

Modelling the Time to Write-Off of Non-Performing Loans Using a Promotion Time Cure Model with Parametric Frailty
 ,
,
Abstract
:1. Introduction
2. Background
3. Proposed Model: The Promotion Time Cure Model with Parametric Frailty
4. Estimation and Simulation
4.1. Maximum Likelihood Estimation of the PTC Model with Gamma Frailty
4.2. Simulation Study
- Generate from a Bernoulli distribution:
- If , then set ;
- If , generate , and calculatewhere is the inverse cumulative distribution function;
- Generate censoring times ;
- The simulated data are then , whereand
- Resample i.i.d from the empirical distribution function of ;
- Fit the model in (9) on the resampled data to obtain estimates . Denote the first of these by ;
- Repeat steps 1 and 2 B times to obtain .
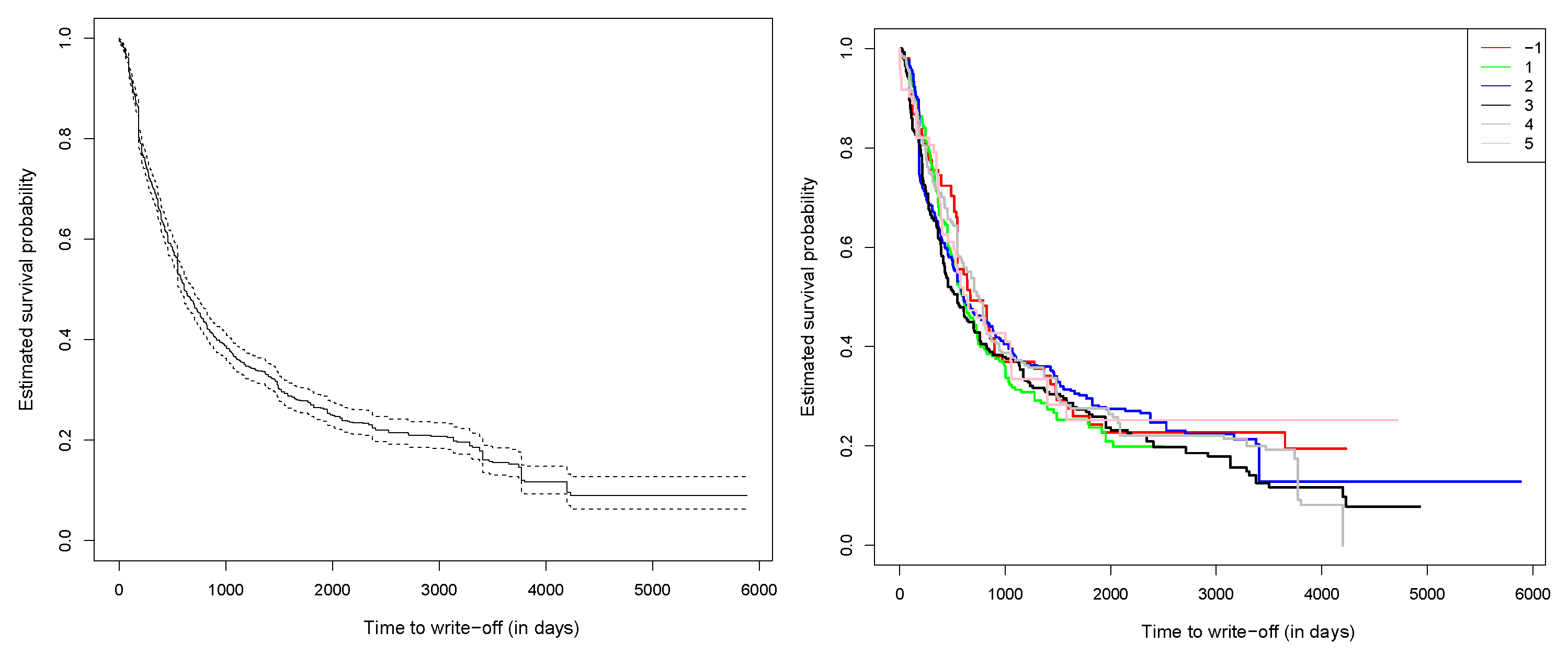
5. Application
5.1. Simulated Dataset
5.2. Real-World Dataset
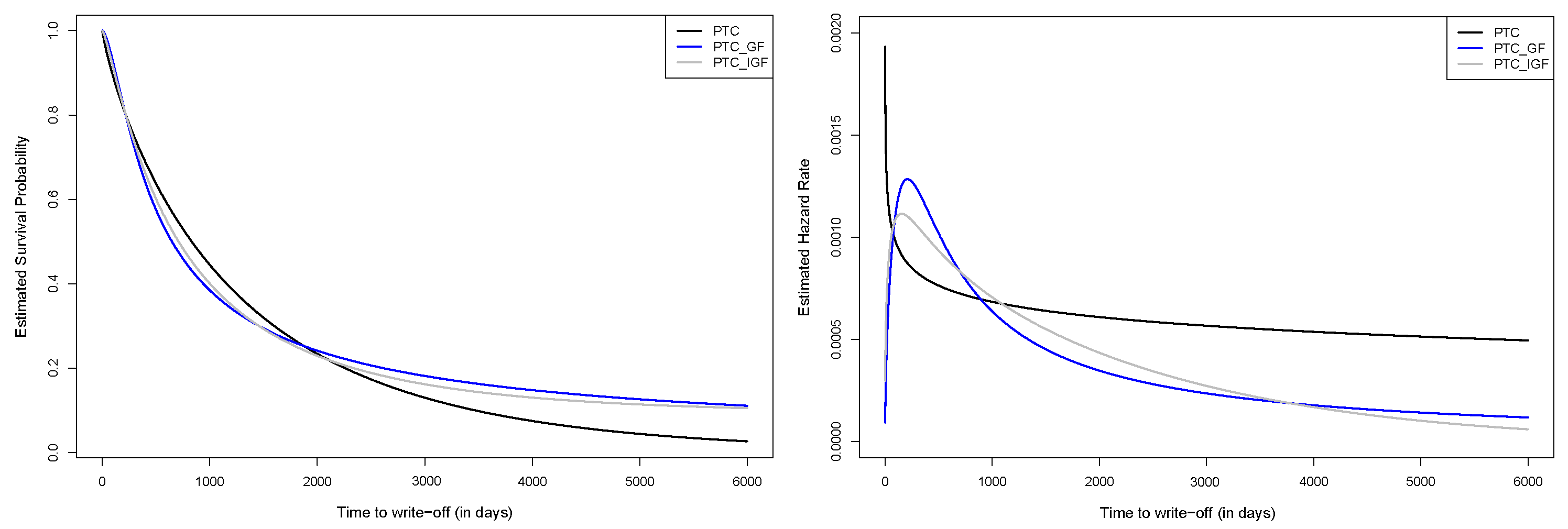
6. Extension to the Shared Gamma Frailty Model
7. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Botha, A.; Beyers, C.; De Villiers, P. Simulation-based optimisation of the timing of loan recovery across different portfolios. Expert Syst. Appl. 2021, 177, 114878. [Google Scholar] [CrossRef]
- Fenech, J.P.; Yap, Y.K.; Shafik, S. Modelling the recovery outcomes for defaulted loans: A survival analysis approach. Econ. Lett. 2016, 145, 79–82. [Google Scholar] [CrossRef]
- Betz, J.; Krüger, S.; Kellner, R.; Rösch, D. Macroeconomic effects and frailties in the resolution of non-performing loans. J. Bank. Financ. 2017, 112, 105212. [Google Scholar] [CrossRef]
- Malwandla, M.C.; Marimo, M.; Breed, D.G. A cross-sectional survival analysis regression model with applications to consumer credit risk. S. Afr. Stat. J. 2017, 51, 217–234. [Google Scholar]
- de Oliveira, M., Jr.; Louzada, F. Recovery Risk: Application of the Latent Competing Risks Model to Non-Performing Loans. arXiv 2014, arXiv:1408.4380. [Google Scholar]
- Hibbeln, M.; Gürtler, M. Pitfalls in Modeling Loss Given Default of Bank Loans. J. Bank. Financ. 2013, 37, 2354–2366. [Google Scholar]
- Allen, L.N.; Rose, L.C. Financial survival analysis of defaulted debtors. J. Oper. Res. Soc. 2006, 57, 630–636. [Google Scholar] [CrossRef]
- Joubert, M.; Verster, T.; Raubenheimer, H.G. Making use of survival analysis to indirectly model loss given default. ORiON 2019, 34, 107–132. [Google Scholar] [CrossRef]
- Tong, E.N.C.; Mues, C.; Thomas, L.C. Mixture cure models in credit scoring: If and when borrowers default. Eur. J. Oper. Res. 2012, 218, 132–139. [Google Scholar] [CrossRef]
- Smuts, M.; Allison, J.S. An overview of survival analysis with an application in the credit risk environment. ORiON 2021, 36, 89–110. [Google Scholar] [CrossRef]
- Dirick, L.; Bellotti, T.; Claeskens, G.; Baesens, B. Macro-Economic Factors in Credit Risk Calculations: Including Time-Varying Covariates in Mixture Cure Models. J. Bus. Econ. Stat. 2019, 37, 40–53. [Google Scholar] [CrossRef]
- de Oliveira, M., Jr.; Moreira, F.; Louzada, F. The zero-inflated promotion cure rate model applied to financial data on time-to-default. Cogent Econ. Financ. 2017, 5, 1395950. [Google Scholar] [CrossRef]
- Barriga, G.D.C.; Cancho, V.G.; Garibay, D.V.; Cordeiro, G.M.; Ortega, E.M. A new survival model with surviving fraction: An application to colorectal cancer data. Stat. Methods Med Res. 2018, 28, 2665–2680. [Google Scholar] [CrossRef] [PubMed]
- Leow, M.; Mues, C. Predicting loss given default (LGD) for residential mortgage loans: A two-stage model and empirical evidence for UK bank data. Int. J. Forecast. 2012, 28, 183–195. [Google Scholar] [CrossRef]
- Cox, D.R. Regression models and life-tables. J. R. Stat. Soc. Ser. B (Methodol.) 1972, 34, 187–202. [Google Scholar] [CrossRef]
- Banasik, J.; Crook, J.N.; Thomas, L.C. Not if but when will borrowers default. J. Oper. Res. Soc. 1999, 50, 1185–1190. [Google Scholar] [CrossRef]
- Stepanova, M.; Thomas, L. Survival analysis methods for personal loan data. Oper. Res. 2002, 50, 277–289. [Google Scholar] [CrossRef]
- Cao, R.; Vilar, J.M.; Devia, A. Modelling consumer credit risk via survival analysis. Sort-Stat. Oper. Res. Trans. 2009, 33, 3–30. [Google Scholar]
- Boag, J.W. Maximum likelihood estimates of the proportion of patients cured by cancer therapy. J. R. Stat. Society. Ser. B (Methodol.) 1949, 11, 15–53. [Google Scholar] [CrossRef]
- Peng, Y.; Yu, B. Cure Models: Methods, Applications, and Implementation; Chapman and Hall/CRC: Boca Raton, FL, USA, 2021. [Google Scholar]
- Berkson, J.; Gage, R.P. Survival curve for cancer patients following treatment. J. Am. Stat. Assoc. 1952, 47, 501–515. [Google Scholar] [CrossRef]
- Farewell, V.T. The use of mixture models for the analysis of survival data with long-term survivors. Biometrics 1982, 38, 1041–1046. [Google Scholar] [CrossRef] [PubMed]
- Amico, M.; van Keilegom, I. Cure models in survival analysis. Annu. Rev. Stat. Appl. 2018, 5, 311–342. [Google Scholar] [CrossRef]
- Yakovlev, A.Y.; Asselain, B.; Bardou, V.; Fourquet, A.; Hoang, T.; Rochefediere, A.; Tsodikov, A. A simple stochastic model of tumor recurrence and its application to data on premenopausal breast cancer. Biom. Anal. Donnees Spatio-Temporelles 1993, 12, 66–82. [Google Scholar]
- Chen, M.H.; Ibrahim, J.G.; Sinha, D. A New Bayesian Model For Survival Data with a Surviving Fraction. J. Am. Stat. Assoc. 1999, 94, 909–919. [Google Scholar] [CrossRef]
- Rodrigues, J.; Cancho, V.G.; de Castro, M.; Louzada-Neto, F. On the unification of long-term survival models. Stat. Probab. Lett. 2009, 79, 753–759. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, Y. A new estimation method for the semiparametric accelerated failure time mixture cure model. Stat. Med. 2007, 26, 3157–3171. [Google Scholar] [CrossRef]
- Portier, F.; El Ghouch, A.; van Keilegom, I. Efficiency and bootstrap in the promotion time cure model. Bernoulli 2017, 23, 3437–3468. [Google Scholar] [CrossRef]
- Delloye, M.; Fermanian, J.D.; Sbai, M. Dynamic frailties and credit portfolio modelling. Risk 2006, 19, 100. [Google Scholar]
- Chih-Wei, L.; Chang, M.J. A credit risk model with dynamic frailties for default intensity estimation. Asia Pac. Manag. Rev. 2008, 13, 557–566. [Google Scholar]
- Chamboko, R.; Bravo, J.M. Frailty correlated default on retail consumer loans in Zimbabwe. Int. J. Appl. Decis. Sci. 2019, 12, 257–270. [Google Scholar] [CrossRef]
- Wienke, A. Frailty Models in Survival Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2010; pp. 57–63. [Google Scholar]
- Balan, T.A.; Putter, H. A tutorial on frailty models. Stat. Methods Med Res. 2020, 29, 3424–3454. [Google Scholar] [CrossRef] [PubMed]
- Li, C.S.; Taylor, J.M.; Sy, J.P. Identifiability of cure models. Stat. Probab. Lett. 2001, 54, 389–395. [Google Scholar] [CrossRef]
- Legrand, C. Advanced Survival Models; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Dirick, L.; Claeskens, G.; Baesens, B. An Akaike information criterion for multiple event mixture cure models. Eur. J. Oper. Res. 2015, 241, 449–457. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Efron, B.; Tibshirani, R. Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy. Stat. Sci. 1986, 1, 54–75. [Google Scholar] [CrossRef]
- Claeskens, G.; Nguti, R.; Janssen, P. One-sided tests in shared frailty models. Test 2008, 17, 69–82. [Google Scholar] [CrossRef]
- Brumma, N.; Winckle, P. LGD Report 2018-Large Corporate Borrowers. SSRN 2018. [Google Scholar] [CrossRef]
- Schuermann, T. What do we know about Loss Given Default? Wharton Financial Institutions Center Working Paper. SSRN 2004. [Google Scholar] [CrossRef]
- Khieu, H.D.; Mullineaux, D.J.; Yi, H.C. The determinants of bank loan recovery rates. J. Bank. Financ. 2012, 36, 923–933. [Google Scholar] [CrossRef]
- Betz, J.; Kellner, R.; Rösch, D. Time matters: How default resolution times impact final loss rates. J. R. Stat. Soc. Ser. C 2021, 70, 619–644. [Google Scholar] [CrossRef]
- Emura, T.; Chen, Y.H. Analysis of Survival Data with Dependent Censoring: Copula-Based Approaches; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Deresa, N.W.; van Keilegom, I. A multivariate normal regression model for survival data subject to different types of dependent censoring. Comput. Stat. Data Anal. 2020, 144, 106879. [Google Scholar] [CrossRef]
- Deresa, N.W.; van Keilegom, I.; Antonio, K. Copula-based inference for bivariate survival data with left truncation and dependent censoring. Insur. Math. Econ. 2022, 107, 1–21. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Parameter | ||||
|---|---|---|---|---|
| PTC with gamma frailty and a Weibull distribution | ||||
| 2.314 (0.988) | 2.165 (0.706) | 2.120 (0.512) | 2.049 (0.330) | |
| −1.035 (0.191) | −1.016 (0.154) | −1.016 (0.116) | −1.004 (0.085) | |
| 2.047 (0.347) | 2.025 (0.276) | 2.017 (0.216) | 2.011 (0.152) | |
| 2.070 (1.217) | 2.064 (0.988) | 2.027 (0.782) | 1.998 (0.560) | |
| 1.018 (0.113) | 1.012 (0.090) | 1.009 (0.069) | 1.002 (0.048) | |
| 0.517 (0.302) | 0.506 (0.247) | 0.516 (0.179) | 0.502 (0.127) | |
| PTC with gamma frailty and a LFR distribution | ||||
| 2.318 (0.833) | 2.199 (0.651) | 2.170 (0.493) | 2.110 (0.353) | |
| −1.059 (0.195) | −1.028 (0.152) | −1.022 (0.108) | −1.009 (0.076) | |
| 2.103 (0.361) | 2.050 (0.262) | 2.029 (0.197) | 2.023 (0.135) | |
| 1.338 (0.804) | 1.391 (0.682) | 1.381 (0.551) | 1.398 (0.415) | |
| 3.337 (4.018) | 2.820 (2.966) | 2.531 (2.510) | 2.257 (1.882) | |
| 0.569 (0.308) | 0.529 (0.238) | 0.528 (0.161) | 0.513 (0.107) | |
| PTC with IG frailty and a Weibull distribution | ||||
| 2.556 (1.461) | 2.385 (1.227) | 2.312 (1.018) | 2.107 (0.496) | |
| −1.079 (0.234) | −1.057 (0.210) | −1.050 (0.167) | −1.018 (0.122) | |
| 2.134 (0.447) | 2.110 (0.407) | 2.089 (0.330) | 2.040 (0.231) | |
| 2.228 (1.346) | 2.181 (1.044) | 2.096 (0.806) | 2.046 (0.558) | |
| 1.060 (0.168) | 1.051 (0.159) | 1.042 (0.130) | 1.016 (0.090) | |
| 1.638 (3.506) | 1.554 (3.553) | 1.213 (2.284) | 0.768 (1.261) | |
| PTC with IG frailty and a LFR distribution | ||||
| 2.344 (0.973) | 2.226 (0.703) | 2.183 (0.497) | 2.106 (0.332) | |
| −1.058 (0.184) | −1.035 (0.150) | −1.023 (0.105) | −1.012 (0.077) | |
| 2.095 (0.337) | 2.069 (0.278) | 2.037 (0.196) | 2.028 (0.139) | |
| 1.362 (0.816) | 1.382 (0.673) | 1.374 (0.551) | 1.404 (0.402) | |
| 3.459 (4.147) | 3.052 (3.301) | 2.585 (2.561) | 2.350 (2.054) | |
| 0.927 (1.549) | 0.886 (2.742) | 0.637 (0.503) | 0.567 (0.293) | |
| Parameter | ||||
|---|---|---|---|---|
| PTC with gamma frailty and a Weibull distribution | ||||
| 0.789 (0.887) | 0.686 (0.755) | 0.581 (0.409) | 0.546 (0.254) | |
| −1.067 (0.245) | −1.023 (0.189) | −1.022 (0.141) | −1.010 (0.102) | |
| 2.097 (0.426) | 2.038 (0.337) | 2.020 (0.247) | 2.021 (0.179) | |
| 2.153 (1.188) | 2.078 (0.982) | 2.077 (0.751) | 1.999 (0.533) | |
| 1.039 (0.135) | 1.020 (0.109) | 1.013 (0.079) | 1.005 (0.055) | |
| 0.595 (0.480) | 0.530 (0.375) | 0.525 (0.273) | 0.517 (0.182) | |
| PTC with gamma frailty and a LFR distribution | ||||
| 0.812 (0.874) | 0.695 (0.591) | 0.618 (0.395) | 0.579 (0.262) | |
| −1.092 (0.264) | −1.039 (0.200) | −1.030 (0.142) | −1.014 (0.098) | |
| 2.158 (0.494) | 2.073 (0.361) | 2.038 (0.252) | 2.029 (0.175) | |
| 1.328 (0.830) | 1.344 (0.669) | 1.399 (0.518) | 1.409 (0.370) | |
| 3.045 (3.104) | 2.705 (2.683) | 2.476 (2.226) | 2.145 (1.645) | |
| 0.671 (0.578) | 0.572 (0.401) | 0.548 (0.280) | 0.526 (0.174) | |
| PTC with IG frailty and a Weibull distribution | ||||
| 0.958 (1.203) | 0.802 (0.950) | 0.746 (0.791) | 0.623 (0.433) | |
| −1.095 (0.271) | −1.062 (0.241) | −1.054 (0.205) | −1.033 (0.146) | |
| 2.164 (0.51) | 2.135 (0.466) | 2.108 (0.383) | 2.069 (0.286) | |
| 2.202 (1.254) | 2.206 (1.014) | 2.131 (0.771) | 2.018 (0.521) | |
| 1.070 (0.179) | 1.060 (0.166) | 1.050 (0.137) | 1.023 (0.100) | |
| 2.139 (5.047) | 1.988 (4.589) | 1.544 (3.243) | 1.045 (2.389) | |
| PTC with IG frailty and a LFR distribution | ||||
| 0.932 (0.970) | 0.829 (0.970) | 0.690 (0.488) | 0.628 (0.341) | |
| −1.098 (0.266) | −1.068 (0.235) | −1.038 (0.170) | −1.028 (0.120) | |
| 2.168 (0.483) | 2.142 (0.426) | 2.080 (0.318) | 2.058 (0.238) | |
| 1.256 (0.795) | 1.298 (0.684) | 1.350 (0.558) | 1.374 (0.412) | |
| 3.138 (3.305) | 2.888 (2.833) | 2.584 (2.381) | 2.248 (1.888) | |
| 5.661 (70.567) | 2.762 (20.101) | 1.108 (2.504) | 0.781 (1.191) | |
| Parameter | PTC | PTC with Gamma Frailty | PTC with IG Frailty |
|---|---|---|---|
| k | |||
| * | |||
| * | |||
| log-likelihood | |||
| AIC | |||
| BIC |
| Industry Group | Industry Description | Frequency | Censored | |
|---|---|---|---|---|
| 1 | Primary Industries | Agriculture, Hunting and Forestry | ||
| Fishing and Fishing Products | ||||
| Mining | ||||
| 2 | Manufacturing, Utilities and Construction | Manufacturing | ||
| Utilities | ||||
| Construction | ||||
| 3 | Trade Industries | Wholesale and Retail Trade | ||
| Transportation and Storage | ||||
| 4 | Service Industries | Hotels and Restaurants | ||
| Finance and Insurance | ||||
| Real Estate Rental and Leasing | ||||
| Professional, Scientific and Technical Services | ||||
| Private Sector Services (Household) | ||||
| 5 | Other | Communications | ||
| Public Administration and Defence | ||||
| Education | ||||
| Health and Social Services | ||||
| Other Community, Social and Personal Services | ||||
| −1 | Unknown | Unknown | ||
| Parameter | PTC | PTC with Gamma Frailty | PTC with IG Frailty | PTC with Shared Frailty |
|---|---|---|---|---|
| 3.920 | 6.968 | 2.141 | 0.843 | |
| −0.025 | −0.021 | −0.029 | −0.023 | |
| 0.187 | 0.094 | 0.134 | ||
| 0.037 | 0.254 | 0.083 | ||
| 0.175 | 0.501 | 0.297 | ||
| 0.050 | 0.064 | 0.093 | ||
| 0.076 | 0.168 | 0.117 | ||
| 4.462 | 4.644 | 2.523 | 3.343 | |
| k | 0.852 | 1.579 | 1.327 | 1.073 |
| 2.157 * | 3.926 | |||
| 2.360 * | ||||
| log-likelihood | −8813.626 | −8735.423 | −8753.194 | −8787.344 |
| AIC | 17,645.200 | 17,490.850 | 17,526.390 | 17,584.690 |
| BIC | 17,693.412 | 17,544.358 | 17,579.900 | 17,611.444 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Larney, J.; Allison, J.S.; Grobler, G.L.; Smuts, M. Modelling the Time to Write-Off of Non-Performing Loans Using a Promotion Time Cure Model with Parametric Frailty. Mathematics 2023, 11, 2228. https://0-doi-org.brum.beds.ac.uk/10.3390/math11102228
Larney J, Allison JS, Grobler GL, Smuts M. Modelling the Time to Write-Off of Non-Performing Loans Using a Promotion Time Cure Model with Parametric Frailty. Mathematics. 2023; 11(10):2228. https://0-doi-org.brum.beds.ac.uk/10.3390/math11102228
Chicago/Turabian StyleLarney, Janette, James Samuel Allison, Gerrit Lodewicus Grobler, and Marius Smuts. 2023. "Modelling the Time to Write-Off of Non-Performing Loans Using a Promotion Time Cure Model with Parametric Frailty" Mathematics 11, no. 10: 2228. https://0-doi-org.brum.beds.ac.uk/10.3390/math11102228