Analysis of the Parametric Correlation in Mathematical Modeling of In Vitro Glioblastoma Evolution Using Copulas

 ,
,  , ,
, ,  ,
,  and
and 
Abstract
:1. Introduction
2. Rationale of the Approach
2.1. Deterministic and Stochastic Models
- (an m-dimensional vector) the output variable, that is, the outcome of the experiments, that we measure.
- the variables which we can control when performing the experiments (such as environmental variables, geometric parameters, or boundary conditions).
- the model parameters, that we cannot control and whose values must be determined (, with the parametric space of dimension n).
- the mathematical model, that relates the experimental configuration with the output variables in terms of the set of parameters .
- Many coupled phenomena are present, being difficult to design experiments able to isolate each of them (complexity).
- The measurement space is large and it is possible to perform a sufficiently big number of experiments N (data availability).
- The model includes many parameters () and/or is non-separable.The separability of a model is evaluated by the possibility of approximating as:The lower M, the easier to define a set of different experimental configurations to isolate each of the parameters by solving separately each equation . Although this separability definition is not very rigorous, it is enlightening enough for our purposes.
- The dimension of the measurement space is high () and/or the sample size is large enough (). Without loss of generality, we consider that m is, actually, the reduced dimensionality of the space or in other words that all variables of the ambient space are independent.
2.2. Case Study: In Vitro GBM Evolution
- Samples variability: Different physical phenomena may have an inherent correlation supported by physical considerations, being this correlation independent of the experiments performed or the model used. For example, when working with GBM cellular models, cell motility is induced by the random motion inherent to any cell and several taxis effects driven by external physical or chemical stimuli. Mathematical parameters related to these phenomena (e.g., diffusion and chemotaxis coefficients) appearing in the model equations will present, therefore, a strong correlation in the different experimental samples.
- Model complexity: The non-separability of the model and/or the experiments does not allow to isolate the particular mechanisms. For example, when working with GBM cellular models, without further measurements of cell oxygen consumption or oxygen flux, it is impossible to establish if a lack of oxygen in a certain region is due to high cell consumption or due to low oxygen diffusion. The mathematical parameters related to these phenomena (e.g., oxygen diffusion and cell oxygen consumption coefficients) should present a strong correlation, although this correlation does not have a physical meaning, being inherent to the model or to the experimental set-up.
3. Methods
3.1. Data Generation and Numerical Solution
3.2. Copula-Based Parametric Model Analysis
3.2.1. Concept of Copulas
- For , and if for some :
- For :
- C is n-non decreasing, that is, for each , the C-volume of B is non-negative:
3.2.2. Fitting and Model Validation
- Problem minimization to obtain . We have to minimize the residual function :where the Mahalanobis distance has been used to take into account the sample variability. Assuming that , Equation (18) can be rewritten as:
- Kernel density estimation of the marginal distributions from the data .
- Transformation into uniformly distributed values .
- Copula fitting of the data to capture the joint dependence.
- Problem minimization to obtain .
- Testing the statistical fitting:
- Marginal fitting: q-q plots, histograms, empirical cumulative distribution functions (ecdf), boxplots, parametric or non-parametric statistical tests [42].
- Joint 2 vs. 2 correlations: correlations, scatterplots, parametric statistical tests for correlations [42].
- Whole joint structural dependence: multivariate parametric and non-parametric statistical tests [43].
3.2.3. Model Analysis and Parameter Estimation
3.2.4. Design of Experiments
4. Results
4.1. Copula Fitting
4.1.1. Marginal Distributions
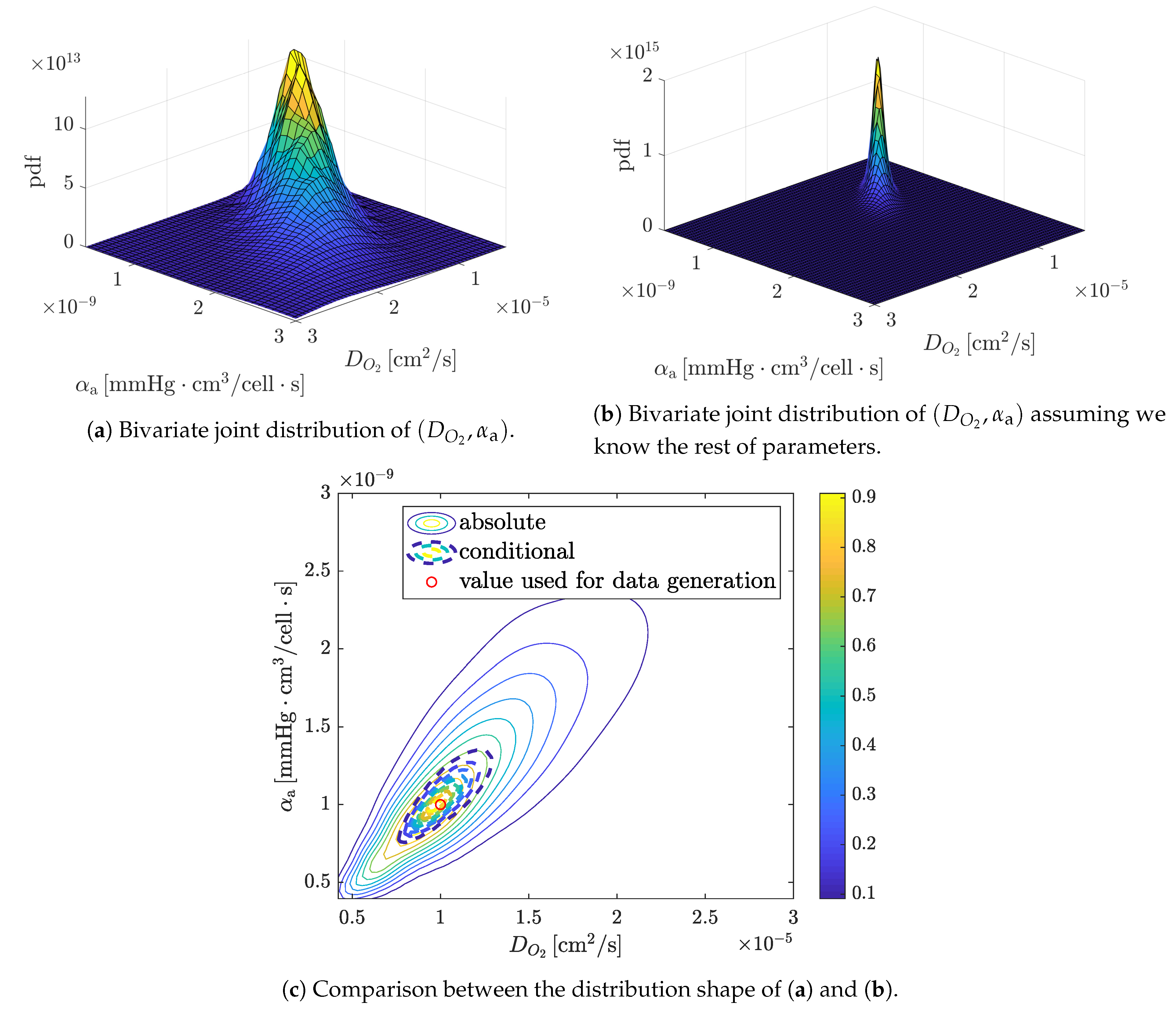
4.1.2. Parametric Copula Structure
4.1.3. Complete Probabilistic Model and Bayesian a Posteriori Corrections
4.2. Validation of the Results Using Test Data
4.2.1. Marginal Distributions
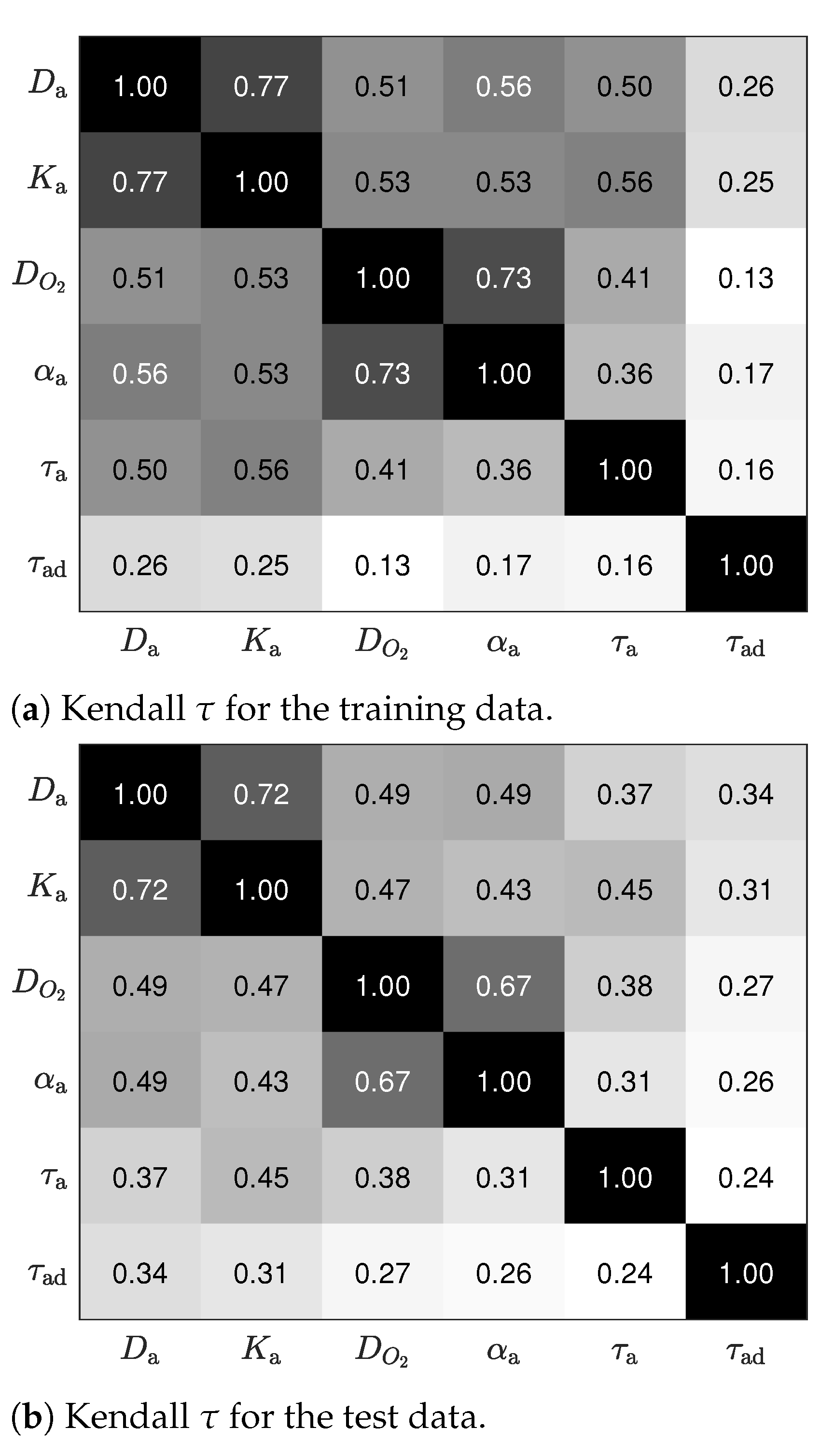
4.2.2. Joint Dependencies
4.3. Parameter Estimation
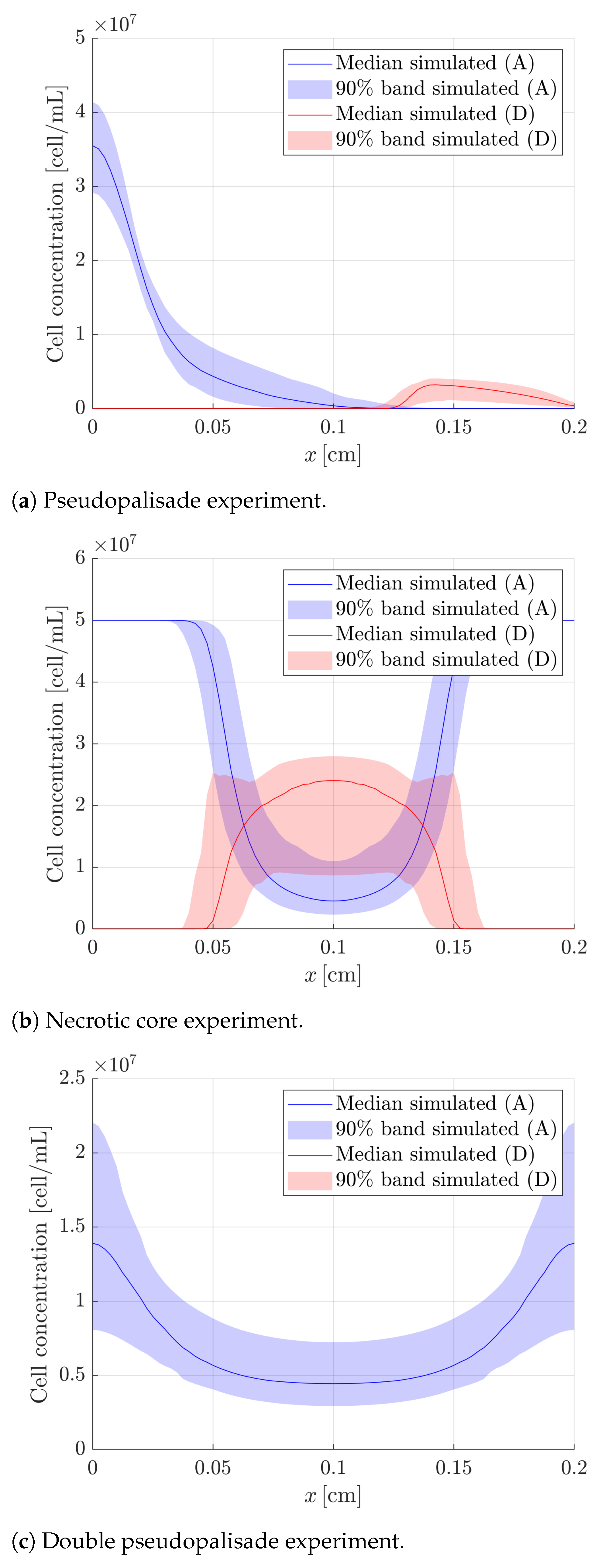
4.4. Estimation of the Output Variables
4.5. Design of Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Quail, D.F.; Joyce, J.A. Microenvironmental regulation of tumor progression and metastasis. Nat. Med. 2013, 19, 1423. [Google Scholar] [CrossRef] [PubMed]
- Hanahan, D.; Weinberg, R.A. Hallmarks of cancer: The next generation. Cell 2011, 144, 646–674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scannell, J.W.; Blanckley, A.; Boldon, H.; Warrington, B. Diagnosing the decline in pharmaceutical R & D efficiency. Nat. Rev. Drug Discov. 2012, 11, 191. [Google Scholar] [PubMed]
- Sackmann, E.K.; Fulton, A.L.; Beebe, D.J. The present and future role of microfluidics in biomedical research. Nature 2014, 507, 181. [Google Scholar] [CrossRef] [PubMed]
- Bhatia, S.N.; Ingber, D.E. Microfluidic organs-on-chips. Nat. Biotechnol. 2014, 32, 760. [Google Scholar] [CrossRef] [PubMed]
- Boussommier-Calleja, A.; Li, R.; Chen, M.B.; Wong, S.C.; Kamm, R.D. Microfluidics: A new tool for modeling cancer–immune interactions. Trends Cancer 2016, 2, 6–19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zervantonakis, I.K.; Hughes-Alford, S.K.; Charest, J.L.; Condeelis, J.S.; Gertler, F.B.; Kamm, R.D. Three-dimensional microfluidic model for tumor cell intravasation and endothelial barrier function. Proc. Natl. Acad. Sci. USA 2012, 109, 13515–13520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Byrne, H.; Alarcon, T.; Owen, M.; Webb, S.; Maini, P. Modelling aspects of cancer dynamics: A review. Philos. Trans. R. Soc. Lond. A Math. Phys. Eng. Sci. 2006, 364, 1563–1578. [Google Scholar] [CrossRef] [Green Version]
- Kitano, H. Computational systems biology. Nature 2002, 420, 206. [Google Scholar] [CrossRef]
- Bearer, E.L.; Lowengrub, J.S.; Frieboes, H.B.; Chuang, Y.L.; Jin, F.; Wise, S.M.; Ferrari, M.; Agus, D.B.; Cristini, V. Multiparameter computational modeling of tumor invasion. Cancer Res. 2009, 69, 4493–4501. [Google Scholar] [CrossRef] [Green Version]
- Ayensa-Jiménez, J.; Pérez-Aliacar, M.; Randelovic, T.; Oliván, S.; Fernández, L.; Sanz-Herrera, J.A.; Ochoa, I.; Doweidar, M.H.; Doblaré, M. Mathematical formulation and parametric analysis of in vitro cell models in microfluidic devices: Application to different stages of glioblastoma evolution. Sci. Rep. 2020, 10, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Brat, D.J. Glioblastoma: Biology, genetics, and behavior. In American Society of Clinical Oncology Educational Book; American Society of Clinical Oncology: Alexandria, VA, USA, 2012; pp. 102–107. [Google Scholar] [CrossRef]
- Ang, A.; Chen, J. Asymmetric correlations of equity portfolios. J. Financ. Econ. 2002, 63, 443–494. [Google Scholar] [CrossRef]
- Boubaker, H.; Sghaier, N. Portfolio optimization in the presence of dependent financial returns with long memory: A copula based approach. J. Bank. Financ. 2013, 37, 361–377. [Google Scholar] [CrossRef]
- McNeil, A.; Frey, R.; Embrechts, P. Quantitative Risk Management: Concepts, Techniques, and Tools; Princeton University Press: Princeton, NJ, USA, 2017. [Google Scholar]
- Kole, E.; Koedijk, K.; Verbeek, M. Selecting copulas for risk management. J. Bank. Financ. 2007, 31, 2405–2423. [Google Scholar] [CrossRef] [Green Version]
- Meucci, A. A new breed of copulas for risk and portfolio management. Risk 2011, 24, 122–126. [Google Scholar]
- Solari, S.; Losada, M. Non-stationary wave height climate modeling and simulation. J. Geophys. Res. Ocean. 2011, 116. [Google Scholar] [CrossRef]
- Munkhammar, J.; Widén, J. An autocorrelation-based copula model for generating realistic clear-sky index time-series. Sol. Energy 2017, 158, 9–19. [Google Scholar] [CrossRef]
- Arya, F.K.; Zhang, L. Copula-based Markov process for forecasting and analyzing risk of water quality time series. J. Hydrol. Eng. 2017, 22, 04017005. [Google Scholar] [CrossRef]
- Laux, P.; Wagner, S.; Wagner, A.; Jacobeit, J.; Bardossy, A.; Kunstmann, H. Modelling daily precipitation features in the Volta Basin of West Africa. Int. J. Climatol. A J. R. Meteorol. Soc. 2009, 29, 937–954. [Google Scholar] [CrossRef] [Green Version]
- Schoelzel, C.; Friederichs, P. Multivariate non-normally distributed random variables in climate research–introduction to the copula approach. Nonlinear Process. Geophys. 2008, 15, 761–772. [Google Scholar] [CrossRef] [Green Version]
- Laux, P.; Vogl, S.; Qiu, W.; Knoche, H.R.; Kunstmann, H. Copula-based statistical refinement of precipitation in RCM simulations over complex terrain. Hydrol. Earth Syst. Sci. 2011, 15, 2401–2419. [Google Scholar] [CrossRef] [Green Version]
- Zou, Y.; Zhang, Y. A copula-based approach to accommodate the dependence among microscopic traffic variables. Transp. Res. Part C Emerg. Technol. 2016, 70, 53–68. [Google Scholar] [CrossRef]
- Spissu, E.; Pinjari, A.R.; Pendyala, R.M.; Bhat, C.R. A copula-based joint multinomial discrete–continuous model of vehicle type choice and miles of travel. Transportation 2009, 36, 403–422. [Google Scholar] [CrossRef]
- Kilgore, R.T.; Thompson, D.B. Estimating joint flow probabilities at stream confluences by using copulas. Transp. Res. Rec. 2011, 2262, 200–206. [Google Scholar] [CrossRef]
- Bartoli, G.; Mannini, C.; Massai, T. Quasi-static combination of wind loads: A copula-based approach. J. Wind Eng. Ind. Aerodyn. 2011, 99, 672–681. [Google Scholar] [CrossRef]
- Dong, S.; Zhou, C.; Tao, S.S.; Xue, D.S. Bivariate Gumbel distribution based on Clayton Copula and its application in offshore platform design. Period. Ocean Univ. China 2011, 41, 117–120. [Google Scholar]
- Pham, H. Recent studies in software reliability engineering. In Handbook of Reliability Engineering; Springer: London, UK, 2003; pp. 285–302. [Google Scholar]
- Kim, J.M.; Jung, Y.S.; Sungur, E.A.; Han, K.H.; Park, C.; Sohn, I. A copula method for modeling directional dependence of genes. BMC Bioinform. 2008, 9, 225. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.; Jeon, H.; Othmer, H. The role of the tumor microenvironment in glioblastoma: A mathematical model. IEEE Trans. Biomed. Eng. 2017, 64, 519–527. [Google Scholar] [CrossRef] [Green Version]
- Ayuso, J.M.; Monge, R.; Martínez-González, A.; Virumbrales-Muñoz, M.; Llamazares, G.A.; Berganzo, J.; Hernández-Laín, A.; Santolaria, J.; Doblaré, M.; Hubert, C.; et al. Glioblastoma on a microfluidic chip: Generating pseudopalisades and enhancing aggressiveness through blood vessel obstruction events. Neuro-Oncology 2017, 19, 503–513. [Google Scholar] [CrossRef] [Green Version]
- Ayuso, J.M.; Virumbrales-Muñoz, M.; Lacueva, A.; Lanuza, P.M.; Checa-Chavarria, E.; Botella, P.; Fernández, E.; Doblare, M.; Allison, S.J.; Phillips, R.M.; et al. Development and characterization of a microfluidic model of the tumour microenvironment. Sci. Rep. 2016, 6, 36086. [Google Scholar] [CrossRef]
- Hatzikirou, H.; Basanta, D.; Simon, M.; Schaller, K.; Deutsch, A. ‘Go or grow’: The key to the emergence of invasion in tumour progression? Math. Med. Biol. A J. IMA 2012, 29, 49–65. [Google Scholar] [CrossRef] [PubMed]
- Stramer, B.; Mayor, R. Mechanisms and in vivo functions of contact inhibition of locomotion. Nat. Rev. Mol. Cell Biol. 2017, 18, 43. [Google Scholar] [CrossRef] [PubMed]
- Galluzzi, L.; Vitale, I.; Aaronson, S.A.; Abrams, J.M.; Adam, D.; Agostinis, P.; Alnemri, E.S.; Altucci, L.; Amelio, I.; Andrews, D.W.; et al. Molecular mechanisms of cell death: Recommendations of the Nomenclature Committee on Cell Death 2018. Cell Death Differ. 2018, 25, 486. [Google Scholar] [CrossRef] [PubMed]
- Sendoel, A.; Hengartner, M.O. Apoptotic cell death under hypoxia. Physiology 2014, 29, 168–176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chance, B.; Williams, G.R. The respiratory chain and oxidative phosphorylation. Adv. Enzymol. Relat. Areas Mol. Biol. 1956, 17, 65–134. [Google Scholar]
- Jaworski, P.; Durante, F.; Härdle, W.K.; Rychlik, T. Copula Theory and Its Applications: Proceedings of the Workshop Held in Warsaw, Poland, 25–26 September 2009; Springer: Berlin/Heidelberg, Germany, 2010; Volume 198. [Google Scholar]
- Sklar, M. Fonctions de repartition an dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Wand, M.P.; Jones, M.C. Kernel Smoothing; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Kottegoda, N.T.; Rosso, R. Applied Statistics for Civil and Environmental Engineers; Blackwell Malden: Malden, MA, USA, 2008. [Google Scholar]
- Fan, Y. Goodness-of-fit tests for a multivariate distribution by the empirical characteristic function. J. Multivar. Anal. 1997, 62, 36–63. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J. Computing and graphing highest density regions. Am. Stat. 1996, 50, 120–126. [Google Scholar]
- Fisher, R.A. The Design of Experiments; Oliver and Boyd: Edinburgh/London, UK, 1937. [Google Scholar]
- Chaloner, K.; Verdinelli, I. Bayesian Experimental Design: A Review. Stat. Sci. 1995, 10, 273–304. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, N.A.; Gokhale, D. Entropy expressions and their estimators for multivariate distributions. IEEE Trans. Inf. Theory 1989, 35, 688–692. [Google Scholar] [CrossRef]
- Demarta, S.; McNeil, A.J. The t copula and related copulas. Int. Stat. Rev. 2005, 73, 111–129. [Google Scholar] [CrossRef]










{kind=link}
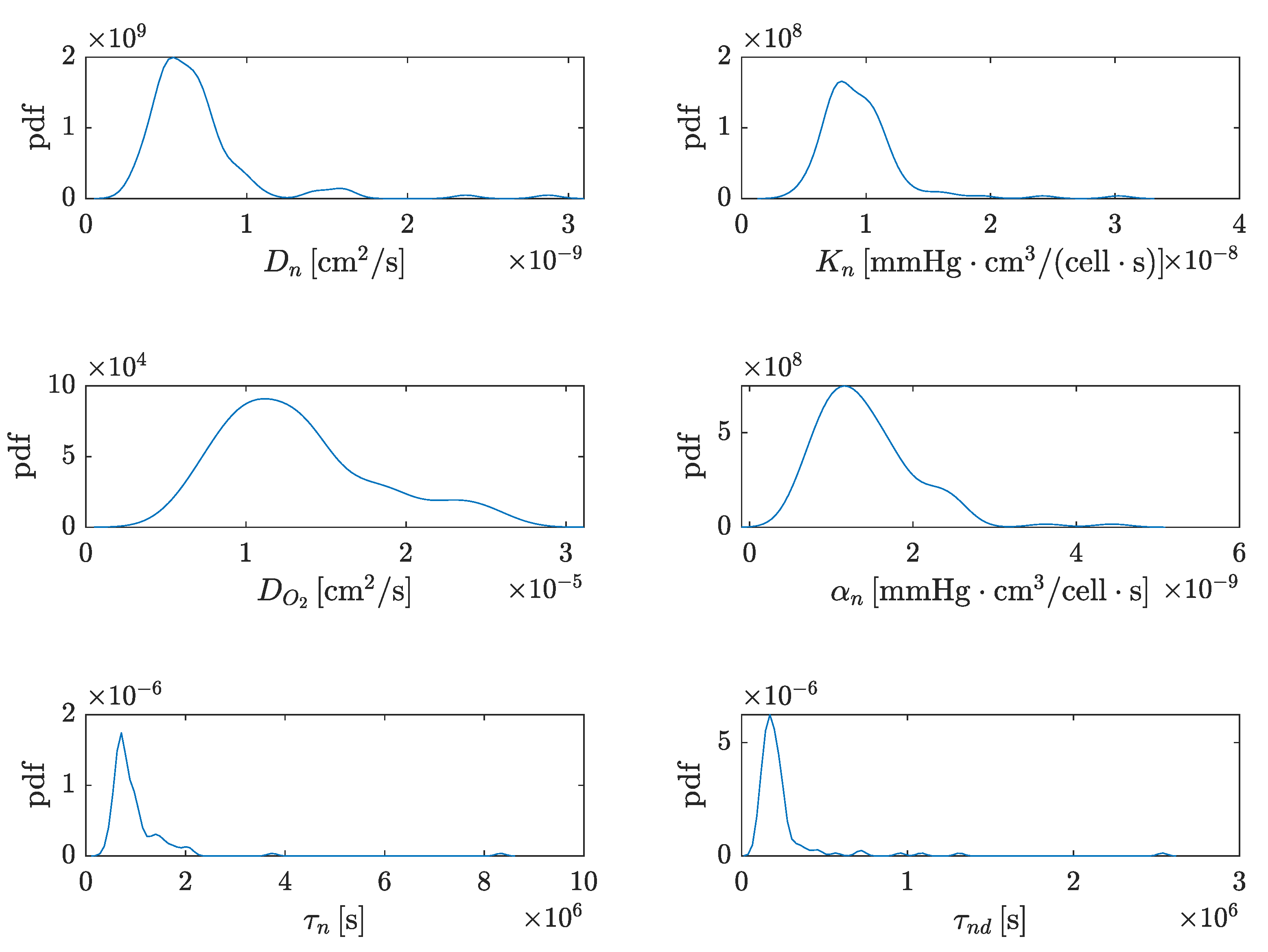{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Symbol | Value Used for Data Generation [11] |
|---|---|---|
| Normoxic cell diffusion coefficient | ||
| Normoxic cell chemotaxis coefficient | ||
| Oxygen diffusion coefficient | ||
| Oxygen consumption coefficient | ||
| Growth characteristic time | ||
| Death characteristic time | ||
| Hypoxia activation threshold | ||
| Growth saturation capacity | ||
| Anoxia activation location parameter | ||
| Anoxia activation spread parameter | ||
| Michaelis-Menten constant |
| Parameter | Lower Bound | Upper Bound | Units |
|---|---|---|---|
| 8 | 3000 | ||
| 24 | 917 |
| Parameters to Be Estimated | Known Parameters | Figure |
|---|---|---|
| None | - | |
| , , , | - | |
| , , , , | Figure 9a | |
| None | - | |
| , , , | - | |
| , , , , | Figure 9b | |
| , | None | - |
| , | , , , | Figure 9c |
| Parameters to Be Estimated | Upper Concentration [mmHg] | Lower Concentration [mmHg] | Maximum Utility Value |
|---|---|---|---|
| 7 | 0 | ||
| 5 | 2 | ||
| 5 | 1 | ||
| 7 | 0 | ||
| 7 | 0 | ||
| 7 | 0 | ||
| 8 | 0 | ||
| 7 | 1 | ||
| 8 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayensa-Jiménez, J.; Pérez-Aliacar, M.; Randelovic, T.; Sanz-Herrera, J.A.; Doweidar, M.H.; Doblaré, M. Analysis of the Parametric Correlation in Mathematical Modeling of In Vitro Glioblastoma Evolution Using Copulas. Mathematics 2021, 9, 27. https://0-doi-org.brum.beds.ac.uk/10.3390/math9010027
Ayensa-Jiménez J, Pérez-Aliacar M, Randelovic T, Sanz-Herrera JA, Doweidar MH, Doblaré M. Analysis of the Parametric Correlation in Mathematical Modeling of In Vitro Glioblastoma Evolution Using Copulas. Mathematics. 2021; 9(1):27. https://0-doi-org.brum.beds.ac.uk/10.3390/math9010027
Chicago/Turabian StyleAyensa-Jiménez, Jacobo, Marina Pérez-Aliacar, Teodora Randelovic, José Antonio Sanz-Herrera, Mohamed H. Doweidar, and Manuel Doblaré. 2021. "Analysis of the Parametric Correlation in Mathematical Modeling of In Vitro Glioblastoma Evolution Using Copulas" Mathematics 9, no. 1: 27. https://0-doi-org.brum.beds.ac.uk/10.3390/math9010027