
Cloud Services User’s Recommendation System Using Random Iterative Fuzzy-Based Trust Computation and Support Vector Regression
 , , , ,
, , , , 
Abstract
:1. Introduction
2. Related Works
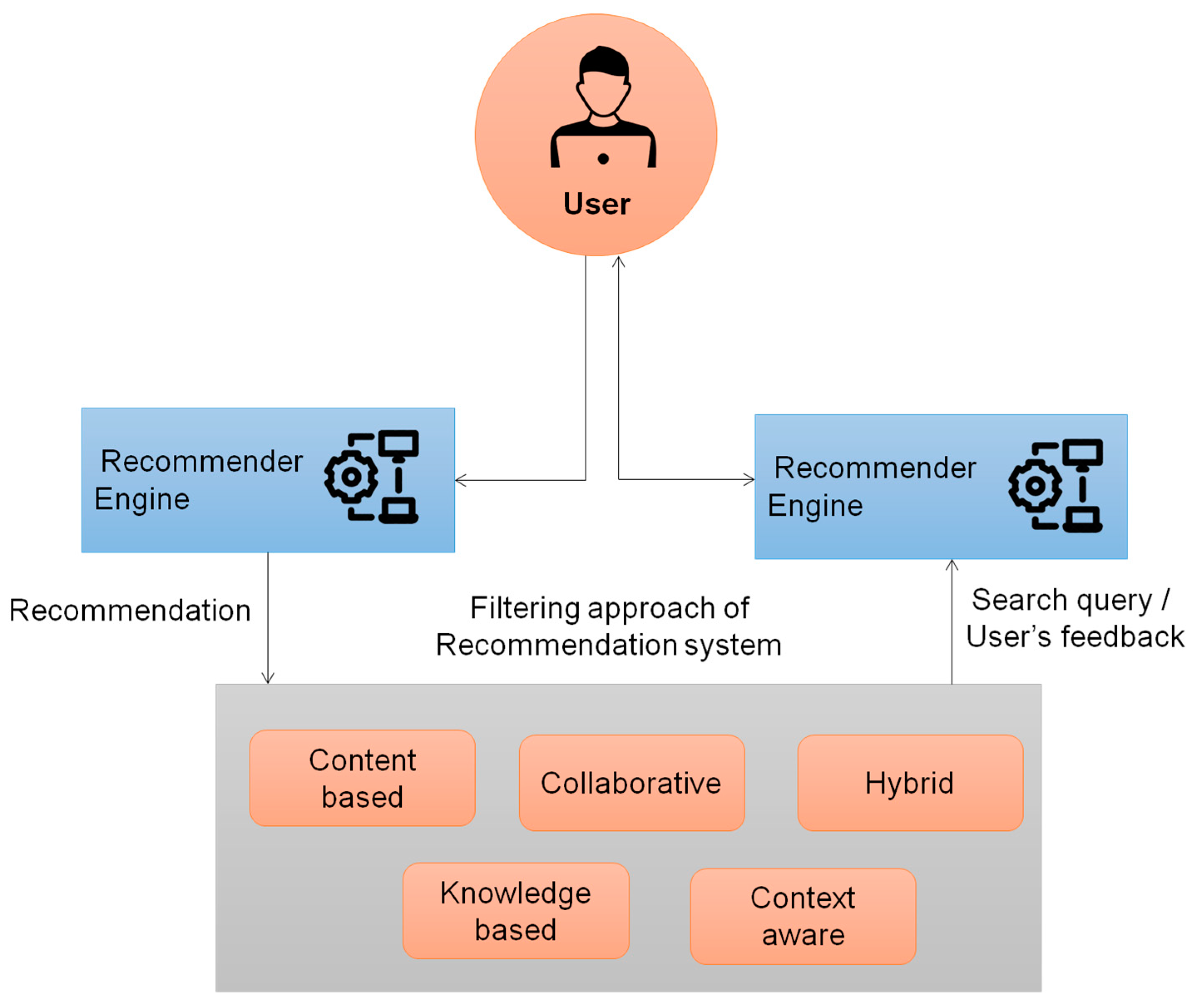
3. Proposed Methodology
3.1. Random Iterative Fuzzy Based Trust Computation (RIFTC)
- I.
- Fuzzy inputs have three states with a 0 to 1 range: low, medium, and high.
- II.
- Fuzzy outputs have a range of 0 to 1 and three states: low, medium, and high.
3.2. Support Vector Regression
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zain, T.; Aslam, M.; Imran, M.R.; Martinez-Enriquez, A.M. Cloud service recommender system using clustering. In Proceedings of the 2014 11th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE), Ciudad del Carmen, Campeche, Mexico, 29 September–3 October 2014. [Google Scholar]
- Balaji, B.S.; Karthikeyan, N.K.; Raj Kumar, R.S. Fuzzy service conceptual ontology system for cloud service recommendation. Comput. Electr. Eng. 2018, 69, 435–446. [Google Scholar] [CrossRef]
- Saleh, R.A.; Driss, M.; Almomani, I. CBiLSTM: A hybrid deep learning model for efficient reputation assessment of cloud services. IEEE Access 2022, 10, 35321–35335. [Google Scholar] [CrossRef]
- Song, F.; Liu, Y.; Jin, W.; Tan, J.; He, W. Data-Driven Feedforward Learning With Force Ripple Compensation for Wafer Stages: A Variable-Gain Robust Approach. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 1594–1608. [Google Scholar] [CrossRef]
- Tang, W.; Yan, Z. CloudRec: A mobile cloud service recommender system based on adaptive QoS management. In Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015. [Google Scholar]
- Abbas, A.; Bilal, K.; Zhang, L.; Khan, S.U. A cloud based health insurance plan recommendation system: A user centered approach. Future Gener. Comput. Syst. 2015, 43–44, 99–109. [Google Scholar] [CrossRef]
- Cao, B.; Zhao, J.; Lv, Z.; Yang, P. Diversified personalized recommendation optimization based on mobile data. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2133–2139. [Google Scholar] [CrossRef]
- Dai, X.; Xiao, Z.; Jiang, H.; Alazab, M.; Lui, J.C.S.; Min, G.; Dustdar, S.; Liu, J. Task offloading for cloud-assisted fog computing with dynamic service caching in enterprise management systems. IEEE Trans. Industr. Inform. 2023, 19, 662–672. [Google Scholar] [CrossRef]
- Preethi, G.; Krishna, P.V.; Obaidat, M.S.; Saritha, V.; Yenduri, S. Application of Deep Learning to Sentiment Analysis for recommender system on cloud. In Proceedings of the 2017 International Conference on Computer, Information and Telecommunication Systems (CITS), Dalian, China, 21–23 July 2017. [Google Scholar]
- Sun, L.; Hou, J.; Xing, C.; Fang, Z. A Robust Hammerstein-Wiener Model Identification Method for Highly Nonlinear Systems. Processes 2022, 10, 2664. [Google Scholar] [CrossRef]
- Mo, Y.; Chen, J.; Xie, X.; Luo, C.; Yang, L.T. Cloud-based mobile multimedia recommendation system with user behavior information. IEEE Syst. J. 2014, 8, 184–193. [Google Scholar] [CrossRef]
- Kong, D.; Zhai, Y. Trust based recommendation system in service-oriented cloud computing. In Proceedings of the 2012 International Conference on Cloud and Service Computing, Shanghai, China, 22–24 November 2012. [Google Scholar]
- Ding, S.; Li, Y.; Wu, D.; Zhang, Y.; Yang, S. Time-aware cloud service recommendation using similarity-enhanced collaborative filtering and ARIMA model. Decis. Support Syst. 2018, 107, 103–115. [Google Scholar] [CrossRef]
- Phasinam, K.; Kassanuk, T.; Shinde, P.P.; Thakar, C.M.; Sharma, D.K.; Mohiddin, M.K.; Rahmani, A.W. Application of IoT and cloud computing in automation of agriculture irrigation. J. Food Qual. 2022, 2022, 8285969. [Google Scholar] [CrossRef]
- Mezni, H.; Abdeljaoued, T. A cloud services recommendation system based on Fuzzy Formal Concept Analysis. Data Knowl. Eng. 2018, 116, 100–123. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, P.; Gui, K.; Wu, X. An Abstract Syntax Tree based static fuzzing mutation for vulnerability evolution analysis. Information and Software Technology. Inf. Softw. Technol. 2023, 158, 107194. [Google Scholar] [CrossRef]
- Rahhali, M.; Oughdir, L.; Jedidi, Y.; Lahmadi, Y.; El Khattabi, M.Z. E-learning recommendation system based on cloud computing. In Lecture Notes in Electrical Engineering; Springer: Singapore, 2022; pp. 89–99. [Google Scholar]
- Chen, J.; Li, K.; Rong, H.; Bilal, K.; Yang, N.; Li, K. A disease diagnosis and treatment recommendation system based on big data mining and cloud computing. Inf. Sci. 2018, 435, 124–149. [Google Scholar] [CrossRef]
- Aznoli, F.; Navimipour, N.J. Cloud services recommendation: Reviewing the recent advances and suggesting the future research directions. J. Netw. Comput. Appl. 2017, 77, 73–86. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y. A personalized clustering-based and reliable trust-aware QoS prediction approach for cloud service recommendation in cloud manufacturing. Knowl. Based Syst. 2019, 174, 43–56. [Google Scholar] [CrossRef]
- Deebak, B.D.; Al-Turjman, F. A novel community-based trust aware recommender systems for big data cloud service networks. Sustain. Cities Soc. 2020, 61, 102274. [Google Scholar] [CrossRef]
- Velusamy, D.; Pugalendhi, G. Water cycle algorithm tuned fuzzy expert system for trusted routing in smart grid communication network. IEEE Trans. Fuzzy Syst. 2020, 28, 1167–1177. [Google Scholar] [CrossRef]
- Gayathri, R.; Rani, S.U.; Čepová, L.; Rajesh, M.; Kalita, K. A Comparative Analysis of Machine Learning Models in Prediction of Mortar Compressive Strength. Processes 2022, 10, 1387. [Google Scholar] [CrossRef]
- Gupta, K.K.; Kalita, K.; Ghadai, R.K.; Ramachandran, M.; Gao, X.-Z. Machine learning-based predictive modelling of biodiesel production—A comparative perspective. Energies 2021, 14, 1122. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Niazmardi, S. A novel multiple-kernel support vector regression algorithm for estimation of water quality parameters. Nat. Resour. Res. 2021, 30, 3761–3775. [Google Scholar] [CrossRef]
- Kalita, K.; Shinde, D.S.; Ghadai, R.K. Machine Learning-Based Predictive Modelling of Dry Electric Discharge Machining Process. In Data-Driven Optimization of Manufacturing Processes; IGI Global: Hershey, PA, USA, 2021; pp. 151–164. [Google Scholar]
- Narayanan, G.; Joshi, M.; Dutta, P.; Kalita, K. PSO-tuned support vector machine metamodels for assessment of turbulent flows in pipe bends. Eng. Comput. 2020, 37, 981–1001. [Google Scholar] [CrossRef]
- Li, X.; Sun, Y. Stock intelligent investment strategy based on support vector machine parameter optimization algorithm. Neural Comput. Appl. 2020, 32, 1765–1775. [Google Scholar] [CrossRef]
- Indira, K.; Kavithadevi, M.K. Efficient machine learning model for movie recommender systems using multi-cloud environment. Mob. Netw. Appl. 2019, 24, 1872–1882. [Google Scholar] [CrossRef]
- Kesarwani, A.; Khilar, P.M. Development of trust based access control models using fuzzy logic in cloud computing. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 1958–1967. [Google Scholar] [CrossRef]
- Ageed, Z.S.; Ibrahim, R.K.; Sadeeq, M.A.M. Unified ontology implementation of cloud computing for distributed systems. Curr. J. Appl. Sci. Technol. 2020, 39, 82–97. [Google Scholar] [CrossRef]
- Eisa, M.; Younas, M.; Basu, K.; Awan, I. Modelling and simulation of QoS-aware service selection in cloud computing. Simul. Model. Pract. Theory 2020, 103, 102108. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | TRSC [30] | Cloud Rec [31] | Clustering [18] | QoS Aware Service [32] | RIFTC+SVR |
|---|---|---|---|---|---|
| 1 | 2.5 | 2.2 | 1.8 | 1.99 | 1.5 |
| 2 | 2.6 | 2.3 | 1.9 | 2.1 | 1.7 |
| 3 | 2.8 | 2.5 | 2.1 | 2.3 | 1.9 |
| 4 | 2.9 | 2.67 | 2.2 | 2.45 | 2.1 |
| 5 | 3 | 2.98 | 2.35 | 2.78 | 2.3 |
| Data Set | TRSC [30] | Cloud Rec [31] | Clustering [18] | QoS Aware Service [32] | RIFTC+SVR |
|---|---|---|---|---|---|
| 1 | 5.5 | 6 | 9.86 | 15 | 16.33 |
| 2 | 6 | 9.5 | 11 | 13.5 | 19 |
| 3 | 7 | 7.98 | 13 | 12.63 | 20 |
| 4 | 8.63 | 11 | 16.33 | 14 | 23.91 |
| 5 | 9 | 9.8 | 14.56 | 11 | 25.99 |
| Data Set | TRSC [30] | Cloud Rec [31] | Clustering [18] | QoS Aware Service [32] | RIFTC+SVR |
|---|---|---|---|---|---|
| 1 | 63 | 54 | 35 | 15 | 99 |
| 2 | 82 | 70 | 42 | 27 | 90 |
| 3 | 25 | 42 | 62 | 32 | 93 |
| 4 | 71 | 37 | 79 | 42 | 96 |
| 5 | 42 | 63 | 81 | 62 | 97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramesh, J.V.N.; Khasim, S.; Abbas, M.; Shaik, K.; Rahman, M.Z.U.; Elangovan, M. Cloud Services User’s Recommendation System Using Random Iterative Fuzzy-Based Trust Computation and Support Vector Regression. Mathematics 2023, 11, 2332. https://0-doi-org.brum.beds.ac.uk/10.3390/math11102332
Ramesh JVN, Khasim S, Abbas M, Shaik K, Rahman MZU, Elangovan M. Cloud Services User’s Recommendation System Using Random Iterative Fuzzy-Based Trust Computation and Support Vector Regression. Mathematics. 2023; 11(10):2332. https://0-doi-org.brum.beds.ac.uk/10.3390/math11102332
Chicago/Turabian StyleRamesh, Janjhyam Venkata Naga, Syed Khasim, Mohamed Abbas, Kareemulla Shaik, Mohammad Zia Ur Rahman, and Muniyandy Elangovan. 2023. "Cloud Services User’s Recommendation System Using Random Iterative Fuzzy-Based Trust Computation and Support Vector Regression" Mathematics 11, no. 10: 2332. https://0-doi-org.brum.beds.ac.uk/10.3390/math11102332