
A Derivative-Free MZPRP Projection Method for Convex Constrained Nonlinear Equations and Its Application in Compressive Sensing

 , ,
, ,  ,
,  and
and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- The new proposed method is derivative-free as well as matrix-free.
- The search direction is sufficiently descending independent of any line search strategy.
- The proposed work relaxes, to some extent, the condition imposed on the user-defined parameter for the ZPRP search direction [37] to satisfy the sufficient descent condition.
- The convergence result of the new method is proved under an assumption that is weaker than monotonicity, that is, pseudomonotonicity.
- The new method is efficient and computationally inexpensive.
- Lastly, the new method is successfully applied to recover some disturbed signals arising from compressive sensing.
2. Motivation and Proposed Method
| Algorithm 1: MZPRP. |
Input: Given any point , , and set . Step 1: Calculate the . If , then stop. Step 3: Calculate the trial point with such that the following condition
Step 4: If , then stop. Else, calculate the next iteration by
Step 5: Set and go to Step 1. |
3. Convergence Analysis
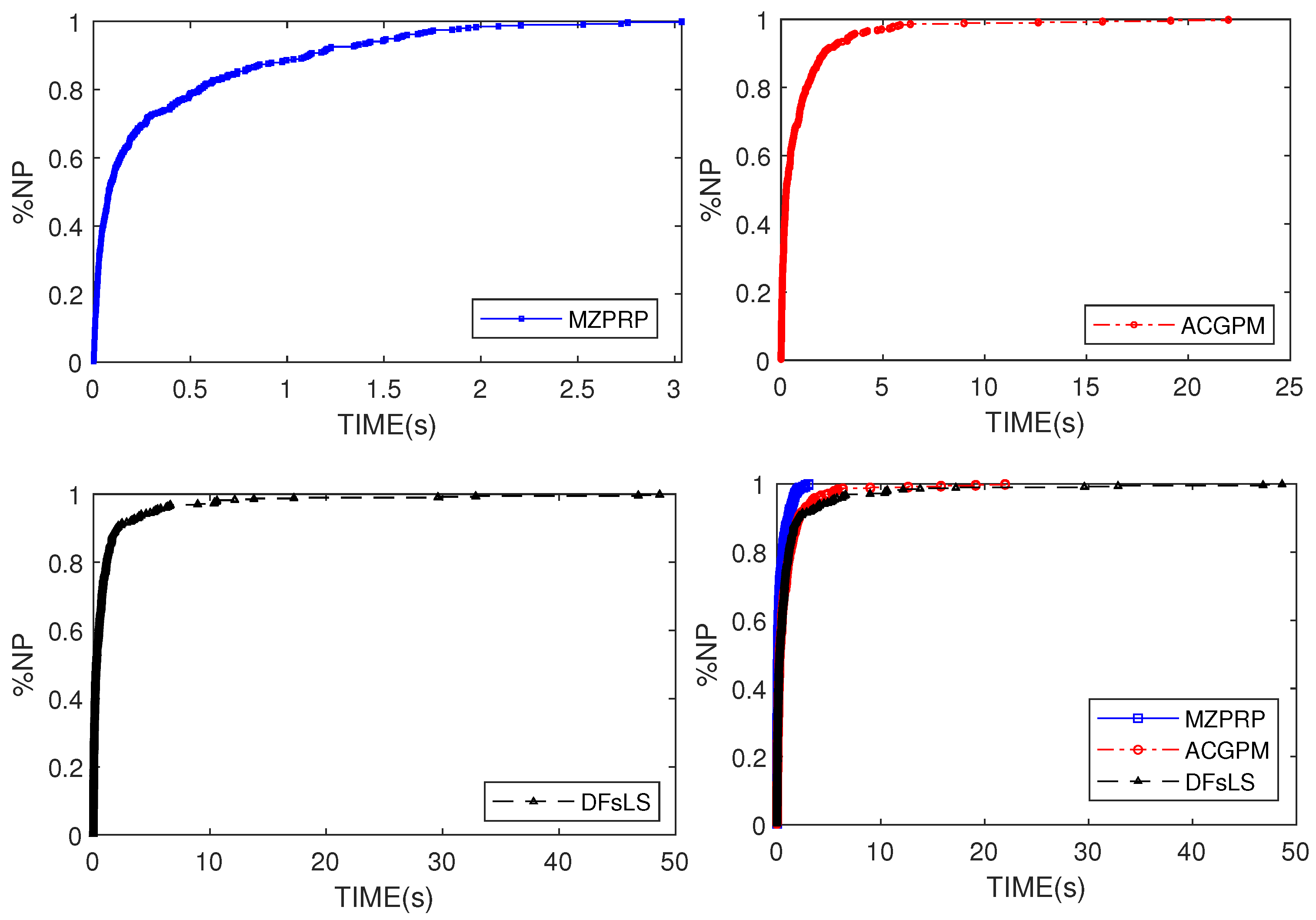
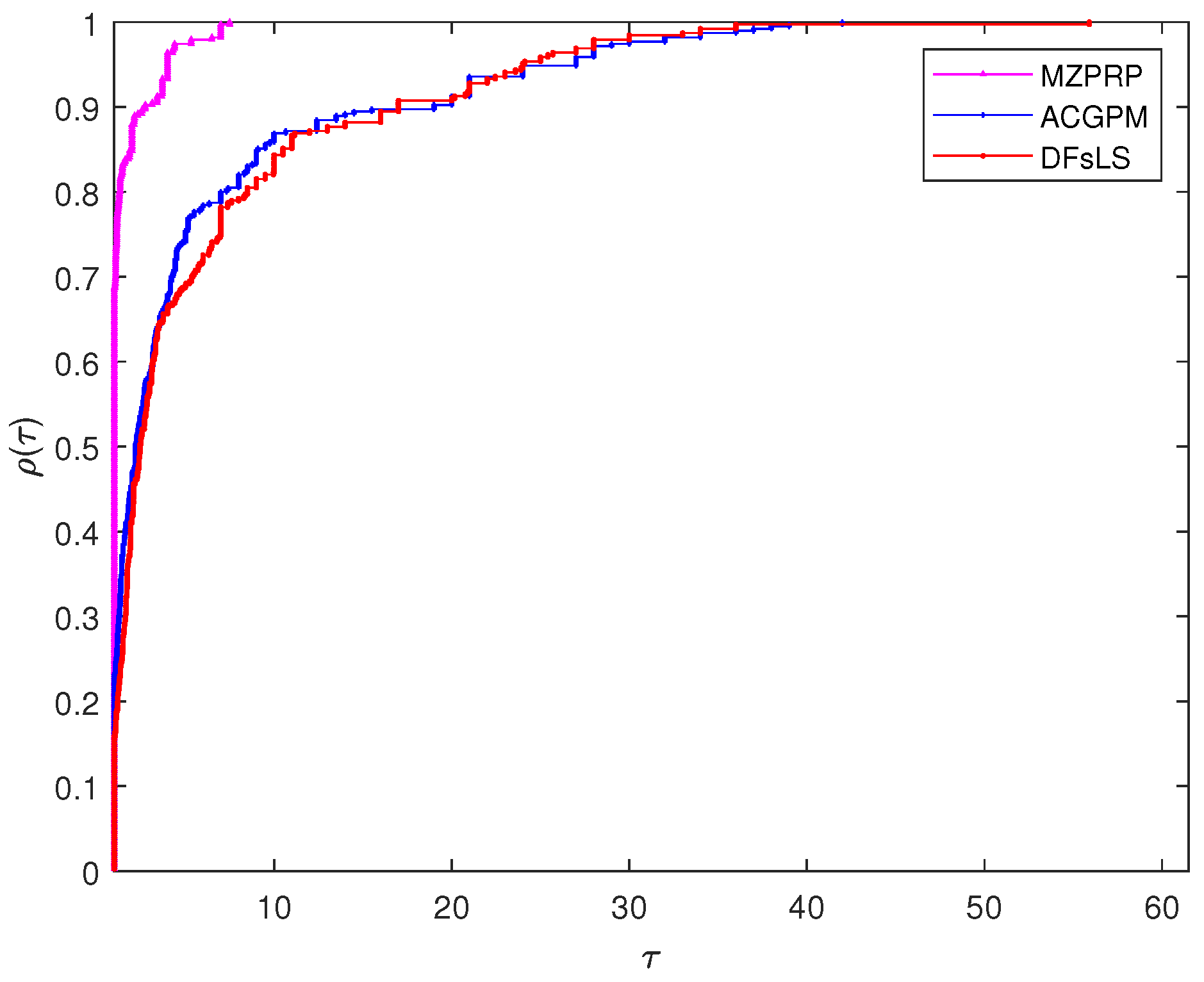
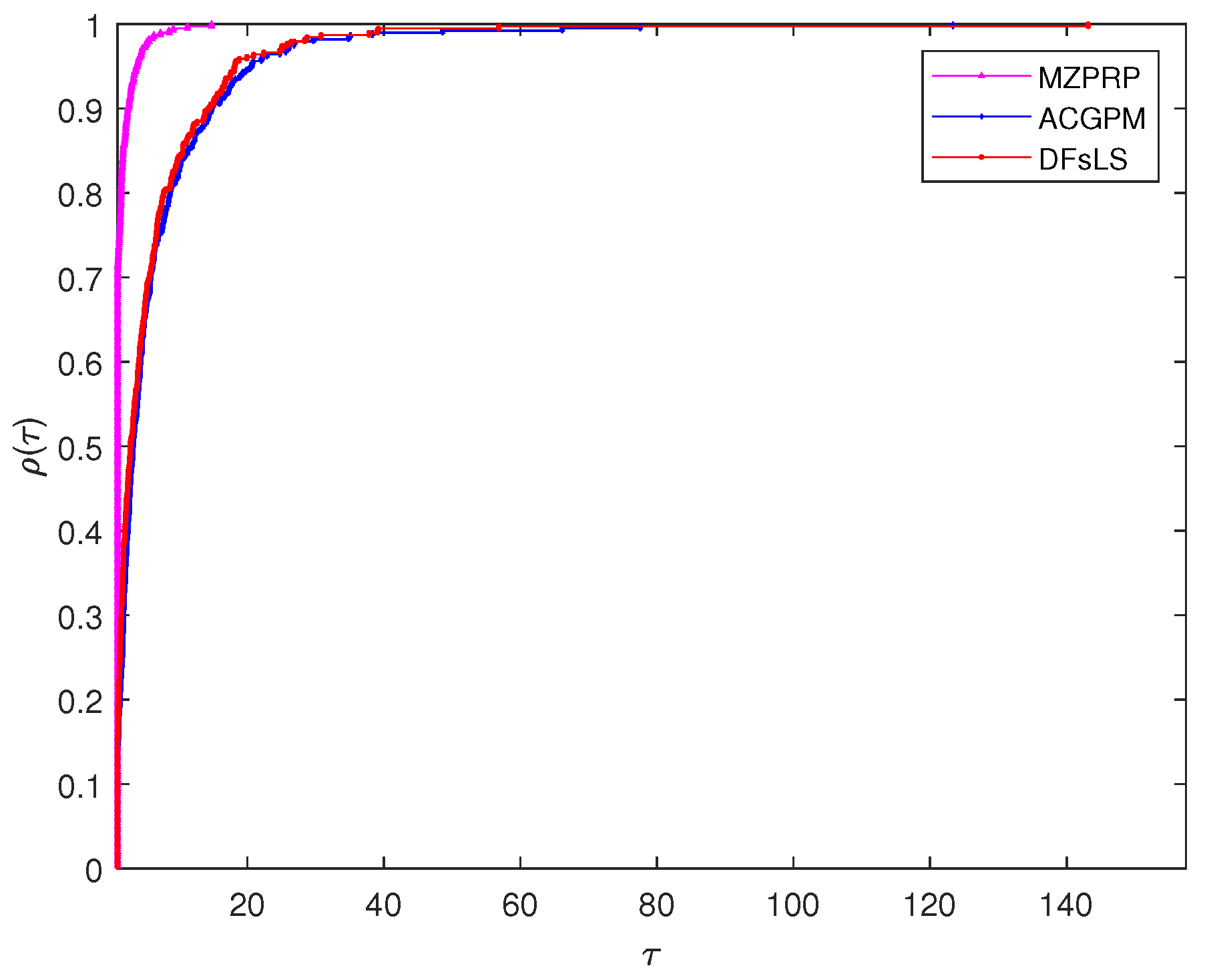
4. Numerical Experiments
- (i)
- “A conjugate gradient projection method for solving equations with convex constraints” proposed by Zheng et al. [38]. For convenience, we denote this method as ACGPM.
- (ii)
- “Partially symmetrical derivative-free Liu–Storey projection method for convex constrained equations” developed by Liu et al. [39]. For simplicity, this method shall be denoted by DFsLS.
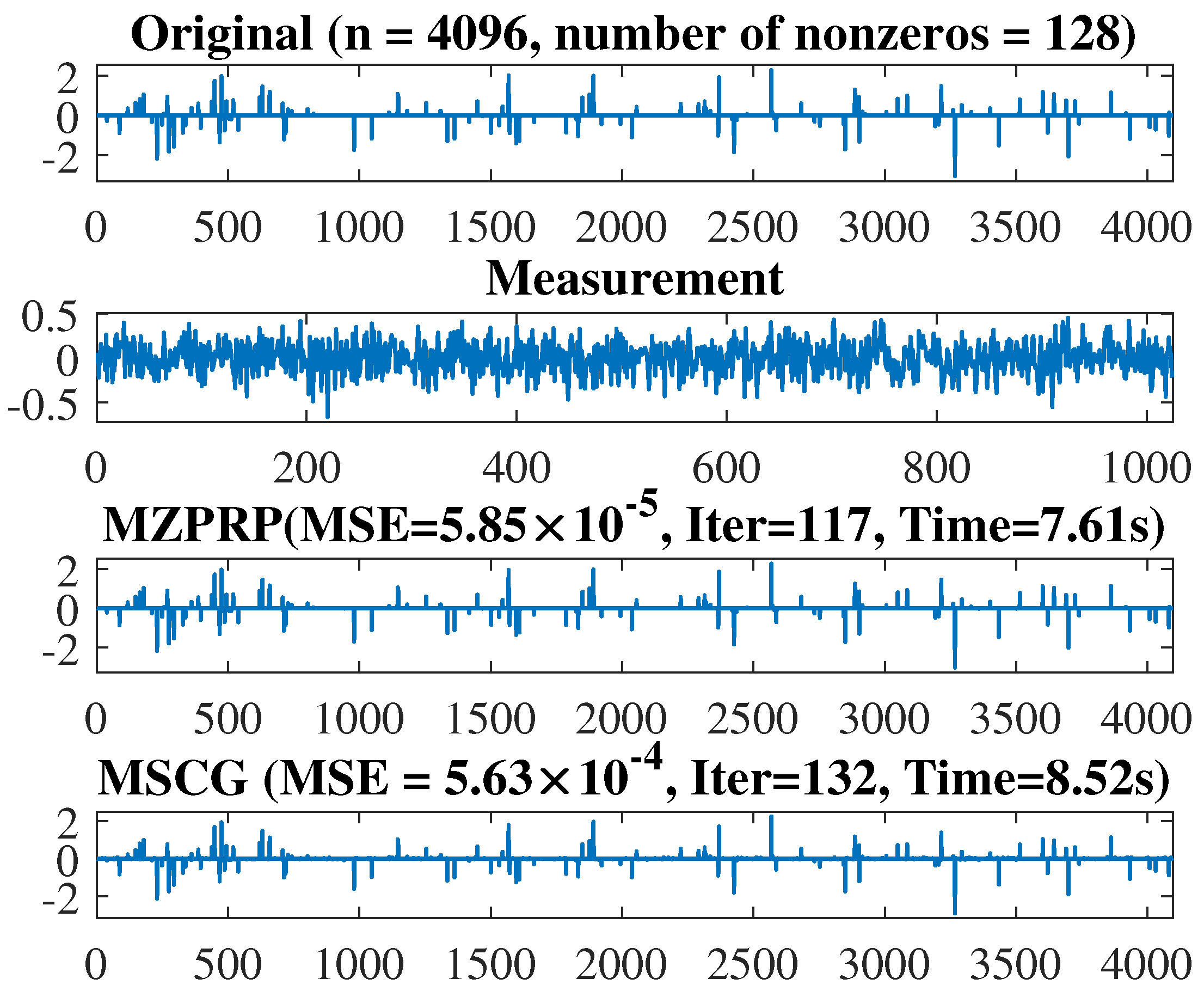
5. Application in Compressive Sensing
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Test Problems
References
- Fang, X. Class of new derivative-free gradient type methods for large-scale nonlinear systems of monotone equations. J. Inequalities Appl. 2020, 2020, 93. [Google Scholar] [CrossRef]
- Schnabel, R.B.; Dennis, J.E., Jr. Numerical Methods for Unconstrained Optimization and Nonlinear Equations; Prentice-Hall: Englewood Cliffs, NJ, USA, 1983. [Google Scholar]
- Grippo, L.; Lampariello, F.; Lucidi, S. A Nonmonotone Line Search Technique for Newton’s Method. SIAM J. Numer. Anal. 1986, 23, 707–716. [Google Scholar] [CrossRef]
- Morini, B.; Bellavia, S. A globally convergent Newton-GMRES subspace method for systems of nonlinear equations. SIAM J. Sci. Comput. 2001, 23, 940–960. [Google Scholar]
- Martínez, J.M.; Birgin, E.G.; Krejic, N.K. Globally convergent inexact quasi-Newton methods for solving nonliear systems. Numer. Algorithms 2003, 32, 249–260. [Google Scholar]
- Gasparo, M.G. A nonmonotone hybrid method for nonlinear systems. Optim. Method Softw. 2000, 13, 79–94. [Google Scholar] [CrossRef]
- Broyden, C.G. A class of methods for solving nonlinear simultaneous equations. Math. Comput. 1965, 19, 577–593. [Google Scholar] [CrossRef]
- Nesterov, Y.; Rodomanov, A. New results on superlinear convergence of classical quasi-Newton methods. J. Optim. Theory Appl. 2021, 188, 744–769. [Google Scholar]
- Rodomanov, A.; Nesterov, Y. Greedy quasi-Newton methods with explicit superlinear convergence. SIAM J. Optim. 2021, 31, 785–811. [Google Scholar] [CrossRef]
- Borwein, J.M.; Barzilai, J. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar]
- Raydann, M.; Cruz, W.L.; Martinez, J.M. Spectral residual method without gradient information for solving large-scale nonlinear systems of equations. Math. Comput. 2006, 75, 1429–1448. [Google Scholar]
- Solodov, M.V.; Svaiter, B.F. A globally convergent inexact Newton method for systems of monotone equations. In Reformulation: Nonsmooth, Piecewise Smooth, Semismooth and Smoothing Methods; Springer: Boston, MA, USA, 1998; pp. 355–369. [Google Scholar]
- Yu, Z.; Lin, J.; Sun, J.; Xiao, Y.; Liu, L.; Li, Z. Spectral gradient projection method for monotone nonlinear equations with convex constraints. Appl. Numer. Math. 2009, 59, 2416–2423. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W. Spectral gradient projection method for solving nonlinear monotone equations. J. Comput. Appl. Math. 2006, 196, 478–484. [Google Scholar] [CrossRef]
- Muhammed, A.A.; Kumam, P.; Abubakar, A.B.; Wakili, A.; Pakkaranang, N. A new hybrid spectral gradient projection method for monotone system of nonlinear equations with convex constraints. Thai J. Math. 2018, 125–147. [Google Scholar]
- Awwal, A.M.; Wang, L.; Kumam, P.; Mohammad, H. A two-step spectral gradient projection method for system of nonlinear monotone equations and image deblurring problems. Symmetry 2020, 12, 874. [Google Scholar] [CrossRef]
- Sulaiman, I.M.; Mamat, M. A new conjugate gradient method with descent properties and its application to regression analysis. J. Numer. Anal. Ind. Appl. Math. 2020, 14, 25–39. [Google Scholar]
- Malik, M.; Mamat, M.; Abas, S.S.; Sulaiman, I.M.; Sukono, F. A new coefficient of the conjugate gradient method with the sufficient descent condition and global convergence properties. Eng. Lett. 2020, 28, 704–714. [Google Scholar]
- Yakubu, U.A.; Sulaiman, I.M.; Mamat, M.; Ghazali, P.L.; Khalid, K. The global convergence properties of a descent conjugate gradient method. J. Adv. Res. Dyn. Control Syst. 2020, 12, 1011–1016. [Google Scholar]
- Stiefel, E.; Hestenes, M.R. Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 1952, 49, 409–436. [Google Scholar]
- Fletcher, R.; Reeves, C.M. Function minimization by conjugate gradients. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef]
- Ribiere, G.; Polak, E. Note sur la convergence de méthodes de directions conjuguées. ESAIM Math. Model. Numer. Anal.-Modél. Math. Anal. Numér. 1969, 3, 35–43. [Google Scholar]
- Malik, M.; Mamat, M.; Abas, S.S.; Sulaiman, I.M.; Sukono, F. A new modification of NPRP conjugate gradient method for unconstrained optimization. Adv. Math. Sci. J. 2020, 9, 4955–4970. [Google Scholar] [CrossRef]
- Storey, C.; Liu, Y. Efficient generalized conjugate gradient algorithms, part 1: Theory. J. Optim. Theory Appl. 1991, 69, 129–137. [Google Scholar]
- Fletcher, R. Practical Methods of Optimization; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Yuan, Y.; Dai, Y.H. A nonlinear conjugate gradient method with a strong global convergence property. SIAM J. Optim. 1999, 10, 177–182. [Google Scholar]
- Rivaie, M.; Mamat, M.; Abashar, A. A new class of nonlinear conjugate gradient coefficients with exact and inexact line searches. Appl. Math. Comput. 2015, 268, 1152–1163. [Google Scholar] [CrossRef]
- Awwal, A.M.; Kumam, P.; Abubakar, A.B. Spectral modified Polak–Ribiére–Polyak projection conjugate gradient method for solving monotone systems of nonlinear equations. Appl. Math. Comput. 2019, 362, 124514. [Google Scholar] [CrossRef]
- Awwal, A.M.; Wang, L.; Kumam, P.; Mohammad, H.; Watthayu, W. A projection Hestenes-Stiefel method with spectral parameter for nonlinear monotone equations and signal processing. Math. Comput. Appl. 2020, 2, 27. [Google Scholar] [CrossRef]
- Awwal, A.M.; Kumam, P.; Wang, L.; Huang, S.; Kumam, W. Inertial-based derivative-free method for system of monotone nonlinear equations and application. IEEE Access 2020, 8, 226921–226930. [Google Scholar] [CrossRef]
- Cheng, W.; Xiao, Y.; Hu, Q.J. A family of derivative-free conjugate gradient methods for large-scale nonlinear systems of equations. J. Comput. Appl. Math. 2009, 224, 11–19. [Google Scholar] [CrossRef]
- Zhu, H.; Xiao, Y. A conjugate gradient method to solve convex constrained monotone equations with applications in compressive sensing. J. Math. Anal. Appl. 2013, 405, 310–319. [Google Scholar]
- Zhang, H.; Hager, W. A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J. Optim. 2005, 16, 170–192. [Google Scholar]
- Min, L. A derivative-free PRP method for solving large-scale nonlinear systems of equations and its global convergence. Optim. Methods Softw. 2014, 29, 503–514. [Google Scholar]
- Qin, N.; Xiaowei, F. A new derivative-free conjugate gradient method for large-scale nonlinear systems of equations. Bull. Aust. Math. Soc. 2017, 95, 500–511. [Google Scholar]
- Sabi’u, J.; Waziri, M.Y. A derivative-free conjugate gradient method and its global convergence for solving symmetric nonlinear equations. Int. J. Math. Math. Sci. 2015, 2015, 961487. [Google Scholar]
- Zheng, X.; Shi, J. A modified sufficient descent Polak–Ribiére–Polyak type conjugate gradient method for unconstrained optimization problems. Algorithms 2018, 11, 133. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, L.; Liang, Y. A conjugate gradient projection method for solving equations with convex constraints. J. Comput. Appl. Math. 2020, 375, 112781. [Google Scholar] [CrossRef]
- Liu, J.K.; Xu, J.Ł.; Zhang, L.Q. Partially symmetrical derivative-free Liu–Storey projection method for convex constrained equations. Int. J. Comput. Math. 2019, 96, 1787–1798. [Google Scholar] [CrossRef]
- Dolan, E.D.; Moré, J.J. Benchmarking optimization software with performance profiles. Math. Program. 2002, 91, 201–213. [Google Scholar] [CrossRef]
- Figueiredo, M.A.T.; Nowak, R.D.; Wright, S.J. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Signal Process. 2007, 1, 586–597. [Google Scholar] [CrossRef]
- Xiao, Y.; Wang, Q.; Hu, Q. Non-smooth equations based method for ℓ1-norm problems with applications to compressed sensing. Nonlinear Anal. Theory Methods Appl. 2011, 74, 3570–3577. [Google Scholar] [CrossRef]
- Pang, J.S. Inexact Newton methods for the nonlinear complementarity problem. Math. Program. 1986, 36, 54–71. [Google Scholar] [CrossRef]
- Abubakar, A.B.; Kumam, P.; Awwal, A.M.; Thounthong, P. A modified self-adaptive conjugate gradient method for solving convex constrained monotone nonlinear equations for signal recovery problems. Mathematics 2019, 7, 693. [Google Scholar] [CrossRef]
- Awwal, A.M.; Kumam, P.; Abubakar, A.B. A modified conjugate gradient method for monotone nonlinear equations with convex constraints. Appl. Numer. Math. 2019, 145, 507–520. [Google Scholar] [CrossRef]
- Aji, S.; Kumam, P.; Awwal, A.M.; Yahaya, M.M.; Sitthithakerngkiet, K. An efficient DY-type spectral conjugate gradient method for system of nonlinear monotone equations with application in signal recovery. AIMS Math. 2021, 6, 8078–8106. [Google Scholar] [CrossRef]
- Awwal, A.M.; Kumam, P.; Sitthithakerngkiet, K.; Bakoji, A.M.; Halilu, A.S.; Sulaiman, I.M. Derivative-free method based on DFP updating formula for solving convex constrained nonlinear monotone equations and application. AIMS Math. 2021, 6, 8792–8814. [Google Scholar] [CrossRef]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sulaiman, I.M.; Awwal, A.M.; Malik, M.; Pakkaranang, N.; Panyanak, B. A Derivative-Free MZPRP Projection Method for Convex Constrained Nonlinear Equations and Its Application in Compressive Sensing. Mathematics 2022, 10, 2884. https://0-doi-org.brum.beds.ac.uk/10.3390/math10162884
Sulaiman IM, Awwal AM, Malik M, Pakkaranang N, Panyanak B. A Derivative-Free MZPRP Projection Method for Convex Constrained Nonlinear Equations and Its Application in Compressive Sensing. Mathematics. 2022; 10(16):2884. https://0-doi-org.brum.beds.ac.uk/10.3390/math10162884
Chicago/Turabian StyleSulaiman, Ibrahim Mohammed, Aliyu Muhammed Awwal, Maulana Malik, Nuttapol Pakkaranang, and Bancha Panyanak. 2022. "A Derivative-Free MZPRP Projection Method for Convex Constrained Nonlinear Equations and Its Application in Compressive Sensing" Mathematics 10, no. 16: 2884. https://0-doi-org.brum.beds.ac.uk/10.3390/math10162884