1. Introduction
The field of application of the model developed in this research is that of Control Charts (CCs). CCs are an extension of time series that represent a chronological sequence of one-variable observations [
1]. There are two types of CCs: univariate CCs (created by Shewhart in 1931) that inspect the nonconformity of a quality characteristic of a random variable and Multivariate Control Charts (MVCCs) that simultaneously monitor various quality characteristics (random variables for statistical effects). The objective of the CCs is to help understand the variation of the observations of the variable (type of pattern with statistical variation) that leads to the establishment of variation structures. As noted in [
2], an effective way of handling the data is by using tolerance ranges and regions. Tolerance intervals are defined to contain a proportion of a population with a given confidence level. These intervals are analogous to what are known in statistical process control as “control limits”. Unlike a confidence interval that provides information about an unknown population parameter, a tolerance interval provides information about the variability that it contains and this is interesting to consider in the approach to pattern recognition.
There are two basic categories of variation structures: natural variation and special variation. The first one is the random variation inherent to only random characteristics of the data generating process; the second one is the variation related to situations outside the process [
3]. When a variable presents some structure of natural or special variation, a pattern is defined. There are patterns for natural variation and for special variation. The objective of pattern recognition in CCs is to recognise the patterns to be associated with the natural variation and for special variation in the variation structures. CCs can exhibit 15 types of patterns [
4], of which seven are considered simple: Natural (N), Increasing Trend (IT), Decreasing Trend (DT), Cycle (Cy), Downward Shift (DS), Upward Shift (US) and Systematic (Sy) patterns.
Univariate CCs have been used mostly in industry as a strategy for individual monitoring of the quality characteristics of the process over MVCCs due to the simplicity of execution and understanding, but in many cases, a simultaneous inspection of two or more characteristics is required. In addition, the variables may present correlation between them. For these cases, the MVCCs appear. The first of these, which are more often used in theory than in practice, is called Hotelling’s
and was developed in 1947 to monitor changes in the mean [
5]. There are other popular MVCCs such as the Multivariate Cumulative Sum (MCUSUM) [
6] and Multivariate Exponentially Weighted Moving Average (MEWMA).
The use of Hotelling’s
CCs as such has made it possible to generate various modifications and is used as the comparative reference method with new proposals. The CCs’ logic of operation and use in the processes allows adaptations to achieve better performance in observable cases [
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17]. Furthermore, with them as reference, the ongoing development of Multivariate Pattern Recognition (MVPR) using Artificial Neural Networks is to achieve the joint monitoring of random variables [
12,
13,
14,
15,
16]. The reasons for generating modifications to the Hotelling’s CCs are: (1) the limitation in its design since it can only detect out-of-control signals for the special pattern of “changes in the mean” when the process has lost stability due to non natural variation causes and, (2) its inability to detect the random variables that cause instability in the process and to identify the type of failure that occurs as discussed in [
17]. This means that there are no defined procedures for the interpretation of variation structures for MVPR.
The approach envisaged in this research consists of the MVPR identifying multivariant patterns that are related to the special variation present in the univariate variables. With this, the effect of special variation on univariate patterns is assessed in the observable multivariate pattern in “the Unified Multivariate Variable” (
UMV). The aforementioned process of association provides valuable information for process improvement. The study of the presence of a special pattern in a random variable implies analysing the type and form of the displacement of the random variables that thus have changed in the values of their statistical parameters, such as the mean and the standard deviation. The analysis process is suitable when evaluating the changes in the mean that allow an association to be made with the variables that present special variation as presented in [
18]. Another approach for analysis of the CCs
is the one shown in [
19]. There, the CC was used to detect outliers associated with patterns present in the random variables. It uses the Birnbaum–Saunders distribution to estimate the parameters of the graph that allow to obtain a new distribution where the special variation detection is carried out. In both studies [
18,
19], the MVPR was not achieved in the variation structures and the patterns were associated only with changes in the performance of the studied parameters.
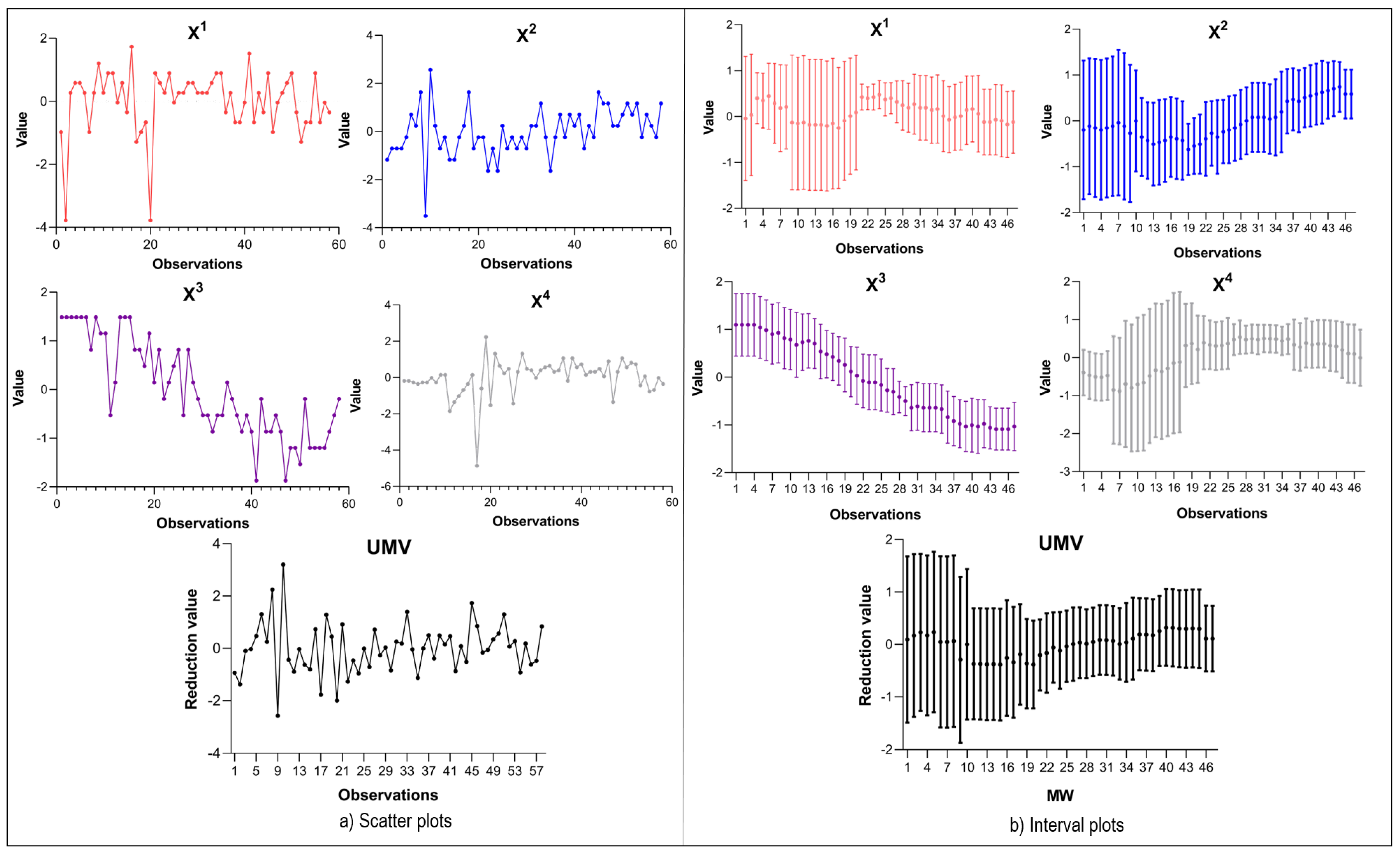
Regarding the interpretation of variation structures for the pattern recognition, there are several studies that share a method of data segmentation in the variable called Moving Windows (
MWs) [
20,
21,
22]. A
MW is a dynamic segmentation method that is applied to the observations that integrate the random variables of the processes. Its use is very practical as it allows various research approaches such as the observation of the covariance by period [
23]. With
MWs, a sequential representation of the observations is achieved by presenting one datum point observation at a time and discarding the oldest observation. The size of the window must be predefined by a reference size, by experimenting with several sizes looking for an optimal size or by determining the size that “visualises” the presence of special variation in the
MW and the characteristics of the identifiable pattern, which are strengthened or gradually weakened as the
MW moves through the stream of observations of the random variable. In [
24,
25], it has been shown that this heuristic approach significantly reduces the rate of misclassification of patterns present in the variation structures.
Song et al. propose a different approach for MVCCs adapting the Naive Bayes method based on Bayesian inference [
26]. The method is used to interpret out-of-control signals in multivariate processes based on test instances and training instances, which is effective for diagnosing processes with a large number of variables. By considering out-of-control signals, the method is able to associate the variables and diagnose some patterns that may indicate that the process is out-of-control. The basic logic of Bayesian inference is based on Bayes’ Theorem [
27]. This theorem is used to calculate the probability of an event while previously having information about it. From this theorem, Bayesian Networks have been developed, which are probabilistic models that allow to establish a graphic model considering random variables and the relationships that exist between them. The Bayesian statistics are applied when the evidence about the true value of a probabilistic event is expressed in terms of degrees of belief, that is, as Bayesian probabilities.
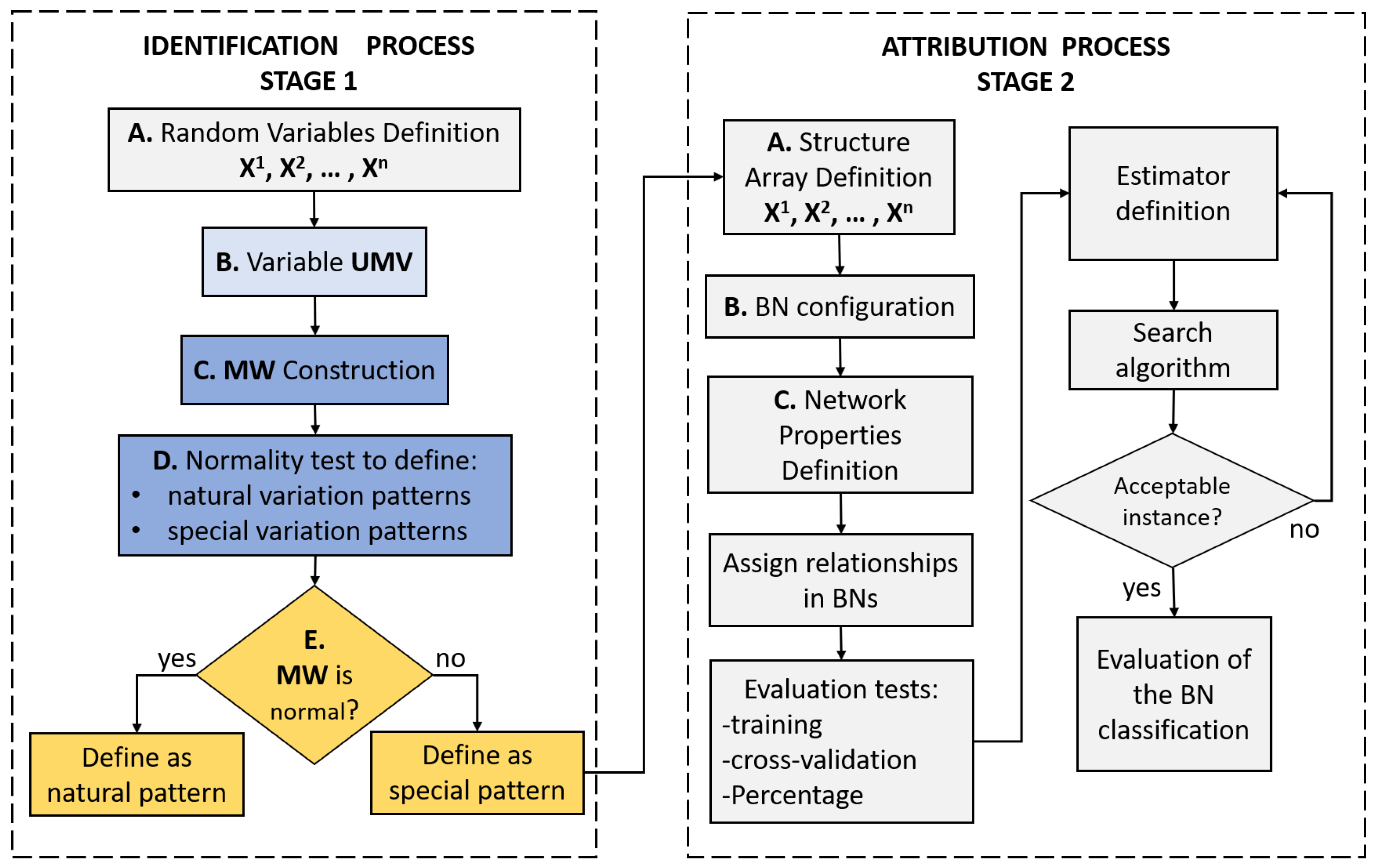
There are limitations in the MVCCs in terms of the identification of the random variables that cause an out-of-control process associated with a pattern present in the univariate variable, which is why in this article an MVPR method is presented taking as reference the structure of observable variation in the multivariate variable. The objective is to show the association of patterns present in the multivariate variable. To achieve this, a Bayesian Network is implemented to calculate the probability that an special variation pattern appears and that it comes from some specific random variable. In this research effort, Bayesian Inference is defined as an alternative approach for the identification of variables and for the MVPR without requiring the necessary assumptions in traditional CCs methods.
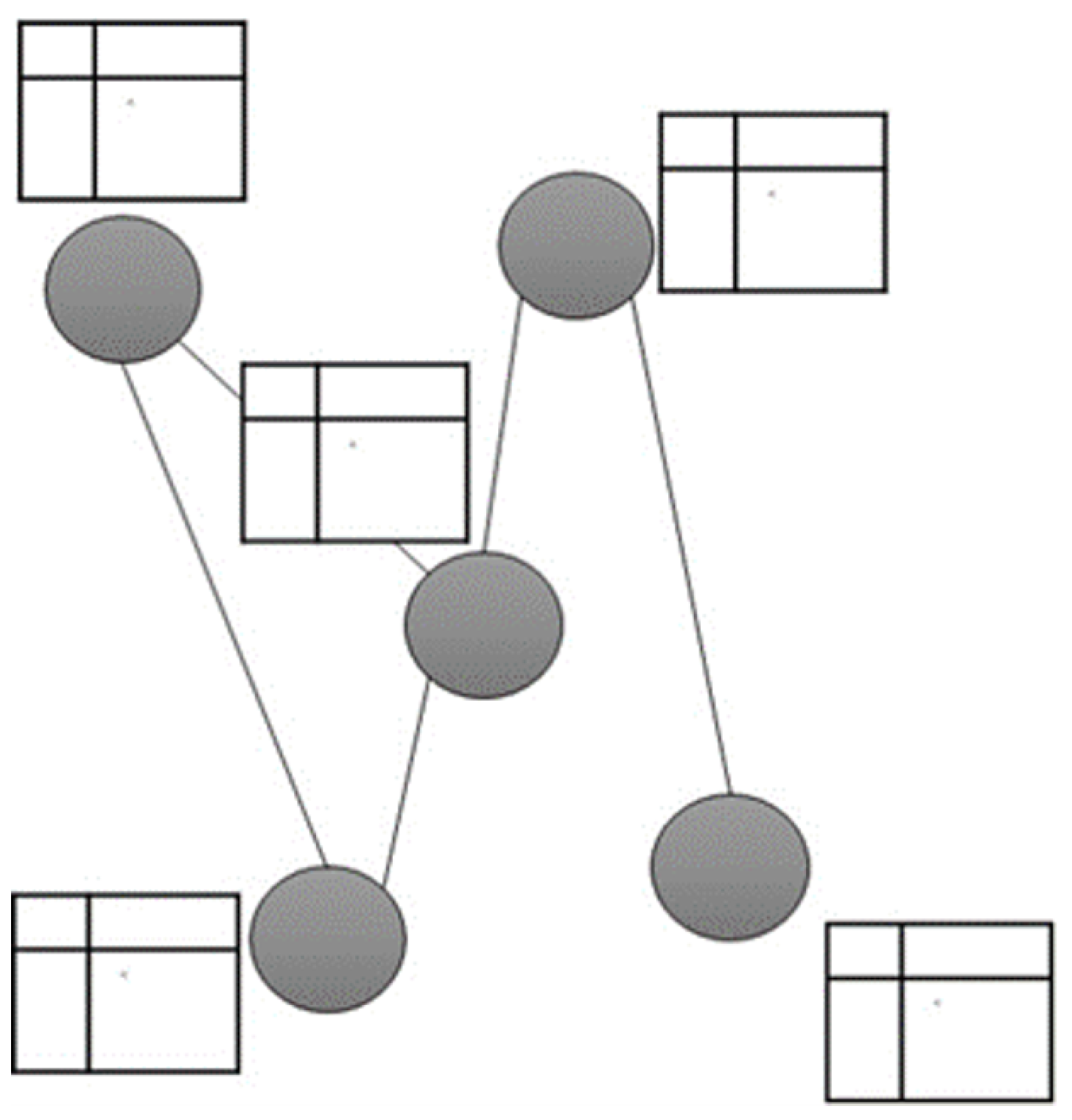
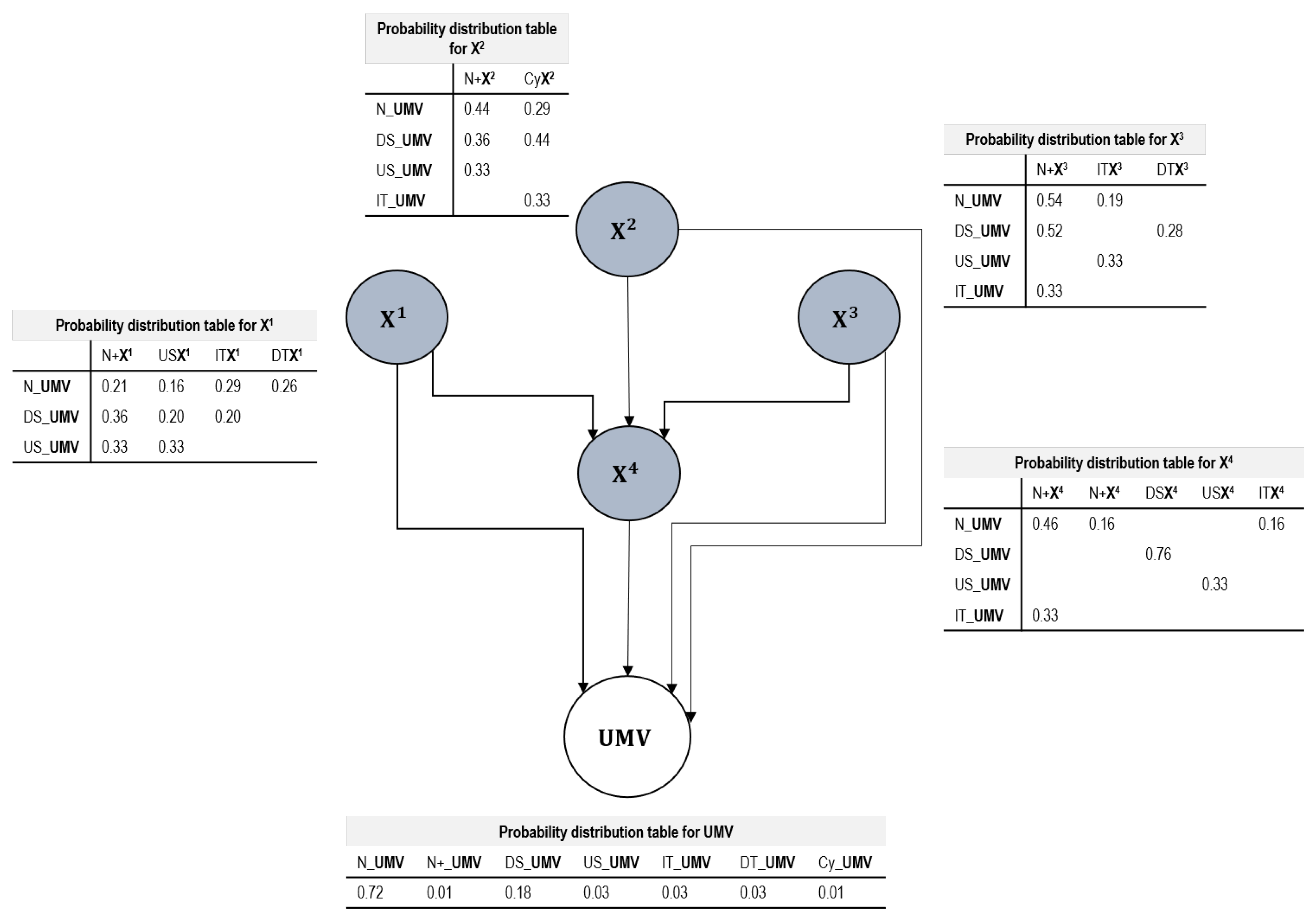
In a Bayesian Network, the data structure marks the way in which the nodes and connections are integrated, that is, the dependence and independence of each variable. A Bayesian Network is a Directed Acyclic Graph as is shown in
Figure 1.
A Directed Acyclic Graph defines a factorisation of the joint probability distribution over the variables that are represented by the nodes and the factorisation is given by the directed links. For each Directed Acyclic Graph consider: (i) G = VE where V denotes a set of nodes and E, a set of directed links between pairs of nodes, (ii) a joint probability distribution
over the set of variables indexed
by V that can be factorised as:
where
denotes the set of variables of the variable
for each node
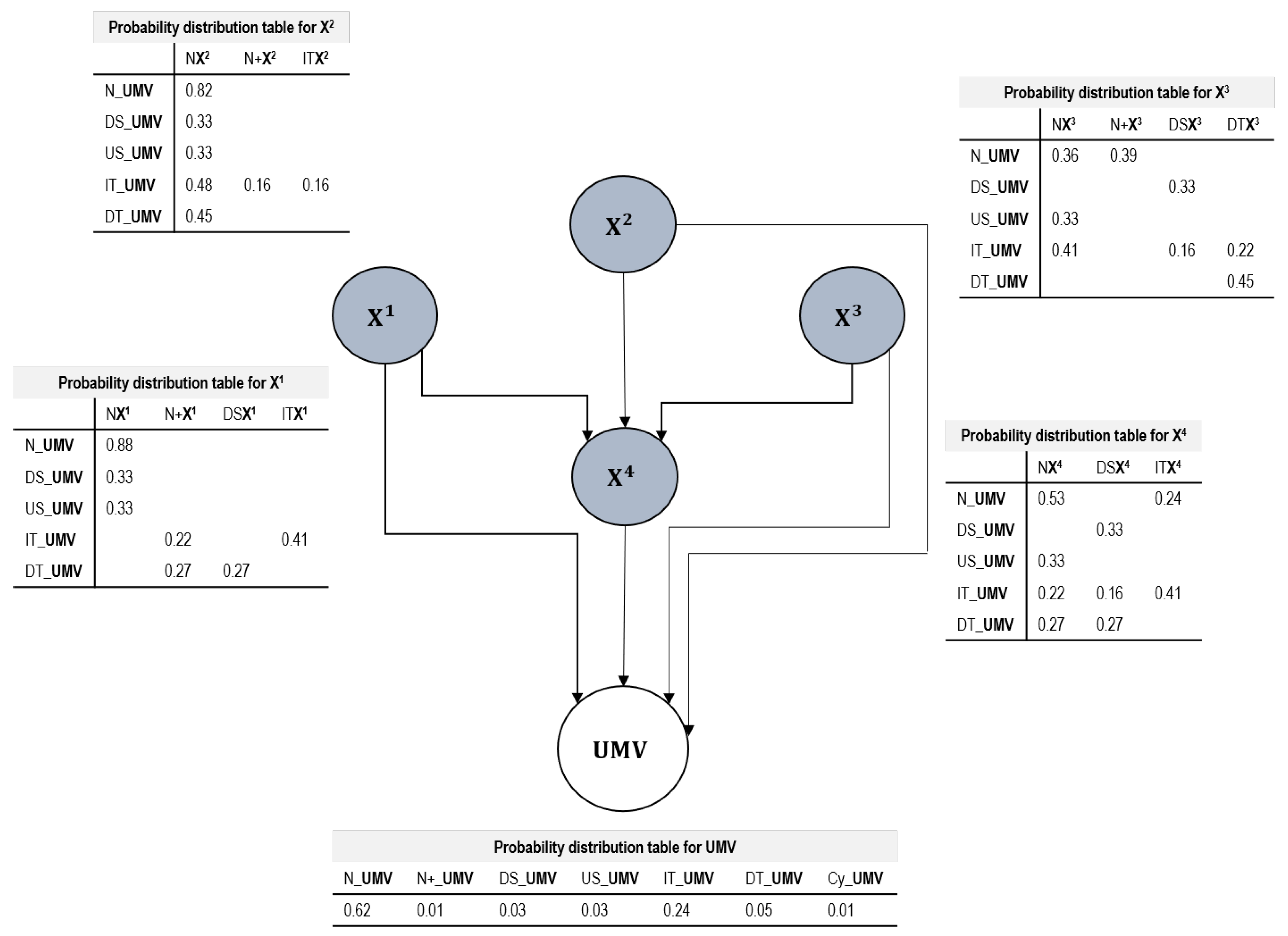
. Factorisation expresses a set of independence assumptions that are represented by the Bayesian Network in terms of pairs of nodes that are not directly connected to each other by a directed link. The existing relationships are defined in Conditional Probability Tables attached to each node that specify the probability of a particular state given the states of the main nodes [
28], which is shown in
Figure 1.
The method for the Bayesian Network validation reserves a certain amount of data for testing with the rest used for confirmation. Each class in the complete data set must be represented with the correct proportions in the training and test sets. There are numerous statistical techniques for comparing models such as cross-validation, which is recommended as one of the best ways to test a model and introduces bias when testing its validity with the same data [
29].
The K2 is a simple learning algorithm for Bayesian Networks. It starts with an order of nodes processing each node in turn and immediately considering adding edges of previously processed nodes to the current one. In each step, it adds an advantage that maximises the network score, and when there are no further improvements, the attention is directed to the next node. As an additional mechanism to avoid overfitting, the number of parents for each node can be restricted to a predefined maximum as stated in [
30].
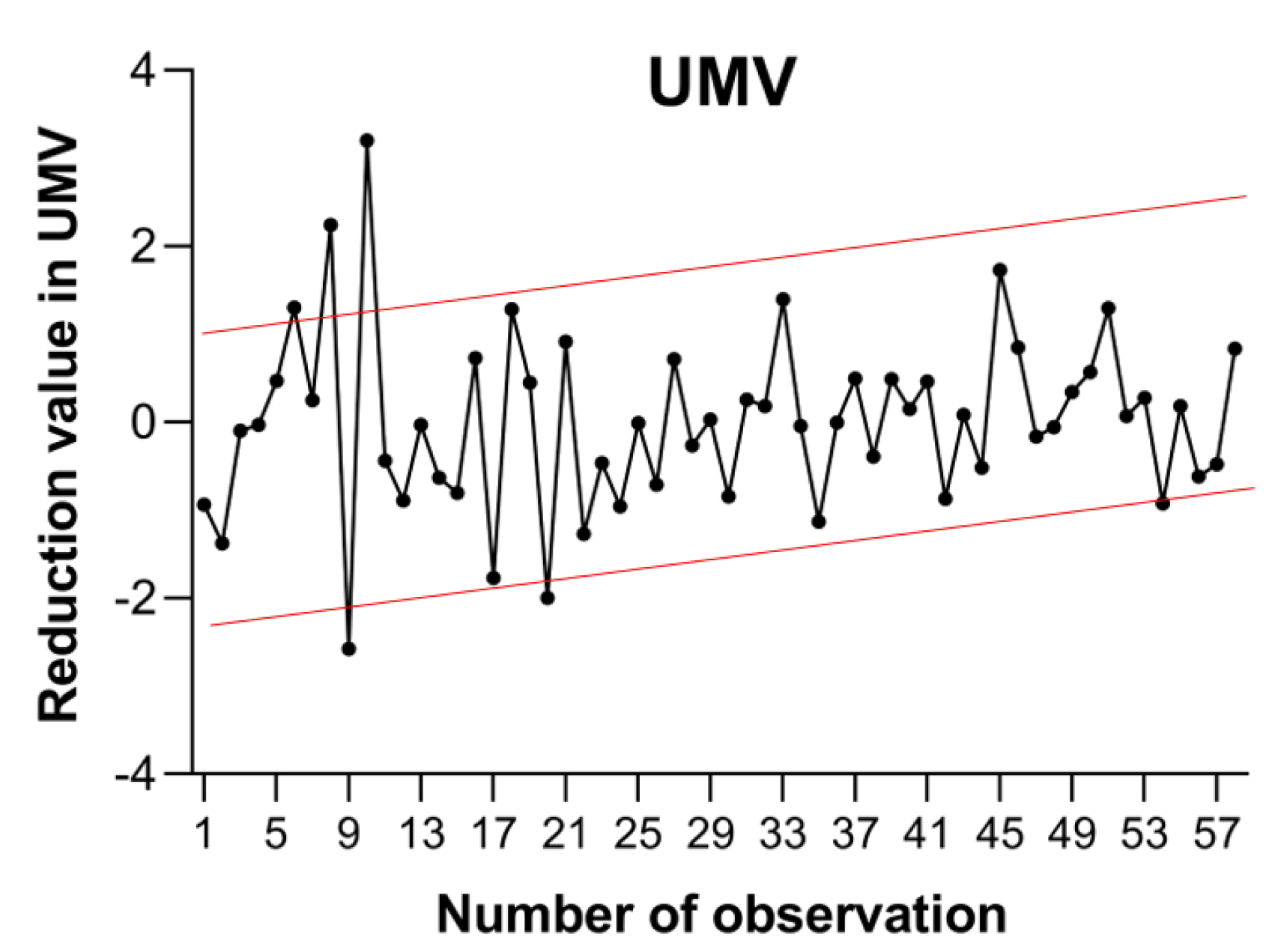
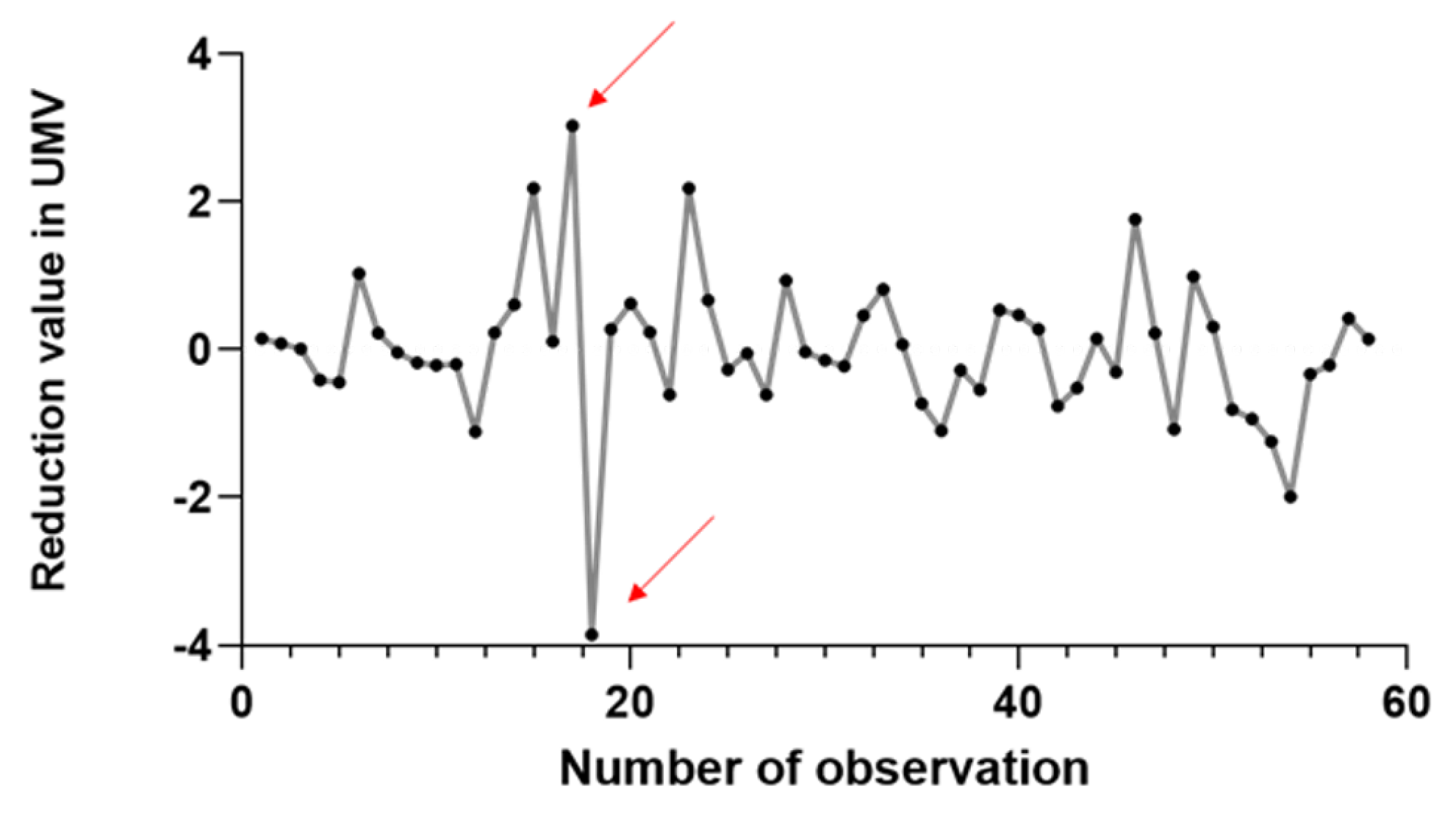
The problem that this article solves is located in multivariate statistics, which seeks to obtain simple methodological forms of analysis of the behaviour of several variables simultaneously. In a practical way, understanding more than two CCs to identify causes of special variation is a complex task and subject to errors, the so-called type 1 and 2 errors in classical statistics. This article shows how through the UMV it is possible to synthesise the variation of the 4 random variables of the study case. The complexity of the system is reduced from 4 to 1. Thus, the analytical inspection of the behaviour of the UMV leads to the generalisation of the 4 variables, without neglecting the fact that a special cause of variation affects more than one random variable.
A notable contribution from this research is the use of index numbers in the method. It is known that index numbers are a statistical measure allowing the study of variations of data series in relation to a measure defined as a base. The advantages are obtaining the properties of identity, proportionality, inalterability and homogeneity in the data series of the variables. Index numbers are used as a statistical measure to study variations of one or more variables with respect to time. With these, the random variables “p” that come from different measurement scales can be compared under the same scale, thus obtaining a way to compare these variations that originally have different magnitudes and units of measurement. Another contribution is the use of Bayesian Networks to calculate the probabilities that a multivariate pattern with special variation presents and the probability that it comes from the presence of some pattern of some specific univariate variable. The Bayesian Inference is an alternative approach for the identification of variables and for the MVPR without requiring the necessary assumptions made in traditional CCs methods.
The paper has been organised as follows: After this brief introduction, the study case is presented in
Section 2;
Section 3 formally presents our model methodology whereas simulated results and real-world case results are presented in
Section 4; finally, conclusions are given in
Section 5.
5. Conclusions
Traditional methods for pattern recognition have tried to answer three fundamental questions about what happens in the process:
1. Has a change occurred in the process?
2. When has this change occurred?
3. What are the process variables that have changed?
The first two questions are solved with the existing multivariate procedures. This novel method of MVPR using Bayesian Networks is able to answer the third question by achieving the association of patterns in a UMV. This association allowed the identification of patterns in the random variables using the concept of MW. It was observed that the graphic representation of the MWs in intervals is a smoothed and equivalent projection of the behaviour of the variables without segmentation. The Bayesian Network was able to report the types of patterns that occur in the UMV and the probability of contribution of each variable. Based on the representation of each pattern in each of the variables, the network functioned as an estimator of the patterns transmitted to the UMV.
It can be stated that it is possible to find the probabilities of occurrence of special variation pattern in the two simulated scenarios using a third degree polynomial regression. The probabilities of a pattern occurring were successfully associated using the Conditional Probability Tables provided by the Bayesian Network. In the first simulation, a correct classification of instances of 80.5% and 61.70% was found for the case of the second simulation. In both cases, the Conditional Probability Table associated the patterns found achieving the identification of the pattern present in the UMV and the influencing variable. In the case of using the network with data from a real process, the probability of occurrence of a specific pattern in the univariate variable is obtained as well as the variable that contributes the most disturbance to the identified pattern. For this scenario, a correct classification of 89.36% was achieved. This is why Bayesian Networks can be used for the association and identification of patterns that influence the UMV.
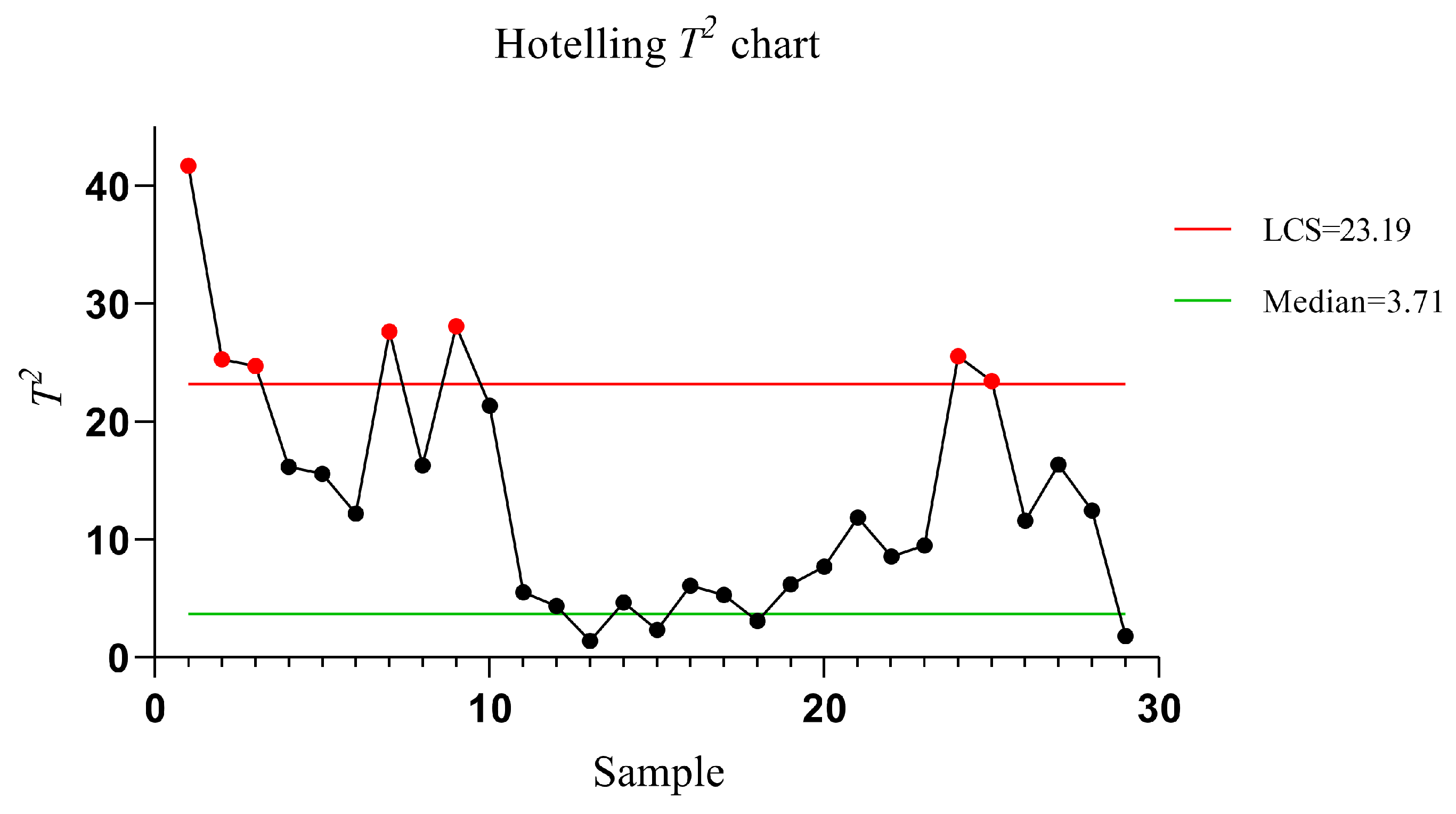
When analysing the variables of the real process with the Hotelling CC , it was observed that the behaviour of the univariate variable does not allow inferring about the variable causing an out of control point. This problem is solved with the proposed model. For this reason, identifying the variables causing special variation pattern in multivariate processes represents our contribution with practical application in the industry. The proposed model is a new approach to pattern analysis in MVCCs using information segmentation, using multivariate variable and the analysis provided by the Bayesian Networks. This multivariate pattern recognition allows to obtain information on the random variables with the greatest influence on the UMV as well as the probability of occurrence of special variation pattern in industrial processes.
For its implementation, the following is required:
(a) A process under statistical control, using traditional statistical process control.
(b) To accomplish the programming to automate the segmentation of variables and the identification of patterns.
(c) To implement the Bayesian Network programming to generate the Conditional Probability Table and the inference about the process.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}