
New Robust Cross-Variogram Estimators and Approximations of Their Distributions Based on Saddlepoint Techniques


Departamento de Estadística, I.O. y C.N., Universidad Nacional de Educación a Distancia (UNED), Paseo Senda del Rey 9, 28040 Madrid, Spain
Mathematics 2021, 9(7), 762; https://0-doi-org.brum.beds.ac.uk/10.3390/math9070762
Submission received: 20 January 2021
/
Revised: 24 March 2021
/
Accepted: 28 March 2021
/
Published: 1 April 2021
(This article belongs to the Special Issue Methodological and Applied Contributions on Stochastic Modelling and Forecasting)
Abstract
:Let be an isotropic second-order stationary multivariate spatial process. We measure the statistical association between the p random components of with the correlation coefficients and measure the spatial dependence with variograms. If two of the components are correlated, the spatial information provided by one of them can improve the information of the other. To capture this association, both within components of and across , we use a cross-variogram. Only two robust cross-variogram estimators have been proposed in the literature, both by Lark, and their sample distributions were not obtained. In this paper, we propose new robust cross-variogram estimators, following the location estimation method instead of the scale estimation one considered by Lark, thus extending the results obtained by García-Pérez to the multivariate case. We also obtain accurate approximations for their sample distributions using saddlepoint techniques and assuming a multivariate-scale contaminated normal model. The question of the independence of the transformed variables to avoid the usual dependence of spatial observations is also considered in the paper, linking it with the acceptance of linear variograms and cross-variograms.
1. Introduction and Notation
Spatial dependence is described by a variogram in the univariate case. If there is another variable correlated with the variable of interest and we want to use its spatial information, we have to use a cross-variogram, thus extending the univariate analysis to the multivariate case.
Formally, let , be an isotropic second-order stationary multivariate spatial process, with D being a fixed subset of , assuming that each component , , has an expectation and variance constant, i.e., they do not depend on the location . We also assume that the covariance between two observations depends only on the distance that separates them and not on the spatial locations.
In addition, we admit that each component possesses a variogram
where is the variance.
We measure the statistical association between the random components of with the correlation coefficients and the spatial dependence in each component with the variograms. To capture the association both within components of and across , the cross-variogram is defined as ([1], p. 67, or [2], p. 229)
, where means covariance and E means mathematical expectation.
This definition is for collocated data, i.e., assuming that each location (site) has all variables measured, a situation that we assume all over the paper.
The results refer to the pair , i.e., to a generic pair of components of the vector .
Let us also assume that we have a sample of at m locations , obtaining m (p-dimensional) observations . Hence, the data matrix is a matrix where the th element is the observation of component at location .
The definition of new robust estimators against outliers of the cross-variogram and their sample distributions are the aims of this paper.
Until now, there were only two robust estimators previously defined by [3]. This author considered the covariance estimation method to obtaining two somewhat weird and difficult to apply estimators. Here, we consider the location estimation method, extending the idea considered first in [4] and followed in [5] to the multivariate case.
To do this, we start with the classical (non-robust) method-of-moments estimator, defined as
with the sample size being and where the cardinality of .
It is usually assumed that spatial data follow a normal distribution, but this is unrealistic because, in practice, they are contaminated by occasional outliers. For this reason, we assume in the paper a model close to the normal, i.e., a normal-like model in the central region but with heavier tails than the normal, namely, a multivariate-scale-contaminated normal distribution with joint probability density function (pdf):
where ; ; denotes the pdf of a p-variate normal random vector with mean vector and covariance matrix , a matrix with values in its diagonal, .
In this framework, represents the small proportion of outliers in the sample (e.g., the proportion of extreme weather events affecting at all locations) and g represents the extent of the contamination. If or , this model reduces to the multivariate normal distribution and, if and , it resembles the normal in the central part but with heavier tails.
This is the usual way in which robust statistics handles the nonnormality of the data: establishing a neighborhood of the standard model distribution, the contamination neighborhood, inside which the underlying model is located (e.g., [6,7,8], p. 12, or [9], p. 870).
From this joint distribution, the marginal distributions of the are the univariate scale contaminated normal models:
The paper is organized as follows. In Section 2, we consider a consecutive pair of transformations of the initial observations to avoid their dependence. With these, we can use standard techniques for independent and identically distributed (iid) random variables. We also obtain in that section the distribution of these new variables. Here, we have a remarkable difference with respect to the paper by [5]: there, the transformed variables were the square of standard normal variables, i.e., distributed random variables, but here, we have the product of two different normal variables.
In Section 3, cross-variogram M-estimators based on the new variables are defined. The von Mises plus saddlepoint (VOM+SAD) approximations for their distributions are also obtained, approximations that are applied to the classical method-of-moment estimator in Section 4. This is the first time that a closed form approximation of its distribution is obtained. Simulations of approximation accuracy and lack of robustness of its distribution are included.
In Section 5, we define the -trimmed cross-variogram estimator and we obtain the VOM+SAD approximation for its distribution. We do the same for the Huber’s cross-variogram estimator in Section 6. We include here a simulation study to compare the robustness of the three estimators as we increase the degree of contamination.
Section 7 is devoted to analyzing the dependence of the transformed variables on the linearized cross-variogram models. We conclude the paper with two examples of real data.
Finally, in Section 8, we give some conclusions, ending the paper with an Appendix, which contains the technical details obtained in the paper.
2. Preliminary Transformation
The usual dependence between spatial observations does not allow for the use of techniques for iid variables. Nevertheless, it is possible to skip this restriction by transforming the initial observations .
Namely, let us define the gap or lag variable as
The cross-variogram is now
the mean of the product, and its classical estimator, the method-of-moments estimator,
The sample mean of the variables , , is non-robust then.
This is the reason why we say that we use the location estimation way: the parameter is the mean, and the classical estimator is the sample mean. In this manner, instead of considering a weird estimator for a strange parameter of the initial distribution, we propose to transform the original (and usually dependent) observations into new data (independent under some conditions) obtaining a natural parameter of the new variable (its mean) for which a manageable estimator (the sample mean) should be feasible. Then, standard techniques of robustification can be applied.
An important problem is determining the distribution of this new variable from the original normal (or contaminated normal) distribution of to later obtain the distribution of the robust estimators obtained, where is now the product of two different normal variables.
2.1. Correlation between and
First, let us define two new functions that are natural extensions of the similar ones associated with the variogram.
Let us call cross-covariogram between and to the function (provided it is well defined)
that will be equal to .
Here, a will be t or t + h and b will be s or s + h, and thus, and , where the equality between the expectations is obtained because of the intrinsic stationary property of the components of Z.
Analogously, we assume the equality of the variances in locations that are distanced by a lag h, , and .
Let us also define the cross-correlogram as
Now, the covariance between and will be (see the Appendix A for details)
Thus, the correlation between and will be zero if
Because locations are fixed in advance (for instance, they could be sample stations) we assume that they are equally spaced on a transect, for instance, in Figure 2.1 of [1], i.e., they are data on a regular grid. Hence, we can match two contiguous (for which the dependence is supposed to be the strongest), so that it is t + h = s.
Now, the previous condition of correlation equal to zero is obtained if
or, in terms of the cross-covariogram, when
On the other hand, with a little of algebra, the cross-variogram can be expressed as (see Appendix A for details)
i.e.,
and then, it will be
Replacing these values of and in (2), we obtain
i.e., the correlation between and will be 0 when
i.e., if a linear cross-variogram can be accepted as model (because, theoretically, the nugget is 0).
Remark 1.
The increments and have as joint cumulative distribution function, if they are uncorrelated,
Hence, if and are uncorrelated, with probability , they are independent under model and, with probability , they are independent under model , being a mixture of independent variables. For this reason, these variables are considered in the paper as independent if they are uncorrelated, following the idea of [4].
2.2. Independence of the Observations
The method-of-moments estimator was expressed as the sample mean of the variables , . Considering only two of them, and , if we can accept a linear variogram for the variable and a linear variogram for the variable , it was proved in [5] that will be independent of and that will be independent of , .
If, additionally, we can accept a linear cross-variogram for the couple , the variables and , and and will be independent.
As a conclusion, if we could accept a linear variogram for the variable , a linear variogram for the variable , and a linear cross-variogram for this pair, the variables , , could be considered independent, a situation that we assume in the paper and to which we shall return later.
2.3. Distribution of the Transformed Variables
Therefore, the initial observations , normal or contaminated normal distributed, are transformed into the lag variables and, finally, into their product . The reason for this transformation is to express the classical estimator as a sample mean of independent variables (if linear variograms and cross-variogram can be accepted), obtaining a nice mathematical expression for the estimator, very useful in the definition of new robust estimators of of location and in the determination of its sample distribution, thanks to this location estimation way.
The problem is that, although, initially, the are contaminated normal variables, after two transformations, we do not have normality in . In what follows, we obtain their distributions.
Proposition 1.
(a) If , then .
(b) If , then .
(Proof in the Appendix A).
To obtain the distribution of we use two results from Nadarajah and Pongány (2016).
Proposition 2.
([10], p. 202, Theorems 2.1 and 2.2)
(a) Let denote a bivariate normal random vector with zero means, unit variances, and correlation coefficient ρ. Then, the pdf of is
, where is the modified Bessel function of the second-order zero.
(b) If () is a random sample of , the pdf of their sample mean is
, where , , and is the modified Bessel function of the second-order b.
Thus, if is a bivariate scale contaminated normal variable with distribution
the variable will be a bivariate scale contaminated normal variable with distribution
where, in , the two elements of the diagonal are and and the correlation coefficient between and is
equal to the correlation coefficient between and , usually shortened as in the rest of the paper. Hence, it will be
3. Cross-Variogram -Estimators
Because the method-of-moments estimator is the sample mean of the transformed variables , this estimator is robustified as it is the sample mean, but here, the model distribution of the observations is somewhat peculiar, with the computations being more elaborated.
Firstly, we define a large class of cross-variogram estimators for which their robustness can be controlled. We call cross-variogram M-estimators, with score function , to the solution of the equation:
where are the variables previously considered and we assume that is monotonically decreasing in for all x. In fact, is an estimator for a location problem, with being of the form , with monotonically increasing in u, [11].
We can control the robustness of the cross-variogram M-estimators, choosing a bounded score function. Other robustness properties, such us the breakdown point, can also be applied to this class of estimators.
3.1. Von Mises Approximation for their Distributions
If is an estimator where F is the underlying model distribution of the observations, the tail probability can be expressed at another model G using the von Mises expansion as [12,13,14]:
where is Hampel’s influence function of the tail probability functional, called tail area influence function (15] and defined as
for all where the right-hand side exists.
This influence function is calculated by changing the underlying model G using a contaminated model before computing the first derivative at , with being the distribution that assigns mass 1 at x.
If distributions F and G are close enough, we can use the von Mises approximation (VOM)
to compute the distribution of under the underlying model F using model G.
In particular, if F is a mixture the von Mises expansion is
because . The von Mises approximation (7) will be then
Distribution G plays an important role in the VOM approximation because we can choose it such that we know the tail probability of the leading term, . Distribution G is called the pivotal distribution, and let us observe that is also computed for this pivotal distribution.
3.2. Saddlepoint Approximation of the TAIF
In order to use von Mises approximation (8) for location M-estimators, we compute a saddlepoint approximation (SAD) of the , using Lugannani and Rice’s formula, [16] ([17], p. 77, or better, [8], p. 314). We use the approximation given in [11] for M-estimators and, following the same computations as that in [18], pp. 402–404, we have that
where is the density function of the standard normal distribution, and s and are the functionals
with
being the cumulant generating function of distribution G; being the second partial derivative of with respect to the first variable ; and being the saddlepoint, i.e., the solution of the saddlepoint equation
4. Sample Distribution of the Method-of-Moments Estimator
Not all the cross-variogram M-estimators are robust. For instance, the classical method-of-moment estimator is not robust because its score function is not bounded. Nevertheless, we compute its VOM+SAD approximation to show its lack of robustness next and because its distribution will be useful in the determination of the distribution of some robust versions of it.
Due to being an M-estimator with score function , we can use approximation (10). Its leading term is computed with respect to distribution , where is the cumulative distribution function for which the pdf is , given by (3) in Proposition 2.
Thus, the leading term in (10) is
where and where is the pdf given by (4) because, now, the previous tail probability is the tail probability of the sample mean of the product of two standard normal distributions.
The rest of the elements in approximation (10) essentially depend on the cumulant generating function of distribution G and are described in the Appendix. All of them are very easy to program with R. They are computed in the Supplementary Materials available on the website. https://www2.uned.es/pea-metodos-estadisticos-aplicados/cross-variogram.htm (accessed on 22 February 2021).
4.1. Performance of the Theoretical Results with Simulations
We can see how accurate the VOM+SAD approximation is for the method-of-moments estimator with a simulation study, considering a sample size as small as . We considered a bivariate normal distribution with mean vector and covariance matrix such that and are the marginal variances and the covariance for . We consider four different situations: no contamination, contamination , contamination , and contamination .
Under these conditions, we obtain Figure 1 in which we appreciate that the approximations are very good, especially in the tails, which are the areas of interest for tests and confidence intervals.
We include in Table 1 some values of Figure 1 (see the Supplementary Materials, p. 6): values of the VOM+SAD approximation and exact ones obtained with the simulation.
4.2. Robustness of the Method-of-Moments-Estimator
We can observe the lack of robustness of the distribution of the method-of-moments-estimator in Figure 2 as we increase or g.
The programs in R, used to obtain this figure, are in the Supplementary Materials.
Remark 2.
The sample size , considered in each estimation, depends on the value of the lagh, that is fixed in advance. Ifhis small, the number of lags will be large and will be small. The VOM+SAD approximations obtained in the paper are very accurate, even in this case.
Nevertheless, ifhis large, the number of lags will be small and the sample size will be large. In this case, it is easier to compute the leading term as
using the central limit theorem because
is the product of two standard normal variables with correlation coefficient . The characteristic function of this product is (expression (4) in [10])
and then, the mean of this product variable is and the second moment about the origin is . Hence, the variance will be and the leading term can be computed if is large, as
Since, if or , the scale contaminated normal distribution is just a normal distribution, this last expression is an approximation for the distribution of the classical method-of-moments estimator under the usual underlying normal distribution model.
5. -Trimmed Cross-Variogram Estimator
Another robust estimator for the cross-variogram, which is not an M-estimator, can be obtained by trimming the observations as follows:
Considering the initial pair of variables and , and transforming them to the couple and and finally to the product , if we trim the of the smallest and the of the largest ordered data , the (symmetrically) sample α-trimmed cross-variogram estimator is defined as
where if stands for the integer part.
To obtain an approximation for its sample distribution, we use an accurate VOM+SAD approximation obtained in [21]. From Corollary 1 therein, we can approximate the small sample distribution of the sample -trimmed cross-variogram when the observations come from , with k iterations (k large), by the VOM+SAD approximation to the distribution of the method-of-moments-estimator , obtained in the previous section, as
where and .
In the bottom row of Figure 3, we plot the tail probability of the -trimmed cross-variogram estimator with no contamination () and with two percentages of contamination: and , with the sample size being .
We observe in this figure that, as we increase the contamination percentage, i.e., as we increase , the tail probabilities obtained with the trimmed cross-variogram estimators are affected but by less than those obtained with the classical method-of-moments estimator. We see this by comparing the first row of figures (non-trimmed cross-variogram estimators) with the second row of figures (trimmed cross-variogram estimators).
6. Huber’s Cross-Variogram Estimator
If the function, , used to obtain the M-estimator in Equation (6) is the Huber’s function , the M-estimator obtained is called the Huber’s cross-variogram estimator, . Since its score function is bounded, this estimator will be robust.
An approximation for its distribution can be obtained from (10). Nevertheless, the leading term is not easy to compute. For this reason, in this case, we use the Lugannani and Rice formula to approximate this leading term, the VOM+SAD approximation for the distribution of the Huber’s cross-variogram estimator being the following:
where the saddlepoint is such that
with G and H being the distributions that appear in (5), and where all the functionals , and s are computed with respect to model G.
This approximation may seem complicated but it is easy to compute using the huber function of the MASS library, [23].
Example 1.
In order to analyze the behaviour of the robust estimators defined in the paper, we compare them with the classical method-of-moments estimator, carrying out a simulation study in which we compare the -trimmed and Huber’s variogram estimators with the classical one.
The study consists of a simulation of two spatial and statistical correlated variables and , both with a normal distribution, in different situations, with some of them considered, for instance, in [4]:
- (A)
- No contamination, ;
- (B)
- ;
- (C)
- ;
- (D)
- ;
- (E)
- ;
- (F)
- ;
- (G)
- .
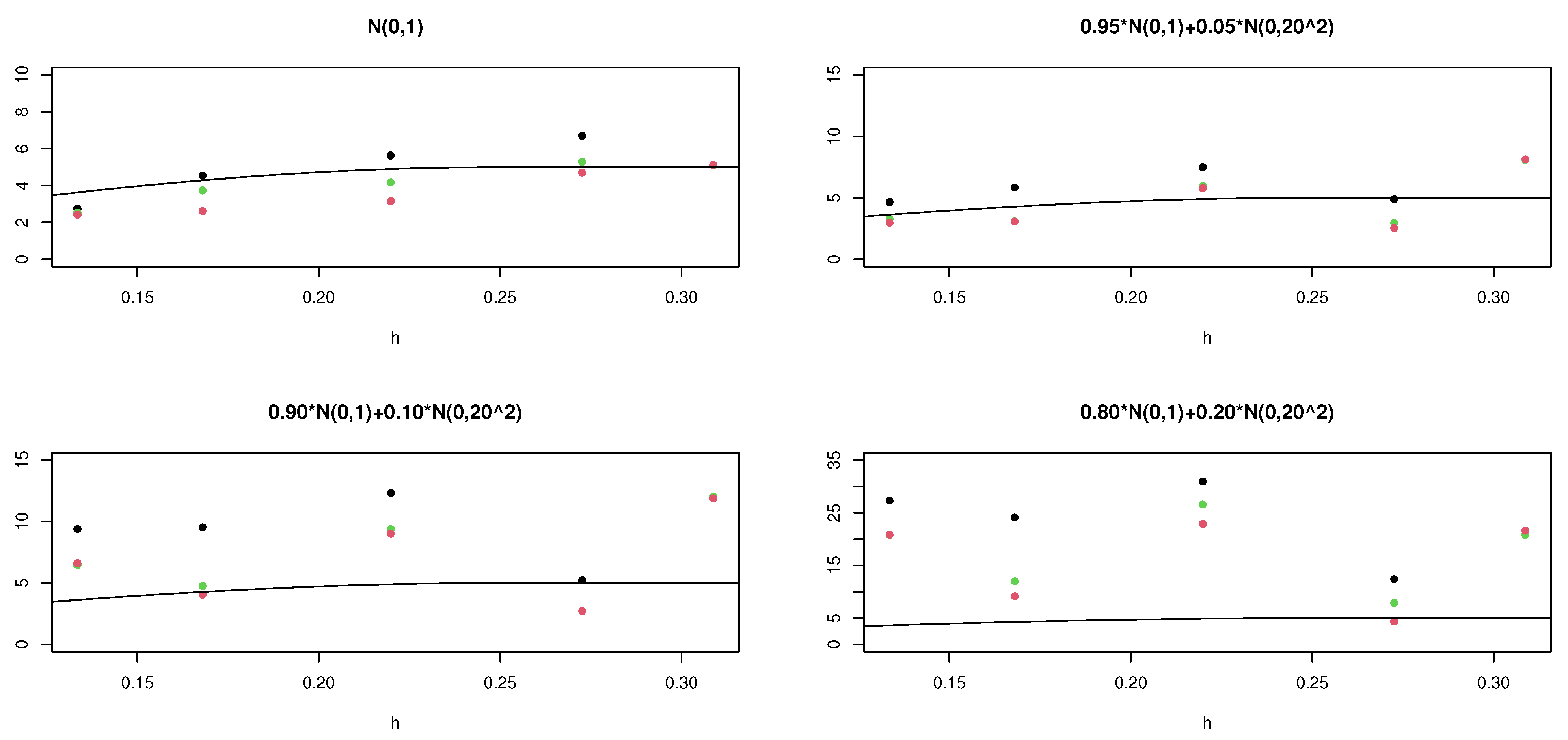
The details of the simulations are in the Supplementary Materials. In these simulations, we observe less sensitivity in the robust estimators than in the classical one, as we increase the contamination in the model. We appreciate this in Figure 4 and Figure 5. In the first one, we observe that the classical variogram model can be accepted for the three estimations in case (A), where there is no contamination. Nevertheless, as we increase the contamination (Figure 5), this variogram model does not represent the classic variogram estimations; only in some cases it represents the 0.1-trimmed variogram estimations, and it can be accepted when we consider Huber’s variogram estimations except, perhaps, in the last case, where it is doubtful.
7. Linearized Version of the Cross-Variogram Model
We saw at the end of Section 2.2 that, if linear models can be accepted as variograms and cross-variograms, the variables can be considered independent. These linearized versions of the model (classical and robust) were introduced in Section 9 of [5] and can be applied to model the cross-variogram. They essentially consists of replacing, before the range, the increasing part of the traditional variogram, or cross-variogram, using the regression line and, after the range, using the sill (or the robust sample mean in the robust linearized version).
Additionally, the test defined in Section 10.1 of [5] can be used to check if these models can be accepted, using saddlepoint approximations for the robust (and classical) estimators of the variograms and cross-variograms.
Namely, we test the null hypothesis of a particular variogram or cross-variogram model from which we obtain the theoretical variogram values (or cross-variogram values )) using as test statistic
or
assuming that we consider K lags.
If we unify both as
the cumulative distribution function of is (see [5])
probabilities that are computed with the VOM+SAD approximations.
We remark that the number K of lags (and hence the value of ) can be modified to obtain the desired linearity.
Example 2.
Let us consider prediction data, included in the jura data set from Pierre Goovaerts’ book that contains geolocated information of several variables. This data set is calledprediction.datin the R library,gstat.
Two correlated variables, with a distribution similar to a scale contaminated normal model, are ln(Pb) (natural logarithm of Lead) and Ni (Nickel).
The values of the classical method-of-moments estimator, the 0.1-trimmed cross-variogram estimator, and the Huber’s cross-variogram estimator (with tuning constant ) are easily obtained for these variables, as can be seen in the Supplementary Materials. The lag distant chosen was . These values are shown in Figure 6.
To use their distributions, obtained in the paper, it is necessary to check if we can accept linear variograms for these two variables and a linear cross-variogram for the pair, as it was pointed out in Section 2.2. If this is the case, the variables , can be considered independent.
Assuming as underlying model, a scale contaminated normal with and , the linearized versions of the variograms for the logarithm of Lead are shown in Figure 7. The linearized versions of the variograms for Nickel are shown in Figure 8.
Finally, the linearized versions for the cross-variograms models are shown in Figure 9.
From a visual point of view, all these linearized versions can be accepted using the test considered in Section 7. The values of the test statistics and the p-values are given in Table 3 (see the Supplementary Materials). Thus, the independence of the can be accepted.
We conclude the paper with a real-data example in which we observe how robust cross-variogram estimations provide models less sensitive to outliers, which will lead us to a more robust cokriging.
Example 3.
Let us consider the geolocated pollution data, included in the Supplementary Materials, that are the 2017 average concentrations of four air pollutants in the Community of Madrid (Spain): nitrogen monoxide (NO), nitrogen dioxide (NO2), suspended particles with a size less than 10 microns (PM10), and ozone (O3). These data are obtained from 22 monitoring stations [24,25,26].
Two of these 4 variables are strongly correlated and have a distribution similar to a scale contaminated normal model; they are NO and NO2.
The variogram-crossvariogram matrix of the classical variogram and cross-variogram estimators along with classical least squares model (Mather’s model in this case) are shown in Figure 10.
The values of the classical method-of-moments estimator, the 0.1-trimmed cross-variogram estimator, and the Huber’s cross-variogram estimator (with tuning constant ) for these variables are obtained in the Supplementary Materials. These values are shown in Figure 11, along with the linearized cross-variogram models.
We observe that, at first lag, the three estimations agree. In the others, we can see the soft effect of the 0.1-trimmed cross-variogram and Huber’s cross-variogram estimators.
The linearized versions of the variograms and cross-variogram can be accepted, and therefore, the independence of the transformed variables , .
Moreover, we appreciate the influence of the outliers in the estimation of the (linearized) cross-variogram in Figure 11 and, therefore, on the cokringing obtained with classical cross-variogram models. Thus, the use of robust estimators of the cross-varogram will be more reasonable in order to obtain a robust cokriging.
8. Conclusions
In this paper, we introduced new robust cross-variogram estimators and we obtained saddlepoint approximations for their distributions when the underlying model is a scale-contaminated normal distribution. We also obtained an approximation for the distribution of the method-of-moments estimator.
These approximations are especially useful when the sample size is small, a situation that we have when the size of the lag h is small.
We also proposed a suitable transformation of the initial observations to avoid the traditional dependence of the spatial observations. We see that is that linear variograms and a linear cross-variogram can be accepted as models to obtain this.
Supplementary Materials
The following are available online at https://www2.uned.es/pea-metodos-estadisticos-aplicados/cross-variogram.htm.
Funding
This work was partially supported by grant PGC2018-095194-B-I00 from the Ministerio de Ciencia, Innovación y Universidades (Spain).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The author is very grateful to the referees and to the assistant editor for their kind and professional remarks.
Conflicts of Interest
The author declare no conflict of interest.
Appendix A
Proof of Proposition 1.
If is a variable with normal distribution, , where stands for “X is distributed as H”; then, it is because of the intrinsic stationary property of .
If has a distribution , the cumulative distribution function of will be
where is the cumulative distribution function of the standard normal distribution. □
Elements of Approximation (10) for the Method-of-Moments estimator
using expression (4) in Nadarajah and Pongány (2016) and with being the correlation coefficient between and , mentioned above.
Hence, the saddlepoint equation from which we obtain the saddlepoint is
References
- Cressie NAC. Statistics for Spatial Data; John Wiley & Sons: New York, NY, USA, 1993. [Google Scholar]
- Bivand, R.S.; Pebesma, E.J.; Gómez-Rubio, V. Applied Spatial Data Analysis with R, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Lark, R.M. Two robust estimators of the cross-variogram for multivariate geostatistical analysis of soil properties. Eur. J. Soil Sci. 2003, 54, 187–201. [Google Scholar] [CrossRef]
- Cressie, N.; Hawkins, D.M. Robust estimation of the variogram: I. J. Int. Assoc. Math. Geol. 1980, 12, 115–125. [Google Scholar] [CrossRef]
- García-Pérez, A. Saddlepoint approximations for the distribution of some robust estimators of the variogram. Metrika 2020, 83, 69–91. [Google Scholar] [CrossRef]
- Huber, P.J. Robust estimation of a locaion parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Tukey, J.W. A survey of sampling from contaminated distributions. In Contributions to Probability and Statistics: Essays in Honor of Harold Hotelling, Stanford Studies in Mathematics and Statistics; Oklin, I., Ed.; Stanford University Press: Palo Alto, CA, USA, 1960; Chaper 39; pp. 448–485. [Google Scholar]
- Huber, P.J.; Ronchetti, E.M. Robust Statistics, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2009. [Google Scholar]
- Ebner, B.; Henze, N. Tests for multivariate normality–a critical review with emphasis on weighted L2-statistics. Test 2020, 29, 845–892. [Google Scholar] [CrossRef]
- Nadarajah, S.; Pongány, T.K. On the distribution of the product of correlated normal random variables. Comptes Rendus Math. 2016, 354, 201–204. [Google Scholar] [CrossRef]
- Daniels, H.E. Saddlepoint approximations for estimating equations. Biometrika 1983, 70, 89–96. [Google Scholar] [CrossRef]
- Withers, C.S. Expansions for the distribution and quantiles of a regular functional of the empirical distribution with applications to nonparametric confidence intervals. Ann. Stat. 1983, 11, 577–587. [Google Scholar] [CrossRef]
- Serfling, R.J. Approximation Theorems of Mathematical Statistics; John Wiley & Sons: New York, NY, USA, 1980. [Google Scholar]
- Ronchetti, E. Accurate and robust inference. Econom. Stat. 2020, 14, 74–88. [Google Scholar] [CrossRef]
- Field, C.A.; Ronchetti, E. A tail area influence function and its application to testing. Sequential Anal. 1985, 4, 19–41. [Google Scholar] [CrossRef]
- Lugannani, R.; Rice, S. Saddle point approximation for the distribution of the sum of independent random variables. Adv. Appl. Probab. 1980, 12, 475–490. [Google Scholar] [CrossRef]
- Jensen, J.L. Saddlepoint Approximations; Clarendon Press: Oxford, UK, 1995. [Google Scholar]
- Von García-Pérez, A. Mises approximation of the critical value of a test. Test 2003, 12, 385–411. [Google Scholar] [CrossRef]
- García-Pérez, A. Another look at the Tail Area Influence Function. Metrika 2011, 73, 77–92. [Google Scholar] [CrossRef]
- García-Pérez, A. A linear approximation to the power function of a test. Metrika 2012, 75, 855–875. [Google Scholar] [CrossRef]
- García-Pérez, A. A Von Mises approximation to the small sample distribution of the trimmed mean. Metrika 2016, 79, 369–388. [Google Scholar] [CrossRef]
- Field, C.A.; Ronchetti, E. Small Sample Asymptotics; Lecture Notes-Monograph Series; Institute of Mathematical Statistics: Hayward, CA, USA, 1990; Volume 13. [Google Scholar]
- R Development Core Team. A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Viena, Austria, 2020; Available online: http://www.R-project.org (accessed on 22 February 2021).
- Council-Enviroment. Department of the Madrid Environment: Air Quality Monitoring System. 2018. Available online: http://www.mambiente.munimadrid.es/opencms/opencms/calaire/consulta/descarga_\opendata.html?__locale=es (accessed on 22 February 2021).
- Council-Enviroment. Environmental Management, Council of the Environment, Local Administration and Territorial Planning, Atmospheric Quality Area-Air Quality Network. 2018. Available online: http://gestiona.madrid.org/azul_internet/html/web/2.htm?ESTADO_MENU=2 (accessed on 22 February 2021).
- Núñez-Alonso, D.; Pérez-Arribas, L.V.; Manzoor, S.; Cáceres, J.O. Statistical Tools for Air Pollution Assessment: Multivariate and Spatial Analysis Studies in the Madrid Region. J. Anal. Methods Chem. 2019, 2019, 9753927. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Approximate tail probabilities (in black) and simulated (in red) for the method-of-moments estimator with sample size , with no contamination, and with three different degrees of contamination .
Figure 1.
Approximate tail probabilities (in black) and simulated (in red) for the method-of-moments estimator with sample size , with no contamination, and with three different degrees of contamination .

Figure 2.
Tail distribution of the method-of-moments estimator with sample size and two underlying models: and , for three different degrees of contamination .
Figure 2.
Tail distribution of the method-of-moments estimator with sample size and two underlying models: and , for three different degrees of contamination .

Figure 3.
Tail probabilities of the classical method-of-moments cross-variogram estimator (top row of figures) and -trimmed cross-variogram estimator (bottom row of figures), with no contamination, , and contaminations and .
Figure 3.
Tail probabilities of the classical method-of-moments cross-variogram estimator (top row of figures) and -trimmed cross-variogram estimator (bottom row of figures), with no contamination, , and contaminations and .

Figure 4.
Variogram estimations of Example 1: classical (black), 0.1-trimmed (green) and Huber’s (red), and the variogram model with no contamination.
Figure 4.
Variogram estimations of Example 1: classical (black), 0.1-trimmed (green) and Huber’s (red), and the variogram model with no contamination.

Figure 5.
Variogram estimations of Example 1: classical (black), 0.1-trimmed (green) and Huber’s (red), and the variogram model with no contamination.
Figure 5.
Variogram estimations of Example 1: classical (black), 0.1-trimmed (green) and Huber’s (red), and the variogram model with no contamination.

Figure 6.
Classical (black) and robust (green and red) cross-variogram estimations of Example 2.

Figure 7.
Classical (black) and robust (green and red) variogram estimations for the logarithm of lead and their linearized variograms of Example 2.
Figure 7.
Classical (black) and robust (green and red) variogram estimations for the logarithm of lead and their linearized variograms of Example 2.

Figure 8.
Classical (black) and robust (green and red) variogram estimations for nickel and their linearized variograms of Example 2.
Figure 8.
Classical (black) and robust (green and red) variogram estimations for nickel and their linearized variograms of Example 2.

Figure 9.
Classical (black) and robust (green and red) cross-variogram estimations, linearized versions, and the classical model (blue) of Example 2.
Figure 9.
Classical (black) and robust (green and red) cross-variogram estimations, linearized versions, and the classical model (blue) of Example 2.

Figure 10.
Variogram-crossvariogram matrix of the classical variogram and cross-variogram estimations with the classical model of Example 3.
Figure 10.
Variogram-crossvariogram matrix of the classical variogram and cross-variogram estimations with the classical model of Example 3.

Figure 11.
Classical (black) and robust (green and red) cross-variogram estimations of Example 3, with the linearized cross-variogram models.
Figure 11.
Classical (black) and robust (green and red) cross-variogram estimations of Example 3, with the linearized cross-variogram models.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Tail probabilities of the VOM+SAD approximation and the exact (simulated) values for the method-of-moments estimator of Figure 1.
Table 1.
Tail probabilities of the VOM+SAD approximation and the exact (simulated) values for the method-of-moments estimator of Figure 1.
| No Contamination | ||||||
|---|---|---|---|---|---|---|
| Approximation | Exact | Approximation | Exact | Approximation | Exact | |
| 0.26627 | 0.27903 | 0.27101 | 0.28199 | 0.28524 | 0.29635 | |
| 0.11944 | 0.12512 | 0.12319 | 0.12904 | 0.13443 | 0.13795 | |
| 0.05052 | 0.05665 | 0.05302 | 0.05895 | 0.06053 | 0.06312 | |
| 0.03189 | 0.03671 | 0.03386 | 0.03727 | 0.03978 | 0.04304 | |
| 0.01950 | 0.02451 | 0.02102 | 0.02449 | 0.02560 | 0.02811 | |
Table 2.
Relative errors of the VOM+SAD approximation, in %.
| No Contamination | |||
|---|---|---|---|
| 1.7698 | 1.5292 | 1.5789 | |
| 0.6492 | 0.6717 | 0.4083 | |
| 0.6498 | 0.6301 | 0.2764 | |
| 0.5004 | 0.3542 | 0.3407 | |
| 0.5136 | 0.3557 | 0.2583 |
Table 3.
Values of and its p-value considering a scale contaminated normal with and of Example 2.
| Log Lead | Nickel | Cross-Variogram | ||||
|---|---|---|---|---|---|---|
| p-Value | p-Value | p-Value | ||||
| Classical | 0.0704076 | 0.052087 | 27.8255 | 0.112065 | 1.160842 | 0.9775347 |
| 0.1-trimmed mean | 0.0312044 | 1 | 58.3908 | 1 | 0.878346 | 0.7257757 |
| Huber | 0.0634437 | 1 | 29.0930 | 1 | 0.894193 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
García-Pérez, A. New Robust Cross-Variogram Estimators and Approximations of Their Distributions Based on Saddlepoint Techniques. Mathematics 2021, 9, 762. https://0-doi-org.brum.beds.ac.uk/10.3390/math9070762
AMA Style
García-Pérez A. New Robust Cross-Variogram Estimators and Approximations of Their Distributions Based on Saddlepoint Techniques. Mathematics. 2021; 9(7):762. https://0-doi-org.brum.beds.ac.uk/10.3390/math9070762
Chicago/Turabian StyleGarcía-Pérez, Alfonso. 2021. "New Robust Cross-Variogram Estimators and Approximations of Their Distributions Based on Saddlepoint Techniques" Mathematics 9, no. 7: 762. https://0-doi-org.brum.beds.ac.uk/10.3390/math9070762
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.