
Advance Landslide Prediction and Warning Model Based on Stacking Fusion Algorithm
1
School of Computer Science and Information Security, Guilin University of Electronic Technology, Guilin 541004, China
2
Information and Communication School, Guilin University of Electronic Technology, Guilin 541004, China
*
Author to whom correspondence should be addressed.
Mathematics 2023, 11(13), 2833; https://0-doi-org.brum.beds.ac.uk/10.3390/math11132833
Submission received: 25 May 2023
/
Revised: 21 June 2023
/
Accepted: 21 June 2023
/
Published: 24 June 2023
(This article belongs to the Special Issue Artificial Intelligence and Data Science)
Abstract
:In landslide disaster warning, a variety of monitoring and warning methods are commonly adopted. However, most monitoring and warning methods cannot provide information in advance, and serious losses are often caused when landslides occur. To advance the warning time before a landslide, an innovative advance landslide prediction and warning model based on a stacking fusion algorithm using Baishuihe landslide data is proposed in this paper. The Baishuihe landslide area is characterized by unique soil and is in the Three Gorges region of China, with a subtropical monsoon climate. Based on Baishuihe historical data and real-time monitoring of the landslide state, four warning level thresholds and trigger conditions for each warning level are established. The model effectively integrates the results of multiple prediction and warning submodels to provide predictions and advance warnings through the fusion of two stacking learning layers. The possibility that a risk priority strategy can be used as a substitute for the stacking model is also discussed. Finally, an experimental simulation verifies that the proposed improved model can not only provide advance landslide warning but also effectively reduce the frequency of false warnings and mitigate the issues of traditional single models. The stacking model can effectively support disaster prevention and reduction and provide a scientific basis for land use management.
1. Introduction
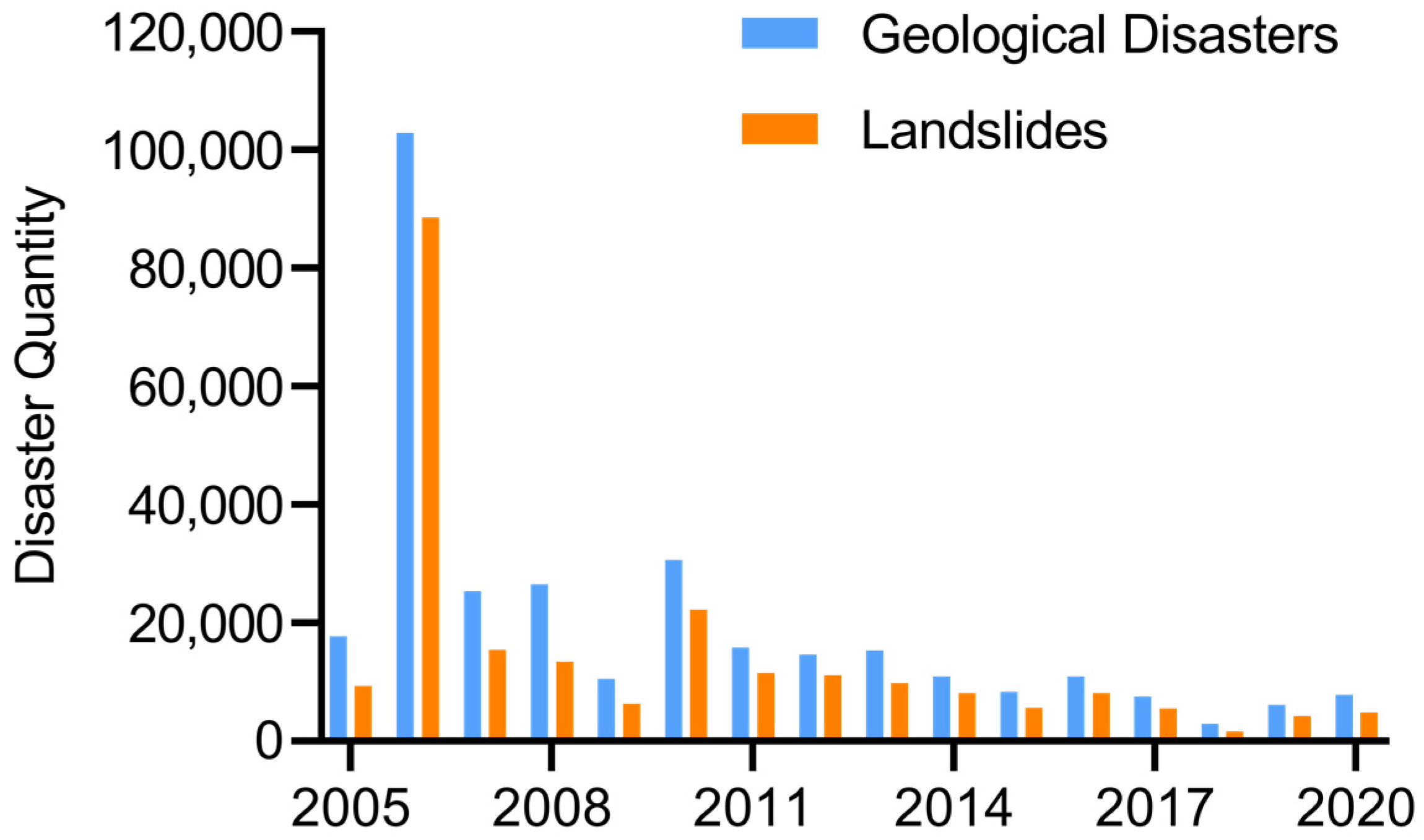
A landslide is a rock and soil mass phenomenon on a slope under the combined actions of gravity, earthquakes, rainfall, human engineering activities and other internal and external causes, which lead to broad or local sliding along a specific sliding surface and in a given sliding direction [1]. Landslide disasters are widely distributed worldwide and occur frequently every year, seriously affecting human engineering construction, operations and safety [2]. With the acceleration of human engineering activities and the intensification of global climate change, the number of landslide disasters is increasing yearly. Landslides are frequent and widespread destructive processes, causing casualties and damage worldwide [3]. China is one of the countries most seriously affected by landslide disasters due to its vast territory, large north–south span, high terrain in the west, low terrain in the east, tropical, subtropical and temperate heat zones and widespread mountains and hills [4]. According to the China Statistical Yearbook 2021 [5] prepared by the National Bureau of Statistics of China, from 2005 to 2020, the direct economic loss was 67.3 billion yuan, with 14,295 casualties and countless indirect economic losses. The number of casualties and direct economic losses caused by geological disasters in this period are shown in Figure 1.
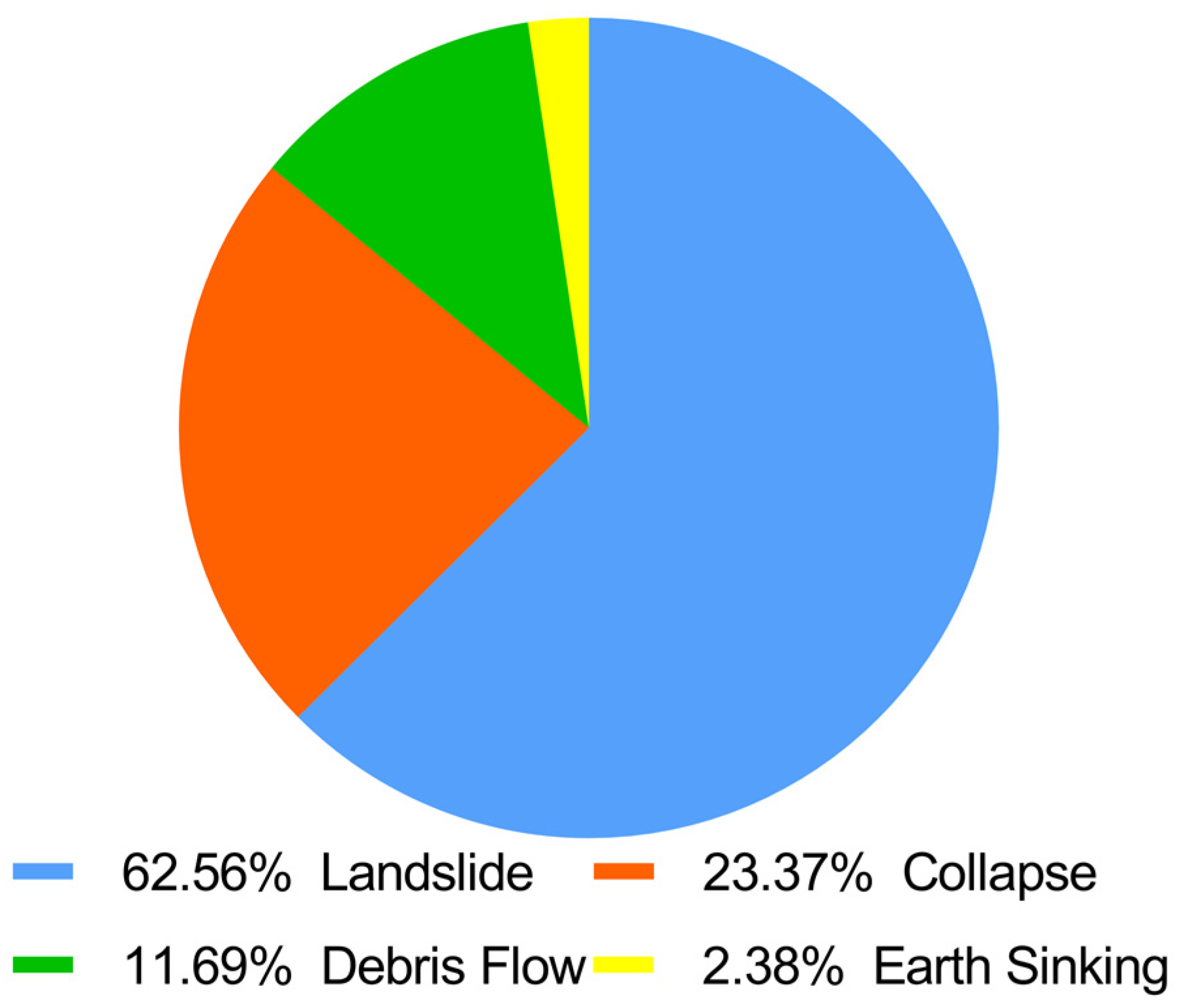
In 2020, a total of 4810 landslides occurred in China, accounting for 61.3% of geological disasters. Figure 2 shows the composition of geological disaster types in China in that year. During the period from 2005 to 2020, based on the available data, a total of 314,309 geological disasters occurred, including 226,022 landslides, accounting for 72% of the geological disasters. The numbers of geological disasters and landslides in this period are shown in Figure 3. Landslide disasters account for the majority of geological disasters in China every year [6], resulting in extensive property losses and casualties. Therefore, landslide warnings are important, and risks must be predicted in advance to enable people to take countermeasures to effectively address those risks [7].
Landslide warnings are important measures to actively prevent and control landslide disasters and avoid casualties and property losses. Landslide generation and evolution are generally long processes, accompanied by surface displacement, surface cracks and other external manifestations. Therefore, an early warning model can be adopted to warn of landslide disasters [8]. An early warning model is key to providing successful early warnings for geological disasters, and many scholars have extensively explored and developed such models. Moreover, artificial intelligence technology is proving successful in many fields [9]. Machine learning is an important area of research in artificial intelligence, with corresponding methods used to model and accurately predict future events based on experience [10]. Therefore, in recent years, landslide warning methods have been increasingly based on machine learning.
Shruti et al. used a combination of cluster analysis and regression analysis for the first time to determine the rainfall threshold that triggered the Amburi landslide event in Kerala, India, analyzed the slope stability in this region and used a probabilistic infinite slope analysis model (PISA-m) to provide early warnings in areas prone to landslides [11]. Weather data can be obtained through various methods, such as rain meters, weather models and weather radar, and Fausto et al. proposed a commercial landslide warning system that included a weather-induced rainfall threshold, distributed slope stability and soil water balance; this approach was designed, implemented, modified and verified in Italy [12]. Nengpan et al. used real-time measured surface displacement combined with a rainfall early warning system to predict slope instability and the probability of debris flow and evaluated the performance of an early warning system by comparing the inverse velocity model (INV) and gradient model (SLO) in terms of slope failure time [13]. To ensure the continuity of landslide warning systems and the rights of community partners, Brain et al. proposed a human-centered early landslide warning system that included problem analysis, action planning and preliminary reflection meetings [14]. Binru et al. considered the important role of soil moisture in the early stage of the landslide initiation process and noted that changes in the rainfall threshold with changes in soil moisture during the early stage of initiation could improve the early warning effect. They proposed that the probability threshold was more appropriate than the rainfall threshold in terms of reducing false alarms [15]. Qingling et al. introduced a disaster preidentification method based on the rapid prediction of groundwater level change. They believed that groundwater level was the key factor for urban landslides caused by heavy rainfall in mountainous areas. Two time series indices, namely, rainfall and the surface soil water content, were introduced as the key factors affecting water level change, and a landslide early warning system in mountainous areas using sliding windows was constructed [16]. Elias et al. used TRMM and ERA-Interim data to compare correlation and extreme precipitation indices of precipitation data from three different sources; additionally, a landslide warning system based on rainfall predictions and a rainfall threshold was established [17]. Qiang et al. developed adaptive data acquisition technology and established a real-time landslide warning system. They introduced the whole process, real-time monitoring method and multicriteria threshold warning function of the warning system in detail [18]. Qulin et al. used monitoring data from a variety of sensors, proposed a spatiotemporal registration method and an ensemble Kalman filter (EnKF) tracking algorithm for targets and built a prediction model to construct a landslide early warning system by optimizing problems and targets. The disadvantage of this system is that it requires the comprehensive acquisition of multipoint landslide monitoring data to provide early warnings [19]. Michele et al. analyzed the performance of the Alerta-Rio rainfall and landslide warning system, divided Rio de Janeiro into four warning areas and realized landslide warning through rainfall monitoring [20]. Luca et al. discussed a variety of early warning systems for rain-induced landslides in mountainous areas and concluded that such landslide early warning systems usually adopt intensity duration thresholds and often use meteorological simulations to predict expected rainfall to issue early warnings within a given advance time [21].
Minu et al. found that empirical and probabilistic methods for defining rainfall thresholds are part of rainfall landslide early warning systems. They improved traditional probabilistic methods to consider the influence of soil moisture and used the average soil moisture obtained from remote sensing data to improve the setting of traditional meteorological thresholds [22]. Ma Gorzata et al. proposed a landslide warning system based on a dendrochronology method. In this method, the landslide activity accurately recorded in seasonal tree rings is used, and analyses of the eccentricity of tree rings can lead to catastrophic landslide warnings [23]. Piciullo et al. proposed a regional warning model of rain-induced landslides based on a frequency method and rainfall threshold and tested it in the landslide-prone area of the Campania region in southern Italy [24]. Loew et al. described a 210,000 m3 rock slope early warning system in Preonzo village (Swiss Alps); a crack extension meter and automatic total station were used to continuously monitor displacement and provide early rock slope warnings by developing alarm thresholds for public alerts and evacuations [25]. Based on data for 229 landslide-related rainfall events in Sicily from 2002 to 2012, Gariano et al. considered the rainfall threshold in a man-made experience area to be a key element for landslide warning and used a comprehensive guided nonparametric technique to determine the uncertainty of this threshold [26]. Joon et al. proposed and verified a landslide warning method that used two different rainfall thresholds and a fixed geological attribute (landslide susceptibility) threshold for statistical evaluation and applied statistical and physical thresholds, in turn, in a decision algorithm [27]. Pecoraro et al. described and analyzed the monitoring strategies implemented in local landslide early warning systems operating worldwide, most of which use a rainfall monitoring method as the core of the early warning system; additionally, the monitoring network used in each system was introduced [28]. Samuele et al. described a regional landslide early warning system based on a statistical rainfall threshold. Over 20 years of practical application, the system constantly collected and incorporated new modeling data to improve the reliability of early warnings [29].
Moritz et al. designed a landslide warning system based on various types of monitoring sensors, which, in combination with flexible data management and analysis systems, yielded a good benefit-to-cost ratio [30]. Minu et al. discussed a comprehensive approach that considered both rainfall thresholds and field monitoring data and used tilt sensors to reduce false alarms generated due to the use of empirical rainfall thresholds [31]. Yan et al. developed a multiparameter comprehensive monitoring system to realize landslide warning considering the complexity of pipeline landslides [32]. Zongji et al. combined hydrodynamic analysis and real-time monitoring data from long time series to implement a multivariate landslide early warning method; multivariate indicators such as the rainfall intensity-probability (I-P), saturation (Si) and dip angle (Lr) were used [33]. Won et al. determined the probability of landslide occurrence based on a Bayesian model; the model considered landslide rainfall conditions and various rainfall variables, and the warning levels were divided into four types [34]. Prakash et al. designed a landslide early warning system that included an extension meter, soil moisture sensor, rain gauge and solar panel and sent real-time alerts through a global mobile signal system (GSM) network [35]. Yuan et al. built a BP neural network and comprehensively considered factors such as earthquakes, rainstorms, human activities, landslide displacement, slope and soil texture to predict and analyze the possible causes of landslides [36]. Musheng et al. used a rainfall detector, global navigation satellite system and depth displacement sensor to monitor the internal states of landslides and related external factors, and based on generalized evidence theory, integrated monitoring data were used to make the final decision [37].
Qinghua et al. conducted a rainfall landslide model test and established a model of the reservoir water level and its change over time as well as a warning threshold for two kinds of landslides with different permeabilities [38]. Benjamin et al. integrated real-time underground hydrological measurements into a landslide warning standard, clarified the utility of calculating precursor humidity and combined real-time underground hydrological monitoring with empirical rainfall thresholds to improve the landslide warning level [39]. Feiyue et al. studied a two-stage monitoring system to record multiple real-time data at the time of landslide occurrence and finally established a landslide stability early warning system composed of landslide stability analysis results, multifactor monitoring data and early warning indicators obtained based on a case-based reasoning method [40]. Geethu et al. explored the effect of previous rainfall and proposed a threshold equation and a study of the effect of previous rainfall on landslides to help strengthen the real-time landslide early warning system (R-LEWS) developed for Sikkim [41]. Yuxin et al. used effective rainfall to explore the optimal combination of rainfall and soil moisture, including both separate and combined modeling of rainfall and soil moisture. Landslide prediction was carried out using support vector machine, logistic regression and three decision tree models [42]. Rosa et al. introduced rainfall and landslide datasets collected during Gloria storms and applied a fuzzy verification method to evaluate the performance of the Gloria regional landslide early warning system (LEWS) during storms [43]. Ascanio et al. defined a three-dimensional rainfall threshold to improve the operation performance of landslide warning systems. The threshold was represented as a plane rather than a straight line, which could effectively reduce warning system false alarms [44]. Chien-Yuan et al. proposed a technique for the interactive analysis of rainfall parameters using three-dimensional regression analysis and established a regression model for landslide rainfall warning based on the average rainfall intensity, effective cumulative rainfall and rainfall duration [45]. Minu et al. used the Sistema Integrato Gestione Monitoraggion Allerta (SIGMA) model and real-time field monitoring, accounting for both long-term and short-term rainfall, to establish a landslide early warning system for the Darjeeling Himalayas [46]. Faming et al. used the landslide sensitivity map and critical rainfall threshold to test a warning system for rainfall-induced landslide disasters [47].
However, most existing landslide warning models adopt a threshold monitoring and warning method [11,12,13,14,15,16,17,18,19,20,21,22,23]. Although the real-time warning performance is good, advance warnings are not effectively obtained. A prediction algorithm can increase the advance of early warnings [48], thus increasing the time for landslide disaster prevention and mitigation.
Therefore, an advance landslide prediction and warning model based on a stacking fusion algorithm is proposed in this paper. This model uses a deep learning stacking integration and fusion algorithm, combined with multiple landslide displacement prediction models previously studied by the author [49,50,51]. Advance prediction and warning technology is established to provide advance landslide warning. In this paper, the Baishuihe landslide in the Three Gorges region of China is used as the research area, research on the landslide disaster warning model is carried out and the ability of the model is successfully verified. This research promotes the application of artificial intelligence in the field of landslide disaster warning, effectively supports the ongoing geological disaster warning projects in China and provides important theoretical significance and application value. Additionally, overcoming the fusion issues noted in several previous studies is a key step.
2. Materials and Methods
To construct a reasonable stacking model, a variety of methods and models, such as the MIC method, stacking fusion algorithm, LSTM and BiLSTM models and LightGBM model, are used. The MIC method is used to quantitatively calculate the relationships between landslides and influencing factors. Notably, the factors that have the highest correlations with landslides are selected. The stacking fusion algorithm is used to fuse multiple subprediction and warning models to obtain the final warning result. The LSTM and BiLSTM models are used to construct the five base learners in the first layer of the stacking model because they are good at handling nonlinear and time series data. The LightGBM model acts as a metalearner for the second layer of the stacking model, stores the results of the first layer and aids in generating final warnings.
2.1. Maximal Information Coefficient
Since landslides are comprehensively affected by complex environments, the early warning model proposed in this paper adopts a maximum information coefficient (MIC) method to select influential factors with the greatest relevance to include in early warning analyses. The MIC reflects the correlations among attributes and was proposed by Reshef et al. [52] in 2011. The MIC method quantifies the relationships between variables based on mutual information, and it can measure the complex relationship between variables, such as linear relationships, nonlinear relationships and nonfunctional relationships [53]. The MIC method is also an optimal discretization method, and mutual information is normalized, with mutual information values converted to the range of [0, 1]. The greater the MIC between two variables is, the stronger the correlation between the two. When two variables have a strictly determined relationship Y = f(x), this relationship is not limited to the functional form, and the MIC is equal to 1. The smaller the MIC of two variables is, the smaller the correlation between them. When the MIC is equal to 0, the two variables are independent [54].
The MIC is characterized by a certain universality; that is, any function between variables is applicable. At the same time, fairness is retained; that is, the same result can be obtained for the same level of noise with different functional forms. For the variable and the variable , the mutual information associated with U and V is expressed as shown in Equation (1):
where and are the edge probability density functions of variables and , respectively, and is the joint probability density function of and . For two variables, and , the dataset is divided into an grid. For each grid, the probability that a point falls within it is calculated for all points, resulting in a binary dataset for the grid . The dataset is divided using one of many division methods. For each partition, the mutual information is calculated, and the maximum value of all partitions is determined based on Equation (2):
The mutual information is different when the number of columns or rows varies. For random variables and , the formula for calculating the MIC is given in Equation (3):
where N is the number of samples and B(N) is the function of samples, indicating that the total number of grid units is less than B(N). It is very important to set an appropriate B(N). The value of B(N) is closely related to the universality of the MIC algorithm with the maximum information coefficient. If the value is too small, the universality of the algorithm will be reduced so that only simple relations can be detected. If the value is too large, it will lead to false associations in the case of limited samples. When B(N) = N0.6 [50,51], the effect is best, and this value is used in this study.
2.2. Stacking Fusion Algorithm
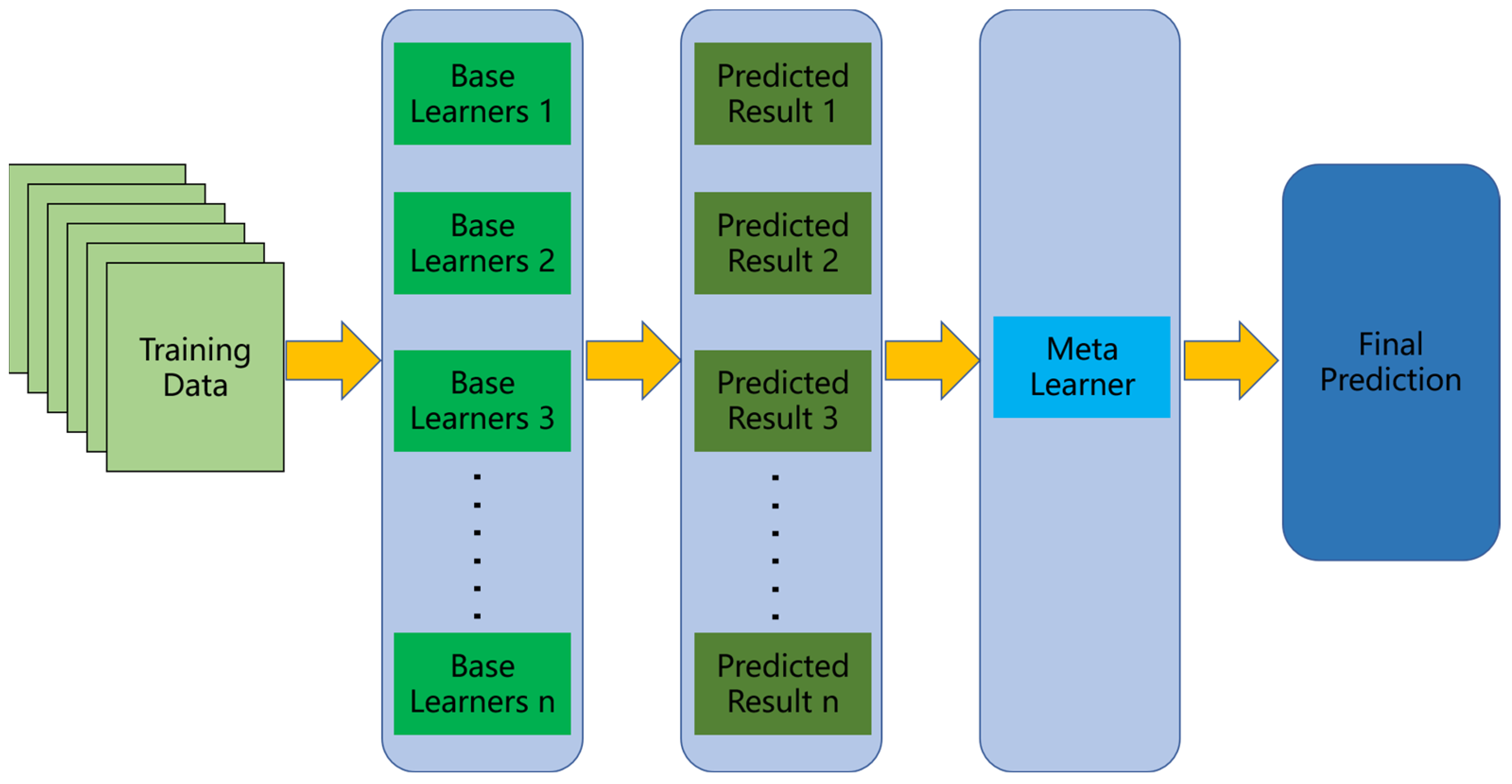
This study uses a stacking fusion algorithm to integrate multiple landslide warning models to improve the accuracy of comprehensive landslide warnings. The fusion system is designed with a two-layer structure, which not only strengthens the learning effect but also avoids the redundancy and complexity of traditional prediction models, guarantees sufficient prediction accuracy and shortens the run time. The stacking fusion algorithm can be used to solve classification, regression and sorting problems. The training process is relatively simple and does not require the adjustment of many hyperparameters. The algorithm structure is shown in Figure 4.
A stacking fusion algorithm is an artificial intelligence model based on statistical learning that combines multiple algorithms [55]. Generally, for a single AI model, the performance is characterized by diminishing marginal utility. A stacking fusion algorithm is an integrated artificial intelligence model [56] that combines the results of multiple submodels to generate a new model [57]. The steps in the stacking fusion algorithm are as follows.
- 1.
- K base learners are selected to form the first layer of the stacking fusion algorithm warning model, and a metalearner is selected to form the second layer of the stacking fusion algorithm warning model. The selection of basic learners and metalearners to optimize the warning effect can be based on experience, the use of popular models or expert guidance.
- 2.
- For the dataset , where is the warning result corresponding to the nth sample, is the characteristic data associated with the nth sample, and the data are decomposed randomly into datasets of the same dimension . is the training set of the kth fold in k-fold cross verification. If in is , then is the kth test set in k-fold cross-validation. The trained model , where , is obtained using to train the kth base learner.
- 3.
- uses the early warning to obtain the result according to the applied model and then obtains N early warning results for the first layer . The N results are the input dataset for the second layer.
- 4.
- is the input of the second-layer metalearner , and trains according to the actual model situation to obtain a numerical result.
Combined with the previous findings of the research team, five improved models [49,50,51] based on an LSTM or a BiLSTM model are selected as the basic models for the first layer of the stacking model fusion system, and the LightGBM model is used as the second-layer prediction model. The forecasting performance of the stacking model is better than that of individual models.
2.3. LSTM and BiLSTM Models
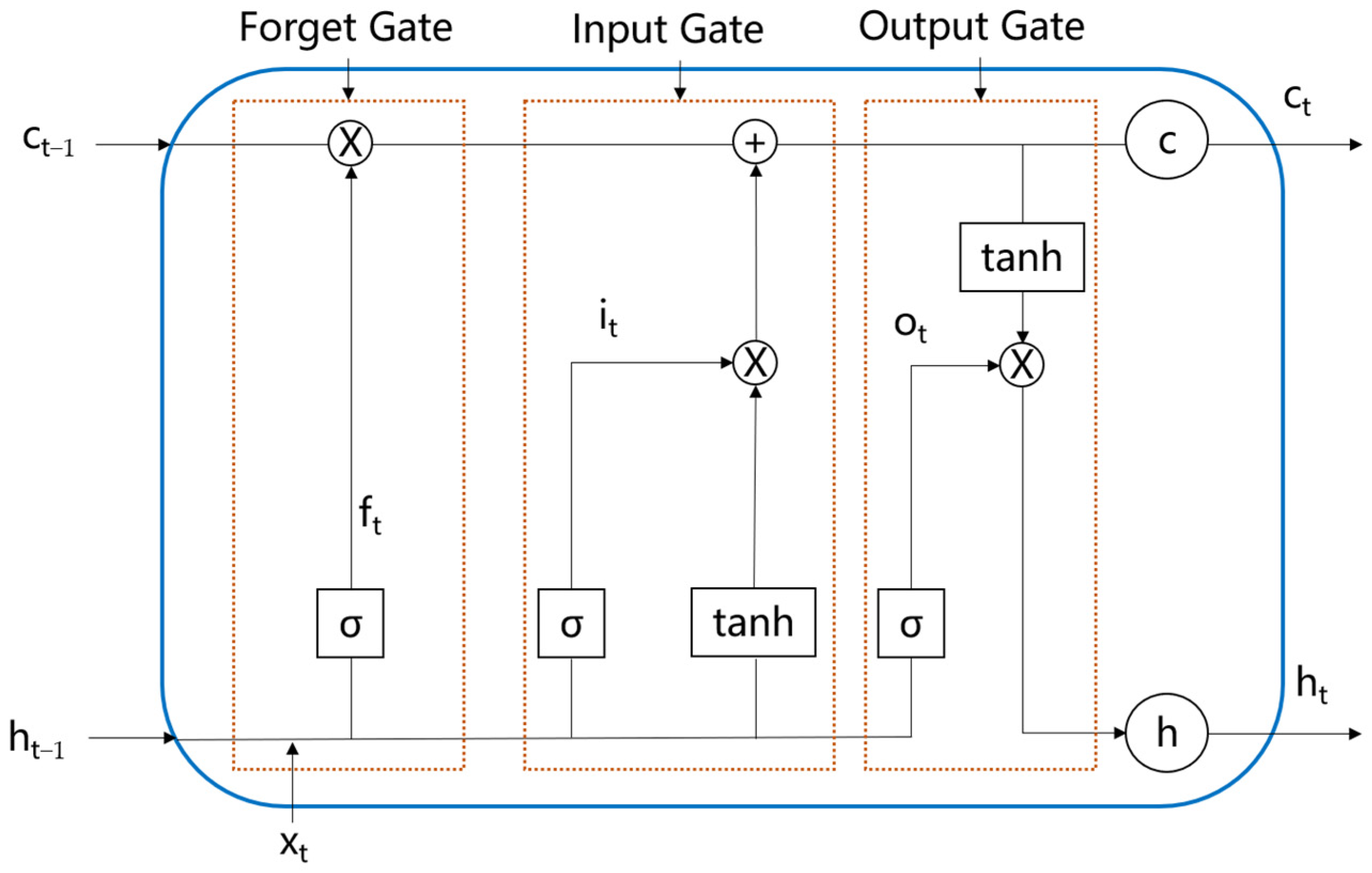
LSTM is an improved version of an RNN. Notably, three gating mechanisms are added to the traditional RNN to solve vanishing gradient and gradient explosion issues [58], and an independent transmission mechanism is formed with memory data and results; this information can then be transmitted across regions. This approach overcomes the long-order dependence problem that RNNs cannot handle certain data well. LSTM is one of the most popular cyclic neural networks. It is widely used in many fields of artificial intelligence. LSTM neurons contain three gates, namely, an input gate, an output gate and a forget gate [59]. An LSTM model stores or updates information through these gates [60]. The input gate controls what data enter a neuron, the output gate controls what data exit a neuron and the forget gate determines what memory is retained and what memory is forgotten. With these three gate structures, the LSTM model memory and output can be adjusted for different tasks. This approach will improve the efficiency and effectiveness of learning. The LSTM model structure is shown in Figure 5.
Suppose is the original dataset. The memory control gate decides which information is retained and forgotten. The formula is given in Equation (4):
where represents the output of the forget gate, is the sigmoid function, represents the weight of the forget gate and is the bias of the forget gate and represents matrix multiplication.
The input gate controls what data enter a neuron, and the corresponding formulae are shown in Equations (5) and (6):
where represents the output of the input gate, tanh represents the tanh function, is the weight of the input gate, represents the bias of the input gate, is the temporary state, is the weight of , and is the bias of .
Then, the cell state must be updated as shown in Equation (7):
where represents the current state, represents the previous state, represents the output of the input gate and represents the temporary state.
Finally, the output data are determined through the output gate, and the process is shown in Equations (8) and (9):
where represents the output of the output gate, represents the final output, represents the weight of the output of the output gate and represents the bias of the output gate.
A BiLSTM model is an improved LSTM model composed of positive and negative LSTM models; this approach can solve the problem that LSTM models cannot encode information from back to front [61]. The BiLSTM model can effectively capture the characteristics of current and historical data. The BiLSTM model structure is shown in Figure 6.
The forward-propagation output , backward-propagation output and final output of the BiLSTM model are shown in Equations (10)–(12):
where represents the input data, represents the forward LSTM output, represents the state before the forward LSTM step, represents the backward LSTM output and represents the state before the backward LSTM step [62].
Because the LSTM and BiLSTM models can be used to process time series data of landslide displacement and environmental factors that change with time, the five prediction and warning models in the first layer of the stacking model proposed in this paper are all constructed based on LSTM and BiLSTM models, namely, the LSTM model, BiLSTM model, LSTM-FC model, Double-BiLSTM model and LMD-BiLSTM model.
2.4. LightGBM Meta Learner
The second-layer metalearner in this study uses a LightGBM model, which is an efficient implementation of a gradient boosting decision tree (GBDT) [63]. This model has the advantages of a fast training speed, high efficiency, a low memory utilization rate, high accuracy, support for parallel and GPU learning and the ability to process large-scale data; moreover, it can effectively reduce server expenses when used in actual projects [64]. Its principle is similar to that of a GBDT, and the negative gradient of the loss function is used to establish the residual approximation of the current decision tree to fit new decision trees; that is, the original model remains unchanged at each iteration, and then a new function is added to the model to approximate the real value with the predicted value [65]. The LightGBM function is shown in Equation (13):
The Taylor formula is used to expand the above formula and obtain Equation (14):
The second-order Taylor expansion of the loss function is shown in Equation (15):
where is the first derivative of the ith loss function and is the second derivative of the ith loss function. The calculation processes of and are shown in Equations (16) and (17):
Then, the simplified objective function can be expressed as shown in Equation (18):
2.5. Performance Metrics
For landslide warning models, using reasonable and accurate performance metrics is the key to objectively evaluating performance. In this paper, three performance metrics, namely, the accuracy of warnings, false warning rate and missed warning rate, are used to evaluate the stacking model and other warning submodels. The accuracy of warnings indicates the number of actual early warning situations successfully predicted by the early warning model, which is the most basic metric for indicating the accuracy of early warnings. The larger the value is, the better the performance of the model. The false warning rate is the number of false warnings issued by the warning model compared to the total number of possible warnings. Excessive false warnings will reduce the trust of decision makers in the warning model. The missed warning rate indicates the number of actual warnings missed by the warning model in reference to the total number of possible warnings. Each missed warning may result in incorrect judgments and economic losses. Smaller values of the false warning rate and missed warning rate indicate good model performance.
3. Results
3.1. Study Area
The Baishuihe landslide is in Shazhenxi town, Zigui County, Hubei Province, 56 km away from the site of the Three Gorges Dam. Since the impoundment of the Three Gorges Reservoir in 2003, the landslide began to deform due to flood season rainfall and the lowered water level of the reservoir. In 2004, the landslide warning area (Figure 7) was delimited according to the deformation characteristics of the Baishuihe landslide. The east side of the warning area is bounded by the loess Baotou groove, the west side of the slip body is bounded by the goat groove, the rear edge is bounded by the elevation contours of 297 m, and the front shear outlet is below the water level of 145 m in the Yangtze River reservoir. The landslide volume is 1.26 × 107 m3. The slope body is mainly composed of quaternary residual slope deposits and accumulated soil. The main sliding direction is 20°, making it a deep large-scale soil landslide.
The Baishuihe landslide has been monitored since 2003. As shown in Figure 7, 11 GPS monitoring points are arranged in the landslide. Since monitoring point ZG118 is in the middle of the landslide and has provided a relatively complete record [66,67], the data collected at this monitoring point were adopted in the experiments in this study. The monitoring data types for the ZG118 monitoring points include landslide displacement, rainfall and reservoir water level data. The monitoring data are obtained once a month, and the changes in the data are shown in Figure 8. Figure 8 shows that the landslide has an obvious step displacement characteristic, which is consistent with the rainfall in the flood season and the lowering of the water level of the Three Gorges Reservoir.
3.2. Warming Threshold Setting
In this study, we monitored three parameter types: landslide displacement, precipitation and reservoir level. According to previous studies, precipitation and reservoir level were used to predict landslide displacement, so only landslide displacement was used in this study in simulations and to verify the stacking model. In the model, different warning threshold setting conditions were formulated for different warning levels at the same monitoring point [24].
The setting of a landslide warning threshold is usually based on monitored historical data [11,15], and there is no unified standard [12]. The warning threshold should be set to ensure that correct alarms are established while errors and missed alarms are minimized [20]. This threshold is one of the important parameters of a landslide warning model [68]. Landslide displacement is the most direct variable for reflecting the landslide situation, and it is considered the key to threshold setting in this paper.
Historical monitored landslide displacement data are used, and the historical cumulative maximum is used as the benchmark setting condition [36]. In addition, when landslide displacement suddenly increases, we believe that the landslide state changes, and the landslide easily slides. Therefore, we compare the displacement in the current month to the total displacement in previous months and set the threshold condition. The warning levels are divided into Level 1, Level 2, Level 3 and Level 4. Level 1 is the lowest warning level, and Level 4 is the highest warning level [20,34]. To avoid accidental situations, we set four conditions for each landslide displacement threshold level.
Level 1 is considered the condition that needs to start gaining attention. The threshold setting conditions are as follows:
- (1)
- 85% to 95% of the maximum value added in history;
- (2)
- 95% to 100% of the second largest added value in history;
- (3)
- 95% to 105% of the third largest increase in history;
- (4)
- Greater than the sum of landslide displacement in the previous 5 consecutive months.
Level 2 is considered a situation that requires vigilance. The threshold setting conditions are as follows:
- (1)
- 95–100% of the maximum value added in history;
- (2)
- 100–105% of the second largest added value in history;
- (3)
- 105–110% of the third largest increase in history;
- (4)
- Greater than the total landslide displacement in the previous 8 consecutive months.
Level 3 is considered a serious case. The threshold setting conditions are as follows:
- (1)
- 100–105% of the maximum value added in history;
- (2)
- 105–110% of the second largest added value in history;
- (3)
- 110–115% of the third largest increase in history;
- (4)
- Greater than the total landslide displacement in the previous 11 consecutive months.
Level 4 is considered the most serious condition. The threshold setting conditions are as follows:
- (1)
- Greater than 105% of the historical maximum added value;
- (2)
- Greater than 110% of the second largest added value;
- (3)
- More than 115% of the third largest added value;
- (4)
- Greater than the total landslide displacement in the previous 14 consecutive months.
When any of the parameters meet the conditions, real-time monitoring will issue a warning. When multiple warning levels are triggered, real-time monitoring will select the highest warning level to issue an early warning.
The landslide displacement threshold settings are shown in Table 1.
3.3. Actual Warning Situation
Typically, in the process of validating model performance, raw data are divided into a training dataset and a test dataset. The training dataset is used to train the model, and the test dataset is used to test the model and verify its performance. The use of reasonable input data can improve model prediction performance [69]. For a single prediction model to be adequately trained, as much training data as possible are required. However, to assess the model performance, more test data are needed. In both cases, abundant data are needed. Based on the above situation, 108 data points were evenly divided into two parts in this study, with the first 54 data points as the training dataset and the last 54 data points as the test dataset. The performance of the model was tested according to the prediction results based on the 54 data points.
According to the data obtained at the ZG118 monitoring point and the warning threshold conditions established, multiple warnings were generated in the monitoring process. Since test set data generally need to be compared, the warnings generated by the training dataset and the test dataset were counted separately in this study.
From Table 2 and Table 3, it is clear that most of the warnings were concentrated from June to August, which coincided with the dramatic changes in rainfall and water level of the reservoir. To a certain extent, this result indicates that the conditions for setting the warning threshold are correct and that the Baishuihe landslide warning time can be effectively determined.
3.4. Warning by Stacked Model
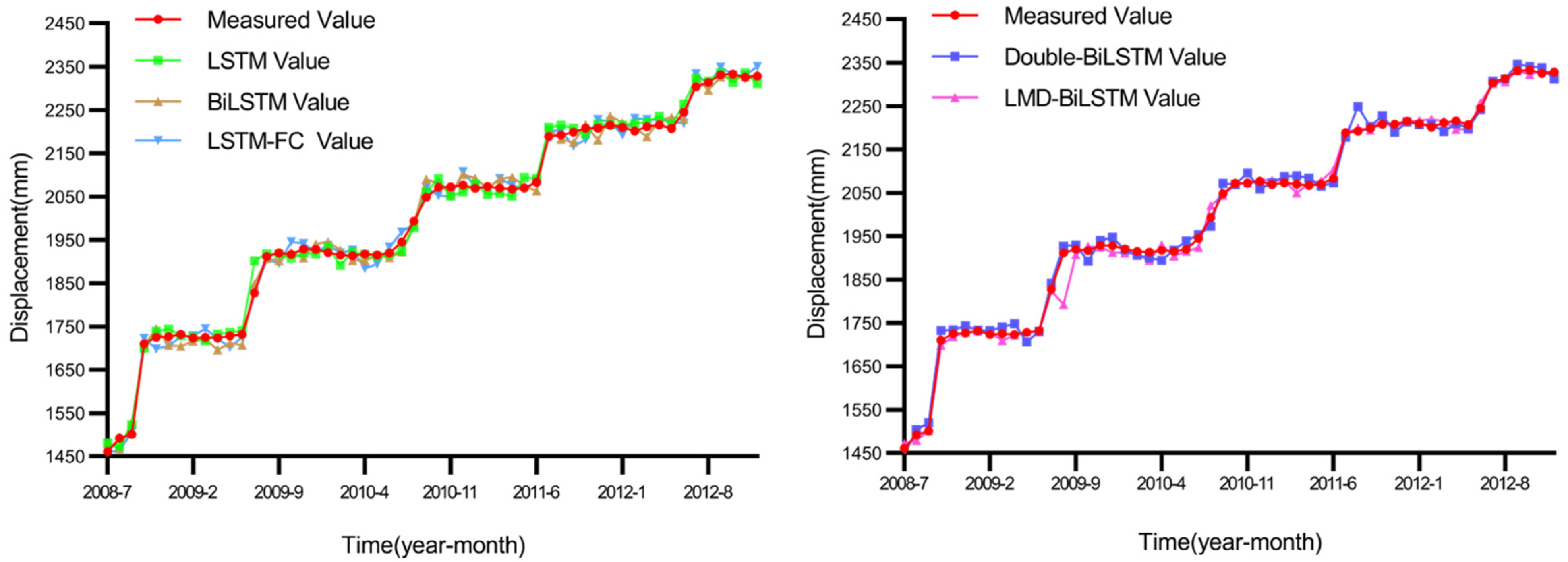
In the prediction submodel, landslide displacement provides more direct feedback regarding the development of landslides than can precipitation and reservoir level parameters, so five kinds of models are used to predict landslide displacement in this study. Similar to real-time landslide displacement monitoring, the same warning thresholds and warning levels are adopted in the advance prediction models. In this study, landslide displacement is predicted based on an LSTM model, a BiLSTM model, an LSTM-FC model [49], a double-BiLSTM model [50] and an LMD-BiLSTM model [51]. A comparison between the results and the actual landslide displacement values is shown in Figure 9.
According to the landslide displacement data predicted by the five models and the established warning thresholds, the prediction models generate multiple warnings. The prediction and warning statistics for each model are shown in Table 4 for the test dataset.
Table 4 shows several characteristics of the predictive early warning models. The first is that at high warning levels, the proposed model easily makes an early warning evaluation. Even if the warning level is not always fully accurate, low-level warnings are also appropriately issued. This may be because the numerical characteristics are more distinct at high warning levels; notably, even if there is a forecast fluctuation, the prediction will still fall within the warning range. Additionally, all the predictive early warning models produce false warnings. Although the number of false warnings is not particularly high, it can have an impact in real situations. Moreover, for Level 1 warnings, if the threshold condition is near the critical value, it is easy to produce judgment bias, leading to missed warnings.
After the warning submodels in the first layer produce warnings, the prediction results of each submodel are input into the LightGBM model in the second layer, the warning information in the test dataset as used as a standard, the LightGBM model parameters are adjusted, and the final stacking model warning value is output. A statistical comparison between the actual warning information and predictions at each time point is shown in Table 5.
As shown in Table 5, although the warning time and level of the stacking model are not 100% accurate, there are gaps between predictions and the actual warning information. Notably, two false Level 1 warnings are generated, one true Level 1 warning is missed and one Level 2 warning is changed to a Level 1. However, in terms of the overall warning effect, five in seven warnings are accurately predicted. We believe that the stacking model is effective. This success rate suggests that the model can be used as a reference to provide warning information and help increase the crisis awareness of decision makers. The results can support the safe evacuation of personnel before a landslide occurs, avoid many casualties, and greatly reduce the loss caused by disasters.
4. Discussion
To fully assess the early warning performance of the stacking fusion model, we compared the prediction results of single prediction models with those of the stacking fusion model, as shown in Table 6 and Figure 10.
For further evaluation, a histogram of the data in Table 6 was established.
As shown in Table 6 and Figure 10, when a single model is used for prediction and warning, regardless of which model is used, there are early warning omissions, and early warning information cannot be comprehensively provided in all cases. When the stacking model is used, most of the prediction and warning information is accurate and comprehensive. After the second stacking model is integrated, the missed warnings generated by individual models in the first layer are resolved. This reflects the comprehensive warning performance of the stacking model, which can successfully reduce disaster losses caused by missing warnings. Additionally, the single prediction models generate more false warnings than the stacking models, and the stacking model largely resolves most false and missed warnings. That is because false warnings are likely to be isolated to a few models, most of which are overconservative. The metalearner in the second layer of the stacking model uses the warning levels output by the base learner in the first layer. The LightGBM model is adjusted according to the hit rate of the base learner after training and learning, thus effectively reducing false warnings, decreasing human and material expenditures, and improving the warning efficiency. Even though the three warning performance metrics are the same for the LSTM, LMDBiLSTM and stacking models, the levels obtained with the stacking model are closest to the actual levels, so the stacking model is the most accurate.
To describe the comparison more accurately, four error indices are introduced to analyze the results. An error comparison between the actual monitored values and the predicted values is shown in Table 7.
As shown in Table 7, no one model has absolute advantages over the other models, and each model has unique advantages based on different error standards. This further illustrates that in the early warning process, a single model is restricted to a limited role. Only when the stacking model is used to integrate the respective advantages of individual models can accurate judgments be obtained to provide effective early warnings for landslide disasters.
According to the principles of disaster prevention and mitigation priority, a risk priority strategy is used. Without considering human and material resources, the maximum warning level obtained with the first base learner is selected as the warning result for danger prioritization at a given time. A corresponding comparison of warnings is shown in Table 8.
As shown in Table 8, the risk priority strategy is effective. Compared with single prediction and warning models, this strategy yields few missed warnings, and most important warning information is provided. However, the disadvantage of the risk priority strategy is that the maximum warning level is always selected, which may lead to excessive measures in some cases. Compared with the stacking model, this approach generates more false warnings. However, the advantage of the risk priority strategy is that it can be widely used in uninhabited areas and does not require excessive training with historical data. It can be preliminarily applied as a warning method when there is only a small amount of data available prior to stacking model development.
We believe that the stacking model proposed in this paper positively contributes to landslide risk prediction and management. In this paper, a novel advance prediction and warning model is proposed to issue early warning information before a disaster occurs. This could inspire other researchers to develop other types of predictive warning models. This model solves the major problem of the existing landslide risk prediction models, namely, that the early warning time was limited, and provides a new research direction for disaster prevention and reduction. The stacking model can play a guiding role in the management of slide-prone areas so that decision makers can make preparations in advance according to the results of forecasting and appropriate warnings and reduce the loss of people and property.
In summary, the proposed advance prediction and warning model based on a stacking fusion algorithm can be effectively used for landslide disaster prevention and mitigation and is an important tool for reducing casualties and economic losses. However, the model proposed in this paper has some limitations. First, only the data for the Baishuihe landslide are considered, and other types of landslides may not be effectively simulated with the proposed model. Second, only landslide displacement data are predicted, a relatively uncomprehensive approach. Thus, the prediction of rainfall data and reservoir level data will be explored in the future. Third, the stacking model proposed in this paper still has the potential to be improved. Next, we will improve it to enhance the accuracy of advance warning prediction.
5. Conclusions
This paper presents an advance landslide prediction and warning model based on a stacking fusion algorithm to solve the problem that the landslide warning time is not sufficiently early. Because most existing landslide warning models are based on real-time monitoring thresholds, resulting in insufficient early warnings, this model effectively integrates the results of several previous landslide displacement prediction models through a stacking fusion algorithm. Based on the concept of the real-time monitoring of historical data and landslide state data, four warning level thresholds and the trigger conditions for each warning level are summarized. According to the alarm threshold conditions established, the alarm results of the entire monitoring cycle are obtained. Then, five separate prediction and stacking models, the proposed stacking model and the actual results are compared to verify the effectiveness of the proposed model. Finally, the simulation results are discussed. The simulation experiment and comparison of results show that the stacking fusion algorithm and advance landslide prediction and warning model can effectively improve the advance warning time, and the accuracy of the fusion result is higher than that of single prediction and warning models. The proposed model reduces the occurrence of false alarms and can effectively avoid missed warnings that often occur in cases with single prediction and warning models, thus better meeting the actual needs of disaster prevention scenarios. At the end of this paper, the advantages and disadvantages of the hazard priority strategy are discussed. This strategy can be used as a substitute for stacking models in the early warning period. Overall, the proposed model can be applied to other landslides in areas with similar geological and rainfall conditions, thus reducing research costs and time.
Author Contributions
Conceptualization, Z.L., Y.J. and X.S.; methodology, Z.L., Y.J. and X.S.; formal analysis, Z.L.; software, Z.L.; validation, Z.L., Y.J. and X.S.; resources, Y.J. and X.S.; writing—original draft preparation, Z.L. and X.S.; writing—review and editing, Z.L., Y.J. and X.S.; funding acquisition, Y.J. and X.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (62161007, 62061010), Department of Science and Technology of Guangxi Zhuang Autonomous Region (AA20302022, AA19254029, AB21196041, AB22035074, AD22080061), Guilin Science and Technology Project (20210222-1).
Data Availability Statement
The datasets analyzed in the current study are available from the corresponding author on reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, Y.; Javed, I.; Yang, Z.; Yao, X. Landslide susceptibility mapping using an integrated model of information value method and logistic regression in the Bailongjiang watershed, Gansu Province, China. J. Mt. Sci. 2017, 2, 249–268. [Google Scholar]
- Prakash, N.; Manconi, A.; Loew, S. Mapping Landslides on EO Data: Performance of Deep Learning Models vs. Tradit. Mach. Learn. Models. Remote Sens. 2020, 12, 346. [Google Scholar]
- Samuele, S.; Stefano, L.G.; Ascanio, R. Preface to the Special Issue “Rainfall Thresholds and Other Approaches for Landslide Prediction and Early Warning”. Water 2021, 13, 323. [Google Scholar]
- Wu, W.; Zhang, Q.; Singh, V.P.; Wang, G.; Zhao, J.; Shen, Z.; Sun, S. A Data-Driven Model on Google Earth Engine for Landslide Susceptibility Assessment in the Hengduan Mountains, the Qinghai–Tibetan Plateau. Remote Sens. 2022, 14, 4662. [Google Scholar] [CrossRef]
- National Bureau of Statistics of the People’s Republic of China. China Statistical Yearbook; China Statistics Press: Beijing, China, 2021. [Google Scholar]
- Yu, X.; Zhang, K.; Song, Y.; Jiang, W.; Zhou, J. Study on landslide susceptibility mapping based on rock–soil char-acteristic factors. Sci. Rep. 2021, 11, 15476. [Google Scholar] [CrossRef]
- Hongtao, N. Smart safety early warning model of landslide geological hazard based on BP neural network. Saf. Sci. 2020, 123, 104572. [Google Scholar] [CrossRef]
- Krkač, M.; Bernat Gazibara, S.; Arbanas, Ž.; Sečanj, M.; Mihalić Arbanas, S. A comparative study of random forests and multiple linear regression in the prediction of landslide velocity. Landslide 2020, 17, 2515–2531. [Google Scholar] [CrossRef]
- Tapeh, A.T.G.; Naser, M.Z. Artificial Intelligence, Machine Learning, and Deep Learning in Structural Engineering: A Scientometrics Review of Trends and Best Practices. Arch. Comput. Methods Eng. 2023, 30, 115–239. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D. Machine learning and data mining in manufacturing. Expert Syst. Appl. 2021, 166, 114060. [Google Scholar] [CrossRef]
- Naidu, S.; Sajinkumar, K.S.; Oommen, T.; Anuja, V.J.; Samuel, R.A.; Muraleedharan, C. Early warning system for shallow landslides using rainfall threshold and slope stability analysis. Geosci. Front. 2018, 9, 1871–1882. [Google Scholar] [CrossRef]
- Guzzetti, F.; Gariano, S.L.; Peruccacci, S.; Brunetti, M.T.; Marchesini, I.; Rossi, M.; Melillo, M. Geographical landslide early warning systems. Earth-Sci. Rev. 2020, 200, 102973. [Google Scholar] [CrossRef]
- Ju, N.; Huang, J.; He, C.; Van Asch, T.W.J.; Huang, R.; Fan, X.; Xu, Q.; Xiao, Y.; Wang, J. Landslide early warning, case studies from Southwest China. Eng. Geol. 2020, 279, 105917. [Google Scholar] [CrossRef]
- Brian, A.G.; Arturo, D. Negotiated participatory action research for multi-stakeholder implementation of early warning systems for landslides. Int. J. Disaster Risk Reduct. 2021, 58, 102184. [Google Scholar]
- Zhao, B.; Dai, Q.; Han, D.; Dai, H.; Mao, J.; Zhuo, L. Probabilistic Thresholds for Landslides Warning by Integrating Soil Moisture Conditions with Rainfall Thresholds. J. Hydrol. 2019, 574, 276–287. [Google Scholar] [CrossRef]
- Liu, Q.; Jian, W.; Nie, W. Rainstorm-induced landslides early warning system in mountainous cities based on groundwater level change fast prediction. Sustain. Cities Soc. 2021, 69, 102817. [Google Scholar] [CrossRef]
- Chikalamo, E.E.; Mavrouli, O.C.; Ettema, J.; van Westen, C.J.; Muntohar, A.S.; Mustofa, A. Satellite-derived rainfall thresholds for landslide early warning in Bogowonto Catchment, Central Java, Indonesia. Int. J. Appl. Earth Obs. Geoinf. 2020, 89, 102093. [Google Scholar] [CrossRef]
- Xu, Q.; Peng, D.; Zhang, S.; Zhu, X.; He, C.; Qi, X.; Zhao, K.; Xiu, D.; Ju, N. Successful implementations of a real-time and intelligent early warning system for loess landslides on the Heifangtai terrace, China. Eng. Geol. 2020, 278, 105817. [Google Scholar] [CrossRef]
- Tan, Q.; Wang, P.; Hu, J.; Zhou, P.; Bai, M.; Hu, J. The Application of Multi-Sensor Target Tracking and Fusion Technology to the Comprehensive Early Warning Information Extraction of Landslide Mul-ti-Point Monitoring Data. Measurement 2020, 166, 108044. [Google Scholar] [CrossRef]
- Michele, C.; Ricardo, N.d.; Luca, P.; Nelson, P.; Marcelo, M.; Willy, A.L. The Rio de Janeiro early warning system for rainfall-induced landslides: Analysis of performance for the years 2010–2013. Int. J. Disaster Risk Reduct. 2015, 12, 3–15. [Google Scholar]
- Luca, P.; Michele, C.; José, M.C. Territorial early warning systems for rainfall-induced landslides. Earth-Sci. Rev. 2018, 179, 228–247. [Google Scholar]
- Minu, T.A.; Neelima, S.; Ascanio, R.; Biswajeet, P.; Samuele, S. Usage of antecedent soil moisture for improving the performance of rainfall thresholds for landslide early warning. CATENA 2021, 200, 105147. [Google Scholar]
- Małgorzata, W.; Ireneusz, M.; Janusz, B. Tree rings as an early warning against catastrophic landslides: Assessing the potential of dendrochronology for determining slope stability. Dendrochronologia 2019, 53, 82–94. [Google Scholar]
- Luca, P.; Stefano, L.G.; Massimo, M.; Maria, T.B.; Silvia, P.; Fausto, G.; Michele, C. Definition and performance of a threshold-based regional early warning model for rainfall-induced landslides. Landslides 2017, 14, 995–1008. [Google Scholar]
- Simon, L.; Sophie, G.; Valentin, G.; Alexandra, K.; Giorgio, V. Monitoring and early warning of the 2012 Preonzo catastrophic rockslope failure. Landslides 2017, 14, 141–154. [Google Scholar]
- Gariano, S.L.; Brunetti, M.T.; Iovine, G.; Melillo, M.; Peruccacci, S.; Terranova, O.; Vennari, C.; Guzzetti, F. Calibration and validation of rainfall thresholds for shallow landslide forecasting in Sicily, southern Italy. Geomorphology 2015, 228, 653–665. [Google Scholar] [CrossRef]
- Park, J.Y.; Lee, S.R.; Lee, D.H.; Kim, Y.T.; Lee, J.S. A regional-scale landslide early warning methodology applying statistical and physically based approaches in sequence. Eng. Geol. 2019, 260, 105193. [Google Scholar] [CrossRef]
- Pecoraro, G.; Calvello, M.; Piciullo, L. Monitoring strategies for local landslide early warning systems. Landslides 2018, 16, 213–231. [Google Scholar] [CrossRef]
- Samuele, S.; Ascaniom, R.; Riccardo, F.; Angela, G.; Antonio, M.; Nicola, C. A Regional-Scale Landslide Warning System Based on 20 Years of Operational Experience. Water 2018, 10, 1297. [Google Scholar]
- Moritz, G.; John, S.; Kurosch, T. Internet of Things Geosensor Network for Cost-Effective Landslide Early Warning Systems. Sensors 2021, 21, 2609. [Google Scholar]
- Minu, T.A.; Neelima, S.; Maria, A.B.; Biswajeet, P.; Binh, T.P.; Samuele, S. Using Field-Based Monitoring to Enhance the Performance of Rainfall Thresholds for Landslide Warning. Water 2020, 12, 3453. [Google Scholar]
- Yan, Y.; Yang, D.S.; Geng, D.X.; Hu, S.; Wang, Z.A.; Hu, W.; Yin, S.Y. Disaster reduction stick equipment: A method for monitoring and early warning of pipeline-landslide hazards. J. Mt. Sci. 2019, 16, 2687–2700. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, L.; Qiao, J.; Uchimura, T.; Wang, L. Application and verification of a multivariate real-time early warning method for rainfall-induced landslides: Implication for evolution of landslide-generated debris flows. Landslides 2020, 17, 2409–2419. [Google Scholar] [CrossRef] [Green Version]
- Won, Y.L.; Seon, K.P.; Hyo, H.S. The optimal rainfall thresholds and probabilistic rainfall conditions for a landslide early warning system for Chuncheon, Republic of Korea. Landeslide 2021, 18, 1721–1739. [Google Scholar]
- Prakash, S.T.; Basanta, R.A. Development of community-based landslide early warning system in the earthquake-affected areas of Nepal Himalaya. J. Mt. Sci. 2019, 16, 2701–2713. [Google Scholar]
- Yuan, Y.; Muhammad, A.A. The application of the intelligent algorithm in the prevention and early warning of mountain mass landslide disaster. Arab. J. Geosci. 2020, 13, 79. [Google Scholar] [CrossRef]
- Chen, M.; Cai, Z.; Zeng, Y.; Yu, Y. Multi-sensor data fusion technology for the early landslide warning system. J. Ambient Intell. Humaniz. Comput. 2022, 1–8. [Google Scholar] [CrossRef]
- Zhan, Q.; Wang, S.; Guo, F.; Chen, Y.; Wang, L.; Zhao, D. Early warning model and model test verification of rainfall-induced shallow landslide. Bull. Eng. Geol. Environ. 2020, 81, 318. [Google Scholar] [CrossRef]
- Benjamin, B.M.; Rachel, E.B.; Rex, L.B.; Joel, B.S. Integrating real-time subsurface hydrologic monitoring with empirical rainfall thresholds to improve landslide early warning. Landslide 2018, 15, 1909–1919. [Google Scholar]
- Feiyue, L.; Zhenqi, Y.; Wenxue, D.; Tianhong, Y.; Jingren, Z.; Qinglei, Y.; Yachun, M. Rock landslide early warning system combining slope stability analysis, two-stage monitoring, and case-based reasoning: A case study. Bull. Eng. Geol. Environ. 2021, 80, 8433–8451. [Google Scholar]
- Geethu, T.H.; Dhanya, M.; Maneesha, V.R.; Divya, P. Towards establishing rainfall thresholds for a real-time landslide early warning system in Sikkim, India. Landslides 2019, 16, 2395–2408. [Google Scholar]
- Yuxin, G.; Zhanya, X.; Shuang, Z.; Xiangang, L.; Yinli, X. Using distributed root soil moisture data to enhance the performance of rainfall thresholds for landslide warning. Nat. Hazards 2023, 115, 1167–1192. [Google Scholar]
- Rosa, M.P.; Marc, B.; Marcel, H.; Daniel, S. Application of a fuzzy verification framework for the evaluation of a regional-scale landslide early warning system during the January 2020 Gloria storm in Catalonia (NE Spain). Landslides 2022, 19, 1599–1616. [Google Scholar]
- Ascanio, R.; Samuele, S.; Vanessa, C.; Antonio, M.; Angela, G.; Nicola, C. Definition of 3D rainfall thresholds to increase operative landslide early warning system performances. Landslides 2021, 18, 1045–1057. [Google Scholar]
- Chien-Yuan, C. Event-based rainfall warning regression model for landslide and debris flow issuing. Environ. Earth Sci. 2020, 79, 127. [Google Scholar] [CrossRef]
- Minu, T.A.; Neelima, S.; Biswajeet, P.; Samuele, S.; Abdullah, A. Developing a prototype landslide early warning system for Darjeeling Himalayas using SIGMA model and real-time field monitoring. Geosci. J. 2022, 26, 289–301. [Google Scholar]
- Faming, H.; JiaWu, C.; Weiping, L.; Jinsong, H.; Haoyuan, H.; Wei, C. Regional rainfall-induced landslide hazard warning based on landslide susceptibility mapping and a critical rainfall threshold. Geomorphology 2022, 408, 108326. [Google Scholar]
- Thirugnanam, H.; Ramesh, M.V.; Rangan, V.P. Enhancing the reliability of landslide early warning systems by machine learning. Landslide 2020, 17, 2231–2246. [Google Scholar] [CrossRef]
- Lin, Z.; Sun, X.; Ji, Y. Landslide Displacement Prediction Model Using Time Series Analysis Method and Modified LSTM Model. Electronics 2022, 11, 1519. [Google Scholar] [CrossRef]
- Lin, Z.; Sun, X.; Ji, Y. Landslide Displacement Prediction based on Time Series Analysis and Double-BiLSTM Model. Int. J. Environ. Res. Public Health 2022, 19, 2077. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, Y.; Liang, W.; Sun, X. Landslide Displacement Prediction Based on Time-Frequency Analysis and LMD-BiLSTM Model. Mathematics 2022, 10, 2203. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.; Grossman, S.R.; Lander, E.S.; Finucane, H.K.; McVean, G.; Turnbaugh, P.J.; Mitzenmacher, M.; Sabeti, P.C. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shao, F.; Li, K. A graph model for preventing railway accidents based on the maximal information coefficient. Int. J. Mod. Phys. B 2017, 31, 1750010. [Google Scholar] [CrossRef]
- Guo, Z.; Yu, B.; Hao, M.; Wang, W.; Jiang, Y.; Zong, F. A novel hybrid method for flight departure delay prediction using Random Forest Regression and Maximal Information Coefficient. Aerosp. Sci. Technol. 2021, 116, 106822. [Google Scholar] [CrossRef]
- Mahendran, N.; Vincent, P.D.R.; Srinivasan, K.; Sharma, V.; Jayakody, D.K. Realizing a Stacking Generalization Model for Improving the Prediction Accuracy of Major Depressive Disorder in Adults. IEEE Access 2020, 8, 49509–49522. [Google Scholar] [CrossRef]
- Bakurov, I.; Castelli, M.; Gau, O.; Fontanella, F.; Vanneschi, L. Genetic Programming for Stacked Generalization. Swarm Evol. Comput. 2021, 65, 100913. [Google Scholar] [CrossRef]
- Shen, T.; Yu, H.; Wang, Y.Z. Discrimination of Gentiana and Its Related Species Using IR Spectroscopy Combined with Feature Selection and Stacked Generalizatio. Molecules 2020, 25, 1442. [Google Scholar] [CrossRef] [Green Version]
- Marcella, C.; Lorenzo, B.; Giuseppe, S.; Rita, C. Predicting Human Eye Fixations via an LSTM-based Saliency Attentive Model. IEEE Trans. Image Process. 2016, 27, 5142–5154. [Google Scholar]
- Zhang, S.; Xiao, J.; Liu, X.; Yang, Y.; Xie, D.; Zhuang, Y. Fusing Geometric Features for Skeleton-Based Action Recognition Using Multilayer LSTM Networks. IEEE Trans. Multimed. 2018, 20, 2330–2343. [Google Scholar] [CrossRef]
- Germánico, L.; Pablo, A. Short-term wind speed forecasting over complex terrain using linear regression models and multivariable LSTM and NARX networks in the Andes Mountains, Ecuador. Renew. Energy 2022, 183, 351–368. [Google Scholar]
- Mingzhe, Z.; Ninoslav, H.; Josip, Đ.; Igor, K.; Roberto, L.; Vincenzo, D.G.; Sasa, Z.D. Bayesian CNN-BiLSTM and Vine-GMCM Based Probabilistic Forecasting of Hour-Ahead Wind Farm Power Outputs. IEEE Trans. Sustain. Energy 2022, 13, 1169–1187. [Google Scholar]
- Mohammed, A.B.; Muhammad, Y.N.; Imad, E.A.; Shaharin, A.S. BiLSTM Network-Based Approach for Solar Irradiance Forecasting in Continental Climate Zones. Energies 2022, 15, 2226. [Google Scholar]
- Wang, X.; Gao, S.; Guo, Y.; Zhou, S.; Duan, Y.; Wu, D. A Combined Prediction Model for Hog Futures Prices Based on WOA-LightGBM-CEEMDAN. Complexity 2022, 2022, 3216036. [Google Scholar] [CrossRef]
- Wang, X.; Xu, N.; Meng, X.; Chang, H. Prediction of Gas Concentration Based on LSTM-LightGBM Variable Weight Combination Model. Energies 2022, 15, 827. [Google Scholar] [CrossRef]
- Wang, B.; Wu, P.; Chen, Q.; Ni, S. Prediction and Analysis of Train Passenger Load Factor of High-Speed Railway Based on LightGBM Algorithm. J. Adv. Transp. 2021, 2021, 9963394. [Google Scholar] [CrossRef]
- Wang, Y.; Tang, H.; Wen, T.; Ma, J. A hybrid intelligent approach for constructing landslide displacement prediction intervals. Appl. Soft Comput. 2019, 81, 105506. [Google Scholar] [CrossRef]
- Du, H.; Song, D.; Chen, Z.; Shu, H.; Guo, Z. Prediction model oriented for landslide displacement with step-like curve by applying ensemble empirical mode decomposition and the PSO-ELM method. J. Clean. Prod. 2020, 270, 122248. [Google Scholar] [CrossRef]
- Wu, S.; Hu, X.; Zheng, W.; Berti, M.; Qiao, Z.; Shen, W. Threshold Definition for Monitoring Gapa Landslide under Large Variations in Reservoir Level Using GNSS. Remote Sens. 2021, 13, 4977. [Google Scholar] [CrossRef]
- Akinosho, T.D.; Oyedele, L.O.; Bilal, M.; Ajayi, A.O.; Delgado, M.D.; Akinade, O.O.; Ahmed, A.A. Deep learning in the construction industry: A review of present status and future innovations. J. Build. Eng. 2020, 32, 101827. [Google Scholar] [CrossRef]
Figure 1.
Casualties and direct economic losses from 2005–2020.

Figure 2.
Casualty types among geological disasters in China in 2020.

Figure 3.
Numbers of geological disasters and landslides from 2005 to 2020.

Figure 4.
Structure of the stacking fusion algorithm.

Figure 5.
LSTM model structure.

Figure 6.
BiLSTM model structure.

Figure 7.
Baishuihe landslide monitoring situation.

Figure 8.
Annual changes in the Baishuihe landslide monitoring data.

Figure 9.
Comparisons between the results of five advance prediction models and the actual data.

Figure 10.
Comparison of five prediction models and the stacking model.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Landslide displacement threshold settings.
| Parameter | Threshold Setting and Warning Level | |||
|---|---|---|---|---|
| Landslide displacement | Level 1 | Level 2 | Level 3 | Level 4 |
| Increase 179.1–188.5 | Increase 188.5–197.9 | Increase 197.9–207.4 | Increase more than 207.4 | |
| More than previous 5 months combined | More than previous 8 months combined | More than previous 11 months combined | More than previous 14 months combined | |
Table 2.
Actual monitoring of landslide displacement and warning times for the training dataset.
| Warning Time | Monitoring Value | Warning Level | Satisfied Threshold Conditions |
|---|---|---|---|
| 2004-06 | 132.3 | Level 1 | More than previous 5 months combined |
| 2005-06 | 312.6 | Level 1 | More than previous 5 months combined |
| 2007-06 | 741.5 | Level 1 | More than previous 5 months combined |
| 2007-07 | 930 | Level 1 | Increase 179.1–188.5 |
| 2007-08 | 1240.9 | Level 4 | Increase more than 207.4 |
| 2007-09 | 1426.1 | Level 1 | Increase 179.1–188.5 |
Table 3.
Actual monitoring of landslide displacement and warning times for the testing dataset.
| Warning Time | Monitoring Value | Warning Level | Satisfied Threshold Conditions |
|---|---|---|---|
| 2008-10 | 1710.3 | Level 4 | Increase by more than 207.4 |
| 2009-07 | 1827.7 | Level 2 | More than previous 8 months combined |
| 2010-07 | 1944.9 | Level 1 | More than previous 5 months combined |
| 2010-08 | 1993.6 | Level 1 | More than previous 5 months combined |
| 2011-07 | 2188.6 | Level 2 | More than previous 8 months combined |
| 2012-06 | 2245.1 | Level 1 | More than previous 5 months combined |
Table 4.
Warnings for each prediction model.
| Warning Time | Real-Time Monitoring | LSTM | BiLSTM | LSTM-FC | Double-BiLSTM | LMD-BiLSTM |
|---|---|---|---|---|---|---|
| 2008-10 | Level 4 | Level 1 | Level 1 | Level 4 | Level 4 | Level 2 |
| 2009-05 | - | - | - | - | Level 1 | - |
| 2009-07 | Level 2 | Level 2 | Level 2 | Level 1 | Level 2 | Level 2 |
| 2010-04 | - | - | - | - | - | Level 1 |
| 2010-07 | Level 1 | - | - | - | - | - |
| 2010-08 | Level 1 | Level 1 | Level 1 | - | - | Level 1 |
| 2010-09 | - | Level 1 | Level 1 | - | Level 1 | - |
| 2011-07 | Level 2 | Level 1 | Level 1 | Level 1 | Level 1 | Level 1 |
| 2012-06 | Level 1 | Level 1 | - | - | Level 1 | Level 1 |
| 2012-07 | - | - | Level 1 | Level 1 | - | - |
Table 5.
Comparison of real-time monitoring and stacking model warnings.
| Warning Time | Real-Time Monitoring | Stacking Model |
|---|---|---|
| 2008-10 | Level 4 | Level 4 |
| 2009-07 | Level 2 | Level 2 |
| 2010-07 | Level 1 | - |
| 2010-08 | Level 1 | Level 1 |
| 2010-09 | - | Level 1 |
| 2011-07 | Level 2 | Level 1 |
| 2012-06 | Level 1 | Level 1 |
| 2012-07 | - | Level 1 |
Table 6.
Comparison of five prediction models and the stacking model.
| Warning Time | Real-Time Monitoring | LSTM | BiLSTM | LSTM-FC | Double-BiLSTM | LMD-BiLSTM | Stacking Model |
|---|---|---|---|---|---|---|---|
| 2008-10 | Level 4 | Level 1 | Level 1 | Level 4 | Level 4 | Level 2 | Level 4 |
| 2009-05 | - | - | - | - | Level 1 | - | - |
| 2009-07 | Level 2 | Level 2 | Level 2 | Level 1 | Level 2 | Level 2 | Level 2 |
| 2010-04 | - | - | - | - | - | Level 1 | - |
| 2010-07 | Level 1 | - | - | - | - | - | - |
| 2010-08 | Level 1 | Level 1 | Level 1 | - | - | Level 1 | Level 1 |
| 2010-09 | - | Level 1 | Level 1 | - | Level 1 | - | Level 1 |
| 2011-07 | Level 2 | Level 1 | Level 1 | Level 1 | Level 1 | Level 1 | Level 1 |
| 2012-06 | Level 1 | Level 1 | - | - | Level 1 | Level 1 | Level 1 |
| 2012-07 | - | - | Level 1 | Level 1 | - | - | - |
Table 7.
Comparison of the prediction errors of the five warning models.
| Model | Minimum Error | Maximum Error | Mean Relative Error | Root Mean Squared Error |
|---|---|---|---|---|
| LSTM | 0.53 | 73.98 | 13.59 | 17.25 |
| BiLSTM | 1.09 | 41.71 | 15.99 | 18.28 |
| LSTM-FC | 0.73 | 32.77 | 15.13 | 17.97 |
| Double-BiLSTM | 1.00 | 56.51 | 13.08 | 16.07 |
| LMD-BiLSTM | 0.14 | 108.44 | 20.15 | 24.67 |
Table 8.
Comparison of the warning results based on different risk priority strategies.
| Warning Time | Real-Time Monitoring | Risk Priority Strategy | Stacking Model | |
|---|---|---|---|---|
| Maximum Warning Level Models | Warning Level | Warning Level | ||
| 2008-10 | Level 4 | LSTM-FC/Double-BiLSTM | Level 4 | Level 4 |
| 2009-05 | - | Double-BiLSTM | Level 1 | - |
| 2009-07 | Level 2 | BiLSTM/Double-BiLSTM/LMD-BiLSTM | Level 2 | Level 2 |
| 2010-02 | - | LSTM | Level 1 | - |
| 2010-04 | - | LMD-BiLSTM | Level 1 | - |
| 2010-07 | Level 1 | - | - | - |
| 2010-08 | Level 1 | LSTM/BiLSTM/LMD-BiLSTM | Level 1 | Level 1 |
| 2010-09 | - | LSTM/BiLSTM/Double-BiLSTM | Level 1 | Level 1 |
| 2011-07 | Level 2 | LSTM/BiLSTM/LSTM-FC/Double-BiLSTM/LMD-BiLSTM | Level 1 | Level 1 |
| 2012-06 | Level 1 | LSTM/BiLSTM/Double-BiLSTM | Level 1 | Level 1 |
| 2012-07 | - | BiLSTM/LSTM-FC | Level 1 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lin, Z.; Ji, Y.; Sun, X. Advance Landslide Prediction and Warning Model Based on Stacking Fusion Algorithm. Mathematics 2023, 11, 2833. https://0-doi-org.brum.beds.ac.uk/10.3390/math11132833
AMA Style
Lin Z, Ji Y, Sun X. Advance Landslide Prediction and Warning Model Based on Stacking Fusion Algorithm. Mathematics. 2023; 11(13):2833. https://0-doi-org.brum.beds.ac.uk/10.3390/math11132833
Chicago/Turabian StyleLin, Zian, Yuanfa Ji, and Xiyan Sun. 2023. "Advance Landslide Prediction and Warning Model Based on Stacking Fusion Algorithm" Mathematics 11, no. 13: 2833. https://0-doi-org.brum.beds.ac.uk/10.3390/math11132833
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.