo, J.A.; Pelekis, N.; et al. Semantic trajectories modeling and analysis. ACM Comput. Surv. 2013, 45, 42. [Google Scholar] [CrossRef]
- Spaccapietra, S.; Parent, C.; Damiani, M.L.; de Macêdo, J.A.; Porto, F.; Vangenot, C. A conceptual view on trajectories. Data Knowl. Eng. 2008, 65, 126–146. [Google Scholar] [CrossRef] [Green Version]
- Trasarti, R.; Olteanu-Raimond, A.-M.; Nanni, M.; Couronné, T.; Furletti, B.; Smoreda, Z.; Ziemlicki, C. Discovering urban and country dynamics from mobile phone data with spatial correlation patterns. Telecommun. Policy 2015, 39, 347–362. [Google Scholar] [CrossRef]
- Hawelka, B.; Sitko, I.; Beinat, E.; Sobolevsky, S.; Kazakopoulos, P.; Ratti, C. Geo-located Twitter as proxy for global mobility patterns. Cartogr. Geogr. Inf. Sci. 2014, 41, 260–271. [Google Scholar] [CrossRef] [PubMed]
- Pappalardo, L.; Rinzivillo, S.; Qu, Z.; Pedreschi, D.; Giannotti, F. Understanding the patterns of car travel. Eur. Phys. J. Spec. Top. 2013, 215, 61–73. [Google Scholar] [CrossRef]
- Guo, D.; Zhu, X.; Jin, H.; Gao, P.; Andris, C. Discovering Spatial Patterns in Origin-Destination Mobility Data. Trans. GIS 2012, 16, 411–429. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Heurich, M. An event-based conceptual model for context-aware movement analysis. Int. J. Geogr. Inf. Sci. 2011, 25, 1347–1370. [Google Scholar] [CrossRef]
- Buchin, M.; Dodge, S.; Speckmann, B. Similarity of trajectories taking into account geographic context. J. Spat. Inf. Sci. 2014, 9, 101–124. [Google Scholar] [CrossRef]
- Siła-Nowicka, K.; Vandrol, J.; Oshan, T.; Long, J.A.; Demšar, U.; Fotheringham, A.S. Analysis of human mobility patterns from GPS trajectories and contextual information. Int. J. Geogr. Inf. Sci. 2016, 30, 881–906. [Google Scholar] [CrossRef]
- Dodge, S.; Bohrer, G.; Weinzierl, R.; Davidson, S.C.; Kays, R.; Douglas, D.; Cruz, S.; Han, J.; Brandes, D.; Wikelski, M. The environmental-data automated track annotation (Env-DATA) system: Linking animal tracks with environmental data. Mov. Ecol. 2013. [Google Scholar] [CrossRef] [PubMed]
- Janssens, D.; Nanni, M.; Salvatore, R. Car traffic monitoring. In Mobility Data; Renso, C., Spaccapietra, S., Zimanyi, E., Eds.; Cambridge University Press: New York, NY, USA, 2013; pp. 197–220. [Google Scholar]
- Orellana, D.; Wachowicz, M.; Andrienko, N.; Andrienko, G. Uncovering Interaction Patterns in Mobile Outdoor Gaming. In Proceedings of the International Conference on Advanced Geographic Information Systems & Web Services (GEOWS’09), Cancun, Mexico, 1–7 February 2009; IEEE Computer Society: Washington, DC, USA, 2009; pp. 177–182. [Google Scholar]
- Dodge, S.; Weibel, R.; Lautenschütz, A.-K. Towards a taxonomy of movement patterns. Inf. Vis. 2008, 7, 240–252. [Google Scholar] [CrossRef] [Green Version]
- Palma, A.T.; Bogorny, V.; Kuijpers, B.; Alvares, L.O. A clustering-based approach for discovering interesting places in trajectories. In Proceedings of the 2008 ACM Symposium on Applied Computing (SAC ’08), Fortaleza, Ceara, Brazil, 16–20 March 2008; ACM Press: New York, NY, USA, 2008. [Google Scholar]
- Dublinked: Dublin Bus GPS sample data from Dublin City Council (Insight Project). Available online: https://data.dublinked.ie/dataset/dublin-bus-gps-sample-data-from-dublin-city-council-insight-project (accessed on 11 April 2016).
- An Garda Síochána, Ireland’s National Police Service. Available online: http://www.garda.ie/News/default.aspx (accessed on 15 March 2016).
- ISSUU. The National Concert Hall Sept-Nov 2012 Calendar of Events. Available online: https://issuu.com/nationalconcerthall/docs/sept-nov2012calendar (accessed on 20 November 2016).
- Laube, P.; Purves, R.S. How fast is a cow? Cross-Scale Analysis of Movement Data. Trans. GIS 2011, 15, 401–418. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Event | Planned Stiles Opening Time | Planned Start Time | Planned End Time | Actual End Time | Number of Attendees |
|---|---|---|---|---|---|---|
| 10 November 2012 | Rugby match (Ireland vs. South Africa) | 16:00 | 17:30 | 19:00 | 19:20 | 49,781 |
| 14 November 2012 | Football match (Ireland vs. Greece) | 18:15 | 19:45 | 21:45 | 21:42 | 16,256 |
| 24 November 2012 | Rugby match (Ireland vs. Argentina) | 12:30 | 14:00 | 15:40 | 15:49 | 43,406 |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazimpaka, J.D.; Timpf, S. How They Move Reveals What Is Happening: Understanding the Dynamics of Big Events from Human Mobility Pattern. ISPRS Int. J. Geo-Inf. 2017, 6, 15. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6010015
Mazimpaka JD, Timpf S. How They Move Reveals What Is Happening: Understanding the Dynamics of Big Events from Human Mobility Pattern. ISPRS International Journal of Geo-Information. 2017; 6(1):15. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6010015
Chicago/Turabian StyleMazimpaka, Jean Damascène, and Sabine Timpf. 2017. "How They Move Reveals What Is Happening: Understanding the Dynamics of Big Events from Human Mobility Pattern" ISPRS International Journal of Geo-Information 6, no. 1: 15. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6010015