1. Introduction
Airborne Light Detection and Ranging (LiDAR) is an active sensor technology that has recently gained attention in forestry as a predictor variable for commonly quantified forest characteristics. Because airborne LiDAR is an effective tool for measuring heights, some have investigated the relationships between those heights and common forest metrics used to inform land management and planning activities [
1,
2]. While studies have shown promise in relating LiDAR obtained heights to metrics such as basal area weighted diameter (BAWD), quadratic mean diameter (QMD), basal area per ha (BAH), and trees per ha (TPH) [
3,
4], it is important to recognize that the precision and accuracy of those estimates are only based on the strength of the relationship between remotely sensed and plot data, and not the technology itself.
Similarly, fine resolution passive airborne imagery produced by organizations such as the National Agricultural Imagery Program (NAIP) [
5] have also been used to estimate forest metrics [
6,
7,
8,
9]. In particular, strong relationships have been developed between BAWD, QMD, BAH, and TPH using spectral values, measures of image texture [
10], and topographic variables derived from imagery such as the National Elevation Dataset (NED) [
11]. Despite these similarities, few direct comparisons have been made between the quality and costs of forest metric estimates produced from LiDAR datasets and those derived from high resolution imagery and topographic data such as NAIP and NED.
In isolation, the quality and cost of using various remotely sensed sources of data as model predictor variables for forest characteristics is fairly straight forward to calculate and compare. Metrics such as root mean squared error (RMSE) and dollars per hectare can be calculated, attributed to each of the different remotely sensed data sources, and evaluated to determine which source of data produces the least error and cost the least to acquire. However, when both quality and cost are simultaneously assessed within the context of informing forest management, tradeoffs in model precision and data acquisition costs can be made to justify the use of a given dataset. This assumes there is a difference between quality (model error) and cost (currency per hectare) in using different remotely sensed data.
Assuming that costs associated with collecting field data used to train predictive models of forest characteristics are the same and that data processing costs are similar for the different sources of remotely sensed data, the vast majority of cost difference among different remotely sensed data can be attributed to data acquisition. Aerial imagery such as NAIP are acquired across the continental USA every two years, and are readily available, free of charge, to the public through United States Department of Agriculture Aerial Photography Field Office [
12]. Similarly, seamless 10 m elevation data for the continental USA have been collected by USGS and is readily available, free of charge to the public [
13]. Airborne LiDAR on the other hand can have variable cost per unit area to acquire and is typically contracted on a project basis, costing both time and money for data acquisition and contract management across a relatively limited spatial extent.
Given that NAIP and NED products are readily available across broad spatial extents and free to the public, these data represent low cost potential predictor variables for modeling forest characteristics within the continental USA. Adding additional remotely sensed data, especially at an increased cost, is really only justifiable from a practical standpoint when the quality (less error) of models are substantially improved. It follows then that acquiring airborne LiDAR for the sole purpose of estimating forest characteristics within the continental USA is really only justifiable when the quality of model predictions substantially improve, and that the added expense of acquisition is less than the gains associated with improved model prediction. Similarly, in the event that this situation is reversed (airborne LiDAR data freely available and there is an additional cost to acquire imagery) the same line of reasoning would apply. However, the improvement in predictive model quality of forest characteristics such as BAWD, QMD, BAH, and TPH given different sources of remotely sensed data is seldom tested. While these different sources of data have been successfully related to forest metrics and measure different aspects of the forest (spectral, elevation, and height) it is important to recognize they are only correlated with BAWD, QMD, BAH, and TPH, and are more than likely highly correlated with one another for a given geographic area. Moreover, given the similarity in reported model errors in studies that solely use imagery [
6,
7,
8,
9] or LiDAR [
3,
4] based predictor variables to estimate forest characteristics, it may be that both sources of data provide similar predictive capability.
This has lead us to hypothesize that there is little difference between modeled estimates of BAWD, QMD, BAH, and TPH derived from NAIP, NAIP assisted NED, and LiDAR based remotely sensed data. To test this hypothesis we compare BAWD, QMD, BAH, and TPH estimates from Random Forest regression models that relate plot measurements to LiDAR, NAIP, and NED derivatives in the Bitterroot National Forest, Montana, USA. Our comparisons evaluate model fit and complexity using RMSE and Akaike’s information criterion (AIC) [
14,
15] at the spatial resolution of the plot and the forest stand.
3. Results
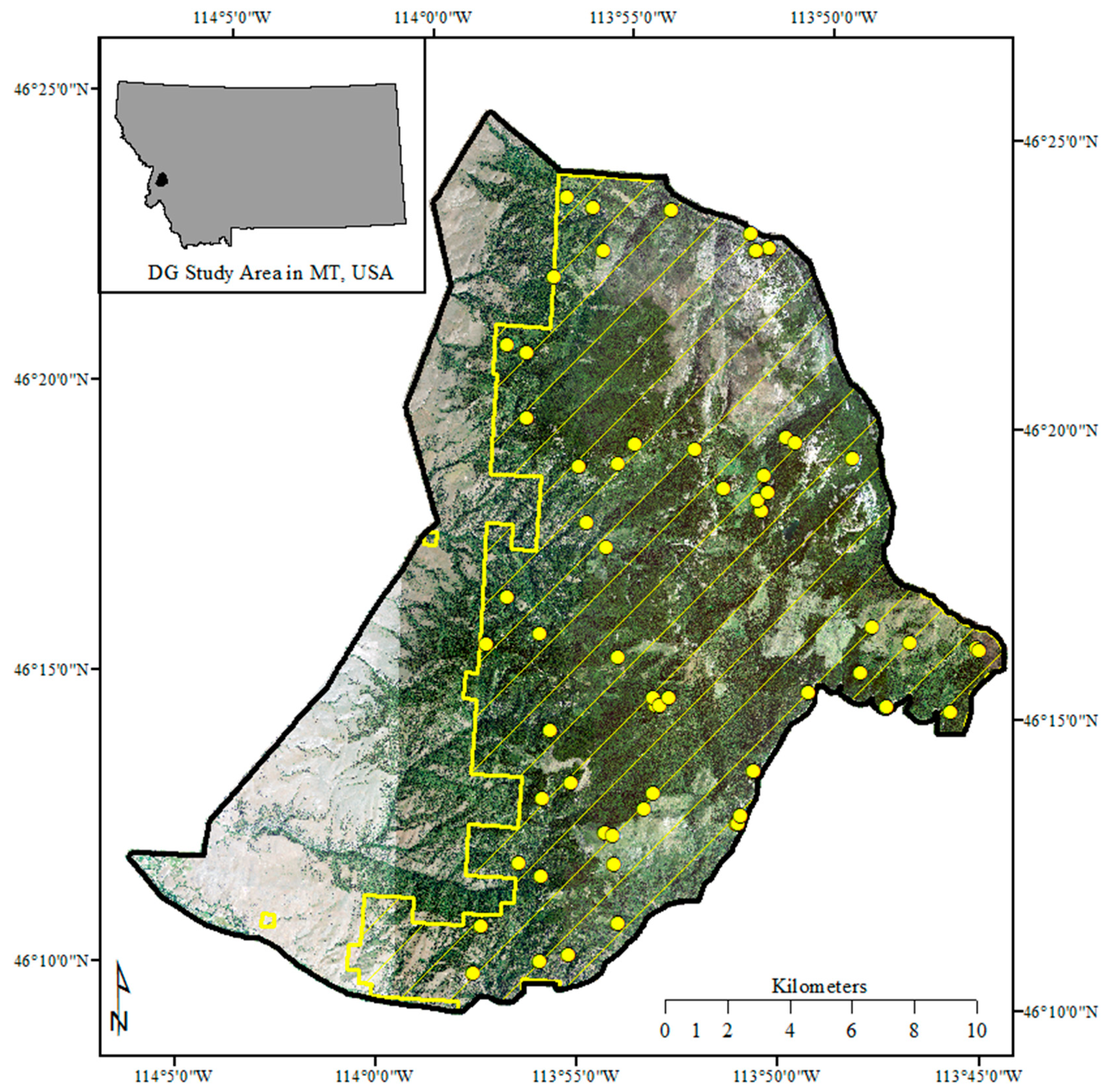
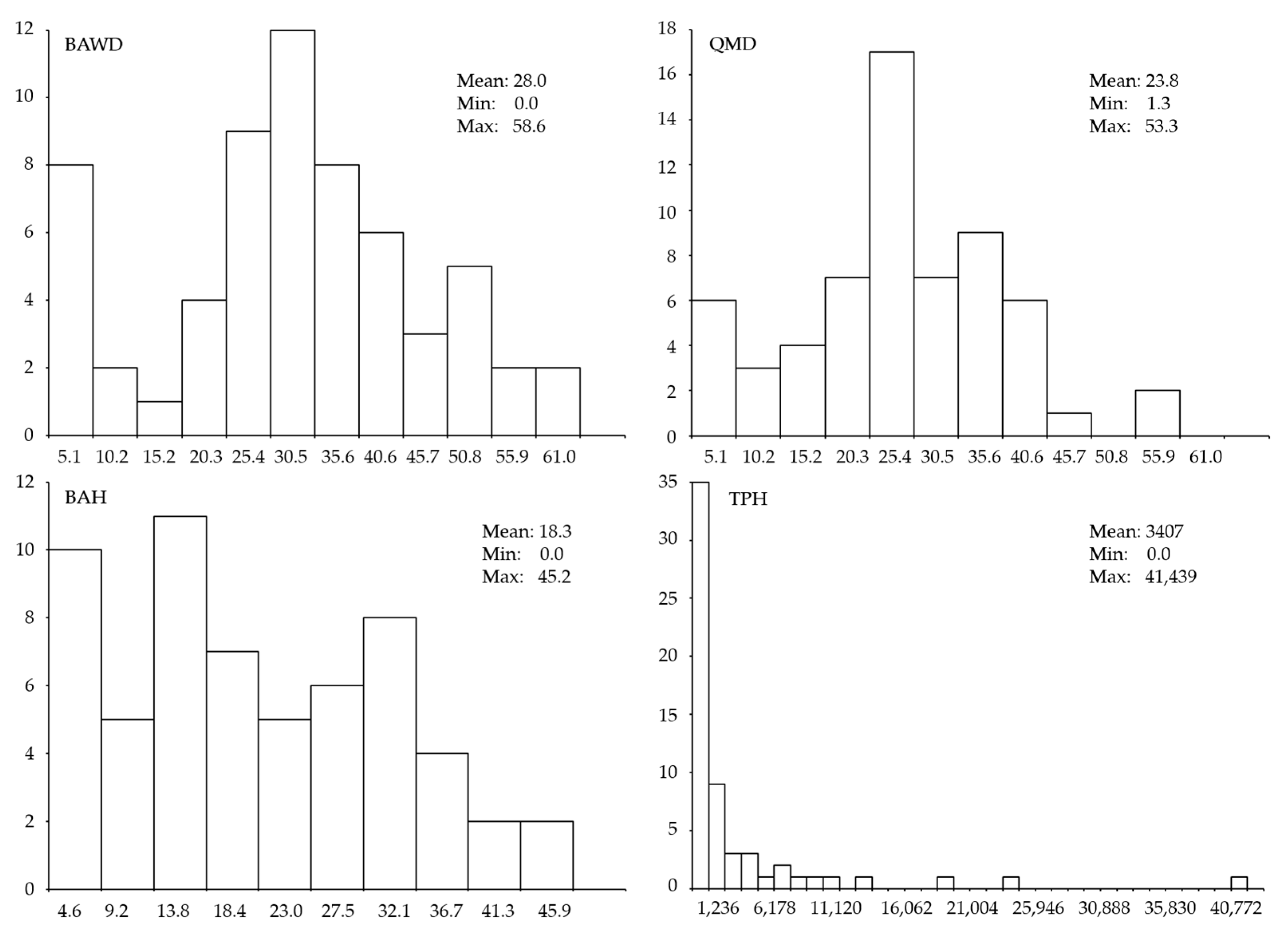
Tree data were collected on 60 plots across the study area, and tabulated to produce plot values for BAWD, QMD, BAH, and TPH. The distribution of BAWD, QMD and BAH plot values was generally considered normal while TPH values were strongly right skewed (
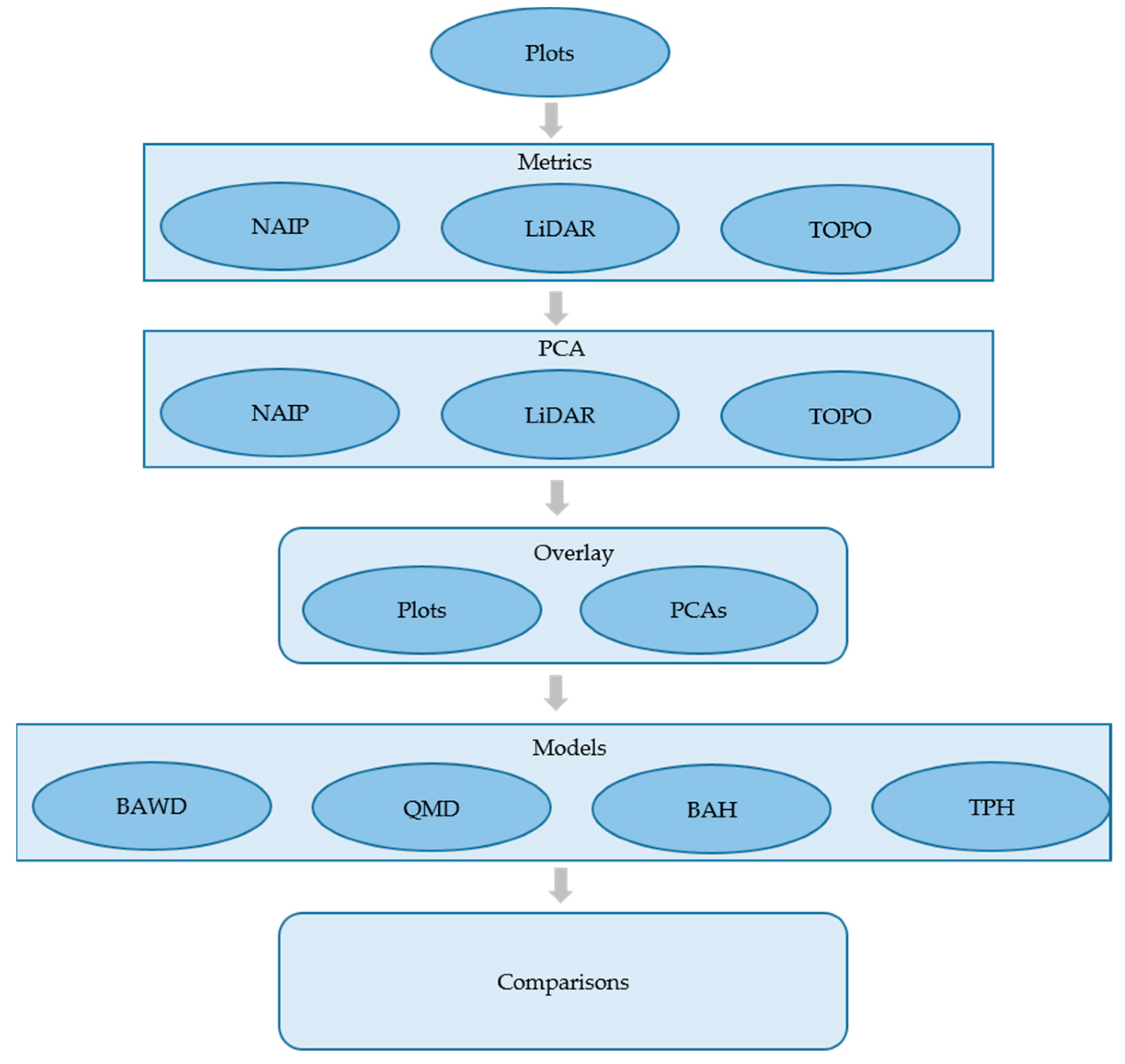
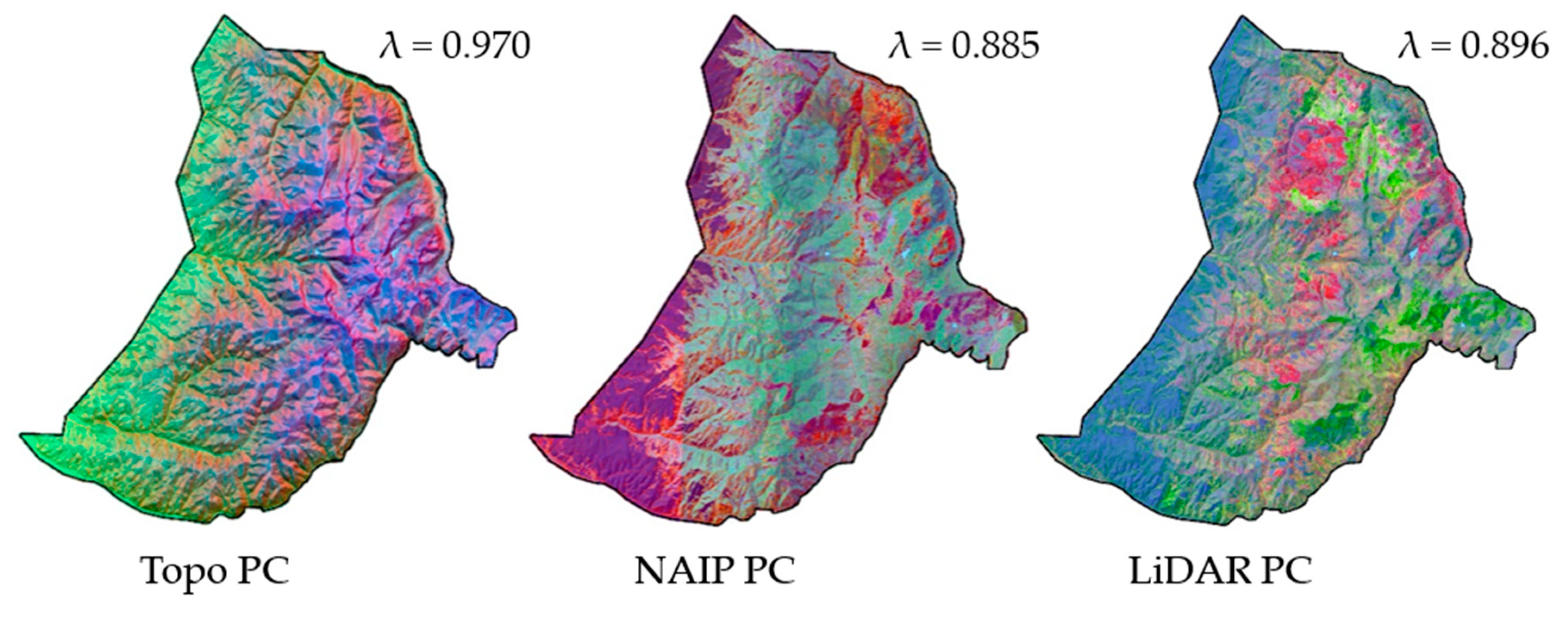
Figure 5). Principle components used as predictor variables accounting for 96%, 97%, and 96% of the information within NAIP (5 components), TOPO (3 components) and LiDAR (5 components) data sources, respectively (
Figure 6). Often Eigen vectors of a PCA are interpreted with respect to original values of the data. In this case we simply wanted to remove the correlation among each source of remotely sensed data and use the orthogonal scores of the components as predictor variables in subsequent analysis. Our PCAs effectively performed this objective. Scores calculated from the Eigen vectors of the corresponding principal components were used with plot summaries of BAWD, QMD, BAH, and TPH to build a suite of models describing the relationship between field and remotely sensed data sources.
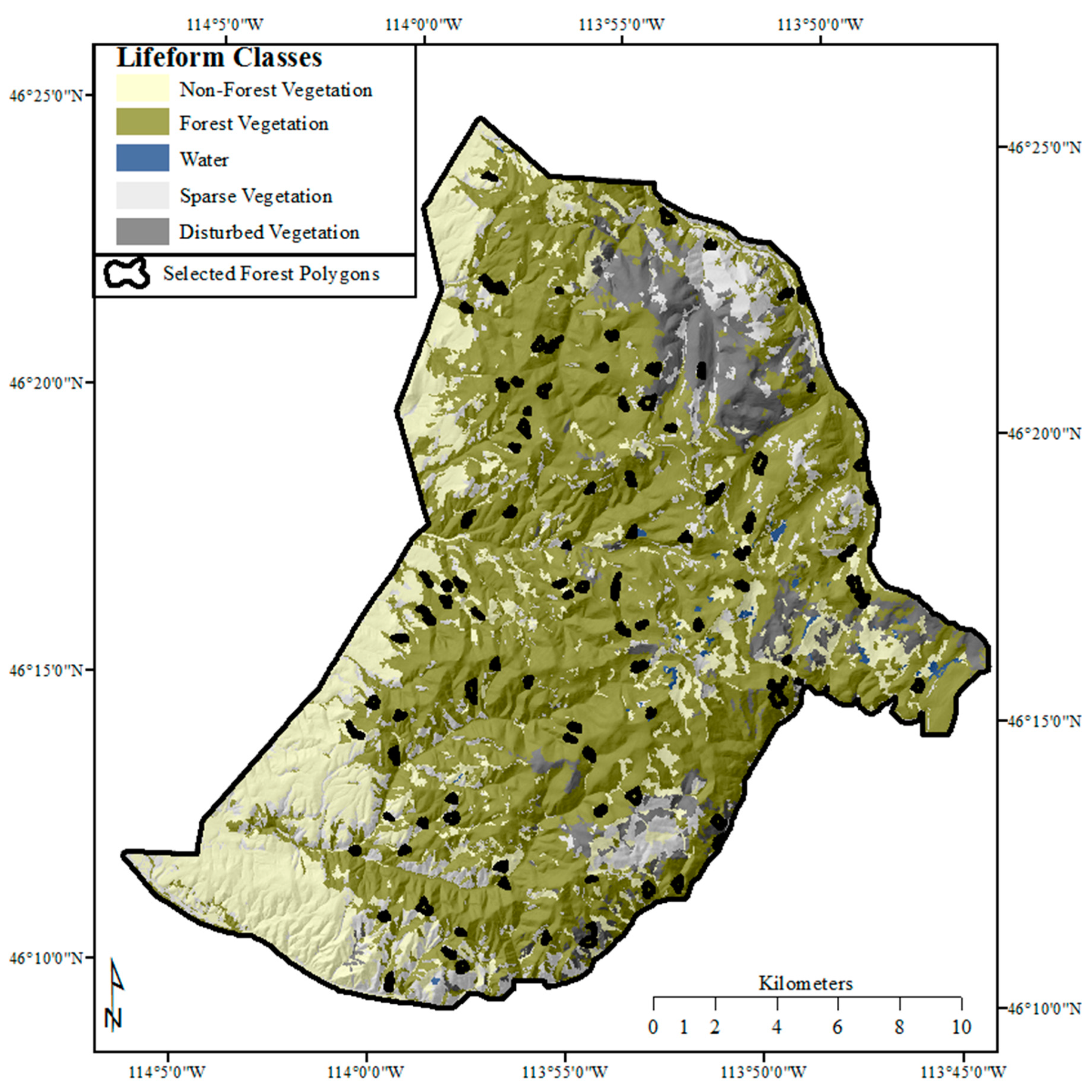
Figure 7 illustrates the spatial distribution of the multiband raster datasets generated from the principal component scores and used to produce the spatial predictions of the response variables.
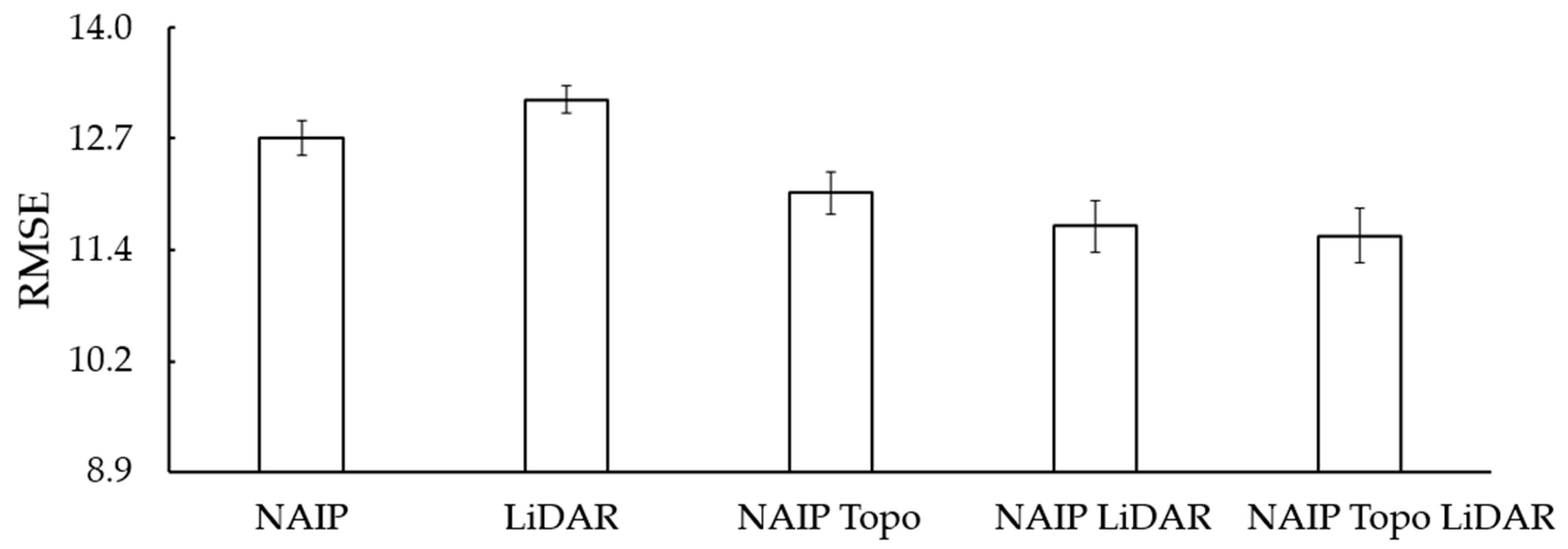
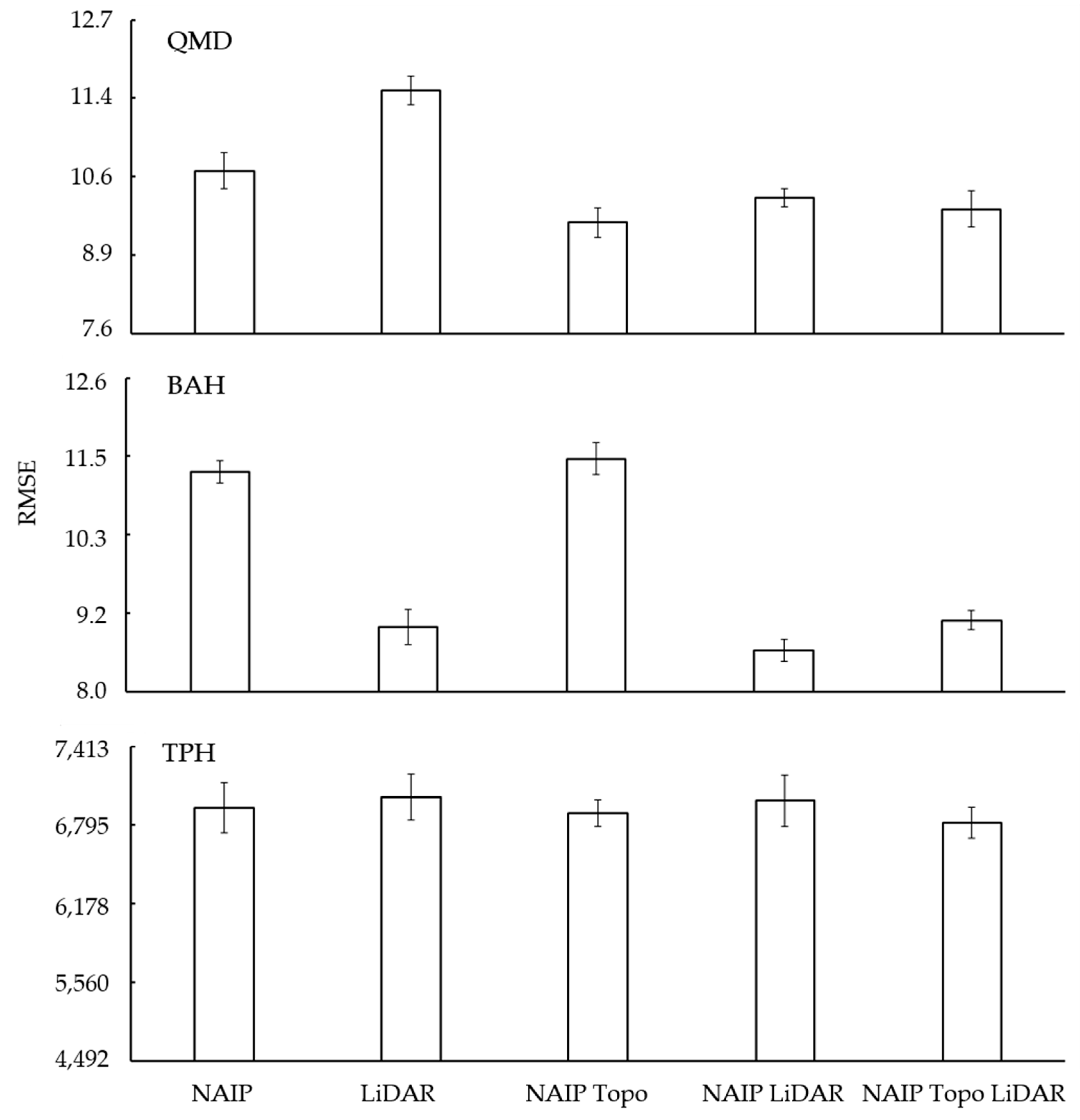
Model fit and complexity were evaluated using RMSE and AIC (
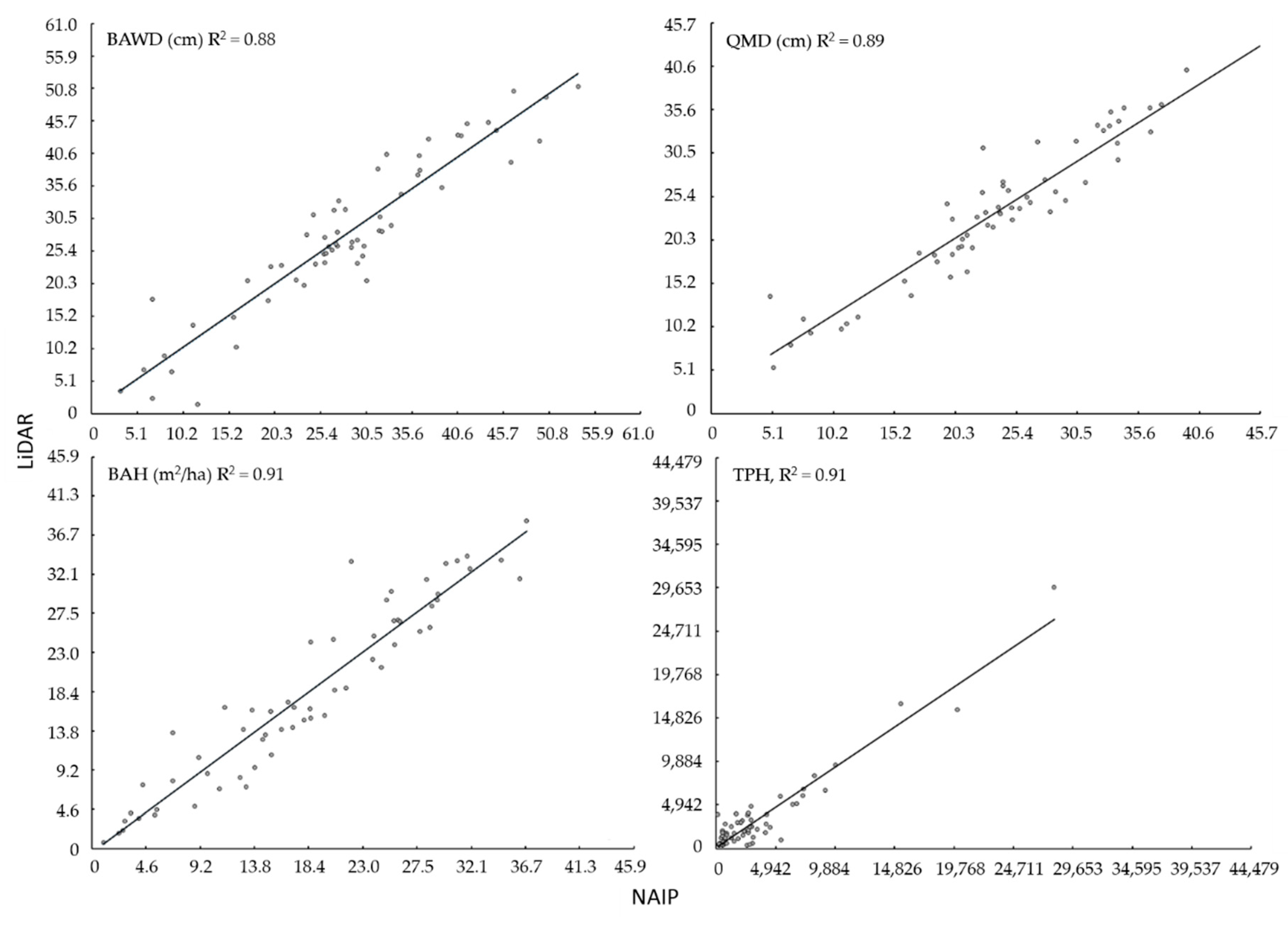
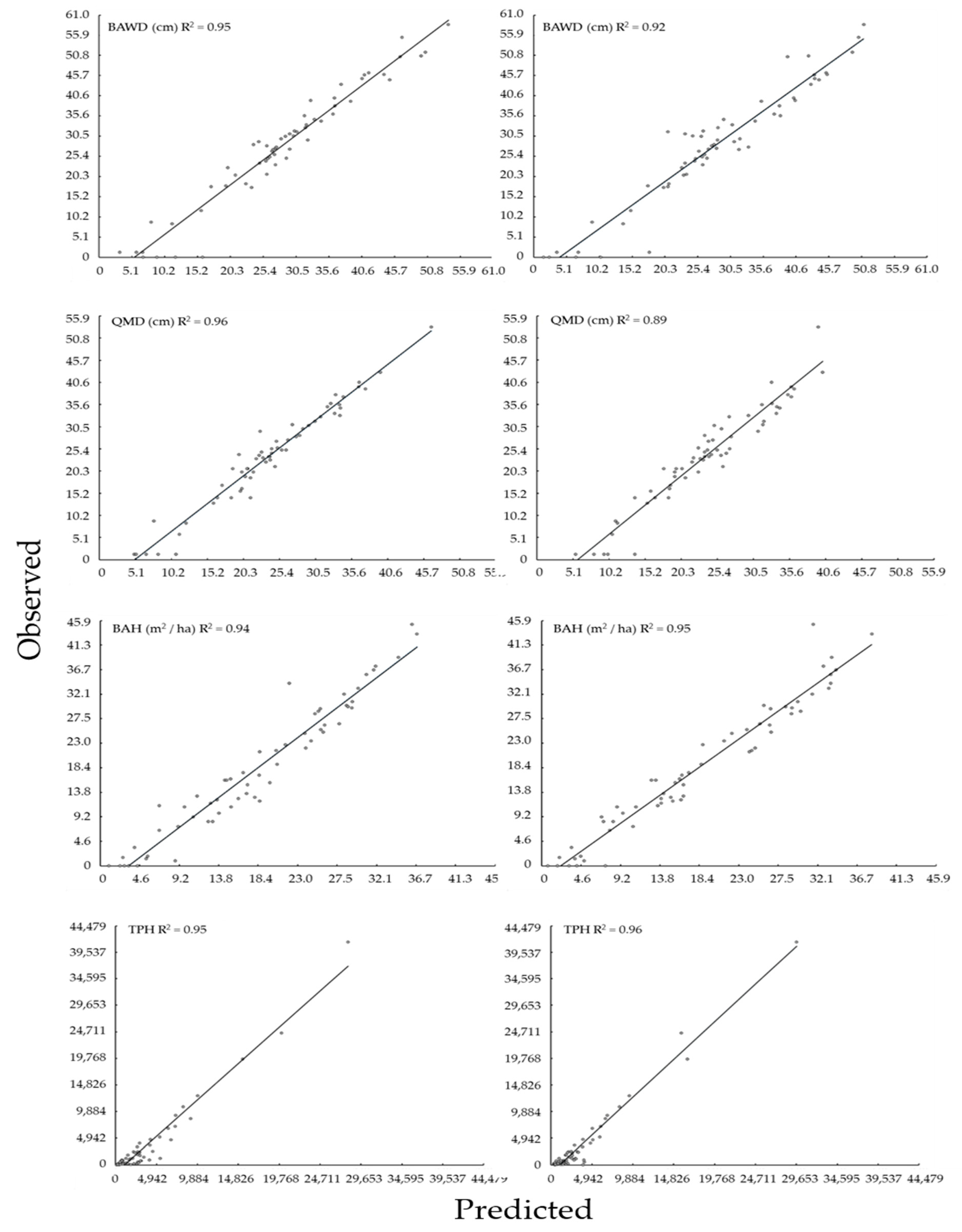
Table 2). Generally, models derived from NAIP and LiDAR predictor variables alone performed as well as more complex models. The best fitting, most parsimonious models for BAWD, QMD, and TPH contained NAIP principal component scores. The best fitting, most parsimonious model for BAH contained LiDAR principal component scores. When estimates of BAWD, QMD, BAH, and TPH derived from NAIP and LiDAR based models were regressed against one another, they followed a positive one to one relationship explaining approximately 90% of the variation between predicted estimates (
Figure 8). When paired with NAIP or LiDAR variables, TOPO variables provided little additional information.
Random Forest regression model iterations yielded similar trends as shown in
Table 2 but illustrate the variability of using the Random Forest ensemble modeling techniques (
Figure 9). While improvements in predictive capability (smaller RMSE) can be achieved by using more complex models (
Table 2 and
Figure 9), those improvements are relatively minor with regard to the additional complexity (AIC scores in
Table 2,
Figure A1). Moreover, given the stochastic nature of ensemble modeling (
Figure 9), some perceived differences in model results may be due to chance alone and was in large part the rationale for using AIC to identify the top fitting models for each characteristic.
At the stand level, differences between summarized estimates of models derived from NAIP and LiDAR are generally indistinguishable. In all comparisons except BAH, paired differences between NAIP and LiDAR derived models were statistically insignificant (
Table 3). For BAH, the average paired difference was less than 2.2 m
2 ha
−1 which in many surveys is roughly equivalent to one tree. Combined, these comparisons suggest that models based on NAIP and LiDAR have very similar predictive capability, error structure, and spatial distribution. This is particularly evident at the spatial scale associated with forest stands where individual pixel predictions are aggregated to produce a mean value for each stand.
4. Discussion
Forest resource managers need timely and accurate information about the size and density of trees to make decisions about what, where, and how to apply treatments across landscapes. Metrics like BAWD, QMD, BAH, and TPH are commonly used to describe structural elements of the forest. LiDAR is a relatively new technology that is capable of providing highly precise measurements of height, and has been shown as an effective tool for making spatial predictions of forest metrics by relating observed heights to ground-based plot measurements of trees [
3,
4].
While LiDAR data can be useful, it is not available in all locations and must generally be acquired for specific project areas [
37]. Many other digital spatial datasets like topography and high resolution imagery are available as continuous data across the continental United States, and can be obtained free of charge. Like LiDAR data, recent research has also shown that fine resolution imagery such as NAIP can be used to effectively predict forest metrics with relationships based on field data.
Alone, neither NAIP nor LiDAR data can model environmental phenomenon without high quality, reliable reference information. In this study, 60 field plots following the CSE protocol were used to describe a range of forest conditions. While this field protocol is commonly used for forest inventories, it may not be optimal for relating ground measurements to fine resolution spatial data such as NAIP imagery or LiDAR [
38].
Without adequate ground representation of the characteristics to be estimated, good model fit cannot be achieved. This was evident in the relatively large RMSE between measured and estimated TPH in our study. To enhance our ability to estimate and map forest characteristics, a sufficient number of plots should be collected to cover the range of conditions across the study area. Those plots should also be designed to fully describe the entire area of the plot. Future research on appropriate plot layout and configuration with regard to predictor variables is needed to better understand these relationships, and improve the predictive ability of forest metric modeling.
For many natural resource management questions, collection of training data can be one of the expensive and important aspects of a project. When data collection saving can be made by using readily available, and free, remotely sensed data in lieu of purchasing new data, it may be beneficial to use those savings on collecting robust training datasets. With more time and resources available for training data collection, the spatial distribution of trainings sites may be enhanced, or more thorough measurements may be taken at each site, depending on project specific needs. Whether more information is collected at each site, or more sites are added to a set, better training data generally lead to better fitting models and ultimately, reduced uncertainly, enhanced predictive ability, and more confident decision making.
Using the relationships derived from our field plots and remotely sensed data, we demonstrated that there was a great deal of similarity between NAIP and LiDAR based model estimates at the spatial scale of a plot and forest stand. In most of our comparisons models that used NAIP based predictors out performed those that used LiDAR or TOPO. In some cases, using both NAIP and LiDAR based predictors showed minor improvements in model fit. Often those improvements though were small and from a model complexity stand point there was no justification for adding additional sources of data, especially sources of data that have additional acquisition costs. Assuming that acquisition cost of remotely sensed data is a key factor to quantifying forest characteristics for the sake of forest management decision making, in our study the added cost of acquiring LiDAR data to estimate BAWD, QMD, BAH, or TPH was not worth the marginal improvement in estimating those characteristics at the spatial scale of the plot and stand.
Cost, quality, continuity, and time are all essential components to consider when quantifying forest characteristics. Our analyses suggest that outputs from models based on NAIP or LIDAR at the spatial scale of the plot and stand compare favorably. Thus, using imagery or elevation-based data to generate estimates of the forest metrics described in this study is somewhat irrelevant. If one source of data is available, there is not much to be gained by spending time or money to acquire an additional source. However, full coverage image data tends to be more readily available than LiDAR, which is currently only collected in isolated patches. Furthermore, when time is of the essence, it must be understood that custom acquisition of remotely sensed data, whether imagery or LIDAR, can be time consuming and may significantly delay a project.
For other forest characteristics related to topography and understory vegetation we presume that airborne LiDAR based models would have a substantial advantage over passive based imagery in accurately quantifying those characteristics. However, our study focused on quantifying common overstory components of the forest used in forest management decision making. In this instance, with the exception of BAH, LiDAR based models did not substantially improve estimates of BAWD, QMD, or TPH. Moreover, when comparing modeled estimates of BAH, especially at the spatial scale of the forest stand, it is highly questionable if the added cost of LiDAR acquisition is worth the minor reduction in modeled error. This has leads us to suggest that when existing remotely sensed data is available such as NAIP and additional resources are available for quantifying overstory forest characteristics, more emphasis on field data collection and design may prove to be a better use of those financial resources than purchasing additional remotely sensed data.
5. Conclusions
Both NAIP and LiDAR were used independently and in combination to predict the spatial distribution of forest characteristics such as BAWD, QMD, BAH, TPH. While recent attention has been focused on using LiDAR data to estimate these characteristics, we have shown that, when using common modeling techniques, similar results can be obtained by using high resolution imagery (NAIP). Therefore, either type of data could be used to perform these analyses and produce equivalent results when estimates of size and density are of interest. This is particularly apparent when fine grain, spatially explicit raster estimates are summarized to larger units such as forest stands.
Interestingly, NAIP and LiDAR measure different aspects of the environment, and when trees and forest characteristics are considered they both provide disparate but useful information for describing BAWD, QMD, BAH, and TPH. Our modeling results show that although different predictor layers (NAIP versus LiDAR) are being used to estimate forest characteristics, each output yields relatively similar interpretations of the forest. We show that regardless of whether NAIP or LiDAR is used, they both have equivalent predictive ability, error structure, and spatial distribution. Given the similarity in predicting forest metrics from these sources of data, using NAIP is a low-cost alternative to using LiDAR.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








