1. Introduction
The price of commodities in the international market varies significantly and rises over time. The fluctuation in commodity prices has a significant impact on the world economy, increasing import costs, promoting inflation, stifling economic growth, and reducing the effectiveness of macroeconomic policy [
1]. Therefore, the global economy must analyze the features of variations in commodities sold on foreign markets to forecast their price and their historical patterns.
As one of the most important energy resources and one of the most widely traded commodities, crude oil is crucial to the global economic system. It is well known for having significant price changes that directly affect the world economy. Crude oil, an essential component of industrial production, has a significant impact on the growth and stabilization of the world economy and the international financial markets. Crude oil price changes have a severe impact on the development and safety of nations worldwide by limiting their growth and destabilizing the global economy [
2]. Oil importers may experience inflation and other economic effects as oil prices rise, whereas oil exporters may experience an economic slump and political unrest as oil prices decrease [
3].
Due to the above-stated factors, researchers have paid a lot of attention to the energy crisis and the volatile petroleum price [
4,
5]. Crude oil is a commodity with significant worldwide influence because it is the key source of primary energy. However, predicting the price of oil is a difficult task since many factors (global economic conditions, speculative expectations, extreme events, political instabilities, and technological trends) influence oil pricing, and the strengths of these factors change over time [
6,
7]. Because of the above-mentioned factors, forecasting day-ahead crude oil prices is one of the most important and challenging tasks and attracts the attention of researchers.
According to the literature, the price of crude oil has been predicted using different types of forecasting techniques. These predictive models can be broadly classified into three main categories: (a) statistical and econometric models; (b) machine learning algorithms; and (c) hybrid models. Statistical and econometric models used for crude oil forecasting include random walk, autoregressive, autoregressive integrated moving average, autoregressive conditional heteroscedasticity, generalized autoregressive conditional heteroscedasticity, vector autoregressive, vector error correction models, etc. [
8,
9]. For instance, Xiong and Wu [
10] employed the vector error correction (VEC) model and cointegration analysis to forecast the demand for crude oil in China. Gülen [
11] also forecasts the West Texas Intermediate (WTI) crude oil price by using the cointegration methodology. Lanza et al. [
12] used the error correction model (ECM) specification to predict crude oil prices. Drachal [
13] used the vector autoregression model (VAR) and found that these models are more accurate than single equation models for forecasting. Ahmad [
14] used Box–Jenkins approaches to examine Oman’s average monthly crude oil prices and recommended the seasonal model ARIMA
. Morana [
15] forecasted the oil prices for short-term horizons by using the semiparametric generalized autoregressive conditional heteroscedasticity (GARCH) model. Mohammadi and Su [
16] evaluated the predictions of several ARIMA-GARCH models on the weekly prices of crude oil in eleven global markets. Hou and Suardi [
17] used a nonparametric GARCH model, which indicates that this approach provides an appealing and practical substitute for the widely used parametric GARCH models. Joshi [
18] used a linear regression model to forecast oil prices. One of the main assumptions of econometric and statistical models is linearity, and they provide good results when the price series are linear or close to linear. These models might not be the best choice, because there is a lot of nonlinearity and inconsistency in the observed crude oil price series [
19].
On the other hand, the price forecasting literature has developed and used several machine learning models, including support vector machines, genetic algorithms, and artificial neural networks, in response to the shortcomings of statistical and econometric methodologies. For example, a neural network model was developed by Movagharnejad et al. [
20] to analyze the price changes in different commercial oils in the Persian Gulf region. Mirmirani and Li [
21] used vector autoregression and artificial neural networks to investigate US oil prices and suggested that in forecasting, a BPN-GA model can perform better than a VAR model. Through the use of the hierarchical conceptual (HC) and artificial neural networks-quantitative (NNA-Q) models, machine learning and computational intelligence techniques are used to forecast the monthly WTI crude oil price for each barrel in US dollars. The outcome of the simulation analysis verified the efficiency of the HC model’s data selection method [
22]. Xie et al. [
23] suggested a new SVM-based technique to forecast the price of crude oil. They compared SVM’s performance with that of ARIMA and BPNN to assess its potential for forecasting. Several studies have shown that when it comes to price prediction, AI models frequently outperform traditional time series models [
19,
24,
25]. Moreover, AI models can have flaws and limitations of their own. For instance, the choice of parameters affects NNAs [
19]. Other proposals fir time series analysis and forecasting can be found in [
26,
27,
28,
29] and references therein.
The complexity of oil pricing is due to relevant time series frequently including lag, nonlinearity, and connections to several markets. It has been difficult in the literature to suggest a hybrid model that can both capture and optimize these aspects. Abdollahi, H., and Ebrahimi, S. B. [
30] proposed a hybrid model to forecast daily Brent crude oil prices with the lowest possible forecasting error and, more importantly, to introduce a hybridization that is best able to capture the key characteristics of the oil price time series, including nonlinearity, lag, and market interactions.
In recent studies, Chen, Z. et al. [
31] used the MIDAS modeling framework, which is a common mixed data sampling approach, to investigate how leverage and jumps affect the ability to forecast the realized volatility (RV) of China’s crude oil futures. This study’s findings can be utilized to better predict the volatility of China’s crude oil futures, reduce investment risks, and provide higher profits. Salisu, A. A., et al. [
32] found that the GARCH-MIDAS-X model for oil volatility forecast accuracy is improved by considering any inherent asymmetries in the global economic activity proxies. The findings that led to these conclusions are valid across a range of forecast periods and alternative energy sources. The Musetescu, R.C., et al. [
33] approach involves forecasting conditional variance over two distinct periods, 20 May 1987 to 24 January 2022 and 20 January 2020 to 24 January 2022. In comparison to the model GARCH-M (1,1), which is appropriate for the period 2020–2022, the forecasting results showed that GARCH (1,1) was the model with the highest level of crude oil volatility anticipated for the entire time. Xing, L. M. and Zhang, Y. J. [
34] studied various shrinkage mechanism specifications to forecast the crude oil price and evaluated the prediction effectiveness from both a statistical and an economic standpoint. By considering the nonlinear forms of predictors, Zhang, Y., et al.’s [
35] study aimed to enhance the forecasting capabilities of diffusion index (DI) models. To be more precise, they used principal component analysis (PCA) and partial least squares (PLS), two popular DI models, to forecast monthly crude oil returns.
In today’s modern world, day-ahead forecasting is beneficial for operational planning, enabling companies to efficiently change production schedules, improve logistics, and allocate resources. On the other hand, short-term forecasting facilitates risk management by allowing traders to measure market volatility and control portfolio risk. In addition, accurate and efficient day-ahead forecasts help energy traders to make wise judgments concerning purchases and sales of energy commodities. Therefore, this study provides a comprehensive analysis of forecasting Brent crude oil prices by comparing various hybrid combinations of linear and nonlinear time series models. To this end, first, the logarithmic transformation is used to stabilize the variance of the crude oil prices time series; second, the original time series of log crude oil prices is decomposed into two new subseries, a long-run trend series, and a stochastic series, using the Hodrick–Prescott filter; and third, two linear and two nonlinear time series models are considered to forecast the decomposed subseries. Finally, the forecast results for each subseries are combined to obtain the final day-ahead forecast. The proposed modeling framework is applied to daily Brent spot prices from 1 January 2013 to 27 December 2022.
The remainder of the paper is designed as follows:
Section 2 comprises the general procedure of the proposed hybrid forecasting approach.
Section 3 contains an empirical application of the proposed forecasting methodology using the daily Brent oil price data.
Section 4 details the discussion of the proposed best combination model versus the considered standard linear and nonlinear time series benchmark models. Finally,
Section 5 covers the conclusions, limitations, and future research directions.
3. Empirical Study Outcomes
This work uses the time series of daily spot Brent oil prices for the ten years from 1 January 2013 to 27 December 2022 (a total of 2239 days). The data used in this study were freely obtainable from the Energy Information Administration website of the Department of Energy of the USA
http://www.eia.doe.gov/ accessed on 1 February 2023.
Table 2 shows the descriptive statistics, such as the number of days, average price, and minimum and maximum prices of the yearly Brent prices. It can be seen from this table that the minimum price was 9.12, which was recorded on 21 April 2020, whereas the maximum price was recorded on 8 March 2022. The minimum value was a consequence of the COVID-19 pandemic that affected the majority of stock markets across the globe. It is worth mentioning that the average price in 2020 was 41.957, which is the minimum among all the years between 2015 and 2022. For modeling and forecasting purposes, three different scenarios are considered: (50%, 50%), (75%, 25%), and (90%, 10%). In each scenario, the first part is the training set that was used to train the models and estimate the parameters, and the second part is the test dataset used to evaluate the performance of the considered forecasting models. The details about all three scenarios are shown in
Table 3.
In order to obtain the forecast for the Brent crude oil price one day ahead using the proposed forecasting methodology described in
Section 2, the following steps had to be followed: first, the HP filter was used to obtain a nonlinear long-run trend (
), and the stochastic (
) time subseries. Second, the previously described four standard time series models were applied to each subseries. Then, the model parameters were estimated, and the one-day-ahead forecast was obtained using the rolling window method, using the different training and testing samples as described in
Table 3. Thus, the final one-day-ahead Brent crude oil price forecasts were obtained using Equation (
16). The different accuracy mean measures (RMASE, MAPE, MAE, RMSE, CC, and DS) were then used to evaluate and compare the performance of the models.
Forecasts for these subseries were obtained using two linear and two nonlinear time series models. To this end, different combinations of the models were used for subseries forecast (
= 16) for each training and testing scenario, (50%, 50%), (75%, 25%), and (90%, 10%), for a total of 48 (
) models. For these 48 models, the one-day-ahead out-of-sample forecast accuracy measures (RMASE, MAPE, MAE, RMSE, CC, and DS) are tabulated in
Table 4. From this table, the results for the first scenario (50%, 50%) show that the
model produced a better forecast than all of the other combination models. The best forecasting model is
, obtaining 0.5435, 0.8808, 0.0171, 0.8196, 0.9993, and 0.9280 for RMSPE, MAPE, MAE, RMSE, CC, and DS, respectively. However, the
and
models are reported as the second and third best models. In contrast, the
,
,
, and
models are shown to have the worst results compared to the rest of the combination models. Furthermore, from the second scenario’s (75%, 25%) results, it is clear that compared to the other combination models, again the
model shows better forecasting in terms of accuracy measures: RMSPE = 0.6132, MAPE = 0.7573, MAE = 0.0104, RMSE = 0.9523, CC = 0.9992, and DS = 0.9364. Again, the
and
models are rated as the second and third best models, and the
,
,
, and
models, in contrast, had the worst outcomes when compared to the other models. Finally, in the third scenario’s (90%, 10%) results, once again, the
model outperformed the rest of the combination models in terms of forecast accuracy measures, with the RMSPE, MAPE, MAE, RMSE, CC, and DS equal to 0.9299, 0.8969, 0.0122, 1.3248, 0.9953, and 0.9518, respectively. On the other hand, once again, the
and
models are reported as the second and third best models. Finally, once again, the
,
,
, and
models had the worst outcomes compared to the rest. Therefore, based on the accuracy measures, the
model is declared the best model among all of the combination models. The consistency of this model (
) is approved by all three training and testing samples.
After obtaining the best combination model based on the accuracy metrics, the next step is to confirm the superiority of the best model listed in
Table 4 using the DM test. The DM test results (
p-values) are shown in
Table 5 for all three training and testing scenarios: (50%, 50%), (75%, 25%), and (90%, 10%). It is confirmed from this table that among all of the sixteen combination models, the
,
, and
models are statistically superior to the others at the 5% significance level in each training and testing sample set. Although within these three best models, the
model produces the highest
p-value, which indicates that the
is statistically most significant compared to the rest of the models in all three scenarios. Thus, it can be concluded that the
combination model is the best model among all of the combination models.
Finally, after confirming the superiority of the best combination model (
) by performance measures and a statistical test, we need to check the superiority of the best model using graphical tools. For this purpose,
Figure 4 shows the mean accuracy errors (RMSPE, MAPE, MAE, and RMSE) of all of the sixteen combination models. The arrangement of these figures is the following: (a) the first scenario results (50%, 50%), (b) the second scenario results (75%, 25%), and (c) the third scenario results (90%, 10%). It can be seen from these bar plots that the
model produces the best results compared to the rest of the combination models. Although
and
are the best competitors,
,
,
, and
showed the worst outcomes. In the same way, the correlation plot of the best model (
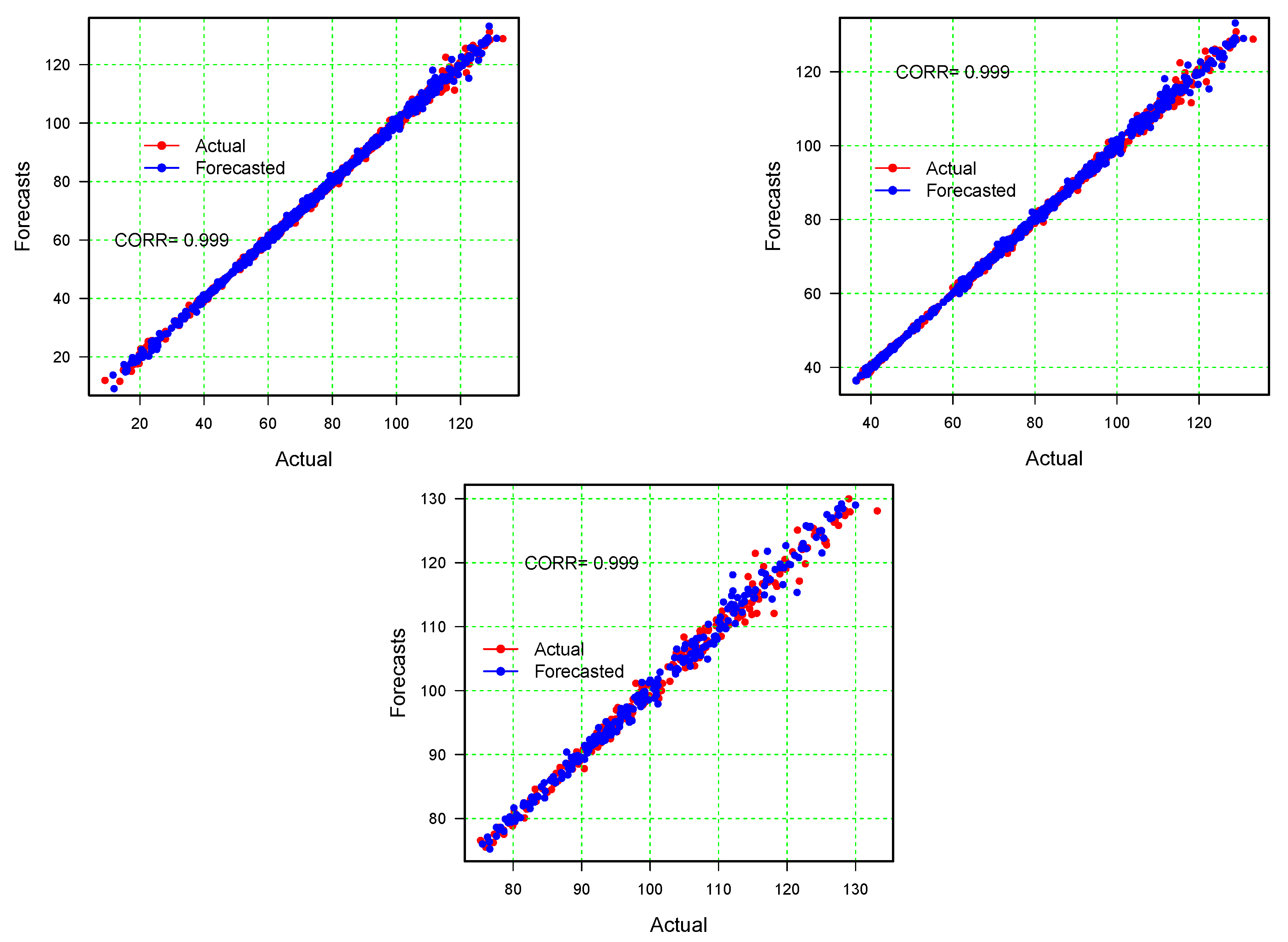
) out of all of the sixteen models in each training and testing scenario is shown in
Figure 5: (a) the first scenario results (50%, 50%), (b) the second scenario results (75%, 25%), (c) the third scenario results (90%, 10%). From these figures, it can be seen that the best model (C
) has the greatest correlation coefficient value and shows a significant correlation between the real and forecast values. Finally, at the end of this section, the real and forecast values for the best three combinations of models, C
, C
, and C
, are superimposed on
Figure 6; each training and testing scenario is shown in
Figure 5: (a) the first scenario results (50%, 50%), (b) the second scenario results (75%, 25%), (c) the third scenario results (90%, 10%). As can be seen in the figure, our model’s forecast follows the original Brent crude oil prices very well. Thus, to conclude this section, from the accuracy metrics (RMSPE, MAPE, MAE, RMSE, CC, and DS), a statistical test (DM test), and graphical outcomes (bar, correlation, and line plots), we can conclude that the proposed hybrid forecasting methodology is highly efficient and accurate for day-ahead Brent crude oil prices. In addition, within the proposed combination of models, the C
model produced more precise forecasts when compared with the alternative combinations.
4. Discussion
In this section, we discuss the comparison of the proposed best combination model with the considered standard benchmark models, such as the autoregressive, autoregressive moving integrated average, nonparametric autoregressive, and nonlinear neural network models. The details about the comparison are shown as follows; a numerical presentation in
Table 6 and a graphical presentation in
Figure 7. From both presentations, it can be seen that the best model proposed in this work produced comparatively accurate and efficient forecasts for the one-day-ahead Brent crude oil prices. The best-proposed combination model obtained the lowest accuracy measures (RMSPE, MAPE, MAE, and RMSE) and the highest values of CC and DS in all scenarios of training and testing sets, which are significantly better than all of the considered benchmark models in all three training and testing data samples. On the other hand, to confirm the superiority of the proposed best model mentioned in
Table 6, we performed a statistical test using the DM on each pair of models. The results (
p-values) of the DM test are reported in
Table 7, showing that among all of the considered benchmark (AR, NPAR, ARMA, and NNA) models, our best combination model outperformed them at the 5% significance level for different combinations of training and testing data. To conclude, based on all of the results, the efficiency and accuracy of the proposed hybrid forecasting technique are comparatively high when compared with all considered competitors.
To sum up this section, crude oil is one of the main energy sources, and its prices have gained increasing attention due to its important role in the world economy. Therefore, accurate prediction of crude oil prices is an important issue not only for ordinary investors but also for the whole of society. To achieve accurate forecasts of nonstationary and nonlinear Brent crude oil price time series, a novel hybrid forecasting technique is developed in this study. Perhaps policymakers, as well as traders, could use the proposed forecasting method when forecasting economic or financial time series data. Our research findings will be of particular interest to investors, traders, regulators, and others. Good forecasts and knowledge of crude oil price trends in developed and developing economies can help traders make more profitable business and trading plans and make useful asset allocation decisions. In addition, based on the best-proposed model, a more robust trading plan can be developed, and the model with the best risk–reward combination can be chosen.
5. Conclusions
Crude oil price forecasting is an important research area in the international bulk commodity market. However, the properties of the time series of daily crude oil prices are complex, being nonstationary and nonlinear, which makes it challenging to produce accurate forecasts. Aiming at bridging that gap, this research work proposed a new hybrid forecasting methodology for daily Brent oil spot prices in which we split the time series of Brent spot prices into two subseries, the long-term nonlinear trend and a stochastic (residual) series, using the Hodrick–Prescott filter. To forecast the two subseries, we also considered two linear and two nonlinear time series models. The proposed modeling framework was applied and evaluated with daily Brent spot prices from 1 January 2013 to 23 December 2022. Six different accuracy measures, pictorial analysis, and statistical tests were performed across different combinations of training and testing data, i.e., (50%, 50%), (75%, 25%), and (90%, 10%). For each of these three scenarios, the model C was found to be the best-proposed combination model because it resulted in lower accuracy measures and larger values for CC and DS. However, C and C were found to be good competitors. After that, we compared the best-proposed combination model to the benchmark models (AR, ARIMA, NPAR, and NNA) by using different accuracy measures and the test, showing that the proposed model outperformed the other models.
In conclusion, this study focused specifically on the daily Brent oil price dataset, but the proposed hybrid forecasting technique can be extended to other markets, such as West Texas Intermediate, Dubai Crude Oil, Oman Crude Oil Futures, and more, to evaluate its performance in diverse contexts. By incorporating additional combinations of time series and machine learning models, such as generalized autoregressive conditional heteroskedasticity, support vector machines, decision trees, random forests, short-term memory networks, and other advanced techniques, future research can broaden the range of forecasting approaches and potentially enhance the accuracy and applicability of the proposed methodology. Moreover, only the HP filter was used in this work. In the future, it should be extended to include other filters and check the performance of different filters within the proposed hybrid time series combination models, for example, Hamilton’s filter, exponential moving filter, nonparametric regression filters, etc. In addition, the proposed hybrid forecasting model’s consistency can be assessed using two-day-ahead, three-day-ahead, five-day-ahead, etc., forecasting in future work.
Furthermore, the findings of this study indicate that the proposed combination model outperformed other methods in capturing the complex and nonlinear behavior of crude oil prices. This suggests that the hybrid forecasting approach holds promise for applications beyond crude oil prices (for example, energy [
47,
48], air pollution [
49,
50,
51], solid waste [
52], academic performance [
53] and digital marketing [
54]). Therefore, it is recommended to employ this methodology for forecasting other complex financial time series data, such as inflation, unemployment, and cryptocurrencies. The demonstrated ability of the hybrid model to deliver highly efficient and accurate forecasts in such scenarios can provide valuable insights into various financial domains.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}