This section offers a thorough discussion of the many methods for classifying fine art styles, including both conventional and deep learning techniques. We will group this study by approach and add critical analysis and method comparisons to make it easier to read and understand. The problem of categorizing fine art has been approached through various methods, broadly categorized into traditional and deep learning (DL) strategies. Details of these two groups are discussed below:
2.2. Deep Learning Strategies
Deep learning has significantly improved art classification, thanks to the strength of neural networks and massive data. In preceding years, deep learning strategies, particularly convolutional neural networks (CNNs) [
17], have gained popularity in fine art style classification. With deep neural networks, these DL techniques can automatically learn hierarchical representations from unprocessed image data. In DL-based approaches, the CNN models are typically trained on significant datasets, such as ImageNet, using millions of natural images. The pre-trained models [
18] capture general visual features and can be fine-tuned or adapted for fine art style classification using transfer learning techniques. The pre-trained CNN models learn to recognize abstract visual patterns and textures, enabling them to capture complex style characteristics. By utilizing deep learning techniques, these models can automatically learn relevant features directly from the artwork images, eliminating the need for handcrafted descriptors. This allows for more effective and data-driven representation learning, potentially improving the accuracy of style classification. Accuracy, scalability, interoperability, and data requirements are all evaluated, and it becomes obvious that while deep learning approaches have revolutionized the classification of art styles due to their higher accuracy and scalability, they also pose problems for interpretability and data requirements. Even though they have limitations, traditional approaches provide insightful interpretations and can be helpful when there is a dearth of labeled data. The future of art classification may lie in combining the two methods, successfully utilizing their individual strengths to close the semantic gap.
Previous research tried the plausibility of painting genre classification on tiny datasets of images and utilizing a couple of style classifications. A dataset of 513 images was used to classify three styles, as shown in [
19]. A method known as “weighted nearest neighbor (WNN)” was used as a classifier, and several transforms, including Fourier, Chebyshev, and wavelet, were used to extract the features. Different instances of significant works in light of the extraction of low-level features incorporate techniques proposed in [
20,
21]. In the previous study, a training dataset comprising 490 paintings was utilized to draw out features and classify seven distinct art genres. The classification process employed methods such as the opponent scale-invariant feature transform (O-SIFT) and the color scale-invariant feature transform (CSIFT) algorithms. Similarly, the latter study employed a dataset called Painting-91, consisting of 4266 images across 13 styles. Various feature-extraction techniques were implemented, including color local binary patterns, local binary patterns (LBPs), generalized image search tree (GIST), histogram of oriented gradient (HOG) parameters, pyramid of histograms of orientation gradients (PHOGs), and scale-invariant feature transform (SIFT). To classify the extracted features in both studies, the SVM algorithm was employed. Multi-class classification results with low-level features were lacking [
20,
21]. In [
22], various combinations of features and classifiers were investigated. In [
23], the focus was on investigating the order of three art styles based on subjective variety descriptors and similarity.
This investigation utilized classifiers such as support vector machines (SVMs) and k-nearest neighbors (k-NNs). However, no significant advancements were achieved in any of these instances. Furthermore, in another study [
24], the classification of 6777 paintings into eight style groups was explored by investigating unsupervised feature extraction techniques. Unfortunately, no noteworthy progress was made in this endeavor. However, the field experienced a breakthrough when researchers started incorporating deep learning (DL) methods. By leveraging convolutional neural networks (CNNs) pre-trained on vast image datasets, significant advancements were finally achieved in image classification tasks. Recent research in the field of style classification has been dominated by pre-trained and fine-tuned CNN models, which possess the capability to learn features and infer style labels effectively. Transfer learning, which involves fine-tuning a pre-trained network using a small dataset, has played a crucial role in achieving these advancements. In this process, a pre-trained CNN is adapted to serve as a feature extractor within various deep-learning methods [
25,
26,
27,
28,
29,
30,
31]. Notably, introducing pre-trained CNN models brought about a shift in determining knowledge-based features. Instead, the features were represented by the parameters of the network itself.
To classify these network parameters, linear classifiers like support vector machines (SVMs) were commonly utilized. A significant and comprehensive investigation of artistic work grouping was reported in [
25]. This study covered an extensive range of artistic works, demonstrating the substantial scope of the research conducted. Studies in this subject have consistently yielded accurate classification results utilizing features generated by a pre-trained CNN model on a sizable dataset of paintings representing 25 styles. The SVM was employed as the classifier of choice. Remarkably, these studies demonstrated that DL-based style classification models surpassed classical models based on knowledge-based features. For instance, in [
31], the efficiency of feature extraction using pre-trained CNN models was compared to the efficiency achieved using a comprehensive collection of hand-designed visual descriptors. The results revealed that the CNN-based feature extraction method outperformed other approaches significantly. Furthermore, transfer learning was applied to enhance style classification by leveraging the same CNN model for feature learning and label inference. This technique improved the accuracy and performance of the style classification models. The work by [
32] stands as one of the pioneering systematic studies employing the method of utilizing pre-trained CNN models for style classification. Their study involved many paintings, encompassing more than 27 stylistic categories.
The AlexNet, a pre-trained CNN originally designed for object classification, was used in this research. Notably, it was demonstrated that training the CNN model “from scratch” yielded superior results compared to typical non-network classifiers trained using CNN-derived features. Subsequent studies [
33,
34] conducted similarly have consistently confirmed these findings. The use of pre-trained CNN models for style classification has proven highly effective, surpassing the performance of traditional classifiers trained on CNN-derived features. In [
35], the suggestion was made that object classification data could potentially lead to better results compared to using transfer learning with an initial image recognition or sentiment analysis training for the CNN model. The authors proposed that using specific data related to object classification tasks could improve the performance of the CNN model. On the other hand, ref. [
36] focused on studying style order results from calibrating three separate CNN models. Principal component analysis (PCA) is used by researchers to learn and analyze CNN representations of artistic styles. The findings of this study indicated a strong correlation between the chronological order of paintings and the features extracted by the CNN models.
In [
37], the study focused on painting recognition using image patches. Specifically, binary identification of Van Goh’s painting was performed. The approach involved utilizing an SVM model trained with features extracted from a CNN model. A smaller dataset consisting of 332 paintings was used to train the CNN. Each analyzed image was divided into patches, and each patch was assigned a unique classification. The highest-scoring categorization patch was used to make the final decision about the painting. Moving on to [
38], this study investigated image analysis using datasets containing images of varying sizes. The researchers employed autonomous CNNs trained on various image scales and calculated the average score across these models to create images of artworks based on artist recognition. This approach aimed to handle images of different sizes effectively. In a similar study, [
39] proposed a three-layer multi-scale pyramid framework for artist recognition. The first layer of the CNN examined fixed-sized input images from input photos expanded by two and four times. The second layer read four patches, while the third layer considered sixteen patches. The category with the highest average class entropy was the basis for the choice.
In [
40], an intriguing patch-based approach was proposed for classifying paintings based on their style. The study utilized a dataset of 2337 images with 13 different style groups to train a complex three-branch CNN architecture. The CNN received three random patches as inputs. Three patches were created: two from the original image and one from a scaled-down version of the same image. This approach aimed to capture style-related information from different parts of the artwork. In [
41], a different approach was suggested for classifying artistic styles across a large image dataset. The study employed a boosted ensemble of SVMs and utilized color histograms and image topographic descriptors as features. The classification results from analyzing the entire painting, and a few random sub-regions were combined using majority voting to decide on the painting’s style. In [
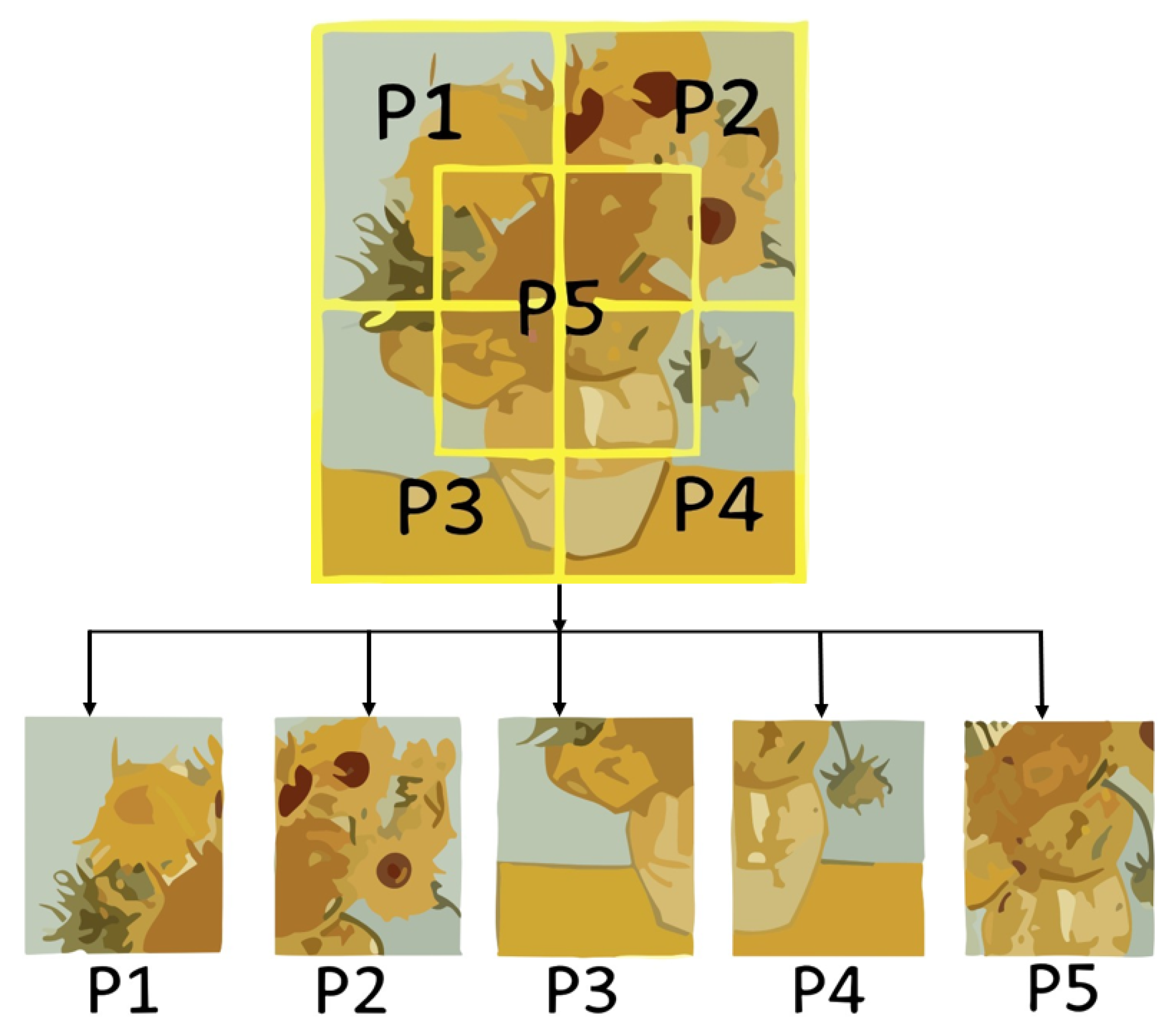
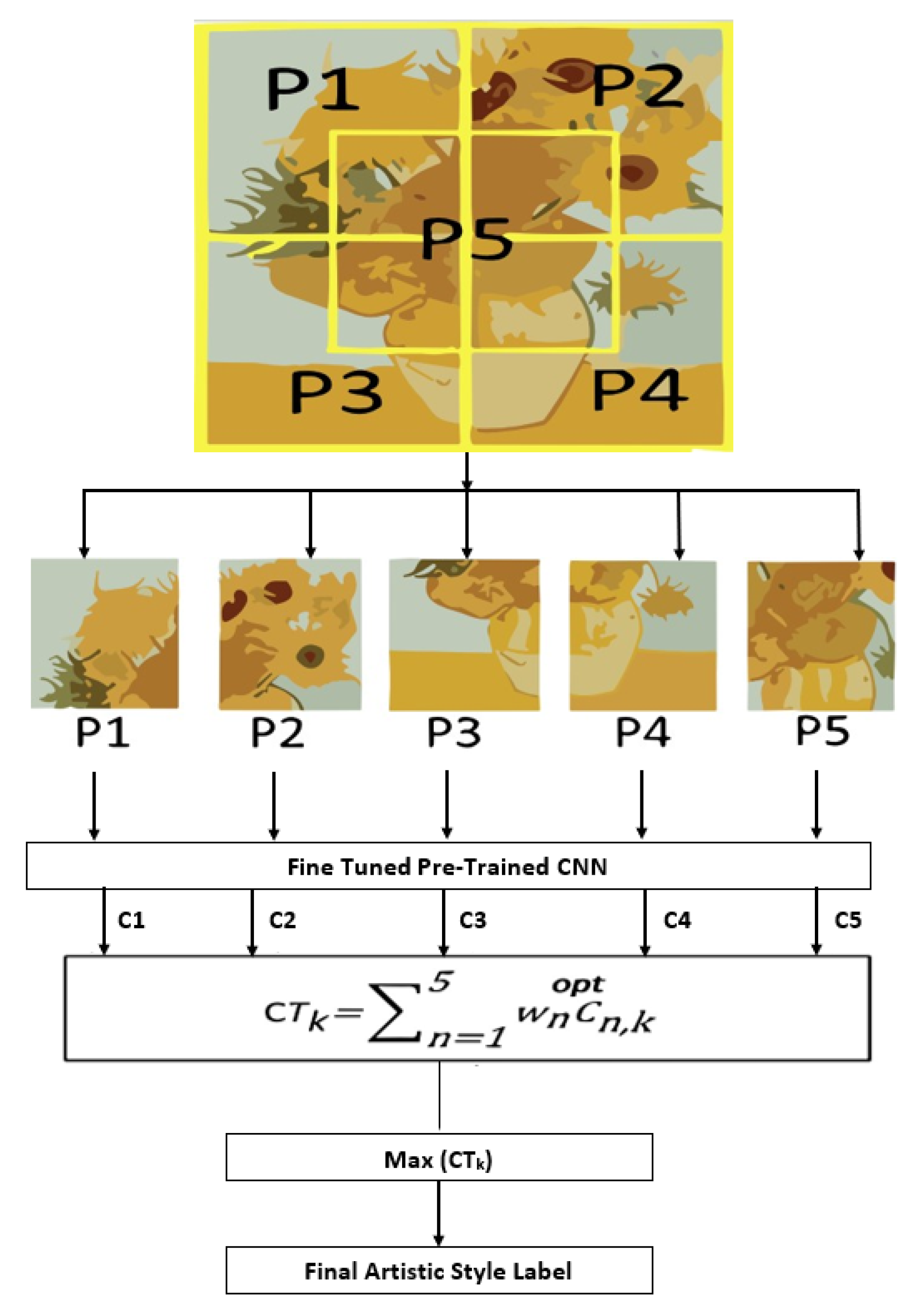
42], it was demonstrated that incorporating a sum of outcomes for individual patches can greatly enhance classification results. The study utilized a CNN to classify each patch independently, and then an average of the classification results was calculated to choose the ultimate style label. The values were determined using mathematical optimizations to enhance the overall accuracy of style ordering. This optimized approach significantly improved the accuracy of style classification. Building on this, in our proposed method, we introduce a two-phase characterization calculation that further enhances the results of patch-based style characterization. This two-phase process aims to provide additional improvements in accurately classifying artistic styles based on fixed image regions.

 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}