1. Introduction
Agricultural products are crucial to the sustenance of humans and livestock. However, their production is faced with several challenges such as extreme weather conditions, soil erosion, pests, and disease outbreaks, which all have far-reaching effects on crop productivity and growth rate [
1,
2]. Protected cultivation systems such as greenhouses offer optimal production of agricultural products throughout the year by the appropriate control of micro- and macro-environments suitable for plant growth [
3]. Furthermore, protected cultivation systems result in higher income compared to open-field cultivation as a result of their higher returns per unit area [
4]. Hence, their adoption is increasing across continents [
5]. Despite these benefits, the operation of greenhouses is non-linear in nature due to changing atmospheric conditions [
6] and therefore requires intricate monitoring and control to obtain optimal yield. In other words, maintaining suitable temperature, which directly affects the humidity, is essential in greenhouse environmental control as these affect crop growth as well as quality and quantity [
7,
8,
9]. Specifically, while effective temperature control improves plant growth and minimizes the energy consumed by the system, an appropriate relative humidity range is required to prevent fungal infection and control transpiration [
10].
To facilitate monitoring and control in protected cultivation systems, the integration of different advanced sensing technologies becomes eminent [
4,
11,
12]. Basically, sensors installed in greenhouses range from those used to monitor and control micro-climatic conditions such as temperature and relative humidity to soil-related parameters such as moisture, PH, and several others, which are vital for maintaining optimal conditions for favorable crop productivity and growth. In terms of micro-climates, previous studies have shown that monitoring and controlling the temperature and relative humidity within a greenhouse is complex and challenging due to drastic variations in daily and seasonal atmospheric conditions [
13].
Generally, sensors are installed arbitrarily in protected systems based on factors such as grower resources, the size of the facility, and technical know-how [
14]. Furthermore, in conventional settings, as many sensors as possible are usually installed to facilitate the necessary measurements. However, the use of multiple randomly/inappropriately placed sensors fails to provide measurements that are true estimates of greenhouse micro-climates. In addition, employing a large number of sensors results in large quantities of data that require efficient data management. In other words, the quality of information and consequently the estimation accuracy of micro-climates depend heavily on the number of sensors and their locations/placements. Therefore, optimizing the number of sensors and their locations, though a challenging task, is crucial as it forms the basis for accurate measurement of micro-climates and consequently optimal control of the cultivation system. Additionally, it reduces the overall operating cost of protected cultivation systems.
In the literature, methods have been proposed based on approximate models of partial differential equations (PDEs), such as the error covariance matrix of the Kalman filter or the finite difference method [
15,
16]. However, these methods were applied without any general systematic procedure to linear systems modeled based on a small number of sensors. Meanwhile, it is important to know that distributed processes, such as in protected cultivation systems, are intrinsically non-linear with infinite dimensions. Therefore, such methods are not appropriate for highly non-linear protected cultivation systems that feature high-dimensional representations. Consequently, different methods, such as genetic algorithms [
17,
18], Harris hawks optimization [
19], the Fisher information matrix [
20], the exponential-time exact algorithm [
21], the system reliability criterion [
22], and Bayesian optimization [
23], have been proposed for optimal sensor placement in different application domains.
In terms of optimal sensor placement in protected cultivation systems (greenhouses), Yeon Lee et al. [
14] proposed a combination of an error-based and entropy-based approach for the optimal location of temperature sensors. In the work, based on the reference temperature obtained by averaging the temperature data obtained from all the measurement locations, sensor locations with measurements statistically close to reference values were selected. Furthermore, the entropy method was used to realize locations that are greatly influenced by external environmental conditions. Based on these two methods, optimal sensor locations that provide representative data of the entire greenhouse condition, as well as understanding regions with high variations in temperature, were realized. In order to maximize the coverage area (a non-occlusion coverage scheme) in a vegetable-cultivating greenhouse, Wu et al. [
24] proposed a hierarchical cooperative particle swarm optimization algorithm for directional sensor placement. Specifically, the decision variables were modeled in terms of the global effective coverage of each sensor and consequently the orientation angles of each sensor. The model demonstrated the capability to avoid occlusion between covered objects and also improved sensor utilization in general. However, the limitation of the aforementioned works is that their investigations were performed for a limited period of time and do not capture all the different planting seasons as well as different weather conditions. Recently, Uyeh et al. [
25] proposed a reinforcement learning (RL)-based approach for optimal sensor location in greenhouses using a robust dataset that covers different planting seasons. From the analysis, it was evident that the optimal locations for temperature and relative humidity are different. Specifically, the RL-based model was able to rank the sensor locations based on their importance in estimating the greenhouse micro-climates, for each temperature and relative humidity. However, it was also reported that the ranking of sensor locations for effective measurement of greenhouse micro-climates varies during the different months of the year with the change in the external weather conditions.
Although the assertion that the optimal sensor locations change from month to month is intuitive and supported by a number of recent literature [
26,
27], the implication is that it would be required to move the sensors every month throughout the growing seasons or to have a huge number of sensors within the cultivation system. This need to relocate the sensors every month is tedious, expensive, and not ideal for a typical grower. Hence in this paper, based on the data collected from a greenhouse used to cultivate strawberries in [
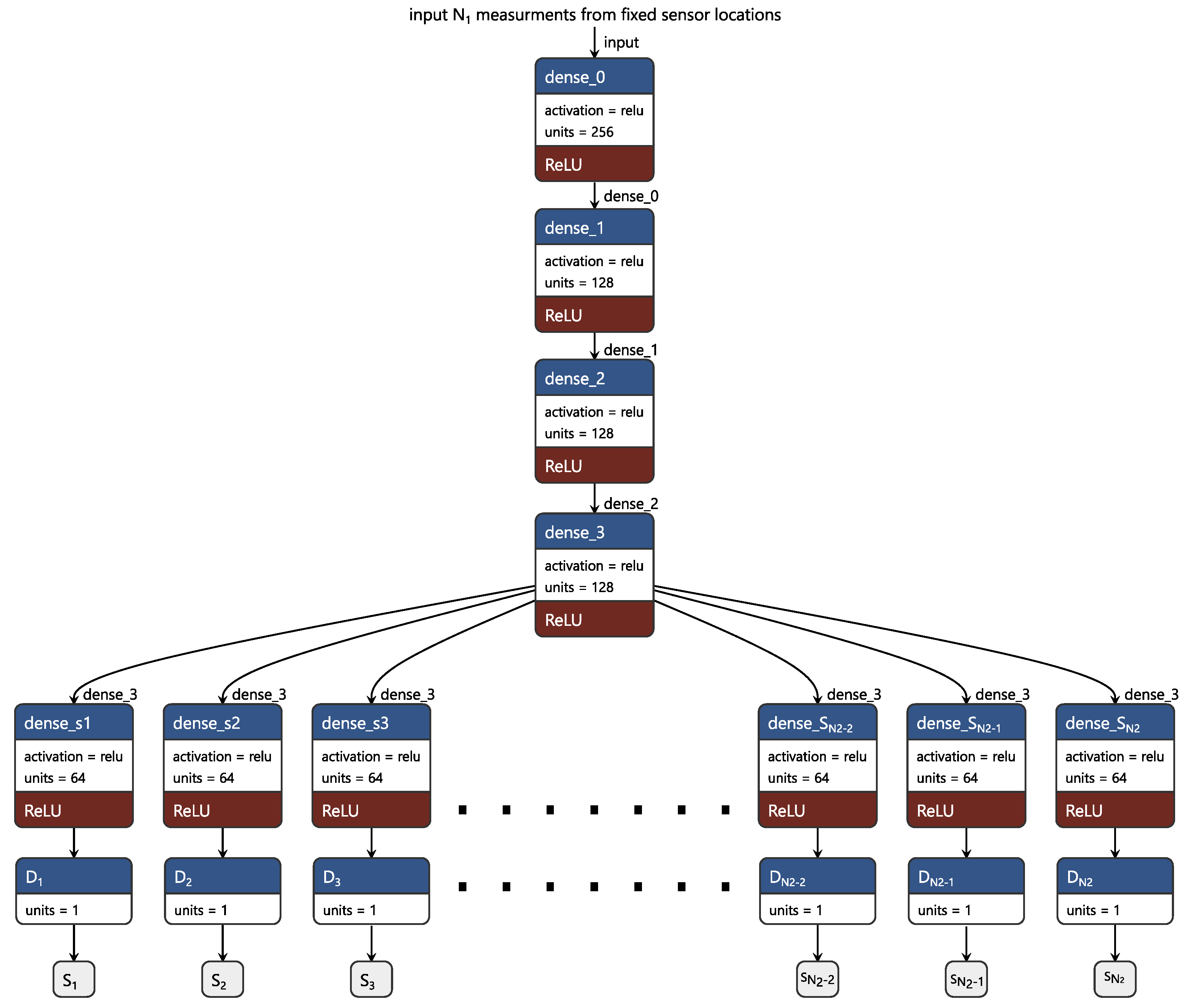
25], a framework based on the multi-channeled dense neural network (DNN) is proposed to be used to predict temperature and relative humidity values corresponding to the optimal sensor locations of each month without the need of moving the sensor from one location to another. Specifically, temperature and relative humidity values measured from the fixed locations (say the optimal locations of February) are used to predict the temperature and relative humidity values corresponding to the optimal locations of the other months referred to as target months (March, April, May, June, July, and October). The prediction of the temperature and relative humidity values corresponding to the optimal locations corresponding to the target month will help better estimate the micro-climates of the greenhouse. The effectiveness of the proposed model to predict temperature and relative humidity is demonstrated in terms of the resulting RMSE values. Furthermore, it is shown that the true and predicted sensor values are highly correlated based on Pearson’s correlation coefficient. Overall the results obtained show that the proposed framework is efficient and applicable in predicting micro-climates within protected cultivation systems and also comes with the advantage of cost reduction.In addition, as the prediction is performed for each month using the same fixed locations, the proposed framework alleviates the issue related to shifting of the sensors with the change in the external weather conditions. In other words, the novel framework proposed in this paper becomes an initiative basis in the research community for modeling dynamic optimal sensor placement in cultivation systems based on fixed sensors. Finally, it is important to note that the choice of the multi-channel DNN employed in this work is motivated by its simplicity in terms of implementation and deployment since it is well suited to several low-precision hardware for deep learning compared to other variants.
The rest of this paper is organized as follows: In
Section 2, a review of related works is presented.
Section 3 gives a brief description of the dataset and the associated pre-processing stages. In
Section 4, the proposed framework and the associated model are presented.
Section 5 presented the results and discussions, and finally, in
Section 6 conclusions and future works are highlighted.
2. Review of Related Works
The prediction of micro-climates in protected cultivation systems under different setups has been studied in the literature [
9,
28,
29,
30]. The prediction models often employed range from very basic deterministic models [
28] to more advanced learning networks such as ANN [
9], multi-layer perceptron neural network (MLP-NN) [
29], and extreme learning machine (ELM) [
30]. Although these works propose the use of learning or deterministic models for micro-climate predictions, most of them applied these models to achieve different goals. For example, the deterministic model proposed in [
28] was aimed at predicting crop temperature from measured air temperature, air density, and other related sensor-measured environmental conditions. The authors argued that rather than the air temperature, the crop temperature is responsible for crop growth and development. In [
31], a dynamic model based on energy and mass transport processes, such as the mechanism of conduction, convection, radiation, etc., was employed to realize a prediction model capable of predicting the temperature of air in plant communities. Although the use of such models is very dependent on the structure of the greenhouse model, the authors claimed that the proposed model can be extended for a general greenhouse micro-climate prediction model. In terms of the use of learning networks, Liu et al. [
30] proposed the use of ELM for predicting temperature and relative humidity from historical samples of indoor temperature and humidity. In order words, the learning model is aimed at predicting current micro-climates based on previously sampled or measured micro-climates. This is beneficial in situations where the cost of continually measuring micro-climates in terms of energy and communication protocols is high and needs to be minimized. In [
9,
29], where MLP-NN and ANN were employed, respectively, the aim of the models was to predict indoor or internal micro-climates based on measured external micro-climates such as temperature, relative humidity, wind speed, etc. Although the aforementioned works have considered the prediction of micro-climates in the greenhouse setting, the aims of their predictions are different from ours, where we predict the measurements of micro-climates at varying optimal sensor locations using input data from fixed-placed sensors.
Generally, it can be observed that most of the aforementioned models are relatively not computationally expensive. This is because the choice of model or learning networks for such applications is usually motivated by the nature of the underlying data (real-valued vectors) and the need for quick prediction or low inference time. In a similar fashion, we employ a simple multi-channel learning model that extracts global features from all the input data, which are consequently fed into the channels’ response for extracting local features corresponding to micro-climate measurements from different sensor locations.
3. Data Description and Pre-Processing
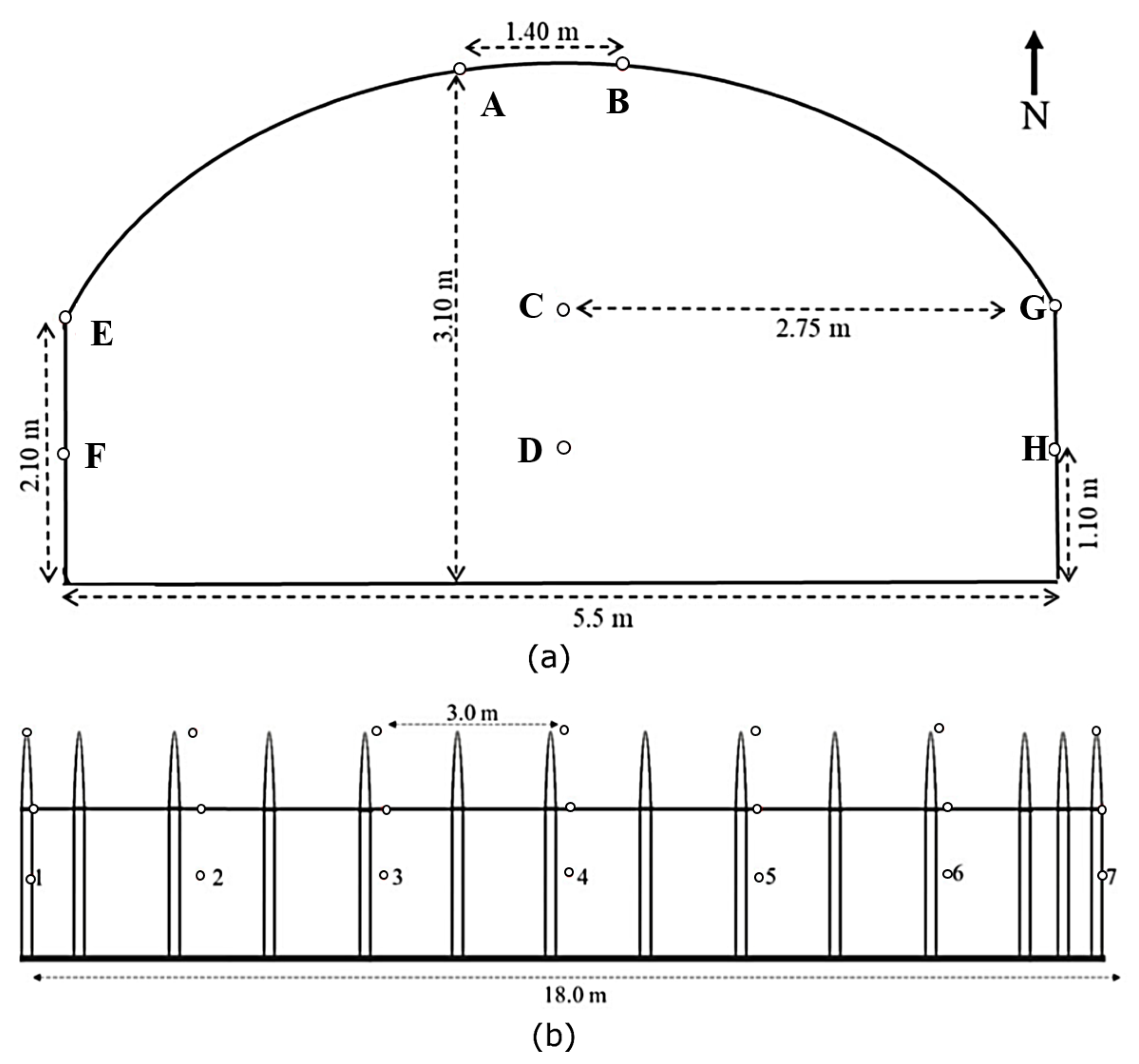
The dataset [
25] employed in the current work contains sensor readings corresponding to internal temperature and relative humidity from 56 two-in-one sensors distributed within a greenhouse used to cultivate strawberries in Daegu, South Korea. The readings were collected for seven months (February, March, April, May, June, July and October). In [
25], the same dataset was used to rank the sensor locations corresponding to each of the seven months. A more detailed description of the protected cultivation facility in terms of size and materials from which the data were collected, the type of sensors used, and how the 56 sensors were distributed within the greenhouse are provided in [
25].
In
Figure 1, the overall layout of the sensors in the considered greenhouse is provided. In addition, the sensor locations corresponding to temperature (T) and relative humidity (RH) corresponding to each month are ranked based on their ability to estimate the micro-climates of the greenhouse [
25]. Due to space constraints, we only present the top 10 ranked sensor locations for each month in
Table 1. A detailed ranking of the 56 sensors for each month can be found in [
25].
In the current work, we assume that
sensors are fixed at
top-ranked locations (referred to as optimal locations) corresponding to the month of February, as shown in
Table 1. It should be noted that the optimal locations corresponding to temperature and relative humidity are different. Therefore, the fixed sensor locations for measuring temperature and relative humidity would be different. By observing the measurements obtained at these fixed locations, the goal is to develop a model that can predict the measurements corresponding to the
optimal locations of the target month (say March). By doing so, the micro-climates of the greenhouse in the month of March, the target month, is accurately estimated without shifting the locations of the sensors. In other words, one prediction model is developed corresponding to each target month (March, April, May, June, July, and October). Therefore, the prediction accuracy of the models determines the precision of micro-climates estimation.
Since the model is expected to predict the values corresponding to the sensors at the optimal locations in the target months based on measurements from February, it is important to ensure consistency in comparison across the various months. Therefore, considering that the number of days in February is less, the length of the entire data samples is limited to those available in the month of February. Furthermore, the rows with missing sensor values were removed across all corresponding input and target months.
In terms of implementing the learning networks, the datasets were divided into training, validation, and test sets. The training and test set consists of 80 percent and 20 percent of the entire data, respectively, and 20 percent of the training data were used as the validation set. In order words, the dataset was divided, with 64%, 16%, and 20% of the entire dataset used for training, validation, and testing, respectively.
Table 2 provides a summary of the length of the training, test, and validation dataset. Furthermore, to ensure a faster convergence of the model, normalization of the input data based on the mean and standard deviation was performed. In the context of predicting sensor values, the input variable
x is a
-dimensional vector comprising readings from
temperature or relative humidity sensors for each case. The output
y are
real values corresponding to temperature or relative humidity values for the target months.
5. Results and Discussion
The proposed model in this work was implemented and evaluated using Python and Keras installed on a computer with an Intel(R) Core(TM) i7, 2.60 GHz, 16 GB RAM, running Windows 10, 64-bit. The results from the experiments are presented in this section accordingly.
5.1. Temperature and Humidity Prediction RMSE
Based on different values of
and
, the results of temperature prediction for all the six months are presented in
Table 3 in terms of RMSE. Furthermore, the table includes the resulting RMSE of the sensor readings without the DNN model as well as the percentage error margin incurred with the DNN model compared with those without the DNN model. The resulting RMSE values, as presented in
Table 3, is indicative that the error associated with the proposed DNN-based prediction of the temperature values from the optimal sensor locations in each month is significantly lower than those measured without the DNN model. Specifically, the proposed framework, which is based on the DNN model results in a 68.67% reduction in the average RMSE over all the five months compared to those obtained without the DNN model.
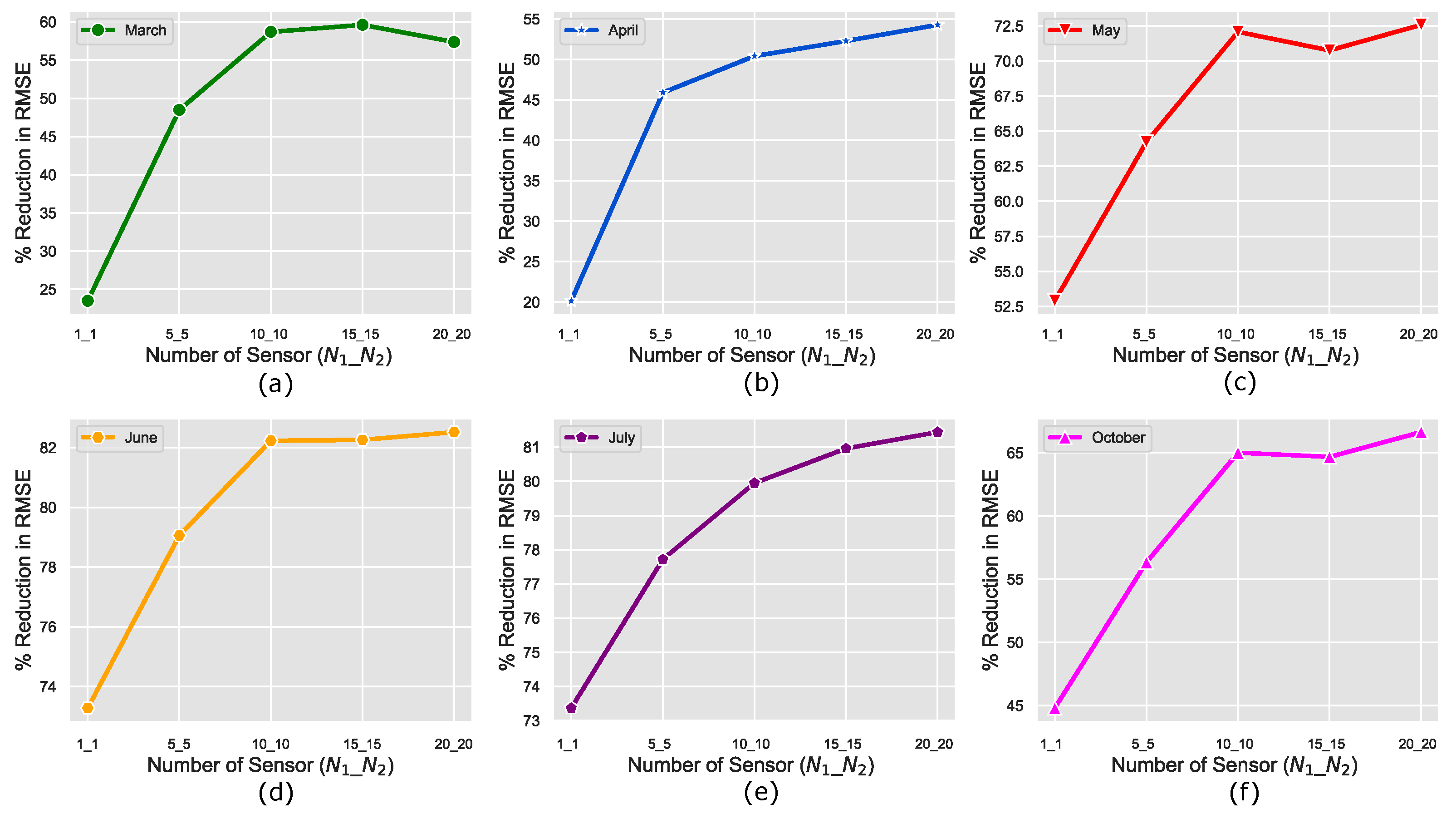
In [
25], the optimal sensor locations were identified based on the ranking of all the 56 sensors distributed within the greenhouse. Consequently,
sensors were selected. However, there was no clear analysis to justify why only
sensors were selected as the optimal number of sensors. Since the DDN-based prediction of the greenhouse micro-climates is superior to those without the DNN model, we provide further analysis based on the DNN model. Specifically, to show the effect of using different numbers of input (
) and output (
) sensors, we present a graphical illustration of the percentage reduction in error incurred with the DNN model for
=
= 1, 5, 10, 15, and 20 for each month, respectively, in
Figure 3. From the figure, it is clear from the error curves that the knee or saturation point is the
=
= 10 for all the months. This is because a drastic increase in error reduction is observed from
=
= 1 to
=
= 10. However, as the values of
=
> 10, the percentage improvement saturates. This might be because of the fact that adding more sensors may not provide any extra information that can help better estimate the micro-climates of the greenhouse. This validates the selection of 10 highly ranked sensors as optimal in [
25].
In
Table 4, the results of humidity prediction for all the associated months are presented in terms of RMSE. The table further includes the resulting RMSE of the sensor readings obtained without the DNN model. In terms of the RMSE, the results show that there is a 46.21% overall reduction in error of the predicted humidity values based on the DNN-based framework compared to those obtained without the DNN model. In addition, the percentage improvement in the measurement error of relative humidity follows a similar pattern to the temperature, as shown in
Figure 3.
5.2. Correlation Coefficients
Correlation results based on Pearson’s correlation coefficients between the real sensor value readings and predicted sensor value readings are shown in
Table 5. From the table, it can be observed that the predicted sensor values are highly correlated with the true sensor values by an average correlation value of 0.91 and 0.85 for temperature and humidity, respectively. These average correlation values are comparable with those from the literature, where the correlation coefficients generally range between 0.977 to 0.980 and 0.825 to 0.967 for temperature and relative humidity, respectively [
9,
33].
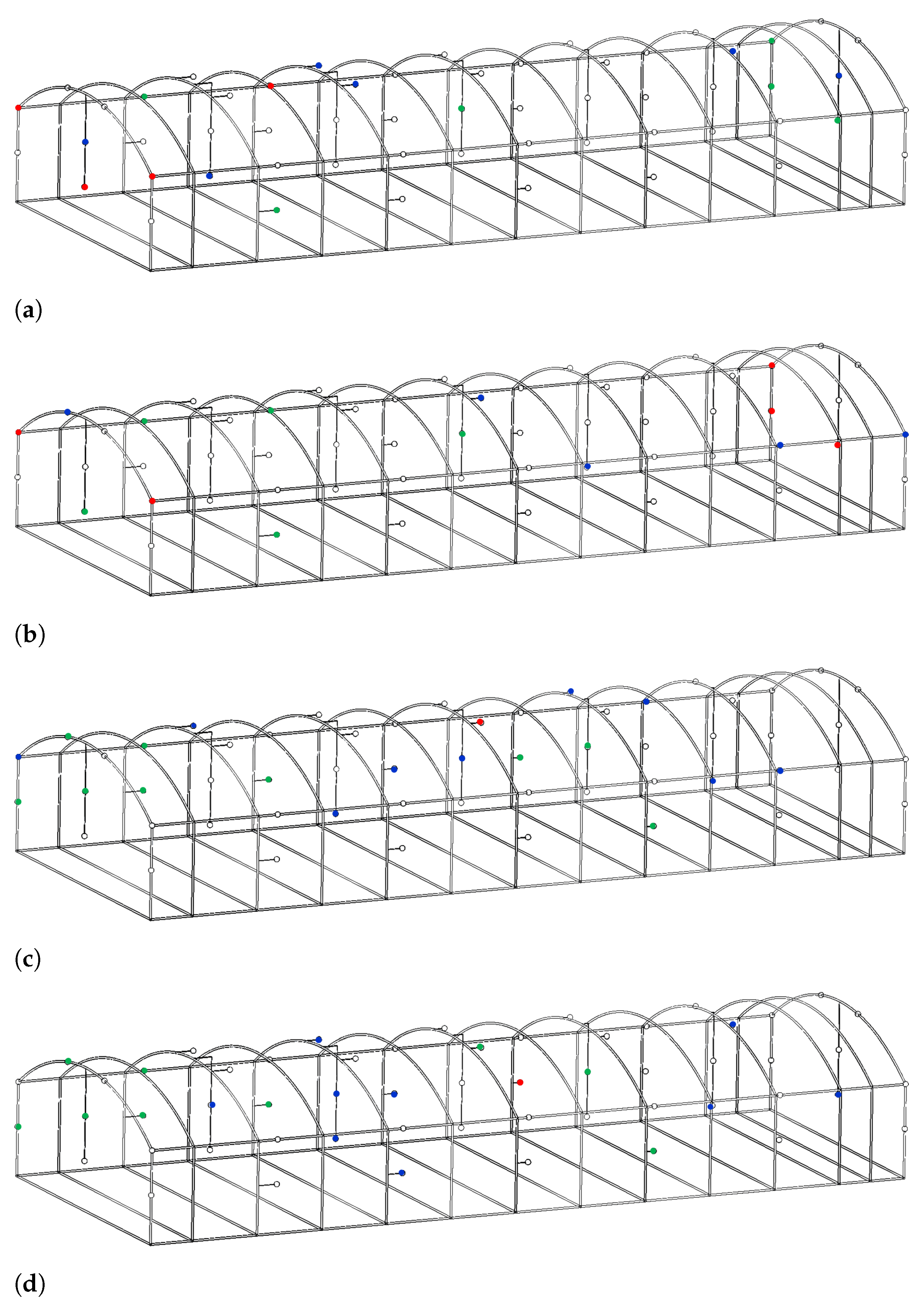
Furthermore, both temperature and humidity show a similar correlation trend, where the highest values of 0.95 and 0.94 are obtained in the month of March, while the lowest values of 0.82 and 0.75 are obtained in the month of July, respectively. This can be attributed to how the optimal sensor locations of March and July are distributed relative to the fixed sensor locations. In
Figure 4, the fixed sensor locations (green) and optimal sensor locations of target months (March and July) are highlighted (glue) for both temperature and humidity to show the effect of the respective locations in the overall percentage of error reduction. In addition, the optimal locations of the target month (March and July) that overlap with some of the fixed locations are depicted in red.
As depicted in
Figure 4a,b, the target months of March and July have four and five overlapping temperature sensor locations with respect to the fixed locations, respectively. Furthermore, as shown in the figure, the sensor locations of March compared to the fixed locations are closer, and for each of the fixed locations, there are also representative locations in March in the same region. However, in July, the sensor locations are much farther from those of the fixed locations when compared with those in March. Therefore, the proximity of the optimal sensor locations of the target month March with respect to the fixed locations resulted in a higher correlation compared to that of July.
Similarly, in terms of humidity, although both March and July have only one overlapping sensor location with fixed locations, as shown in
Figure 4c,d, it is clear that the high correlation in March can be associated with the observation that the sensors are well distributed in regions close to the fixed locations. On the other hand, the sensor locations of July are simply packed in regions where none of the fixed sensors are located.
5.3. Effect of Number of Fixed Sensor Locations on the Prediction Accuracy of DNN Model
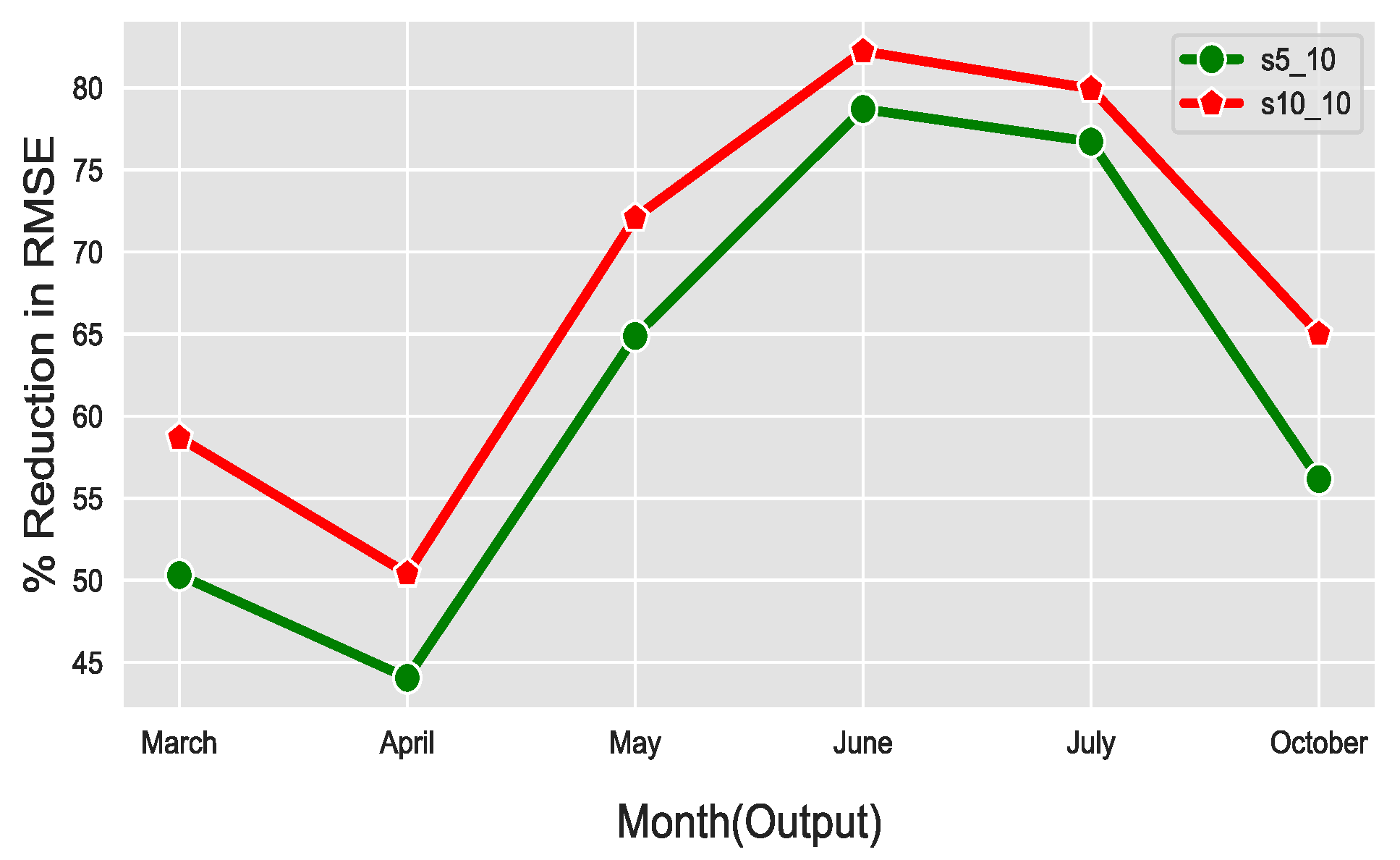
In the previous section, the analysis was conducted considering that the input and output dimensions, and , respectively, are equal ( = ). However, it would be interesting to investigate instances where as this would help to facilitate decisions related to the trade-off between cost and accuracy of estimation. Specifically, the input dimension is directly related to cost, while the output dimension N is directly proportional to the accuracy of prediction, thus providing a better estimation of micro-climates. In other words, since is the number of sensors that would be installed, as the number of sensors increases, the cost also increases. On the other hand, as the number of increases, the accuracy of prediction tends to increase until saturation is reached.
Table 6 summarizes the RMSE values for different combinations of the input and output number of sensors. From
Table 6, we can observe that the prediction accuracy of the DNN model, where the input of 10 sensors is provided is better compared to the prediction of the DNN model with only 5 input measurements. However, the prediction accuracy of the DNN model that employs five input measurements is better than the measurements taken from fixed sensors (or without the DNN model). In other words, it is intuitive that installing more sensors can help estimate the environment better, as clearly depicted in
Figure 5, but it is expensive. Therefore, the best way is to use fewer sensors and use the model proposed so that the environment can be better estimated by predicting the values of the sensors at top preferred locations.
The above analysis was conducted with respect to the temperature measurement in the greenhouse. However, a similar observation was made with respect to the measurement of relative humidity in the greenhouse.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}