A Hybrid Forward–Backward Algorithm and Its Optimization Application

1
School of Mathematical Sciences, University of Electronic Science and Technology of China, Chengdu 611731, China
2
Department of Mathematics, Hangzhou Normal University, Hangzhou 31121, China
3
Research Center for Interneural Computing, China Medical University Hospital, Taichung 40447, Taiwan
*
Author to whom correspondence should be addressed.
Mathematics 2020, 8(3), 447; https://0-doi-org.brum.beds.ac.uk/10.3390/math8030447
Submission received: 25 February 2020
/
Revised: 17 March 2020
/
Accepted: 18 March 2020
/
Published: 19 March 2020
(This article belongs to the Special Issue Nonlinear Analysis and Optimization)
{kind=link}
{kind=link}
{kind=link}
Abstract
:In this paper, we study a hybrid forward–backward algorithm for sparse reconstruction. Our algorithm involves descent, splitting and inertial ideas. Under suitable conditions on the algorithm parameters, we establish a strong convergence solution theorem in the framework of Hilbert spaces. Numerical experiments are also provided to illustrate the application in the field of signal processing.
1. Introduction
Let H be a real Hilbert space. denotes the associated scalar product and stands for the induced norm. Recall that a set-valued operator is said to be maximally monotone iff and its graph, denoted by , is not properly contained in the graph of any other monotone operator on H.
A fundamental and classical problem is to find a zero of a maximally monotone operator G in a real Hilbert space H, namely
This problem includes, as special cases, bifunction equilibrium problems, convex-concave saddle-point problems, minimization problems, non-smooth variational inequalities, etc. Due to its diverse applications in economics, medicine, and engineering, the techniques and methods for solving (1) have received much attention in the optimization community, see [1,2,3,4]. Indeed, the interdisciplinary nature of Problem (1) is evident from the viewpoint of algorithmic developments; see, for instance, [5,6,7,8] and the references therein. Among them, a celebrated method for solving (1) is the following proximal point algorithm. It can be traced back to the early results obtained in [6,7,8,9]. Given the current iterate , calculate the next iterate via
where stands for the identity operator and is a positive real number. The operator is the so-called resolvent operator, which was introduced by Moreau in [8]. In the context of algorithms, the resolvent operator is often referred as the backward operator. In [7], Rockefeller studied the operator and proved that the sequence generated by algorithm (2) is weakly convergent via the inexact evaluation of the resolvent operator in the framework of infinite-dimensional real Hilbert spaces. However, the evaluation error has to satisfy a summability restriction. Indeed, this restriction essentially implies that the resolvent operator is computed with the increasing accuracy. In fact, due to the computation of the resolvent operator is often hard to control in practice situation, this is still somewhat limiting. Quite often, computing the resolvent of a maximally monotone operator, which is an inverse problem, is not easy in many cases. Thus, this limits the practicability of the proximal point algorithm in its plain form. Aiming at this, a favorable situation occurs when the operator G can be written as the sum of two operators. Precisely, let us define such that the resolvent (implicit, backward step), and the evaluation of B (explicit, forward step) are much easier to compute than the full resolvent . In so doing, we only consider the following inclusion problem: find a zero of an additively structured operator , acting on space H, namely
where B is a smooth operator for which we can use direct evaluations, and A is a proxfriendly operator for which we can compute the resolvent. For solving (3), Lions and Mercier [10] proposed the forward–backward splitting method. It is based on the recursive application of a forward step with respect to B, followed by a backward step with respect to A. For any initial data ,
where stands for the identity operator and . Basically, the operator is maximally monotone, and the operator B is -cocoercive (i.e., such that ) and -Lipschitz continuous (i.e., such that ). It was proven that the generated sequence converges weakly to a solution of (3). Of course, the problem decomposition is not the only consideration, the convergence rate is another. Accelerating first-order method is a subject of active research, which has been extensively studied. Since Polyak [6] introduced the so-called heavy ball method for minimizing a smooth convex function, much has been done on the development of first-order accelerated methods; see [11,12,13,14,15]. The inertial nature of the first-order accelerated method can be exploited in numerical computations to accelerate the trajectories and speed up the rate of convergence. In the context of algorithms, it is often referred as the inertial extrapolation, which involves two iterative steps and the second iterative step is defined based on the previous two iterates. In [16], Alvarez and Attouch employed the first-order accelerated method to study an initial proximal point algorithm for solving the problem of finding zero of a maximally monotone operator. This iteration can be written as the following form: for any initial data ,
where stands for the identity operator, G is a maximally monotone operator, the parameters , , . It was showed that the iterative sequence generated by (4) converges to a solution of inclusion Problem (1) weakly. An alternative modification to the inertial forward–backward splitting algorithm or its modifications is the following algorithm proposed by Lorenz and Pock [17]. The algorithm weakly converges to a zero of the sum of two maximally monotone operators, with one of two operators being Lipschitz continuous and single valued. Starting with any data , we define a sequence as
where M is a positive definite and linear self-adjoint operator that can be used as a preconditioner for the scheme, is a step-size parameter and is an extrapolation factor. The algorithm keeps the weak convergence property of the iterates. To motivate the so-called the inertial forward–backward splitting algorithm, we consider the following differential equation
where and are operators, is the operator defined by
It comes naturally by discretizing the continuous dynamics (5) explicitly with a time step . Set , and . An explicit finite-difference scheme for (5) with centered second-order variation gives that
where is a point in the line passing through and (we have some flexibility for the choice of ). The above equality (6) can be rewritten as
Set and in (7). With the aid of the classical Nesterov extrapolation choice for , continuous dynamics (5) leads to a special case of the algorithm as
where is a step-size parameter and is an extrapolation factor, the extrapolation term is intended to speed up the rate of convergence. In so doing, this dynamical approach leads to a special case of the forward–backward algorithm of inertial type.
Consider the following monotone variational inequality problem (VIP, in short), which consists of finding such that
where is a monotone operator. We denote the solution set of the variational inequality problem by .
Remark 1.
It is known that x solves the iff x is an equilibrium point of the following dynamical system, i.e.,
where is the nearest point (or metric) projection from H onto Ω.
Variational inequality problems, which serve as a powerful mathematical model, unify several important concepts in applied mathematics, such as systems of nonlinear equations, complementarity problems, and equilibrium problems under a general and unified framework [18,19,20]. Recently, spotlight has been shed on developing efficient and implementable iterative schemes for solving monotone variational inequality problems, see [21,22,23,24]. A significant body of the work on iteration methods for VIPs has accumulated in the literature recently. In 2001, Yamada [25] investigated a so-called hybrid steepest descent method. Given the current iterate , calculate the next iterate via
where the operator is nonexpansive, the operator S is -Lipschitz continuous for some and -strongly monotone (i.e., such that ), while the parameters , , and . In this paper, the set can be regarded as the solution set of the inclusion problem. In continuous case, Attouch and Mainǵe [26] developed a second-order autonomous system with a Tikhonov-like regularizing term , which reads
where and is an arbitrarily given initial data. With the assumptions: (i) is a convex, differentiable operator with strongly monotone and Lipschitz continuous; (ii) is a convex, differentiable operator with Lipschitz continuous; (iii) is a maximally monotone and cocoercive operator; (iv) is a positive and decreasing function of class such that and as , with Lipschitz continuous and bounded, they proved that each trajectory of (10) strongly converges to as , which solves the following variational inequality problem:
In the spirit of the splitting forward–backward method and the hybrid steepest descent method, we present an iterative scheme as a new strategy, parallel to that of the autonomous system (10). We analyze the convergence with the underlying operator B cocoercive and the extension from condition (ii) to the general maximally monotone case, which is considered in Section 3. From this perspective, our study is the natural extension of the convergence results obtained by Attouch and Mainǵe [26] in the case of continuous dynamical systems.
2. Preliminaries
Lemma 1
([25]). Suppose that is Frchet differentiable with being κ-strongly monotone and ι-Lipschitz continuous. Define , where and . Then , where .
Lemma 2
([27]). If is a ρ-cocoercive operator, then
- (i)
- B is a -Lipschitz continuous and monotone operator;
- (ii)
- if ν is any constant in , then is nonexpansive, where stands for the identity operator on H.
Lemma 3.
Let H be a Hilbert space, be a maximally monotone operator and be a κ-cocoercive on H. Then
- (i)
- where t and s are any positive real numbers with
- (ii)
- , .
Proof.
Since A is maximally monotone, one has
□
Lemma 4
([28]). Let S be a nonexpansive mapping defined on a closed convex subset C of a Hilbert space H. Then is demi-closed, i.e., whenever is a sequence in C weakly converging to some and the sequence strongly converges to some , it follows that .
Lemma 5
([29]). Let be a sequence of nonnegative real numbers such that
where and , satisfy the following conditions (i) , ; (ii) ; (iii) , . Then .
Lemma 6
([30]). Let be a sequence of nonnegative real numbers such that there exists a subsequence of such that for all . Then there exists a nondecreasing sequence of such that and the following properties are satisfied by all (sufficiently large) number of , , In fact, is the largest number n in the set such that .
3. Main Results
Throughout this section, we make the following standing assumptions
Assumption 1.
(a) stands for the identity operator. The operator is supposed to be κ-strongly monotone and ι-Lipschitz continuous for some ;
(b) Let be a maximally monotone operator, and be a ρ-cocoercive operator for some , with the solution set .
Our Algorithm 1 is formally designed as follows.
| Algorithm 1: The hybrid forward–backward algorithm |
 |
We make the following assumption with respect to the algorithm parameters.
Assumption 2.
() ; (C) ; (C) ; (C) .
Remark 2.
Please note that the condition (C) of Assumption 2 can be easily implemented since the value of is known before choosing . Indeed, the parameter can be chosen such that
where and is a positive sequence such that .
Now we are in a position to state and prove the main result of this section.
Theorem 1.
Suppose that Assumptions 1, 2 hold. Then for any initial data , the weak sequential cluster point of sequences and generated by Algorithm 1 belongs to the solution set of Problem 3. In addition, the three sequences converge strongly to the unique element of .
Proof.
First, we show that is a contraction operator. According to Lemma 1, we have
where . Thus, we find that is a contraction operator with the constant . In light of the nonexpansivity of , we further obtain that is a contraction operator. From the Banach contraction principle, there exists a unique point such that .
Now, it remains to prove that is bounded. Since is -cocoercive and is firmly nonexpansive, one concludes from Lemma 2 that is nonexpansive. Let be arbitrarily chosen. Invoking Assumption 2 (C), one infers that
which yields
and
From the definition of , one reaches
Invoking Assumption 2 (C), there exists a positive constant such that
From the definition of , which together with (14)–(16), one obtains
where , due to Assumption 2 . This implies that sequence is bounded. At the same time, by putting together (14) and (15), one concludes that and are bounded. Once again, using the definition of , one concludes that
where
By combining (12) with (18), one immediately concludes that
Invoking (20), which together with the definition of , one deduces that
where , due to the boundedness of . Let us rewrite (21) as
By using the firmly nonexpansive property of , one arrives at
which can be equivalently rewritten as
Returning to (14), (18) and (23), one concludes
that is,
Next, we show that converges to zero by considering two possible cases on the sequence .
Case 1. There exists such that . Recalling that is lower bounded, one deduces that exists. Using Assumption 2 (C), and letting n tend to infinity in (22), one finds that
Taking account of Assumption 2 (C), (C), (25), and letting n tend to infinity in (24), one concludes that
It follows from Assumption 2 (C), (C) the definitions of and that
and
Resorting to (26)–(28), one finds that
Denote . It is then immediately that
For any such that , , it implies from Lemma 3 that
Since is a bounded sequence, there exists a subsequence of and a weak sequential cluster point such that as . Due to (26) and (27), one finds that and as . Thus,
From the demiclosedness of and Lemma 4, one obtains that . In view of , one concludes . From the fact that , one sees . As a straightforward consequence, one finds
Coming back to (29), (32) and (33), one has
Returning to (11) and owing to the definitions of and , one finds that
where . Let
and
Furthermore, due to Assumption 2 (C) and the boundedness of , we find that . In so doing, it asserts that
Invoking (32), we infer that
According to Assumption 2 (C), one finds that and . So doing, Lemma 5 asserts that , which further implies that . Coming back to (26) and (27), one concludes that , , converge strongly to a.
Case 2. There exists a subsequence of such that
In this case, it is obvious that there exists a nondecreasing sequence such that as . Lemma 6 asserts that the following inequalities hold,
Thanks to (21) and (36), one finds
By letting n tend to infinity in the above inequality, one infers that . According to (24) and (36), one finds that
Accordingly, one finds that . A calculation similar to the proof in Case 1. guarantees that
and
Invoking (35), one finds
which sends us to
where , and . By applying Assumption 2 (C), which together with (39), we additionally derive that
From , we obtain that . This further implies that converges strongly to a. Furthermore, one has
Recalling that the sequence converges strongly to a, which together with (41), one finds that the sequences and also converge strongly to a. From the above, one can conclude that the sequences generated by Algorithm 1 converge strongly to the unique solution such that . In view of Remark 1, one sees that . Furthermore, the solution of such variational inequality is unique due to the properties of S. This completes the proof. □
If , we obtain the following Algorithm 2 without the inertial extrapolation as a special case of Algorithm 1.
| Algorithm 2: The hybrid forward–backward algorithm without the inertial term |
 |
Recently, much attention has been paid to the relationship between continuous-time systems and neural network models, see [31,32]. One can views an iterative algorithm as a time discretized version of a continuous-time dynamic system. We propose a recurrent neural network to Problem (1). By taking constant parameters, we obtain the following consequence of the dynamical with respect to the time variable t
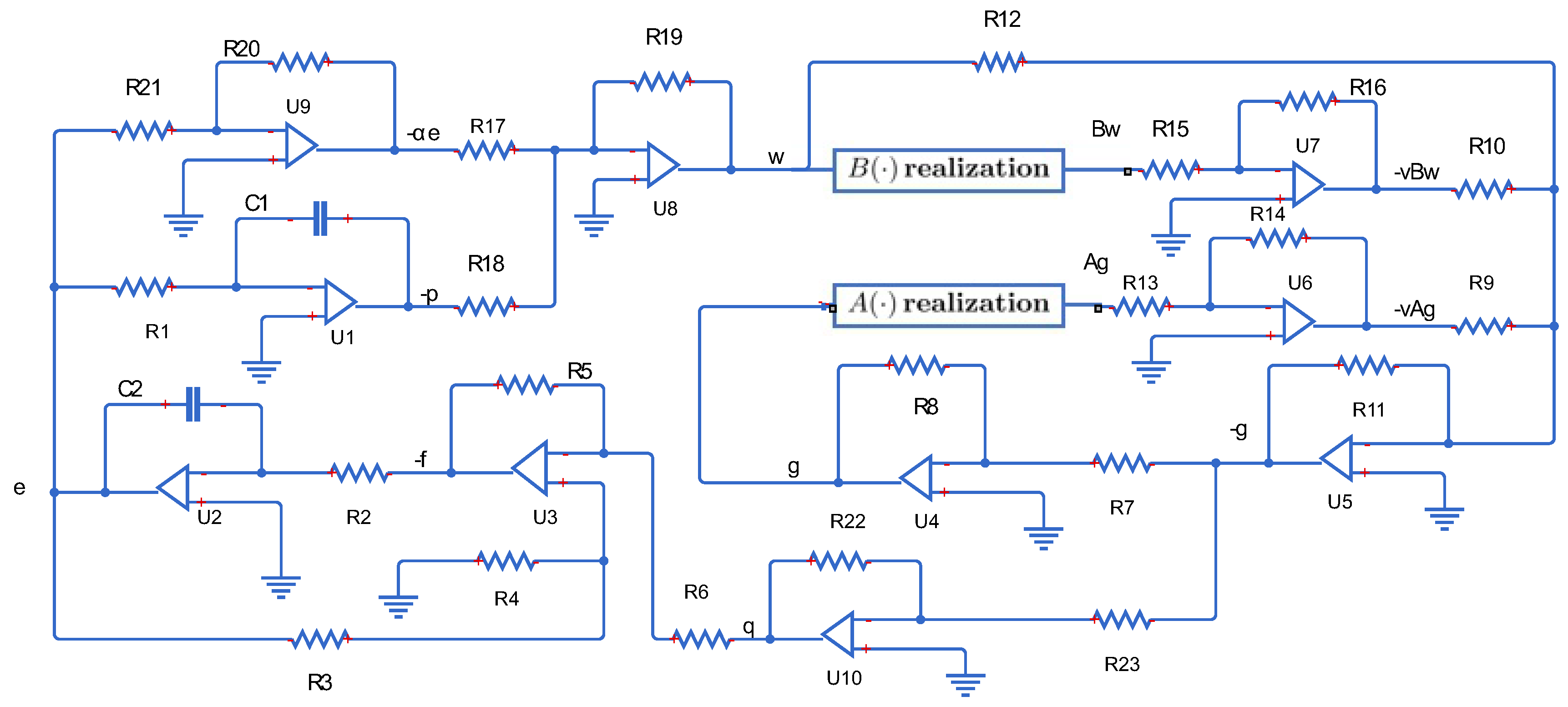
Algorithm 1 is strongly connected with the damped inertial system (42). Indeed, Algorithm 1 comes naturally into play by performing an implicit discretization of the inertial system with respect to the time variable t. Without ambiguity, we omit to write the variable t to get simplified notations. In so doing, p stands for , and so on. By setting and , the circuit architecture diagram of the model (42) is shown in Figure 1.
The operational amplifiers are combined with capacitors , resistors to work as integrators to realize the transformations between . The amplifier cooperated with resistors brings about effectiveness in amplification and opposition. Hence is translated into . The amplifier and resistors are united as the subtractor block to achieve . Also, in the same way, the amplifier and resistors are united as another subtractor block to achieve . One sees that and are obtained, respectively, by “ realization” block and “ realization” block. The amplifier cooperated with resistors brings about effectiveness in amplification and opposition, therefore, is translated into . The amplifier cooperated with resistors brings about effectiveness in amplification and opposition, and hence is translated into . The amplifier and resistors are united as the subtractor block to achieve , that is . On the other hand, is translated into through the phase inverter composed by the operational amplifier and resistors .
4. Numerical Experiment
In this section, we consider a computational experiment to illustrate the convergence properties of the proposed method. The experiment is performed on a PC with Intel (R) Core (TM) i5-8250U CPU @1.60GHz under the MATLAB computing environment.
Digital signal reconstruction is one of the earliest and most classical problem in the file restoration, the video and image coding, the medical, the astronomical imaging and some other applications. Many problems in signal processing can be formulated as inverting the linear system, which are modeled as
where is the original signal to be reconstructed, is the noise, is the noisy measurement, is a bounded linear observation operator, often ill conditioned because it models a process with loss of information.
In our experiment, we consider a general compressed sensing scenario, where the goal is to reconstruct an i-length sparse signal x with exactly k nonzero components from j observations, i.e., the number of measurements is much larger than the sparsity level of x and at the same time smaller than the number of the signal length. Considering the storage limitation of the PC, we test a small size signal with and the original signal contains randomly nonzero elements. We reconstruct this signal from observations. More precisely, the observation , where is the Gaussian matrix whose elements are randomly obtained from the standard normal distribution and is the Gaussian noise distributed as with .
A classical and significant approach to the problems of the signal processing is the regularization method, which has attracted a considerable amount of attention and revived much interest in the compressed sensing literature. We restrict our attention to the -regularized least squares model (43). Lasso framework is a particular instant of the linear problems of type (43) with the non-smooth -norm as a regularizer, in which minimizes a squared loss function, and seeks to find the sparse solutions of
where the regularization parameter provides a tradeoff between the noise sensitivity and the fidelity to the measurements. One knows that Problem (44) always has a solution. However, it needs not to be unique. Please note that the optimal solution tends to zero as . As , the limiting point has the minimum norm among all points that satisfy , i.e., . Since the objective function of Problem (44) is convex but not differentiable, one uses a first-order optimality condition based on the subdifferential calculus. For , one can obtain the necessary and sufficient condition for the optimal solution as follows
From above, one sees that the optimal solution of Problem (44) is 0, for , (), i.e., . Thus, one can now derive the formula For -regularized least squares; however, the convergence occurs for a finite value of . To avoid the optimal sparse solution is a zero vector, in this experiment, the regularization parameter was denoted by , where the value of is computed by the above formula.
The proximal methods give a better modeling of the sparsity structure in the dataset. The major step in proximal methods is to find a solution of with respect to the function g and the parameter . On the other hand, the proximity operator is defined as the resolvent operator of the subgradient . Furthermore, the proximity operator for -norm is described as the shrinkage operator, which is defined as . Now one considers the deblurring Problem (43) via the definition of the iterative shrinkage algorithm. Resorting to and , one can see that Problem (44) is a special instance of the problem
Under the class of regularized loss minimization problems, the function g is considered to be a non-smooth regularization function and the function f is viewed as a smooth loss function with gradient being -cocoercive. Furthermore,
One solves the deblurring problem by using the definition of the iterative shrinkage algorithm. Setting , and in Algorithm 1, one can obtain the proximal gradient type algorithm given as follows
where . Meanwhile, we set , and , where . Next, we randomly choose the starting signal in the range of and take the number of iterations as the stopping criterion.
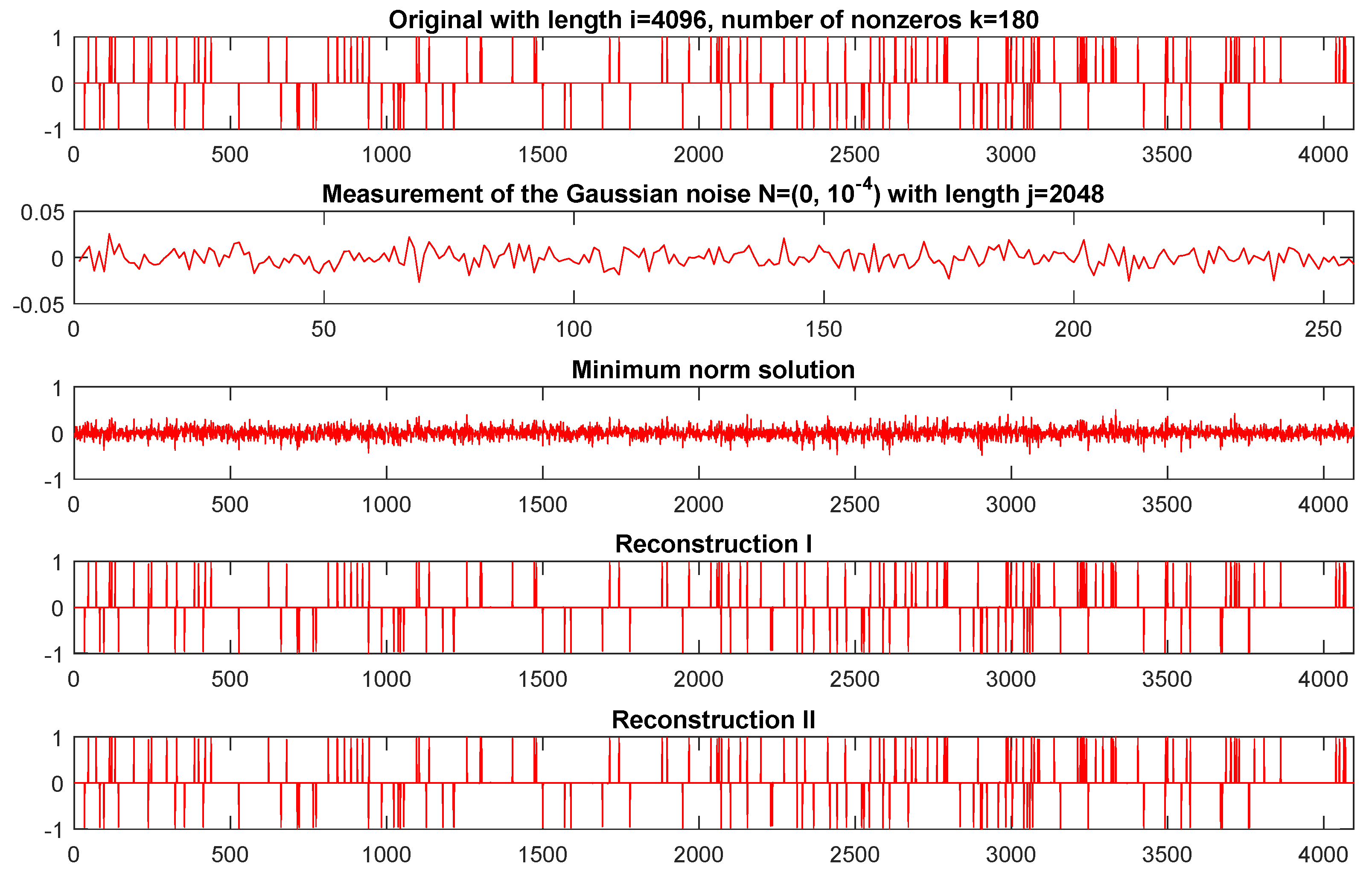
In this experiment, the minimum norm solution is the point in the set , which is closest to the original sparse signal. Thus, we can see that the result of this experiment for a signal sparse reconstruction is showed in Figure 2. By comparing the last two plots in Figure 2 and the top plot in Figure 2, one finds that the original sparse signal is recovered almost exactly. We hence conclude that our algorithm is efficient for dealing with the signal deblurring problem.
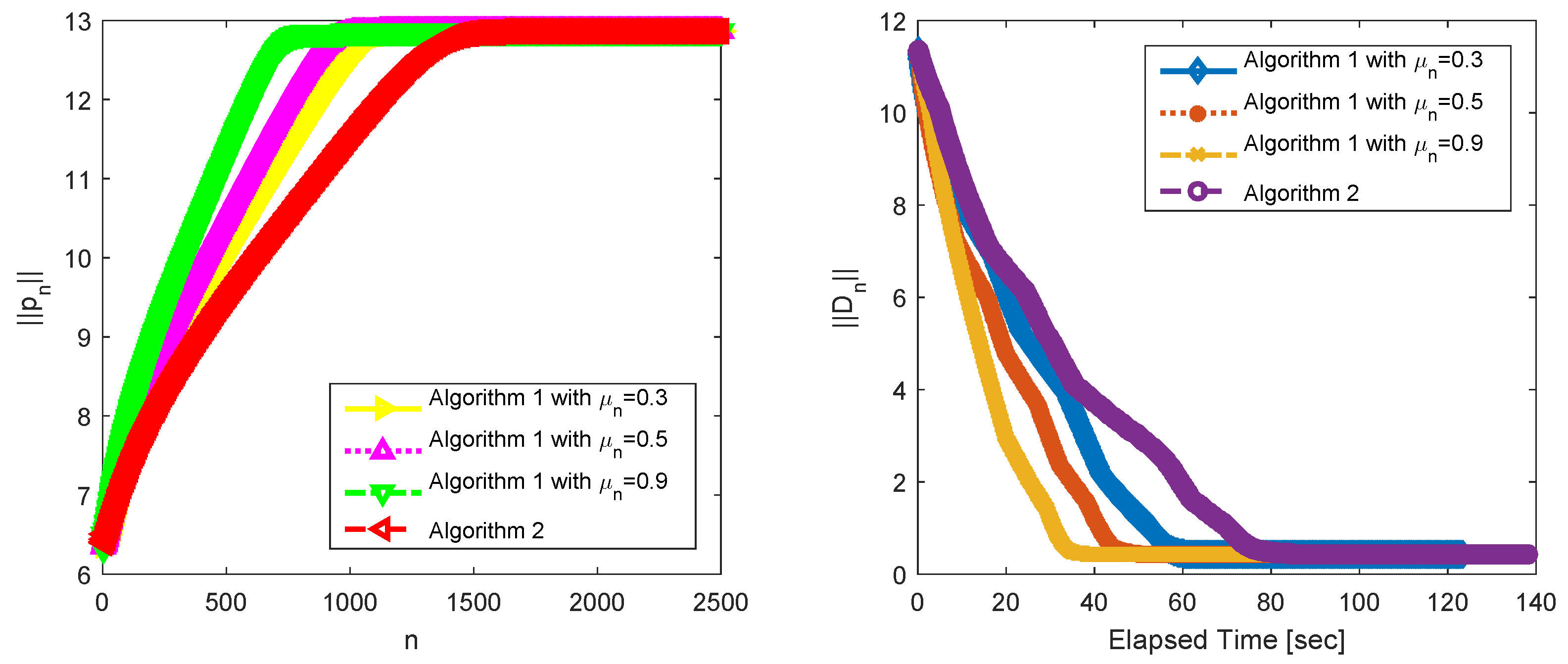
To illustrate that Algorithm 1 has a competitive performance compared with Algorithm 2, we describe the following numerical results shown in Figure 3.
The left plot in Figure 3 shows that the behaviors of the term (the y-axis) with respect to the number of iterations (x-axis), where is generated by Algorithms 1 and 2. It can be observed from the test result reported in Figure 3 that converges to . Thus, we can use to study the convergence and the computational performance of Algorithms 1 and 2. We denote , where x is the original signal to be reconstructed, and is an estimated signal of x. The right plot in Figure 3 shows that the value of (the y-axis) when the execution time in second elapses (x-axis). The sequence converges to with the running time. The restoration accuracy can be measured by means of the mean squared error. We find that the mean squared error converges to , which further implies that the iterative sequence converges to the original signal x in this experiment.
We make a comparison of the behaviors of , generated respectively by Algorithms 1 and 2. It shows that the bigger is, the fewer the required number of iterations becomes, the faster the convergence rate becomes. Furthermore, we find that all cases in Algorithm 1 need less computer time and enjoy a faster rate of the convergence than Algorithm 2. It can be observed from the plots that the changing process in all cases of Algorithm 1 outperforms Algorithm 2. The inertial extrapolation of Algorithm 1 plays a key role in the acceleration. For judiciously chosen, this inertial term improves the convergence speed of this algorithm.
5. Conclusions
In this paper, we introduced a variational inequality problem over the zero solution set of the inclusion problems. Since this problem has a double structure, it can be considered as a double-hierarchical optimization problem. The proposed algorithm uses the extrapolation term , which can be viewed as the procedure of speeding up the rate of convergence. As an application, the algorithm was used to solve the signal deblurring problem to support our convergence result.
Author Contributions
Conceptualization, L.L., X.Q. and J.-C.Y.; methodology, L.L., X.Q. and J.-C.Y.; data curation, L.L., X.Q. and J.-C.Y.; visualization, L.L.; supervision, X.Q. and J.-C.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Moudafi, A. Split monotone variational inclusions. J. Optim. Theory Appl. 2011, 150, 275–283. [Google Scholar] [CrossRef]
- Iiduka, H. Two stochastic optimization algorithms for convex optimization with fixed point constraints. Optim. Methods Softw. 2019, 34, 731–757. [Google Scholar] [CrossRef] [Green Version]
- Ansari, Q.H.; Bao, T.Q. A limiting subdifferential version of Ekeland’s variational principle in set optimization. Optim. Lett. 2019, 1–5. [Google Scholar] [CrossRef]
- Al-Homidan, S.; Ansari, Q.H.; Kassay, G. Vectorial form of Ekeland variational principle with applications to vector equilibrium problems. Optimization 2020, 69, 415–436. [Google Scholar] [CrossRef]
- Li, X.; Huang, N.; Ansari, Q.H.; Yao, J.C. Convergence rate of descent method with new inexact line-search on Riemannian manifolds. J. Optim. Theory Appl. 2019, 180, 830–854. [Google Scholar] [CrossRef]
- Polyak, B.T. Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Rockafellar, R.T. Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 1976, 14, 877–898. [Google Scholar] [CrossRef] [Green Version]
- Moreau, J.J. Proximité et dualité dans un espace hilbertien. Bull. De La Société Mathématique De Fr. 1965, 93, 273–299. [Google Scholar] [CrossRef]
- Bruck, R.E.; Reich, S. Nonexpansive projections and resolvents of accretive operators in Banach spaces. Houst. J. Math. 1977, 3, 459–470. [Google Scholar]
- Lions, P.L.; Mercier, B. Splitting algorithms for the sum of two nonlinear operators. SIAM J. Numer. Anal. 1979, 16, 964–979. [Google Scholar] [CrossRef]
- Cho, S.Y.; Kang, S.M. Approximation of fixed points of pseudocontraction semigroups based on a viscosity iterative process. Appl. Math. Lett. 2011, 24, 224–228. [Google Scholar] [CrossRef]
- Bot, R.I.; Csetnek, E.R. Second order forward-backward dynamical systems for monotone inclusion problems. SIAM J. Control Optim. 2016, 54, 1423–1443. [Google Scholar] [CrossRef]
- Cho, S.Y.; Kang, S.M. Approximation of common solutions of variational inequalities via strict pseudocontractions. Acta Math. Sci. 2012, 32, 1607–1618. [Google Scholar] [CrossRef]
- Cho, S.Y.; Li, W.; Kang, S.M. Convergence analysis of an iterative algorithm for monotone operators. J. Inequal. Appl. 2013, 2013, 199. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Shang, M.; Tan, B. A general inertial viscosity type method for nonexpansive mappings and its applications in signal processing. Mathematics 2020, 8, 288. [Google Scholar] [CrossRef] [Green Version]
- Alvarez, F.; Attouch, H. An inertial proximal method for maximal monotone operators via discretization of a nonlinear oscillator with damping. Set-Valued Anal. 2001, 9, 3–11. [Google Scholar] [CrossRef]
- Lorenz, D.A.; Pock, T. An inertial forward-backward algorithm for monotone inclusions. J. Math. Imaging Vis. 2015, 51, 311–325. [Google Scholar] [CrossRef] [Green Version]
- He, S.; Liu, L.; Xu, H.K. Optimal selections of stepsizes and blocks for the block-iterative ART. Appl. Anal. 2019, 1–14. [Google Scholar] [CrossRef]
- Cho, S.Y. Generalized mixed equilibrium and fixed point problems in a Banach space. J. Nonlinear Sci. Appl. 2016, 9, 1083–1092. [Google Scholar] [CrossRef] [Green Version]
- Liu, L. A hybrid steepest descent method for solving split feasibility problems involving nonexpansive mappings. J. Nonlinear Convex Anal. 2019, 20, 471–488. [Google Scholar]
- Kassay, G.; Reich, S.; Sabach, S. Iterative methods for solving systems of variational inequalities in reflexive Banach spaces. SIAM J. Optim. 2011, 21, 1319–1344. [Google Scholar] [CrossRef]
- Censor, Y.; Gibali, A.; Reich, S.; Sabach, S. Common solutions to variational inequalities. Set-Valued Var. Anal. 2012, 20, 229–247. [Google Scholar] [CrossRef]
- Gibali, A.; Liu, L.W.; Tang, Y.C. Note on the modified relaxation CQ algorithm for the split feasibility problem. Optim. Lett. 2018, 12, 817–830. [Google Scholar] [CrossRef]
- Cho, S.Y. Strong convergence analysis of a hybrid algorithm for nonlinear operators in a Banach space. J. Appl. Anal. Comput. 2018, 8, 19–31. [Google Scholar]
- Yamada, I. The hybrid steepest descent method for the variational inequality problem over the intersection of fixed point sets of nonexpansive mappings. Inherently Parallel Algorithms Feasibility Optim. Their Appl. 2001, 8, 473–504. [Google Scholar]
- Attouch, H.; Maingé, P.E. Asymptotic behavior of second-order dissipative evolution equations combining potential with non-potential effects. ESAIM Control Optim. Calc. Var. 2011, 17, 836–857. [Google Scholar] [CrossRef] [Green Version]
- Iiduka, H.; Takahashi, W. Strong convergence theorems for nonexpansive mappings and inverse-strongly monotone mappings. Nonlinear Anal. 2005, 61, 341–350. [Google Scholar] [CrossRef]
- Opial, Z. Weak convergence of the sequence of successive approximations for nonexpansive mappings. Bull. Am. Math. Soc. 1967, 73, 591–597. [Google Scholar] [CrossRef] [Green Version]
- Maingé, P.E. Inertial iterative process for fixed points of certain quasi-nonexpansive mappings. Set-Valued Anal. 2007, 15, 67–79. [Google Scholar] [CrossRef]
- Maingé, P.E. The viscosity approximation process for quasi-nonexpansive mappings in Hilbert spaces. Comput. Math. Appl. 2010, 59, 74–79. [Google Scholar] [CrossRef] [Green Version]
- Peypouquet, J.; Sorin, S. Evolution equations for maximal monotone operators: Asymptotic analysis in continuous and discrete time. arXiv 2009, arXiv:0905.1270. [Google Scholar]
- He, X.; Huang, T.; Yu, J.; Li, C.; Li, C. An inertial projection neural network for solving variational inequalities. IEEE Trans. Cybern. 2016, 47, 809–814. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Circuit architecture diagram of model (42), where , , , , .

Figure 2.
From top to bottom: the original signal, the noisy measurement, the minimum norm solution, the reconstruction signals respectively by Algorithm 1 () and Algorithm 2 .
Figure 2.
From top to bottom: the original signal, the noisy measurement, the minimum norm solution, the reconstruction signals respectively by Algorithm 1 () and Algorithm 2 .

Figure 3.
The behavior of with the number of iterations (left), the behavior of with the running time (right). The number of iterations is 2000. The first CPU time to compute is about s; the second CPU time to compute is about s; the third CPU time to compute is about s; the fourth CPU time to compute is about s (from top to bottom in legend).
Figure 3.
The behavior of with the number of iterations (left), the behavior of with the running time (right). The number of iterations is 2000. The first CPU time to compute is about s; the second CPU time to compute is about s; the third CPU time to compute is about s; the fourth CPU time to compute is about s (from top to bottom in legend).

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, L.; Qin, X.; Yao, J.-C. A Hybrid Forward–Backward Algorithm and Its Optimization Application. Mathematics 2020, 8, 447. https://0-doi-org.brum.beds.ac.uk/10.3390/math8030447
AMA Style
Liu L, Qin X, Yao J-C. A Hybrid Forward–Backward Algorithm and Its Optimization Application. Mathematics. 2020; 8(3):447. https://0-doi-org.brum.beds.ac.uk/10.3390/math8030447
Chicago/Turabian StyleLiu, Liya, Xiaolong Qin, and Jen-Chih Yao. 2020. "A Hybrid Forward–Backward Algorithm and Its Optimization Application" Mathematics 8, no. 3: 447. https://0-doi-org.brum.beds.ac.uk/10.3390/math8030447
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.