
Identification of Location and Camera Parameters for Public Live Streaming Web Cameras

1
Pacific Oceanological Institute of Far Eastern Branch of RAS, 690041 Vladivostok, Russia
2
Center for Research and Education in Mathematics, Institute of Mathematics and Computer Technologies, Far Eastern Federal University, 690922 Vladivostok, Russia
*
Author to whom correspondence should be addressed.
Mathematics 2022, 10(19), 3601; https://0-doi-org.brum.beds.ac.uk/10.3390/math10193601
Submission received: 5 August 2022
/
Revised: 17 September 2022
/
Accepted: 23 September 2022
/
Published: 1 October 2022
(This article belongs to the Special Issue Numerical Methods and Algorithms Applied in Intelligent Transportation Systems)
Abstract
:Public live streaming web cameras are quite common now and widely used by drivers for qualitative analysis of traffic conditions. At the same time, they can be a valuable source of quantitative information on transport flows and speed for the development of urban traffic models. However, to obtain reliable data from raw video streams, it is necessary to preprocess them, considering the camera location and parameters without direct access to the camera. Here we suggest a procedure for estimating camera parameters, which allows us to determine pixel coordinates for a point cloud in the camera’s view field and transform them into metric data. They are used with advanced moving object detection and tracking for measurements.
Keywords:
depth map; radial distortion; perspective distortion; camera calibration; transport traffic statisticsMSC:
37M10; 65D18; 68U10; 90B20
1. Introduction
There are many ways to measure traffic [1,2,3]. The most common in the practice of road services are radars combined with video cameras and other sensors. The measuring complexes are above or at the edge of the road. Inductive sensors are the least dependent on weather conditions and lighting. The listed surveillance tools assume installation by the road or on the road. Providers of mobile navigator applications receive data about the car’s movement from the sensors of mobile devices. Autonomous cars collect environmental information using various sensors, including multiview cameras, lidars, and radars. The results of the data collection systems of road services, operators of navigators, and autonomous cars are usually not available to third-party researchers. Notably, pioneering traffic analysis work describes processing video data recorded on film [3] (pp. 3–10).
Operators worldwide install public web cameras, many of which look at city highways; e.g., there are more than a hundred similar cameras available in Vladivostok.
A transport model verification requires actual and accurate data on transport traffic, covering a wide range of time intervals with substantial transport activity. Public live-streaming cameras can be a good and easily accessible source of data for that kind of research. Of course, this accessibility is relative. Video processing involves storing and processing large amounts of data.
The ref. [4] demonstrates road traffic statistics collection from a public camera video, where the camera has little perspective and radial distortions in the region of interest in the road (Region Of Interest, ROI). However, the distortions make significant changes in images for the majority of public cameras. The current article generalizes this approach to the case where a camera has essential radial and perspective distortions.
Street camera owners usually do not announce camera parameters (focal length, radial distortion coefficients, camera position, orientation). Standard calibration procedures with a pattern rotation can be useless for cameras on a wall or tower. In this case, we suggest the implementable camera calibration procedure, which uses only online data (global coordinates of some visible points, photos, and street view images).
With known camera parameters, we construct the mapping between the ROI pixel coordinates and metric coordinates of points on the driving surface, which gives a way to estimate traffic flow parameters in standard units such as car/meter for traffic density and meter/second for car velocity with improved accuracy.
2. Coordinate Systems, Models
We select an ENU coordinate frame (East, North, Up) with an origin on a fixed object to localize points , where and are coordinates of P in .
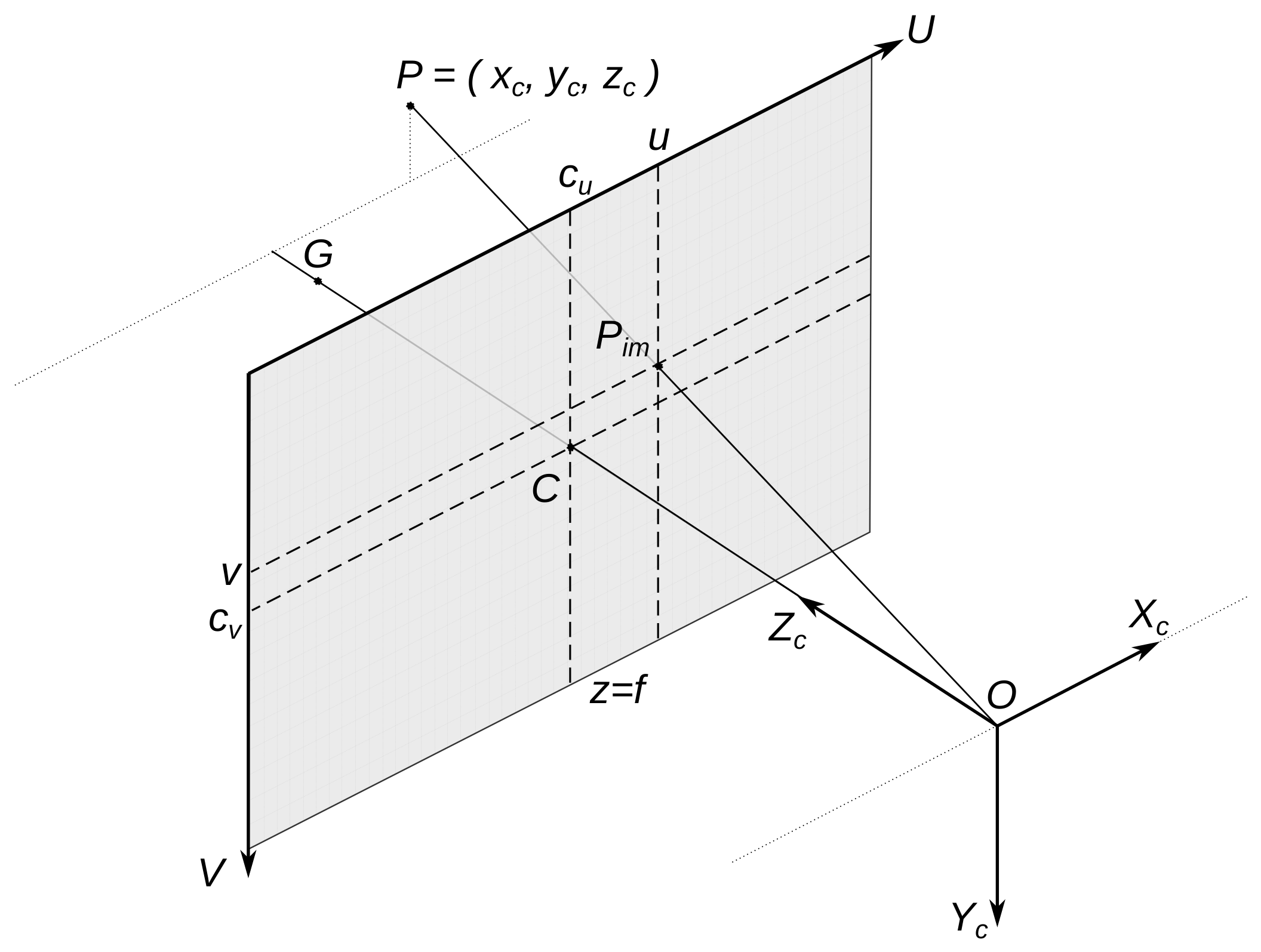
A camera forms an image in the sensor (Figure 1 and Figure 2). A digital image is a pixel matrix (N columns, M rows). A pixel position is described in the image coordinate frame in the image plane where u and v are real numbers, coordinates of in . Axis U corresponds to the image matrix rows (towards the right), and axis V corresponds to columns (from up to down). The camera orientation determines the image sensor plane orientation. Integer indexes define pixel position in the image matrix. We can obtain them by rounding u and v to the nearest integers. Let w and h be the image pixel width and height, respectively. For the image width and height, we have and .
Camera position and orientation define the camera coordinate frame (Figure 1). The camera perspective projection center O is the origin of . We denote by the O coordinates in . Axis follows along the camera optical axis, axis is parallel to axis U, and is parallel to axis V. Axis defines the camera horizon. The deviation of from the horizontal plane defines the camera horizon tilt. Unlike , the and are metric coordinate frames. coordinates approximate matrix indexes. To obtain meters from u on axis U, we use the expression , and to obtain meters from v on axis V, we use .
Suppose the camera builds an image close to a perspective projection of a 3D scene. We describe this camera transformation as the pinhole camera model (Figure 1, Figure 2 and ref. [5]). A point image is the transformation of the original 3D point P coordinates described in . The matrices A and define this transformation:
The triangular matrix A contains the intrinsic parameters of the camera. Camera position and orientation determine matrix . Matrix defines transformation from frame to camera coordinates :
Here, R is a rotation matrix, and t is the shift vector from the origin of to O (origin of ). Matrix A includes the principal point C coordinates in frame and the camera focal length f divided by pixel width and height:
The camera’s optical axis and the image plane intersect at C. It is the spatial point G image (Figure 1 and Figure 2). Usually, the coordinates point to the image sensor matrix center (e.g., full HD resolution is 1920 × 1080, so ). Some modes of cameras can produce cropped images shifted from the principal point; we do not consider this case here.
The triangles and are similar on the plane and on (Figure 2), so
It follows from (5) that pixel coordinates in are connected with coordinates of the spatial source in by the equations
where are homogeneous coordinates of . If and , the pixel defines the relations (5). However, we need to know the value (“depth map”) to recover original 3D coordinates and from the pixel coordinates . Additional information about the scene is needed to build the depth map for some range of pixels . Perspective projection preserves straight lines.
A wide-angle lens, used by most street public cameras, introduces perspective distortion described by the pinhole camera model and substantial radial distortion. Usually, the radial distortion is easily detectable, especially on ”straight” lines near the edges of the image. An extended model was used to take it into account. A popular quadratic model of radial distortion ([6] (pp. 63–66), [7] (pp. 189–193), [5]) changes the pinhole camera model (6) as follows:
where and are radial distortion coefficients. In addition to the quadratic, more complex polynomials and models of other types are used ([5], [6] (pp. 63–66, 691–692), [7] (pp. 189–193)). Let the coefficients and be selected so that the formation of images from the camera is sufficiently well described by (7)–(9). To construct the artificial image on which the radial distortion and is eliminated, we must for each pair of relations obtain new positions of pixels according to the pinhole camera model:
To do this, we need all values (coordinates in ), which form the original image. To obtain the relations from an image, you have the image pixel coordinates and equations (follows from (7)–(9))
if . Similar equations are valid for and . Equation (13) has five roots (complex, generally speaking), so we need an additional condition to select one root. We can select the real root nearest to . The artificial image will not be a rectangle, but we can select a rectangle part of it (see figures of Example 2). Note that the mapping is determined by the camera parameters and . It does not change from frame to frame and can be computed once and used before the parameters are changed.
3. Public Camera Parameters Estimation
Model parameters (3), (7)–(9) define the transformation of the 3D point, visible by camera, to pixel coordinates in the image. These parameters are: rotation matrix of the camera orientation R (2) and (3); camera position coordinates (point O) in (3); intrinsic camera parameters and , (1) and (4); and radial distortion coefficients and , (8) and (9).
The camera calibration process estimates the parameters using a set of 3D point coordinates and a set of the point image coordinates . The large set is called a point cloud. There are software libraries that work with point clouds. Long range 3D lidars or geodesic instruments measure 3D coordinates values for a set . Another camera depth map can help obtain a set . Stereo/multi-view cameras can build depth maps, but it is hard to obtain high accuracy for long distances. When the tools listed above are unavailable, it is possible to obtain global coordinates of points in the camera field of view by GNSS sensors or from online maps. The latter variants are easier to access but less accurate. There are many tools [8] to translate global coordinates to an ENU.
Camera calibration procedure is well studied ([7] (pp. 178–194), [9] (pp. 22–28), [10], [6] (pp. 685–692)). It looks for the parameter values that minimize the difference between pixels and pixels generated by the model (3), (7)–(9) from . Computer vision software libraries include calibration functions for a suitable set of images from a camera [5]. The OpenCV function calibrateCamera [5,11] needs a set of points and pixels of a special pattern (e.g., “chessboard”) rotated before the camera. The function returns an estimation of intrinsic camera parameters and camera placements concerning the pattern positions. These relative camera placements are usually useless after outdoor camera installation. If the camera uses a zoom lens and the zoom changes on the street, the camera focal length changes too, and new calibration is needed. If we use a public camera installed on a wall or tower, it is hard to collect appropriate pattern images from the camera to apply a function such as calibrateCamera. Camera operators usually do not publish camera parameters, but this information is indispensable for many computer vision algorithms. We need a calibration procedure applicable to the available online data.
Site-Specific Calibration
If the unified calibration procedure data are unavailable, we can estimate camera position and orientation parameters (R,O) separately from others. Resolution of images/video from a camera is available with the images/video. As noted earlier, usually
Many photo cameras (including phone cameras) add the EXIF metadata to the image file, which often contain focal length f. The image sensor model description can contain a pixel width w and height h, so (4) gives and values. The distortion coefficients are known for high-quality photo lenses. Moreover, the raw image processing programs can remove the lens radial distortion. If lucky, we can obtain intrinsic camera parameters and radial distortion coefficients and apply a pose computation algorithm (PnP, [12,13]) to sets , to obtain R,O estimates. When EXIF metadata from the camera are of no help (this is typical for most public cameras), small sets and and Equation (5) can help to obtain and estimations. Suppose we know the installation site of the camera (usually, the place is visible from the camera’s field of view). In that case, we can estimate GNSS/ENU coordinates of the place (point O coordinates) by the method listed earlier. The camera orientation (matrix R) can be detected with the point G coordinates (Figure 1) and the estimation of the camera horizon tilt. Horizontal or vertical 3D lines (which can be artificial) in the camera’s field of view can help evaluate the tilt.
4. Formulation of the Problem and Its Solution Algorithm
Designers and users of transport models are interested in the flow density (number of vehicles per unit of lane length or direction at a time); speed of vehicles (on a lane or direction); and intensity of the flow (number of vehicles crossing the cross section of a lane or direction). We capture some areas (ROI) of the frames to determine these values from a fixed camera. The camera generates a series of ROI images, usually at a fixed interval, such as 25 frames/second. The algorithms (object detection or instance segmentation or contours detection and object tracking, see [14,15,16,17]) find a set of contours describing the trajectory of each vehicle crossing the ROI. The contour description consists of the coordinates of the vertices in . We count the number of contours per meter in the ROI of each frame to estimate flow density. We choose the vertex (e.g., “bottom left”) of the contour in the trajectory and count the meters that the vertex has passed in the trajectory to estimate the car speed. Both cases require estimation in meters of distance given in pixels, so we need to convert lengths in the image (in ) to lengths in space (in or ). In some examples, distances in pixels are related to metric distances almost linearly (where radial and perspective distortions are negligible). We will consider the public cameras that produce images with significant radial and perspective distortions in the ROI (more common case).
Problem 1.
- Let Q be the area that is a plane section of the road surface in space (the road plane can be inclined);
- Φ is the camera frame of resolution containing the image of Q, denoting the image by ;
- Φ contains the image of at least one segment, the prototype of which in space is a segment of a straight line with a known slope (e.g., vertical);
- The image is centered relative to the optical axis of the video camera, that is, and ;
- The coordinates of the points O (camera position) and G (the source of the optical center C) are known;
- The coordinates of one or more pixels of located on the line and the coordinates of their sources are known;
- The coordinates of one or more pixels of located on the line and the coordinates of their sources are known;
- The coordinates of three or more points are known; at least three of them must be non-collinear;
- The coordinates of one or more groups of three pixels are known, and in the group, the sources of the pixels are collinear in space.
Find the parameters of the camera and and construct the mapping
Online maps allow remote estimation of global coordinates of points and horizontal distances. Many such maps do not show the altitude, and most do not show the height of buildings, bridges, or vegetation. Online photographs, street view images, and horizontal distances can help estimate such objects’ heights. Camera locations are often visible in street photos. This variant of measurements suggests that the coordinate estimates may contain a significant error. The errors result in some algorithms (e.g., PnPransac) being able to generate a response with an unacceptable error.
To find ,,, and coordinates, the points must be visible both in the image and on the online map.
4.1. Solution Algorithm
We want to eliminate the radial distortion of area to go to the pinhole camera model. From (10)–(13), it follows that for this you need values and .
4.1.1. Obtain the Intrinsic Parameters (Matrix A)
Note that from and (7)–(9) it follows for the point (because leads to and ). So, the point stays on the central horizontal line of the image for any values and . By analogy, for take place , and the point stays on the central vertical line for any values and .
It follows from (5) that if the effect of radial distortion on the values and can be ignored (camera radial distortion is moderate, and the points are not too far from C), then
Equation (16) gives the initial approximation of coefficients and and an evaluation of matrix A.
4.1.2. Obtain the Radial Distortion Compensation Map
Let be the image obtained from by the transformation (10) and solution of Equations (11)–(13). Denote the mapping of to :
We create the image according to the pinhole camera model. The model transforms a straight line in space into a straight line in the image.
Let and in and
We can find and values that minimize the sum of distances from pixels to the lines passing through and . We calculate the distance as:
for each triplet . This approach is a variant of the one described, for example, in [7] (pp. 189–194). OpenCV offers the realization of (initUndistortRectifyMap). It is fast, but we need to invert it for our case. We solve Equations (11)–(13) (including version for ) to obtain . The is polinomial from (see (7)–(10)).
4.1.3. Obtain the Camera Orientation (Matrix R )
To determine the camera orientation, we use the point O and the point G given in the coordinates (Figure 1). Unit vector
gives direction to axis of frame . , and O determines the plane of points x, for which the vector is perpendicular to . In this plane, lie the axes and of coordinate frame . Unit vector is downward. Let be camera coordinates with the same optical axis as , but the has zero horizon tilt. Axis of the frame is perpendicular to as far as is parallel to the horizontal plane. We can find axes directions and of the frame :
Vectors (21) form the orthonormal basis, which allows us to construct a rotation matrix for transition from to :
If is a rotation matrix, the following equations hold:
From Clause 4 of the problem statement, there is a line segment in the artificial image with a known slope in space. It is possible to compare the segment slope in the image and the slope of its source in space. So, we can estimate the camera horizon tilt angle (denote it as ) and rotate the plane with the axes and around the optical axis at this angle. The resulting system of coordinates corresponds to the actual camera orientation. To pass from the camera coordinates to , we can first go from to by rotation with the angle around the optical axis using the rotation matrix
We can describe the transition from to (without origin displacement) as a combination of rotations by the matrix
which is also a rotation matrix. The matrix that we have already designated R (2) gives the inverse transition from to the coordinates of the camera frame :
and the shift t, which in the coordinates characterizes the transition from the beginning of the coordinates of to the point of installation of the camera O. The t is often more easily expressed through the coordinates given in , see (3). To convert the coordinates of a from to coordinates for the camera frame, use the following expressions:
Typically, an operator aims to set a camera with zero horizon tilt.
4.1.4. Obtain the Mapping for
Let be the area in corresponding to in the image . and are the domain Q on the road plane in coordinates , and , respectively. From (27), we obtain
From Clause 2 of the problem statement, it follows that an image of is visible in (and in , so ).
We can convert the ENU coordinates of points to by following (27). We denote the result as . Let .
We approximate its plane with the least squares method. The plane is defined in by the equation
The matrix D and vector E represent the points on the road:
The plane parameters p can be found by solving the least squares problem
the exact solution to the least squares task is:
For a point represented by the pixel coordinates in we obtain, taking into account (6)
.
If and (it means that and ) then
so there are linear equations that allow us to express and through and . Let
We have constructed a function that assigns to each pixel coordinates (in image ) a spatial point in the coordinate system , according to (36) and (37):
If , so
4.2. Auxiliary Steps
4.2.1. Describing of the Area Q
Different Q shapes help for varying tasks. We fix as a quadrilateral on the image . The (source of the quadrilateral in space) in the plane may be a rectangle or a tetragon. We choose the four corners of and of the domain as pixels in the . The “tetragon” is the ROI in the original image , in which we use object detection to estimate transport flows statistics. The lines bound are ([7] (p. 28)):
where are the homogeneous coordinates of pixel . Pixel must be the solution to a system of four inequalities:
The is a continuous domain in , but the whole image contains only a fixed number of actual pixels (). The same is true for . We can obtain real pixels that fall in from with the per-pixel correspondence . We apply the mapping (39) and obtain the set of points in which correspond to actual pixels in . is a metric coordinate system, so the distance in can be used to estimate meters/second or objects/meter. The same is true for any rotations or shifts of the frame .
4.2.2. Coordinate Frame Associated with the Plane
We can go from to a coordinate system associated with the plane . We apply it for illustrations, but it can be helpful for other purposes. We can regard the traffic in as anything that rises above the plane . We denote by the coordinate system connected to . and use the normal to the plane at the coordinates from (32) as the axis .
We choose in the plane the direction of another axis (e.g., ), and the third axis is determined automatically. Let the Y axis be pointed by the vector (that is, along the direction of traffic movement in the Q area), then
Select the origin of the coordinate system as follows
The rotation matrices from to and their inverses look like the following:
Use the following expression for the translation of coordinates of given in frame to given in frame :
5. Examples
Consider a couple of public camera parameters evaluations, where the images and small sets of coordinates and of limited accuracy are available.
5.1. Example 1: Inclined Driving Surface and a Camera with Tilted Horizon
Figure 3 shows a video frame from the public camera.
The camera is a good example, as its video contains noticeable perspective and radial distortion. In the image, there is a line demonstrating the camera’s slight horizon tilt (the wall at the base of which is ). The visible part of the road has a significant inclination. This is a FullHD camera (). Select a point as the origin of . Assess ENU coordinates of the point O (the camera position), point G (the source of the principal point C, Figure 1 and Figure 3), and points and on the lines and , respectively. Using maps and online photos, we obtained the values listed in Table 1. Convert global coordinates to the coordinates (see [8]) and add it to the table (in meters).
The points from Table 1 can be found on the satellite layer of [18] using the latitude and longitude of the query.
We obtain and by using (15), (16) and Table 1 data. Street camera image sensors usually have square pixels, so and (4). If the difference and is small, let be equal (we use mean value). So we have an approximation of matrix A.
Now, we can estimate radial distortion coefficients and by minimizing distances (19) or in another way. Put and to compute the mapping (17) and apply it to eliminate radial distortion and from the original image (). The mapping does not change for different frames from the camera video. We obtained the undistorted version of image , which we have identified (Figure 4).
The radial distortion of the straight lines in the vicinity of the road has almost disappeared in . The camera’s field of view decreased, the C point remained in place, and the and points moved further along the lines and . The values of and can be recalculated, but radial distortion is not the only cause of errors. Therefore, we will perform additional cross-validation and compensate the values of and if required.
We can estimate the horizon tilt angle from the image (Figure 4) and rotate the plane with the axes and of frame around the optical axis at this angle. As a result of rotating the image around the optical axis of the camera on , the verticality of the required line was achieved (Figure 5), so let in (24).
We compute the camera orientation matrix R with (20)–(26). Now, we can convert coordinates to with (27).
Let us use the area nearest to the camera carriageway region as the ROI (area Q). We select several points in Q, estimate their global coordinates, and convert them to [8]. Next, we convert coordinates to with (27). The results are in Table 2.
We calculate the lines that bound domain by (41) and detect the set of pixel coordinates that belong to . Note that this set does not change for different frames from the camera video. We can save it for later usage with the camera and the Q.
We compute the as by (48) and (35)–(39). We convert the pixel coordinates from to by (43)–(47):
and save the result. The coordinates set does not change for the (fixed) camera and the Q. The obtained discrete sets and are sets of metric coordinates. We can use for measurements on the plane as is or apply an interpolation.
Since , the point set is suitable to output in a plane picture. If for each point, we use and the color of the pixel g for all , and output the plane as the scatter map, we obtain the bottom image from Figure 6. We chose a multi-car scene in the center of Q for the demonstration. We obtain the accurate ”view from above” for the points that initially lie on the road’s surface. The positions of the pixels representing objects that tower above plane have shifted. There are options for estimating and accounting for the height of cars and other objects so that their images look realistic in the bottom image. However, this is the subject of a separate article.
It is worth paying attention to the axes of the bottom figure (they show meters). In comparison with the original (top image of Figure 6), there are noticeable perspective distortion changes in the perception of distance. The width and length of the area are in good agreement with the measurements made by the rangefinder and estimates from online maps. The horizontal lines in the image are almost parallel which indicates the good quality of and . In this way, we cross-checked the camera parameters obtained earlier. Obviously, all vehicles are in contact with the road surface.
We do not need to remove distortions (radial and perspective) from all video frames to estimate traffic statistics. The object detection or instance segmentation works with original video frames in . We use the distortions compensation for traffic measurements to obtain distances in meters for selected pixels. We calculate the needed maps once for the camera parameters and Q and use them as needed for measurements. Let us demonstrate this on a specific trajectory.
The detected trajectory of the vehicle consists of 252 contours, 180 of which are in . A total of 200 contours in the image look messy, so we draw every 20th (Figure 7). We deliberately did not choose rectangles to demonstrate a more general case. Vertex coordinates describe the contour. It is enough to select one point on or inside each contour to evaluate the speed or acceleration of an object. The point should not move around the object; we want the point source closer to the road’s surface. The left bottom corner of a contour is well suited for this camera. However, what does it mean for a polygon? For a contour we can build the pixel coordinates
We call the left bottom corner of a contour the vertex for that
considering the axes direction of the . Another option is to search the point nearest to on the edges of the contour with the help of (19).
We map all contour vertexes on the to obtain Figure 8. However, we need to map only these “corners” for measurements.
The “corners” of the selected contours have the following coordinates after the mapping:
We can use a variety of formulas to estimate speed, acceleration, and variation. The simplest estimation of the vehicle speed is (the camera frame rate is 25 frames/second, we use 1/20 of the frames):
or km/h.
5.2. Example 2. More Radial Distortion and Vegetation, More Calibration Points
Figure 9 illustrates a frame image from another public camera of the same operator. This camera has zero horizon tilt and more substantial radial distortion. We have calibrated the camera and calculated the maps in the season of rich vegetation. Tree foliage complicates the selection and estimation of coordinates of points. The two-way road is visible to the camera. This is a FullHD camera (). The zero horizon tilt is visible on the line near (see Table 4). We select the point as the origin of (see Table 4). We assess global coordinates of the point O (the camera position), point G (the source of the principal point C, Figure 1, Figure 9), and points and on the lines (index u) or (index v). Next, we convert the global coordinates to and append them to Table 4.
We obtained estimations and using Formulas (15) and (16) and Table 4 data. There are a few points, but one can assume a pattern . Perhaps the camera’s sensor pixel has a rectangular shape (see (4)). Consider the two hypotheses:
The second variant means the square pixel.
Let us try variant (50). With and we obtained the intrinsic parameters matrix A (1). We estimate radial distortion coefficients and , put and to compute the mapping (17), and apply it to eliminate radial distortion from the (). We obtained the undistorted image (see Figure 10). We showed a cropped and interpolated version of in Example 1 (Figure 4). Let us demonstrate the result of mapping without postprocessing. The image’s resolution is , but it contains only pixels colored by the camera. So, the black grid is the unfilled pixels of the large rectangular.
Let us return to the illustration that is more pleasing to the eye by cutting off part of and filling the void with interpolation (see Figure 11).
We noted that in the field of view of the camera, there is a section of the wall of the building (near ), allowing you to put (see Figure 9). We are ready to compute the orientation matrix R (20)–(26), so we can convert coordinates to (27). We select the points to approximate the road surface (see Table 5).
We choose four corners of and of in the image (see Table 6 and Figure 12). Let us try the nonrectangular area .
We calculate the lines that bound domain with (41) and detect the set of pixel coordinates that belongs to . We compute the as with (48) and (35)–(39). Next, we convert the pixel coordinates from to with (43)–(47) and (49) and save the result.
The distances in Q correspond to estimates obtained online and a simple rangefinder (accuracy up to a meter). We plan more accurate assessments using the geodetic tools.
We repeat the needed steps for hypothesis (51) and compare the results (see Figure 12 and Figure 13).
We observed a change in the geometry of for the hypothesis (51). For example, the pedestrian crossing changed its inclination; the road began to expand to the right. In this example, it is not easy to obtain several long parallel lines due to vegetation, and it is an argument for examining the cameras in a suitable season.
6. Conclusions
This work is an extension of the technology of road traffic data collection described in [4] to allow accurate car density and speed measurements using physical units with compensation for perspective and radial distortion.
Although we processed video frames in the article, all the mappings obtained for measurements () transform only coordinates. We used the pixel content of the images only for demonstrations. In the context of measurements, object detection (or instance segmentation) and object tracking algorithms work with pixel colors. The mappings work with the pixel coordinates of the results of these algorithms. We can calculate the discrete maps once and use them until the camera parameters or the Q area change. In this sense, the computational complexity of mapping generation is not particularly important. We plan to refine estimates of camera parameters as new data on the actual geometry of the ROI area will be available, and the accuracy of the maps will increase. Evaluating or refining the camera parameters in a suitable season might be better.
Author Contributions
Investigation, A.Z. and E.N.; Software, A.Z.; Visualization, A.Z.; Writing—original draft, A.Z.; Writing—review & editing, A.Z. and E.N. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been supported by the project 075-02-2022-880 of Ministry for Science and Higher Education of the Russian Federation from 31 January 2022.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Xinqiang, C.; Shubo, W.; Chaojian, S.; Yanguo, H.; Yongsheng, Y.; Ruimin, K.; Jiansen, Z. Sensing Data Supported Traffic Flow Prediction via Denoising Schemes and ANN: A Comparison. IEEE Sens. J. 2020, 20, 14317–14328. [Google Scholar]
- Xiaohan, L.; Xiaobo, Q.; Xiaolei, M. Improving Flex-route Transit Services with Modular Autonomous Vehicles. Transp. Res. Part E Logist. Transp. Rev. 2021, 149, 102331. [Google Scholar]
- 75 Years of the Fundamental Diagram for Traffic Flow Theory: Greenshields Symposium TRB Transportation Research Electronic Circular E-C149. 2011. Available online: http://onlinepubs.trb.org/onlinepubs/circulars/ec149.pdf (accessed on 17 September 2022).
- Zatserkovnyy, A.; Nurminski, E. Neural network analysis of transportation flows of urban agglomeration using the data from public video cameras. Math. Model. Numer. Simul. 2021, 13, 305–318. [Google Scholar]
- Camera Calibration and 3D Reconstruction. OpenCV Documentation Main Modules. Available online: https://docs.opencv.org/4.5.5/d9/d0c/group__calib3d.html (accessed on 18 March 2022).
- Szeliski, R. Computer Vision: Algorithms and Applications, 2nd ed.; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- Transformations between ECEF and ENU Coordinates. ESA Naupedia. Available online: https://gssc.esa.int/navipedia/index.php/Transformations_between_ECEF_and_ENU_coordinates (accessed on 18 March 2022).
- Forsyth, D.A.; Ponce, J. Computer Vision: A Modern Approach, 2nd ed.; Pearson: Hoboken, NJ, USA, 2012. [Google Scholar]
- Peng, S.; Sturm, P. Calibration Wizard: A Guidance System for Camera Calibration Based on Modeling Geometric and Corner Uncertainty. arXiv 2019, arXiv:1811.03264. [Google Scholar]
- Camera Calibration. OpenCV tutorials, Python. Available online: http://docs.opencv.org/4.x/dc/dbb/tutorial_py_calibration.html (accessed on 18 March 2022).
- Marchand, E.; Uchiyama, H.; Spindler, F. Pose estimation for augmented reality: A hands-on survey. IEEE Trans. Vis. Comput. Graph. 2016, 22, 2633–2651. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perspective-n-Point (PnP) Pose Computation. OpenCV documentation. Available online: https://docs.opencv.org/4.x/d5/d1f/calib3d_solvePnP.html (accessed on 18 March 2022).
- Liu, C.-M.; Juang, J.-C. Estimation of Lane-Level Traffic Flow Using a Deep Learning Technique. Appl. Sci. 2021, 11, 5619. [Google Scholar] [CrossRef]
- Khazukov, K.; Shepelev, V.; Karpeta, T.; Shabiev, S.; Slobodin, I.; Charbadze, I.; Alferova, I. Real-time monitoring of traffic parameters. J. Big Data 2020, 7, 84. [Google Scholar] [CrossRef]
- Zhengxia, Z.; Zhenwei, S. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055v2. [Google Scholar]
- Huchuan, L.; Dong, W. Online Visual Tracking; Springer: Singapore, 2019. [Google Scholar]
- Yandex Maps. Available online: https://maps.yandex.ru (accessed on 18 March 2022).
Figure 1.
Coordinate frames , . are the image of the 3D point P. Axis follows the camera optical axis. The camera forms a real image on the image sensor behind aperture O in the plane ; however, the equivalent virtual image in the plane is preferable in illustrations.
Figure 1.
Coordinate frames , . are the image of the 3D point P. Axis follows the camera optical axis. The camera forms a real image on the image sensor behind aperture O in the plane ; however, the equivalent virtual image in the plane is preferable in illustrations.

Figure 2.
Virtual and real images for a camera with aperture O. The scene is projected on the plane of frame . The coordinates of the point P in are denoted by , and the are coordinates of points on the axis U of frame .
Figure 2.
Virtual and real images for a camera with aperture O. The scene is projected on the plane of frame . The coordinates of the point P in are denoted by , and the are coordinates of points on the axis U of frame .

Figure 3.
Field of view of the public street camera in Vladivostok. Example 1, image .

Figure 4.
The image after compensation of radial distortion. Example 1, image .

Figure 5.
The image rotated by around the optical axis of the camera.

Figure 6.
The set visualization in plane , by the colors of the pixels from . Given the geometry of the sample, is the horizontal axis, the vertical.
Figure 6.
The set visualization in plane , by the colors of the pixels from . Given the geometry of the sample, is the horizontal axis, the vertical.

Figure 7.
Every twentieth contour of a vehicle’s trajectory in the original image .

Figure 8.
Every twentieth contour in the vehicle’s trajectory mapped on the with the selected points.
Figure 8.
Every twentieth contour in the vehicle’s trajectory mapped on the with the selected points.

Figure 9.
Field of view of the public street camera in Vladivostok. Example 2, image .

Figure 10.
The image after compensation of radial distortion; Example 2, image without postprocessing.
Figure 10.
The image after compensation of radial distortion; Example 2, image without postprocessing.

Figure 11.
Cropped and interpolated part of image .

Figure 12.
The set visualization in plane for case (50).
Figure 12.
The set visualization in plane for case (50).

Figure 13.
The set visualization in plane for case (51).
Figure 13.
The set visualization in plane for case (51).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The points used for the calibration. Latitude and longitude in degrees, altitudes and ENU coordinates in meters, coordinates of pixels in units (u is the column index, v is the row).
Table 1.
The points used for the calibration. Latitude and longitude in degrees, altitudes and ENU coordinates in meters, coordinates of pixels in units (u is the column index, v is the row).
| Name | Lat | Long | Height | u | v | |||
|---|---|---|---|---|---|---|---|---|
| 56 | 0 | 0 | 0 | |||||
| G | 57 | 960 | 540 | 1 | ||||
| O | 98 | 42 | ||||||
| 57 | 1534 | 540 | 1 | |||||
| 52 | 960 | 353 |
Table 2.
The spatial points used for the road plane approximation (global and coordinates); coordinates are in meters.
Table 2.
The spatial points used for the road plane approximation (global and coordinates); coordinates are in meters.
| Num | Lat | Long | Height | |||
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 59 | |||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | 56 | |||||
| 8 | ||||||
| 9 | 56 |
Table 3.
Domain corners coordinates in .
| Corner | Name | u | v |
|---|---|---|---|
| top left | 504 | 849 | |
| bottom left | 739 | 1079 | |
| top right | 1468 | 410 | |
| bottom right | 1642 | 462 |
Table 4.
The points used for the calibration. Latitude and longitude are in degrees, altitudes and ENU coordinates are in meters, and coordinates of pixels are in units (u is the column index, v is the row).
Table 4.
The points used for the calibration. Latitude and longitude are in degrees, altitudes and ENU coordinates are in meters, and coordinates of pixels are in units (u is the column index, v is the row).
| Name | Lat | Long | Height | u | v | |||
|---|---|---|---|---|---|---|---|---|
| 14 | 0 | 0 | 0 | |||||
| G | 25 | 960 | 540 | |||||
| O | 56 | |||||||
| 18 | 306 | 540 | ||||||
| 15 | 960 | 671 | ||||||
| 14 | 1559 | 540 | ||||||
| 960 | 815 | |||||||
| 43 | 960 | 199 |
Table 5.
The points used to approximate road plane (global and coordinates, and altitudes given in meters).
Table 5.
The points used to approximate road plane (global and coordinates, and altitudes given in meters).
| Num | Lat | Long | Height | |||
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | ||||||
| 3 | 14 | |||||
| 4 | ||||||
| 6 | 15 | |||||
| 7 | 14 | |||||
| 8 | 14 | |||||
| 9 | 14 | |||||
| 10 | 14 | |||||
| 11 |
Table 6.
Domain corners coordinates in , Example 2.
| Corner | Name | u | v |
|---|---|---|---|
| top left | 509 | 962 | |
| bottom left | 993 | 1078 | |
| top right | 1630 | 498 | |
| bottom right | 1858 | 558 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zatserkovnyy, A.; Nurminski, E. Identification of Location and Camera Parameters for Public Live Streaming Web Cameras. Mathematics 2022, 10, 3601. https://0-doi-org.brum.beds.ac.uk/10.3390/math10193601
AMA Style
Zatserkovnyy A, Nurminski E. Identification of Location and Camera Parameters for Public Live Streaming Web Cameras. Mathematics. 2022; 10(19):3601. https://0-doi-org.brum.beds.ac.uk/10.3390/math10193601
Chicago/Turabian StyleZatserkovnyy, Aleksander, and Evgeni Nurminski. 2022. "Identification of Location and Camera Parameters for Public Live Streaming Web Cameras" Mathematics 10, no. 19: 3601. https://0-doi-org.brum.beds.ac.uk/10.3390/math10193601
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.