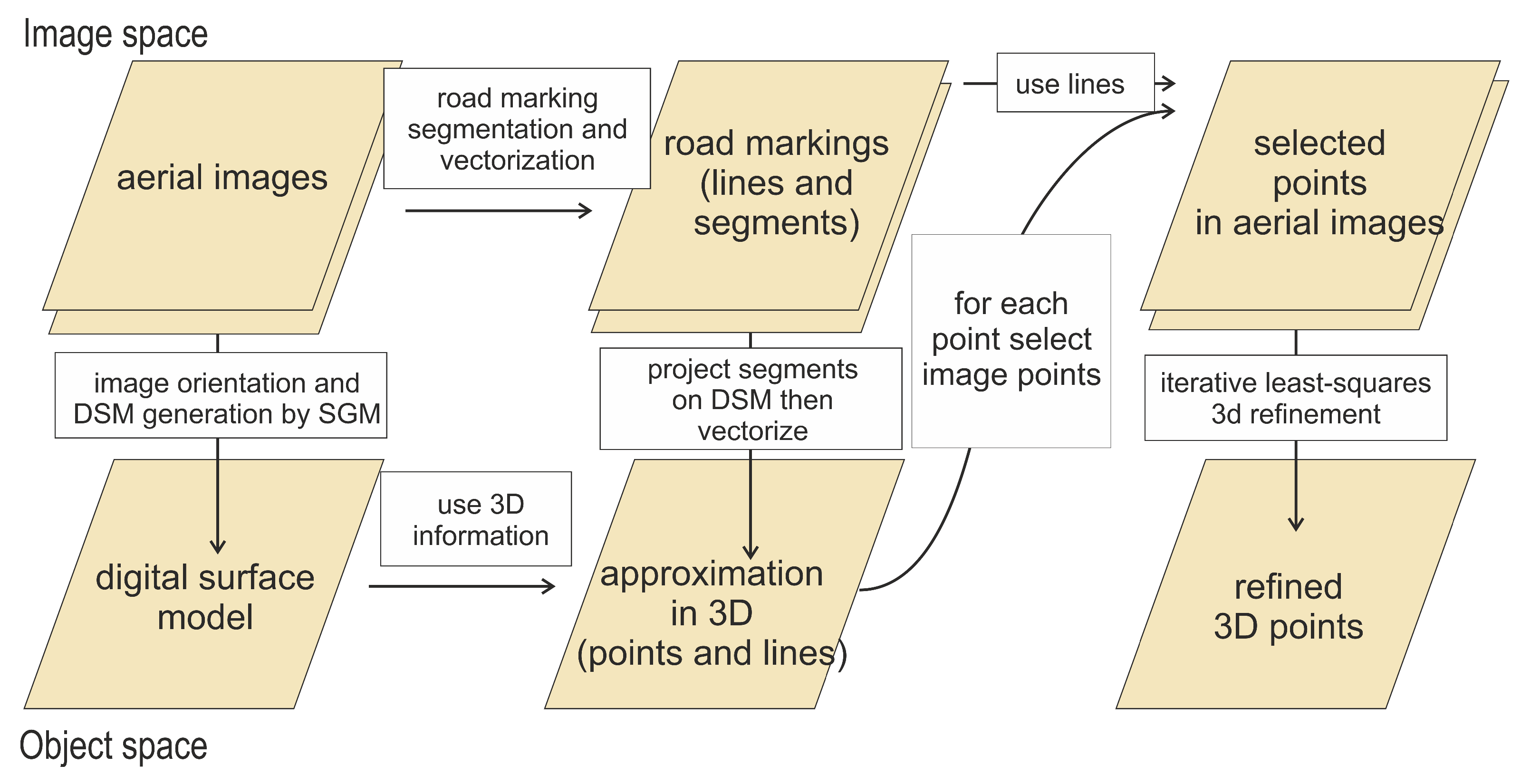
In this section, the methodology of selected processing steps for automatic segmentation and 3D reconstruction using multiview aerial imagery based on the work flow shown in
Figure 2 is described. The work flow can be divided into image space and object space operations. The work flow starts with the aerial images, from which a DSM was generated and the road markings were segmented. Based on the segmented road markings and the DSM, approximation points can be derived in the object space. The last step starts with the selection of points in the aerial images for each approximation point, with which the 3D refinement will be fed.
In the following subsections, the most important operations are depicted: Deep-learning-based segmentation of road markings (
Section 3.1), the least-squares refinement of 3D points (
Section 3.2), and the generation of approximations as well as selection of corresponding line points (
Section 3.3). Other processing steps, like DSM generation, are described in the Experimental section (
Section 4).
3.1. DL (Deep Learning) Segmentation of Road Markings
In order to localize road markings (lane markings), we applied a deep learning algorithm based on an improved version of the algorithm proposed by the authors of [
5]. To localize the lane markings, previous methods mostly applied two-step algorithms. First, a binary road segmentation method was applied to create a road mask, then non-learning-based algorithms were used to localize the lane markings. The masking of road segments reduces the high false positive rate in non-road areas. However, Azimi et al. [
5] proposed a single-step learning-based algorithm for the first time, to the best of our knowledge, to localize the lane markings directly by learning their features.
In order to use deep learning methods, an annotated data set is necessary. Therefore, a pixel-wise lane marking segmentation data set was created using airborne imagery, called the AerialLanes18 data set. They used images acquired by the 3K sensor system [
6]. The images were acquired over the city of Munich on the 26 April 2012 with a GSD of 13 cm.
Since lane markings in aerial images appear as tiny patterns, the direct application of deep learning algorithms will lead to a poor performance, e.g., based on patterns of 1 × 1 pixel size. The reason for this is the low-spectral analysis capability in CNNs (convolutional neural networks). Therefore, a method based on a modified fully CNN enabling a full spectral analysis will provide better performance.
In this article, the proposed DL algorithm was again trained with the AerialLanes18 data set, but here, a cleaned version of the data set was used. The architecture of the network is composed of two parts, an encoder and a decoder. The encoder extracts the high semantic, but lower resolution features from input data and the decoder recovers the original resolution from the output of the encoder. Wavelet transformations are used in combination with the CNN, allowing a full-spectral analysis of input images, which is important when it comes to tiny object segmentation, like lane markings. In this work, residual blocks have been used in the network architecture to further improve the performance.
To apply the modified neural network, the images were first chopped to the size of pixel. Afterwards, each patch was fed to the network as input. As output, a binary pixel-wise mask was obtained, containing predicted pixels for lane and non-lane marking classes. In the last step, a customized stitching algorithm was applied, considering the fact that CNNs have lower performance in boundary regions, which is assumed to be caused by the receptive field of the network.
It should be emphasized once again that the whole work flow is independent of any 3rd party information, such as OpenStreetMaps or Google Maps, and allows us to localize road markings with their 3D information regardless of their location with pixel-wise accuracy. It is also capable of localizing different road marking types, such as long, dash, no parking, and zebra lines, and different symbols, such as turn, speed-limit, bus, bicycle, and disabled signs.
The accuracy of the algorithm is expected to be higher on dark road surfaces, because the AerialLanes18 data set contains mostly roads with dark surfaces. Therefore, expanding the data set to contain roads with stretched contrasts between lane markings and road surfaces would improve the performance. For more information, we refer to Azimi et al. [
5].
3.2. Least-Squares Refinement of 3D Points
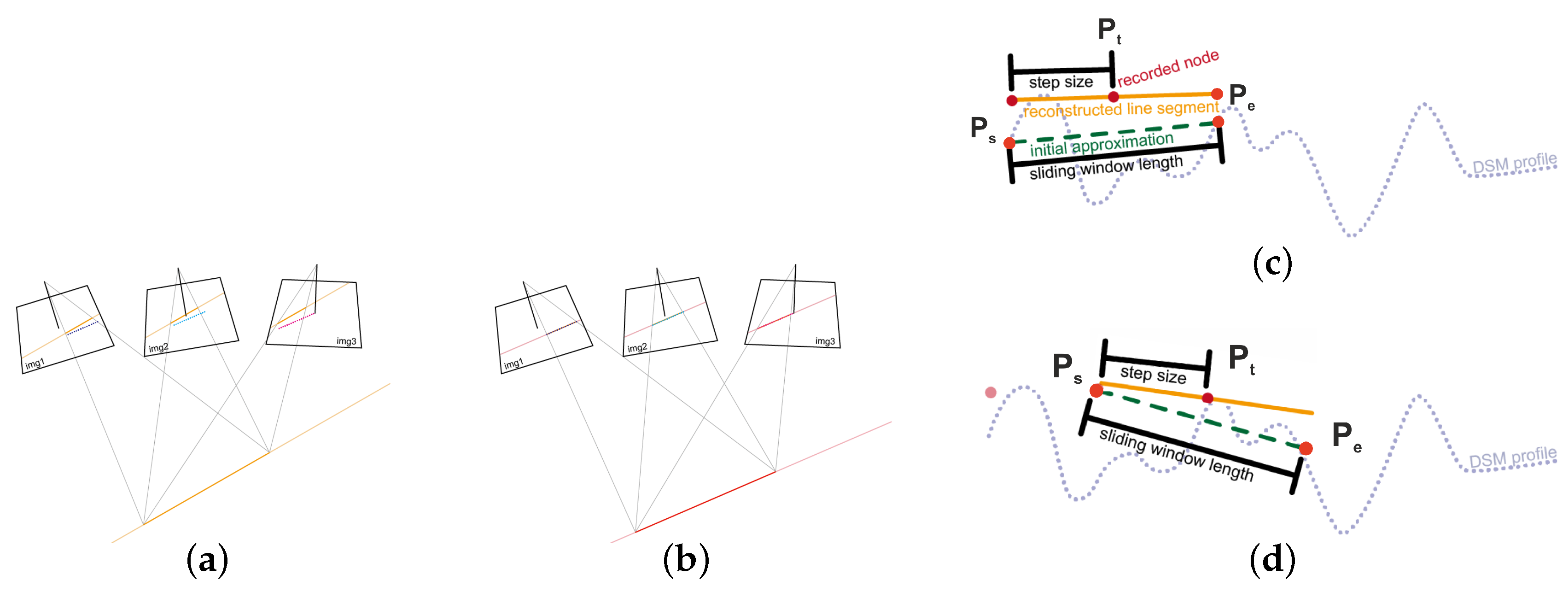
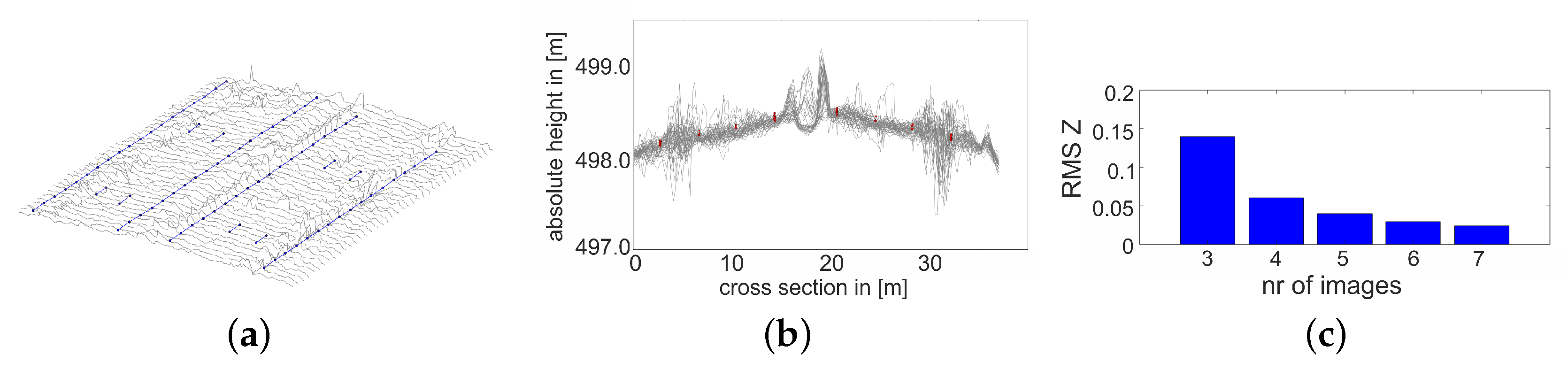
In this section, the process of refining the 3D position of a point at a road marking is described, as illustrated in
Figure 3. Following Taylor’s idea on minimization of a objective function [
7], we define an orthogonal regression function to optimize the 3D position of each point in the object space so that its back projection would best fit the detected lines in all the covering views (see
Figure 3a,b). Thus, the position and height of each 3D lane marking segment will be refined in one optimization step. The proposed approach addresses the challenging (quasi) infinite and curved properties of lane markings in the 3D reconstruction by applying a sliding window iteration of length
defined by a start point
, an end point
, and
S as step size. The 3D coordinates of the start and end point are estimated by the least-squares process and the target point
coordinates in the center are then recorded afterwards. After this, the sliding window moves to the next point. Starting from the recorded node of previous process, another line segment is reconstructed, i.e., the sliding window has moved step size forward. Its center point is then recorded and the step is repeated.
The orthogonal regression in the image space is defined as follows. Let the image coordinates of start and end point on the regression line be
and
where
, and the observed image points (here: The skeleton points of segmented road markings) be
for
with
N as the number of points. The observed image points have errors
and
. The orthogonal regression model in two-point form is then:
To express (
1) and (
2) shortly, a function
is defined as:
which takes the image coordinates of the start point
and end point
in the image space as well as the predicted y-coordinate
of an image point
and returns the estimated image coordinates
on
.
For the setup of the least-squares functions, observation and constraint equations must be defined. They describe the fitting of straight lines defined by the approximation start and end point to the extracted lines in all covering images, where the fitting lines on different images are transformed from a single line segment in the object space through the extended collinearity equation. Regarding the fact that the collinearity is a point-wise condition, a line segment is represented by the start and end point and in the object space.
Given a start point
and an end point
of a line segment
m in the object space and the interior and exterior parameters
of image
j, where
, with
J as the number of images covering this line segment, the back projection of these points into image
j then results in the image coordinates
and
.
Let
m be the corresponding line segment on image
j, where
, with
M as number of lines being extracted (observed). Given a data set
of point
i on line segment
m in image
j, their estimated image coordinates
on the infinite line
derived from the orthogonal regression model (Equation (
3)) are then:
Combining Equations (
4) with (
5) gives function
:
which takes image interior and exterior parameters
, the object coordinates of
and
, which define a line
, and the observed y-coordinate of the point
in image space, and returns the estimated image coordinates
on the back projected line of
. Following the structure of the
Gauss–Markov model, they are expressed as:
with the amount of observations
and with the amount of unknowns
.
To make the least-squares system robust and to avoid singularities, three constraint equations are defined. The first two equations are to fix the X- and Y-coordinates of the start point using the approximate values. This has influence on the very first estimation, as the start point has to be fixed to the approximation values. In the following steps of the sliding window, the estimated middle point can be used as fixed start point. The third equation is the fixation of the length of the line segment (i.e., constraining the relative location of the end point), which avoids unnecessary movements of the line end point. Following the structure of the
Gauss–Markov model with constraints , all constraint equations can be written as:
with the number of constraints
. The redundancy of the problem is then:
Two kinds of singular cases can happen. First, a configuration defect in the object space appears, if there is no intersection of at least two projection rays possible as the 3D reconstruction approach still relies on the intersection of multiple projection rays from different views. This happens if there is only one image covering the area or all line segment lay on epipolar lines. In these cases, the problem is not solvable. Second, a configuration defect in image space can happen, when all or nearly all of the extracted lines lie in row direction on all the covering images. In all other cases, e.g., if the targeted line segments lie only on some of the stereo pairs’ epipolar planes, the problem is still solvable, as those stereo pairs are not contributing to the solution. The same shall apply if only in some of the images, the extracted line segments lie in row direction: The problem is solvable, as those images are not contributing measurements to the estimation. In practice, no configuration defects occur, as the special flight configuration described in
Section 4.1 will prevent the occurrence.
More details about the implemented Gauss–Markov model with constraints, including some sensitivity and simulation studies can be found in Reference [
1]. The resulting 3D coordinates of the target point
are simply calculated as the geometric center of start and end point.
3.3. Generation of Approximations and Selection of Corresponding Line Points
The task here is to select observed points
on line
m in image
j as defined in Equation (
7), given a start and end point
and
in object space. The starting point is the road marking segments in the covering images, as well as the orthoprojected segments in the object space. With projecting all images onto the DSM, the segmented labels will be superimposed in the object space, i.e., if one point of the road marking is missed in one image, it may be detected in the other images and thus result in a higher confidence.
The whole process of selecting image points and generating approximation points is visualized in
Figure 4. Given the road marking segments in the images, a skeleton operator is performed, which extracts the center lines of the road marking segments (see
Figure 4a,b). After pruning and smoothing of the center lines, the center points are recorded. Additionally, approximation points are generated for each line based on the Euclidean distance of step size
S using the labels in the orthoprojected images. The
X and
Y values are derived from the orthoprojection of the original image onto the DSM, whereas the
Z value is taken from the DSM directly, which finally gives approximations for start, end, and target points as visualized in
Figure 4c.
By back-projecting the start and end points into each image, the corresponding line points can be found, which is a crucial step, as the assignment can be ambiguous due to inaccurate approximation values or missing line detection. This step is visualized in
Figure 4d. A search space around the back-projected start and end points must be defined, in which all points are assumed to belong to the same line. Additional checks are required in terms of parallelism, distances, and straightness to avoid wrong assignments, which finally leads to many rejected points. However, a parameter defining the size of the search space must be defined, which is the distance of observed line point to the line between the back-projected start and end point in pixel. This parameter depends, among others, on the GSD of images and road marking sizes. Finally, all the observed road marking points for each image are collected as shown in
Figure 4e. Based on this procedure, there is no need for a direct point or line matching between the images, as the points on each line are collected independently in each image.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

