
Hierarchical Modeling for Diagnostic Test Accuracy Using Multivariate Probability Distribution Functions

 ,
,  , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Statistical Methods
2.2. Evaluation of Heterogeneity
2.3. Threshold Effect
2.4. Bivariate and Hierarchical Approach
2.5. A Statistical Method for Meta-Analysis of Diagnostic Tests Using a Copula Approach
2.6. The Hierarchical Copula Model
2.7. Selection of a Model Copula
3. Simulation Study and Goodness-of-Fit of Copula Models
3.1. Generation of Simulated Data
3.2. Adjusting the Hierarchical HSROC and Copula Models
4. Results of the Adjustment to AUDIT-C Data and Simulated Data
Simulation Results
5. Conclusions and Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
List of Abbreviations
| AUDIT | Alcohol Use Disorder Identification Test |
| AUDIT-C | Alcohol Use Disorder Identification Test abbreviated version |
| BRMA | Bivariate random-effects meta-analysis |
| C270 | Clayton 270 |
| C90 | Clayton 90 |
| CI | confidence interval |
| FGM | Farlie–Gumbel–Morgenstern |
| FN | False negative |
| FP | False positive |
| HSROC | Hierarchical summary ROC |
| MCMC | Markov chain Monte Carlo |
| ROC | Receiver operating characteristic |
| Se | Sensibility |
| SE | Standard error |
| Sp | Specificity |
| SROC | Summary ROC |
| TN | True negative |
| TP | True positive |
Appendix A
Beta Distribution Combined with a Binomial Distribution
Appendix B

Appendix C

Appendix D
Example R Code
References
- Ahn, E.; Kang, H. Introduction to systematic review and meta-analysis. Korean J. Anesthesiol. 2018, 71, 103–112. [Google Scholar] [CrossRef] [Green Version]
- Doebler, P.; Holling, H.; Böhning, D. A mixed model approach to meta-analysis of diagnostic studies with binary test outcome. Psychol. Methods 2012, 17, 418–436. [Google Scholar] [CrossRef]
- Califf, R.M. Biomarker definitions and their applications. Exp. Biol. Med. 2018, 243, 213–221. [Google Scholar] [CrossRef] [PubMed]
- Egger, M.; Smith, G.D.; Schneider, M. (Eds.) Systematic Reviews of Observational Studies. In Systematic Reviews in Health Care: Meta-Analysis in Context, 2nd ed.; BMJ Publishing Group: London, UK, 2001; Volume 8, pp. 211–227. [Google Scholar] [CrossRef]
- Hasselblad, V.; Hedges, L.V. Meta-analysis of screening and diagnostic tests. Psychol. Bull. 1995, 117, 167–178. [Google Scholar] [CrossRef] [PubMed]
- Rutter, C.M.; Gatsonis, C.A. A hierarchical regression approach to meta-analysis of diagnostic test accuracy evaluations. Stat. Med. 2001, 20, 2865–2884. [Google Scholar] [CrossRef]
- Reitsma, J.B.; Glas, A.S.; Rutjes, A.W.; Scholten, R.J.; Bossuyt, P.M.; Zwinderman, A.H. Bivariate analysis of sensitivity and specificity produces informative summary measures in diagnostic reviews. J. Clin. Epidemiol. 2005, 58, 982–990. [Google Scholar] [CrossRef] [PubMed]
- Chu, H.; Nie, L.; Chen, Y.; Huang, Y.; Sun, W. Bivariate random effects models for meta-analysis of comparative studies with binary outcomes: Methods for the absolute risk difference and relative risk. Stat. Methods Med. Res. 2010, 21, 621–633. [Google Scholar] [CrossRef] [Green Version]
- Takwoingi, Y.; Guo, B.; Riley, R.D.; Deeks, J.J. Performance of methods for meta-analysis of diagnostic test accuracy with few studies or sparse data. Stat. Methods Med. Res. 2017, 26, 1896–1911. [Google Scholar] [CrossRef] [Green Version]
- Chu, H.; Guo, H. Letter to the editor. Biostatistics 2008, 10, 201–203. [Google Scholar] [CrossRef]
- Kuss, O.; Hoyer, A.; Solms, A. Meta-analysis for diagnostic accuracy studies: A new statistical model using beta-binomial distributions and bivariate copulas. Stat. Med. 2014, 33, 17–30. [Google Scholar] [CrossRef]
- Lee, J.; Kim, K.W.; Choi, S.H.; Huh, J.; Park, S.H. Systematic Review and Meta-Analysis of Studies Evaluating Diagnostic Test Accuracy: A Practical Review for Clinical Researchers-Part II. Statistical Methods of Meta-Analysis. Korean J. Radiol. 2015, 16, 1188–1196. [Google Scholar] [CrossRef] [Green Version]
- Moses, L.E.; Shapiro, D.; Littenberg, B. Combining independent studies of a diagnostic test into a summary roc curve: Data-analytic approaches and some additional considerations. Stat. Med. 1993, 12, 1293–1316. [Google Scholar] [CrossRef]
- Schwarzer, G.; Carpenter, J.R.; Rücker, G. Meta-Analysis with R; Springer: Berlin, Germany, 2015. [Google Scholar]
- Riley, R.D.; Dodd, S.R.; Craig, J.V.; Thompson, J.R.; Williamson, P.R. Meta-analysis of diagnostic test studies using individual patient data and aggregate data. Stat. Med. 2008, 27, 6111–6136. [Google Scholar] [CrossRef] [PubMed]
- Steinhauser, S.; Schumacher, M.; Rücker, G. Modelling multiple thresholds in meta-analysis of diagnostic test accuracy studies. BMC Med. Res. Methodol. 2016, 16, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Bauz, S.; Pambabay-Calero, J.J.; Nieto-Librero, A.B.; Galindo-Villardón, M.P. Meta-Analysis in DTA with Hierarchical Models Bivariate and HSROC: Simulation Study. In Selected Contributions on Statistics and Data Science in Latin America; Antoniano-Villalobos, I., Mena, R., Mendoza, M., Naranjo, L., Nieto-Barajas, L., Eds.; Springer: Cham, Switzerland, 2019; Volume 301, pp. 33–42. [Google Scholar] [CrossRef]
- Arends, L.R.; Hamza, T.H.; van Houwelingen, J.C.; Heijenbrok-Kal, M.H.; Hunink, M.G.M.; Stijnen, T. Bivariate Random Effects Meta-Analysis of ROC Curves. Med. Decis. Mak. 2008, 28, 621–638. [Google Scholar] [CrossRef]
- Harbord, R.M.; Deeks, J.J.; Egger, M.; Whiting, P.; Sterne, J. A unification of models for meta-analysis of diagnostic accuracy studies. Biostatistics 2007, 8, 239–251. [Google Scholar] [CrossRef] [Green Version]
- Macaskill, P.; Gatsonis, C.; Deeks, J.; Harbord, R.; Takwoingi, Y. Cochrane Handbook for Systematic Reviews of Diagnostic Test Accuracy; Chapter 10 Analysing and Presenting Results; The Cochrane Collaboration: London, UK, 2010. [Google Scholar]
- Senturk, D. Explanatory Item Response Models: A Generalized Linear and Nonlinear Approach. Technometrics 2006, 48, 568–569. [Google Scholar] [CrossRef]
- Nikoloulopoulos, A.K. A mixed effect model for bivariate meta-analysis of diagnostic test accuracy studies using a copula representation of the random effects distribution. Stat. Med. 2015, 34, 3842–3865. [Google Scholar] [CrossRef] [Green Version]
- Kriston, L.; Hölzel, L.; Weiser, A.-K.; Berner, M.M.; Härter, M. Meta-analysis: Are 3 Questions Enough to Detect Unhealthy Alcohol Use? Ann. Intern. Med. 2008, 149, 879–888. [Google Scholar] [CrossRef]
- Babor, T.; Higgins-Biddle, J.C.; Saunders, J.B.; Monteiro, M.G. The Alcohol Use Disorders Identification Test: Guidelines for Use in Primary Care; World Health Organization: Geneva, Switzerland, 2001; pp. 1–40. [Google Scholar]
- Muhammad, N.; Coolen-Maturi, T.; Coolen, F.P. Nonparametric predictive inference with parametric copulas for combining bivariate diagnostic tests. Stat. Optim. Inf. Comput. 2018, 6, 398–408. [Google Scholar] [CrossRef] [Green Version]
- Ghalibaf, M.B. Relationship Between Kendall’s tau Correlation and Mutual Information. Revista Colombiana de Estadística 2020, 43, 3–20. [Google Scholar] [CrossRef]
- SKLAR, M. Fonctions de repartition a n dimensions et leurs marges. Publ. Inst. Stat. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas; Springer Science & Business Media: Berlin, Germany, 2000; Volume 42, p. 317. [Google Scholar]
- Schweizer, B.; Wolff, E.F. On Nonparametric Measures of Dependence for Random Variables. Ann. Stat. 1981, 9, 879–885. [Google Scholar] [CrossRef]
- Hoyer, A.; Kuss, O. Meta-analysis of diagnostic tests accounting for disease prevalence: A new model using trivariate copulas. Stat. Med. 2015, 34, 1912–1924. [Google Scholar] [CrossRef]
- Hoyer, A.; Kuss, O. Meta-analysis for the comparison of two diagnostic tests to a common gold standard: A generalized linear mixed model approach. Stat. Methods Med Res. 2016, 27, 1410–1421. [Google Scholar] [CrossRef]
- Zapf, A.; Hoyer, A.; Kramer, K.; Kuss, O. Nonparametric meta-analysis for diagnostic accuracy studies. Stat. Med. 2015, 34, 3831–3841. [Google Scholar] [CrossRef]
- Coakley, C.W.; Conover, W.J. Practical Nonparametric Statistics. J. Am. Stat. Assoc. 2000, 95, 332. [Google Scholar] [CrossRef]
- Bachmann, L.M.; Puhan, M.A.; Ter Riet, G.; Bossuyt, P.M. Sample sizes of studies on diagnostic accuracy: Literature survey. BMJ 2006, 332, 1127–1129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Morris, T.P.; White, I.R.; Crowther, M.J. Using simulation studies to evaluate statistical methods. Stat. Med. 2019, 38, 2074–2102. [Google Scholar] [CrossRef] [Green Version]
- Nyaga, V.N.; Arbyn, M.; Aerts, M. CopulaDTA: An R Package for Copula-Based Bivariate Beta-Binomial Models for Diagnostic Test Accuracy Studies in a Bayesian Framework. J. Stat. Softw. 2017, 82, 1–27. [Google Scholar] [CrossRef]
- Schiller, I.; Dendukuri, N. HSROC: An R Package for Bayesian Meta-Analysis of Diagnostic Test Accuracy; Version 2.1.8; R Core Team: Vienna, Austria, 2015. [Google Scholar]
- Huerta, M.; Leiva, V.; Lillo, C.; Rodriguez, M.; Leiva-Sanchez, V. A beta partial least squares regression model: Diagnostics and application to mining industry data. Appl. Stoch. Model. Bus. Ind. 2018, 34, 305–321. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Q.; Hou, H.-D.; Rho, S.; Gupta, B.; Mu, Y.-X.; Shen, W.-Z. Big data driven outlier detection for soybean straw near infrared spectroscopy. J. Comput. Sci. 2018, 26, 178–189. [Google Scholar] [CrossRef]
- Dukic, V.; Gatsonis, C. Meta-analysis of diagnostic test accuracy assessment studies with varying number of thresholds. Biometrics 2003, 59, 936–946. [Google Scholar] [CrossRef]
- Genest, C.; Nešlehová, J. A Primer on Copulas for Count Data. ASTIN Bull. 2007, 37, 475–515. [Google Scholar] [CrossRef] [Green Version]
- Mikosch, T. Copulas: Tales and Facts—Rejoinder. Extremes 2006, 9, 55–62. [Google Scholar] [CrossRef]
- Chu, H.; Nie, L.; Cole, S.R.; Poole, C. Meta-analysis of diagnostic accuracy studies accounting for disease prevalence: Alternative parameterizations and model selection. Stat. Med. 2009, 28, 2384–2399. [Google Scholar] [CrossRef]
- Pambabay-Calero, J.J.; Bauz-Olvera, S.A.; Nieto-Librero, A.B.; Galindo-Villardon, M.P.; Hernandez-Gonzalez, S. An alternative to the Cochran-(Q) statistic for analysis of heterogeneity in meta-analysis of diagnostic tests based on HJ BIPLOT. Investig. Oper. 2018, 39, 536–545. [Google Scholar]
- Pambabay-Calero, J.J.; Bauz-Olvera, S.A.; Nieto-Librero, A.B.; Galindo-Villardón, M.P.; Sánchez-García, A.B. A tutorial for meta-analysis of diagnostic tests for low-prevalence diseases: Bayesian models and software. Methodology 2020, 16, 258–277. [Google Scholar] [CrossRef]
- Liu, Y.; DeSantis, S.M.; Chen, Y. Bayesian mixed treatment comparisons meta-analysis for correlated outcomes subject to reporting bias. J. R. Stat. Soc. Ser. C 2017, 67, 127–144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krog, J.; Jacobsen, L.H.; Lund, F.W.; Wüstner, D.; Lomholt, M.A. Bayesian model selection with fractional Brownian motion. J. Stat. Mech. Theory Exp. 2018, 2018, 093501. [Google Scholar] [CrossRef] [Green Version]
- Krog, J.; Lomholt, M.A. Bayesian inference with information content model check for Langevin equations. Phys. Rev. E 2017, 96, 062106. [Google Scholar] [CrossRef] [Green Version]
- Thapa, S.; Lomholt, M.A.; Krog, J.; Cherstvy, A.G.; Metzler, R. Bayesian analysis of single-particle tracking data using the nested-sampling algorithm: Maximum-likelihood model selection applied to stochastic-diffusivity data. Phys. Chem. Chem. Phys. 2018, 20, 29018–29037. [Google Scholar] [CrossRef]




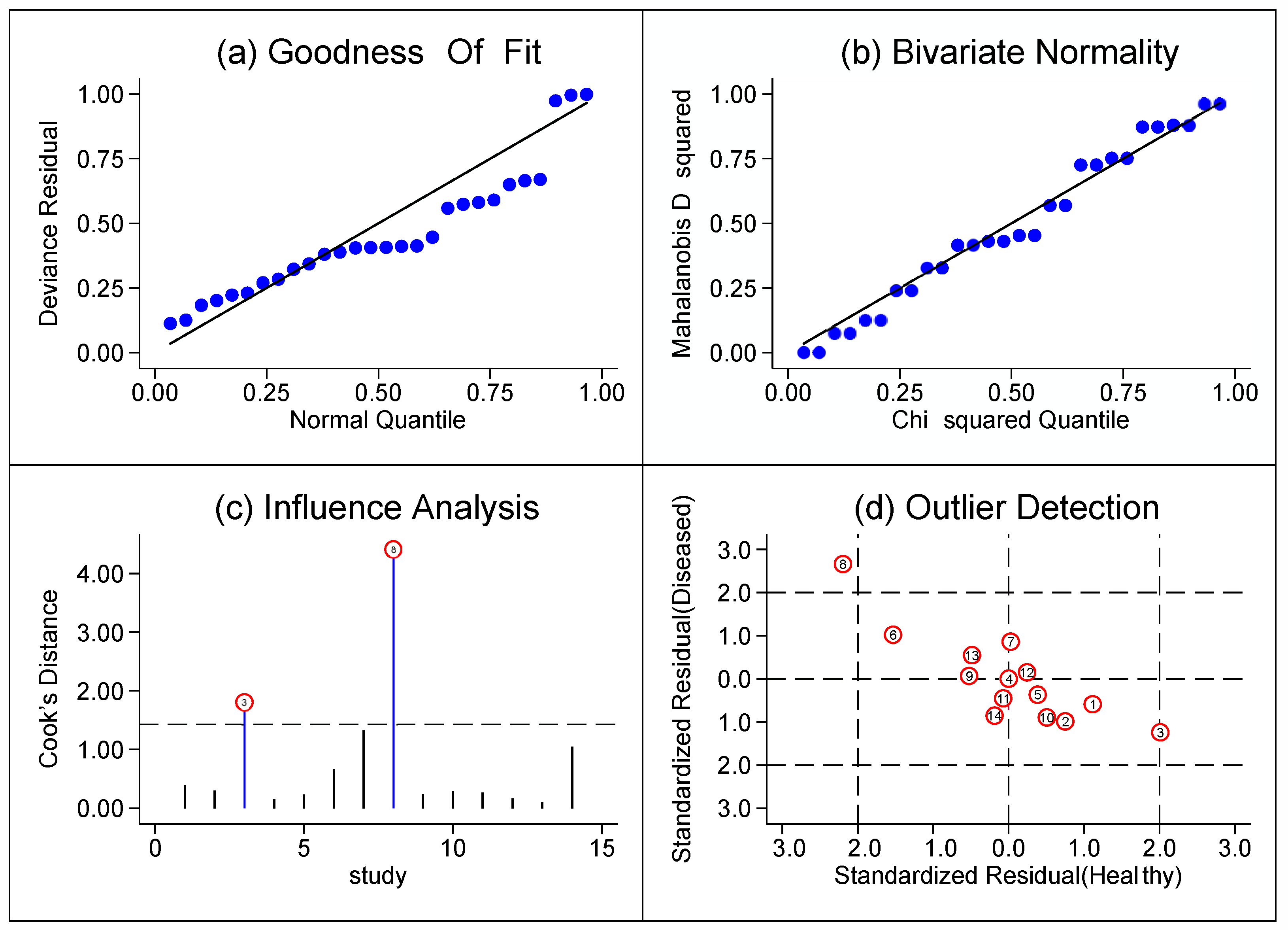{kind=link}
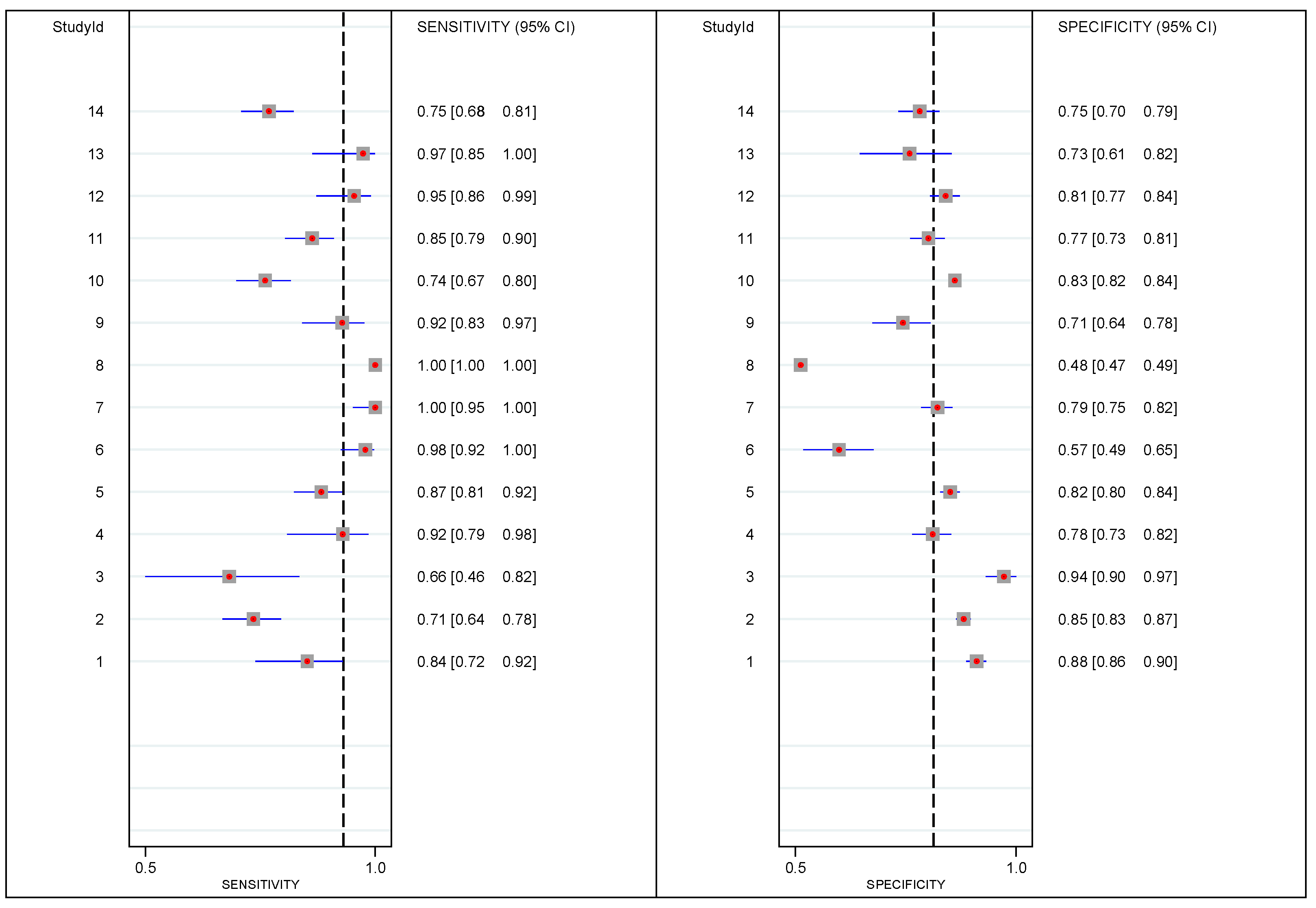{kind=link}
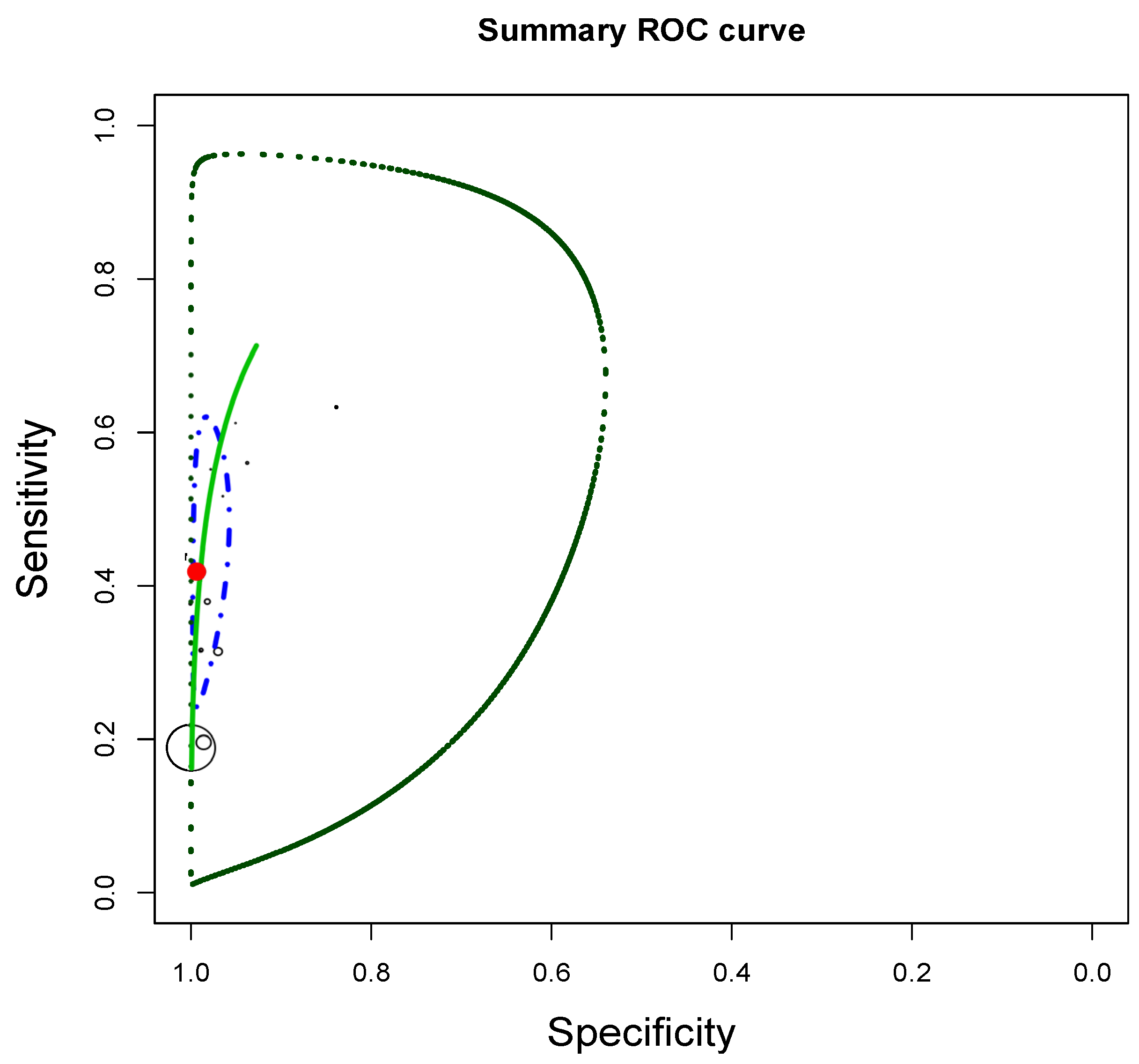{kind=link}
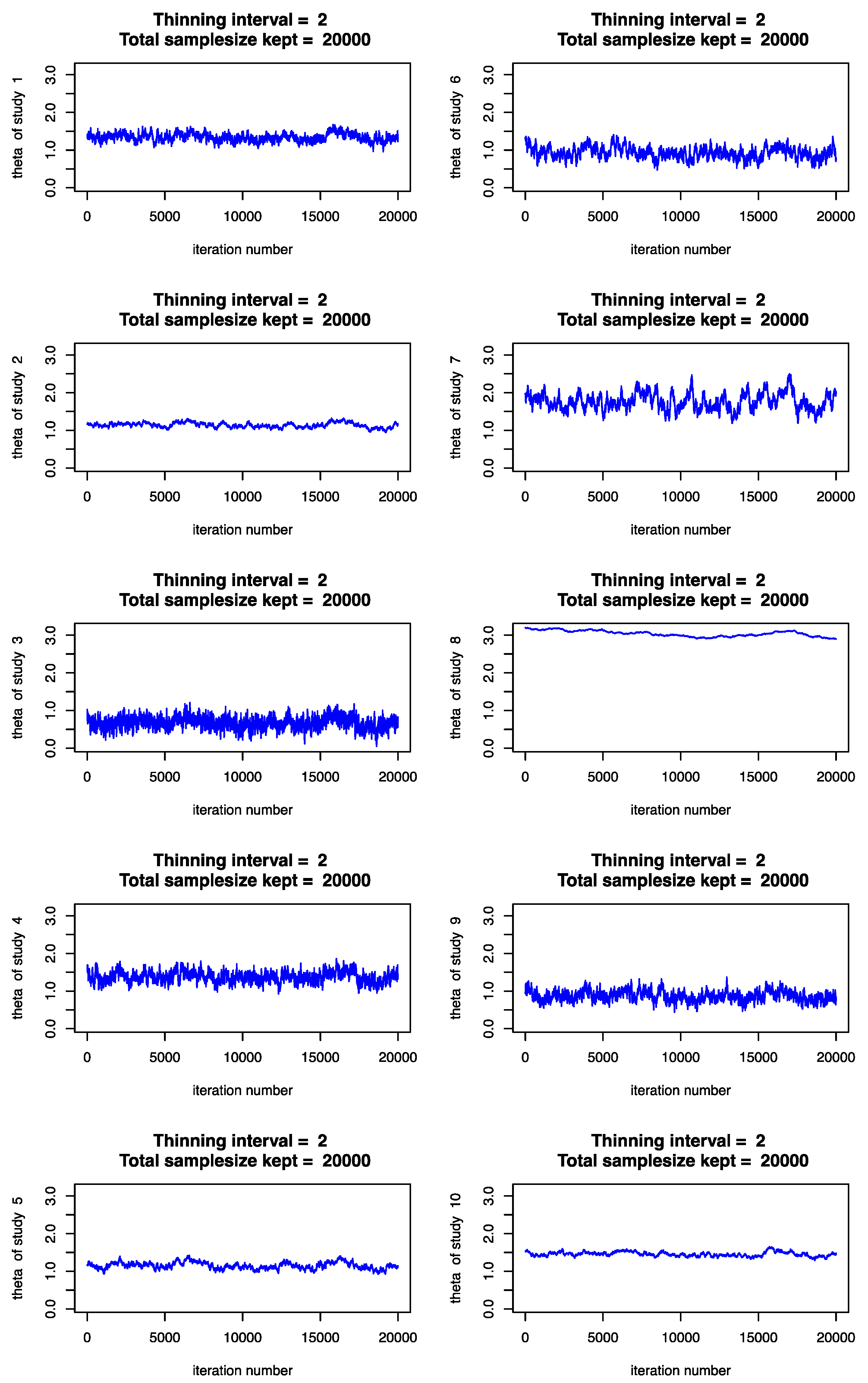{kind=link}
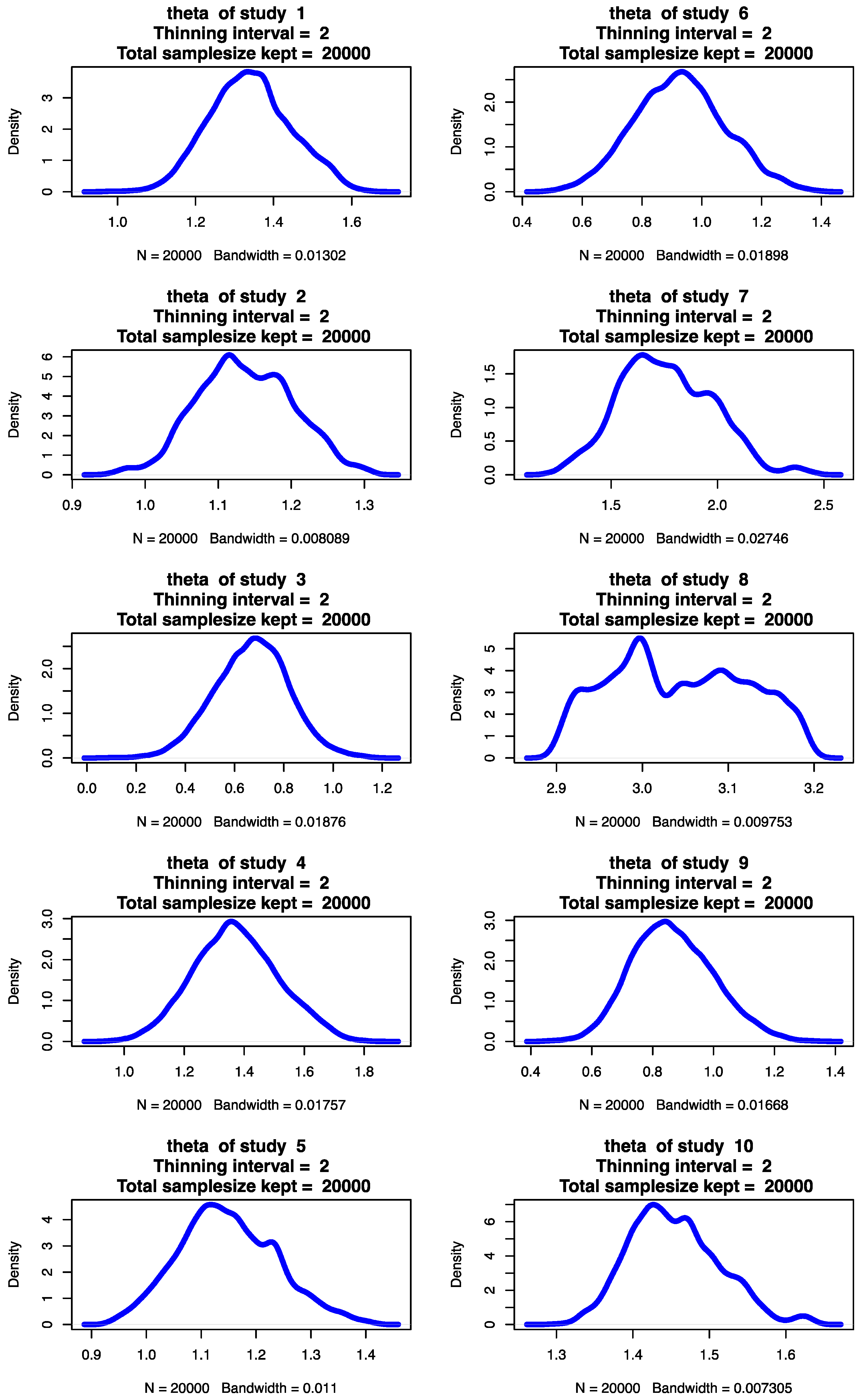{kind=link}
| ID | TP | FP | TN | FN |
|---|---|---|---|---|
| 1 | 47 | 101 | 738 | 9 |
| 2 | 126 | 272 | 1543 | 51 |
| 3 | 19 | 12 | 192 | 10 |
| 4 | 36 | 78 | 276 | 3 |
| 5 | 130 | 211 | 959 | 19 |
| 6 | 84 | 68 | 89 | 2 |
| 7 | 68 | 112 | 423 | 0 |
| 8 | 752 | 3226 | 2977 | 0 |
| 9 | 59 | 55 | 136 | 5 |
| 10 | 142 | 571 | 2788 | 50 |
| 11 | 137 | 107 | 358 | 24 |
| 12 | 57 | 103 | 437 | 3 |
| 13 | 34 | 21 | 56 | 1 |
| 14 | 152 | 88 | 264 | 51 |
| Copulas | Parameter | Mean | Lower | Upper |
|---|---|---|---|---|
| Gauss | Se | 0.862 | 0.766 | 0.920 |
| Sp | 0.755 | 0.6898 | 0.811 | |
| Correlation | −0.570 | −0.799 | −0.289 | |
| C90 | Se | 0.865 | 0.777 | 0.922 |
| Sp | 0.760 | 0.695 | 0.813 | |
| Correlation | −0.466 | −0.801 | −0.0005 | |
| C270 | Se | 0.854 | 0.743 | 0.920 |
| Sp | 0.752 | 0.680 | 0.810 | |
| Correlation | −0.324 | −0.758 | −2.219 × 10−17 | |
| FGM | Se | 0.871 | 0.780 | 0.932 |
| Sp | 0.756 | 0.692 | 0.812 | |
| Correlation | −0.214 | −0.222 | −0.121 | |
| Frank | Se | 0.858 | 0.754 | 0.929 |
| Sp | 0.751 | 0.773 | 0.808 | |
| Correlation | −0.600 | −0.767 | 1.000 |
| Copula Model | Statistic | p-Value |
|---|---|---|
| Gauss | 0.06547 | 0.301 |
| Clayton | 0.05539 | 0.659 |
| FGM | 0.02287 | 0.903 |
| Frank | 0.06647 | 0.296 |
| Number of Studies in the Meta-Analysis | ||||||
|---|---|---|---|---|---|---|
| Copula | Parameter | 5–10 | 11–16 | 17–22 | 23–38 | 29–35 |
| Gauss | Statistic | 0.11823 | 0.06988 | 0.050 97 | 0.04320 | 0.03739 |
| SE | 0.00252 | 0.00113 | 0.00064 | 0.00069 | 0.00061 | |
| p-value | 0.50309 | 0.49000 | 0.47070 | 0.44991 | 0.49072 | |
| Clayton | Statistic | 0.16819 | 0.16851 | 0.13742 | 0.11023 | 0.03460 |
| SE | 0.03237 | 0.05993 | 0.06356 | 0.07039 | 0.00061 | |
| p-value | 0.52656 | 0.52146 | 0.52786 | 0.48326 | 0.49891 | |
| FGM | Statistic | 0.06490 | 0.050 25 | 0.04871 | 0.06154 | 0.06717 |
| SE | 0.00293 | 0.00159 | 0.00152 | 0.00032 | 0.00416 | |
| p-value | 0.71763 | 0.62812 | 0.48737 | 0.34574 | 0.30307 | |
| Frank | Statistic | 0.11127 | 0.06867 | 0.05102 | 0.04355 | 0.03735 |
| SE | 0.00361 | 0.00123 | 0.00075 | 0.00078 | 0.00067 | |
| p-value | 0.43157 | 0.48938 | 0.46523 | 0.43418 | 0.46655 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pambabay-Calero, J.; Bauz-Olvera, S.; Nieto-Librero, A.; Sánchez-García, A.; Galindo-Villardón, P. Hierarchical Modeling for Diagnostic Test Accuracy Using Multivariate Probability Distribution Functions. Mathematics 2021, 9, 1310. https://0-doi-org.brum.beds.ac.uk/10.3390/math9111310
Pambabay-Calero J, Bauz-Olvera S, Nieto-Librero A, Sánchez-García A, Galindo-Villardón P. Hierarchical Modeling for Diagnostic Test Accuracy Using Multivariate Probability Distribution Functions. Mathematics. 2021; 9(11):1310. https://0-doi-org.brum.beds.ac.uk/10.3390/math9111310
Chicago/Turabian StylePambabay-Calero, Johny, Sergio Bauz-Olvera, Ana Nieto-Librero, Ana Sánchez-García, and Puri Galindo-Villardón. 2021. "Hierarchical Modeling for Diagnostic Test Accuracy Using Multivariate Probability Distribution Functions" Mathematics 9, no. 11: 1310. https://0-doi-org.brum.beds.ac.uk/10.3390/math9111310