
Gradient-Based Optimization Algorithm for Solving Sylvester Matrix Equation



1
Key Laboratory of Intelligent Computing and Information Processing of Ministry of Education, Xiangtan University, Xiangtan 411105, China
2
Hunan Key Laboratory for Computation and Simulation in Science and Engineering, Xiangtan University, Xiangtan 411105, China
*
Author to whom correspondence should be addressed.
Mathematics 2022, 10(7), 1040; https://0-doi-org.brum.beds.ac.uk/10.3390/math10071040
Submission received: 14 February 2022
/
Revised: 17 March 2022
/
Accepted: 22 March 2022
/
Published: 24 March 2022
(This article belongs to the Special Issue Numerical Methods for Solving Nonlinear Equations)
Abstract
:In this paper, we transform the problem of solving the Sylvester matrix equation into an optimization problem through the Kronecker product primarily. We utilize the adaptive accelerated proximal gradient and Newton accelerated proximal gradient methods to solve the constrained non-convex minimization problem. Their convergent properties are analyzed. Finally, we offer numerical examples to illustrate the effectiveness of the derived algorithms.
Keywords:
Sylvester matrix equation; Kronecker product; adaptive accelerated proximal gradient method; Newton-accelerated proximal gradient methodMSC:
15A24; 65F451. Introduction
Matrix equations are ubiquitous in signal processing [1], control theory [2], and linear systems [3]. Most time-dependent models accounting for the prediction, simulation, and control of real-world phenomena may be represented as linear or nonlinear dynamical systems. Therefore, the relevance of matrix equations within engineering applications largely explains the great effort put forth by the scientific community into their numerical solution. Linear matrix equations have an important role in the stability analysis of linear dynamical systems and the theoretical development of the nonlinear system. The Sylvester matrix equation was first proposed by Sylvester and produced from the research of relevant fields in applied mathematical cybernetics. It is a famous matrix equation that occurs in linear and generalized eigenvalue problems for the computation of invariant subspaces using Riccati equations [4,5,6]. The Sylvester matrix equation takes part in linear algebra [7,8,9], image processing [10], model reduction [11], and numerical methods for differential equations [12,13].
We consider the Sylvester matrix equation of the form
where are given matrices, and is an unknown matrix to be solved. We discuss a special form of the Sylvester matrix equation, in which A and B are symmetric positive definite.
Recently, there has been a lot of discussion on the solution and numerical calculation of the Sylvester matrix equation. The standard methods for solving this equation are the Bartels–Stewart method [14] and the Hessenberg–Schur method [15], which are efficient for small and dense system matrices. When system matrices are small, the block Krylov subspace methods [16,17] and global Krylov subspace methods [18] are proposed. These methods use the global Arnoldi process, block Arnoldi process, or nonsymmetric block Lanczos process to produce low-dimensional Sylvester matrix equations. More feasible methods for solving large and sparse problems are iterative methods. When system matrices are large, there are some effective methods such as the alternating direction implicit (ADI) method [19], global full orthogonalization method, global generalized minimum residual method [20], gradient-based iterative method [21], and global Hessenberg and changing minimal residual with Hessenberg process method [22]. When system matrices are low-rank, the ADI method [23], block Arnoldi method [17], preconditioned block Arnoldi method [24], and extended block Arnoldi method [25] and its variants [26,27], including the global Arnoldi method [28,29] and extended global Arnoldi method [25], are proposed to obtain the low-rank solution.
The adaptive accelerated proximal gradient (A-APG) method [30] is an efficient numerical method for calculating the steady states of the minimization problem, motivated by the accelerated proximal gradient (APG) method [31], which has wide applications in image processing and machine learning. In each iteration, the A-APG method takes the step size by using a line search initialized with the Barzilai–Borwein (BB) step [32] to accelerate the numerical speed. Moreover, as the traditional APG method is proposed for the convex problem and its oscillation phenomenon slows down the convergence, the restart scheme has been used for speeding up the convergence. For more details, one can refer to [30] and the references therein.
The main contribution is to study gradient-based optimization methods such as the A-APG and Newton-APG methods for solving the Sylvester matrix equation through transforming this equation into an optimization problem by using Kronecker product. The A-APG and Newton-APG methods are theoretically guaranteed to converge to a global solution from an arbitrary initial point and achieve high precision. These methods are especially efficient for large and sparse coefficient matrices.
The rest of this paper is organized as follows. In Section 2, we transform this equation into an optimization problem by using the Kronecker product. In Section 3, we apply A-APG and Newton-APG algorithms to solve the optimization problem and compare them with other methods. In Section 4, we focus on the convergence analysis of the A-APG method. In Section 5, the computational complexity of these algorithms is analyzed exhaustively. In Section 6, we offer corresponding numerical examples to illustrate the effectiveness of the derived methods.
Throughout this paper, let be the set of all real matrices. is the identity matrix of order n. If , the symbols , , and express the transpose, the inverse, the 2-norm, and the trace of A, respectively. The inner product in matrix space is .
2. The Variant of an Optimization Problem
In this section, we transform the Sylvester equation into an optimization problem. We recall some definitions and lemmas.
Definition 1.
Let , the Kronecker product of Y and Z be defined by
Definition 2.
If , then the straightening operator of Y is
Lemma 1.
Let then
From Lemma 1, the Sylvester Equation (1) can be rewritten as
Lemma 2.
Let A be a symmetric positive matrix; solving the equation is equivalent to obtaining the minimum of .
According to Lemma 2 and Equation (2), define
Therefore, Equation (2) should be . Obviously, if A and B are symmetric positive, then is symmetric positive. The variant of the Sylvester Equation (2) reduces to the optimization problem:
Using the calculation of the matrix differential from [33], we have the following propositions immediately.
Proposition 1.
If , then .
Proposition 2.
If , then .
Proposition 3.
If , then .
Using Propositions 2 and 3, the gradient of the objective function (3) is
By (4), the Hessian matrix is
3. Iterative Methods
In this section, we will introduce the adaptive accelerated proximal gradient (A-APG) method and the Newton-APG method to solve the Sylvester equation. Moreover, we compare the A-APG and Newton-APG methods with other existing methods.
3.1. APG Method
The traditional APG method [31] is designed for solving the composite convex problem:
where is the finite-dimensional Hilbert space equipped with the inner product , g and f are both continuously convex, and has a Lipschitz constant L. Given initializations and , the APG method is
where and the mapping is defined as
Since our minimization problem is linear, we choose the explicit scheme. The explicit scheme is a simple but effective approach for the minimization problem. Given an initial value and the step , the explicit scheme is
where is the approximation solution. The explicit scheme satisfies the sufficient decrease property using the gradient descent (GD) method.
Let and be the current and previous states and the extrapolation weight be . Using the explicit method (6), the APG iterative scheme is
Together with the standard backtracking, we adopt the step size when the following condition holds:
for some .
3.2. Restart APG Method
Recently, an efficient and convergent numerical algorithm has been developed for solving a discretized phase-field model by combining the APG method with the restart technique [30]. Unlike the APG method, the restart technique involves choosing whenever the following condition holds:
for some . If the condition is not met, we restart the APG by setting .
The restart APG method (RAPG) is summarized in Algorithm 2.
| Algorithm 2 RAPG algorithm. |
|
3.3. A-APG Method
In RAPG Algorithm 2, we can adaptively estimate the step size by using the line search technique. Define
We initialize the search step by the Barzilai–Borwein (BB) method, i.e.,
Therefore, we obtain the A-APG algorithm summarized in Algorithm 3.
| Algorithm 3 A-APG algorithm. |
|
3.4. Newton-APG Method
Despite the fast initial convergence speed of the gradient-based methods, the tail convergence speed becomes slow. Therefore, we use a practical Newton method to solve the minimization problem. We obtain the initial value from A-APG Algorithm 3, and then choose the Newton direction as the gradient in the explicit scheme in RAPG Algorithm 2. Then we have the Newton-APG method shown in Algorithm 4.
| Algorithm 4 Newton-APG algorithm. |
|
3.5. Gradient Descent (GD) and Line Search (LGD) Methods
Moreover, we show gradient descent (GD) and line search (LGD) methods for comparing with the A-APG and Newton-APG methods. The GD and line search LGD methods are summarized in Algorithm 5.
| Algorithm 5 GD and LGD algorithms. |
3.6. Computational Complexity Analysis
Further, we analyze the computational complexity of each iteration of the derived algorithms.
The computation of APG is mainly controlled by matrix multiplication and addition operations in three main parts. The iterative scheme needs computational complexity. The backtracking linear search needs computational complexity defined by Equation (8). The extrapolation needs computational complexity defined by the Equation (7). The total computational complexity is in Algorithm 1.
The computation of RAPG is mainly controlled by matrix multiplication and addition operations in four main parts. The iterative scheme needs computational complexity. The backtracking linear search defined by Equation (8) needs computational complexity. The extrapolation defined by Equation (7) needs computational complexity. The restart defined by Equation (9) needs computational complexity. The total computational complexity is in Algorithm 2.
The computation of A-APG is mainly controlled by matrix multiplication and addition operations in four main parts. The iterative scheme needs computational complexity. The BB step and the backtracking linear search defined by Equations (8) and (10) need , , , and computational complexity. The extrapolation defined by Equation (7) needs computational complexity. The restart defined by Equation (9) needs computational complexity. The total computational complexity is in Algorithm 3.
The computation of Newton-APG is mainly controlled by matrix multiplication and addition operations in four main parts, different from the A-APG method. The iterative scheme needs computational complexity. The BB step and the backtracking linear search defined by Equations (8) and (10) need , , , and computational complexity. The extrapolation defined by Equation (7) needs computational complexity. The restart defined by Equation (9) needs computational complexity. The total computational complexity is in Algorithm 4.
4. Convergent Analysis
In this section, we focus on the convergence analysis of A-APG Algorithm 3. The following proposition is required.
Proposition 4.
Let M be a bounded region that contains in , then satisfies the Lipschitz condition in M, i.e., there exists such that
Proof.
Using the continuity of , note that
defined by (5) is bounded. Then satisfies the Lipschitz condition in M. □
In recent years, the proximal method based on the Bregman distance has been applied for solving optimization problems. The proximal operator is
Basically, given the current estimation and step size , update via
Thus we obtain
which implies that
This is exactly the explicit scheme in our algorithm.
4.1. Linear Search Is Well-Defined
Using the optimization from Equation (11), it is evident that
4.2. Sufficient Decrease Property
In this section, we show the sufficient decrease property of the sequence generated by A-APG Algorithm 3. If satisfies the condition Equation (13), then
where . Since is a bounded function, then there exists such that and as . This implies
which shows that
4.3. Bounded Gradient
Define two sets and . Let , for any , then when . There exists such that as k increases. If , since
we have
Thus,
Note that , then
where .
If , then
which implies that
Thus
4.4. Subsequence Convergence
As is compact, there exists a subsequence and such that . Then is bounded, i.e., and keeps decreasing. Hence, there exists such that . Note that
Summation over k yields
Therefore,
Due to the property of the gradient, thus
Considering the continuity of and , we have
which implies that .
4.5. Sequence Convergence
In this section, the subsequence convergence can be strengthened by using the Kurdyka–Lojasiewicz property.
Proposition 5.
For dom , there exists , an ϵ neighborhood of , and , where ψ is concave, such that for all , we have
Then we say satisfies the Kurdyka–Lojasiewicz property.
Theorem 1.
Assume that Propositions 4 and 5 are met. Let be the sequence generated by A-APG Algorithm 3. Then, there exists a point so that and .
Proof.
Let be the set of limiting points of the sequence . Based on the boundedness of and the fact that , it follows that is a non-empty and compact set. In addition, by Equation (16), we know that is a constant on , denoted by . If there exists some such that , then for , we have . Next, we assume that . Therefore, for , for we have and i.e., for . Applying Proposition 5, for , we have
Then
By the convexity of , it is obvious that
Define
Applying the geometric inequality to Equation (19), thus
Therefore, for , summing up the above inequality for , we obtain
For , it is evident that
which implies that
In the end, we have . □
5. Numerical Results
In this section, we offer two corresponding numerical examples to illustrate the efficiency of the derived algorithms. All code is written in Python language. Denote iteration and error by the iteration step and error of the objective function. We take the matrix order “n” as 128, 1024, 2048, and 4096.
Example 1.
Let
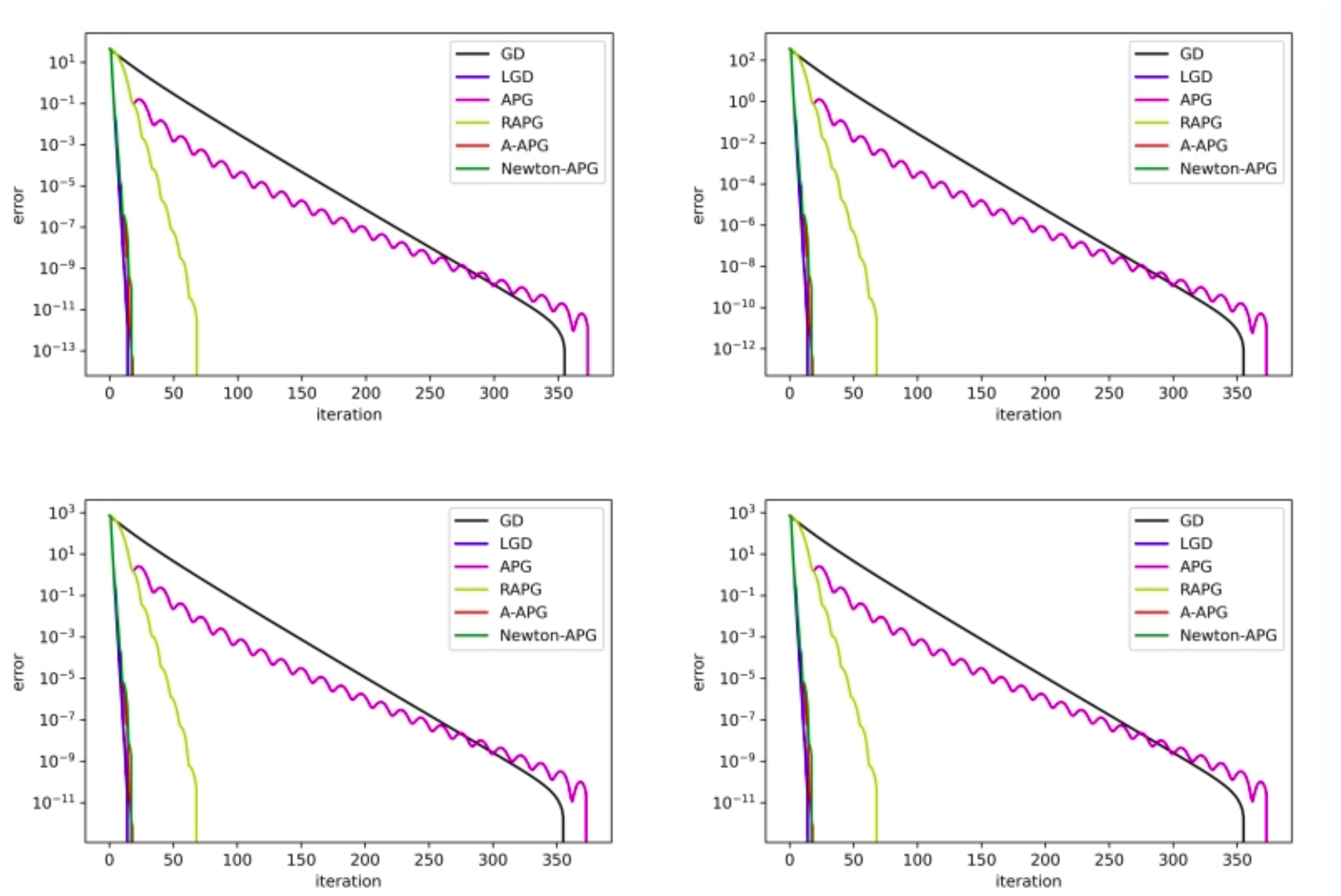
be tridiagonal matrices in the Sylvester Equation (1). Set the matrix as the identity matrix. The initial step size is 0.01, which is small enough to iterate. The parameters are taken from (0,1) randomly. Table 1 and Figure 1 show the numerical results of Algorithms 1–5. It can be seen that the LGD, A-APG, and Newton-APG Algorithms are more efficient than other methods. Moreover, the iteration step does not increase when the matrix order increases due to the same initial value. The A-APG method has higher error accuracy compared with other methods. The Newton-APG method takes more CPU time and fewer iteration steps than the A-APG method. The Newton method needs to calculate the inverse of the matrix, while it has quadratic convergence. From Figure 1, the error curves of the LGD, A-APG, and Newton-APG algorithms are hard to distinguish. We offer another example below.
Example 2.
Let be positive semi-definite matrices in the Sylvester Equation (1). Set the matrix as the identity matrix. The initial step size is 0.009. The parameters are taken from (0,1) randomly. Table 2 and Figure 2 show the numerical results of Algorithms 1–5. It can be seen that the LGD, A-APG, and Newton-APG algorithms take less CPU time compared with other methods. Additionally, we can observe the different error curves of the LGD, A-APG, and Newton-APG algorithms from Figure 2.
Remark 1.
The difference of the iteration step in Examples 1 and 2 emerges due to the given different initial values. It can be seen that the LGD, A-APG, and Newton-APG algorithms have fewer iteration steps. Whether the A-APG method or Newton-APG yields fewer iteration steps varies from problem to problem. From Examples 1 and 2, we observe that the A-APG method has higher accuracy, although it takes more time and more iteration steps than the LGD method.
Remark 2.
Moreover, we compare the performance of our methods with other methods such as the conjugate gradient method (CG) in Table 1 and Table 2. We take the same initial values and set the error to 1 × 10. From Table 1 and Table 2, it can be seen that the LGD and A-APG methods are more efficient for solving the Sylvester matrix equation when the order n is small. When n is large, the LGD and A-APG methods nearly have a convergence rate with the CG method.
6. Conclusions
In this paper, we have introduced the A-APG and Newton-APG methods for solving the Sylvester matrix equation. The key idea is to change the Sylvester matrix equation to an optimization problem by using the Kronecker product. Moreover, we have analyzed the computation complexity and proved the convergence of the A-APG method. Convergence results and preliminary numerical examples have shown that the schemes are promising in solving the Sylvester matrix equation.
Author Contributions
J.Z. (methodology, review, and editing); X.L. (software, visualization, data curation). All authors have read and agreed to the published version of the manuscript.
Funding
The work was supported in part by the National Natural Science Foundation of China (12171412, 11771370), Natural Science Foundation for Distinguished Young Scholars of Hunan Province (2021JJ10037), Hunan Youth Science and Technology Innovation Talents Project (2021RC3110), the Key Project of the Education Department of Hunan Province (19A500, 21A0116).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Dooren, P.M.V. Structured Linear Algebra Problems in Digital Signal Processing; Springer: Berlin/Heidelberg, Germany, 1991. [Google Scholar]
- Gajic, Z.; Qureshi, M.T.J. Lyapunov Matrix Equation in System Stability and Control; Courier Corporation: Chicago, IL, USA, 2008. [Google Scholar]
- Corless, M.J.; Frazho, A. Linear Systems and Control: An Operator Perspective; CRC Press: Boca Raton, FL, USA, 2003. [Google Scholar]
- Stewart, G.W.; Sun, J. Matrix Perturbation Theory; Academic Press: London, UK, 1990. [Google Scholar]
- Simoncini, V.; Sadkane, M. Arnoldi-Riccati method for large eigenvalue problems. BIT Numer. Math. 1996, 36, 579–594. [Google Scholar]
- Demmel, J.W. Three methods for refining estimates of invariant subspaces. Computing 1987, 38, 43–57. [Google Scholar]
- Chen, T.W.; Francis, B.A. Optimal Sampled-Data Control Systems; Springer: London, UK, 1995. [Google Scholar]
- Datta, B. Numerical Methods for Linear Control Systems; Elsevier Inc.: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Lord, N. Matrix computations. Math. Gaz. 1999, 83, 556–557. [Google Scholar]
- Zhao, X.L.; Wang, F.; Huang, T.Z. Deblurring and sparse unmixing for hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4045–4058. [Google Scholar]
- Obinata, G.; Anderson, B.D.O. Model Reduction for Control System Design; Springer Science & Business Media: London, UK, 2001. [Google Scholar]
- Bouhamidi, A.; Jbilou, K. A note on the numerical approximate solutions for generalized Sylvester matrix equations with applications. Appl. Math. Comput. 2008, 206, 687–694. [Google Scholar]
- Bai, Z.Z.; Benzi, M.; Chen, F. Modified HSS iteration methods for a class of complex symmetric linear systems. Computing 2010, 87, 93–111. [Google Scholar]
- Bartels, R.H.; Stewart, G.W. Solution of the matrix equation AX + XB = C. Commun. ACM 1972, 15, 820–826. [Google Scholar]
- Golub, G.H. A Hessenberg-Schur Method for the Problem AX + XB = C; Cornell University: Ithaca, NY, USA, 1978. [Google Scholar]
- Robbé, M.; Sadkane, M. A convergence analysis of GMRES and FOM methods for Sylvester equations. Numer. Algorithms 2002, 30, 71–89. [Google Scholar]
- Guennouni, A.E.; Jbilou, K.; Riquet, A.J. Block Krylov subspace methods for solving large Sylvester equations. Numer. Algorithms 2002, 29, 75–96. [Google Scholar]
- Salkuyeh, D.K.; Toutounian, F. New approaches for solving large Sylvester equations. Appl. Math. Comput. 2005, 173, 9–18. [Google Scholar]
- Wachspress, E.L. Iterative solution of the Lyapunov matrix equation. Appl. Math. Lett. 1988, 1, 87–90. [Google Scholar]
- Jbilou, K.; Messaoudi, A.; Sadok, H. Global FOM and GMRES algorithms for matrix equations. Appl. Numer. Math. 1999, 31, 49–63. [Google Scholar]
- Feng, D.; Chen, T. Gradient Based Iterative Algorithms for Solving a Class of Matrix Equations. IEEE Trans. Autom. Control 2005, 50, 1216–1221. [Google Scholar]
- Heyouni, M.; Movahed, F.S.; Tajaddini, A. On global Hessenberg based methods for solving Sylvester matrix equations. Comput. Math. Appl. 2019, 77, 77–92. [Google Scholar]
- Benner, P.; Kürschner, P. Computing real low-rank solutions of Sylvester equations by the factored ADI method. Comput. Math. Appl. 2014, 67, 1656–1672. [Google Scholar]
- Bouhamidi, A.; Hached, M.; Heyouni, M.J.; Bilou, K. A preconditioned block Arnoldi method for large Sylvester matrix equations. Numer. Linear Algebra Appl. 2013, 20, 208–219. [Google Scholar]
- Heyouni, M. Extended Arnoldi methods for large low-rank Sylvester matrix equations. Appl. Numer. Math. 2010, 60, 1171–1182. [Google Scholar]
- Agoujil, S.; Bentbib, A.H.; Jbilou, K.; Sadek, E.M. A minimal residual norm method for large-scale Sylvester matrix equations. Electron. Trans. Numer. Anal. Etna 2014, 43, 45–59. [Google Scholar]
- Abdaoui, I.; Elbouyahyaoui, L.; Heyouni, M. An alternative extended block Arnoldi method for solving low-rank Sylvester equations. Comput. Math. Appl. 2019, 78, 2817–2830. [Google Scholar]
- Jbilou, K. Low rank approximate solutions to large Sylvester matrix equations. Appl. Math. Comput. 2005, 177, 365–376. [Google Scholar]
- Liang, B.; Lin, Y.Q.; Wei, Y.M. A new projection method for solving large Sylvester equations. Appl. Numer. Math. 2006, 57, 521–532. [Google Scholar]
- Jiang, K.; Si, W.; Chen, C.; Bao, C. Efficient numerical methods for computing the stationary states of phase-field crystal models. SIAM J. Sci. Comput. 2020, 42, B1350–B1377. [Google Scholar]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar]
- Bao, C.; Barbastathis, G.; Ji, H.; Shen, Z.; Zhang, Z. Coherence retrieval using trace regularization. SIAM J. Imaging Sci. 2018, 11, 679–706. [Google Scholar]
- Magnus, J.R.; Neudecker, H. Matrix Differential Calculus; John Willey & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
Figure 1.
The error curves when n = 128, 1024, 2048, 4096 for Example 1.

Figure 2.
The error curves when n = 128, 1024, 2048, 4096 for Example 2.


{kind=link}
{kind=link}
Table 1.
Numerical results for Example 1.
| Algorithm | n | Iteration | Error | Time(s) |
|---|---|---|---|---|
| GD | 128 | 356 | 1.13687 × 10 | 3.30 |
| LGD | 128 | 15 | 1.26477 × 10 | 0.27 |
| APG | 128 | 374 | 1.4353 × 10 | 4.31 |
| RAPG | 128 | 69 | 1.4353 × 10 | 1.45 |
| A-APG | 128 | 19 | 3.55271 × 10 | 0.38 |
| Newton-APG | 128 | 18 | 9.47438 × 10 | 0.48 |
| CG | 128 | 19 | 3.49364 × 10 | 0.42 |
| GD | 1024 | 356 | 1.02318 × 10 | 806 |
| LGD | 1024 | 15 | 1.06866 × 10 | 69 |
| APG | 1024 | 374 | 1.18803 × 10 | 1261 |
| RAPG | 1024 | 69 | 2.59774 × 10 | 367 |
| A-APG | 1024 | 19 | 2.84217 × 10 | 113 |
| Newton-APG | 1024 | 18 | 8.95682 × 10 | 144 |
| CG | 1024 | 19 | 3.37046 × 10 | 71 |
| GD | 2048 | 356 | 2.04636 × 10 | 6315 |
| LGD | 2048 | 15 | 2.13731 × 10 | 569 |
| APG | 2048 | 374 | 2.38742 × 10 | 9752 |
| RAPG | 2048 | 69 | 5.20686 × 10 | 2994 |
| A-APG | 2048 | 19 | 6.82121 × 10 | 926 |
| Newton-APG | 2048 | 18 | 8.95682 × 10 | 1015 |
| CG | 2048 | 19 | 3.34616 × 10 | 521 |
| GD | 4096 | 356 | 4.09273 × 10 | 66,155 |
| LGD | 4096 | 15 | 4.27463 × 10 | 4199 |
| APG | 4096 | 374 | 4.77485 × 10 | 71,636 |
| RAPG | 4096 | 69 | 1.04365 × 10 | 21,596 |
| A-APG | 4096 | 19 | 1.81899 × 10 | 6829 |
| Newton-APG | 4096 | 18 | 3.64571 × 10 | 7037 |
| CG | 4096 | 19 | 3.33322 × 10 | 3553 |
Table 2.
Numerical results for Example 2.
| Algorithm | n | Iteration | Error | Time(s) |
|---|---|---|---|---|
| GD | 128 | 243 | 1.63425 × 10 | 2.38 |
| LGD | 128 | 20 | 2.45137 × 10 | 0.47 |
| APG | 128 | 260 | 1.58096 × 10 | 4.51 |
| RAPG | 128 | 53 | 1.90781 × 10 | 1.46 |
| A-APG | 128 | 32 | 3.55271 × 10 | 0.78 |
| Newton-APG | 128 | 36 | 2.30926 × 10 | 1.26 |
| CG | 128 | 34 | 4.13025 × 10 | 0.79 |
| GD | 1024 | 243 | 1.3074 × 10 | 516 |
| LGD | 1024 | 20 | 1.89573 × 10 | 95 |
| APG | 1024 | 260 | 1.25056 × 10 | 835 |
| RAPG | 1024 | 53 | 1.51772 × 10 | 267 |
| A-APG | 1024 | 32 | 4.61569 × 10 | 181 |
| Newton-APG | 1024 | 36 | 4.20641 × 10 | 214 |
| CG | 1024 | 34 | 4.29936 × 10 | 92 |
| GD | 2048 | 243 | 2.6148 × 10 | 4129 |
| LGD | 2048 | 20 | 3.78577 × 10 | 814 |
| APG | 2048 | 260 | 2.48974 × 10 | 6507 |
| RAPG | 2048 | 53 | 3.03544 × 10 | 2193 |
| A-APG | 2048 | 32 | 2.27374 × 10 | 1622 |
| Newton-APG | 2048 | 36 | 8.52651 × 10 | 2125 |
| CG | 2048 | 34 | 4.22694 × 10 | 797 |
| GD | 4096 | 243 | 5.22959 × 10 | 29,859 |
| LGD | 4096 | 20 | 7.54881 × 10 | 6023 |
| APG | 4096 | 260 | 4.97948 × 10 | 48,238 |
| RAPG | 4096 | 53 | 6.07088 × 10 | 16,482 |
| A-APG | 4096 | 32 | 2.27374 × 10 | 12,896 |
| Newton-APG | 4096 | 36 | 7.95808 × 10 | 14,901 |
| CG | 4096 | 34 | 4.18275 × 10 | 5337 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, J.; Luo, X. Gradient-Based Optimization Algorithm for Solving Sylvester Matrix Equation. Mathematics 2022, 10, 1040. https://0-doi-org.brum.beds.ac.uk/10.3390/math10071040
AMA Style
Zhang J, Luo X. Gradient-Based Optimization Algorithm for Solving Sylvester Matrix Equation. Mathematics. 2022; 10(7):1040. https://0-doi-org.brum.beds.ac.uk/10.3390/math10071040
Chicago/Turabian StyleZhang, Juan, and Xiao Luo. 2022. "Gradient-Based Optimization Algorithm for Solving Sylvester Matrix Equation" Mathematics 10, no. 7: 1040. https://0-doi-org.brum.beds.ac.uk/10.3390/math10071040
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.