1. Introduction
Networks of bio-inspired processors (NBP) is a family of computational models facing NP-complete problems by mimicking, from a syntactical perspective, the manner by which cell communities evolve via gene mutations in DNA molecules. Each cell is represented by a word that describes their DNA sequences. Mutation and cellular division are defined by operations based on string rewritings. Cells form colonies, which belongs to specific species, and a colony can be interpreted as an evolutionary system that evolves according to these operations. This dynamic abstracts the natural process of evolution and it is defined over a highly parallel and distributed computing architecture for symbolic processing. NBP can process one or two-dimensional arrays of symbols belonging to a predefined alphabet. The specific NBP model processing one-dimensional arrays of symbols (strings) are: network of [evolutionary/splicing/genetic] processors [
1,
2,
3]. On the other hand, NBP models processing pictures (two-dimensional strings) are named networks of picture processors (NPP) [
4]. The NBP model family defines a computational process based on the application of rewriting operations over strings, which can be explained as an abstraction of the behavior of mutating genes in chromosomes. For the NPP model, this process is applied to pictures representing a generalization of gene mutations in chromosomes over two-dimensional strings [
4].
The NBP architecture consists of a set of processors, each of which occupies a node of a virtual graph, employed to set up a network of evolutionary processors. An evolutionary processor is a theoretical device that applies simple rewriting operations to data. These rules, called evolutionary rules, are specialized in either deleting a symbol, inserting a symbol or changing a symbol for other symbol, which simulates operations over a pair of nucleotides. It is important to stress that each processor can apply a single type of rule (insertion, deletion or substitution) to its local data and that all processors in the network simultaneously applies their predefined rules (this is what is known as an evolutionary step).
Data (syntactical representation of cells) may evolve by these rules (evolutionary process). Then, data may be interchanged through the network by means a predefined protocol. This protocol is a filtering strategy based on enforcing a set of conditions, defined in each processor, in order to control the dispatch and the reception of data (even simultaneously). The navigation of data following a filtering strategy is defined as the communication process. It is important to stress that the filtering strategies mimic the process of selection from a Darwinian perspective.
As computing devices, the functioning of NBP networks occurs in turn repeatedly by intermixing the application of the evolutionary and communication processes. The computation is finished only if a predefined stopping condition is fulfilled. All processors modify their local data at the same time, defining a processing step and then local data that satisfies some filtering condition are allowed to flow from a processor to another according to the network topology (communication step).
NBP models have been extensively studied as language generators, language-accepting devices and problem solvers. Additionally, other properties of them have been extensively investigated, e.g., their computational power, their complexity aspects, their efficiency as problem solvers, the existence of universal networks, etc. For a better comprehension of these studies, we refer the reader to [
5].
Particularly, networks of picture processors (NPP) [
4,
6,
7] is a specialized model for computing two-dimensional strings, called pictures. There, a picture is a two-dimensional array of elements belonging a finite set of symbols (alphabet). Traditionally, the NPP model is applied to problems concerning image processing, picture recognizability or pattern matching [
8,
9,
10].
Recently, an NPP model named networks of polarized evolutionary picture processors (NPEPP) was proposed in [
11]. NPEPP defines its communication protocol based on the polarization concept. This filtering strategy generalizes the protocol defined by networks working over strings [
12,
13] in such a way that it does work over rectangular pictures. In particular, the polarization is an abstraction of the electric charge (negative, positive or neutral) that may be applied to both pictures and nodes. Whereas the polarization of a node is predetermined and not subject to or able to be changed during the entire computing process, the polarization of a picture is dynamically computed by a valuation mapping that determines the picture’s polarity based on its symbols and its predefined values. The valuation mapping returns the sign of this value but not its exact value. The movement of a picture from one node to other node through the communication protocol (filtering strategy) relies on both the picture polarization and the node polarization. Thus, this flow of a picture from one node to other node mimics the bio-electrical communication between cells.
A generalization of the polarization concept using evaluation sets to enhance the valuation mapping to calculate the exact value (not only the sign of this value) was proposed in [
14] and was used to empower the network of splicing processors [
15] and the networks of evolutionary processors [
16] models. In these works, the valuation mapping is used to give the precise numerical value of a string. In addition, the polarization is redefined to provide a filtering strategy able to allow the communication between two nodes, simulating the movement of molecules or particles from an area to other along a concentration gradient in a solution. Finally, it is demonstrated that this kind of communication protocol is more flexible and is able to deal with hard optimization problems with integer restrictions in an efficient way.
In this context, we propose an extension of the NPEPP model proposed in [
11], enhancing this model with the evaluation sets as filtering strategy for improving the communication protocol. In particular, we adapted the communication protocol working over strings proposed in [
14,
15] to work over pictures.
With this proposal, we enhanced the general NPP model with a more versatile protocol to include some quantitative features in a simple way, keeping rules for pictures processing. To show the computational power of our proposed model as well as its flexibility, we show how to leverage it to solve systems of quadratic polynomial equations over finite fields, e.g., the so called multivariate quadratic (MQ) problem.
Based on the hardness of the MQ problem (or variants of it), several cryptographic primitives have been constructed over the years. For instance, it is the security underpinning of the multivariate public key cryptosystems, a new family of post-quantum cryptographic schemes that withstand the action or effect of quantum computer attacks. In general terms, the hardness of solving the MQ problem over
is directly connected to the security of these cryptographic schemes [
17]. Recently, the authors of [
18] proposed a proof-of-work (PoW) based on random multivariate quadratic equations for a post-quantum blockchain [
19], which requests a solver (miner) to solve a set of random multivariate quadratic equations (RMQE) over the finite field
.
The main aim of this research paper was to provide a solver for the MQ problem over
using our extended and adapted model from NPP, named network of picture processors with evaluation sets (NPPES). As far as we know, this is the first occasion in which a bio-inspired computational model, such as the NBP model, was used to deal with solving systems of random quadratic equations (SRQE/RMQE) and therefore this paper proposes a unconventional solver for the PoW proposed in [
18] running in
computational (processing and communication) steps, where
n is the number of indeterminates. We remark that some results reported in the literature solving SRQE/RMQE problem require exponential time [
20,
21,
22,
23] for specific
input values. Therefore, our results suggest that the NPPES model faces such problems adequately and that the proposed network might be potentially deployed into a massively distributed and highly parallel platform without any modification, extension or adaptation.
This paper is structured as follows. In
Section 2, we introduce the background concepts as well as the formal definition for the NPPES model.
Section 3 discusses the capability of NPPES to solve the RMQE problem. We designed an NPEPP algorithm that works in
time. In addition, in
Section 4.6, we discuss the obtained results, the reasons we believe our solution is more suitable for such problems and how the proposed algorithm may be transformed to be deploy into an ultra-scalable computational platform without any modification, extension or adaptation. Finally, conclusions and forthcoming works are presented in
Section 5.
2. Networks Picture Processors with Filtering by Evaluation Sets
In this section, we introduce the network of picture processors with evaluation sets (NPPES) proposed model. First, we start off by summarizing the notions used throughout this paper, which were previously introduced in [
7]. This is the theoretical background underlying our proposed model. We later introduce the formal definitions for the NPPES model.
2.1. Preliminary Concepts
We define an alphabet as a set of non-empty symbols. The number of elements of a finite set S is denoted by (this is also known as the cardinality of S). Also, we define a picture as a two-dimensional array of symbols taken from an alphabet V. The set denotes the set of all pictures over V and denotes the empty picture. The pair defines the size of the picture , where denotes the number of rows and denotes the number of columns of . The size of the empty picture is given by with . The notation denotes the symbol placed at the intersection of the row with the column of the picture .
Let be a picture of size over V, and , then is a sub-picture of that consist of all symbols with and . Following this definition, is . The minimal alphabet containing all visible symbols appearing in a picture is denoted by . Also, we define a valuation of in as a homomorphism from the monoid to the monoid of additive integers . For any alphabet V and a symbol , denotes the invisible copy of a and }. A picture is said to be a well-defined picture if there exist and such that all elements of are from V and all the other elements of are from . In this case, the maximal visible subpicture of is denoted as . In concrete, a well-defined picture may be interpreted as one having some rows and/or columns on its border hidden but not deleted. We stress that any picture over the alphabet V is a well-defined picture and that, from this point forward, we deal with only well-defined pictures.
We use the rewriting operations or evolutionary rules such as they are introduced and used in [
6,
7]. Concretely, we use substitution, mask and unmask rules. We summarize the definitions of these rules below. In order to know the rest of rules (insertion and deletion) as well as the formal definitions for all evolutionary rules, we refer the reader to [
7].
An evolutionary rule is defined as , with . Particularly, r is defined as a substitution rule if neither nor is .The set is the set of substitution rules. On the other hand, a mask rule is a rule able to hide a column or a row. Similarly, an unmask rule is able to make visible a column or a row. The action mode is the element that defines the picture’s position in which a rule r can be applied. Let be a picture and let be the maximal visible subpicture of , then the actions of r on are (. These actions are defined as following:
Substitution rules:
- −
is the set of all pictures obtained from by replacing an occurrence of by in the leftmost column of . We remark that r is applied to all instances of the symbol in the leftmost column of the ’s different copies.
- −
Similarly as above, is the set of all pictures obtained by applying r to the rightmost column of ; is the set of all pictures obtained by applying r to the first row of ; is the set of all pictures obtained by applying r to the last row of ; is the set of all pictures obtained by applying r to any column/row of the .
Mask and unmask rules:
- −
mask returns a picture obtained from , by transforming all visible symbols from the leftmost column of the into their invisible copies. Analogously, it is defined as the mappings mask, mask and mask.
- −
unmask returns a picture from , by making its leftmost column visible. If is , then all invisible symbols , become visible. If , then unmask. Similarly, it occurs for unmask, unmask, and unmask.
For every rule
r, symbol
and
, the
-action of
r on
L is defined by
. For a finite set of rules
M, we define the
-action of
M on the picture
and the language
L by:
Analogously, for every , it defined maskmask and unmaskunmask.
2.2. NPPES: Formal Model Definition
We start defining a new function that is required to extend the NPP model with the filtering strategy using evaluation sets. This function is necessary to extend or more precisely generalize the NPP variant proposed in [
11].
Definition 1. Let V be a finite alphabet and π be a picture over V with size . We define the projection function as follows This function is required because we need to calculate, for a picture, the “concentration” of the symbols included in S. Therefore, this function ignores the other symbols that do not belong to S. With this definition and other components required to propose the evaluation sets filtering strategy, we define our extension of a picture processor as follows.
Definition 2. Let V be an alphabet. A generalized picture processor over V is a triple such that:
M is a set of evolutionary rules containing either substitution or deletion rules over V ( or ).
.
α is a set of mutually disjoint intervals of , which gives the generalized polarity of the node. In particular, the polarity of a node, that is , in our generalization, it can be viewed as the intervals , , , respectively.
Definition 3. A hiding generalized picture processor over is a triple such that M is a set of either mask or unmask rules over V. The rest of the other parameters are identical to those in the Definition 2.
The set of (hiding) generalized picture processors over
V is denoted by
. Evidently, the generalized picture processor introduced here is a mathematical concept comparable to that of an evolutionary algorithm, both of which are motivated by the Darwinism. Compared to evolutionary algorithms, the evolutionary rules may be understood as a two-dimensional generalization of gene mutations and the evaluation sets (supported by means of
S and
elements, Definitions 1 and 2) might be seen as a selection process similar to, as we have mentioned in the
Section 1, the bio-electrical properties of the concentration gradients in a solution.
Definition 4. A network of picture processors with evaluation sets (NPPES) is a 10-tuple
, where:
V is the input alphabet and U is the network alphabet.
is an undirected graph (which is called the underlying graph of the network) such that is the set of vertices and is the set of edges.
defines a mapping for associating each node with the generalized picture processor over U, such that .
such that defines the action mode of the rules of node x on the pictures existing in that node.
ρ is a mapping which allows to associate each subset of U with an interval (possibly empty) of satisfying that for any subsets of U.
is a valuation of in .
are nodes of such that they are the input, halting and accepting nodes of Γ, respectively.
Definition 5. A configuration of an NPPES Γ such as it is defined in the Definition 4, is a mapping linking every node of the network’s graph with a set of pictures. Informally, a configuration represents the content (the set of pictures) of each node at a given moment. Let a picture, the initial configuration of Γ on π is formally denoted by and .
An NPPES network evolves through two steps: processing and communication steps over the configurations. On a processing step for instance, each element belonging to a configuration C evolves according to the set of rules defined for the node x (). These steps are defined as follows.
Definition 6. One processing step that produces a configuration is obtained from the previous configuration C, which is denoted by , iff Definition 7. One communication step, denoted by produces a configuration denoted bywhere Assuming that a picture within node x has its valuation with respect to some in , if belongs to , then a copy of the picture is kept within the node x, else it is forced out. If , then a copy of the picture gets into y as long as x is adjacent to y in G. On condition that a picture is forced out of a node and is not able to get in any node, then it is lost. We remark that a copy of some picture can stay in x and the same time other copies of can move from x to other nodes that are adjacent to x.
Definition 8. A computation for an NPPES Γ on the input picture is defined as a sequence of configurations such that is the initial configuration and and , for all are the processing and communication steps performed in an alternate way. Note that the configuration determines the configuration .
Finally, the stop condition for an NPPES
occurs when the halting node is non-empty at some point of the computation. Then, the picture language decided by
is given by
3. Random Multivariate Quadratic Equations
In this section, we formally describe a well-known NP-hard problem regarding the hardness of solving a set of
m random quadratic equations in
n indeterminates over a finite field
F. This is called the MQ problem [
24].
Let
be the finite field with
q elements. The multivariate quadratic (MQ) problem is defined as follows. Given
m quadratic polynomials
in the
n indeterminates
as shown below
where
, with
and
, are chosen uniformly and independently in a random way. The MQ problem asks to find
such that
The MQ problem is proven to be NP hard, even with quadratic polynomials over the field
(MQ
) [
24]. Moreover, the hardness of the MQ problem is the security underpinning for multivariate public key cryptosystems [
25], a new family of post-quantum cryptosystems that can withstand the action or effect of quantum computer attacks. For instance, several MQ-based signature schemes were submitted to the National Institute of Standardization of Technology post-quantum cryptographic standardization process [
23,
25,
26,
27,
28]. In particular, Rainbow has been included in the third round of this process [
29].
The MQ problem has also been used to construct a proof of work for post-quantum blockchains [
19], and is part of the cryptocurrency called ABC Mint [
18]. In this setting, the solver’s task is to find a solution to a given instance of the problem within a reasonable period of time in order for the solver to include a block of transactions in the blockchain. In particular, this instance of the MQ problem is defined over
with
n being a suitable but variable chosen integer and
m being set to
. The reason of this choice is to guarantee that a solution can be found with overwhelming probability within a reasonable period of time [
18]. To perform the task, a solver first generates a bit string of
bits uniformly and independently at random, by applying a cryptographic hash function to a random input formed from the block to be included in the blockchain. This long string is then partitioned into
strings of
bits, each of which represent the coefficients of a polynomial in the equations system. The solver then performs a computational task consisting in finding a vector
such that the Equation (
4) holds [
18].
As an additional remark, a coefficient-based representation of a polynomial requires storing elements of . In total, elements of are required to represent all polynomials. That is, a complete coefficient-based representation of all polynomials in the equation system requires bits in a classical computer.
Another contribution of this paper is that we construct a solver based on NPPES for solving an instance of the MQ problem, assuming the polynomials
are given in a special form. We introduce such solver based on NPPES, which is able to find a vector
that satisfies the Equation (
4), in the following section.
4. A Solver for the Random Multivariate Quadratic Equations (RMQE) Problem Using NPPES
In this section we discuss how to construct a solver for the MQ problem described in the previous section.
Let
be defined as the number of variables and equations respectively. Following the definitions introduced in the
Section 2, we define the next components of an NPPES, named
, for our proposed solver.
Let be the input alphabet such that:
, where
- −
, where and . The two symbols and represent the two values that can assume. In other words, the symbol represents that assumes the value 1, while the symbol represents that assumes the value 0.
- −
is the set of all symbols , for and . The two symbols and represent the two values that can assume. In other words, the symbol represents that assumes the value 1, while the symbol represents that assumes the value 0.
- −
. The two symbols and represent the two values that can assume. In particular, the symbol represents that assumes the value 1, while the symbol represents that assumes the value 0.
, represents the n indeterminates .
, is the set of control symbols used through the computation of the NPPES algorithm.
, with
representing a signaling symbol for the polynomial
from Equation (
3).
Let
be the set of pictures
, for
, where the size of each picture
is
. Each picture may be seen as a matrix of which rows are indexed starting from one. The
n first rows of
encode the terms
for
, having the empty entries filled with the symbol
$. In particular, the
-row, with
, has the first
entries, from left to right, filled with the symbol
$, the entry
filled with a symbol from
, then the entry
filled with
, then the entry
filled with
and so on. The
row of
encodes the terms
for
, having the empty entries filled with the symbol
$. The
row encodes the independent term
and the
term, having the empty entries filled with the symbol
$. Finally, the last row encodes the control symbols from the set
C, which are required for internal computation of
. For example, given the polynomial
, it is then encoded as the picture shown by
Table 1.
We remark that our network receives
m input pictures encoding the
m polynomials
from the instance of the problem to be solved, and then our network
will obtain values (if they exists) for the indeterminates
such that Equation (
4) holds.
Let be the network alphabet, where:
.
.
.
.
.
.
.
In particular, the sets
are needed to control the transition between the different
’s phases, namely: generation, linear evaluation, quadratic evaluation and validation. These phases are represented by different subnetworks as explained below. The set
X is the set of symbols representing the indeterminates
. Similarly, the sets
and the set
encapsulate the symbols with the values assigned to the indeterminates
when they are evaluated in each phase of
and require some evaluation. The symbols
are trash symbols required for some transformations at different phases of the computation. Finally,
are punctual transformations of the control symbol
in order to indicate the final evaluation of the Equation (
4) for a picture.
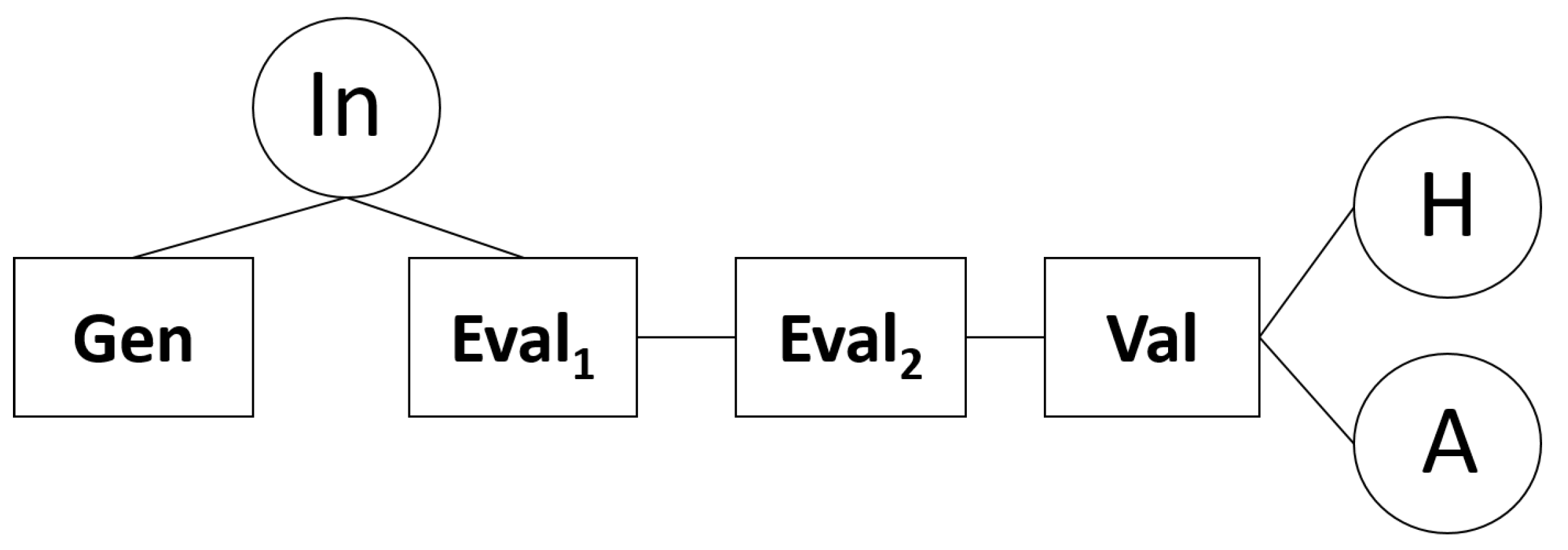
The underlying graph G of our proposed
is depicted in the
Figure 1. The nodes
In,
H and
A are the input, halting and accept nodes, respectively, while the boxes
Gen,
,
,
Val are subnetworks representing the different stages or phases for
computation. In particular, the box
Gen represents the subnetwork in charge of the combinatorial task for generating all pictures
containing the different values for the indeterminates
for each input picture. Also, both boxes
and
represent the subnetworks for the phases of evaluation. The former represents the subnetwork that computes the evaluation of the
row of a given picture, namely, the evaluation of the terms
, while the latter represents the subnetwork that computes the evaluation of the first
n-rows of a given picture, namely, the evaluation of the terms
. Finally, the box
Val represents the subnetwork in charge of the phase for selecting the pictures that satisfy the Equation (
4). Detailed description for each subnetwork as well as the
and
A nodes are introduced in the
Section 4.1,
Section 4.2,
Section 4.3,
Section 4.4,
Section 4.5. In addition, the internals for each subnetwork are given in the
Figure 2,
Figure 3,
Figure 4 and
Figure 5.
The mapping function is defined as follows:
We assume that any symbol in U not appearing in the previous mapping has an empty interval for evaluation since it is not relevant for the proposed algorithm.
The function is defined as follows:
, for all
, for all
, for all
, for all
, for all
, for all
, for all
We remark that the values for elements in P are given as input values.
4.1. The Node in
By default, in the initial configuration, the node
In holds the input picture coding the instance of the problem to solve. For our network
, the node
In holds the input pictures representing each polynomial
. In addition, this node serves like a both receptor and transmitter of the pictures processed by subnetwork
. For this reason, this node only has a substitution rule that changes one control symbol by other one. In particular, while the subnetwork
is generating configurations, i.e., pictures with the corresponding symbols assigned to each indeterminate, these are allowed to pass to the
subnetwork by the
In node for further processing. This node’s internals are shown in
Table 2.
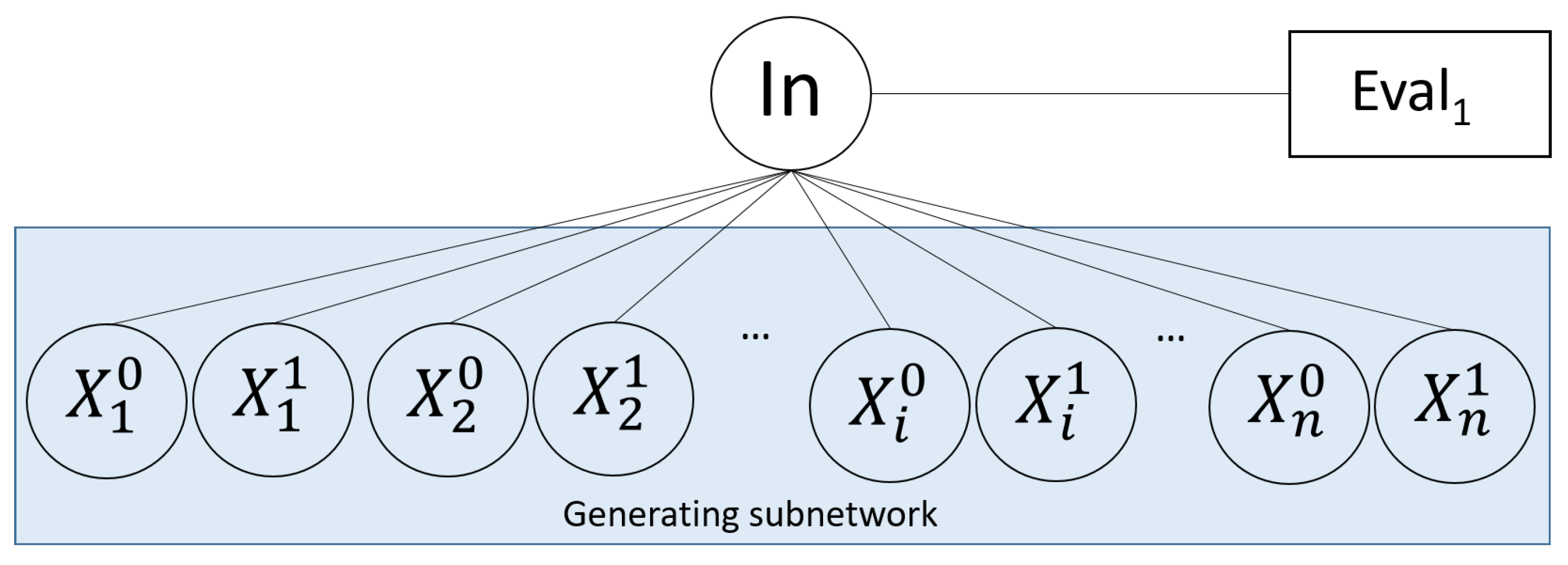
4.2. Generating Subnetwork
The subnetwork
represents the
generating phase, namely, the phase in charge of generating
configurations for the initial pictures
encoding an RMQE instance. In particular, this subnetwork replaces each
for a symbol
or
, which represents the value 1 or 0 respectively, and hence generates
configurations for each initial picture
. The graphical representation of the underlying subgraph for subnetwork
is depicted in the
Figure 2.
According to the
Figure 2, each indeterminate
is represented by two nodes, namely,
and
. Concretely, the node
replaces all occurrences of symbol
for the symbol
(which represents 0). On the other hand, the node
replaces all occurrences of symbol
for one symbol
(which represents the value 1). After
n processing steps, the subnetwork
will have modified all
symbols and generated
configurations for each initial picture
. These configurations will be collected by the
In node. The internals of each node
in this subnetwork are defined in the
Table 2.
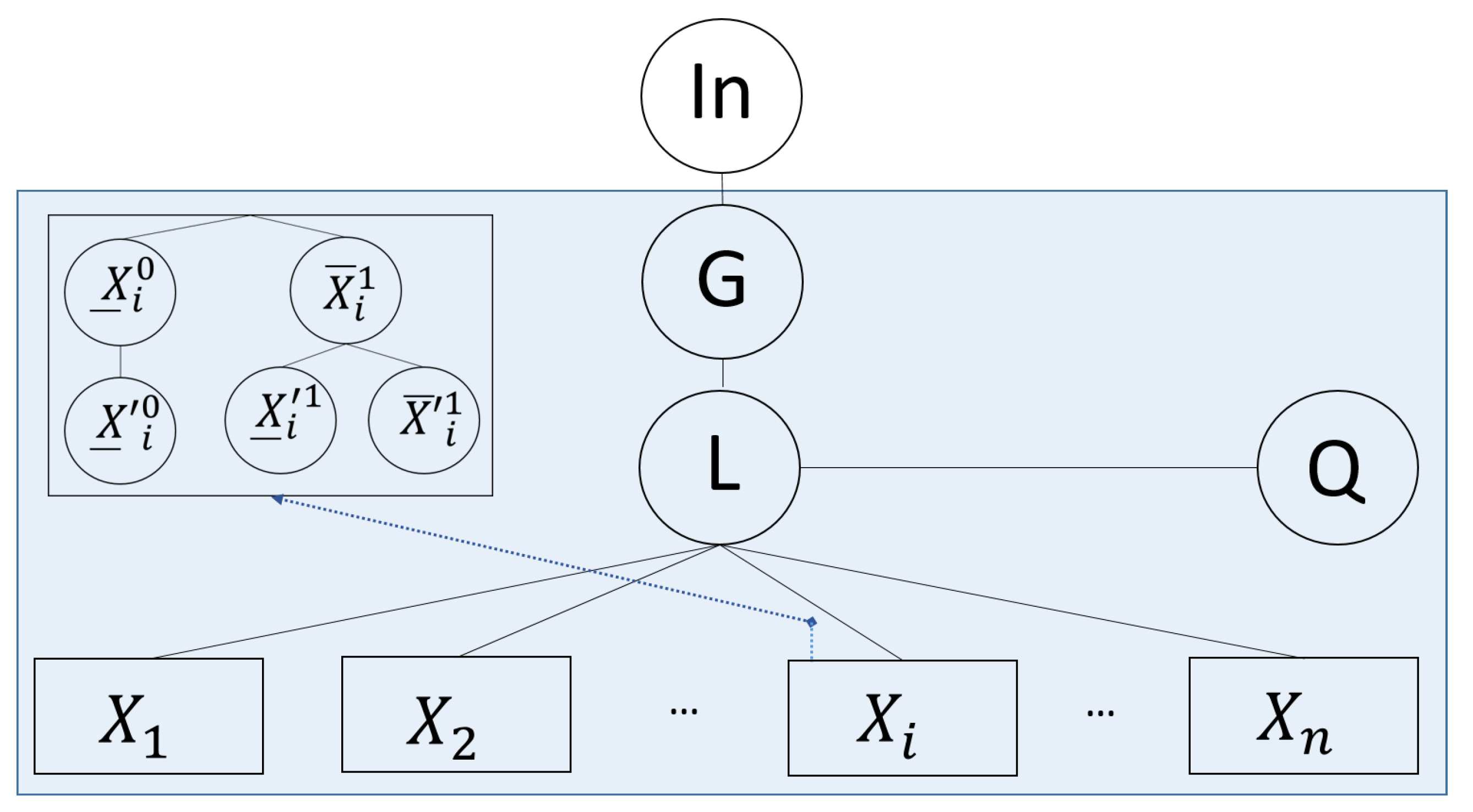
4.3. Linear-Evaluating Subnetwork
The aim of this subnetwork is to evaluate AND operations for each pair of symbols
with
, which are encoded at the row
of each picture. The graph representing this subnetwork is depicted in the
Figure 3.
This subnetwork starts off with the node G receiving pictures from the node . The received pictures are then processed by the node G, by masking the two last rows (at indexes and ) from them. This makes each processed picture’s last visible row be the row that contains the terms (i.e., the row). This row is what will then be processed by other nodes in this subnetwork, by applying on it substitution rules with the mode ↓.
The node
L serves as a control node to keep the traceability of the substitution of each pair
done by the subnetwork
depicted in the
Figure 3 (the internals of these boxes can be seen in the rectangle at left-upper corner). In a similar way as the subnetwork
operates, the nodes
and
replace all occurrences of symbols
and
for an intermediary symbol in the set
. With them, this subnetwork is able to evaluate whether the result of the AND operation for the pair
is 0 or 1 through the evaluation sets defined in the nodes
and
, respectively. In these nodes, the symbols belonging to the set
are substituted by the symbols either
or
according to the result from the AND operation (representing 0 and 1, respectively). Concretely, in the node
, the symbols representing the
values are substituted by trash symbols either
or ⧫. Subsequently, the nodes
and
let pass only the pictures which evaluation represents 1 or 0, respectively. Then, they substitute the trash symbols for the specific result (1 or 0). Therefore, the result of the evaluation has been assigned to the place for the
symbols at the picture. The processing for
L and nodes represented in the boxes
is repeated until all terms
in the pictures have been substituted, with the valid resulting pictures leaving the node
L and entering the node
Q. Finally, the node
Q masks the recently evaluated row for all received pictures making only the first
n rows visible, i.e., the rows that encode the terms the
. In this way, the pictures are prepared for the following phase (subnetwork
), which evaluates the quadratic terms. The internals of each node in this subnetwork
are defined in the
Table 3.
4.4. Quadratic-Evaluating Subnetwork
This subnetwork is responsible for evaluating each term
in the pictures. The result from evaluating the AND operation between each one these three terms will be represented by the substitution of the
symbols by a symbol 0 or 1 (depending of the result). Similarly at the subnetwork
, the symbols
are replaced by the trash symbols
$ or
. The
Figure 4 depicts the graph of this subnetwork. The internals of each node in this subnetwork are defined in the
Table 4.
The processing of this subnetwork starts off with the node receiving all pictures from the node Q. Then, this node unmasks all invisible rows such that it makes the last rows visible. More specifically, the node unmasks the rows at indexes , and in each received picture. After that, the processed pictures are allowed to move to the node , which substitutes the control symbol and the symbol in each picture for the symbols and , respectively. Note that this node only does this substitution once and it is only for controlling the internal processing.
After this substitution is carried out, the process for evaluating each row containing the terms , starts such that each term is evaluated one at time. The node is responsible for keeping track the evaluation of each row. Specifically, this node starts with the substitution of the symbol for in order to indicate that the row 1 will be evaluated subsequently. In addition, this node substitutes all symbols ■ for the trash symbol $, because they are no longer needed.
The next time this node receive pictures from node , it can substitute the symbol again and so on until all rows are evaluated. The node M is able to mask all columns from the rightmost column to the column containing the (exclusive) symbol of the current to be evaluated (this is controlled by means of the symbol place at this same column). With this masking process, makes visible only the current three terms at the first visible row. Subsequently, the operation AND is calculated for these three symbols in a similar way as it is processed for the subnetwork (in the boxes ). More concretely, this evaluation is done by the nodes and . Then, the node substitutes the for in order to identify that the current quadratic term was evaluated. In addition, this node substitutes the symbol for the original one. Note that the result of the AND operation is encoded at the place in which the symbol was placed. In order to carry out the evaluation for the rest of the terms in the current row, the nodes and unmask the rightmost three columns and mask the current three visible columns, respectively. is connected with the nodes and and it allows that the process for evaluating each term is repeated until all of them are evaluated. When it occurs, the pictures from node migrate to the node and it makes the other branch of the subnetwork will be processed.
Given that the last control symbol substituted was by , the pictures can enter to the node . Then, this node returns the symbols to their original one (). Similarly, this node substitutes the symbols by their original ones. After that, the pictures migrate to the node and this node substitutes one symbol $ for a in order to indicate that the current row was just evaluated. Then, the pictures enter to and the current row is masked. Subsequently, the node unmasks all masked columns to the left. The processing for this branch finishes when the node substitutes all symbols for their original ones in the set . With these substitutions, is able to evaluate the next visible row and hence, the pictures migrate to the node in order to repeat the processing of the next row. When the pictures do not contain symbols, then they migrate from the node to the node . Note that all pictures with the symbol are allowed into the node . Finally, the nodes and are responsible for unmasking all hidden rows and columns in order to promote them for the next phase.
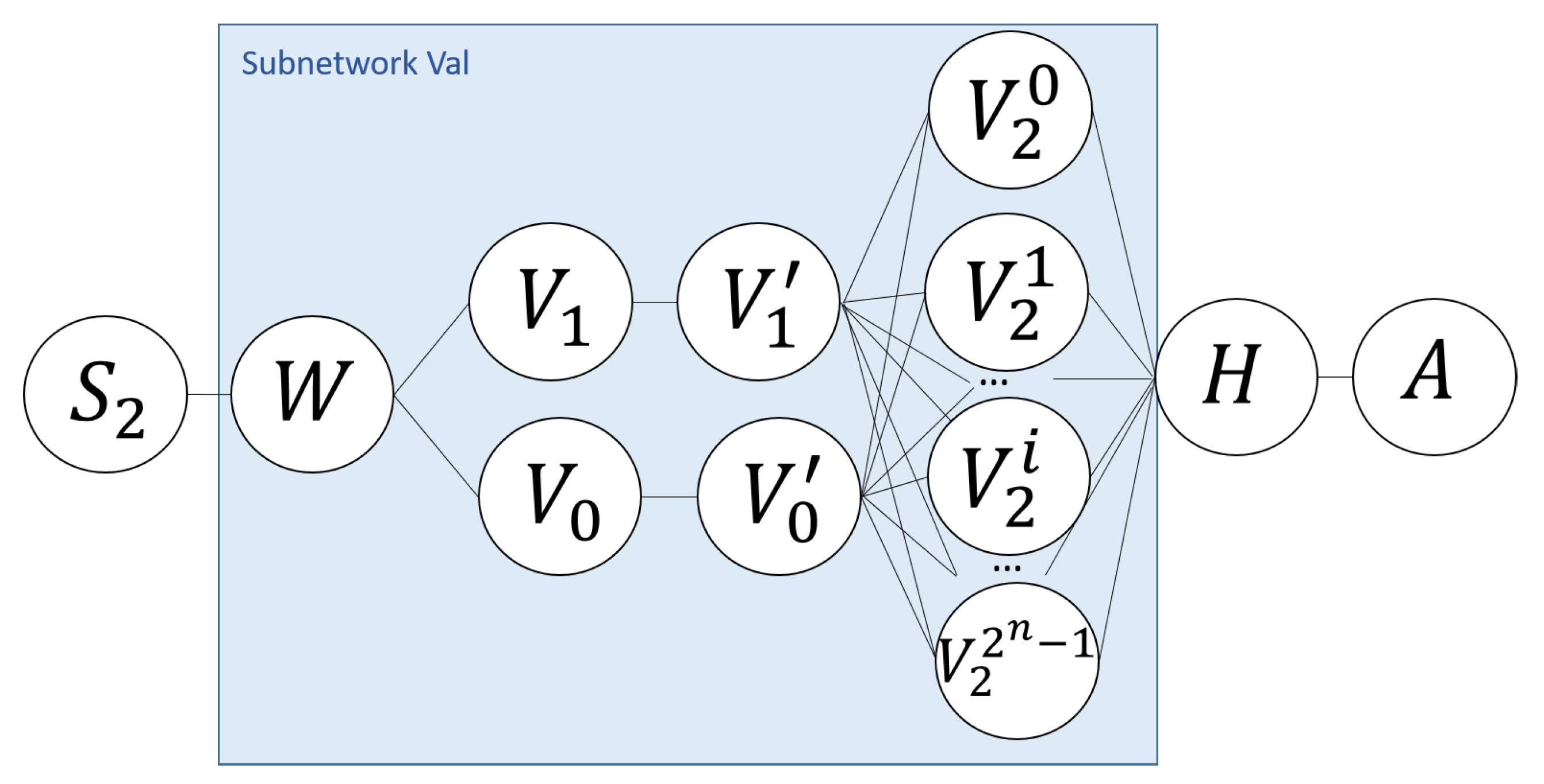
4.5. Validation Subnetwork
The goal of this subnetwork is twofold. First, this subnetwork calculates the final value for each picture, e.g., the evaluation to the polynomial that the picture represents. More specifically, this subnetwork computes the resulting value from each
(i.e., 0 or 1), for all
, after performing XOR operations between the terms that compose the picture (summation of all them). This result will be stored as a value for the control symbol
at the last row in the pictures. Second, this subnetwork groups all the pictures sharing the same values for the indeterminates
. This grouping will allow to obtain the solutions for the problem, that is, to find vectors
satisfying Equation (
4). The values for each
remains represented by the symbols belonging to
or
placed into the row
n (0 or 1, respectively). The
Figure 5 depicts the graph of this subnetwork.
Concretely, the nodes
and
performs a XOR operation with the values placed in rows from one to
n and replace the control symbol
with the result obtained from performing the XOR operation, i.e., by substituting the symbol
by other control symbol
if the result of XOR operation is 0 or
otherwise. The nodes
,
, group all pictures belonging to each possible combination of
n values assigned to the indeterminates. In particular, each configuration is mapped to an integer in the range
. Previously, the node
W has substituted all symbols in the sets
and
for their corresponding symbols in the sets
and
, respectively. It is necessary in order to evaluate each configuration filtering each picture according to the value obtained by nodes
. These nodes substitutes the control symbol
for a control symbol
, where the index
i represents the number of configuration. Finally, the node
substitutes all symbols belonging to the sets
and
for the original ones and the node
collects all pictures representing the solution of the input instance. The internals of each node in this subnetwork are defined in the following
Table 5.
4.6. Discussion
Lemma 1. The NPPES
Γ defined in Section 4 computes a solution for the RMQE problem. Proof of Lemma 1. At the beginning of the computation,
contains the set of pictures
encoding the polynomials to be evaluated (all of them in the node
). Thus, the initial configuration is defined by
and
. 25A0
consist of the initial pictures (with the
symbol substituted by
) for all
,
represented in the
Figure 2. After
n processing steps, the node
has collected
pictures. Note that for each initial picture
, the subnetwork
generates a picture for each possible
tuple of values to the indeterminates
in
. Therefore, it generates
pictures that are collected by the node
and are then sent out to the subnetwork
, more concretely to the node
G. This node masks the three last rows in all received pictures and then sends the pictures out to the node
L, which includes one new trash symbol indicating the first step to evaluate the terms placed in the row
n, namely
, for all
.
Note that the nodes evaluate, in two processing steps, whether each term is 0. At the same processing steps, the nodes evaluate whether each term is 1. These evaluations are done by applying simple substitution rules. After n processing steps, each picture will have all terms evaluated and be collected by the node L. All pictures then migrate to the Q node, which masks the row containing the recently evaluated terms (last row) within a processing step. Then, the pictures are sent out to the subnetwork , more precisely to the node . This node makes all masked rows in each received picture visible through two processing steps. Note that is a control node which performs its task once, then it performs one processing step. controls the rows being evaluated by the subnetwork, starting from the first row by substituting one symbol and n symbols ■ using n processing steps. The nodes evaluate each term in each corresponding row of a picture, by making the three columns occupied by each term visible and then performing an AND operation with the corresponding values. When all terms are evaluated, the hidden columns are made visible again and a mechanism to indicate that this row was evaluated is used. Then, these nodes perform n times their respective steps.
The nodes
and
make the just-evaluated row invisible, mark the index of the evaluated row (substituting the respective symbol in
and preparing the pictures for the evaluation of the next row). After the evaluation of the possible occurrences of the
terms, the node
and subsequently
collect all evaluated pictures and return the masked rows to the visible state after perform
n and
processing steps, respectively. Then
contains a set of pictures encoding each and every admissible evaluation of each polynomial in the Equation (
3). However, at this stage, we need to organize all pictures by classes, where each groups pictures of each polynomial for one of the
tuple of values that can be assigned to the indeterminates, and then determine which classes satisfy the Equation (
4), if any (if a class has
m pictures then the corresponding
tuple is a solution).
The node
W performs
n processing steps in order to do all substitutions.
and
substitutes the independent term in the
row of a picture for the corresponding symbol for all pictures at the same processing step. In addition, these nodes let can pass to the nodes
and
only the pictures with evaluation of all symbols 1 being wither odd or even, respectively.
and
nodes substitute control symbols at the last row in the same processing step. The nodes
group the pictures according to each possible
tuple of values for the indeterminates that satisfy Equation (
4), via marking the picture with an
symbol, where the index
i represents the
tuple of values, at same processing step. The transition of
H to
A is immediate:
H returns the symbols of the vector to the original ones and
A puts the final result of the evaluation in the control symbol
. Each one of these two nodes perform one processing step. Finally, the node
A collects the pictures containing the solution for the given instance. □
Therefore, as a consequence of this result, we obtained the following theorem:
Theorem 1. The RMQE problem as it was defined in Section 3 can be solved by a NPPES Γ
in time . Proof of Theorem 1. Following the identical conditions as we have mentioned before, the processing steps in are:
Node In: steps
Subnetwork : n steps performed by ,, nodes.
Subnetwork : steps performed as follows:
- −
Node G: 2 steps
- −
Node L: steps
- −
Node Q: 2 steps
- −
Nodes ,, : n steps
- −
Nodes , , , : n steps
Subnetwork : steps performed as follows:
- −
Node : 2 steps.
- −
Node : 1 step.
- −
Nodes: : steps (1 processing step performed by every node)
- −
Nodes : steps ( processing steps performed by every node)
- −
Nodes : at most steps for each of these nodes, then
- −
Nodes and : at most n processing steps for each n row, then, steps
- −
Node : n steps
- −
Node : steps
Subnetwork : steps performed as follows:
- −
Node W: n processing steps
- −
Nodes , 1 step
- −
Nodes , 1 step
- −
Nodes , 1 step
Nodes H and A, 1 step every node, then, 2 steps.
Therefore, the total number of processing steps is not more than
. Note that, if a given instance of the problem has
k solutions, with
, then
finds the
k tuples of values for the indeterminates that are solutions for the given instance. Consequently, the overall time for solving an instance of the RMQE problem, as it is defined in Equation (
4), is
. □
We remark that the proposed network
seems to have a significant size in terms of number of nodes. This can be seen as an aspect to be improved; however, note that this construction allows us to control the exponential growth of the generated strings in any moment. In addition, we obtain a viable solution in an acceptable computation time given the complexity of the problem we are dealing with. Also,
sieves the correct pictures in an early identification step, minimizing the unnecessary copies. Additionally, note that other NBP models do not give such flexibility when the problem needs to meet integer constraints. Consequently, NPPES opens up an interesting perspective to fill this gap. Another important reason to support the solution we presented here is that, given the high maturity achieved by the ultra-scalable computing platforms, since this facilities deploying distributed algorithms in a reasonable way [
16], our proposed solution might be deployed by using any hardware/software solution as those reported in [
30], without requiring any modification (re-structuring of nodes, rules, mechanism to workload distribution between computational units or so on). That is to say, we potentially may put our solution to run on workers or parallel computing units in any scalable software or hardware platform without re-defining the proposed algorithm, because our distribution of nodes would be more suitable to reallocate parallel processing units within a real computing platform.
5. Conclusions and Final Remarks
We have introduced a solver for the RMQE problem that is based on NPPES and runs in quadratic time, suggesting that the NPPES model can be employed to cope with hard complex problems in which numerical evaluation has an essential role. In this context, the extended model is able to deal with a new variety of hard problems because of the model’s new features, in particular its filtering strategy makes the selection of correct pictures easier compared to the previous model. Additionally, the model exhibits efficiency and uses up less resources than similar bio-inspired models facing similar hard problems. To the best of our knowledge, this is the first time in which an NBP model is used to propose a solver for the RMQE problem. Also this solver demonstrates the computational power that may be achieved by employing bio-inspired computational models, since existing non-bio-inspired solutions run in exponential time for specific input values. Furthermore, our proposed solution for the RMQE problem opens an interesting opportunity to propose new solvers for these complex problems, bringing about real computing solutions with a reasonable computing time (which can be understood as “efficient time”).
In previous works [
14,
31], it is stated that NPEP solutions need an adaptation for allowing the deployment on computational platforms for massive distributed processing. Moreover, this adaptation must preserve the solution’s complexity in order to achieve practical solutions to real problems on big data computing platforms (which is extensible to any solution using similar models computing pictures instead of strings). In this context, the proposed solution here does not require any adaptation to be deployed in massively parallel and distributed computing platforms, and therefore, we avoid the previously commented drawbacks when these algorithms are deployed in practical scenarios.
Our results additionally suggest that the NPPES model may be more simple than other models working on pictures or strings for tackling hard optimization problems with numerical evaluations. We thus think this model shows features worthy of further investigation, both from a theoretical approach and from a practical point of view. With respect to the latter, we think studying the limits of software and hardware implementations to attack complex problems with big data computing platforms deserves effort and attention. Additionally, researching into the suitability of extending this model to reinforce it for other related high-processing problems also is interesting. Finally, we shall return to these topics in a forthcoming work.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}