Finding Visible kNN Objects in the Presence of Obstacles within the User’s View Field †

1
NCTU Office of Research and Development, National Chiao Tung University, Hsinchu 300, Taiwan
2
MediaTek Inc., Hsinchu 300, Taiwan
3
Department of Computer Science and Information Engineering, National Cheng Kung University, Tainan City 701, Taiwan
4
Department of Industrial Engineering and Management, National Kaohsiung University of Science and Technology, Kaohsiung City 807, Taiwan
*
Author to whom correspondence should be addressed.
†
The manuscript is an extended version of our previous report. We will explain the differences between this paper and the previous version in more detail on page 3.
ISPRS Int. J. Geo-Inf. 2019, 8(3), 151; https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8030151
Submission received: 8 February 2019
/
Revised: 11 March 2019
/
Accepted: 15 March 2019
/
Published: 20 March 2019
(This article belongs to the Special Issue Spatial Databases: Design, Management, and Knowledge Discovery)
Abstract
:In many spatial applications, users are only interested in data objects that are visible to them. Hence, finding visible data objects is an important operation in these real-world spatial applications. This study addressed a new type of spatial query, the View field-aware Visible k Nearest Neighbor (V2-kNN) query. Given the location of a user and his/her view field, a V2-kNN query finds data object p so that p is the nearest neighbor of and visible to the user, where visible means the data object is (1) not hidden by obstacles and (2) inside the view field of the user. Previous works on visible NN queries considered only one of these two factors, but not both. To the best of our knowledge, this work is the first to consider both the effect of obstacles and the restriction of the view field in finding the solutions. To support efficient processing of V2-kNN queries, a grid structure is used to index data objects and obstacles. Pruning heuristics are also designed so that only data objects and obstacles relevant to the final query result are accessed. A comprehensive experimental evaluation using both real and synthetic datasets is performed to verify the effectiveness of the proposed algorithms.
1. Introduction
The k nearest neighbor () query is an important spatial query type that has been studied extensively during the past decade [1,2]. Given a set of data objects and a query point q, a kNN query reports k data objects that are close to q. This kind of queries is useful in many real-world applications. For example, a tourist uses Google Maps to explore the restaurants that are closest to his/her location or a taxi driver utilizes the kNN query to find customers who are close to the taxi.
However, most existing works do not take the visibility of data objects into consideration, which makes their algorithms infeasible in many spatial applications; for example, interactive 2D online games, military simulation systems, and tourist recommendation systems.
Interactive 2D online games: In an interactive 2D online game, the overview map provides the enemy locations that can be seen from a player’s location. The player is interested in the map as the visible enemies are the main threat. Thus, the player should keep track of his/her nearest visible game objects so that he/she can attack or avoid them.
Military simulation systems: In a battle field, the command center wants to find one location to serve as the assembling point. Obviously, the assembling point should be clearly seen by the command center (i.e., it is not blocked by obstacles such as civilian buildings or vehicles), and the Euclidean distance from the command center to the assembling point should be minimized.
Tourist recommendation: A tourist information system provides k closest visible scenes for a given tourist. In this scenario, the scenes cannot be hidden by buildings or mountains so that the tourist can clearly see them in order to decide which one is his/her next visit point.
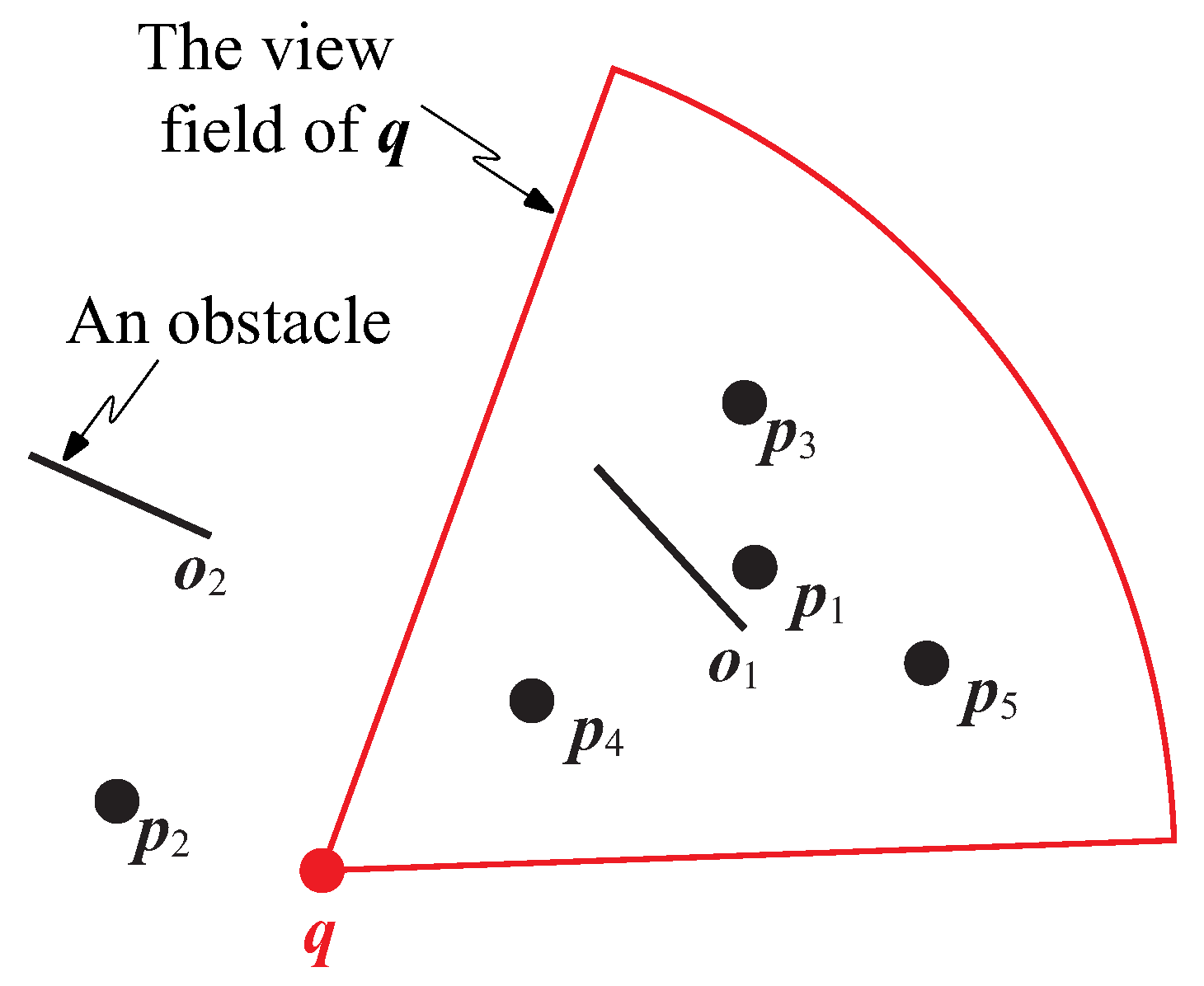
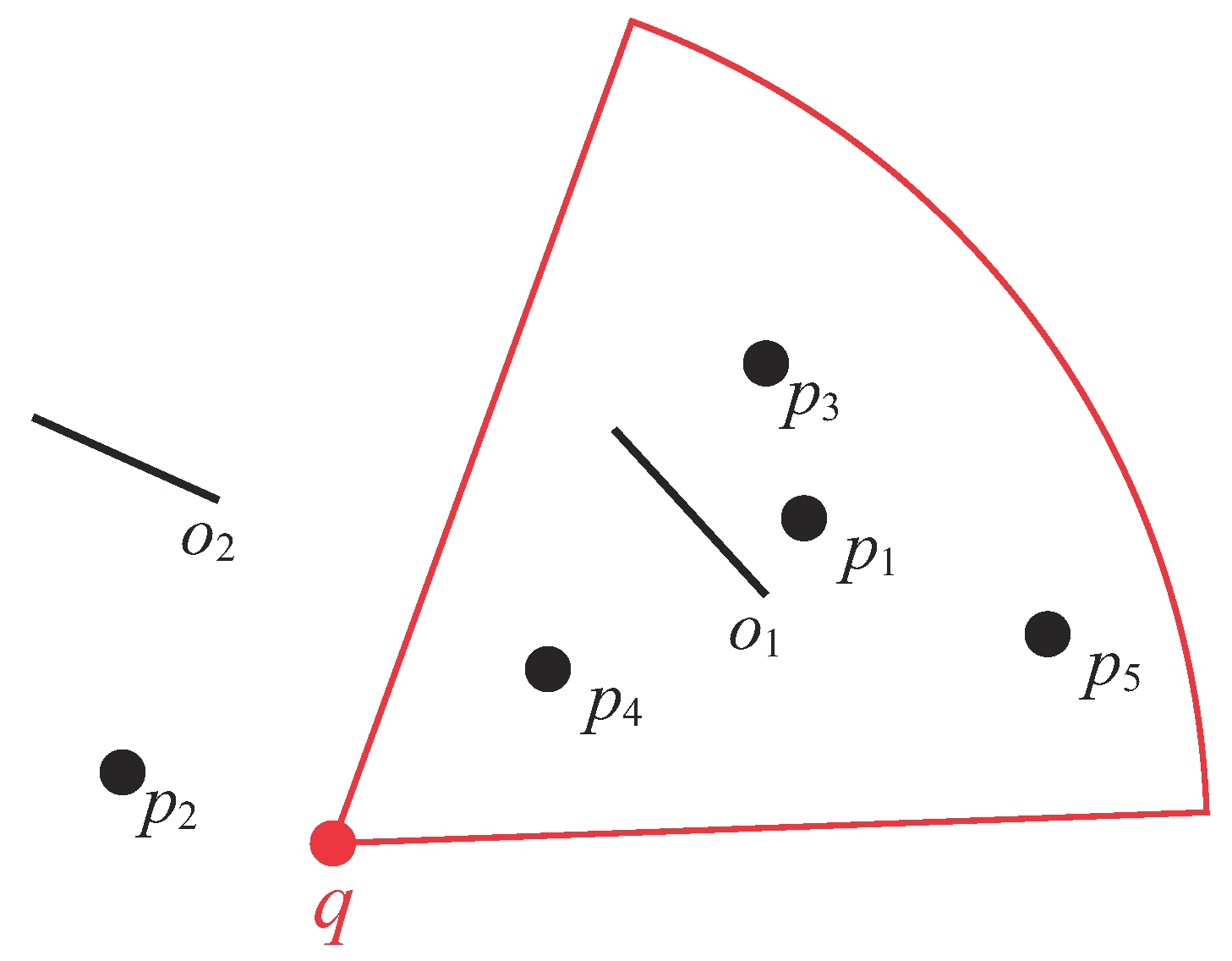
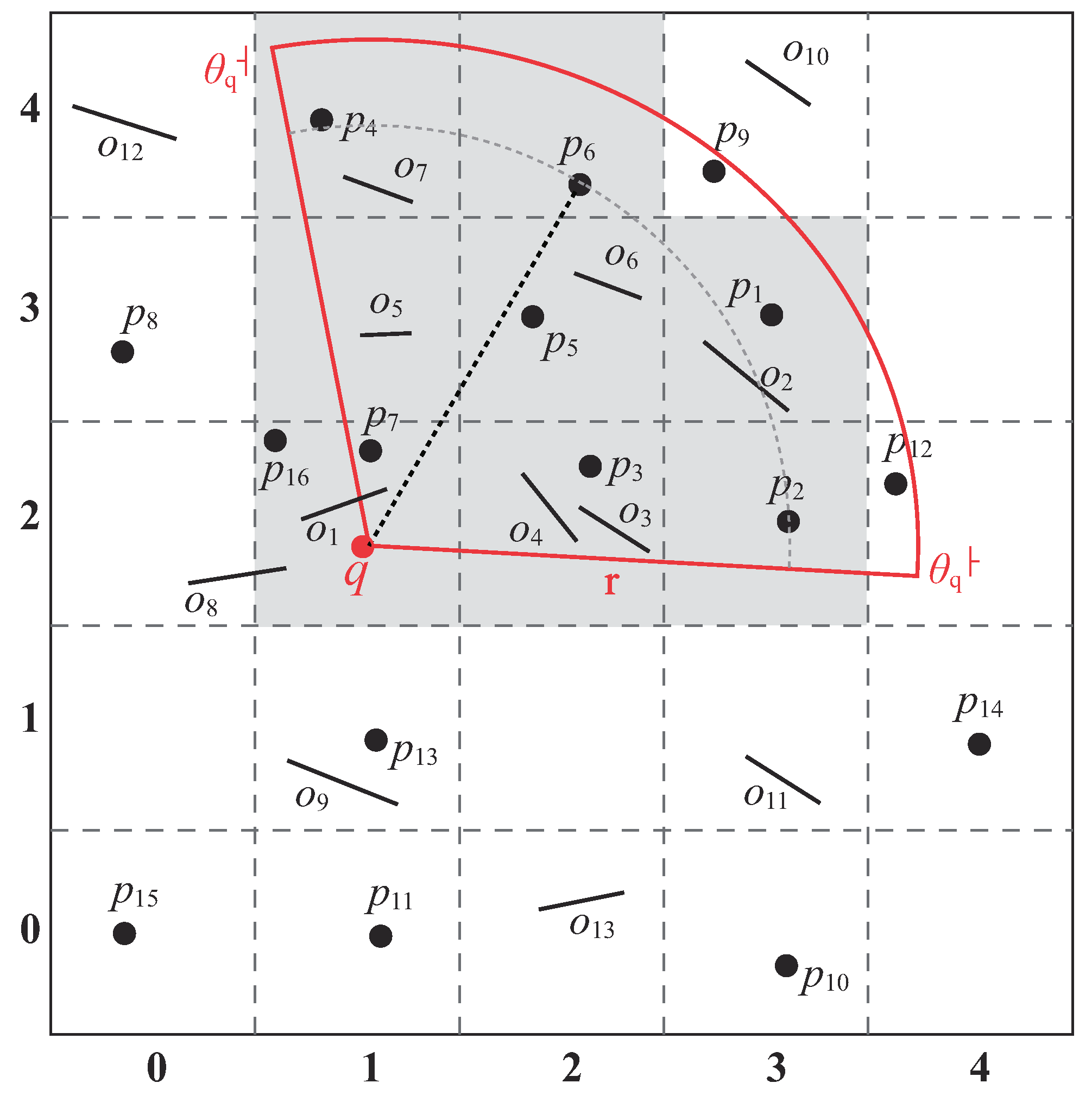
Conventional kNN query processing algorithms are inefficient for supporting current real-world applications as they do not take the visibility of data objects into consideration. This issue is illustrated in Figure 1, where q is the query point, are the obstacles (denoted by straight lines), and is a set of data objects. The fan-shaped area is the view field of query point q. Note that in this study, the visibility of a data object is affected by (1) the view field of a user and (2) the obstacles in the data space. The same as in [3], the view field defined in this paper is a 2D area that is the extent of the scene seen by a user; data objects are invisible to a user if they are outside his/her view field. Physical obstacles (e.g., building, trees, and hills) can block data objects so that they are invisible to the user [4].
Suppose ; the two visible nearest data objects of q are and . Note that is the closest data objects for q in the conventional kNN retrieval. However, it is neglected in visible kNN applications as it is not within q’s view field. Furthermore, although is closer to q than , it is not in the result set as is invisible to q owing to obstacle .
To process such kinds of queries, an intuitive thought is to utilize the conventional kNN algorithms to find the solutions. Hence, a simple approach is to set a very large m value () so as to make sure that the “real answers” are included in the result set. However, a serious problem is that it is very difficult to decide on a proper m value. If m is too small, k visible NNs may not be identified; in this case, a new value () has to be chosen, and the search is repeated. This can result in redundant computations as many data objects are re-evaluated during the execution iterations. On the other hand, if m is too large, time is wasted in checking data objects that are not included in the final answer, leading to expensive I/O costs and computational overhead. Hence, a completely new method has to be devised to address this v2-kNN problem.
Related work of this research will be discussed in Section 2. Major challenges in processing the View field-aware Visible k Nearest Neighbor (V2-kNN) queries are (1) how to efficiently identify data objects and obstacles inside a given view field and (2) how to determine the visibility of a data object as fast as possible. If every data object p is accessed and compared with all the obstacles to determine whether p is inside the given view field, the I/O cost, as well as the computation time must be extremely high.
To address this problem, we propose an efficient algorithm to retrieve the visible data objects in a given view field. The algorithm checks the data objects from near to far (according to their distance from the query point), because nearer data objects are more likely to be included in the result set. In addition, we also develop a set of pruning heuristics so that only the obstacles highly relevant to the query result are accessed when the visibility check is performed. Finally, we conducted extensive experiments using both real and synthetic datasets to verify the effectiveness of our algorithms.
The manuscript is an extended version of our previous report [5], in which we introduced the V2-kNN problem and outlined the idea of our basic method. Here, we substantially extend the basic method to a much more sophisticated algorithm, which includes three smart pruning techniques and efficient techniques to further enhance the performance of the algorithm (see Section 4.2, Section 4.3 and Section 4.4). Other augmentations are include in Section 2, and we give a quite thorough review of related work to make the paper self-contained. In Section 3, we add several examples to explain the meaning of the notations. Furthermore, we conduct a comprehensive performance evaluation in Section 5.
The rest of the work is organized as follows. In Section 2, we review some related studies. We formalize the V2-kNN problem and introduce our index scheme in Section 3. In Section 4, we give the detailed description of the proposed algorithm. We also introduce the pruning techniques in the section. Results of our experimental study are reported in Section 5. Finally, Section 6 gives the conclusions and future research directions.
2. Related Work
kNN query processing is a hot research topic in the database community [1,2,4,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27]. Numerous algorithms and data structures (e.g., B-tree [26], grid structure [27], or R-tree [28]) have been proposed for kNN query processing. Only a few of them are capable of processing “visible” kNN queries [4,14,15,18,19,20,21,22,23,24,25]. We can classify these works into two types: (1) visible kNN queries with the obstacle constraint and (2) visible kNN queries with the view field constraint. We will briefly review each of them in the following. Note that as we have mentioned in the previous section, none of these works consider the effect of obstacles and the view field at the same time.
2.1. Visible kNN Queries with the Obstacle Constraint
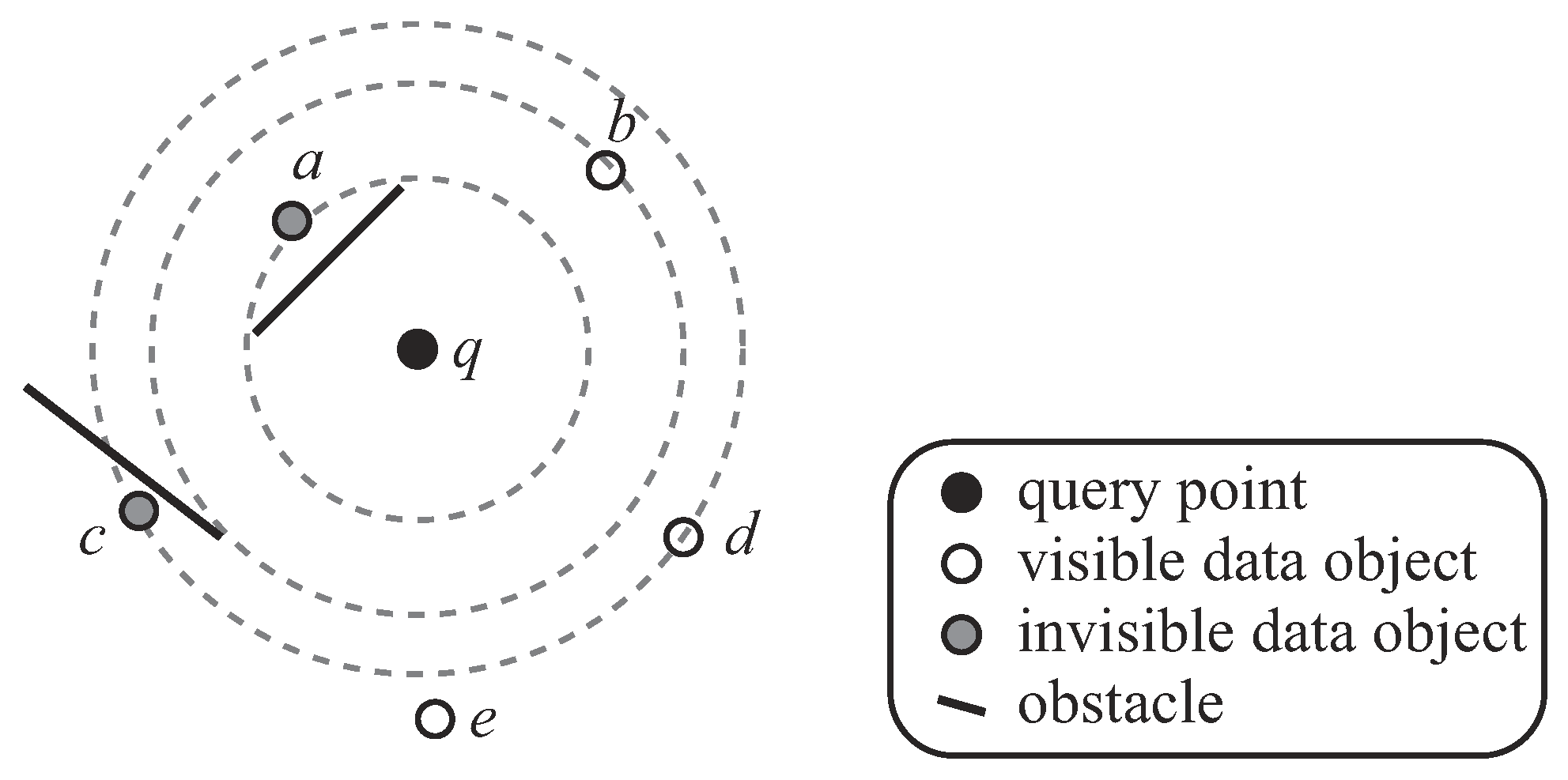
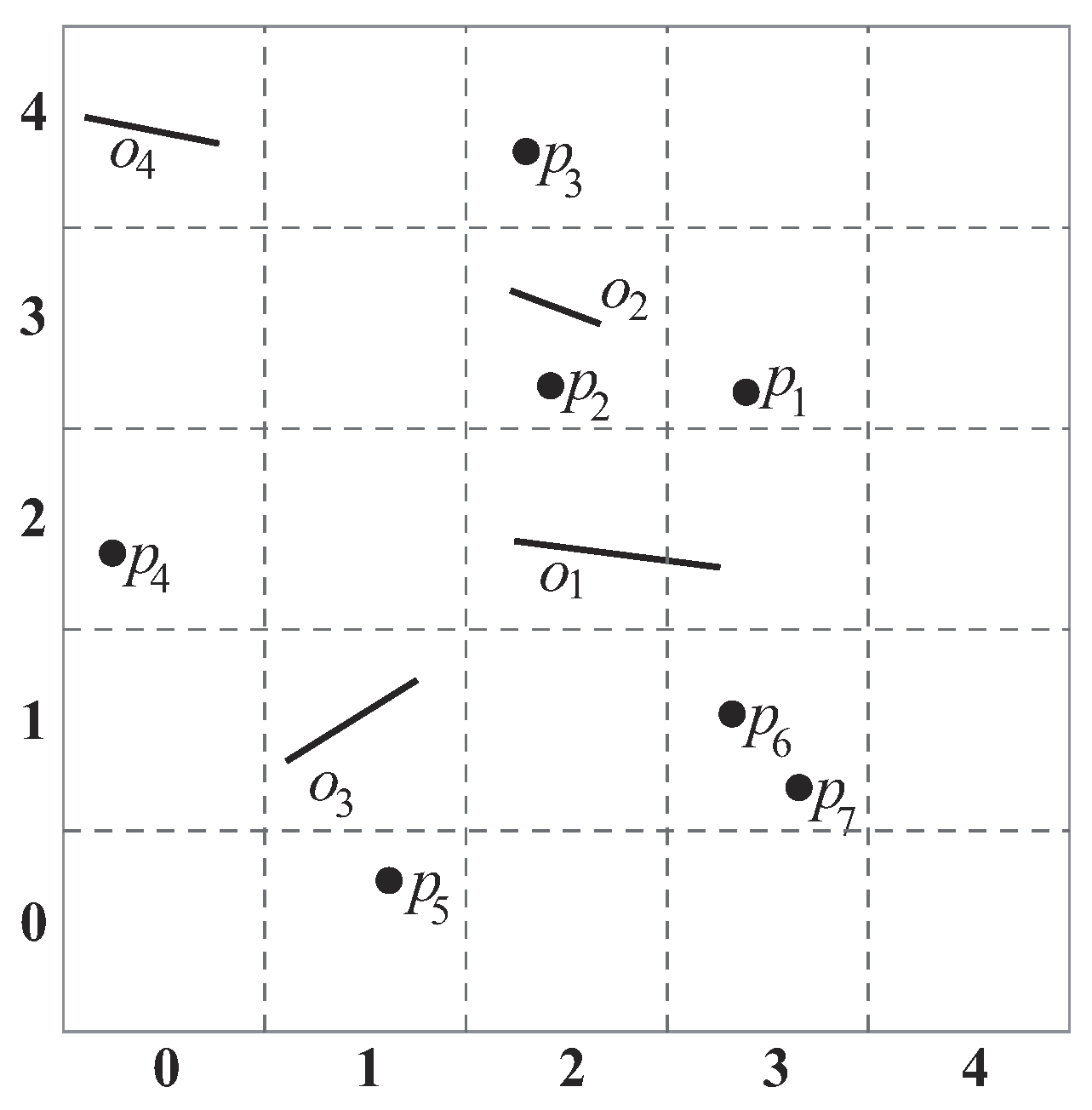
The VkNN query as proposed by Nutanong et al. [14,15]. A VkNN query retrieves k visible objects with the smallest distance to a query point q. Figure 2 shows an example of a VkNN query. In the figure, there are five data objects (i.e., ) and a query point q. The VkNN of q is (in order of their distance to q). Note that although a is the closest data object to q, it is not a qualifying answer. The reason is that a is hidden by an obstacle, and thus, it is invisible to q.
In [14,15], all data objects were indexed in an R-tree [28]. Nutanong et al. proposed two algorithms, POSTPRUNING and PREPRUNING, for processing VkNN queries. The difference between these two algorithms is the pruning strategies. The two algorithms are based on the observation that to check the visibility between q and data object p, we only need to compare p with the obstacles that are nearer to q than p.
Gao et al. in [4] studied the problem of continuously reporting visible k nearest neighbors to a query point moving along a line segment, whereas all the data objects are static. The algorithm utilizes R-tees to index the dataset and the obstacle set and uses a branch-and-bound technique to process the query. Gao et al. also proposed several pruning heuristics to improve the query performance. Another work that focused on continuously determining visible k nearest neighbors was proposed by Wang et al. [20]. They proposed a filtering-and-refinement framework to process the query efficiently. In the filtering stage, the authors proposed two pruning strategies to reduce the search space. Then, in the refinement stage, the algorithm examines the exact positions of the unfiltered data objects and finds the final result.
In [29], Wang et al. introduced All-k-Nearest-Neighbor (AkNN) search. Given a set of data objects P and a query set Q, an AkNN query finds for each query its k visible nearest neighbor in P. A naive method to tackle the problem is to perform the VkNN search for each query in Q. However, the method is inefficient as it needs to access the data objects in P many times, leading to high I/O and CPU costs. Wang et al. developed two algorithms to efficiently process AkNN queries. They also designed several pruning techniques to improve the query performance.
The Group Nearest Neighbor (GNN) query [16,17] is a novel form of NN search, which returns a data object with the minimum aggregate distance to all query points. For example, a group of friends, located at different places in a city, wants to find a restaurant for a meeting. The location of the restaurant should minimize the total travel distance to all the members in the group. The authors in [18,19] extended the idea of the GNN query by taking obstacles into account. Both of the works developed efficient pruning methods to prune unnecessarily accessed obstacles so as to enhance the query processing performance. The algorithms proposed in [18] can only handle the SUMaggregate function. However, in [19], the algorithm works for SUM, MIN, and MAXaggregate functions.
Gao et al. [30,31] introduced the Visible Reverse k Nearest Neighbor (VRkNN) query, which considers the obstacle influence on the visibility of data objects. They proposed the Visible Region Computation (VRC) algorithm to efficiently retrieve obstacles that affect the visibility of the query point. The VRkNN query processing algorithm utilizes the VRC algorithm to prune the search space and enhance the performance.
2.2. Visible kNN Queries with the View Field Constraint
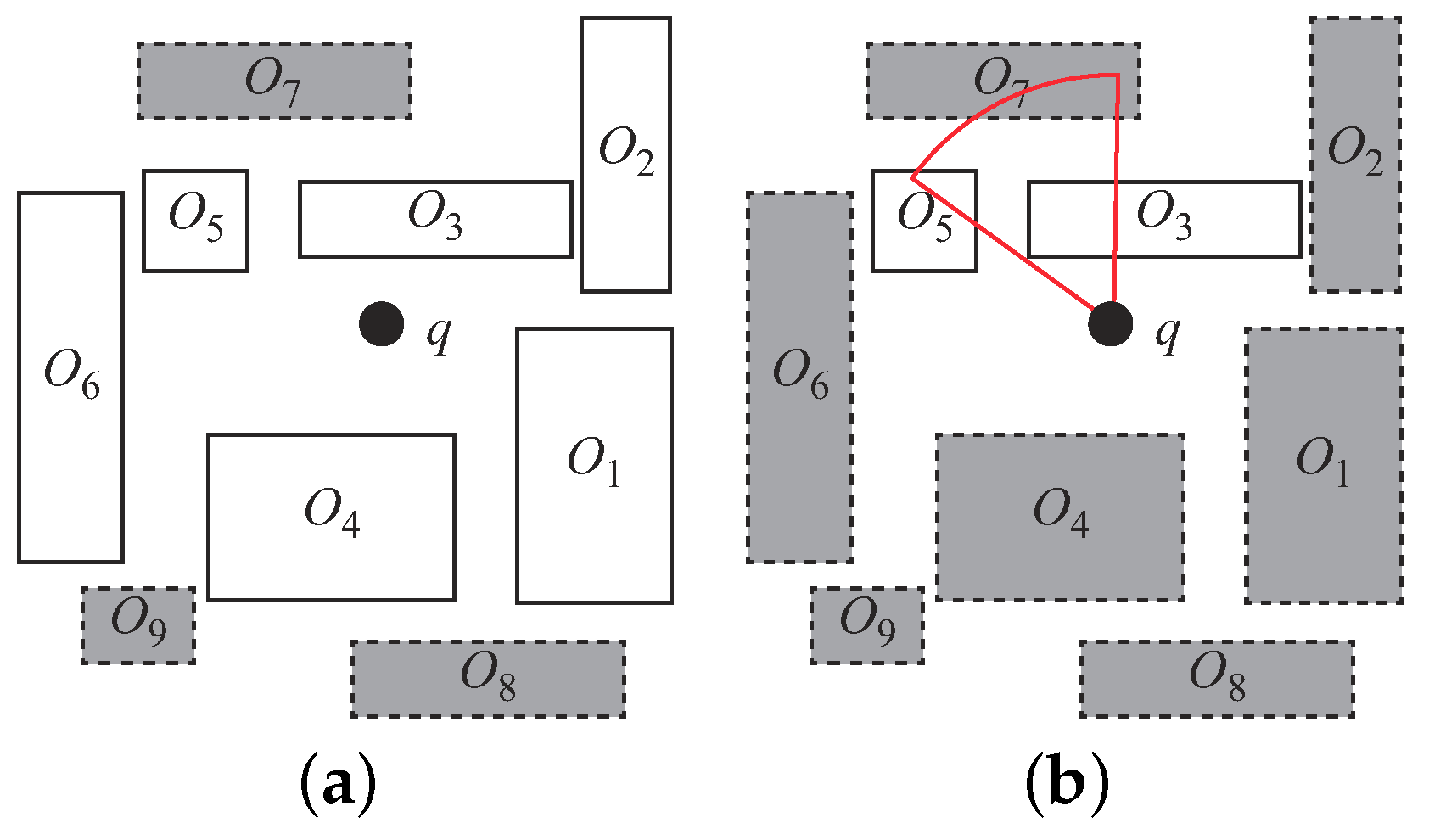
The Nearest Surrounder (NS) query was proposed by Lee et al. [21,22]. An NS query retrieves the nearest neighbor objects for all orientations around the query point q. For example, in Figure 3a, data objects (i.e., the white rectangles) are the nearest surrounder objects of q. Note that and (i.e., the gray rectangles) are not included in the answer set as they are hidden by other data objects.
For many applications, the data objects inside a certain view field are needed. The authors further proposed an NS query variant, named the Angle-constrained NS (ANS) query, which retrieves NS objects residing in a specified view field. In Figure 3b, an ANS query issued at q returns . The major difference between (A)NS and V2-kNN is that the (A)NS query retrieves “all visible” data objects in the view field. However, on the other hand, the number of visible data objects returned by the V2-kNN query is specified by the k value.
Yi et al. [23,24] introduced the View Field Nearest Neighbor () query that can retrieve the closest visible data object residing in a user’s view field. In [23], the authors used R*-tree [32] to index data objects and develop a branch-and-bound search algorithm to traverse the R*-tree to find the results. They also designed a pruning technology that can efficiently filter the R*-tree nodes that do not overlap with the given view field to enhance the search performance. In [24], Yi et al. designed a new algorithm to process the VFNN query. The new algorithm proposed in [24] uses a grid-based index to maintain data objects. The main difference between our approach and that of Yi et al. is that they did not take the effect of obstacles into consideration.
In [25], Yi et al. introduced the Reverse View Field Nearest Neighbor (RVFNN) query, which returns the nearest object (according to a query point) from among the data objects whose view fields contain the query point. The authors first proposed an algorithm that runs on R*-tree to process the RVFNN query. Then, they introduced a new type of spatial data index structure called the view field R-tree for RVFNN searches to overcome the limitations of R*-tree.
The hidden-surface determination problem [33] studied in the area of computer graphics shares some similarity to our problem. The hidden-surface determination is a process used to determine which surfaces and parts of surfaces are not visible from a certain viewpoint. Z-buffering [34] is one of algorithms that can address the problem.
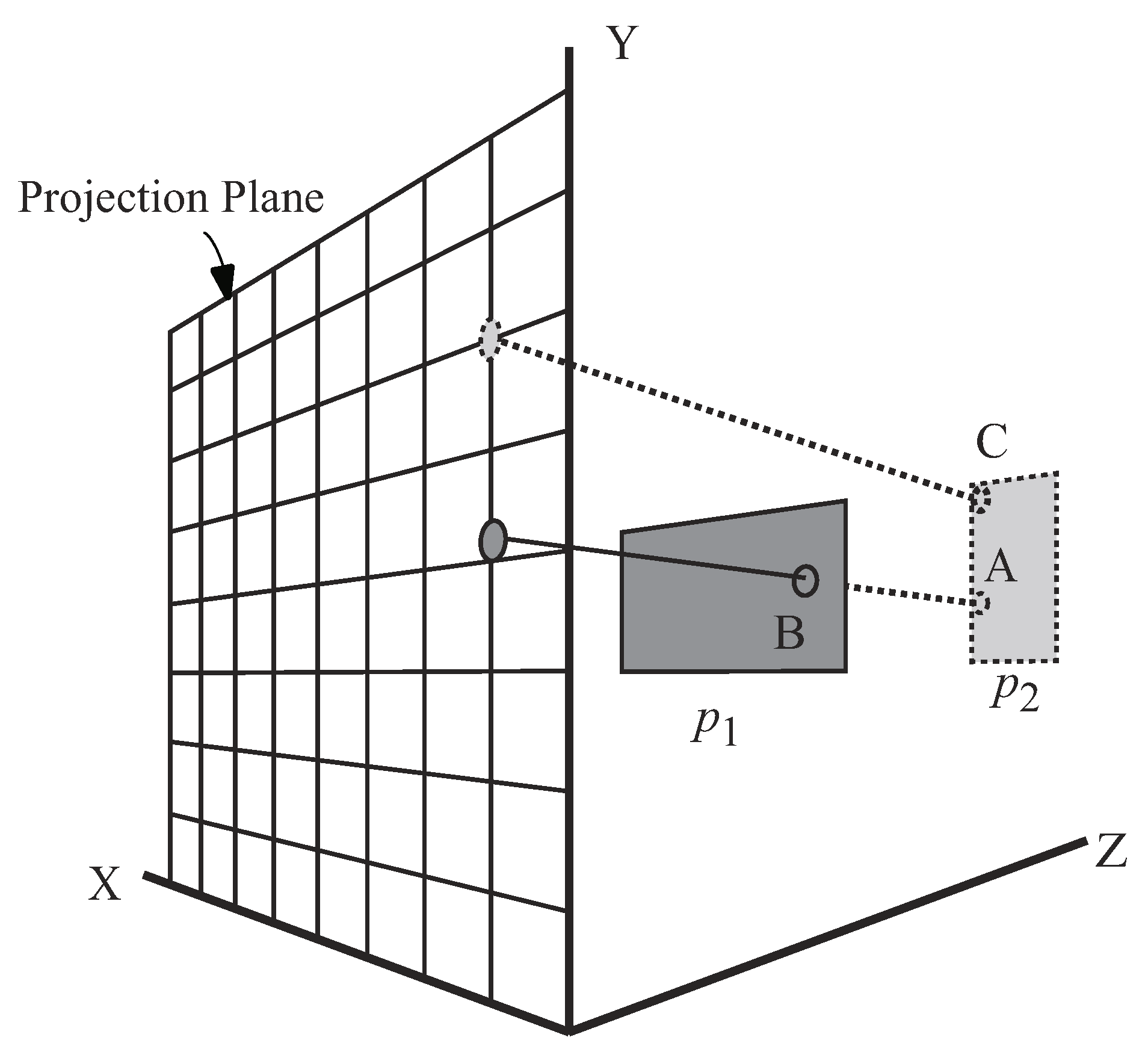
When rendering a data object, z-buffering scans each pixel of the data object and projects it on a projection plane that faces a query point. Thus, only the pixels on the projection plane are visible to the user. For instance, in Figure 4, Point A is not projected on the projection plane since it is hidden by Point B. However, Point C is visible to the user.
Our problem and image rendering are conceptually and functionally different. Our work aims to design efficient mechanisms for finding visible objects from a very large set of data objects. Thus, how to design the index that facilitates faster data retrieval and how to develop pruning strategies that reduce the search space are the main concerns of the work. One the other hand, the image-rendering algorithm assumes that the data objects inside the view field are known in advance. The main jobs of the image rendering are how to improve the result accuracy and how to reduce the memory consumption.
3. Preliminary
In this section, we define several terms that are used in the work. We also formulate the V2-kNN search and present our index scheme for the processing of V2-kNN queries. We summarize the symbols used in the following discussion in Table 1.
3.1. Problem Definition
In a two-dimensional Euclidean space, there are a set of data objects P = and a set of obstacles O = . In this paper, we assume each obstacle is a line segment. Although an obstacle o may be an arbitrary convex polygon (e.g., triangle), we assume o is a line to simplify our discussion. The proposed algorithms can work with o of an irregular shape by treating o as a set of line segments.
Definition 1.
Query point and its view field
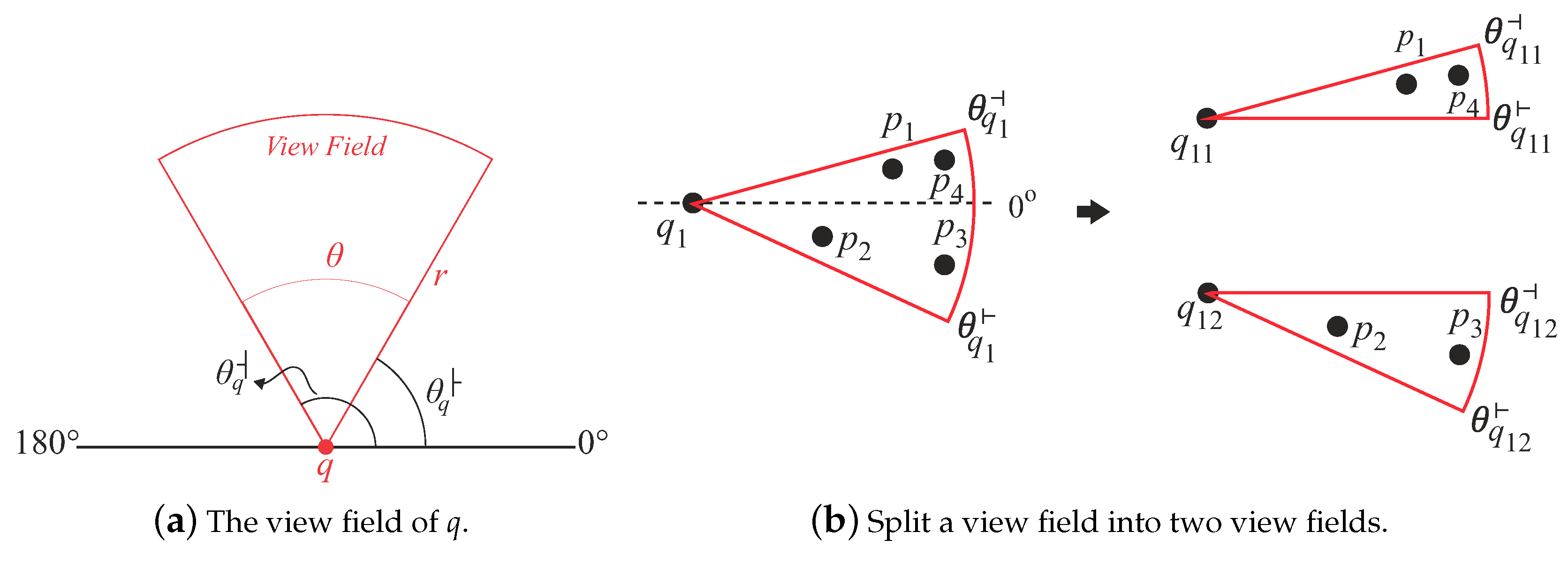
A query point q is represented as a triplet , where denotes the location of q, r denotes the maximum visible distance of a user, and θ is the view field angle of q. Note that is a combination of two angles and , where and are the values of the starting and ending angles based on the positive x-axis (see Figure 5a) (the definitions of starting and ending angles were adopted from [24]).
Also note that and must be in a continuous range between - , i.e., . If is bigger than , it must be a view field crossing from the first quadrant to the fourth quadrant of the coordinate space. For example, Figure 5b depicts a view field with = and = . In this case, we will separate this view field into two parts. In Figure 5b, is split into and where , , , and . When processing , our algorithm will separately evaluate and and then merge the results. Thus, in Figure 5b, our algorithm returns to the user after it merges the results of (i.e., ) and (i.e., ).
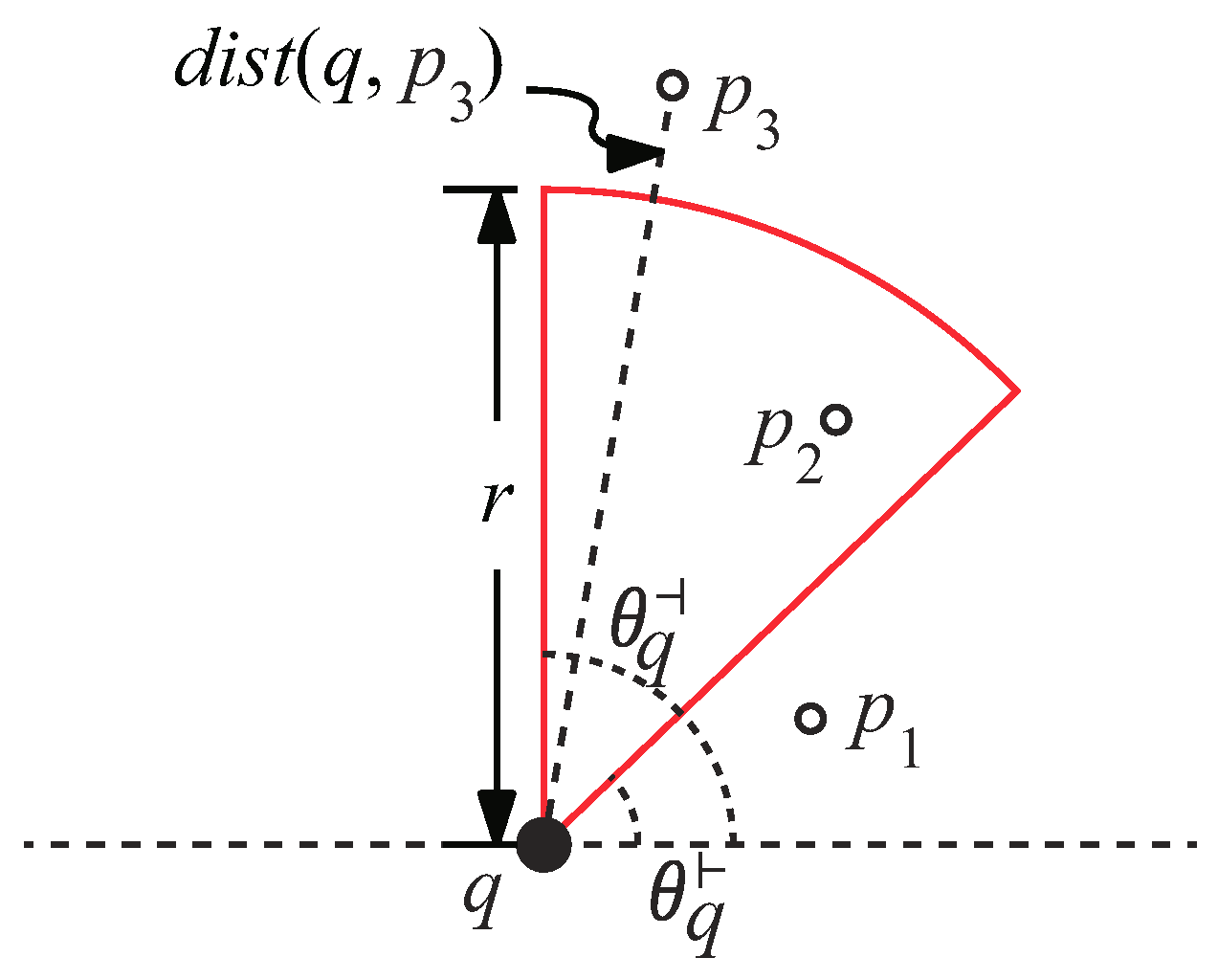
Now, we explain how to determine whether a data object or an obstacle is inside a view field or not. Given a data object p, we define to be the Euclidean distance between q and p and to be the angle between the positive x-axis and the vector . Then, p is inside q’s view field if (1) and (2) [24]. In Figure 6, is not inside the view field as . For , it is outside the view field because .
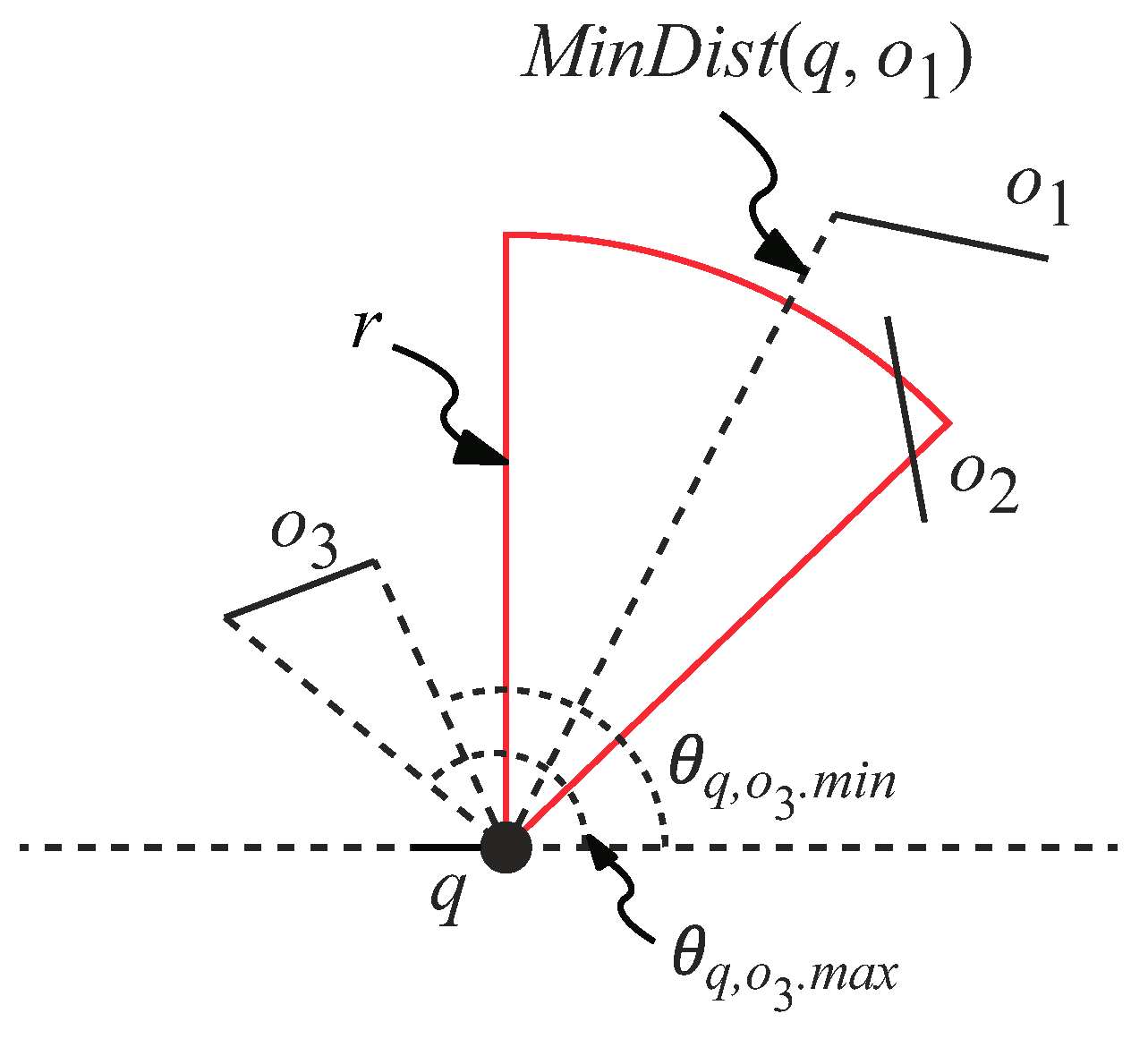
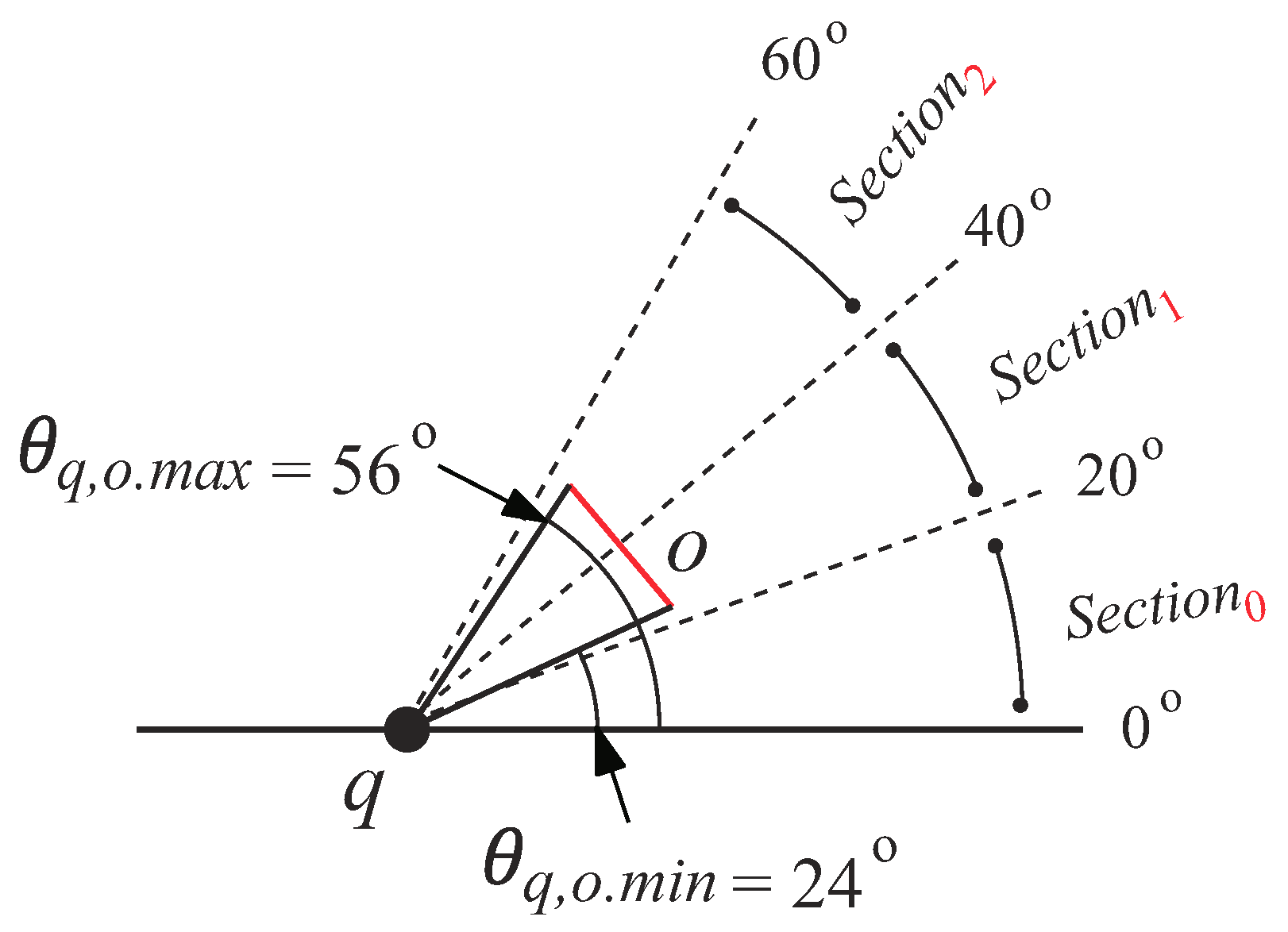
To explain how to evaluate whether an obstacle o is inside the view field, we first define some terms. We use (, ) to represent the angular bound of o’s line segment w.r.t. q, where denotes the minimum angle and denotes the maximum angle [31]. We also use (q, o) and (q, o) to denote the minimum and maximum distance between o and q, respectively. An illustration of , , (q, o), and (q, o) is shown in Figure 7.
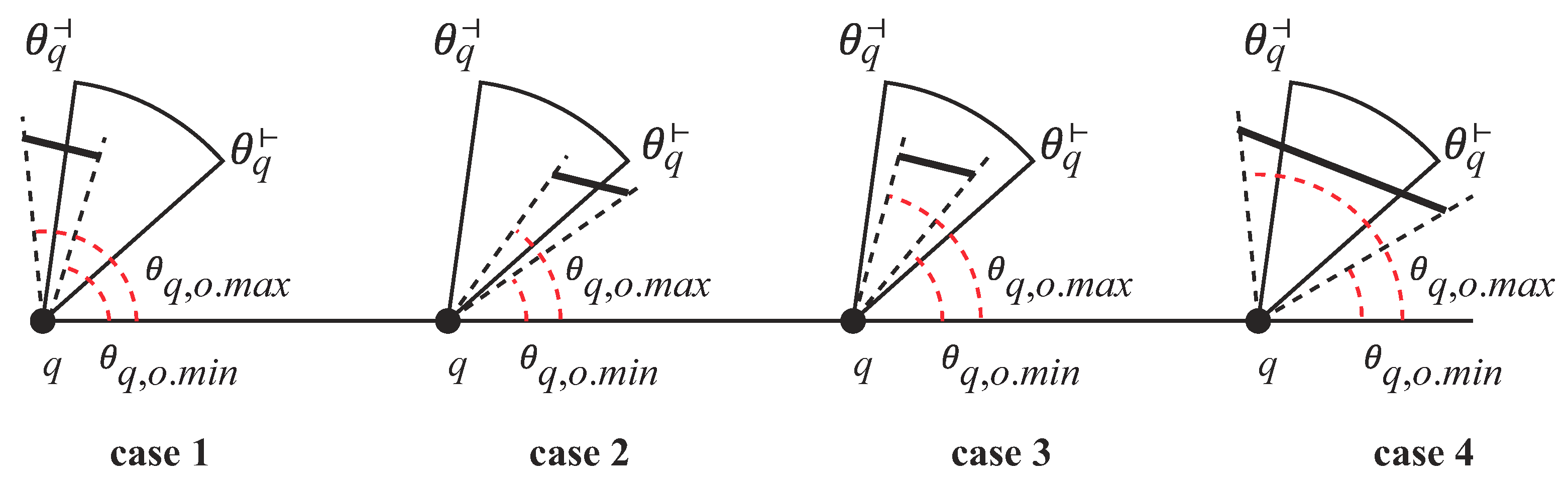
Given an obstacle o and a query object q, if o resides in q’s view field, then o satisfies (1) the minimum distance between q and o must be less than or equal to r (i.e., ), and (2) the relationship among , and meets one of the following conditions:
In Figure 9, is inside the view field (i.e., Case 4). On the other hand, is not in the view field because . is also outside the view field as and . Similar to the view field, the obstacle is split into two obstacles and if o crosses the first and the fourth quadrants in the coordinate space.
Now, we formally define the visibility of data objects.
Definition 2.
Visibility of data objects
Given a query , a set of data objects , and a set of obstacles , a data object is visible to q if all the following conditions are satisfied: (1) p is inside q’s view field. (2) There is no obstacle between the straight line connecting q and p (denoted as ).
In addition, to represent the distance between two objects, taking visibility into consideration, we define the visible distance as follows:
Definition 3.
Visible distance[20]
Given a query q and a data object p, if p is visible to q, the visible distance between q and p (denoted as ) is the minimum Euclidean distance between them (i.e., ). Otherwise, is set as infinite. That is,
After giving the definitions of the view field, visibility, and the visible distance, we can formally define our problem:
Definition 4.
View-Field-aware Visible k Nearest Neighbor (V2-kNN) search problem
Given a query , a set of data objects , and a set of obstacles , a view-field-aware visible k nearest neighbor query retrieves a subset of P, denoted by -, such that:
- -;
- -, p is visible to q;
- - and -, .
Figure 10 illustrates an example of - with , , and . We assume that k = 2. In Figure 10, we can find that the , , , are the candidate data objects that are in the view field of q. Although , are the closest objects compared to w.r.t to q, they are not visible to q. Therefore, they are not the solutions to -. The data objects meet all of the requirements in Definition 4 - = ordered by their distance w.r.t q.
3.2. Indexing Scheme
To enhance the query processing performance, we use a grid index to collect data objects and obstacles in the data space. We adopt the grid index as it is known as an efficient method [35] for spatial queries. Figure 11 illustrates an example of our index. We divide the data space using grid cells sized , where m is a system parameter that defines the cell size of the grid. Each cell stores the position information of data objects and obstacles inside it. For example, cell stores the position information of data object and obstacle . Note that, if an obstacle o is located in several cells at the same time (e.g., ), the position information of the obstacle must be stored in every cell with which it has an intersection. For example, the location information of is stored in and .
To check whether a view field covers a cell C, we first define the following three terms: , , and .
Definition 5.
Minimum distance between a query q and a cell C,
If query q is inside the cell, then is zero. Otherwise, the is the Euclidean distance between q and the closest edge of C.
Definition 6.
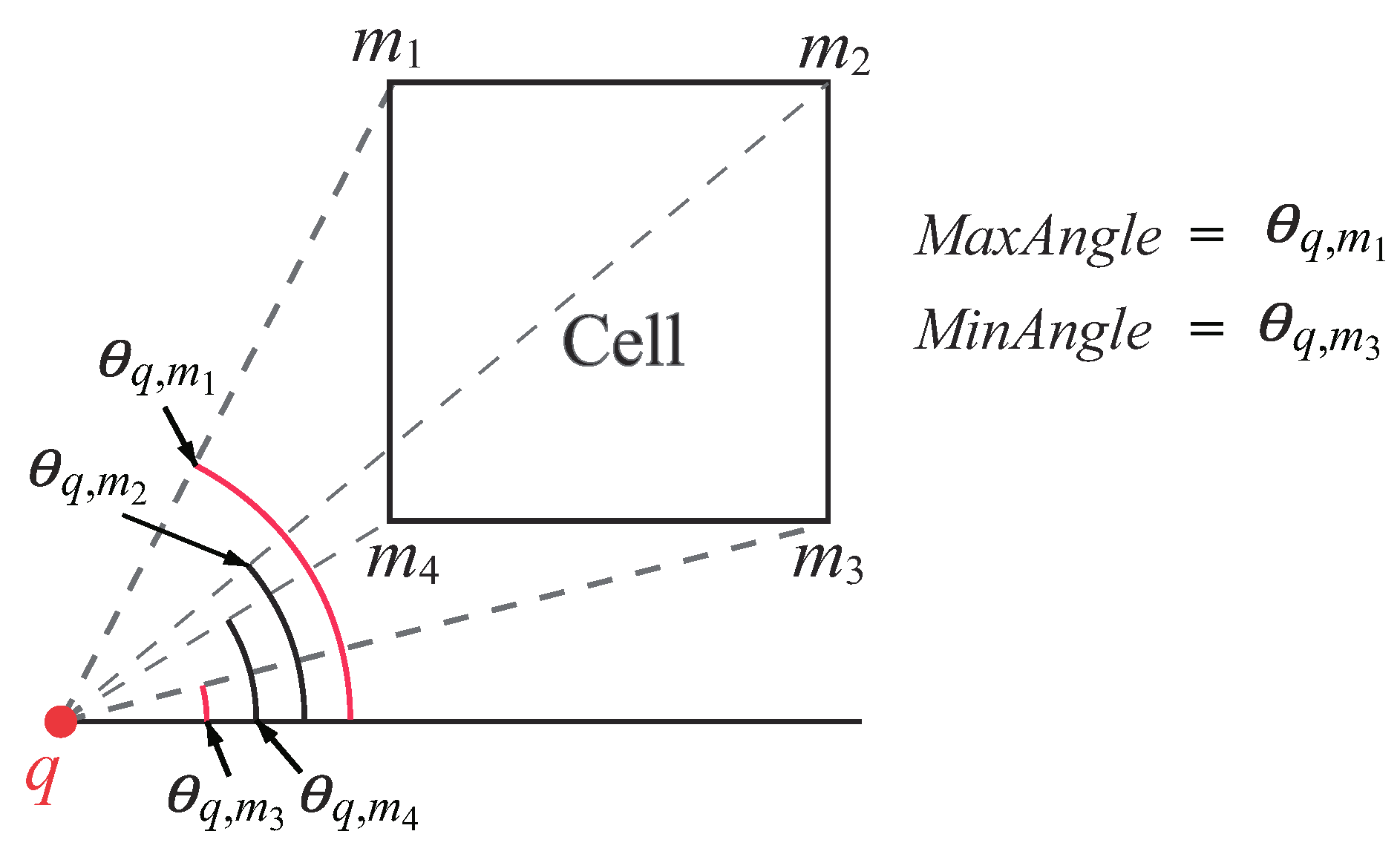
and [24]
Let be the four vertices of a cell C. We use to denote the angle between and the positive x-axis. The min angle and max angle between q and C are defined as follows:
- .
- .
Figure 12 shows an example of and .
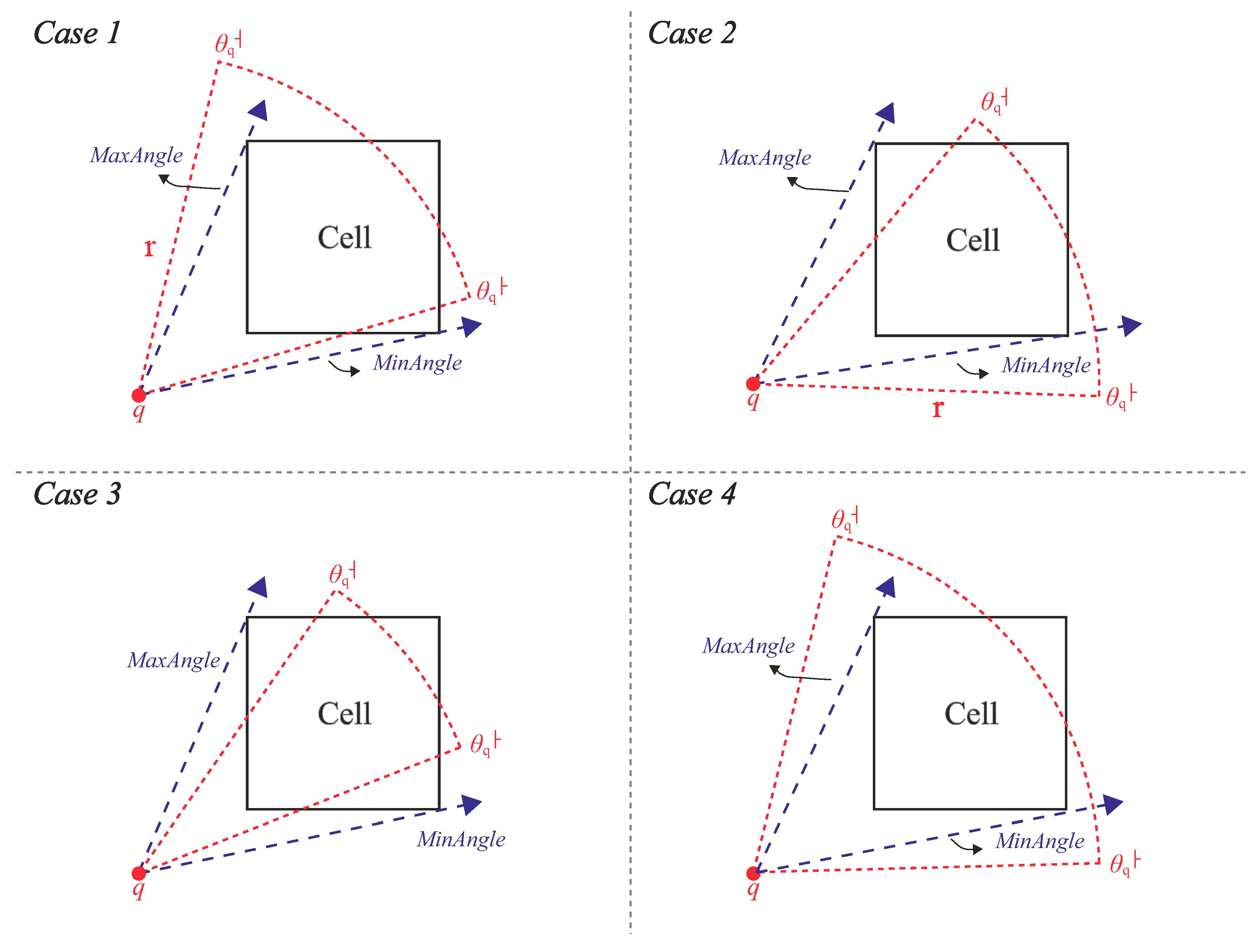
Given a query and a grid cell C, if q’s view field covers C, then (1) the minimum distance between q and C must be less than or equal to r (i.e., ) and (2) the relationship among , and must satisfy one of the following four cases [24]:
4. V2-kNN Query Processing
4.1. The Baseline Algorithm
Given a V2-kNN query , a set of data objects P, and a set of obstacles O, we assume P and O are indexed by the grid index proposed in Section 3.2. The intuitive approach to process q is to access all the cells covered by q’s view field. Then, we retrieve all the data objects and obstacles in the covering cells. Finally, we check the visibility of all the retrieved data objects and return the k visible nearest data objects to the user as the answer.
Our first algorithm, the baseline algorithm, is designed based on the aforementioned idea. The baseline algorithm is extended from the Fan-shaped Exploration algorithm [24], which is the most well-known and efficient algorithm that can retrieve nearest data objects in a view field. The difference between ours and the FE algorithm is that the FE algorithm does not consider the obstacles that exist in many real-life scenarios.
The overall procedure of the baseline algorithm is presented in Algorithm 1. The baseline algorithm first initializes two empty min-heaps H and , as well as an empty set . H sorts accessed cells according to their minimum possible distance to q (see Definition 5); maintains candidate data objects that may eventually become query results; and retains already accessed obstacles. The variable is defined as the visible distance of the kth visible data object of q, and it is set to ∞ at the beginning of the algorithm. Initially, the algorithm pushes the cells containing q into H (Lines 5–6). Each time, the algorithm pops out the top element of H and puts it in a variable (i.e., the current cell). Then, the baseline algorithm calls the VC algorithm (Visibility Check algorithm; see Algorithm 2) to check the visibility of data objects residing in . After that, the CAC algorithm (Check Adjacent Cells algorithm; see Algorithm 3) is called to insert four adjacent cells of into H.
| Algorithm 1. The baseline algorithm. |
 |
The VC algorithm (see Algorithm 2) first puts all the obstacles in into set (Lines 1–2). Then, it examines the visibility of each data object p in (Lines 4–9). If p is invisible to q, then we discard it. Otherwise, the VC algorithm pushes p into as it may become the final result (Line 11). In addition, the VC algorithm updates if there are more than k elements in (Line 12).
| Algorithm 2. Visibility Check (VC) algorithm. |
 |
| Algorithm 3. Check Adjacent Cells (CAC) algorithm. |
 |
Given a current cell , the CAC algorithm inserts each of ’s adjacent cells C into H if C satisfies the following conditions: (1) C is a non-visited cell (Line 2); (2) C overlaps with q’s view field (Line 3); and (3) the minimum possible distance between q and C is less than or equal to (line 4). Condition (3) indicates that the cell C may contain data objects with a distance smaller than . Thus, we should keep it for further examination.
The baseline algorithm terminates in two cases. Case 1: Heap H is empty (Line 7 of Algorithm 1). This means that the baseline algorithm has explored all the cells that overlap with the view field. Case 2: The current cell has (Line 9 of Algorithm 1); that is, all the data objects contained in the remaining cells in H whose distances to q are larger than . Therefore, they cannot become part of the final result.
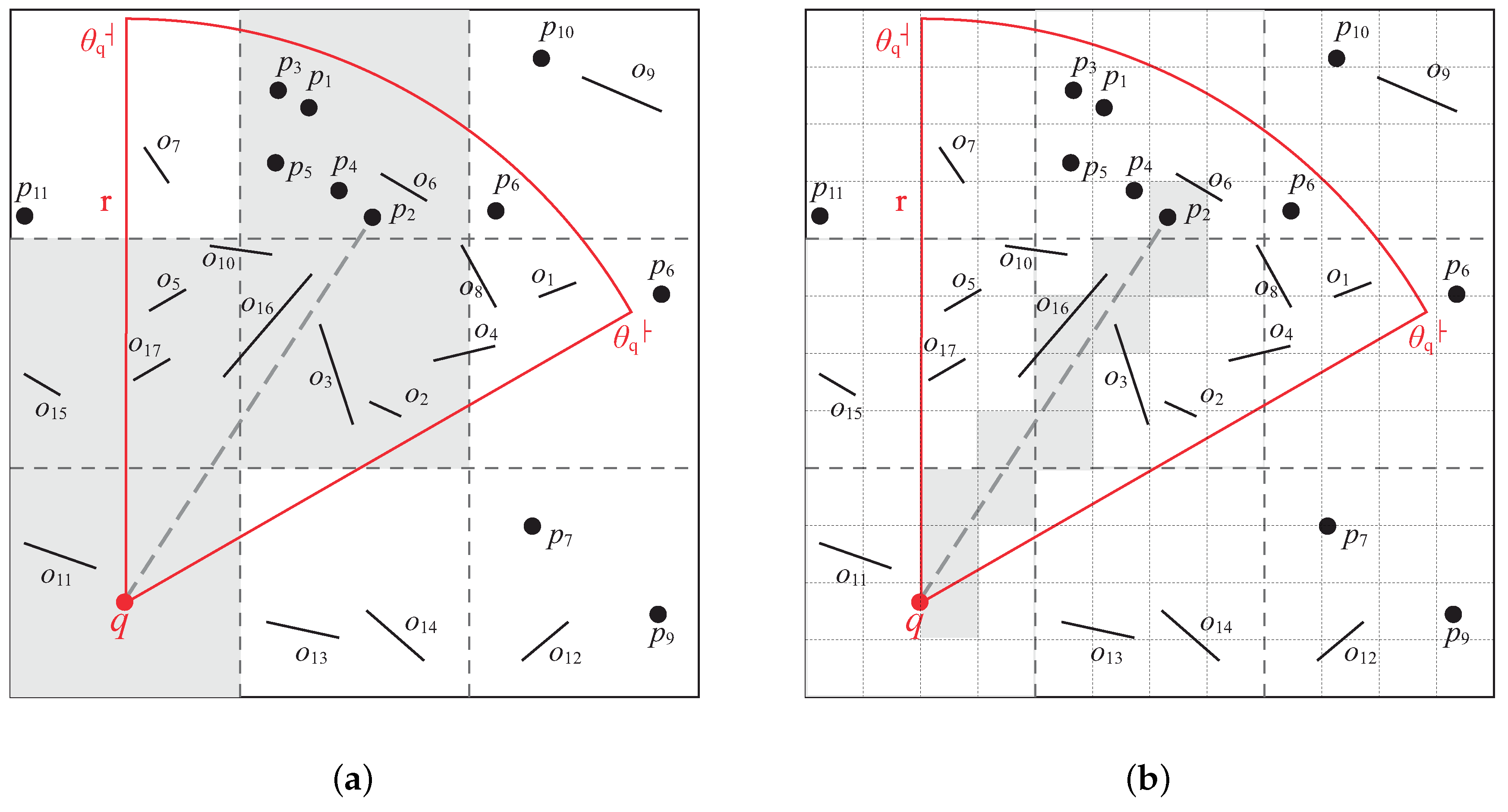
We use Figure 14 to explain how the baseline algorithm works. In this example, k is two. Table 2 shows the content of each data structure when the baseline algorithm is running. We start form the cell in which q is located (i.e., ). First, we call the VC algorithm (i.e., Algorithm 2) to check the visibility of data objects in . The VC algorithm first puts obstacle into as it falls in the view field. Then, the VC algorithm checks the visibility of by comparing with all the obstacles in . is discard as it is blocked by . After that, we call the CAC algorithm (i.e., Algorithm 3) to check ’s neighboring (i.e., above, below, left, right) cells to see if they overlap the view field of q. The CAC algorithm puts these overlapping cells (i.e., and ) into heap H. The second row of Table 2 shows the content of each data structure after visiting . Note that although and are the adjacent cells of , they are not put into H as they are outside the view field.
Then, we repeat the previous procedures to visit and . When visiting , we find the first visible data object and insert it into . The is still ∞ as , and we only find one candidate. Again, we repeat the same procedure to visit cells , , , and . After visiting , we find the second visible data object . We update as . At this time, we find that the top element of H is , and we observe that . This means that distances of all the unseen data objects (i.e., and in Figure 14) to q are larger than . Therefore, we can terminate the baseline algorithm.
4.2. The Influential Cells Algorithm
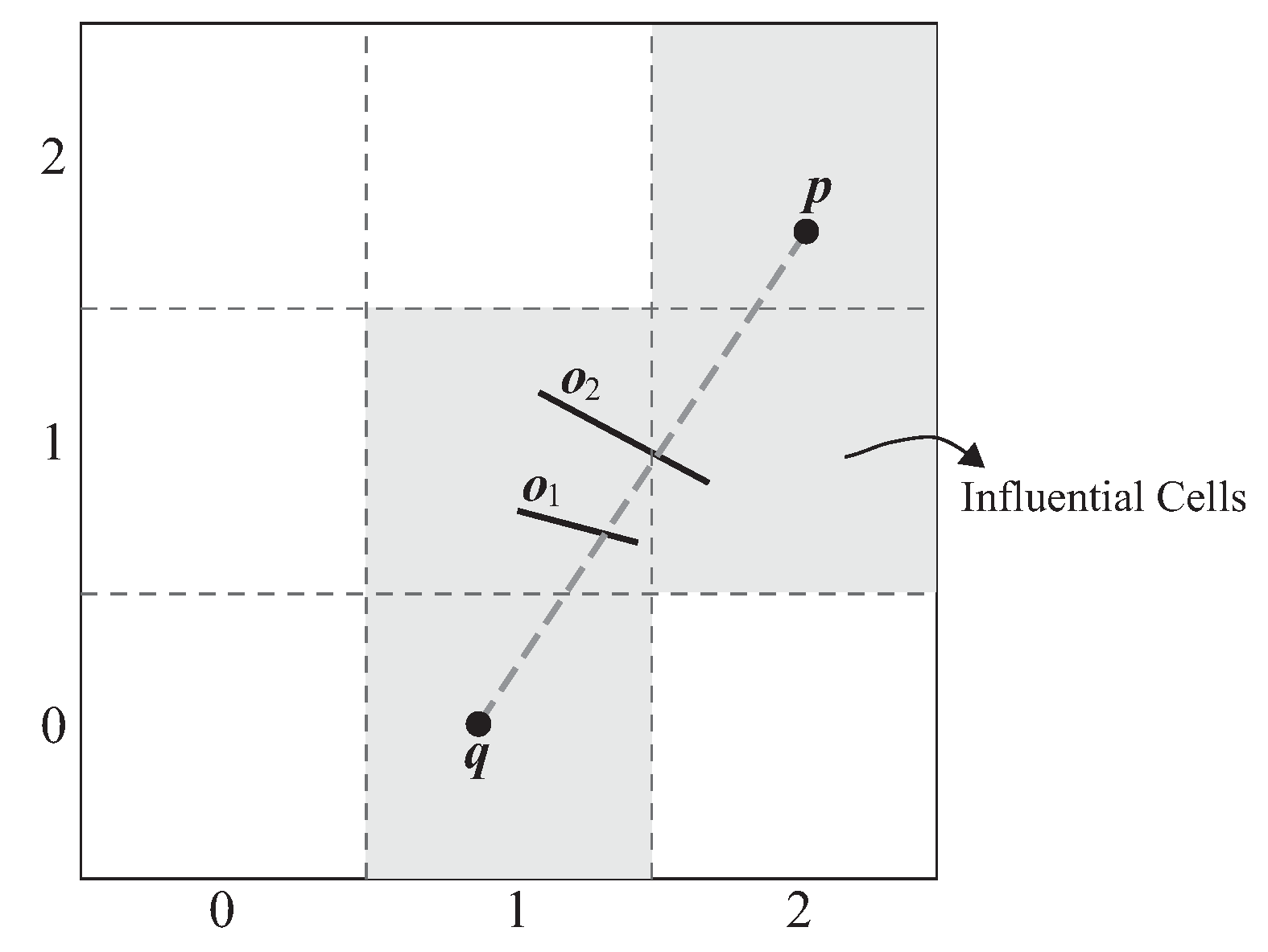
The baseline algorithm is simple in design and easy to implement. The main drawback of the baseline algorithm is that it requires the comparison between a data object p and all accessed obstacles when performing the visibility check. We take in Figure 14 as an example. To check whether is visible to q, the baseline algorithm lets be examined with seven obstacles (i.e., , , , , , , ). However, we find that the cells and have no intersection with the line segment . This means that all of the obstacles located in cells and (i.e., , and ), have no influence on the visibility of . Thus, it is unnecessary to examine with and when performing the visibility check.
Base on this observation, we design a new algorithm, named the influential cells algorithm, which can improve the performance of the baseline algorithm by reducing the number of obstacles to be checked when checking the visibility of a data object. Before we explain the design of the algorithm, we first introduce the notation of the influential cells.
Definition 7.
Influential cells
Given a query and a data object , the influential cells of (denoted as ) represent a set of cells that intersect with the line segment . That is, .
In Figure 15, given a data object p and a query q, the influential cells of p (i.e., ) are cells , and , which are highlighted in gray.
Theorem 1 tells us that we can improve the performance of the visibility check by ignoring those obstacles that are not inside the influential cells of a data object.
Theorem 1.
Given a query , a data object p, and a set of obstacles O, let be an obstacle that is not located in the influential cells of p (i.e., ), then it is impossible for o to affect the visibility of p.
Proof. (By contradiction)
Assume that o makes p invisible to q and p is not located in . Then, o must intersect with the line segment . Let o intersect with on a point x. We know that x must lie on the line segment . Thus, x is located in at least one of the influential cells of p, which contradicts the assumption that p is not located in . □
We extend the visibility check algorithm (i.e., Algorithm 2) to use Theorem 1 to enhance the performance. The pseudocode of the extended version is shown as follows Algorithm 4.
| Algorithm 4. Visibility Check Ver. 2 (VC2) algorithm (visibility check algorithm based on Theorem 1). |
 |
To find the influential cells of a given data object p, Algorithm 5 checks each cell C in to determine if C intersects with (Lines 3–4). Note that is a list containing cells that are visited by Algorithm 1.
| Algorithm 5. Find Influential Cells (FindIC) algorithm. |
 |
We use the same example in Figure 14 to show the process of Algorithm 4 (i.e., the VC2 algorithm). The result is shown in Table 3. The forth column illustrates the number of obstacles verified by the VC2 algorithm. Note that the underlined obstacles are ignored by the VC2 algorithm. For example, when checking the visibility of (see the seventh row), the VC algorithm examines six obstacles, while the VC2 algorithm only tests three obstacles. From the above example, we find that the idea of the influential cells reduces the number of obstacles, which are necessary to be checked, thus improving the efficiency of queries. Furthermore, as the view field becomes larger, the number of obstacles inside the view field also increases, leading to a higher computational cost for the visibility check. The idea of the influential cells can identify unqualified obstacles, which improves the performance of the search algorithm even when the view fields are large.
4.3. Direction Index
The idea of the influential cells can greatly reduce the number of obstacles to be checked by the baseline algorithm and thus enhance the search performance. However, there is room to further speedup the search performance. In this subsection, we will introduce the Direction Index () method, which builds an index to index the obstacles. When performing the visibility check, the DI method uses the index to further exclude the obstacles that cannot affect the visibility of the data object even if the obstacles are inside the influential cells. We first use an example to illustrate the concept of the direction index.
When checking the visibility of , in Figure 16a, the IC technique needs to examine nine obstacles (i.e., , , , , , , , , and ). However, we find that , , , , , and have no influence on the visibility of as they are “far from” the line segment . The search performance can be improved if we can exclude these obstacles from the visibility test. A question here is how can we identify those obstacles that are far from the line segment?
One solution is to adjust the size of the grid cell. Figure 16b illustrates a fine granularity grid. Compared with Figure 16a, we only need to check three obstacles (i.e., and ). However, the fine granularity reduces the number of checked obstacles, and it also leads to low search performance as the algorithm needs to access more grid cells. In addition, a fine granularity may make more obstacles be located in several cells at the same time. This means that there would be more repetitive obstacle data stored in each cell. The algorithm must increase the effort to retrieve and filter the repetitive obstacle data. Therefore, it is obvious that adjusting the size of the grid cell still cannot improve the efficiency of the overall execution effectively.
Another solution is to take the “direction of the obstacle” into consideration. More specifically, when checking the visibility of data objects, we can retrieve the obstacles that may influence the visibility of the data object based on therelative anglebetween query point and the obstacles. Based on this idea, we propose the Direction Index (DI) method.
4.3.1. The Design Rationale of the Direction Index
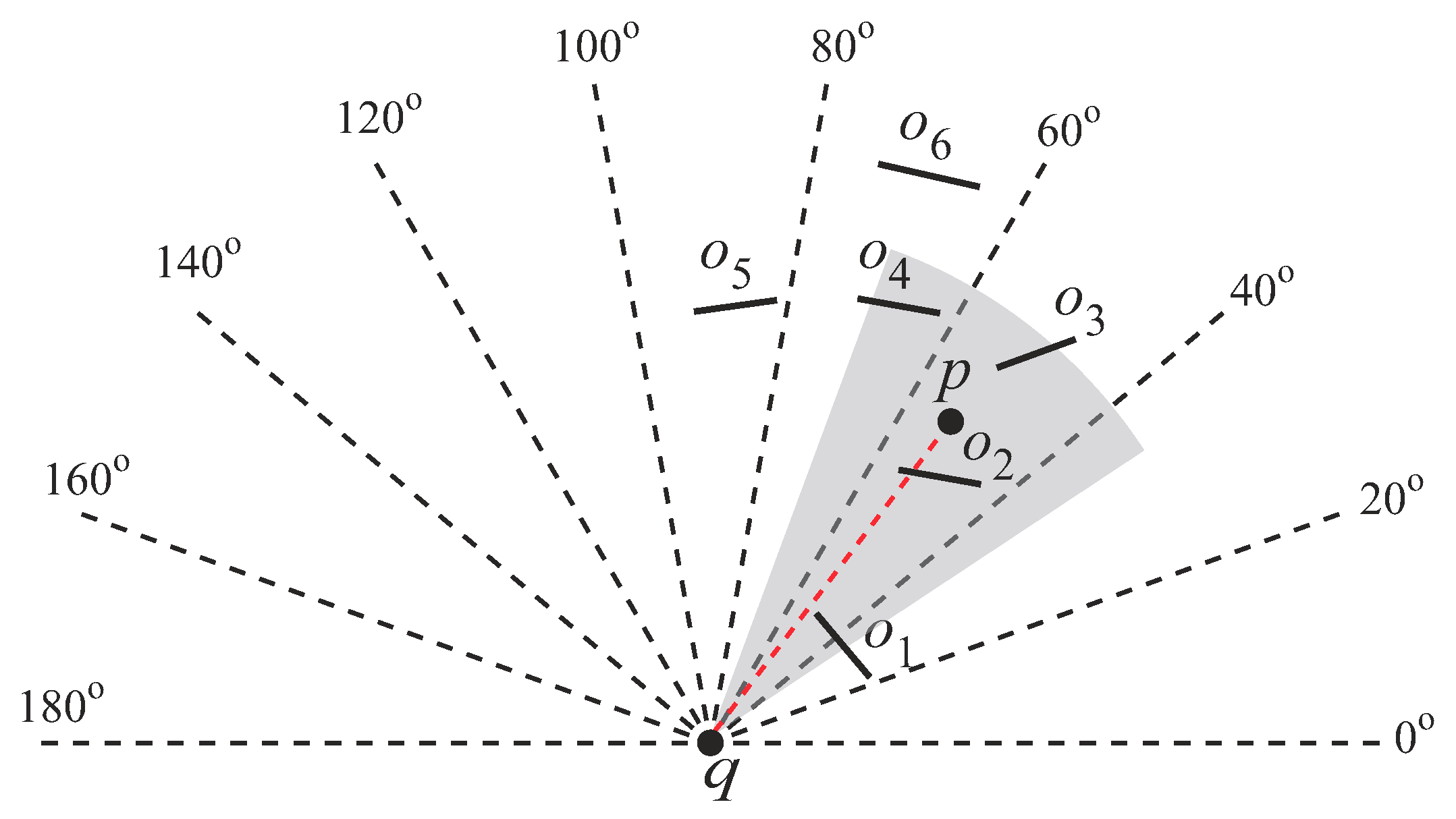
The main idea of the direction index is as follows. Given a splitting angle (which is a system parameter), we can split the 2D space into sections equally based on q. The ids of the sections are numbered − 1. The ith section, , represents the angle range . In Figure 17, is , and the 2D space is split into sections. represents ; represents , ⋯, and so on.
From Figure 17, we observe that all the obstacles that are not located in the section where p resides cannot affect the visibility of p. For example, and cannot influence the visibility of p as they do not reside in (i.e., the section where p resides). The observation can be validated by the following theorem.
Theorem 2.
Let p and o be a data object and an obstacle, respectively. p is located in , and o resides in , where . o cannot affect the visibility of p.
Proof.
The proof is omitted as it is trivial. □
Given an obstacle o and a query point q, we can derive the sections where o is located by using and ; that is, the sections where o is located ranging from to . We take Figure 18 as an example. and . Thus, o resides in and .
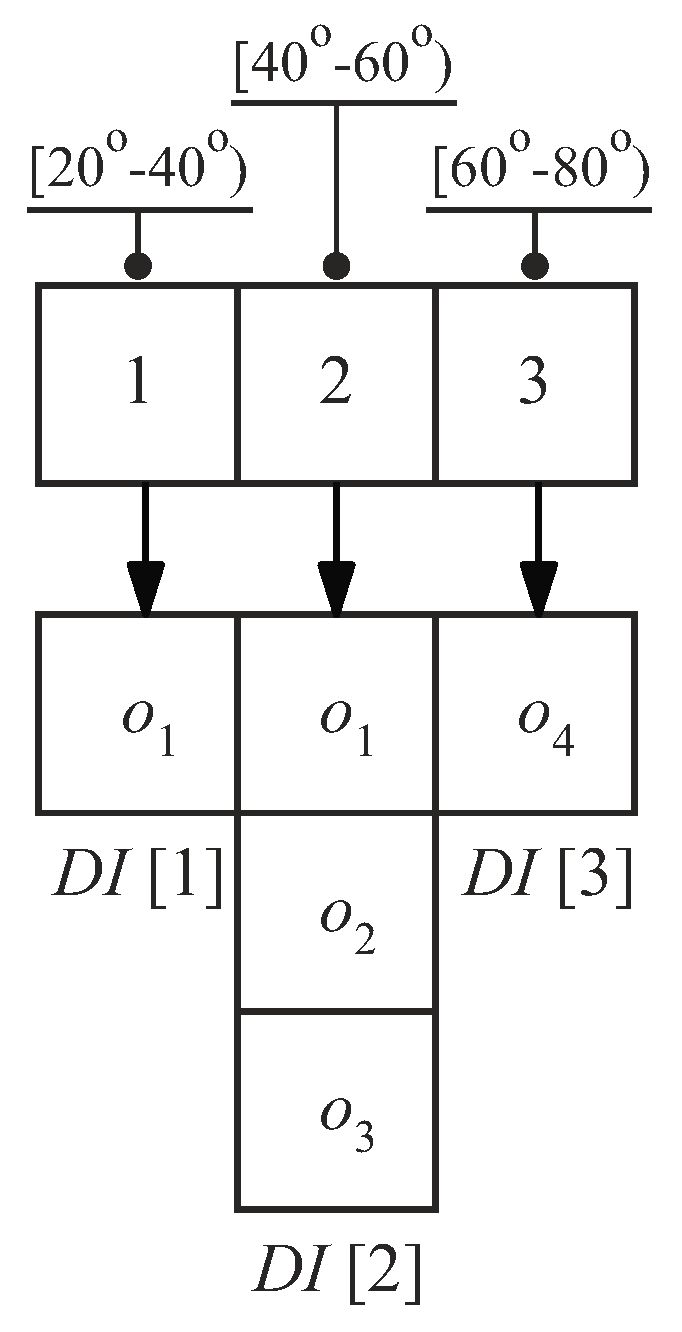
We use a hash table to record the obstacle information in every section. The hash table is named the Direction Index (). The section id is used as a hash key, and represents a hash value. is a queue that stores the obstacles (1) residing in and (2) located in the view field. The queue is sorted in ascending order based on the obstacle’s minimum distance (see Section 3.1) to the query point. Figure 19 shows the content of the for Figure 17. Note that only the obstacles residing in and are kept in as q’s view field overlaps with the three sections. Also note that since falls in and , we store in , as well as .
4.3.2. Using for Query Processing
We construct the direction index on-the-fly when processing a query q. Each time the Baseline algorithm visits a cell C, we retrieve the obstacles in C and insert them into a direction index (Line 3 in Algorithm 6). To check the visibility of a data object p, we first calculate the section id of the section where p resides (Line 6). Assume that the section id is , then we compare p with all the obstacles in . Note that the obstacle in with is greater than , which are discard as they cannot affect the visibility of p (Line 12). Thus, we can safely exclude them and save computational cost.
Algorithm 7 shows the details of inserting an obstacle into the direction index. Lines 1–2 calculate the section id(s). Then, we simply insert the obstacle into the corresponding slots of .
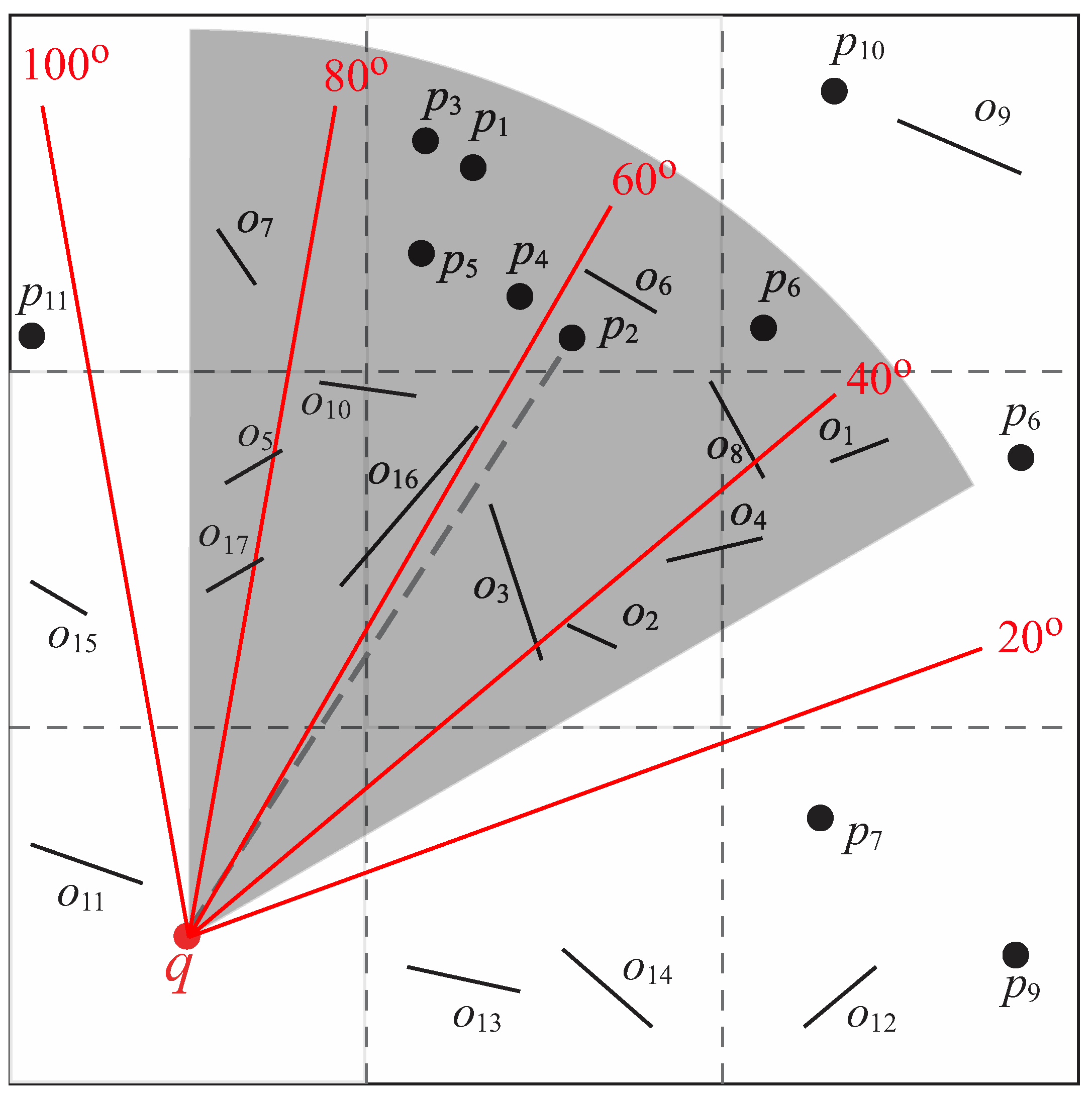
We use Figure 20 as an example to explain how the direction index works. In the example, k is one, is , and the gray area is the view field. Since falls in , we compare with all the obstacles in (i.e., ) to check its visibility. The obstacles in are (sorted according to the ). We find that is a visible nearest neighbor of q as and cannot block it. Note that the checking process is terminated when we meet as is greater than , and all the unchecked obstacles ordered after cannot affect ’s visibility.
In summary, the direction index can reduce unnecessary examinations of obstacles with a smaller value of , as it finds a more precise section, which may influence the visibility of data objects. However, a smaller means that more obstacles might be located in the different sections at the same time, increasing the storage overhead of the direction index. In the experiment section, we will find the suitable through simulations.
| Algorithm 6. Visibility Check ver. 3 (VC3) algorithm (visibility check algorithm based on Theorem 1). |
 |
| Algorithm 7. Insert an obstacle into a direction index (InsertToDI) algorithm. |
| GIVEN: The obstacle o, the direction index , and the splitting angle FIND: The direction index 1 ; 2 ; 3 for to do Push o into ; 4 return ; |
4.4. The Invisible Regions Lookup Buffer
4.4.1. Motivation
The DI method finds a more precise region that contains visible influential obstacles, improving the efficiency of the visibility check. However, there is still room for further improvement. We use the following example to explain it. In Figure 20, is blocked by . However, to check its visibility, the method not only compares with , but also examines with , , and . The same thing happens in the visibility checking of and . Obviously, the more obstacles we compare with, the higher processing time the visibility check algorithm consumes. Thus, if we can reduce the number of data-obstacle comparisons, then we can speed-up the process of V2-kNN queries.
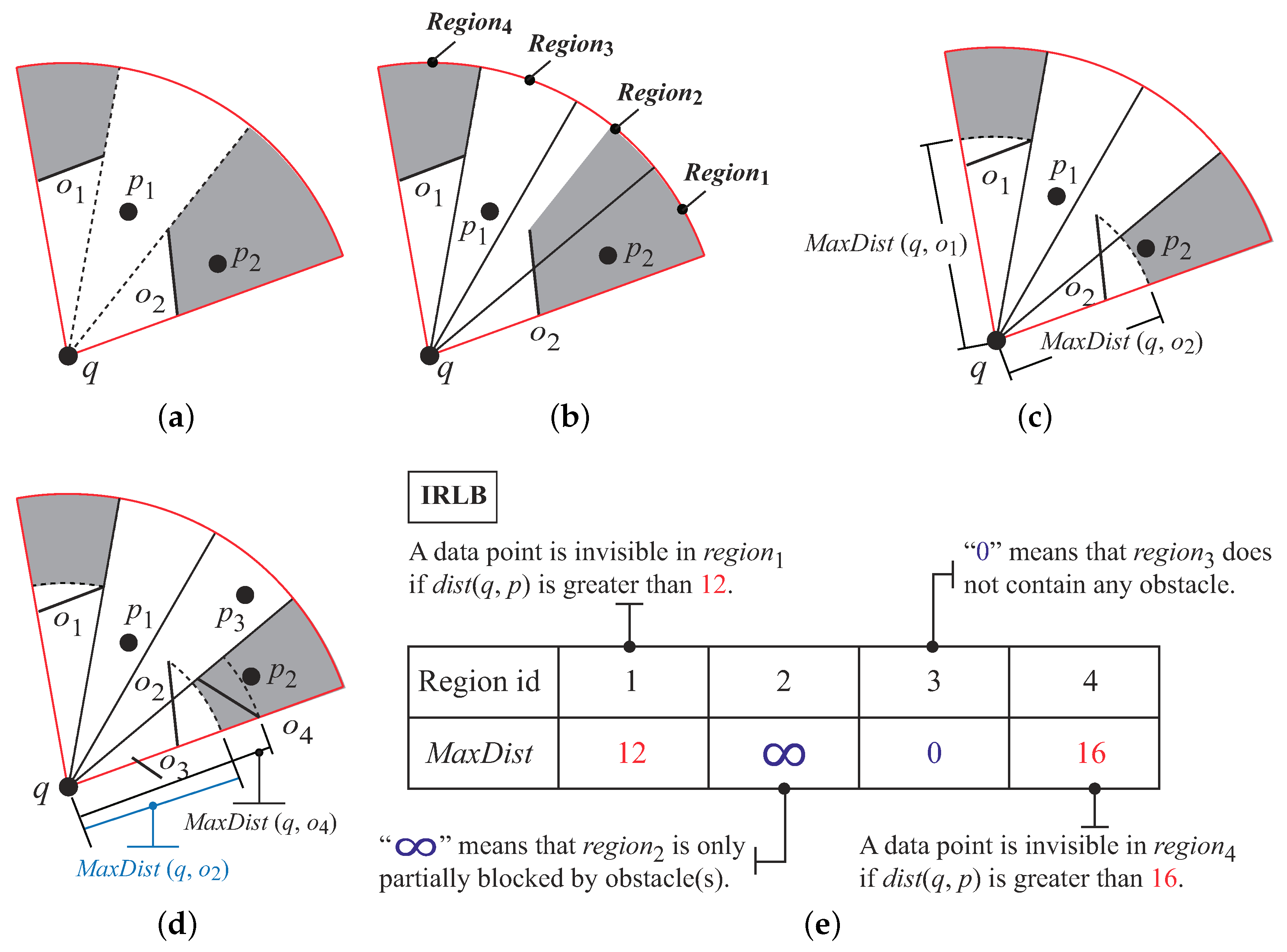
To achieve this goal, we propose an effective and light-weight data structure named Invisible Regions Lookup Buffer . The idea of is to keep the “invisible regions” in a hash table. An invisible region is an area blocked by an obstacle. If p falls in o’s invisible region, then p is blocked by o and is invisible to q. Figure 21a shows a view field and the invisible regions (i.e., the gray areas) made by the two obstacles and . Since resides in ’s invisible region, is an invisible data object.
When checking the visibility of a data object p, instead of comparing p with all the obstacles in the same section, we first lookup to examine if p is inside an invisible region. If yes, p is immediately discarded. Since the underlying data structure of is a hash table, the checking procedure is very fast (i.e., ). Thus, we improve the performance of the V2-kNN search.
The challenge in designing is that invisible regions are irregular shapes. The construction and storage costs of invisible regions are very high. In addition, testing if a data object is inside an invisible region is also time-consuming since we have to perform many geometric evaluations. To address this problem, we sacrifice the accuracy of invisible regions for faster computation. Our design rationale contains two strategies. We use the following figures to explain them.
First, we divide the view field into several small regions as Figure 21b shows. The advantage of the strategy is that we can classify the relationships between an obstacle and a region into three categories: (1) the region being “fully blocked” by obstacles (e.g., and ); (2) the region that is “partially blocked” by obstacles (e.g., ); and (3) the region that does not contain any obstacle (e.g., ).
The second strategy is to use the maximum distance between an obstacle o and the query q (i.e., ) to represent the invisible region made by o. The benefits of the strategy are two-fold. First, it reduces the storage cost of each invisible region. The reason is that for each invisible region, we only need to keep a float point variable (i.e., ) in the main memory. Second, the invisible region becomes a “regular” pie shape. For example, in Figure 21c, the invisible region made by in becomes a regular pie shape. Thus, checking if a data object falling in an invisible region becomes “a piece of cake” task as we only need to compare with .
Indeed, these strategies degrade the precision of the invisible regions. For example, the invisible region made by in Figure 21c is smaller than that in Figure 21b. Furthermore, we do not record the invisible region in as only partially blocks . However, the design can greatly enhance the performance of the visibility checking. Let us use Figure 21d to explain it. We have to compare with three obstacles (i.e., , and ) so as to check the visibility of in DI. On the other hand, by using , we only perform one operation (i.e., test whether ) and find that is invisible to q. This shows that our design can reduce the number of data-obstacle comparisons and thus enhance the performance of the visibility check. In the next section, we will introduce the details of .
4.4.2. The Construction of
As we did in , we use an IRLB slitting Angle to split the 2D data space into equal-sized regions. The region corresponds to angle range , where . Note that is a system parameter, and we set in practical implementations.
is a hash table to keep the information of invisible regions in each region. contains elements. Each element is a key-value pair. A key corresponds to the region id. The value for key i, denoted as , has three possible values:
- is zero if does not contain any obstacle. For example, in Figure 21d, does not contain any obstacle. Thus, is zero.
- If is fully blocked by a set of obstacles , then is the minimum value of all the maximum distances between a query point q and each obstacle . That is, . For the formal definition of a full block, please refer to Definition 8. For example, in Figure 21d, is fully blocked by . Thus, .
- is ∞ if is only partially blocked (see Definition 9) by some obstacles. In Figure 21d, is ∞ since is partially blocked by .
Definition 8.
(Fully blocked)
Given a query and a region with angle range , is fully blocked by the obstacle o if (1) and (2) and .
Definition 9.
(Partially blocked)
A region is partially blocked by an obstacle o if neither is fully blocked by o nor does contain any obstacle.
Algorithm 8 shows the pseudocode for inserting an obstacle into . Note that at the beginning, each element in is initialized to be zero (i.e., for ). Given an obstacle o, Lines 1–2 determine the ids of regions that are covered by o. For each region , if it is fully blocked by o, then we set to the minimum value of (Lines 4–6). Otherwise, is partially blocked by o, and is set to be ∞ (Lines 7–8).
Figure 21e shows the IRLB for Figure 21d. Since there are two obstacles (i.e., and ) fully blocking , . is ∞ as is partially blocked by . Since does not contain any obstacle, is zero. There is only one obstacle (i.e., ) fully blocking ; thus, .
| Algorithm 8. Insert an obstacle into an Invisible Regions Lookup Buffer (InsertToIRLB) algorithm. |
 |
4.4.3. DI with
In this section, we present a new V2-kNN search algorithm that leverages the and the DI method. The algorithm is a two-phase visible kNN search algorithm. In the first phase, we use to categorize a data object p quickly into one of two types: (1) p is a candidate data object or (2) p is an invisible one. In the second phase, only the candidate data objects are processed by the DI method to find the exact answer. Since is fast, we can quickly reduce the search space and thus improve the efficiency of the DI method. The pseudocode of our search algorithm is shown in Algorithm 9. Lines 1–4 initialize the data structures and . In Phase 1, given a data object p, we first calculate the region in which p is located (Line 7). Then, we use to determine the visibility of p quickly. We state the decision rules as follows.
- Case 1: is zero. This means that p falls in a region that does not contain any obstacle. Thus, p is visible to q (Line 9). For example, in Figure 21d is visible to q.
- Case 2: . In this case, p is blocked by at least one obstacle in . Thus, p is invisible to q and can be directly dropped (Line 10). For example, in (Figure 21d) is blocked by and . Therefore, is invisible to q.
- Case 3: If p does not belong to the above two cases, then we call DI to check p’s visibility (i.e., Lines 12–17). For the details of DI, please refer to Section 4.3.2. In Figure 21d, we cannot determine the visibility of by using . Thus, we pass to DI for further processing.
| Algorithm 9. Visibility Check Ver. 4 (VC4) Algorithm (visibility check algorithm based on DI and ). |
 |
The correctness of Algorithm 9 is guaranteed by Theorems 3 and 4.
Theorem 3.
Given a data object p inside a region , p is invisible to q if and . More precisely, if p is blocked by an obstacle o in , then is fully blocked by o and .
Proof.
o fully blocks . Since o is a “continuous” line segment, we can find a point x on o such that . If we can show that x lies on , then we prove that p is invisible to q. Fact 1: The cross product of . This means that q, x, and p are collinear. Fact 2: Since x lies on line segment o, . Furthermore, we know that . We have . Thus, x lies between q and p. From Fact 1 and Fact 2, we conclude that x lies on , and thus, p is blocked by o. □
Theorem 4.
If p is inside and does not contain any obstacle, then p is a visible data object.
Proof.
We prove it by contradiction. Assume that p is invisible to q. There must be an obstacle o that intersects with line segment on a point x. Since falls in , x also resides in . Thus, o must be in . □
4.4.4. Discussion
The effectiveness of greatly depends on . For example, in Figure 21d, if we use a smaller and split the data space with a finer granularity, then would fall in a region that is fully blocked by . Therefore, we can directly drop without invoking DI. In our experiment, we used , and we found that the visibility of over 99% of data objects was identified by . Only 1% of data objects required further processing.
Since the design of is very simple, its storage overhead is very small. In our simulation, the with required 46,080 bits KB. Compared with modern-day computer systems that usually have more than 8 GB main memory capacity, the storage overhead of is negligible.
5. Experimental Study
In this section, we evaluate and compare the performance of the algorithms we proposed through extensive experiments. We first introduce our experimental environment, varying parameters and the methods of performance evaluation, then giving detailed descriptions and analysis for each experiment.
5.1. Simulation Environments
All of the algorithms were implemented in Java, and the experiments were conducted on a Windows 10 desktop computer with Intel(R) Core(TM) i5-4460 CPU 3.20 GHz and 8 GB RAM. Both real and synthetic datasets were used in our experiments. To reflect the real-world situations of our problem with the existence of obstacles, we used a real dataset that is widely used in the research of visible nearest neighbor queries [4,18,20,30], containing 24,650 river distribution information data in Greece [36] as our obstacle sets, and each of them is represented by a bounding rectangle. We took the diagonals of the rectangles as the obstacles in our experiments, and the distribution is shown in Figure 22.
Two types of data objects were generated, the Gaussian and the Zipfian datasets. For the Gaussian dataset, the location of a data object was Gaussian distributed with mean equal to 1000 and variance equal to 2000. For the Zipfian distribution, the data objects were more dense around the center of the data space and became sparse quickly toward the outside. In the following experiments, we used “RG” to represent the simulation being based on the Real obstacle dataset and the Gaussian distributed dataset. Similarly, “RZ” indicates that the simulation was based on the Real obstacle dataset and the Zipfian dataset. In our experiments, the number of data objects was varied from 10 k–1000 k. All of the obstacles and data objects were mapped into a domain of size [0, 20,000] × [0, 20,000] and were indexed in grid cell partitions.
The locations of the query points were also generated by the Gaussian and the Zipfian distributions. When we generated a query point q, we uniformly selected a value from as the starting angle (i.e., , please refer to Section 3.1) of the view field. The view field angle and the maximum visible distance r were uniformly chosen from and [1, 10,000], respectively. We ran 100 queries for each experiment, and the average performance is reported. Table 4 summarizes the parameters used, where the “Default Value” column shows the default values.
We evaluated four algorithms in the experiments as listed below:
- Baseline: the straightforward method to process V2-kNN queries (see Section 4.1). The baseline algorithm is extended from the Fan-shaped Exploration (FE) algorithm [24]. We can understand the effectiveness of our design by comparing the performance of the EF algorithm and our technique proposed in the paper.
- Influential Cells algorithm (IC algorithm): the V2-kNN query processing method that leverages influential cells to decrease the search space (see Section 4.2).
- Direction Index algorithm (DI algorithm): this algorithm uses the direction index as the index of in-view-field obstacles. It reduces unnecessary obstacles to perform the visibility check and further improves the efficiency of the algorithm, with its direction and distance perspectives (see Section 4.3).
- Invisible Regions Lookup Buffer algorithm (IRLB algorithm): The algorithm uses an efficient data structure (i.e., IRLB) to index the invisible regions in the view field. Then, the algorithm uses IRLB to prune invisible objects in advance, further reducing the computations in the visibility check (see Section 4.4).
We measured the computational cost by recording the query processing time. To show the efficiency of our pruning technique, we also considered the number of accessed obstacles. The lower the number of accessed obstacles, the more effective the pruning method.
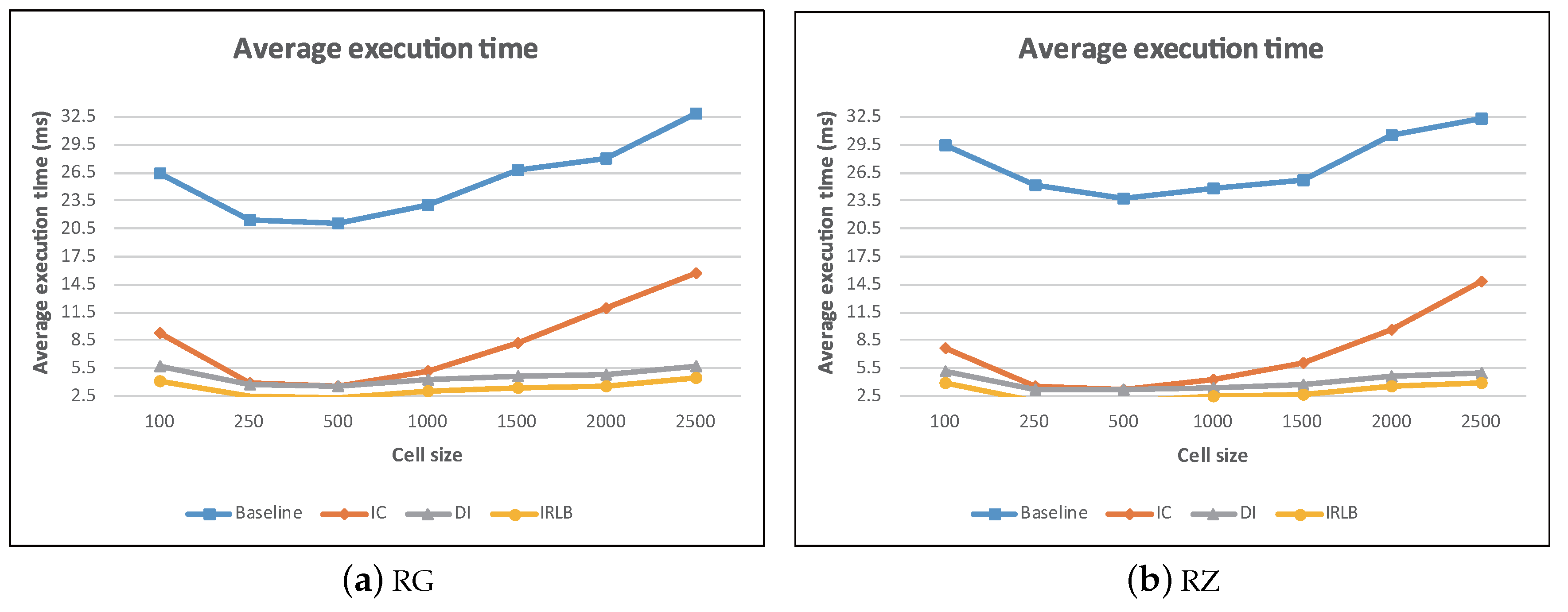
5.2. The Effect of Cell Granularity
In this experiment, we evaluated the performance of the proposed algorithms under various cell granularity settings. We varied the cell size m from 100–2500 and record the average execution time of each algorithm in Figure 23a,b. We observed that with a large m value (i.e., large cell size), each cell contained a large number of data objects and obstacles. All algorithms spent much effort to filter out irrelevant data objects and obstacles. This incurred excessive computational cost. On the other hand, with a small m value (i.e., small cell size), each cell contained a small number of data objects and obstacles. Although, this results in lower CPU time, where the visibility check is performed among a few data objects and obstacles. However, the algorithms needed to access more cells so as to find the query result. Thus, additional computational overhead was incurred.
From Figure 23, we also find that IC, DI, and IRLB greatly outperformed the baseline algorithm. This means that our proposed data pruning techniques can efficiently filter out unaffected data objects or obstacles and thus decrease the computational overhead of the visibility check.
Figure 23a,b also shows that the performance of IC was strongly dependent on the cell size. In our experiment, the efficiency of IC decreased substantially when the cell size became larger than 1000. The reason is that the IC algorithm finds influential cells when checking the visibility of the data object p. When the cell size becomes larger, each cell contains more obstacles. Therefore, in the larger size cell, IC had to check the visibility with more obstacles, making the efficiency of IC algorithm decrease when the cell size increased over 1000. On the other hand, the pruning techniques of DI and IRLB did not rely heavily on the grid size. Thus, DI and IRLB performed more stably than IC as m increased.
5.3. The Effect of Number of Data Objects ()
In this experiment, we studied the performance of all approaches against the data object cardinalities (: 10 k up to 1000 k). The result is depicted in Figure 24. We notice that all the algorithms incurred a longer execution time with the increase of . This is mainly because the algorithms had to perform more visibility checks as increased.
Among all the methods, Baseline performed the worst as it had to do exhaustive comparisons between each data object and all obstacles. Meanwhile, IC, DI, and IRLB outperformed baseline as they can avoid many comparisons. Finally, IRLB showed its superiority over others due to the following two reasons. First, the data were pruned efficiently by checking the invisible regions lookup buffer. We can avoid computational overhead for performing the visibility check. Second, IRLB can terminate the search early as soon as visible data objects are identified.
5.4. The Effect of Number of Obstacles
Figure 25a,b shows the performance results for all algorithms with the increase of the number of obstacles. In this experiment, we varied the number of obstacles by randomly sampling the 24,650 obstacles from rivers in Greece. Figure 25 shows that the average execution time of all the algorithms increased when increased. The main reason is that when increased, the number of in-view-field obstacles may increase as well. Therefore, the examined obstacles of all the algorithms increased while doing visibility checking of in-view-field objects, thus leading to increasing computational cost.
IC, DI, and IRLB performed better than baseline as they use obstacle pruning techniques to reduce the number of obstacles that need to be compared, resulting in effective visibility check. Also note that DI and IRLB outperformed IC. This shows that the direction-based filter can prune more irrelevant obstacles than the cell-based filter. Finally, IRLB leveraged the invisible regions lookup buffer to discard the invisible data objects from further examination, leading to faster query processing.
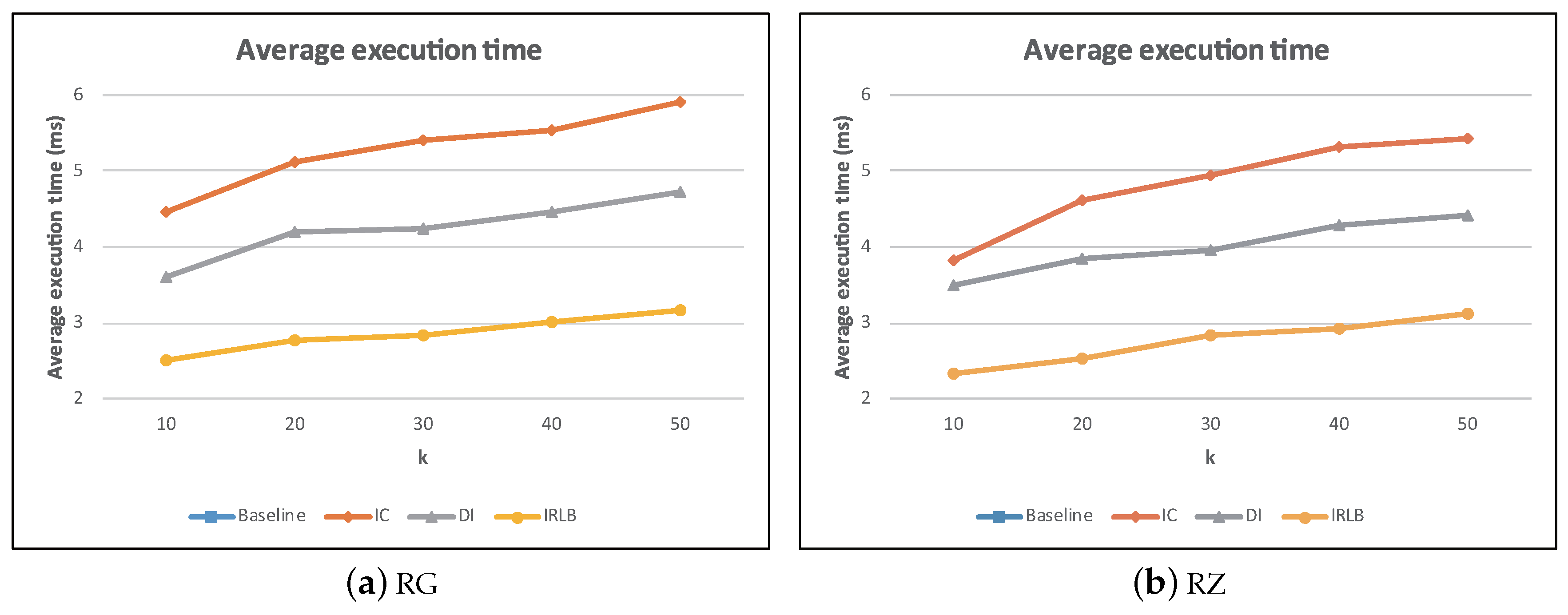
5.5. The Effect of k
This experiment was to study the influence of k for baseline, IC, DI, and IRLB, and the results are plotted in Figure 26a,b. Note that we did not draw the curves of baseline because the average execution time of baseline was too large. The average execution time of baseline is about 4.5-times and eight-times higher than that of IC and IRLB, respectively. As expected, the execution times of all algorithms increased as k grew. However, DI and IRLB remained superior over baseline and IC. While the average execution time of all the algorithms increased linearly as k increased, the rate of increase for DI and IRLB was slower. This is primarily because as k increased, the number of visibility checks also increased. Therefore, the direction-based pruning technique for DI and IRLB can efficiently decrease the number of obstacle comparisons when checking the visibility of a data object, leading to a low search time.
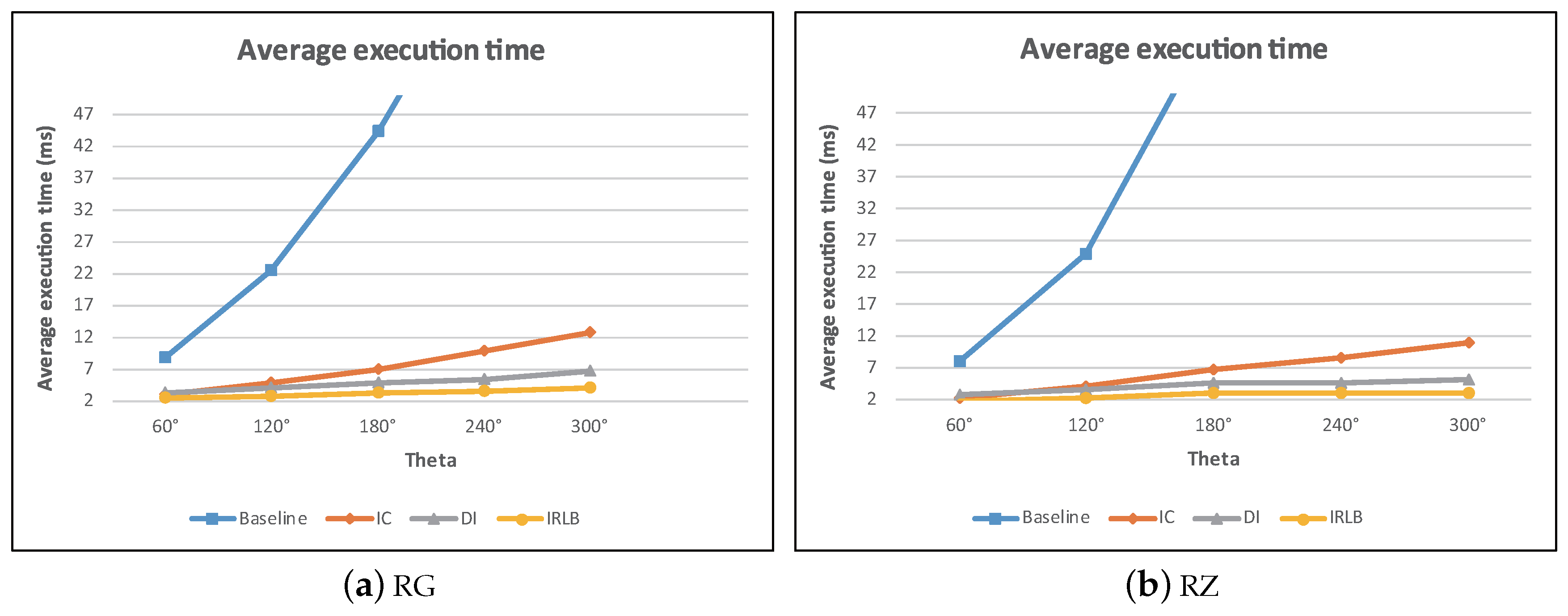
5.6. The Effect of r and
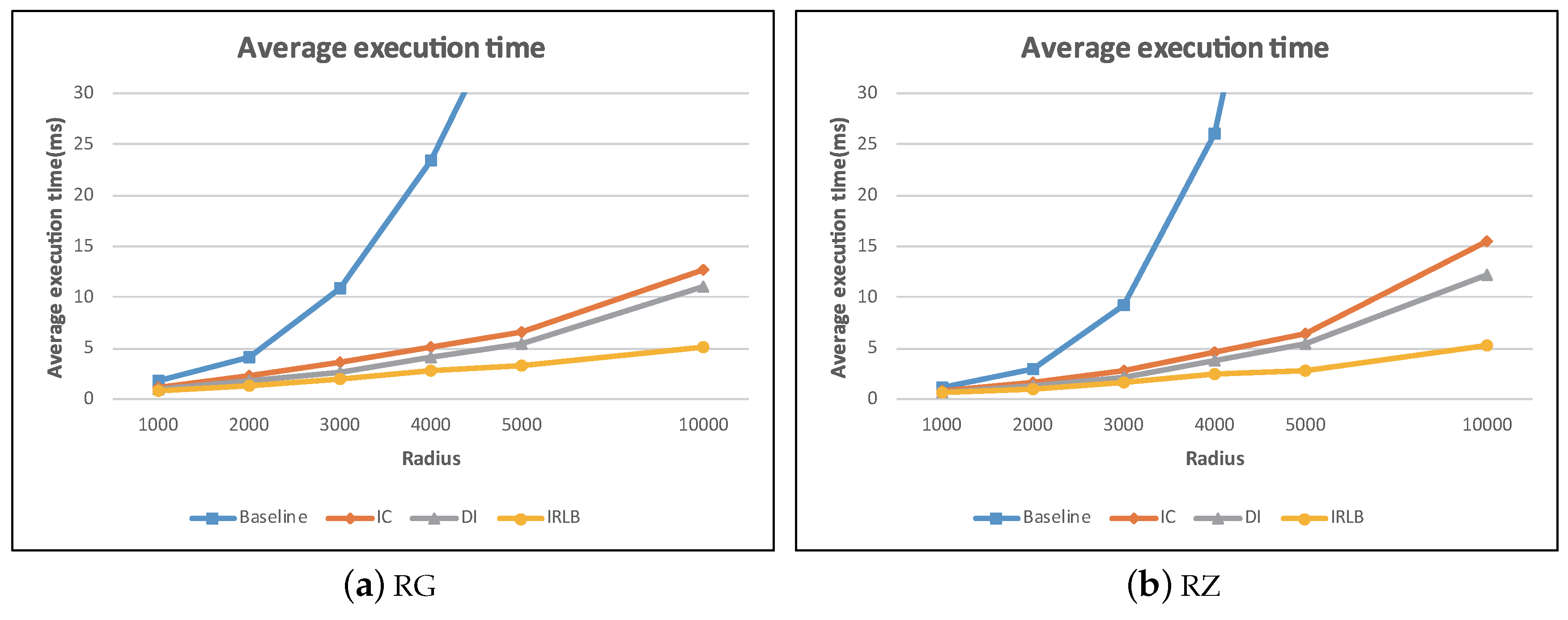
In the experiments, we analyzed how the performance was impacted by two parameters: r and . The two parameters control the covering area of a view field. The larger the value of r and , the more data objects and obstacles are covered by a view field. The results are reported in Figure 27 and Figure 28. The two figures show a very similar trend, that is the larger the size of a view field, the longer the query execution time. Once again, the results show that our pruning techniques can discard many unqualified obstacles so that IC, DI, and IRLB provide acceptable performance even when the view field is large.
5.7. The Effect of the Splitting Angle
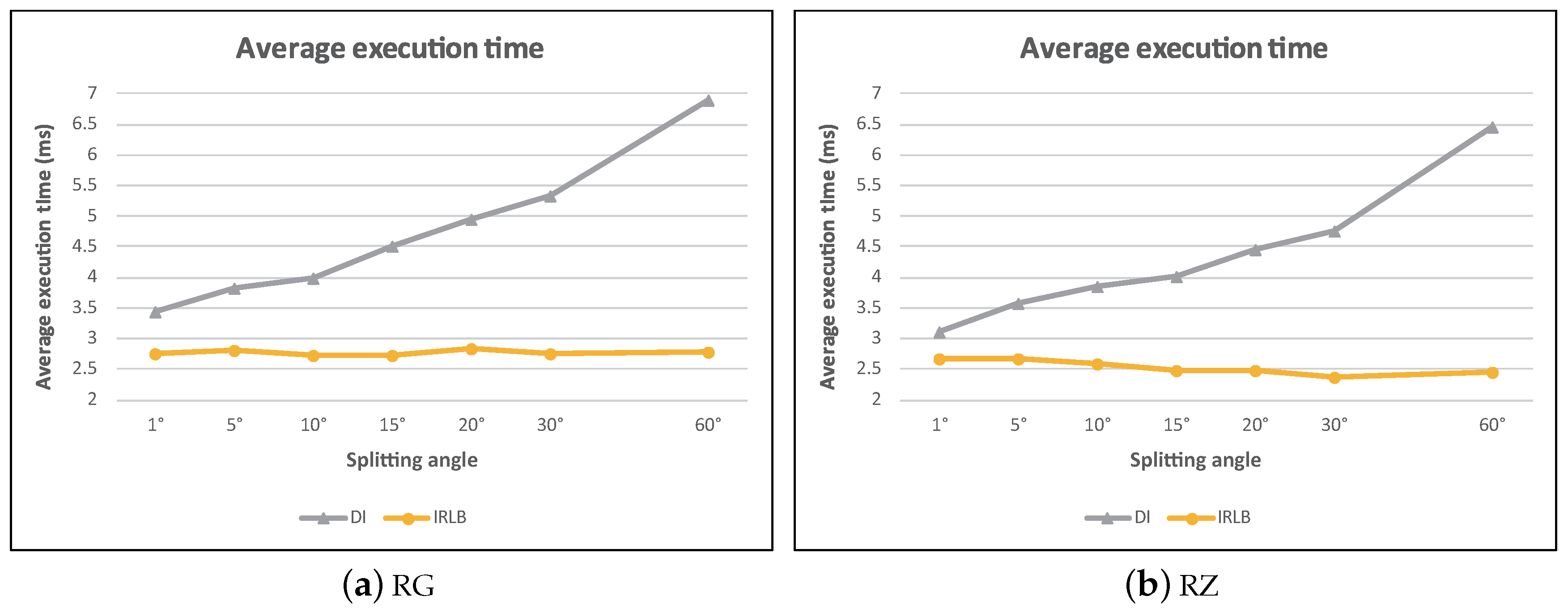
In this experiment, we investigated the effect of , which determines the direction index’s angle range of each section. Since parameter only affected the performance of DI and IRLB, we omit the simulation results of baseline and IC. By observing Figure 29, we find that the average execution time of DI increased rapidly when increased. This is because the larger value of means that a section would cover a wider spatial region, and more obstacles would be contained in a section. Thus, DI had to spend more time to check the visibility of data objects, incurring excessive computational cost.
Although IRLB is based on DI, it uses invisible regions lookup table to perform a two-phase search scheme (see Section 4.4.3). Since the visibility of a large number of data objects is determined by the lookup table (i.e., in phase one), only a few data objects are passed to DI for further processing. This makes IRLB much less sensitive to the increases of .
5.8. The Effect of the Slitting Angle
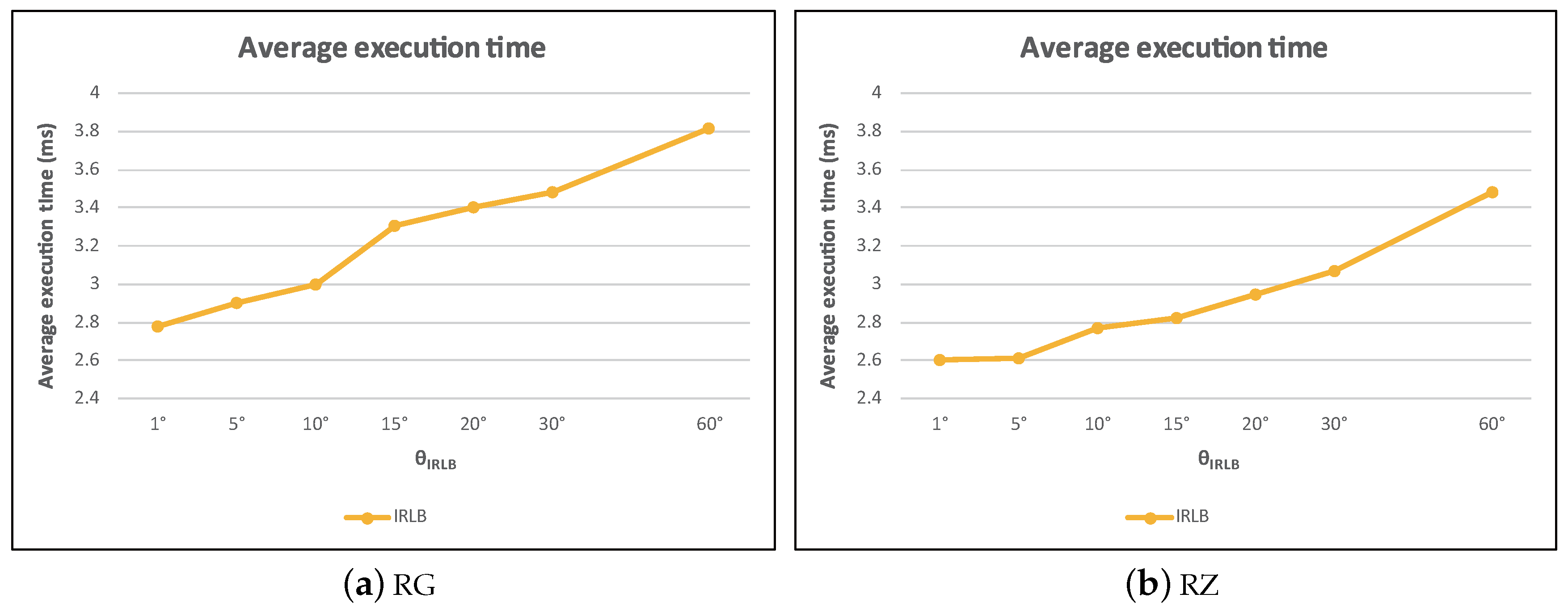
Continuing with the previous experiment, with a fixed value of = , we keep investigating the effect of . Since is only related to IRLB, we only plot the performance of IRLB in Figure 30. We find that the average execution time of IRLB increased as increased. This is mainly because as became larger, the probability that a region was fully blocked by obstacles became lower. This means that less data objects can be pruned in advance and have to be further examined by DI. With the computational cost of visibility checking increasing, the execution efficiency of IRLB became less effective.
6. Conclusions and Future Work
In this paper, we proposed algorithms for processing V2-kNN queries, which retrieve k visible data objects in the presence of obstacles within user’s view field. Two factors affect the visibility of data objects: (1) the view field and (2) physical obstacles (e.g., buildings, or hills). This paper represents a first attempt at considering both factors in finding the solutions. To make V2-kNN more efficient, we utilized a grid index structure to index data objects and obstacles. Based on the index, we designed four algorithms (i.e., baseline, IC, DI, and IRLB) to process V2-kNN queries. Baseline is the basis for the remaining three algorithms. Baseline uses the grid index to access only cells that overlap with the view field. The core idea of the baseline algorithm is to visit cells from near to the distant according to their distance to q. Without having any pruning heuristics, this algorithm resulted in a quite high execution cost. The IC algorithm extends the baseline algorithm by exploiting the fact that obstacles affecting the visibility of p can only exist in the cells intersecting with (i.e., the line segment connecting q and p). Thus, IC only checks the cells overlapping . This strategy greatly reduced the number of accessed obstacles, leading to a much more acceptable performance. In the DI algorithm, we devised the “direction index” to index the obstacles within a view field. Based on the direction index, we proved that for p, only obstacles falling within a certain angle may affect the visibility of p (this angle is relative to q). In IRLB, we designed a light-weight data structure to index the invisible areas in the view field. Data objects that fall in the invisible areas cannot be the answer. We used the index structure to discard those invisible data objects quickly when processing a V2-kNN query. Consequently, only a small number of data objects required further processing. Our experiments have demonstrated that all proposed algorithms can achieve our goal, that is finding visible kNN objects in the presence of obstacles within a user’s view field. The results also showed that IC, DI, and IRLB were better than baseline. This proves that the pruning strategies indeed significantly reduced the number of accessed obstacles and data objects. In addition, IRLB performed the best among all the algorithms, manifesting that the angle-based pruning strategy and the two-phase searching scheme were effective, as expected, in cutting down the size of the search space.
This work opens several promising directions. First, the Euclidean distance can be extended to the road network distance, which will require our algorithm to be redesigned to meet the need of road-network applications. Second, it would be interesting to take the dynamic environment into consideration, meaning that data objects and the query point may move and change their direction of movement. Third, as the obstacles are irregular in shape in the real world, we will investigate an efficient approach to check the visibility of objects under such conditions to make the solutions better meet the needs of real life.
Author Contributions
Conceptualization and methodology, Yu-Chi Chung, I-Fang Su, and Ding-Li Chen; validation and investigation, Chiang Lee and Ding-Li Chen; formal analysis, Yu-Chi Chung and I-Fang Su; data curation and writing-original draft preparation, I-Fang Su and Ding-Li Chen; writing-review and editing, Yu-Chi Chung and Chiang Le.; visualization, Yu-Chi Chung and Ding-Li Chen; project administration, Yu-Chi Chung and I-Fang Su; funding acquision, Yu-Chi Chung.
Funding
This research was funded by Ministry of Science and Technology of Taiwan (R.O.C.) under grants MOST 107-2119-M-309-001 -.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sharifzadeh, M.; Shahabi, C. VoR-Tree: R-trees with Voronoi Diagrams for Efficient Processing of Spatial Nearest Neighbor Queries. In Proceedings of the VLDB Endowment, Singapore, 13–17 September 2010. [Google Scholar]
- Bohm, C.; Ooi, B.C.; Plant, C.; Yan, Y. Efficiently Processing Continuous k-NN Queries on Data Streams. In Proceedings of the International Conference on Data Engineering (ICDE), Istanbul, Turkey, 15–20 April 2007; pp. 156–165. [Google Scholar]
- Field of View. Available online: https://en.wikipedia.org/wiki/Field_of_view (accessed on 20 March 2019).
- Gao, Y.; Zheng, B.; Chen, G.; Li, Q.; Guo, X. Continuous visible nearest neighbor query processing in spatial databases. Int. J. Very Large Data Bases (VLDB) 2011, 20, 371–396. [Google Scholar] [CrossRef]
- Chung, Y.C.; Su, I.F.; Lee, C.; Chen, D.L. Finding Visible kNN Objects with the View Field Constraint. In Proceedings of the First International Cognitive Cities Conference (IC3 2018), Okinawa, Japan, 7–9 August 2018. [Google Scholar]
- Cui, B.; Ooi, B.C.; Su, J.; Tan, K.L. Indexing High-Dimensional Data for Efficient In-Memory Similarity Search. IEEE Trans. Knowl. Data Eng. 2005, 17, 339–353. [Google Scholar]
- Hjaltason, G.R.; Samet, H. Distance Browsing in Spatial Databases. ACM Trans. Database Syst. (TODS) 2010, 24, 265–318. [Google Scholar] [CrossRef]
- Kolahdouzan, M.; Shahabi, C. Voronoi-Based K Nearest Neighbor Search for Spatial Network Databases. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; pp. 840–851. [Google Scholar]
- Korn, F.; Sidiropoulos, N.; Faloutsos, C.; Siegel, E.; Protopapas, Z. Fast Nearest Neighbor Search in Medical Image Databases. In Proceedings of the 22nd International Conference on VLDB, Mumbai, India, 3–6 September 1996; pp. 215–226. [Google Scholar]
- Lu, H.; Ooi, B.C.; Shen, H.T.; Xue, X. Hierarchical Indexing Structure for Efficient Similarity Search in Video Retrieval. IEEE Trans. Knowl. Data Eng. 2006, 18, 1544–1559. [Google Scholar] [Green Version]
- Mouratidis, K.; Papadias, D. Continuous Nearest Neighbor Queries over Sliding Windows. IEEE Trans. Knowl. Data Eng. 2007, 19, 789–803. [Google Scholar] [CrossRef] [Green Version]
- Seidl, T.; Kriegel, H.P. Efficient User-adaptable Similarity Search in Large Multimedia Database. In Proceedings of the 23rd International Conference on Very Large Data Bases, Athens, Greece, 25–29 August 1997; pp. 506–515. [Google Scholar]
- Zhang, J.; Zhu, M.; Papadias, D.; Tao, Y.; Lee, D.L. Location-based Spatial Queries. In Proceedings of the ACM SIGMOD International Conference on Management of Data, San Diego, CA, USA, 9–12 June 2003; pp. 443–454. [Google Scholar]
- Nutanong, S.; Tanin, E.; Zhang, R. Visible nearest neighbor queries. In International Conference on Database Systems for Advanced Applications; Springer: Berlin/Heidelberg, Germany, 2007; pp. 876–883. [Google Scholar]
- Nutanong, S.; Tanin, E.; Zhang, R. Incremental evaluation of visible nearest neighbor queries. IEEE Trans. Knowl. Data Eng. 2010, 22, 665–681. [Google Scholar] [CrossRef]
- Papadias, D.; Shen, Q.; Tao, Y.; Mouratidis, K. Group nearest neighbor queries. In Proceedings of the IEEE 20th International Conference on Data Engineering, Boston, MA, USA, 2 April 2004; pp. 301–312. [Google Scholar]
- Sun, W.; Chen, C.; Zheng, B.; Chen, C.; Zhu, L.; Liu, W.; Huang, Y. Merged aggregate nearest neighbor query processing in road networks. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2243–2248. [Google Scholar]
- Xu, H.; Li, Z.; Lu, Y.; Deng, K.; Zhou, X. Group visible nearest neighbor queries in spatial databases. In International Conference on Web-Age Information Management; Springer: Berlin/Heidelberg, Germany, 2010; pp. 333–344. [Google Scholar]
- Sultana, N.; Hashem, T.; Kulik, L. Group meetup in the presence of obstacles. Inf. Syst. 2016, 61, 24–39. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, R.; Xu, C.; Qi, J.; Gu, Y.; Yu, G. Continuous visible k nearest neighbor query on moving objects. Inf. Syst. 2014, 44, 1–21. [Google Scholar] [CrossRef]
- Lee, K.C.; Lee, W.C.; Leong, H.V. Nearest surrounder queries. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006. [Google Scholar]
- Lee, K.C.; Lee, W.C.; Leong, H.V. Nearest surrounder queries. IEEE Trans. Knowl. Data Eng. 2010, 22, 1444–1458. [Google Scholar] [CrossRef]
- Yi, S.; Jung, H.; Park, J.P.; Chung, Y.D. On processing view field nearest neighbor queries on the R*-tree. In Proceedings of the IEEE 2011 International Conference on Electrical and Control Engineering (ICECE), Yichang, China, 16–18 September 2011; pp. 4838–4841. [Google Scholar]
- Yi, S.; Ryu, H.; Son, J.; Chung, Y.D. View field nearest neighbor: A novel type of spatial queries. Inf. Sci. 2014, 275, 68–82. [Google Scholar] [CrossRef]
- Yi, S.; Shim, C.; Chung, Y.D. Reverse View Field Nearest Neighbor queries. Inf. Sci. 2017, 402, 35–49. [Google Scholar] [CrossRef]
- Jagadish, H.V.; Ooi, B.C.; Tan, K.L.; Yu, C.; Zhang, R. iDistance: An adaptive B+-tree based indexing method for nearest neighbor search. ACM Trans. Database Syst. (TODS) 2005, 30, 364–397. [Google Scholar] [CrossRef]
- Mouratidis, K.; Papadias, D.; Hadjieleftheriou, M. Conceptual partitioning: An efficient method for continuous nearest neighbor monitoring. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 634–645. [Google Scholar]
- Guttman, A. R-Trees: A Dynamic Index Structure for Spatial Searching; ACM: New York, NY, USA, 1984; Volume 14. [Google Scholar]
- Wang, Y.; Gao, Y.; Chen, L.; Chen, G.; Li, Q. All-visible-k-nearest-neighbor queries. In International Conference on Database and Expert Systems Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 392–407. [Google Scholar]
- Gao, Y.; Zheng, B.; Chen, G.; Lee, W.C.; Lee, K.C.; Li, Q. Visible reverse k-nearest neighbor queries. In Proceedings of the IEEE International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 1203–1206. [Google Scholar]
- Gao, Y.; Zheng, B.; Chen, G.; Lee, W.C.; Lee, K.C.; Li, Q. Visible reverse k-nearest neighbor query processing in spatial databases. IEEE Trans. Knowl. Data Eng. 2009, 21, 1314–1327. [Google Scholar]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD ’90), Atlantic City, NJ, USA, 23–26 May 1990; Volume 19, pp. 322–331. [Google Scholar]
- Sutherland, I.E.; Sproull, R.F.; Schumacker, R.A. A characterization of ten hidden-surface algorithms. ACM Comput. Surv. (CSUR) 1974, 6, 1–55. [Google Scholar] [CrossRef]
- Straßer, W. Schnelle Kurven-Und Flächendarstellung auf Grafischen Sichtgeräten. Ph.D Thesis, Berlin, Germany, 1974. Available online: https://diglib.eg.org:443/handle/10.2312/2631196 (accessed on 5 September 1974).
- Kalashnikov, D.V.; Prabhakar, S.; Hambrusch, S.E. Main memory evaluation of monitoring queries over moving objects. Distrib. Parallel Databases 2004, 15, 117–135. [Google Scholar] [CrossRef]
- Datasets & Algorithms. Available online: http://chorochronos.Datastories.Org/ (accessed on 20 March 2019).
Figure 1.
Example of finding k visible nearest data objects in the view field of q.

Figure 2.
The VkNN query.

Figure 3.
(a) Nearest surrounder query and (b) Angle-constrained Nearest Surrounder (ANS) query.

Figure 4.
Z-buffering.

Figure 5.
The view field.

Figure 6.
is inside the view field, but and are not.

Figure 7.
Angular and distance bounds of an obstacle.

Figure 8.
The four possible cases where an obstacle is inside a view field.

Figure 9.
is inside the view field, but and are not.

Figure 10.
Example of -, where k = 2.

Figure 11.
Grid cell indexing.

Figure 12.
and .

Figure 13.
Relationships between a query view field and a cell.

Figure 14.
An example of the baseline algorithm.

Figure 15.
Influential cells .

Figure 16.
(a) A coarse granularity grid. (b) A fine granularity grid.

Figure 17.
Split the 2D space into sections (i.e., ). The gray area is q’s view field. Note that the data space that covers 180– is omitted here.
Figure 17.
Split the 2D space into sections (i.e., ). The gray area is q’s view field. Note that the data space that covers 180– is omitted here.

Figure 18.
q, o, , and the sections where o is located.

Figure 19.
The content of the Direction Index () for Figure 17.
Figure 19.
The content of the Direction Index () for Figure 17.

Figure 20.
An example of the direction index (.

Figure 21.
(a) Irregular invisible regions. (b) Equally split the view field into several small regions. (c) Use to represent an invisible region. (d) contains multiple obstacles. (e) The of (c,d).
Figure 21.
(a) Irregular invisible regions. (b) Equally split the view field into several small regions. (c) Use to represent an invisible region. (d) contains multiple obstacles. (e) The of (c,d).

Figure 22.
The obstacle set of Greece.

Figure 23.
Average execution time vs. cell size. RG, Real Gaussian; RZ, Real Zipfian.

Figure 24.
Average execution time vs. .

Figure 25.
Average execution time vs. .

Figure 26.
Average execution time vs. k.

Figure 27.
Average execution time vs. θ.

Figure 28.
Average execution time vs. r.

Figure 29.
Average execution time vs. θS.

Figure 30.
Average execution time vs. θIRLB


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
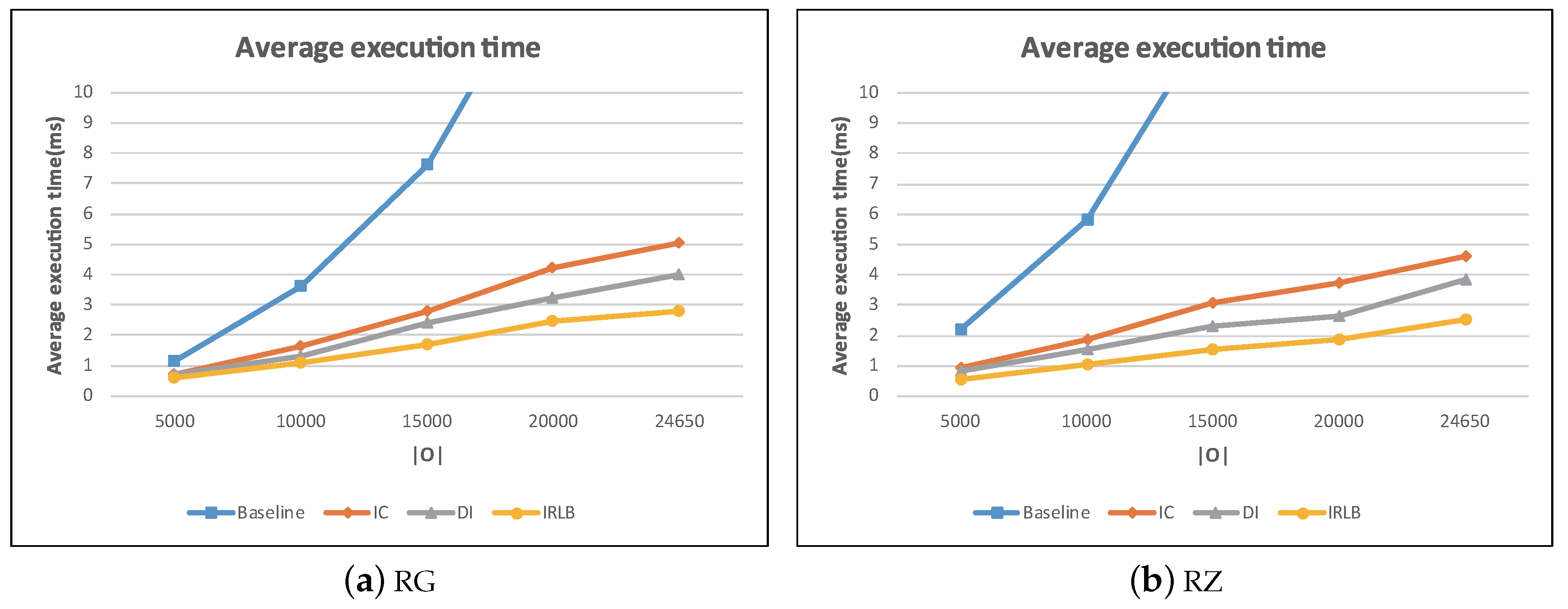{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary of symbols.
| Symbols | Meanings |
|---|---|
| The location, the maximum visible distance, and the view field angle of q | |
| The starting angle of q based on the positive x-axis | |
| The ending angle of q based on the positive x-axis | |
| The Euclidean distance between q and p | |
| The minimum angle between q and o | |
| The maximum angle between q and o | |
| The minimum distance between o and q | |
| The maximum distance between o and q | |
| The visible distance | |
| C | A grid cell |
| The minimum angle between query q and cell C | |
| The maximum angle between query q and cell C | |
| H | A min-heap that sorts accessed cells according their minimum possible distance to q |
| A min-heap that maintains candidate query results | |
| A min-heap that retains already accessed obstacles | |
| The current visible distance of the visible data object of q | |
| The current cell | |
| A visited cells list | |
| A splitting angle | |
| The splitting angle in the Invisible Regions Lookup Buffer (IRLB) | |
| The region, which is split in IRLB |
Table 2.
The example steps of the baseline algorithm.
| Round | Visited Cell | Heap H | Obstacles to Be Checked | Visited Data Object(s) | ||
|---|---|---|---|---|---|---|
| 1 | ∞ | |||||
| 2 | ∞ | |||||
| 3 | ∞ | |||||
| 4 | ∞ | |||||
| 5 | ∞ | |||||
| 6 | ∞ | |||||
| 7 | ∞ | |||||
| 8 |
Table 3.
The example steps of the baseline algorithm when calling the Visibility Check Ver. 2 (VC2) algorithm for visibility checking. Note that the “underlined” obstacles are checked in the VC algorithm but are not verified in the VC2 algorithm.
Table 3.
The example steps of the baseline algorithm when calling the Visibility Check Ver. 2 (VC2) algorithm for visibility checking. Note that the “underlined” obstacles are checked in the VC algorithm but are not verified in the VC2 algorithm.
| Round | Visited Cell | Heap H | Obstacles to Be Checked | Visited Data Object(s) | ||
|---|---|---|---|---|---|---|
| 1 | ∞ | |||||
| 2 | ∞ | |||||
| 3 | ∞ | |||||
| 4 | ∞ | |||||
| 5 | ∞ | |||||
| 6 | ∞ | |||||
| 7 | ∞ | |||||
| 8 |
Table 4.
Parameters and values of the experiments.
| Parameter | Value Range | Default Value |
|---|---|---|
| 10 k–1000 k | 100 k | |
| 5000–24,650 | 24,650 | |
| 100–2500 | 1000 | |
| k | 10–50 | 20 |
| 60– | ||
| r | 1 half of map | 4000 |
| 1– | ||
| 1– |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Su, I.-F.; Chen, D.-L.; Lee, C.; Chung, Y.-C.
Finding Visible kNN Objects in the Presence of Obstacles within the User’s View Field
AMA Style
Su I-F, Chen D-L, Lee C, Chung Y-C.
Finding Visible kNN Objects in the Presence of Obstacles within the User’s View Field
Su, I-Fang, Ding-Li Chen, Chiang Lee, and Yu-Chi Chung.
2019. "Finding Visible kNN Objects in the Presence of Obstacles within the User’s View Field
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.