Site Selection Improvement of Retailers Based on Spatial Competition Strategy and a Double-Channel Convolutional Neural Network

Abstract
:1. Introduction
2. Study Area and Data
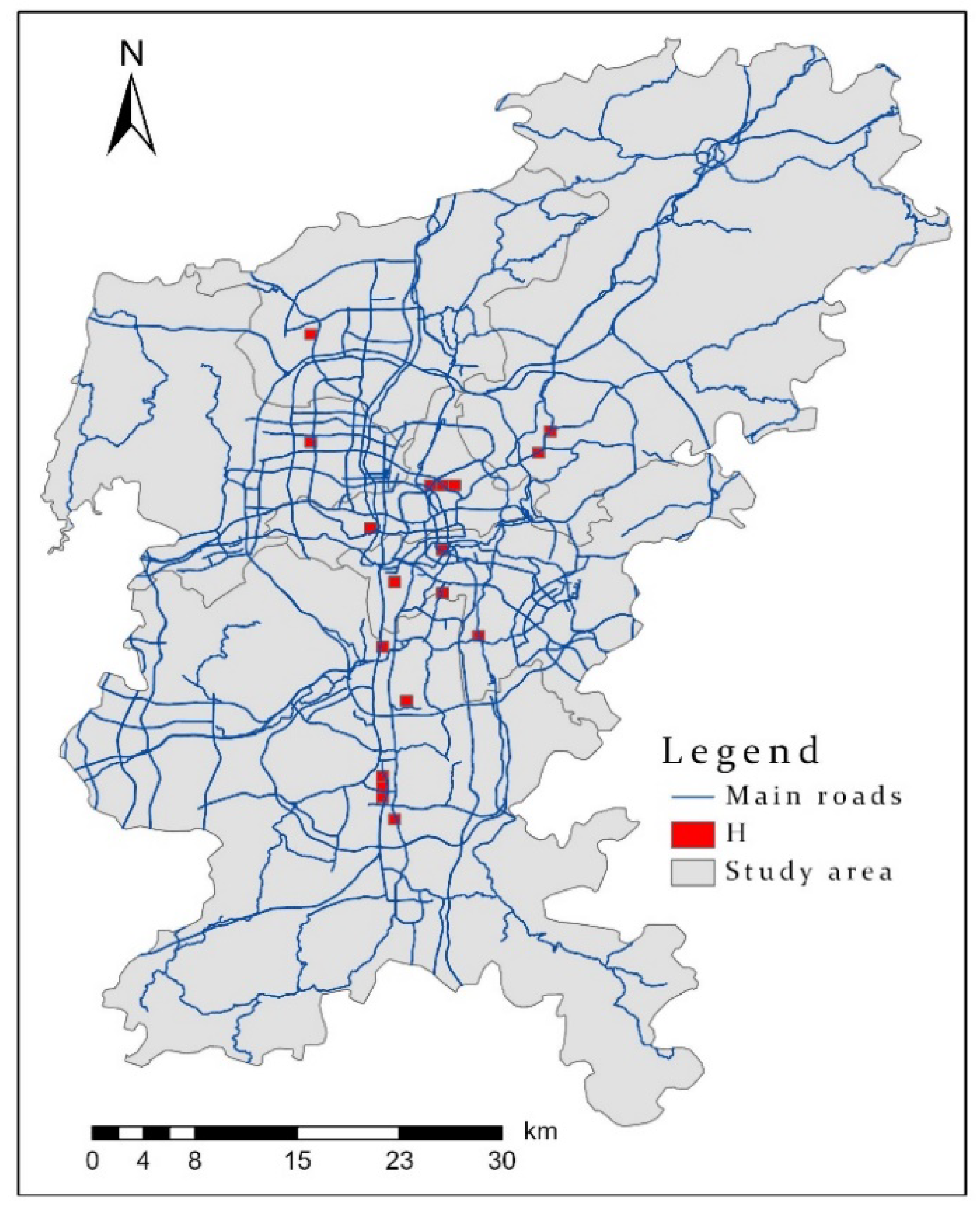
2.1. Study Area
2.2. Data
3. Methods
3.1. Preprocessing
3.1.1. Feature Selection and Normalization
3.1.2. Correlation Coefficient
3.1.3. Data Augmentation (DA)
3.2. Spatial Relationship Analysis
3.2.1. Spatial Competition Index
3.2.2. Range of Feature Spatial Correlation
3.3. Estimation of Market Potential Demand
3.3.1. Double-Channel Convolutional Neural Network (DCCNN)
3.3.2. Accuracy Metrics
4. Results and Analysis
4.1. Spatial Division
4.2. Evaluation for Range of Feature Spatial Correlation
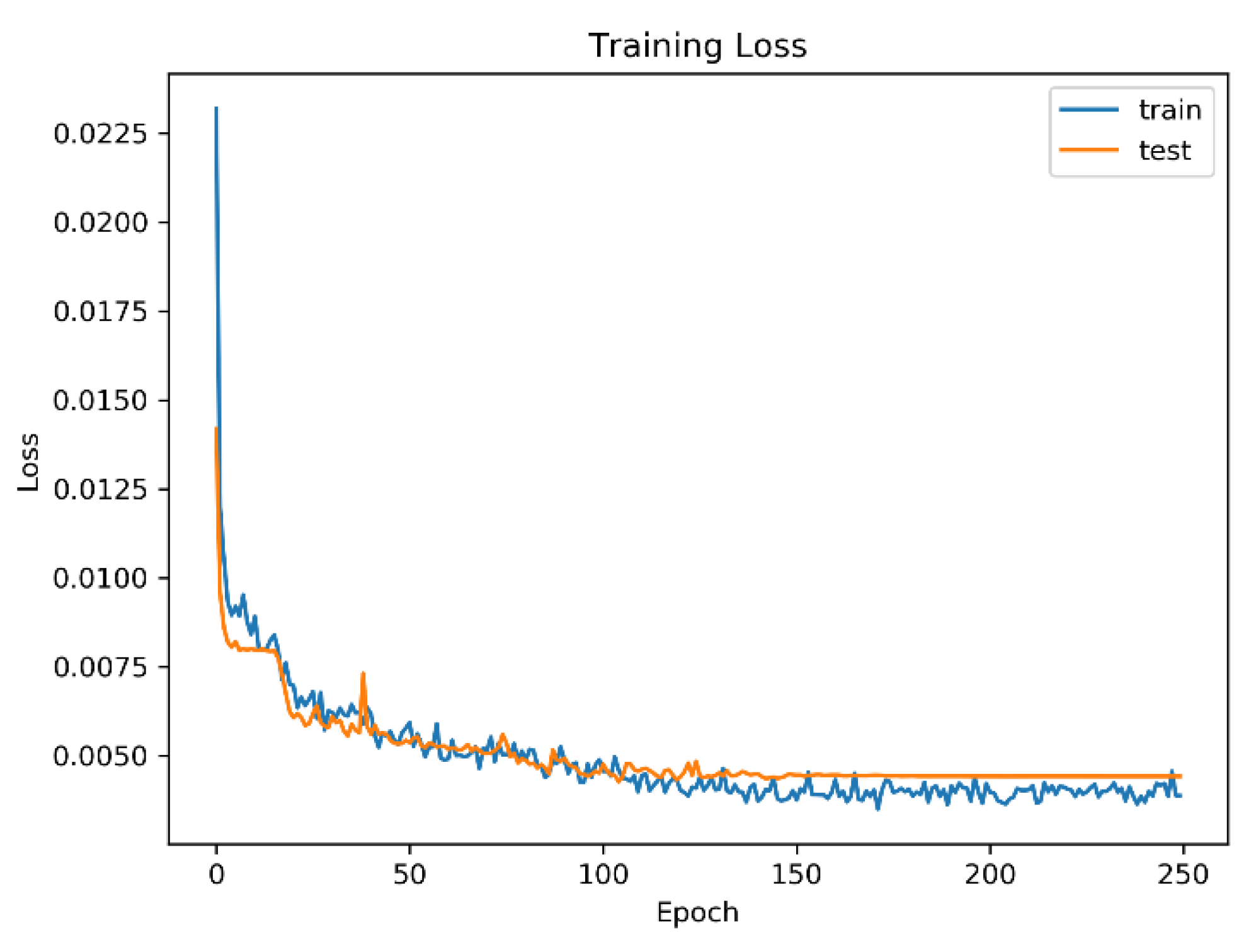
4.3. DA-DCCNN Model Training
4.4. Model Accuracy Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, Y.; Liu, X.; Zhang, T.; Gu, Z. Review of the Electric Vehicle Charging Station Location Problem. In Proceedings of the DependSys: International Conference on Dependability in Sensor, Cloud, and Big Data Systems and Applications, Guangzhou, China, 12–15 November 2019; pp. 435–445. [Google Scholar]
- Pachecano, L.C.; Larralde, H. Agglomeration or separation: Store patterns through an optimal location model. Phys. A Stat. Mech. Appl. 2020, 542, 123366. [Google Scholar] [CrossRef]
- Sen, A.; Smith, T.E.; Sen, P.D.A.; Smith, P.D.T.E. Gravity Models of Spatial Interaction Behavior; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Le Texier, M.; Caruso, G. Aggregate and Disaggregate Dynamic Spatial Interaction Approaches to Modeling Coin Diffusion. In Spatial Analysis and Location Modeling in Urban and Regional Systems; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2017; pp. 193–222. [Google Scholar]
- Reilly, W.J. The Law of Retail Gravitation; University of California: Oakland, CA, USA, 1931. [Google Scholar]
- Converse, P.D. New laws of retail gravitation. J. Mark. 1949, 14, 379–384. [Google Scholar] [CrossRef]
- Cohen, S.B.; Applebaum, W. Evaluating store sites and determining store rents. Econ. Geogr. 1960, 36, 1–35. [Google Scholar] [CrossRef]
- Suhara, Y.; Bahrami, M.; Bozkaya, B.; Pentland, A.S. Validating Gravity-Based Market Share Models Using Large-Scale Transactional Data. arXiv 2019, arXiv:1902.03488. [Google Scholar]
- Qun-Hong, L.; Pu-Ping, Z.; Min, L. An Empirical Study of Urban Trade Area Evolutionary Mechanism Based on Gray Correlation Analysis—A Case Study in Nanchang. In Proceedings of the 19th International Symposium on Advancement of Construction Management and Real Estate; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2015; pp. 1111–1120. [Google Scholar]
- Wang, L.; Fan, H.; Wang, Y. Site Selection of Retail Shops Based on Spatial Accessibility and Hybrid BP Neural Network. ISPRS Int. J. GeoInf. 2018, 7, 202. [Google Scholar] [CrossRef] [Green Version]
- Tierno, N.R.; Puig, A.B.; Vera, J.M.B.; Perez, C.E. Assessing food retail competitors with a multi-criteria GIS-based method. Economía Agraria y Recursos Naturales 2018, 18, 5–22. [Google Scholar] [CrossRef]
- Piovani, D.; Molinero, C.; Wilson, A. Urban retail location: Insights from percolation theory and spatial interaction modeling. PLoS ONE 2017, 12, e0185787. [Google Scholar] [CrossRef] [Green Version]
- Widaningrum, D.L. GIS and SVM Approach for Convenience Store Location Analysis. In Proceedings of the 9th International Conference on Machine Learning and Computing, Singapore, 24–26 February 2017; pp. 112–116. [Google Scholar]
- Fang, J.; Hu, J.; Shi, X.; Zhao, L. Assessing disaster impacts and response using social media data in China: A case study of 2016 Wuhan rainstorm. Int. J. Disaster Risk Reduct. 2019, 34, 275–282. [Google Scholar] [CrossRef]
- Deng, Y.; Liu, J.; Liu, Y.; Luo, A. Detecting Urban Polycentric Structure from POI Data. ISPRS Int. J. GeoInf. 2019, 8, 283. [Google Scholar] [CrossRef] [Green Version]
- Jiang, W.; Wang, Y.; Dou, M.; Liu, S.; Shao, S.; Liu, H. Solving Competitive Location Problems with Social Media Data Based on Customers’ Local Sensitivities. ISPRS Int. J. GeoInf. 2019, 8, 202. [Google Scholar] [CrossRef] [Green Version]
- Byun, S.-E.; Han, S.; Kim, H.; Centrallo, C. US small retail businesses’ perception of competition: Looking through a lens of fear, confidence, or cooperation. J. Retail. Consum. Serv. 2020, 52, 101925. [Google Scholar] [CrossRef]
- Chen, T.-Y.; Chen, L.-C.; Chen, Y.-M. Mining Location-Based Service Data for Feature Construction in Retail Store Recommendation. In Proceedings of the 17th Industrial Conference Data Mining, New York, NY, USA, 12–13 July 2017; Volume 10357, pp. 68–77. [Google Scholar]
- Glaeser, C.K.; Fisher, M.; Su, X. Optimal Retail Location: Empirical Methodology and Application to Practice. Manuf. Serv. Oper. Manag. 2019, 21, 86–102. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Tsai, C.-H.; Lin, P.-C. Applying spatial-temporal analysis and retail location theory to public bikes site selection in Taipei. Transp. Res. Part A Policy Pr. 2016, 94, 45–61. [Google Scholar] [CrossRef]
- Han, Z.; Cui, C.; Miao, C.; Wang, H.; Chen, X.; Cui, H.; Wang, M. Chen Identifying Spatial Patterns of Retail Stores in Road Network Structure. Sustainability 2019, 11, 4539. [Google Scholar] [CrossRef] [Green Version]
- Mulbi, B.; Ramli, A. The Factors Affecting Buyer Interest in Indomaret Retail in Maros City. Arch. Bus. Res. 2019, 7, 225–241. [Google Scholar]
- Kumar, S.N.; Fred, A.L.; Kumar, H.A.; Varghese, P.S.; Jacob, S.A. Segmentation of Anomalies in Abdomen CT Images by Convolution Neural Network and Classification by Fuzzy Support Vector Machine. In Hybrid Machine Intelligence for Medical Image Analysis; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2019; pp. 157–196. [Google Scholar]
- Li, G.; Tang, H.; Sun, Y.; Kong, J.; Jiang, G.; Jiang, D.; Tao, B.; Xu, S.; Liu, H. Hand gesture recognition based on convolution neural network. Clust. Comput. 2017, 22, 2719–2729. [Google Scholar] [CrossRef]
- Yang, H.; Zhao, G.; Zhang, L.; Zhu, N.; He, Y.; Zhao, C. Real-Time Emotion Recognition Framework Based on Convolution Neural Network. In Advances in Intelligent Information Hiding and Multimedia Signal Processing; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2019; pp. 313–321. [Google Scholar]
- Kowalski, P.A.; Sapała, K.; Warchałowski, W. PM10 forecasting through applying convolution neural network techniques. Int. J. Environ. Impacts 2020, 3, 31–43. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, S.; Paul, S.; Sarkar, R.; Nasipuri, M. Feature Map Reduction in CNN for Handwritten Digit Recognition. In Recent Developments in Machine Learning and Data Analytics; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2018; pp. 143–148. [Google Scholar]
- Zhang, J.; Zheng, Y.; Qi, D. Deep spatio-temporal residual networks for citywide crowd flows prediction. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017.
- Wang, L.; Fan, H.; Wang, Y. Sustainability Analysis and Market Demand Estimation in the Retail Industry through a Convolutional Neural Network. Sustainability 2018, 10, 1762. [Google Scholar] [CrossRef] [Green Version]
- Government Official Website of Guiyang. Available online: http://www.guiyang.gov.cn/ (accessed on 8 May 2020).
- WorldPop. Available online: https://www.worldpop.org/ (accessed on 8 May 2020).
- Tatem, A.J. WorldPop, open data for spatial demography. Sci. Data 2017, 4, 170004. [Google Scholar] [CrossRef]
- Lloyd, C.T.; Sorichetta, A.; Tatem, A.J. High resolution global gridded data for use in population studies. Sci. Data 2017, 4, 170001. [Google Scholar] [CrossRef] [Green Version]
- Sina Weibo Webpage. Available online: https://weibo.cn/ (accessed on 8 May 2020).
- Baidu Map Open Platform. Available online: https://lbsyun.baidu.com/ (accessed on 8 May 2020).
- Chinese National Catalogue Service for Geographic Information. Available online: https://www.webmap.cn (accessed on 8 May 2020).
- Yanine, F.; Cordova, F.M.; Valenzuela, L.; Isla, P. A fresh look to an old problem: Saturation in the retail market, and how it affects both retailers and consumers. Indian J. Sci. Technol. 2019, 12, 1–10. [Google Scholar] [CrossRef]
- Pereira, J.; De Oliveira, E.C.B.; Gomes, L.F.A.M.; Araújo, R.M. Sorting retail locations in a large urban city by using ELECTRE TRI-C and trapezoidal fuzzy numbers. Soft Comput. 2018, 23, 4193–4206. [Google Scholar] [CrossRef]
- Hu, Q.; Bai, G.; Wang, S.; Ai, M. Extraction and monitoring approach of dynamic urban commercial area using check-in data from Weibo. Sustain. Cities Soc. 2019, 45, 508–521. [Google Scholar] [CrossRef]
- Wang, J. Using Network Analysis to Explore the Effects of Road Network on Traffic Congestion and Retail Store Sales. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2017. [Google Scholar]
- Liu, Y.; Mu, Y.; Chen, K.; Li, Y.; Guo, J. Daily Activity Feature Selection in Smart Homes Based on Pearson Correlation Coefficient. Neural Process. Lett. 2020, 51, 1771–1787. [Google Scholar] [CrossRef]
- Feng, W.; Zhu, Q.; Zhuang, J.; Yu, S. An expert recommendation algorithm based on Pearson correlation coefficient and FP-growth. Clust. Comput. 2018, 22, 7401–7412. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies from Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 113–123. [Google Scholar]
- Agrawal, A.; Mittal, N. Using CNN for facial expression recognition: A study of the effects of kernel size and number of filters on accuracy. Vis. Comput. 2019, 36, 405–412. [Google Scholar] [CrossRef]
- Wang, L.; Fan, H.; Gong, T. The Consumer Demand Estimating and Purchasing Strategies Optimizing of FMCG Retailers Based on Geographic Methods. Sustainability 2018, 10, 466. [Google Scholar] [CrossRef] [Green Version]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Nielsen, D. Tree Boosting with XGBoost—Why does XGBoost Win “Every” Machine Learning Competition? Master’s Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2016. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Yıldız, N.; Tuysuz, F.; Yildiz, N. A hybrid multi-criteria decision making approach for strategic retail location investment: Application to Turkish food retailing. SocioEcon. Plan. Sci. 2019, 68, 100619. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User ID | Latitude | Longitude | Time |
|---|---|---|---|
| XXX | 106.711212 | 26.60239 | 2016/9/15 01:54 |
| XXX | 106.704857 | 26.583679 | 2016/3/27 10:41 |
| XXX | 106.687027 | 26.568529 | 2016/5/17 10:13 |
| XXX | 106.707619 | 26.577271 | 2016/11/4 16:27 |
| Factors | Index | Description |
|---|---|---|
| Consumer groups | Local resident | WorldPop population data |
| Passenger flow | Sina Weibo check-in data | |
| Urban infrastructure | POIs | Sum of POIs in grid |
| Road network | Road network density | OSM road network density |
| Business competition | Degree of spatial competition | Related with store sales and distance |
| Layer | Feature Maps | Kernel Size | Strides | ReLU | Output Size |
|---|---|---|---|---|---|
| 4 | (3, 3) | 1 | Yes | (12, 14) | |
| 4 | (2, 2) | 2 | No | (7, 7) | |
| 8 | (3, 1) | 1 | Yes | (5, 7) | |
| 8 | (1, 3) | 1 | Yes | (5, 5) | |
| 8 | (2, 2) | 3 | No | (2, 2) | |
| 2 | (5, 5) | 1 | Yes | (12, 12) | |
| 2 | (2, 2) | 2 | No | (6, 6) | |
| 4 | (3, 3) | 1 | Yes | (4, 4) | |
| 4 | (2, 2) | 2 | No | (2, 2) | |
| - | (1, 1) | - | Yes | (16) | |
| - | (1, 1) | - | No | (1) |
| Grid Size (m) | Pop | Check-in | POIs | SCI | Road Density | |
|---|---|---|---|---|---|---|
| 100 | 0.1505 | 0.0657 | 0.1259 | 0.0487 | 0.0067 | 0.25 |
| 200 | 0.2018 | 0.2184 | 0.1786 | 0.1584 | 0.0834 | 0.29 |
| 300 | 0.2170 | 0.2276 | 0.2421 | 0.3013 | 0.1421 | 0.31 |
| 400 | 0.2656 | 0.2290 | 0.2927 | 0.4093 | 0.1788 | 0.35 |
| 500 | 0.2765 | 0.3806 | 0.3479 | 0.4898 | 0.2314 | 0.38 |
| 600 | 0.3173 | 0.4442 | 0.4146 | 0.5837 | 0.2626 | 0.24 |
| 700 | 0.4052 | 0.4919 | 0.4668 | 0.5947 | 0.2953 | 0.34 |
| 800 | 0.4567 | 0.4839 | 0.5078 | 0.6454 | 0.2993 | 0.32 |
| 900 | 0.4548 | 0.5256 | 0.5032 | 0.6675 | 0.2958 | 0.26 |
| 1000 | 0.4191 | 0.5010 | 0.5515 | 0.6388 | 0.3545 | 0.27 |
| No. | Parameters | Value | No. | Parameters | Value |
|---|---|---|---|---|---|
| 1 | Batch size | 206 | 4 | Channels of | 2 |
| 2 | Epoch | 120 | 5 | Channels of | 1 |
| 3 | Initial learning rate | 0.005 | 6 | Reduce learning rate | ReduceLROnPlateau |
| No. | Estimated Sales | Grid Image | Google Map Image | Google Earth Image | Coordinates |
|---|---|---|---|---|---|
| 1 | RMB 544,259 /month |  |  |  | Lat: 26.616611 Lon: 106.704806 |
| 2 | RMB 633,058 /month |  |  |  | Lat: 26.616556 Lon: 106.699111 |
| 3 | RMB 2,261,795 /month |  |  |  | Lat: 26.416000 Lon: 106.664917 |
| 4 | RMB 545,272 /month |  |  |  | Lat: 26.645111 Lon: 106.616806 |
| 5 | RMB 582,950 /month |  |  |  | Lat: 26.715786 Lon: 106.619050 |
| 6 | RMB 2,234,156 /month |  |  |  | Lat: 26.637889 Lon: 106.769833 |
| 7 | RMB 716,952 /month |  |  |  | Lat: 26.389110 Lon: 106.675040 |
| Model | MSE | MAE | RMSE |
|---|---|---|---|
| Support vector regression (SVR) | 0.3410 | 0.0754 | 0.0933 |
| Random Forest (RF) | 0.0074 | 0.0498 | 0.0858 |
| XGBoost | 0.0066 | 0.0543 | 0.0814 |
| Single-channel CNN | 0.0072 | 0.0500 | 0.0849 |
| DA-DCCNN (Ours) | 0.0043 | 0.0388 | 0.0657 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, J.; Fan, H.; Wang, L.; Yang, M.; Ma, Y. Site Selection Improvement of Retailers Based on Spatial Competition Strategy and a Double-Channel Convolutional Neural Network. ISPRS Int. J. Geo-Inf. 2020, 9, 357. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9060357
Ouyang J, Fan H, Wang L, Yang M, Ma Y. Site Selection Improvement of Retailers Based on Spatial Competition Strategy and a Double-Channel Convolutional Neural Network. ISPRS International Journal of Geo-Information. 2020; 9(6):357. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9060357
Chicago/Turabian StyleOuyang, Jiani, Hong Fan, Luyao Wang, Mei Yang, and Yaohong Ma. 2020. "Site Selection Improvement of Retailers Based on Spatial Competition Strategy and a Double-Channel Convolutional Neural Network" ISPRS International Journal of Geo-Information 9, no. 6: 357. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9060357