
Identification and Correction of Grammatical Errors in Ukrainian Texts Based on Machine Learning Technology

 , , and
, , and
Abstract
:1. Introduction
- -
- Research of the Ukrainian text corpora;
- -
- Comparison of state-of-the-art methods for GEC;
- -
- Research of using neural networks with different architectures;
- -
- Choice of the most optimum model of a GEC system for texts written in Ukrainian.
2. Related Works
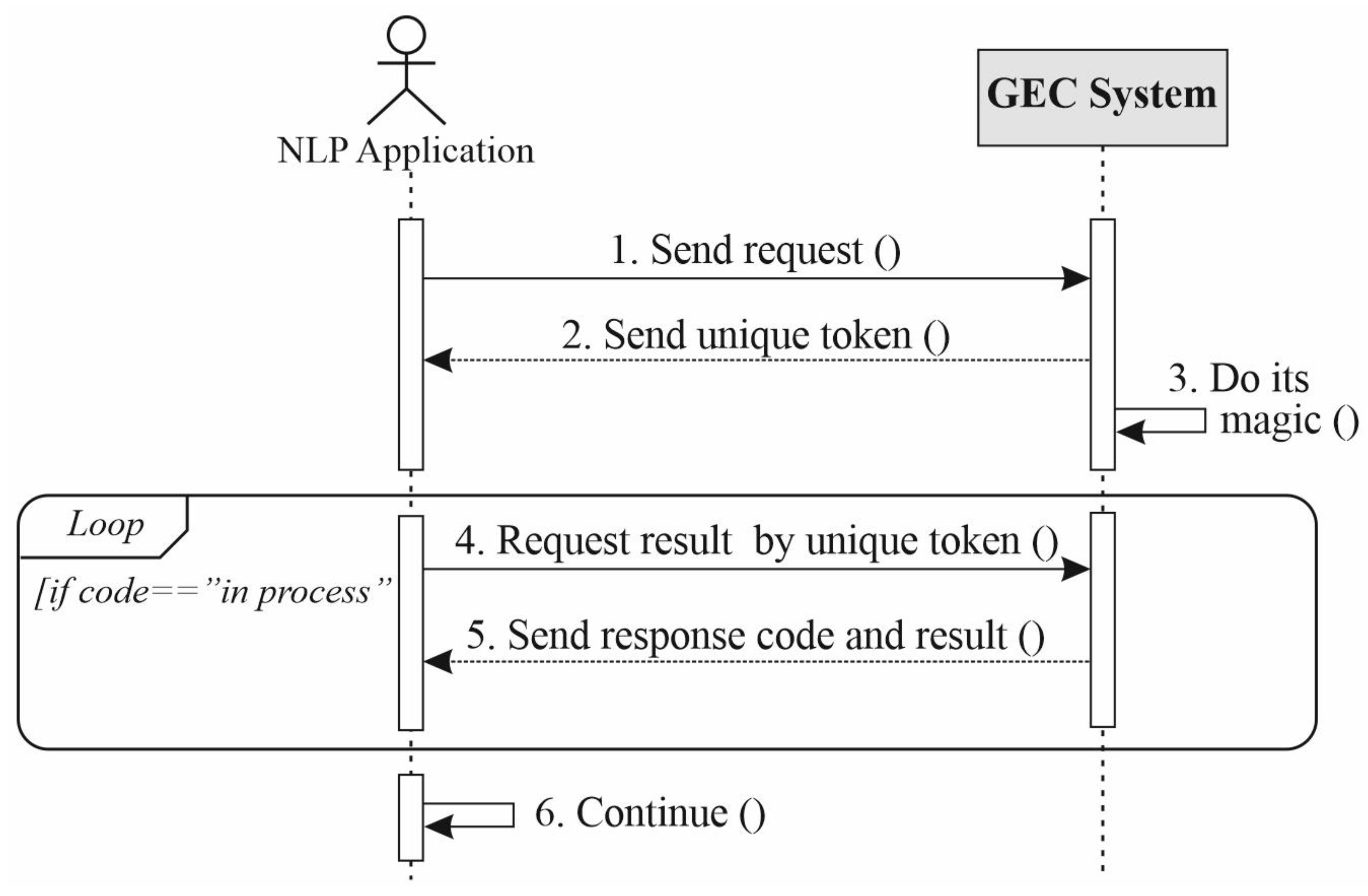
3. Materials and Methods
- Absence of sufficiently large annotated /parallel Ukrainian language corpora to study entirely automatic models based on deeper study algorithms;
- The insufficient capability of the language models of artificial intelligence to generalize rules.
4. Results
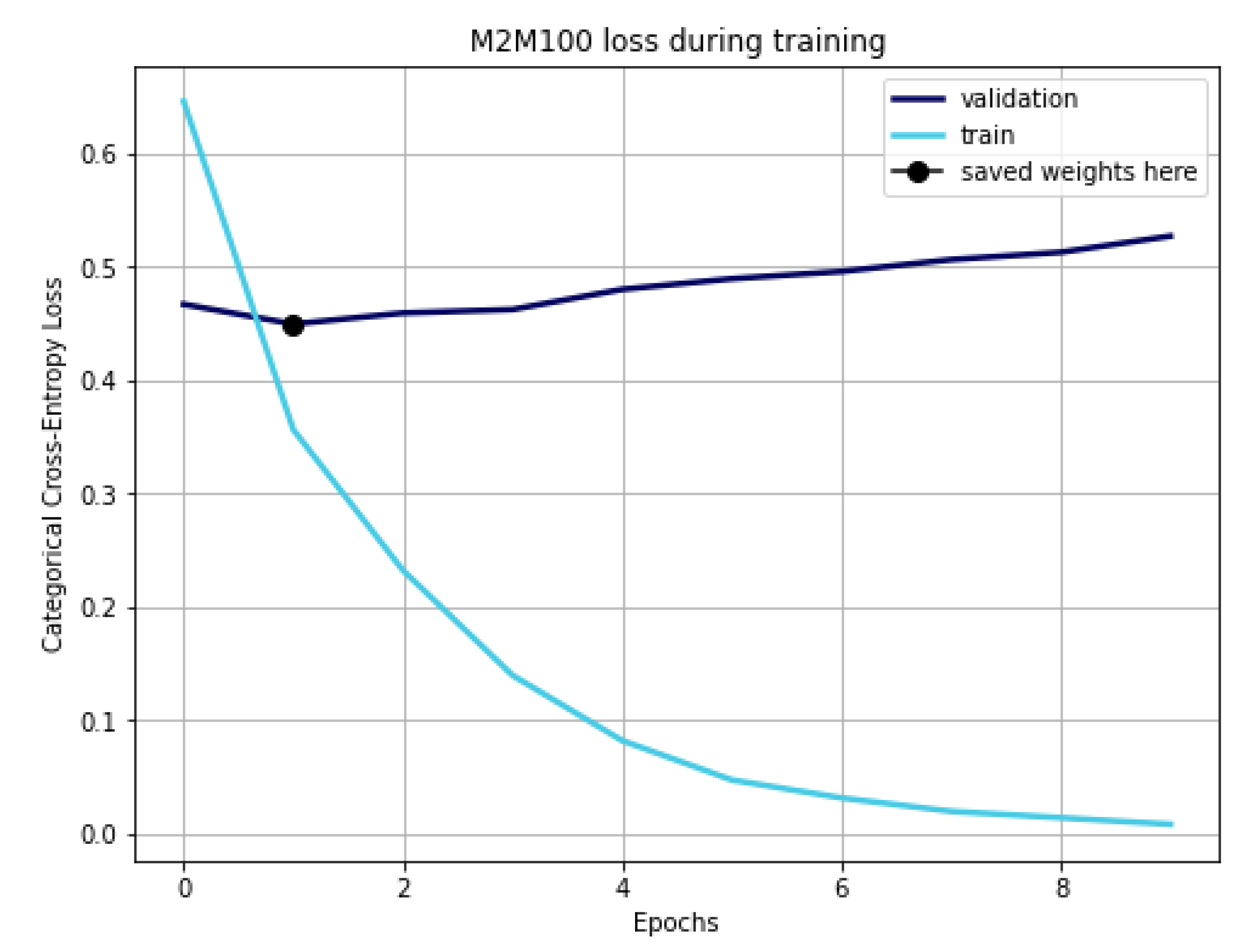
4.1. Setting the RoBERTa Pre-Trained MT Model
- n_epochs = 15;
- batch_size = 8;
- lr = 0.00001.
4.2. Setting the Pre-Trained mT5 MT Model
- Hyper-parameters values;
- Amount of studied sampling;
- The number of training epochs;
- Architecture and parameters number of neural network;
- Token number of input text;
- Studied sampling (validation data were used or was used all corpora).
5. Discussion
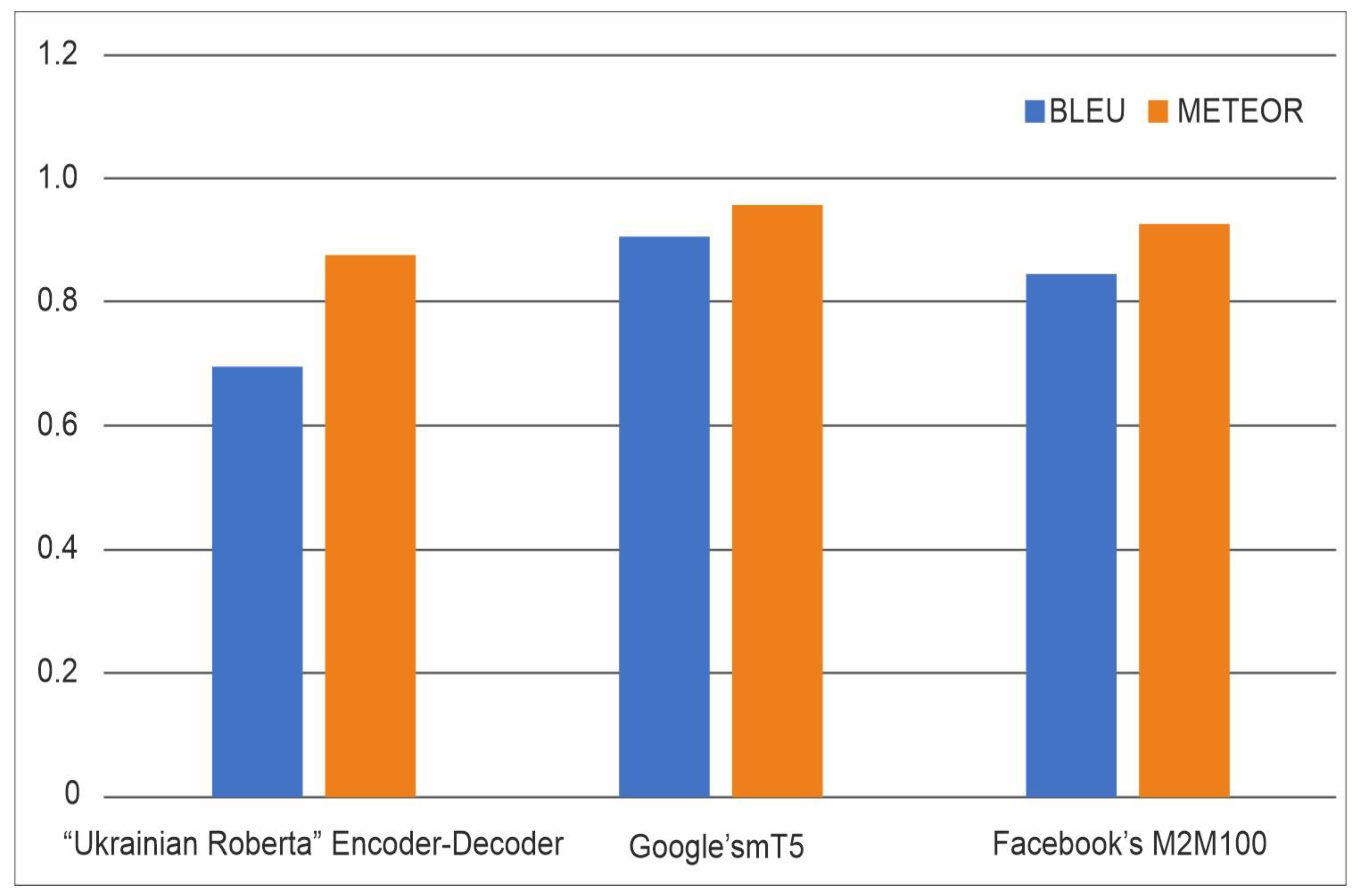
- ‘Ukrainian Roberta’ Encoder-Decoder—0.697;
- Google’s mT5—0.908;
- Facebook’s M2M100—0.847.
- The exact establishment of correspondence means to determine strings that are identical in standard and machine translation;
- The establishment of stem correspondence is called ‘steaming’, which is determined by words with the same stem in standard and machine translation;
- The establishment of synonyms correspondence means determining words being synonyms corresponding to WordNet.
- ‘Ukrainian Roberta’ Encoder-Decoder—0.876;
- Google’s mT5—0.956;
- Facebook’s M2M100—0.925.
6. Conclusions
- -
- Building a good machine learning model for GEC in morphologically complex texts requires a large amount of parallel or manually labeled data. Manual data annotation requires much effort by professional linguists, which makes the creation of text corpora a time- and resource-consuming process.
- -
- Solving the task of automatic detection and correction of errors in Ukrainian texts requires further research due to the small number of works focusing on the study of the Ukrainian language. In addition, according to the results of the study of S.D. Pohorily and Kramova A.A. [27], the methods used to study the English language cannot be used for Ukrainian since the latter is a much more complex and morphologically richer language.
- -
- The appearance of the new transformer deep learning architecture in 2017 [3], which includes an attention mechanism, allowed for significant simplification of the development of language models. A disadvantage of this approach for developing models for different languages is the need for large corpora of annotated or parallel data. The only (at the time of writing) Ukrainian-language data set [15] contains only tens of thousands of sentences, and such a number of training samples is not enough to create an automatic intelligent system for identifying and correcting grammatical errors for Ukrainian texts.
- -
- The development of a quality system for checking the grammatical correctness of sentences in Ukrainian texts requires a combination of machine learning algorithms with several different types of methods, in particular, the application of expert knowledge in computer linguistics.
- -
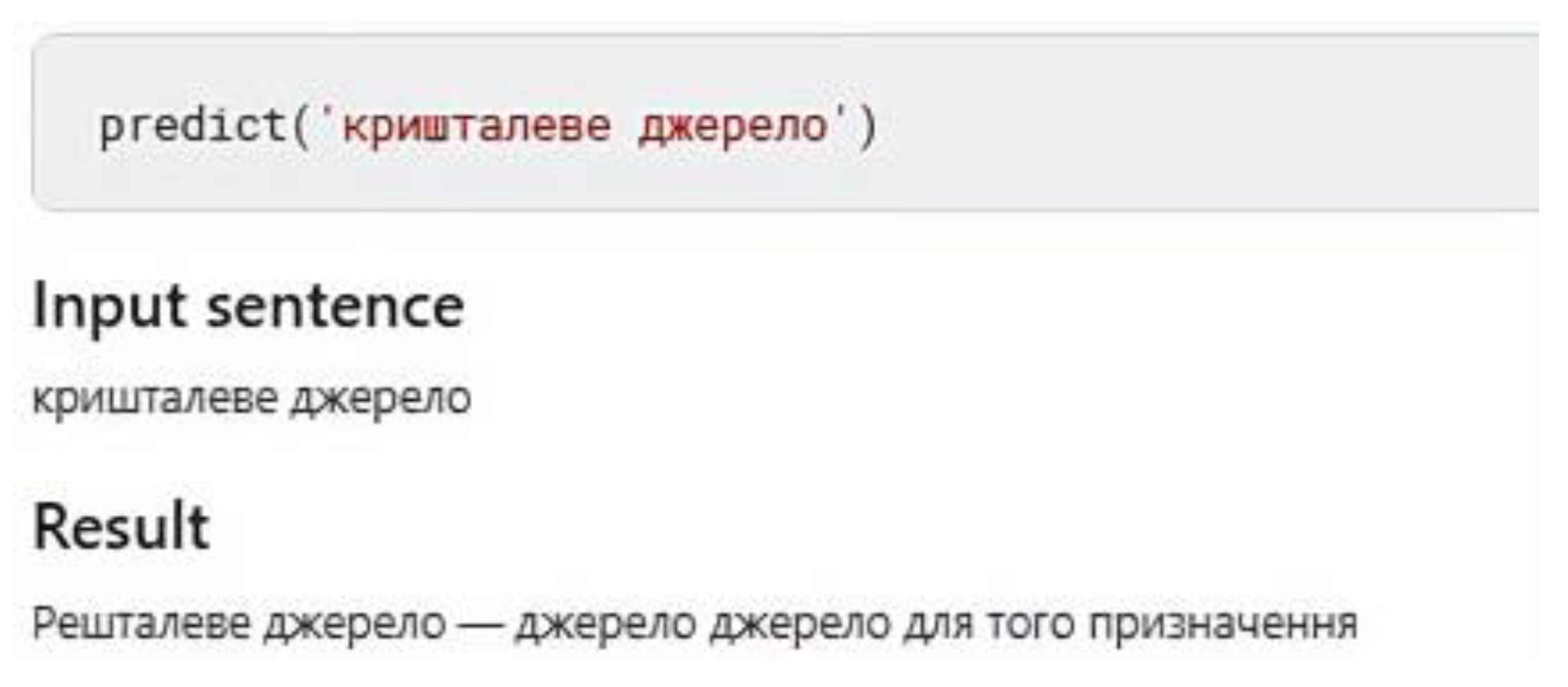
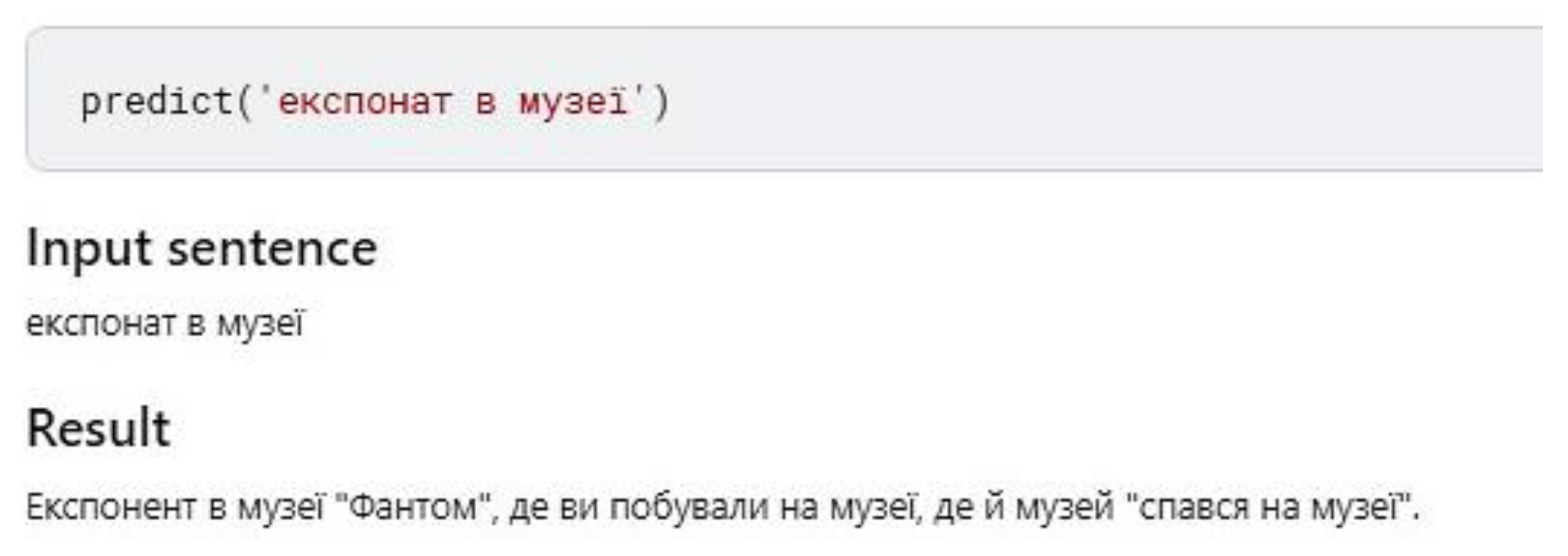
- The best value for both BLEU and METEOR is obtained for the mT5 model. The results are consistent with the analysis of our own examples, in which the most accurate error corrections without changing the initial sentence were obtained for this neural network. The results of applying the neural network at the phrase level are the following: the correlation with the human decision was 0.964, while the correlation with BLUE was 0.817 on the same set of input data. At the sentence level, the maximum correlation with the experts’ assessment was 0.403. Calculated metrics allow only partial comparison of the models since most of the words and phrases in the original and corrected sentences match. The best value of both BLEU (0.908) and METEOR (0.956) was obtained for mT5. Mt5 has a higher BLEU score than the ‘Ukrainian Roberta’ encoder–decoder (0.697); however, subjectively evaluating the results of correcting examples, Mt5 performs much worse. Mt5 also has a higher METEOR score than the ‘Ukrainian Roberta’ encoder–decoder (0.876). A cross-validation procedure can be the forthcoming step of our research.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Naghshnejad, M.; Joshi, T.; Nair, V.N. Recent Trends in the Use of Deep Learning Models for Grammar Error Handling. arXiv 2020, arXiv:2009.02358. [Google Scholar]
- Leacock, C.; Chodorow, M.; Gamon, M.; Tetreault, J. Automated Grammatical Error Detection for Language Learners. Synthesis Lectures on Human Language Technologies, 2nd ed.; Springer: Berlin, Germany, 2014. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations, ACL Anthology, Online, 16–20 November 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Bick, E. DanProof: Pedagogical Spell and Grammar Checking for Danish. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Hissar, Bulgaria, 7–9 September 2015; pp. 55–62. [Google Scholar]
- Gakis, P.; Panagiotakopoulos, C.T.; Sgarbas, K.N.; Tsalidis, C.; Verykios, V.S. Design and construction of the Greek grammar checker. Digit. Scholarsh. Humanit. 2017, 32, 554–576. [Google Scholar] [CrossRef]
- Deksne, D. A New Phase in the Development of a Grammar Checker for Latvian. Frontiers in Artificial Intelligence and Applications 2016, 289, 147–152. [Google Scholar] [CrossRef]
- Sorokin, A. Spelling Correction for Morphologically Rich Language: A Case Study of Russian. In Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing, Valencia, Spain, 3–4 April 2017; pp. 45–53. [Google Scholar] [CrossRef]
- Rozovskaya, A.; Roth, D. Grammar Error Correction in Morphologically Rich Languages. Trans. Assoc. Comput. Linguist. 2019, 7, 1–17. [Google Scholar] [CrossRef]
- Gill, M.S.; Lehal, G.S. A Grammar Checking System for Punjabi. In Proceedings of the Companion volume: Demonstrations, Manchester, UK, 18–22 August 2008; pp. 149–152. [Google Scholar]
- Go, M.P.; Borra, A. Developing an Unsupervised Grammar Checker for Filipino Using Hybrid N-grams as Grammar Rules. In Proceedings of the 30th Pacific Asia Conference on Language, Information and Computation: Oral Papers, Seoul, Republic of Korea, 28–30 October 2016; pp. 105–113. [Google Scholar]
- Shaalan, K.F. Arabic GramCheck: A grammar checker for Arabic. Softw. Pract. Exp. 2005, 35, 643–665. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Liu, J.; Liu, Z. A Comprehensive Survey of Grammar Error Correction. arXiv 2020, arXiv:2005.06600. [Google Scholar]
- Syvokon, O.; Nahorna, O. UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language. arXiv 2021, arXiv:2103.16997. [Google Scholar]
- Lardinois, F. Grammarly Goes Beyond Grammar. TechCrunch 2019. Available online: https://techcrunch.com/2019/07/16/grammarly-goes-beyond-grammar/ (accessed on 1 December 2022).
- Lardinois, F. Grammarly Gets a Tone Detector to Keep You Out of Email Trouble. TechCrunch 2019. Available online: https://techcrunch.com/2019/09/24/grammarly-gets-a-tone-detector-to-keep-you-out-of-email-trouble/ (accessed on 1 December 2022).
- Grammarly Inc. About Us. Available online: https://www.grammarly.com/about (accessed on 1 December 2022).
- Grammarly Inc. Does Grammarly Support Languages Other than English? Available online: https://support.grammarly.com/hc/en-us/articles/115000090971-Does-Grammarly-support-languages-other-than-English- (accessed on 1 December 2022).
- LanguageTool. Languages. Available online: https://dev.languagetool.org/languages (accessed on 29 December 2022).
- LanguageTool. Error Rules for LanguageTool. Available online: https://community.languagetool.org/rule/list?offset=0&max=10&lang=uk&filter=&categoryFilter=&_action_list=%D0%A4%D1%96%D0%BB%D1%8C%D1%82%D1%80 (accessed on 13 December 2022).
- LanguageTool. About. Available online: https://languagetool.org/about (accessed on 15 December 2022).
- Korobov, M. Morphological Analyzer and Generator for Russian and Ukrainian Languages. arXiv 2015. [Google Scholar] [CrossRef]
- Tmienova, N.; Sus, B. System of Intellectual Ukrainian Language Processing. In Proceedings of the XIX International Conference on Information Technologies and Security, Kyiv, Ukraine, 28 November 2019; pp. 199–209. [Google Scholar]
- Pogorilyy, S.; Kramov, A.A. Method of noun phrase detection in Ukrainian texts. arXiv 2020, arXiv:2010.11548. [Google Scholar] [CrossRef]
- Glybovets, A.; Tochytskyi, V. Tokenization and stemming algorithms for the Ukrainian language. NaUKMA Res. Papers. Comput. Sci. 2017, 198, 4–8. [Google Scholar]
- Kholodna, N.; Vysotska, V.; Markiv, O.; Chyrun, S. Machine Learning Model for Paraphrases Detection Based on Text Content Pair Binary Classification. CEUR Workshop Proc. 2022, 3312, 283–306. [Google Scholar]
- Kholodna, N.; Vysotska, V.; Albota, S. A Machine Learning Model for Automatic Emotion Detection from Speech. CEUR Workshop Proc. 2021, 2917, 699–713. [Google Scholar]
- Abbasi, A.; Javed, A.R.; Iqbal, F.; Kryvinska, N.; Jalil, Z. Deep learning for religious and continent-based toxic content detection and classification. Sci. Rep. 2022, 12, 17478. [Google Scholar] [CrossRef]
- Bashir, M.F.; Arshad, H.; Javed, A.R.; Kryvinska, N.; Band, S.S. Subjective Answers Evaluation Using Machine Learning and Natural Language Processing. IEEE Access 2021, 9, 158972–158983. [Google Scholar] [CrossRef]
- Kapłon, T.; Mazurkiewicz, J. The Method of Inflection Errors Correction in Texts Composed in Polish Language—A Concept. Lect. Notes Comput. Sci. 2005, 3697, 853–858. [Google Scholar] [CrossRef]
- Jędrzejowicz, P.; Strychowski, J. A Neural Network Based Morphological Analyser of the Natural Language. Adv. Soft Comput. 2005, 31, 199–208. [Google Scholar] [CrossRef]
- Wróbel, K. KRNNT: Polish recurrent neural network tagger. In Proceedings of the 8th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics, Poznań, Poland, 17–19 November 2017; pp. 386–391. [Google Scholar]
- Shishkina, Y.; Lyashevskaya, O. Sculpting Enhanced Dependencies for Belarusian. Lect. Notes Comput. Sci. 2022, 13217, 137–147. [Google Scholar] [CrossRef]
- Rozovskaya, A.; Chang, K.-W.; Sammons, M.; Roth, D. The University of Illinois System in the CoNLL-2013 Shared Task. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning: Shared Task, Sofia, Bulgaria, 8–9 August 2013; Association for Computational Linguistics. pp. 13–19. Available online: https://aclanthology.org/W13-3602/ (accessed on 1 December 2022).
- Radchenko, V. Ukrainian Roberta. Available online: https://github.com/youscan/language-models (accessed on 17 December 2022).
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 July 2021; pp. 483–498. [Google Scholar] [CrossRef]
- Fan, A.; Bhosale, S.; Schwenk, H.; Ma, Z.; El-Kishky, A.; Goyal, S.; Baines, M.; Celebi, O.; Wenzek, G.; Chaudhary, V.; et al. Beyond English-Centric Multilingual Machine Translation. arXiv 2020. [Google Scholar] [CrossRef]
- Tang, Y.; Tran, C.; Li, X.; Chen, P.-J.; Goyal, N.; Chaudhary, V.; Gu, J.; Fan, A. Multilingual Translation with Extensible Multilingual Pretraining and Finetuning. arXiv 2020, arXiv:2008.00401. [Google Scholar]
- Platen, V.P. Leveraging Pre-trained Language Model Checkpoints for Encoder-Decoder Models. Available online: https://huggingface.co/blog/warm-starting-encoder-decoder (accessed on 19 December 2022).
- Rothe, S.; Narayan, S.; Severyn, A. Leveraging Pre-trained Checkpoints for Sequence Generation Tasks. arXiv 2019, arXiv:1907.12461. [Google Scholar] [CrossRef]
- Napoles, C.; Sakaguchi, K.; Post, M.; Tetreault, J. Ground truth for grammatical error correction metrics. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 588–593. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Platen, V.P. Encoder-Decoder Models Don’t Need Costly Pre-Training to Yield State-of-the-Art Results on seq2seq Tasks. Available online: https://twitter.com/patrickplaten/status/1325844244095971328 (accessed on 20 December 2022).
- RegEx. Available online: https://regex101.com/r/F8dY80/3 (accessed on 18 December 2022).
- RegEx. Available online: https://www.guru99.com/python-regular-expressions-complete-tutorial.html (accessed on 20 December 2022).
- RegExr. Available online: https://regexr.com/ (accessed on 21 December 2022).
- Bengfort, B.; Bilbro, R.; Ojeda, T. Applied Text Analysis with Python: Enabling Language-Aware Data Products with Machine Learning; O’Reilly Media, Inc.: Boston, MA, USA, 2018. [Google Scholar]
- Transformers—Hugging Face. Available online: https://huggingface.co/docs/transformers/main/en/index (accessed on 21 December 2022).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Epochs | CCEL Validation (Test) | CCEL Train (Train) |
|---|---|---|
| 14 | 0.28125 | 0.09309 |
| 15 | 0.28119 | 0.09299 |
| 16 | 0.28139 | 0.09375 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lytvyn, V.; Pukach, P.; Vysotska, V.; Vovk, M.; Kholodna, N. Identification and Correction of Grammatical Errors in Ukrainian Texts Based on Machine Learning Technology. Mathematics 2023, 11, 904. https://0-doi-org.brum.beds.ac.uk/10.3390/math11040904
Lytvyn V, Pukach P, Vysotska V, Vovk M, Kholodna N. Identification and Correction of Grammatical Errors in Ukrainian Texts Based on Machine Learning Technology. Mathematics. 2023; 11(4):904. https://0-doi-org.brum.beds.ac.uk/10.3390/math11040904
Chicago/Turabian StyleLytvyn, Vasyl, Petro Pukach, Victoria Vysotska, Myroslava Vovk, and Nataliia Kholodna. 2023. "Identification and Correction of Grammatical Errors in Ukrainian Texts Based on Machine Learning Technology" Mathematics 11, no. 4: 904. https://0-doi-org.brum.beds.ac.uk/10.3390/math11040904