Study of NSSDA Variability by Means of Automatic Positional Accuracy Assessment Methods


Abstract
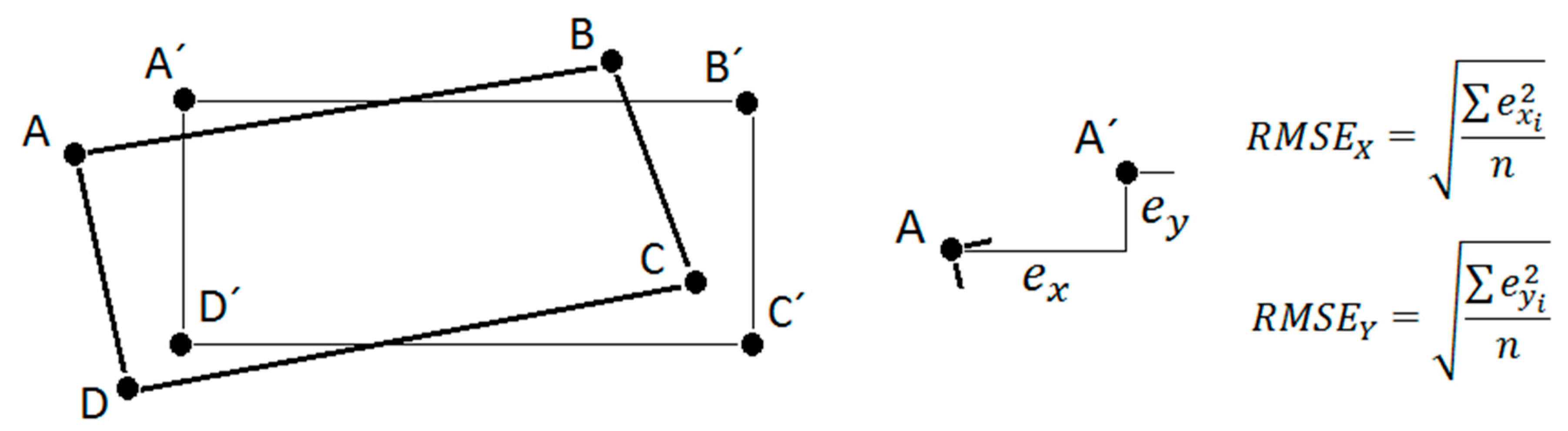
:1. Introduction
- Give information about the statistical behavior of the methodology.
- Related to the previous, give a clear and better recommendation about the number and distribution of check points and their influence on the variability and reliability of results.
2. Urban Databases Used and Points Population
3. Sampling Procedure
3.1. Normality Testing
3.2. Sample Design
3.3. Sample Sizes and Application of the NSSDA Standard
4. Effect of Sample Size and Sample Distribution on NSSDA Variability
4.1. Effect of Sample Size on NSSDA Variability
4.2. Effect of Sample Distribution on NSSDA Variability
5. Conclusions
- The NSSDA presents a small tendency to underestimate accuracy.
- For the minimum proposed sample size n = 20 points (size recommended by the FGDC and suggested by most of the PBSM), the variability of results is in the order of ±11%.
- The variation range decreases when the sample size increases.
- When the results are expressed graphically, the curve obtained can be employed in order to give some guidance on the recommended sample size when PBSM is used, specifically, when APAA methods are used for evaluating the positional quality of urban GDBs.
- When the number of points selected for each pair of polygons increases the positional accuracy determined by the NSSDA estimations decreases, probably due to the generalization processes.
Author Contributions
Funding
Conflicts of Interest
References
- Ruiz-Lendínez, J.J.; Ureña-Cámara, M.A.; Ariza-López, F.J. A Polygon and Point-Based Approach to Matching Geospatial Features. ISPRS Int. J. Geo-Inf. 2017, 6, 399. [Google Scholar] [CrossRef]
- Ariza-López, F.J.; Ruiz-Lendinez, J.J.; Ureña-Cámara, M.A. Influence of Sample Size on Automatic Positional Accuracy Assessment Methods for Urban Areas. ISPRS Int. J. Geo-Inf. 2018, 7, 200. [Google Scholar] [CrossRef]
- Morrison, J. Spatial data quality. In Elements of Spatial Data Quality; Guptill, S.C., Morrison, J.L., Eds.; Pergamon Press: Oxford, UK, 1995; pp. 1–12. [Google Scholar]
- Ariza-López, F.J.; Atkinson-Gordo, A. Variability of NSSDA Estimations. J. Surv. Eng. 2008, 134, 39–44. [Google Scholar] [CrossRef]
- Li, Z. Effects of check points on the reliability of DTM accuracy estimates obtained from experimental test. Photogramm. Eng. Remote Sens. 1991, 57, 1333–1340. [Google Scholar]
- U.S. Bureau of the Budget (USBB). United States National Map Accuracy Standards; U.S. Bureau of the Budget (USBB): Washington, DC, USA, 1947. [Google Scholar]
- American Society of Civil Engineering (ASCE). Map Uses, Scales and Accuracies for Engineering and Associated Purposes; ASCE Committee on Cartographic Surveying, Surveying and Mapping Division: New York, NY, USA, 1983. [Google Scholar]
- Federal Geographic Data Committee (FGDC). Geospatial Positioning Accuracy Standards, Part 3: National Standard for Spatial Data Accuracy; FGDC-STD-007; FGDC: Reston, VA, USA, 1998. [Google Scholar]
- Ruiz-Lendinez, J.J.; Ariza-López, F.J.; Ureña-Cámara, M.A. A point-based methodology for the automatic positional accuracy assessment of geospatial databases. Surv. Rev. 2016, 48, 269–277. [Google Scholar] [CrossRef]
- Ley, R. Accuracy assessment of digital terrain models. In Proceedings of the Auto-Carto, London, UK, 14–19 September 1986; pp. 455–464. [Google Scholar]
- Newby, P.R. Quality management for surveying, photogrammetry and digital mapping at the ordnance survey. Photogramm. Rec. 1992, 79, 45–58. [Google Scholar] [CrossRef]
- Minnesota Planning Land Management Information Center (MPLMIC). Positional Accuracy Handbook; MPLMIC: St. Paul, MN, USA, 1999. [Google Scholar]
- Atkinson-Gordo, A. Control de Calidad Posicional en Cartografía: Análisis de los Principales Estándares y Propuesta de Mejora. Ph.D. Thesis, University of Jaén, Jaén, Spain, 2005. [Google Scholar]
- Zandbergen, P. Positional Accuracy of Spatial Data: Non-Normal Distributions and a Critique of the National Standard for Spatial Data Accuracy. Trans. GIS 2008, 12, 103–130. [Google Scholar] [CrossRef]
- Ruiz-Lendinez, J.; Ureña-Cámara, M.; Mozas-Calvache, A. GPS survey of roads networks for the positional quality control of maps. Surv. Rev. 2009, 41, 374–383. [Google Scholar] [CrossRef]
- Goodchild, M.; Hunter, G. A simple positional accuracy measure for linear features. Int. J. Geogr. Inf. Sci. 1997, 11, 299–306. [Google Scholar] [CrossRef]
- Herrera, F.; Lozano, M.; Verdegay, J. Tackling real-coded genetic algorithms: Operators and tools for behavioral analysis. Artif. Intell. Rev. 1998, 12, 265–319. [Google Scholar] [CrossRef]
- Arkin, E.; Chew, L.; Huttenlocher, D.; Kedem, K.; Mitchell, J. An Efficiently Computable Metric for Computing Polygonal Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 209–216. [Google Scholar] [CrossRef]
- Ruiz-Lendinez, J.J.; Ariza-López, F.J.; Ureña-Cámara, M.A.; Blázquez, E. Digital Map Conflation: A Review of the Process and a Proposal for Classification. Int. J. Geogr. Inf. Sci. 2011, 25, 1439–1466. [Google Scholar] [CrossRef]
- Giordano, A.; Veregin, H. Il Controllo di Qualitá nei Sistemi Informative Territoriali; Cardo Editore: Venetia, Italy, 1994. [Google Scholar]
- Goodchild, M.; Gopal, S. Accuracy of Spatial Data Bases; Taylor & Francis: London, UK, 1989. [Google Scholar]
- Leung, Y. A locational error model for spatial features. Int. J. Geogr. Inf. Sci. 1998, 12, 607–620. [Google Scholar] [CrossRef]
- Shi, W.; Liu, W. A stochastic process-based model for the positional error of a line segments in GIS. Int. J. Geogr. Inf. Sci. 2001, 12, 131–143. [Google Scholar] [CrossRef]
- McCollum, J.M. Map error and root mean square. In Proceedings of the Towson University GIS Symposium, Baltimore, MD, USA, 2–3 June 2003. [Google Scholar]
- Greenwalt, C. and Shultz, M. Principles of Error Theory and Cartographic Applications; Technical Report-96; ACIC: St Louis, MO, USA, 1962. [Google Scholar]
- Vonderohe, A.P.; Chriman, N.R. Tests to establish the quality of digital cartographic data: Some example from the Dane County Land Records Project. In Proceedings of the Auto-Carto 7, Washington, DC, USA, 11–14 March 1985; pp. 552–559. [Google Scholar]
- Bolstad, P.V.; Gessler, P.; Lillesand, T.M. Positional uncertainty in manually digitized map data. Int. J. Geogr. Inf. Syst. 1990, 4, 399–412. [Google Scholar] [CrossRef]
- Vauglin, F. Modèles statistiques des imprécisions géométriques des objets géographiques linéaires. Ph.D. Dissertation, University of Marne-La-Vallée, Champs-sur-Marne, France, 1997. [Google Scholar]
- Bel Hadj, A. Moment representation of polygons for the assessment of their shape quality. J. Geogr. Syst. 2002, 4, 209–232. [Google Scholar]
- Zandbergen, P.A. Characterizing the error distribution of Lidar elevation data for North Carolina. Int. J. Remote Sens. 2011, 32, 409–430. [Google Scholar] [CrossRef]
- Liu, X.; Hu, P.; Hu, H.; Sherba, J. Approximation Theory Applied to DEM Vertical Accuracy Assessment. Trans. GIS. 2012, 16, 397–410. [Google Scholar] [CrossRef]
- Rodríguez-Gonzálvez, P.; Garcia-Gago, J.; Gomez-Lahoz, J.; González-Aguilera, D. Confronting passive and active sensors with non-gaussian statistics. Sensors 2014, 14, 13759–13777. [Google Scholar] [CrossRef]
- Rodríguez-Gonzálvez, P.; González-Aguilera, D.; Hernández-López, D.; González-Jorge, H. Accuracy assessment of airborne laser scanner dataset by means of parametric and non-parametric statistical methods. IET Sci. Meas. Technol. 2015, 9, 505–513. [Google Scholar] [CrossRef]
- Ariza-López, F.J.; Rodríguez-Avi, J.; González-Aguilera, D.; Rodríguez-Gonzálvez, P. A New Method for Positional Accuracy Control for Non-Normal Errors Applied to Airborne Laser Scanner Data. Appl. Sci. 2019, 9, 3887. [Google Scholar] [CrossRef]
- Van Niel, T.G.; McVicar, T.R. Experimental evaluation of positional accuracy estimates from a linear network using point- and line-based testing methods. Int. J. Geogr. Inf. Sci. 2002, 16, 455–473. [Google Scholar] [CrossRef]
- Marsaglia, G.; Tsang, W.W.; Wang, J. Evaluating Kolmogorov’s distribution. J. Stat. Softw. 2003, 8, 1–4. [Google Scholar] [CrossRef]
- Chauve, A.; Vega, C.; Durrieu, S.; Bretar, F.; Allouis, T.; Pierrot-Deseilligny, M.; Puech, W. Advanced full-waveform LiDAR data echo detection: Assessing quality of derived terrain and tree height models in an alpine coniferous forest. Int. J. Remote Sens. 2009, 30, 5211–5228. [Google Scholar] [CrossRef]
- Estornell, J.; Ruiz, L.; Velázquez-Martí, B.; Hermosilla, T. Analysis of the factors affecting LiDAR DTM accuracy in a steep shrub area. Int. J. Digit. Earth 2011, 4, 521–538. [Google Scholar] [CrossRef]
- Razak, K.A.; Straatsma, M.W.; Van Westen, C.J.; Malet, J.P.; de Jong, S.M. Airborne laser scanning of forested landslides characterization: Terrain model quality and visualization. Geomorphology 2011, 126, 186–200. [Google Scholar] [CrossRef]
- National Digital Elevation Program (NDEP). Guidelines for digital elevation data-The National Map; 3D Elevation Program Standards and Specifications: Washington, DC, USA, 2006. [Google Scholar]
- US Army Corps of Engineers (USACE). Engineering and Design-Photogrammetric Mapping; EM 1110-1-1000; US Army Corps of Engineers (USACE): Washington, DC, USA, 2002. [Google Scholar]
- Ariza-López, F.J.; Atkinson, A. Metodologías de Control Posicional. Visión general y Análisis crítico; Technical Report-CT-148 AENOR; Universidad de Jaén: Jaén, Spain, 2006. [Google Scholar]
- Ariza-López, F.J. Guía para la evaluación de la exactitud posicional de datos espaciales; Publicación 557: Serie de documentos especializados; Instituto Panamericano de Geografía e Historia: Montevideo, Uruguay, 2019. [Google Scholar]
- Ariza-López, F.J.; Rodríguez-Avi, J. A Statistical Model Inspired by the National Map Accuracy Standard. Photogramm. Eng. Remote Sens. 2014, 80, 271–281. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sheet | Urban Area DENOMINATION | Number of Polygons BCN25/MTA10 | Total Number of Features Matched | Features Matched with 95% Confidence Level | |||||
|---|---|---|---|---|---|---|---|---|---|
| Polygons Matched | Total Number of Vertexes | % of Matched Polygons | Number of Matched Vertexes | % of Matched Vertexes | |||||
| BCN25 | MTA10 | BCN25 | MTA10 | ||||||
| 1009 | Granada_08 | 1309/1345 | 1303 | 4494 | 11481 | 22.79 | 668 | 14,86 | 5,81 |
| 1009 | Granada_07 | 2250/2301 | 2223 | 8999 | 16144 | 45.07 | 3378 | 37.53 | 20.92 |
| TOTAL | 3559/3656 | 3526 | 13493 | 27625 | 38.67 | 4046 | 29.98 | 14.64 | |
| 1- Select a sample of a minimum of 20 check points (n> = 20). 2- Compute individual errors for each point i: - If = then NSSDA (H) = 2.44771/2 ∗ = 2.4477 ∗ RMSEX - If ≠ and 0.6 < (/) < 1 then
NSSDA (H) = 2.4477 ∗ 0.5 ∗ (RMSEX + RMSEY)
|
| Sample Size n | NSSDA Accuracy (m) | Deviation ±(m) | Variation ±(%) | Sample Size n | NSSDA Accuracy (m) | Deviation ±(m) | Variation ±(%) |
|---|---|---|---|---|---|---|---|
| 10 | 12.224 | 1.495 | 12.2 | 100 | 12.627 | 0.650 | 5.1 |
| 20 | 12.392 | 1.376 | 11.1 | 150 | 12.635 | 0.545 | 4.3 |
| 30 | 12.475 | 1.182 | 9.5 | 200 | 12.642 | 0.482 | 3.8 |
| 40 | 12.520 | 1.048 | 8.4 | 250 | 12.640 | 0.421 | 3.3 |
| 50 | 12.552 | 0.978 | 7.8 | 300 | 12.655 | 0.342 | 2.7 |
| 60 | 12.580 | 0.867 | 6.9 | 350 | 12.659 | 0.273 | 2.2 |
| 70 | 12.598 | 0.798 | 6.3 | 400 | 12.662 | 0.218 | 1.7 |
| 80 | 12.610 | 0.747 | 5.9 | 450 | 12.662 | 0.161 | 1.3 |
| 90 | 12.614 | 0.685 | 5.4 | 500 | 12.665 | 0.112 | 0.9 |
| Points × Polygon | Total Points | Accuracy (m) | Points × Polygon | Total Points | Accuracy (m) | Points × Polygon | Total Points | Accuracy (m) |
|---|---|---|---|---|---|---|---|---|
| 1 | 1375 | 12.610 | 8 | 2902 | 13.012 | 15 | 3890 | 13.996 |
| 2 | 2047 | 12.671 | 9 | 3174 | 13.103 | 16 | 3943 | 14.102 |
| 3 | 2189 | 12.698 | 10 | 3192 | 13.116 | 17 | 3991 | 14.154 |
| 4 | 2311 | 12.724 | 11 | 3368 | 13.552 | 18 | 4009 | 14.157 |
| 5 | 2389 | 12.729 | 12 | 3553 | 13.617 | 19 | 4046 | 14.160 |
| 6 | 2672 | 12.773 | 13 | 3711 | 13.812 | 20 | - | - |
| 7 | 2799 | 12.881 | 14 | 3788 | 13.833 | - | - | - |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruiz-Lendínez, J.J.; Ariza-López, F.J.; Ureña-Cámara, M.A. Study of NSSDA Variability by Means of Automatic Positional Accuracy Assessment Methods. ISPRS Int. J. Geo-Inf. 2019, 8, 552. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8120552
Ruiz-Lendínez JJ, Ariza-López FJ, Ureña-Cámara MA. Study of NSSDA Variability by Means of Automatic Positional Accuracy Assessment Methods. ISPRS International Journal of Geo-Information. 2019; 8(12):552. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8120552
Chicago/Turabian StyleRuiz-Lendínez, Juan José, Francisco Javier Ariza-López, and Manuel Antonio Ureña-Cámara. 2019. "Study of NSSDA Variability by Means of Automatic Positional Accuracy Assessment Methods" ISPRS International Journal of Geo-Information 8, no. 12: 552. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8120552