
An Ensemble Method for Feature Screening

1
National Cancer Center, National Clinical Research Center for Cancer, Cancer Hospital, Peking Union Medical College, Chinese Academy of Medical Sciences, Beijing 100021, China
2
NCMIS, KLSC, Academy of Mathematics and Systems Science, Chinese Academy of Sciences, Beijing 100190, China
3
School of Science, Beijing University of Civil Engineering and Architecture, Beijing 100044, China
*
Author to whom correspondence should be addressed.
Mathematics 2023, 11(2), 362; https://0-doi-org.brum.beds.ac.uk/10.3390/math11020362
Submission received: 23 October 2022
/
Revised: 3 January 2023
/
Accepted: 6 January 2023
/
Published: 10 January 2023
(This article belongs to the Special Issue Statistical Methods for High-Dimensional and Massive Datasets)
Abstract
:It is known that feature selection/screening for high-dimensional nonparametric models is an important but very difficult issue. In this paper, we first point out the limitations of existing screening methods. In particular, model-free sure independence screening methods, which are defined on random predictors, may completely miss some important features in the underlying nonparametric function when the predictors follow certain distributions. To overcome these limitations, we propose an ensemble screening procedure for nonparametric models. It elaborately combines several existing screening methods and outputs a result close to the best one of these methods. Numerical examples indicate that the proposed method is very competitive and has satisfactory performance even when existing methods fail.
Keywords:
classification; nonparametric regression; R-square; sparsity; sure independent screening; variable selectionMSC:
62G08; 62H301. Introduction
In this paper, we study the feature screening problem for nonparametric models when the number of predictors, p, is larger than the number of observations, p. The nonparametric models we focus on include nonparametric interpolation, regression, and classification models. Interpolation is commonly used in modeling computer simulation experiments [1] and spatial data [2]. Nonparametric regression and classification are basic issues in statistics and machine learning [3]. High-dimensional problems are commonly encountered in these areas.
For linear regression models with , Fan and Lv proposed the sure independence screening (SIS) method to screen the subsets of important/active features/predictors/variables [4]. This method was extended to generalized linear models [5], nonparametric additive models [6], and varying coefficient models [7]. Many model-free SIS-type methods were also provided in the literature, see, e.g., [8,9,10,11,12], and they can be used for the aforementioned high-dimensional nonparametric models. These SIS-type methods consider random predictors and screen active predictors by ranking some independence indices, which describe the independence between each predictor and the response.
For nonparametric interpolation models with , Li, Chen, and Xiong proposed the linear screening method [13]. Their idea stems from the method of selecting important variables via the main effects in the experimental design literature [14]. This method adopts linear regression to model the data from nonlinear models and uses the -screening [15,16] or -screening principle [17] for the linear model to screen the active variables. Li, Chen, and Xiong proved that the linear screening method is asymptotically valid under some conditions [13]. Numerical simulations show that this method performs better than SIS-type methods in most cases for interpolation models.
Note that the linear screening method can also be used for other nonparametric problems, including regression and classification. In this paper, we first discuss the two classes of nonparametric screening methods, the SIS-type and linear screening methods, and then point out their own limitations. For the SIS-type methods, we provide an example where the regression function depends on a variable while the random version of this variable is independent of the response. Therefore, any independence index-based SIS-type method cannot screen this important variable of the regression model. For the linear screening method, we show that when the function is not close to a linear norm and the predictors are correlated, it may perform very poorly. To overcome these limitations, we propose an ensemble procedure to combine the two classes of methods. This procedure conducts the linear screening methods with linear and quadratic basis functions first and uses to evaluate their performance. If the values of are low, then we further conduct an SIS-type method and output the result of this SIS-type method. Otherwise, we output the subset selected by the linear screening method corresponding to the higher . The ensemble method is very simple and easy to implement. Simulations and several real examples show that it is very competitive and has satisfactory performance even when the SIS-type methods or the linear screening methods fail.
This article is organized as follows. Section 2 gives a general description of sparse function models. Section 3 discusses the limitations of the SIS-type and linear screening methods. Section 4 presents the proposed ensemble method. Section 5 illustrates the methods with several datasets. We conclude the paper with some concluding remarks in Section 6. More simulation results and technical proofs are given in the Supplementary Materials.
2. Sparse Function Models
This section discusses some basic characteristics of sparse function models in a rigorous mathematical manner. We will emphasize that the sparsity property of a function does not depend on the distributions of the covariates/input variables.
Suppose the unknown function of interest is , where the features/variables , f is square integrable, i.e., , is an interval, and ‘denotes the transpose. Without loss of the generality, let , and our discussion can straightforwardly be modified to accommodate general such as or . To make the following notation clear, let denote the range of for .
We need further definitions and notation. Let . For a set , denotes its cardinality. For and , let denote the sub-vector corresponding to and let . Note that is a closed Hilbert space with the inner product for . We write in the sense of the norm in , i.e., . For , define
which is a closed subspace of . It can be seen that and are isomorphic. Define to be the projection of f onto , i.e.,
We know that is the unique projection in the sense of the norm in [18].
We make the following sparsity assumptions. Denote with .
Assumption 1.
.
Assumption 2.
For each ![Mathematics 11 00362 i001]() , .
, .
 , .
, .Proposition 1.
Under Assumptions 1 and 2, if there exists with such that , then .
Proposition 1 shows the uniqueness of . We call the true subset of important/active variables for the nonparametric model f. The goal of screening is to find a subset with . A suggestion for selecting M is [4], where denotes the floor function.
Consider the situations where the variables are random with a probability measure P on .
Assumption 3.
P has a density ψ with respect to the Lebesgue measure, and ψ is positive almost everywhere.
Assumption 3 implies that P is not degenerate. Let
Similarly define for . For , denote if f and g are identical in the sense of the norm in , i.e., . Define to be the projection of onto , i.e.,
We know that is the unique projection in the sense of the norm in . In general, will vary as P varies for fixed f and . However, we have the following proposition showing the invariance property of sparsity.
Proposition 2.
Under Assumption 3, for , the two following statements are equivalent:
- (i)
- and for each
![Mathematics 11 00362 i001]() ;
; - (ii)
- and for each
![Mathematics 11 00362 i001]() .
.
Proposition 2 indicates that the true subset does not rely on the distribution P of , and that the sparsity is an essential property that only depends on f itself. In other words, the true subset uniquely exists and can be identified in theory no matter what distribution the predictors follow. The above results can be extended to the cases where has some discrete components by making assumptions on P accordingly.
A selection principle depends on the distribution P of the variables , i.e., . An ideal selection principle should satisfy the selection consistency property for all reasonable P, where is free of P by Proposition 2. For the cases of , the selection consistency property is usually relaxed as the sure screening property . Based on the sample version of P, the sure screening property requires that the probability of should tend to one as [4]. However, for nonparametric function f, it is difficult to find an ideal selection principle. We will show that there exist commonly-encountered P’s that cause popular screening methods do not have the selection consistency property in the next section.
3. Discussion on Existing Methods
For a high-dimensional sparse function f discussed in the previous section, the feature screening problem is to find an M-subset of these p variables that can include all the active variables based on data of sample size n (), where is a pre-specified number.
3.1. SIS-Type Methods
The SIS-type methods consider the situations with random predictors (covariates). Let follow a probability measure P. The SIS-type methods use the selection principle
where Y is the corresponding random response depending on the underlying function f. For instance, we review Li, Zhong, and Zhu [9]’s method as follows.
Li, Zhong, and Zhu used the distance correlation (DC) to screen the important variables [9]. For two random variables U and V, the DC between them is denoted by . Székely, Rizzo, and Bakirov showed that if and only if U and V are independent [19] and that can be computed by
where , , , , and is an independent copy of .
Suppose that is a random sample from the population . The DC can be estimated by
where , , , .
For p random predictors and the response Y, we have the sample , where . The DC-SIS method first computes for by (2), and then screens the subset with M variables corresponding to the M largest values among .
We can see from (1) that the SIS-type methods greatly depend on the distribution of . As discussed in Section 2, the sparsity property of a function does not depend on the distributions of the covariates/input variables. The following example shows that the dependency-based selection principle does not have the selection consistency property.
Example 1.
Let and . If is not independent of , then , where P is the joint distribution of .
In the above example, we can say that possesses at least the sure screening property . However, we have the following fact, which can be shown by Example 2.
Fact 1.
The SIS-type methods may lack the screening property, i.e., some important features may be missed.
Example 2.
Let
in a regression model
with , where Φ denotes the cumulative distribution function of the standard normal distribution. Consider the random , independent of ε, generated as follows. First generate , the uniform distribution on . Then generate W, given , from , and let . We have
which implies . Therefore, the response Y is independent of . We cannot find the important variable in f in (3) via dependency.
The case provided in Example 2 seems to be extreme since it depends on special f and P. In fact, for cases that are not so extreme, the performance of the SIS-type methods may be unsatisfactory. This is because they are all marginal methods and may miss the important variables with weak marginal effects in finite-sample cases. Recently Azadkia and Chatterjee proposed a model-free variable selection method via a measure of conditional dependence [20]. Their method possesses appealing theoretical properties. However, our numerical experience indicates that its finite-sample performance is not good for large p, small n problems. SIS-type methods such as DC-SIS outperform it in many cases. Some examples are given in our simulations in the Supplementary Materials.
3.2. Linear Screening Methods
Li, Chen, and Xiong proposed the linear screening method for nonparametric interpolation models [13]. Unlike the marginal SIS-type methods, this method is based on linear approximations of the underlying nonparametric function. Linear screening uses a linear regression model with specific basis functions to fit the interpolation data and applies the or methods for linear regression models to screen the active variables in the nonparametric function f. Li, Chen, and Xiong showed that under some mild conditions, the set of active variables in f is identical to that in the linear projection of f [13]. Therefore, the linear screening method is valid for many cases. Since methods based on dependence and conditional dependence, such as SIS-type methods, suffer from very slow convergence in high dimensions, linear screening can be viewed as an alternative for finite-sample cases.
Li, Chen, and Xiong [13] only discussed the case where the predictors . This subsection further studies the linear screening methods with a general distribution P of , where P satisfies Assumption 3.
For a basis function that is not a constant, define
which is a closed subspace of . Consider the projection of onto with respect to the norm of ,
Denote
Note that the matrix is invertible (see the proof of Lemma B.3 in the Supplementary Materials). By solving the quadratic optimization problem in (4), we have
where . The selection principle of linear screening with basis b is
The following proposition is obvious.
Proposition 3.
Under Assumptions 1 and 2, if , then for all P satisfying Assumption 3.
Proposition 3 provides an ideal selection principle. However, the condition of f in the proposition is very strong. For general f, the following assumptions are needed to make the linear screening method have the selection consistency.
Assumption 4.
for all , where φ is a density function on .
Assumption 5.
For , .
Proposition 4.
Under Assumptions 1–5, .
The following example shows that, without Assumption 4, Proposition 4 may not hold.
Example 3.
Let and . For and both generated from , by (5), some algebra shows that if and only if , where P is the joint distribution of . Therefore, if and are correlated, then , which implies .
By Lemma B.3 in the Supplementary Materials, under Assumptions 1–4, Assumption 5 is the sufficient and necessary condition of . We give an example when Assumption 5 does not hold.
Example 4.
Let
with . Suppose P is the probability measure of , which satisfies Assumption 4. For , , and . Therefore, Assumption 5 does not hold for any basis function b. In fact, the linear screening method selects the variables whose main effects exist, while there are only interactions in Function (6).
The above two examples actually show the following fact.
Fact 2.
The linear screening methods may lack the screening property when Assumption 4 or Assumption 5 does not hold.
Generally speaking, Assumption 4 is not easy to hold but is relatively easy to verify. When Assumption 4 holds, Assumption 5 holds for most cases except for some extreme cases such as Example 4. This is because inequality is usually easier to hold than equality. For example, if f is assumed to be a realization from a Gaussian process, then Assumption 5 holds with a probability of one.
From the discussion in this subsection, we draw the overall conclusions. (a) By Proposition 3, if f is close to , then the linear screening method with basis b performs well for most P. (b) By Proposition 4, if are identically and independently distributed, then the linear screening method is good for many cases. (c) If neither (a) nor (b) holds, then linear screening may be poor.
4. Ensemble Screening
In the previous section, we have pointed out the limitations of the SIS-type and linear screening methods for nonparametric models. To overcome these limitations, here we propose an ensemble procedure that combines the two classes of methods. First consider the linear screening methods, and we know that they perform very well when f is close to its linear approximation. We can use some fitting index to check whether f is close to its linear approximation or not. If the linear screening method with a candidate b passes the check, then we select it to output the screening result; otherwise, we consider the SIS-type methods. The fitting index is selected as the R-square
where and is the ith prediction value of the response from the linear screening method.
Specifically, for interpolation and regression problems, we use the lasso method [17] for the linear model to screen the important feature variables. The ten-fold cross-validation is used to specify the tuning parameter in the lasso. If the number of selected features is larger than M, we only keep the features with the largest M absolute values of coefficients. Let denote the set of selected features. Then used in (7), where denotes the n-vector whose components are all 1’s, is the sub-matrix of corresponding to , and is the least squares estimator under the selected sub-model .
For classification problems with , we use the lasso method for the linear logistic model to screen the important features. Then used in (7), where is the maximum likelihood estimator under the selected sub-model and . A number of definitions of R-square for logistic regression, including that in (7), were compared in [21]. Here we recommend using (7), which is consistent with the regression cases, by our numerical experience.
The detailed steps of the ensemble screening procedure are described as follows. Let be a threshold value.
- Step 1:
- Conduct the linear screening method with the linear basis . Obtain the subset and the corresponding .
- Step 2:
- Conduct the linear screening method with the quadratic basis . Obtain the subset and the corresponding .
- Step 3:
- If , then conduct DC-SIS, and output ;if and , then output (if the size of , denoted by , is less than M, then add the first variables selected by DC-SIS to );if and , then output (if the size of is less than M, then add the first variables selected by DC-SIS to ).
There is no feasible method to find the optimal basis function in the linear screening methods [13]; see also Section 3.2. Here we only consider the two basic linear and quadratic basis functions. The linear basis function corresponds to the method of selecting important variables via the main linear effects. This basis is commonly used with two-level supersaturated designs [14,22] when the predictors can be designed. The linear screening method with the quadratic basis selects important variables via the main quadratic effects and is relevant to three-level supersaturated designs [23]. Unlike the two basis functions, other basis functions do not have clear interpretations. We also try other basis functions, including high-order polynomials and some random functions. Our numerical experience shows that more than two basis functions do not lead to significant improvement. In fact, the linear screening method with only the linear basis has much better performance than SIS-type methods in most cases under interpolation models [13]. From a practical point of view, for a new dataset, at first, one usually uses a linear model (with the linear basis) to fit it. The use of the linear basis in the proposed method is consistent with this manner.
Furthermore, we try a number of feasible implementations in the linear screening method. If we use different basis functions for different variables, similar to the nonparametric additive model or use parametric interaction models [24] to conduct variable screening, then there are too many basis functions (>>p) in the linear model, and this will lead to poor screening performance since p itself is large. Therefore, these more complex models are not recommended in linear screening methods.
Note that SIS-type methods are all marginal methods based on independence ranking and have similar performance in most cases. Among them, DC-SIS seems to have good performance for situations where linear screening fails, in our experience. In Step 3, we choose DC-SIS in our method.
The proposed ensemble method stems from some natural ideas. For high-dimensional settings, the data are not enough to build a complex model, and we should first try linear models. If the linear model fits the data well, we use it to screen active features. Otherwise, we consider an SIS-type method, which acts as the “last” method because of its slow convergence in high-dimensional nonparametric settings. We also consider other ensemble strategies combining the two classes of screening methods, including the method that takes a union set of the results from the two classes of methods, the method that uses other criteria such as the prediction performance instead of R-square, and others. Our numerical comparisons indicate that the proposed ensemble method outperforms these strategies.
After screening the active features, an important work is the post-selection inference, including forming valid confidence intervals for the selected coefficients and testing whether all relevant variables have been included in the model [25]. For nonparametric settings, the post-selection inference problem is quite challenging. It is a valuable topic to develop effective post-selection inference methods that can be applied to the proposed ensemble procedure in the future.
5. Numerical Examples
In this section, we apply the proposed screening method to analyze several simulated and real datasets. The real datasets are all from the UC Irvine Machine Learning Repository. More numerical examples can be found in the Supplementary Materials.
5.1. Simulations for Interpolation
This subsection considers the following test functions,
Function (I) is known as the weighted sphere model, Function (II) is Ackley’s model, Function (III) is Yang’s model, and Function (IV) is Zakharov’s model [26]. Function (V) is given in (6), which can make the linear screening methods fail. The data of predictors are generated as identically and independently distributed from . Combinations of in our simulations can be found in Table 1.
Fix suggested by [4]. Five methods are compared, including two SIS-type methods, two linear screening methods, and the proposed ensemble method. The two SIS-type methods are Li, Zhong, and Zhu [9]’s DC-SIS and Shao and Zhang [10]’s martingale difference correlation (MDC)-SIS method. The two linear screening methods, denoted by linear screening with linear basis (LSLB) and linear screening with quadratic basis (LSQB), respectively, adopt the linear and quadratic basis functions and use the lasso method, conducted with the Matlab package glmnet [27], to screen the important features. We use ten-fold cross-validation to specify the tuning parameter in lasso and only keep the variables with the largest M absolute values of coefficients if the number of selected features is larger than M. In our method, three values of the threshold , 0.6, 0.7, and 0.8, are used. The values of are selected by experience.
The coverage rates that the selected subset include for the true submodel over 1000 repetitions are given in Table 1. It can be seen from the table that MDC-SIS is slightly better than DC-SIS for Functions (I)–(IV) but performs poorly for Function (V). LSLB and LSQB have clear differences for some cases, which indicates that the selection of basis influences the performance of the linear screening methods. Although the linear screening methods have better overall performance than the SIS-type methods, they do not work for Function (V), which is pointed out in Example 4. For the proposed ensemble method, we find that the value of does not heavily influence its performance. In addition, ensemble screening overcomes the limitations of the SIS-type and linear screening methods and performs very close to the best method among DC-SIS, MDC-SIS, LSLB, and LSQB for all the cases.
As mentioned in Section 3.1, Azadkia and Chatterjee proposed a forward variable selection method for nonparametric models via a measure of conditional dependence [20]. This method usually yields very sparse selection results and has relatively good performance for problems in our numerical experience. Note that we can use it as a screening method when conducting it until M variables have been selected. However, as a screening method, this forward method performs poorly when . For example, for and , its coverage rates of correct screening over 1000 repetitions for Functions (I)–(III) are only 0.048, 0.116, and 0.019, respectively.
We also conduct simulations for regression and classification problems with the test functions and report the results in the Supplementary Materials. It can be seen from the regression and classification results that the main findings are similar to those in the interpolation cases.
The dataset in this subsection contains N = 9568 data points collected from a Combined Cycle Power Plant (CCPP) over 6 years (2006–2011) [28], when the power plant was set to work with a full load. Features consist of hourly average ambient variables Temperature, Ambient Pressure, Relative Humidity, and Exhaust Vacuum to predict the net hourly electrical energy output of the plant.
We first standardize the data of the four features into via the linear transformation for . Then, we randomly draw a subsample of 200 data points from the whole dataset, and add 296 noisy variables to construct the test dataset of n = 200 and p = 300 to evaluate the screening methods. To generate the noisy features, we draw a number J among with equal probabilities, and let , where . It can be seen that the noisy variables are correlated with the true features. We repeat the process of generating the test datasets 1000 times and report the coverage rates for which the screening methods correctly select the four true features with different M in Figure 1.
It can be seen from the results that the two SIS-type methods perform very similarly. The two linear screening methods perform poorly. However, with their help, the proposed method outperforms DC-SIS and MDC-SIS.
5.2. Computer Tomography Images
The dataset in this subsection was retrieved from a set of 583 computer tomography images from a person. Each computer tomography slice is described by two histograms in polar space. The first histogram has 240 components describing the location of bone structures in the image. The second histogram has 144 components, describing the location of air inclusions inside the body. Both histograms are concatenated to form the final feature vector. The response variable is the relative location of an image on the axis, which was constructed by manually annotating up to 10 different distinct landmarks in each computer tomography volume with a known location. A more detailed description of the dataset can be found in [29]. Among those 583 images, 350 of them are randomly selected as the training sample, and the remaining 233 are set as the test sample. Therefore, the sample size n is 350, less than the number of variables, p = 384, in the feature vector.
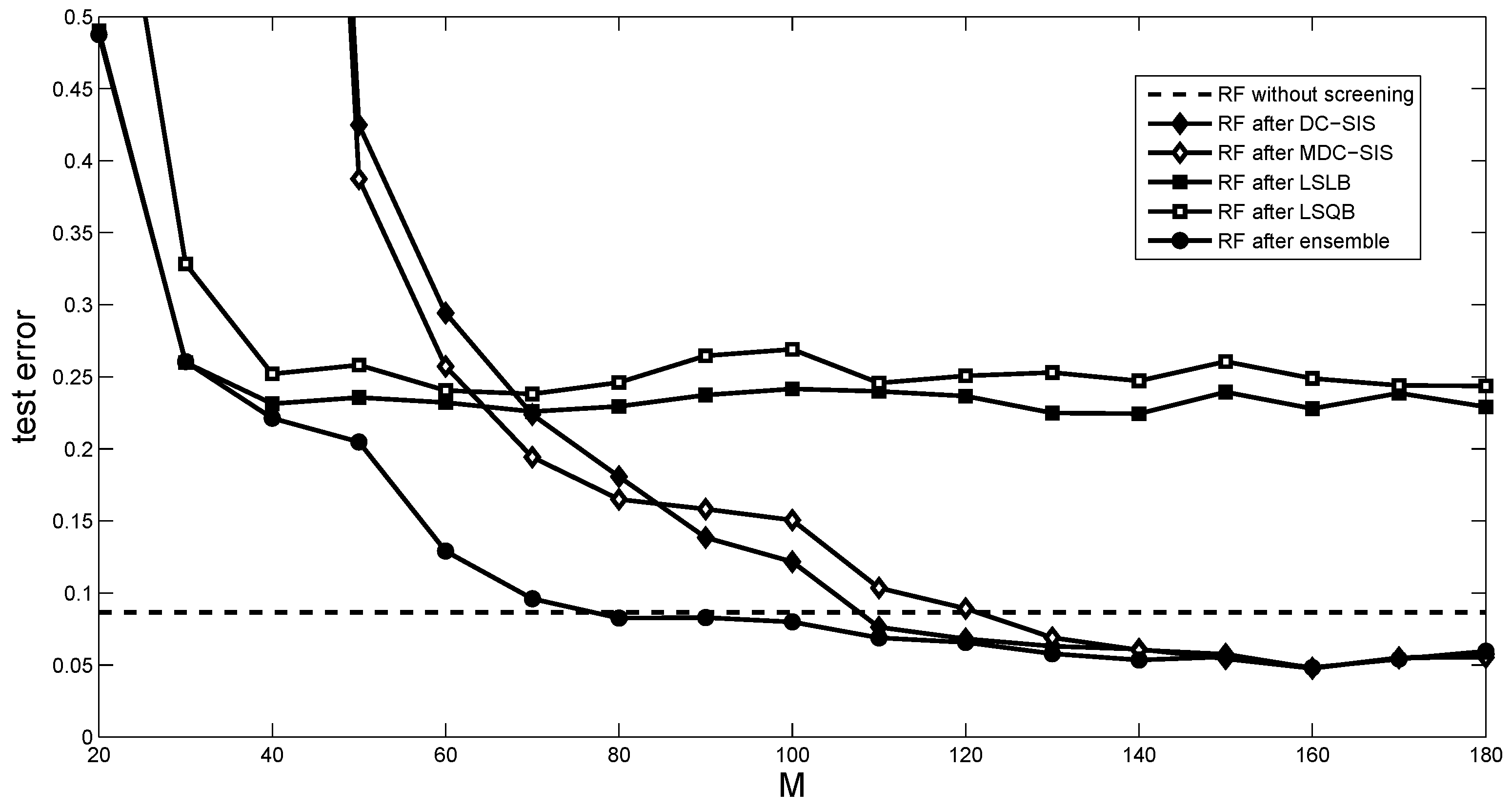
Based on the training sample, we conduct the screening methods to reduce the number of predictors from p to M. Like in [20], we then use the random forest (RF) algorithm [30], conducted by the Matlab function TreeBagger with 500 decision trees in the ensemble, to predict the response on the test sample. The mean test errors of these methods over 100 replications are presented in Figure 2. We also show the test errors of random forest without the screening step.
It can be seen from the results that, for a small M, the two SIS-type methods perform very poorly. The proposed method always yields the smallest test errors among the five methods. In particular, with about 70 variables selected by our method, the test error is very close to that with all 384 variables, while DC-SIS and MDC-SIS need about 110 variables to achieve a similar result.
5.3. Voice Rehabilitation
The dataset from a study on objective automatic assessment of rehabilitative speech treatment in Parkinson’s disease contains 126 data points with 310 predictors. The predictors are all continuous values, and the response is binary. Detailed information on the predictors and response can be found in [31]. Among those 126 data, we randomly selected 100 of them as the training sample, and the remaining 26 were set as the test sample.
In addition to the methods compared in the previous subsections, we add Cui, Li, and Zhong [32]’s MV-SIS method, which is a model-free feature screening approach for high-dimensional classification problems. Similarly, we conducted the six screening methods to reduce the number of predictors from 310 to 15. Then the random forest algorithm was used to predict the response on the test sample. The mean test errors of these methods over 100 replications are presented in Table 2. We also show the test errors of random forest without the screening step. From Table 2, we find that the two linear screening methods and the ensemble method effectively reduce the dimensionality: their test errors are less than that from random forest without the screening step. In addition, the performance of the ensemble screening method is very close to the best method, LSQB, among these screening methods. This point is consistent with our findings in simulations with test functions in the Supplementary Materials.
6. Concluding Remarks
For the screening problem in nonparametric settings, SIS-type methods have some limitations. The linear screening methods, from the perspective of applied statistics or data analytics, are alternatives. A natural idea is to combine the two classes of methods to overcome their shortcomings. The ensemble method proposed in this paper follows this line. Numerical investigations indicate that it performs stably even when existing methods fail. For highly correlated predictors, the threshold in ensemble screening can be set as 0.8 or larger, while for other cases, seems to be a good choice. This paper focuses on continuous and binary responses. The method proposed here can be applied to other types of responses, such as counting or multivariate responses, without any extra difficulties.
Supplementary Materials
The following supporting information can be downloaded at: https://0-www-mdpi-com.brum.beds.ac.uk/article/10.3390/math11020362/s1, Table S1: Coverage rates in regression; Table S2: Coverage rates in classification, and the reference in Supplementary Materials was cited in Ref. [32].
Author Contributions
Methodology, X.W. and S.X.; Validation, S.X.; Formal analysis, X.W.; Investigation, W.M.; Data curation, X.W.; Writing—original draft, X.W.; Writing—review & editing, W.M.; Supervision, W.M.; Project administration, W.M.; Funding acquisition, S.X. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Key R&D Program of China (Grant nos. 2021YFA1000300, 2021YFA1000301, and 2021YFA1000303) and the National Natural Science Foundation of China (Grant no. 12171462).
Data Availability Statement
Not applicable.
Acknowledgments
We thank the editors and referees for constructive comments which lead to a significant improvement of this article. This work is supported by the National Key R&D Program of China (Grant nos. 2021YFA1000300, 2021YFA1000301, and 2021YFA1000303) and the National Natural Science Foundation of China (Grant no. 12171462).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Santner, T.J.; Williams, B.J.; Notz, W.I. The Design and Analysis of Computer Experiments, 2nd ed.; Springer: New York, NY, USA, 2018. [Google Scholar]
- Cressie, N.A.C. Statistics for Spatial Data, Revised ed.; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning: Data Mining, Inference and Prediction, 2nd ed.; Springer: New York, NY, USA, 2008. [Google Scholar]
- Fan, J.; Lv, J. Sure independence screening for ultrahigh dimensional feature space. J. R. Stat. Soc. Ser. B 2008, 70, 849–911. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Song, R. Sure independence screening in generalized linear models with NP-dimensionality. Ann. Stat. 2010, 38, 3567–3604. [Google Scholar] [CrossRef]
- Fan, J.; Feng, Y.; Song, R. Nonparametric independence screening in sparse ultra-high dimensional additive models. J. Am. Stat. Assoc. 2011, 106, 544–557. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Ma, Y.; Dai, W. Nonparametric independence screening in sparse ultra-high dimensional varying cofficient models. J. Am. Stat. Assoc. 2014, 109, 1270–1284. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.P.; Li, L.X.; Li, R.Z.; Zhu, L.X. Model-free feature screening for ultrahigh dimensional data. J. Am. Stat. Assoc. 2011, 106, 1464–1475. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Zhong, W.; Zhu, L. Feature screening via distance correlation learning. J. Am. Stat. Assoc. 2012, 107, 1129–1139. [Google Scholar] [CrossRef] [Green Version]
- Shao, X.; Zhang, J. Martingale difference correlation and its use in high-dimensional variable screening. J. Am. Stat. Assoc. 2014, 109, 1302–1318. [Google Scholar] [CrossRef]
- Mai, Q.; Zou, H. The fused Kolmogorov filter: A nonparametric model-free screening method. Ann. Stat. 2015, 43, 1471–1497. [Google Scholar] [CrossRef] [Green Version]
- Yu, Z.; Dong, X.; Shao, J. On marginal sliced inverse regression for ultrahigh dimensional model-free feature selection. Ann. Stat. 2016, 44, 2594–2623. [Google Scholar] [CrossRef]
- Li, C.; Chen, D.; Xiong, S. Linear screening for high-dimensional computer experiments. STAT 2021, 10, e320. [Google Scholar] [CrossRef]
- Lin, D.K.J. A new class of supersaturated designs. Technometrics 1993, 35, 28–31. [Google Scholar] [CrossRef]
- Xiong, S. Better subset regression. Biometrika 2014, 101, 71–84. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Chen, J. The sparse MLE for ultra-high-dimensional feature screening. J. Am. Stat. Assoc. 2014, 109, 1257–1269. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Conway, J.B. A Course in Functional Analysis; Springer: New York, NY, USA, 1985. [Google Scholar]
- Székely, G.J.; Rizzo, M.L.; Bakirov, N.K. Measuring and testing dependence by correlation of distances. Ann. Stat. 2007, 35, 2769–2794. [Google Scholar] [CrossRef]
- Azadkia, M.; Chatterjee, S. A simple measure of conditional dependence. Ann. Stat. 2021, 49, 3070–3102. [Google Scholar] [CrossRef]
- Tjur, T. Coefficients of determination in logistic regression models—A new proposal: The coefficient of discrimination. Am. Stat. 2009, 63, 366–372. [Google Scholar] [CrossRef]
- Wu, C.F.J. Construction of supersaturated designs through partially aliased interactions. Biometrika 1993, 80, 661–669. [Google Scholar] [CrossRef]
- Yamada, S.; Lin, D.K.J. Three-level supersaturated designs. Stat. Probab. Lett. 1999, 45, 31–39. [Google Scholar] [CrossRef]
- Radchenko, P.; James, G.M. Variable selection using adaptive nonlinear interaction structures in high dimensions. J. Am. Stat. Assoc. 2010, 105, 1541–1553. [Google Scholar] [CrossRef]
- Lee, J.D.; Sun, D.L.; Sun, Y.; Taylor, J.E. Exact post-selection inference, with application to the lasso. Ann. Stat. 2016, 44, 907–927. [Google Scholar] [CrossRef]
- Ang, X.-S. Test Problems in Optimization. In Engineering Optimization; Yang, X.-S., Ed.; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularized paths for generalized linear models via coordinate descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Tüfekci, P. Prediction of full load electrical power output of a base load operated combined cycle power plant using machine learning methods. Int. J. Electr. Power Energy Syst. 2014, 60, 126–140. [Google Scholar] [CrossRef]
- Graf, F.; Kriegel, H.-P.; Schubert, M.; Pöelsterl, S.; Cavallaro, A. 2D image registration in CT images using radial image descriptors. In Medical Image Computing and Computer-Assisted Intervention; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6892, pp. 607–614. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Tsanas, A.; Little, M.A.; Fox, C.; Ramig, L.O. Objective automatic assessment of rehabilitative speech treatment in Parkinson’s disease. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 181–190. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cui, H.; Li, R.; Zhong, W. Model-free feature screening for ultrahigh dimensional discriminant analysis. J. Am. Stat. Assoc. 2015, 110, 630–641. [Google Scholar] [CrossRef]
Figure 1.
Coverage rates in Section 5.2.
Figure 1.
Coverage rates in Section 5.2.

Figure 2.
Test errors in Section 5.2.
Figure 2.
Test errors in Section 5.2.


{kind=link}
{kind=link}
Table 1.
Coverage rates in interpolation.
| Function (I) | ||||||
|---|---|---|---|---|---|---|
| n = 100, | p = 150 | n = 200, | p = 500 | n = 400, | p = 2000 | |
| DC-SIS | 0.298 | 0.004 | 0.423 | 0.012 | 0.596 | 0.034 |
| MDC-SIS | 0.328 | 0.003 | 0.461 | 0.018 | 0.669 | 0.039 |
| LSLB | 0.998 | 0.401 | 1.000 | 0.656 | 1.000 | 0.930 |
| LSQB | 1.000 | 0.984 | 1.000 | 1.000 | 1.000 | 1.000 |
| ensemble () | 1.000 | 0.984 | 1.000 | 1.000 | 1.000 | 1.000 |
| ensemble () | 1.000 | 0.984 | 1.000 | 1.000 | 1.000 | 1.000 |
| ensemble () | 1.000 | 0.984 | 1.000 | 1.000 | 1.000 | 1.000 |
| Function (II) | ||||||
| n = 100, | p = 150 | n = 200, | p = 500 | n = 400, | p = 2000 | |
| DC-SIS | 0.979 | 0.175 | 0.999 | 0.892 | 1.000 | 1.000 |
| MDC-SIS | 0.981 | 0.231 | 1.000 | 0.951 | 1.000 | 1.000 |
| LSLB | 1.000 | 0.871 | 1.000 | 1.000 | 1.000 | 1.000 |
| LSQB | 0.897 | 0.161 | 0.986 | 0.817 | 1.000 | 1.000 |
| ensemble () | 1.000 | 0.872 | 1.000 | 1.000 | 1.000 | 1.000 |
| ensemble () | 0.999 | 0.872 | 1.000 | 1.000 | 1.000 | 1.000 |
| ensemble () | 0.997 | 0.855 | 1.000 | 1.000 | 1.000 | 1.000 |
| Function (III) | ||||||
| n = 100, | p = 150 | n = 200, | p = 500 | n = 400, | p = 2000 | |
| DC-SIS | 0.981 | 0.296 | 1.000 | 0.933 | 1.000 | 1.000 |
| MDC-SIS | 0.988 | 0.372 | 1.000 | 0.962 | 1.000 | 1.000 |
| LSLB | 1.000 | 0.999 | 1.000 | 1.000 | 1.000 | 1.000 |
| LSQB | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| ensemble () | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| ensemble () | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| ensemble () | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Function (IV) | ||||||
| n = 100, | p = 150 | n = 200, | p = 500 | n = 400, | p = 2000 | |
| DC-SIS | 0.277 | 0.003 | 0.420 | 0.026 | 0.537 | 0.042 |
| MDC-SIS | 0.286 | 0.004 | 0.411 | 0.013 | 0.621 | 0.055 |
| LSLB | 0.829 | 0.158 | 0.976 | 0.354 | 1.000 | 0.541 |
| LSQB | 0.860 | 0.134 | 0.981 | 0.320 | 1.000 | 0.470 |
| ensemble () | 0.841 | 0.158 | 0.974 | 0.354 | 1.000 | 0.541 |
| ensemble () | 0.841 | 0.158 | 0.974 | 0.354 | 1.000 | 0.541 |
| ensemble () | 0.841 | 0.158 | 0.972 | 0.351 | 1.000 | 0.540 |
| Function (V) | ||||||
| n = 100, | p = 100 | n = 200, | p = 300 | n = 400, | p = 800 | |
| DC-SIS | 0.775 | 0.155 | 0.978 | 0.573 | 1.000 | 0.998 |
| MDC-SIS | 0.045 | 0.003 | 0.016 | 0.002 | 0.005 | 0.000 |
| LSLB | 0.009 | 0.000 | 0.009 | 0.001 | 0.002 | 0.000 |
| LSQB | 0.012 | 0.002 | 0.014 | 0.001 | 0.001 | 0.000 |
| ensemble () | 0.747 | 0.151 | 0.980 | 0.567 | 1.000 | 0.996 |
| ensemble () | 0.772 | 0.155 | 0.982 | 0.573 | 1.000 | 0.998 |
| ensemble () | 0.775 | 0.155 | 0.982 | 0.573 | 1.000 | 0.998 |
Table 2.
Test errors of RF in the real data example.
| Full Model | DC-SIS | MDC-SIS | MV-SIS | LSLB | LSQB | Ensemble | |
|---|---|---|---|---|---|---|---|
| Mean | 0.163 | 0.232 | 0.231 | 0.361 | 0.142 | 0.136 | 0.138 |
| Standard deviation | 0.069 | 0.083 | 0.086 | 0.109 | 0.058 | 0.057 | 0.053 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wu, X.; Xiong, S.; Mu, W. An Ensemble Method for Feature Screening. Mathematics 2023, 11, 362. https://0-doi-org.brum.beds.ac.uk/10.3390/math11020362
AMA Style
Wu X, Xiong S, Mu W. An Ensemble Method for Feature Screening. Mathematics. 2023; 11(2):362. https://0-doi-org.brum.beds.ac.uk/10.3390/math11020362
Chicago/Turabian StyleWu, Xi, Shifeng Xiong, and Weiyan Mu. 2023. "An Ensemble Method for Feature Screening" Mathematics 11, no. 2: 362. https://0-doi-org.brum.beds.ac.uk/10.3390/math11020362
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.