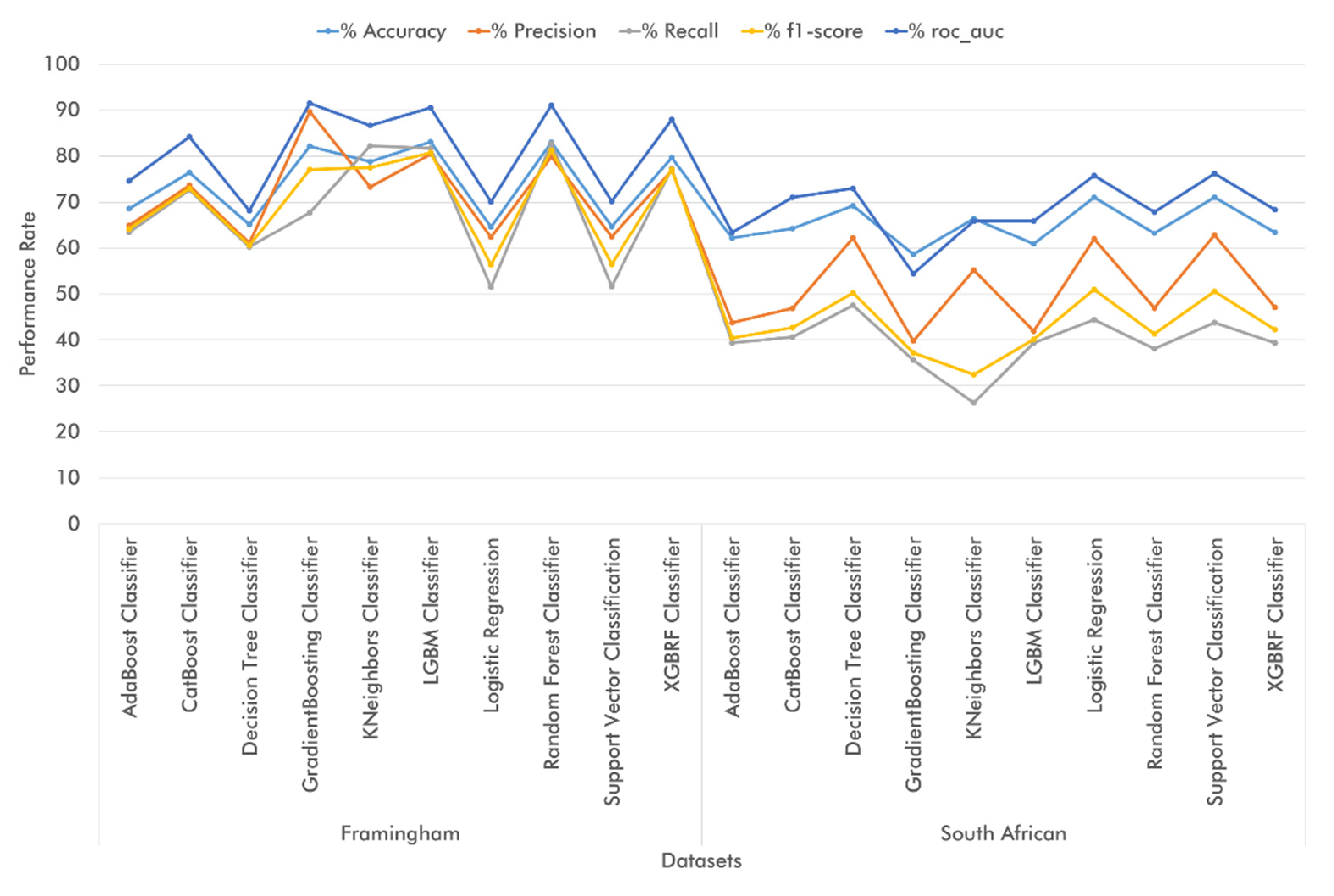
This section discusses the results from the several performance analyses of the ten ML classification models in terms of their ability to identify the top-two and top-four main attributes from publicly available datasets of CVD patient records. As previously mentioned, we conducted the classifier performance evaluations, first by applying the train-test split method (70–30%), and second with k-fold cross-validation (k = 10). During the evaluations, we recorded five performance measures: accuracy, precision, recall, f1-score, and ROC-AUC.
4.4. Most Important Dataset Attributes
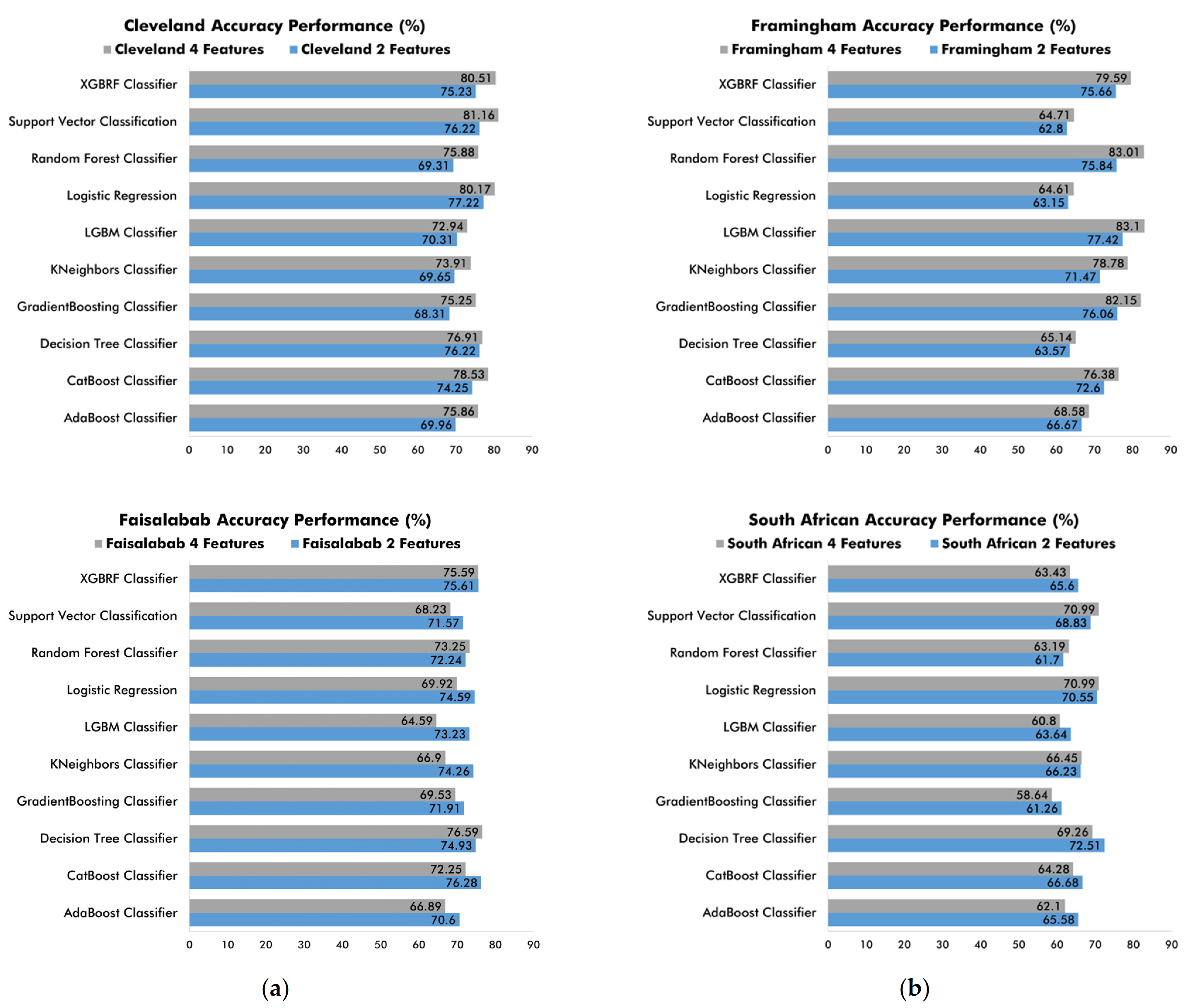
The importance of this research lies in finding the best precision and accuracy results from the ten ML classifiers to identify the top-two and top-four attributes for CVD detection and prevention. At this stage, we compared the results obtained from all the previous performance analyses. When comparing the accuracy metrics (
Figure 8), we found that in both the two-attribute and the four attribute classifications, the ML classifiers performed adequately on all the CVD diagnostic and prediction datasets using k-fold cross-validation. Specifically, when working with medical diagnosis datasets, the ten classifiers performed better when applied on the top-four attributes of the Cleveland dataset and the top-two attributes of the Faisalabad dataset. Conversely, when working with medical prediction datasets, we observed overall better classifier performance on the top-four attributes from the Framingham dataset and the top-two attributes from the South African Hearth dataset.
As for the validation technique, we found that it is feasible to rely on k-fold cross-validation to obtain adequate classifier performance on the Cleveland, Framingham, and Faisalabad datasets. However, on the South African Hearth dataset, ML classifiers are lowest-performing when using k-fold cross-validation.
Figure 8.
Comparison of ML classifier accuracy performance using k-fold cross-validation on top-two and top-four attributes from (a) medical diagnostic datasets; (b) medical prediction datasets.
Figure 8.
Comparison of ML classifier accuracy performance using k-fold cross-validation on top-two and top-four attributes from (a) medical diagnostic datasets; (b) medical prediction datasets.
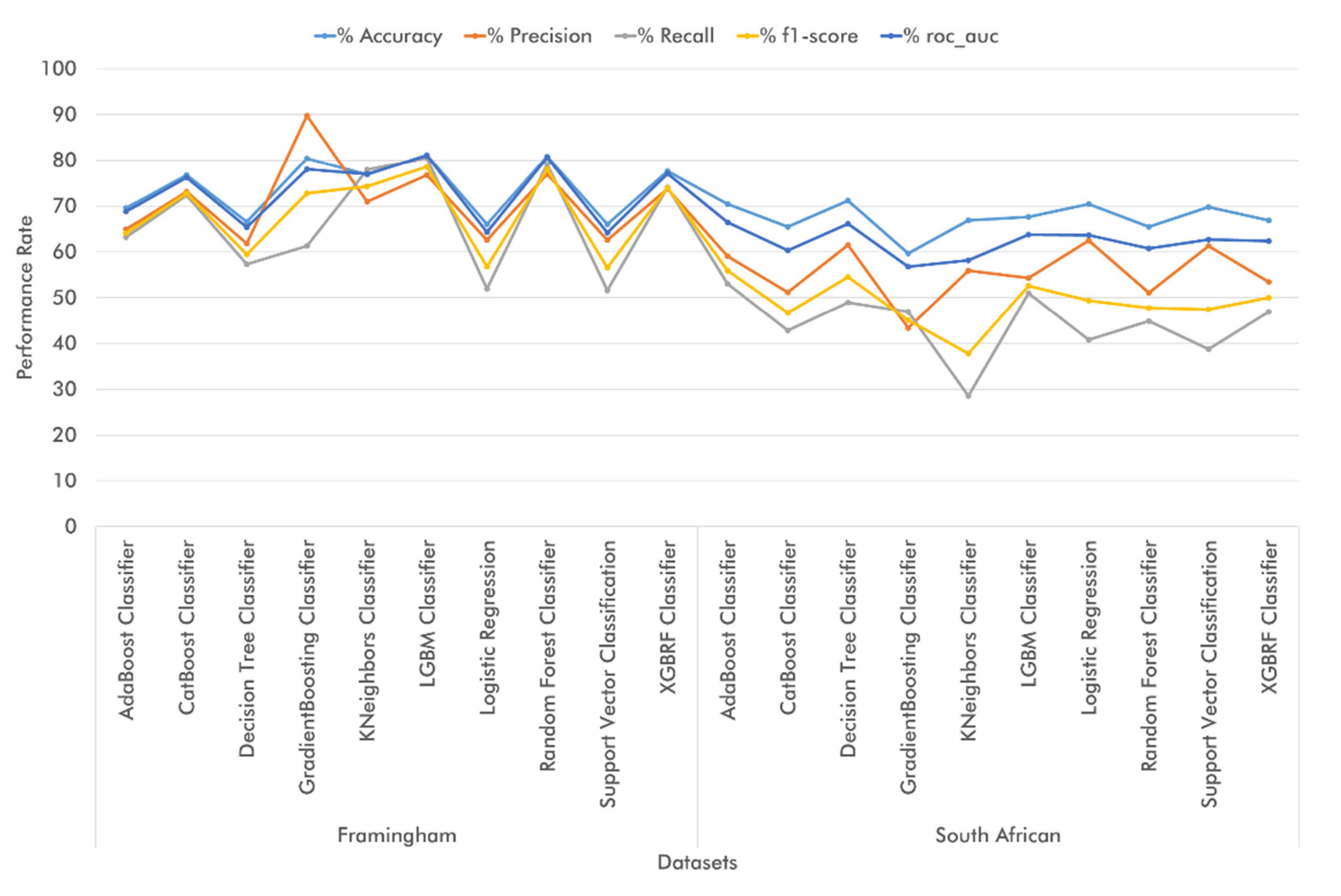
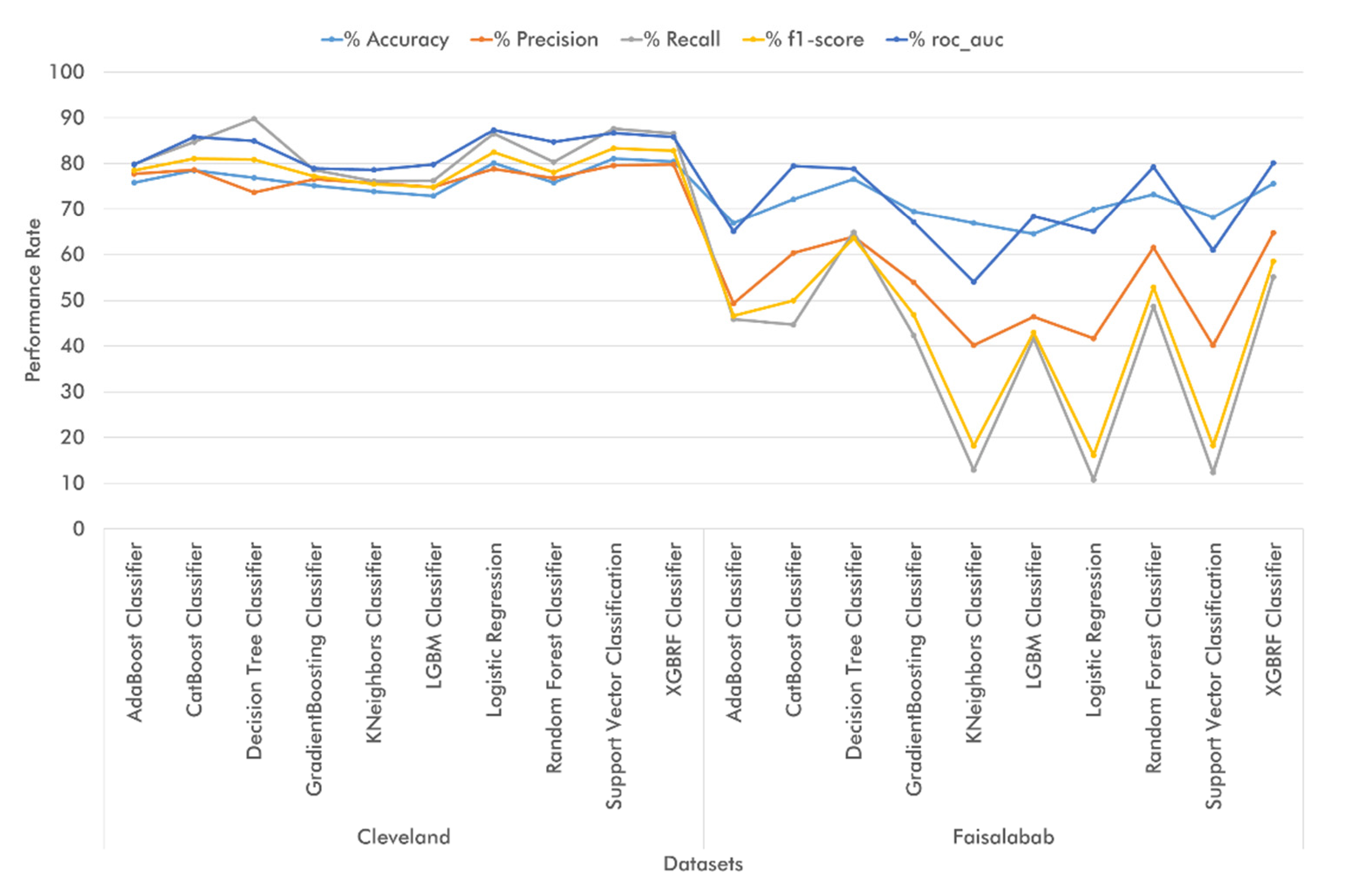
Regarding the accuracy metrics using train-test split,
Figure 9 shows that adequate classifier performance was achieved in all top-two and top-four attribute classifications on the Cleveland and Framingham datasets. Additionally, we found that when working with medical diagnosis datasets, the ML classifiers performed better in terms of accuracy on the Cleveland dataset during the top-four attribute classifications and on the Faisalabad dataset during the top-two attribute classifications. On the other hand, when dealing with medical prediction datasets, we achieved better classifier performance results on the Framingham dataset (top-four attribute classification) and the South African dataset (top-two classification). As for the evaluated technique, train-and-test set validation worked best on the Cleveland dataset, whereas on the Faisalabad and Framingham datasets, some algorithms performed better when using the train-and-test set technique. Regarding the South African Hearth dataset, it is feasible to use both train-test split and k-fold cross-validation, since the ML classifiers exhibited adequate performance with both techniques.
As a result of the previous analysis, we managed to identify the main attributes for CVD diagnosis across the four datasets. On the Cleveland database, such attributes include cp (Chest Pain Type), thalach (maximal heart rate), ca (number of vessels colored by fluoroscopy), and oldpeak (exercise relative to rest). In the top-two attribute classification, CatBoost Classifier and XGBRF Classifier achieved the best accuracy (81.32%), Logistic Regression yielded the best precision performance (84.09%), Decision Tree Classifier outperformed in terms of recall (86.00%), and CatBoost Classifier and XGBRF Classifier achieved the best performance results in terms of f1-score and roc-auc, respectively (82.83% and 81.24%, respectively). On the other hand, when using k-fold cross-validation, Logistic Regression exhibited the best performance in accuracy (77.22%), precision (79.95%), and f1-score (78.96%), whereas Decision Tree Classifier showed the best results in terms of recall (79.85%), and Support Vector Classification yielded the best performance in roc-auc (80.25%).
As regards the top-four classification of Cleveland attributes using train-test split, Logistic Regression and Support Vector Classification yielded the highest accuracy (82.42%), whereas Logistic Regression alone outperformed the other algorithms in terms of precision (88.64%). On the other hand, the best-performing classifiers in recall, f1-score, and roc-auc were Decision Tree Classifier (86.00%), Support Vector Classification (83.33%), and Logistic Regression (82.9%), respectively. Finally, when using k-fold cross-validation, Support Vector Classification exhibited the highest classification accuracy (81.16%), XGBRF Classifier yielded the best results in terms of precision (79.77%), Decision Tree Classifier was the best-performing algorithm in recall (89.78%), Support Vector Classification showed the best results in f1-score (83.33%), and Logistic Regression was the best-performing algorithm in roc-auc (87.34%).
In the Faisalabad dataset, the main attributes identified included serum creatinine, ejection fraction, patient age, and platelets. In the top-two attribute classification using the test-train split technique, the best-performing classifiers were as follows: Decision Tree Classifier in accuracy (74.44%), f1-score (65.67%), and roc-auc (72.18%), KNeighbors Classifier in precision (72.22%), and Random Forest Classifier in recall (62.16%). Conversely, when relying on k-fold cross-validation, CatBoost Classifier exhibited the best results in accuracy and f1-score (76.28% and 58.55%, respectively), Logistic Regression yielded the highest precision (76.67%), Random Forest Classifier outperformed the other classifiers in terms of recall (57.11%), and XGBRF Classifier showed the best performance in roc-auc (81.18%). In the top-four classification of Faisalabad attributes using the train-test split technique, Decision Tree Classifier proved to be the best-performing algorithm as regards accuracy (71.11%), recall (70.27%), f1-score (66.67%), and roc-auc (70.98%), whereas Support Vector Classification exhibited the highest precision performance (100.00%). On the other hand, during k-fold cross-validation, the best classification performance was exhibited by Decision Tree Classifier in terms of accuracy (76.59%), recall (64.89%), and f1-score (63.59%), and by XGBRF Classifier in terms of precision (64.74%) and roc-auc (80.17%).
As regards the two CVD medical prediction datasets, the main attributes identified in the Framingham dataset included sysBP (systolic blood pressure), BMI (Body Mass Index), age (age at exam time), and totChol (total cholesterol). In the top-two attribute classification using the train-test split technique, LGBM Classifier proved to be the best-performing classifier across the five metrics: accuracy (77.84%), precision (74.61%), recall (73.26%), f1-score (73.93%), and roc-auc (77.27%). On the other hand, when using k-fold cross-validation, LGBM Classifier exhibited the best performance in accuracy (77.42%), recall (74.52%), f1-score (74.03%), and roc-auc (84.74%), whereas GradientBoosting Classifier showed the best precision results (75.17%). As regards the top-four attribute classification with the train-test split technique, LGBM Classifier outperformed the other classifiers in terms of accuracy (81.18%), recall (80.50%), f1-score (78.59%), and roc-auc (81.10%), while the highest precision was achieved by GradientBoosting Classifier (89.80%). On the other hand, when using k-fold cross-validation, the best performing classifiers included LGBM Classifier in terms of accuracy (83.10%), GradientBoosting Classifier in terms of precision (89.60%) and roc-auc (91.41%), and Random Forest Classifier in recall and f1-score (82.74% and 81.21%, respectively).
In the South African Hearth dataset, the main attributes included tobacco (cumulative tobacco), age (age at the exam), LDL (low-density lipoprotein cholesterol), and adiposity. In the top-two attribute classification using train-test split, the best-performing classifiers proved to be Logistic Regression in accuracy (73.38%), Support Vector Classification in precision (80.00%), and Decision Tree Classifier in terms of recall (48.98%), f1-score (55.17%), and roc-auc (66.71%). Conversely, when relying on k-fold cross-validation, Decision Tree Classifier yielded the highest accuracy (71.22%), Logistic Regression outperformed the other classifiers in precision (62.50%), and AdaBoost Classifier exhibited the best performance in recall (53.06%), f1-score (55.91%), and roc-auc (66.53%). Regarding the top-four attribute classifications, the best-performing classifiers with the train-test split technique were Decision Tree Classifier in accuracy (71.22%), Logistic Regression in precision (62.50%), and AdaBoost Classifier in recall (53.06%), f1-score (55.91%), and roc-auc (66.53%). On the other hand, when relying on k-fold cross-validation, both Logistic Regression and Support Vector Classification achieved the highest accuracy (70.99%), whereas Support Vector Classification itself exhibited the best performance in terms of precision (62.79%). Decision Tree yielded the best results in recall (47.50%), Logistic Regression in f1-score (50.98%), and Support Vector Classification in roc-auc (76.17%).
From this discussion of the results, we concluded that the ten studied ML classifiers performed adequately in the classification of top-two and top-four dataset attributes. Hence, efforts in predicting and/or diagnosing CVD with said features will yield the expected results (
Table 11).
Of the variables identified, age in the Faisalabad, Framingham, and South African Hearth datasets is an important risk factor for any CVD. As regards heart rate (found in the Cleveland dataset as thalach), normal ranges of pulse per minute (bpm) should be monitored. On the other hand, blood pressure is known to trigger all types of CVDs. It refers to the force exerted against the walls of the arteries as the heart pumps blood to the body. In this sense, the systolic pressure range, found in the Framingham dataset, should be properly monitored, especially among patients suffering from hypertension. Levels of blood cholesterol in the body are measured with cholesterol tests, which determine the amount of each type of cholesterol and certain fats in the body. LDL cholesterol, or bad cholesterol, (attribute from the South African Hearth dataset) is a major CVD risk factor, since it causes plaque buildup in the arteries, thus reducing blood flow. Similarly, total blood cholesterol levels—attributes found in the Framingham dataset—must be monitored in all CVD diagnosis and detection efforts.
Regarding Cleveland dataset attributes, coronary angiography (ca) is a special procedure that uses contrast dyes and X-rays to see how blood flows in the arteries in the heart, thus showing whether any of the coronary arteries are blocked or narrowed due to fatty plaques and how serious it may be. Coronary angiography thus allows monitoring the development of CVDs such as heart disease, arterial disease, and coronary artery disease. As for cp, ECGs (i.e., graphical representation of the electrical forces working on the heart) allows monitoring the cardiac cycle of pumping and filling in a known pattern of changing electrical pulses that accurately reflect the action of the heart. ECGs are performed by collecting the pulses through electrodes attached to the surface of the body. Hence, ECGs help identify CVDs such as heart failure, arrhythmia, heart disease, and arterial or coronary artery disease. Finally, exercise-induced ST-segment depression (oldpeak) can be monitored via stress tests (i.e., ergometry) to examine how the heart functions during physical activity to prevent the development of CVDs, such as heart failure, heart disease, arterial and coronary artery disease. These attributes are the most important for correct CVD prediction and diagnosis. Similarly, we identified other important attributes, such as tobacco and blood platelet count. On the one hand, nicotine in the body must be monitored among both smokers and non-smokers by modifying patient lifestyle, whereas high blood platelet counts may be an indicator of CVD. Finally, as discussed by Davide Chicco, et al., other key attributes for CVD detection and diagnosis include ejection fraction (i.e., percentage of blood leaving the heart at each heartbeat) and serum creatinine (i.e., level of blood creatinine), whose abnormal levels are usually observed among diabetic patients, kidney disease sufferers, and patients with high blood pressure.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}