
Why Improving the Accuracy of Exponential Integrators Can Decrease Their Computational Cost?


1
Departamento de Matemática Aplicada, Facultad de Ciencias, Universidad de Valladolid, IMUVA, Paseo de Belén 7, 47011 Valladolid, Spain
2
Departamento de Matemáticas y Computación, Universidad de Burgos, IMUVA, Escuela Politécnica Superior, Avda. Cantabria, 09006 Burgos, Spain
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Mathematics 2021, 9(9), 1008; https://0-doi-org.brum.beds.ac.uk/10.3390/math9091008
Submission received: 30 March 2021
/
Revised: 22 April 2021
/
Accepted: 23 April 2021
/
Published: 29 April 2021
(This article belongs to the Special Issue Numerical Methods for Evolutionary Problems)
Abstract
:In previous papers, a technique has been suggested to avoid order reduction when integrating initial boundary value problems with several kinds of exponential methods. The technique implies in principle to calculate additional terms at each step from those already necessary without avoiding order reduction. The aim of the present paper is to explain the surprising result that, many times, in spite of having to calculate more terms at each step, the computational cost of doing it through Krylov methods decreases instead of increases. This is very interesting since, in that way, the methods improve not only in terms of accuracy, but also in terms of computational cost.
1. Introduction
Exponential methods have become a valuable tool to integrate initial boundary value problems due to the recent development of techniques which allow us to calculate exponential-type functions in a more efficient way. From the paper in [1] to that in [2] twenty-five years later, some advances were made. However, apart from that, Krylov methods have become especially interesting in the context of the space discretization of boundary value problems because the matrices which turn up there are sparse. These iterative methods reduce the computation of an exponential-type function of those large matrices applied over a certain vector to the computation of a function of a much smaller matrix. In that sense, not only polynomial Krylov methods [3,4,5,6,7,8,9,10] have been considered, but also rational Krylov methods [11,12,13,14,15,16,17,18], which lead to a much better convergence rate, but imply to solve linear systems during the iteration process.
On the other hand, exponential methods were first introduced and analysed for the case of homogeneous boundary conditions [19]. Even in that case, order reduction is observed with respect to their classical counterparts unless more stringent conditions of annihilation on the boundary or periodic boundary conditions are considered (see [20,21] for the analysis with Lawson methods and [22] for splitting ones). With exponential Runge–Kutta methods, stiff order conditions have been derived [23] which may increase the number of stages which are necessary to get a given order.
In order to avoid order reduction with all these methods (without increasing the number of stages and even for time-dependent boundary conditions), some techniques have been suggested in [24,25,26,27,28,29,30]. What we have observed in some numerical experiments with the techniques in those papers is that, when avoiding order reduction, it does not only happen that the error diminishes more quickly with the stepsize, but also that, for a same moderate stepsize, the error is smaller and, what is more impressive, that the computational cost for a same stepsize is smaller. This is striking because increasing the order of the method implies calculating more terms at each step. However, by using the Krylov subroutine phipm.m in [8] in MATLAB to calculate those terms, we have checked in some cases that the computational cost is reduced. More precisely, Figure 6.1 in [30] shows this phenomenon when avoiding order reduction with a second-order Lawson method and Figure 1 [28] does the same with a second-order exponential Runge–Kutta method.
The aim of the paper is to understand why that reduction in computational cost for a same stepsize happens when avoiding order reduction. For that, we centre on symmetric discretizations of the differential operator of the problem at hand. Moreover, we will consider both the standard Krylov method and the purely rational Krylov one.
The paper is structured as follows. Section 2 gives some preliminaries on the problem to integrate and the technique to avoid order reduction. In Section 3, the standard Krylov technique and the commonly used adaptive subroutine phipm.m is described. It is then analysed how the subroutine works when the technique to avoid order reduction is applied in the naive way. Then, another more clever way to apply the same subroutine is suggested, as well as an improvement of the subroutine for the case at hand. Finally, in Section 4, the behaviour of the purely rational Krylov method is also studied when applied inside the technique to avoid order reduction, and it is again justified that increasing the order (and therefore accuracy) may be cheaper than not doing it. The main conclusions are stated in Section 5.
2. Preliminaries
The technique in [21,24,25,26,27,29,30] to avoid order reduction when integrating linear and non-linear initial boundary value problems with exponential splitting, Lawson and Runge–Kutta methods is based on applying the method of lines in the reverse order than usual: Integrating firstly in time and then in space.
More precisely, we assume that the problem to integrate is
where ’ corresponds to differentiation with respect to time, X and Y are function spaces, corresponds to a boundary operator, to a differential space operator, and is a smooth source term. For a more detailed description of the assumptions, look at [21,24,25,26,27,29,30]. When considering the time integration of this problem with exponential methods, exponential-type functions turn up. We remind that , and that, for ,
For example, , . Then, as the exponentials and -functions should be applied over a differential operator instead of a matrix, those terms were suggested to be substituted by the solution of initial boundary value problems with appropriate boundaries. More precisely, has been understood as the solution of problem
when , while () has been understood as the solution of problem
Suitably increasing the value of r in these expressions implies increasing the local order of the method until the classical order is achieved (i.e., the order obtained when a non-stiff ordinary differential system is integrated).
Then, a space discretization for A is considered. For each elliptic problem of the form
with source term F and boundary condition g, the approximation is given through a vector which satisfies a system of the form
for some matrix , some operator , and some approximation vector of F. We will assume throughout the paper that is symmetric and negative definite, and that, for small enough h, there exists a constant such that (see (H1) in [26]).
In such a way, if can be calculated in terms of data, the space discretization of (3) becomes
and that of (4),
By using the variation-of-constants formula and the definition of the -functions, the solution of these systems can then be written, respectively, as
In order to achieve a certain local order , the value of r to be considered for the approximation of each of the terms which define the time integrator should be p or . That depends on whether these terms are multiplied or not by the factor k, which corresponds to the timestepsize in the definition of the time integrator. In any case, increasing the value of r implies getting a higher local order of the method (until the classical local order is achieved), but that means calculating more terms in each of the expressions of the form (6) to (7).
2.1. An Example as a Motivation
In order to better understand how Krylov subroutines behave when calculating those terms, we have considered a specific example.
In (1), we take , , A the second-order space derivative, ∂ a Dirichlet boundary condition and, for the space discretization, we take and as the standard symmetric second-order difference scheme, so that, for the boundary conditions and at and , respectively,
and is the nodal projection of a function on the nodes with .
Then, we concentrate on calculating an expression like (6). More precisely, we take , which has unit -norm in the interval . We consider , , and the values . For that, we have used subroutine phipm.m in [8], which is explicitly constructed to calculate
for some vectors , and therefore it seems very suitable for our purposes. As the subroutine is adaptive, it calculates this expression except for an estimated error, which is assured to be less than a parameter , and which is given as an input of the subroutine. We have considered two values for the tolerances: and . The results in terms of CPU time in a laptop computer can be seen in Table 1, which clearly shows that, for the first tolerance , in spite of having to calculate more terms, the subroutine phipm.m takes less cpu time when r increases. However, when , the cpu time increases with r. We give an explanation for this in the following section.
3. Standard Krylov Method
3.1. Description of Subroutine Phipm.m
The subroutine phipm.m is based on the standard Krylov method, which consists of the following: For a symmetric matrix B, a scalar and a vector v,
where , and are obtained from a Lanczos iteration process [31] and . More precisely, the columns of are the elements of an orthonormal basis of the space
whose first element is and is a tridiagonal -matrix which satisfies
In order to calculate , it is usual to consider the idea of Saad [9] (generalized by Sidje [10]) in which an augmented matrix is constructed, which has the form
where I is the identity matrix. Then, the top m entries of the last column of yield the vector . In phipm.m, this exponential of the small matrix is calculated through the function from MATLAB, which calculates it considering a 13-degree diagonal Padé approximant combined with scaling and squaring [32].
According to [9], the error when approximating through (8) is bounded by
for some constant C for large enough m. Therefore, when is large, m must be very big in order to approximate the exact value. More precisely, in [3,5,6] it is stated that, for symmetric matrices, only when superlinear convergence is guaranteed. As for our purposes, comes from the space discretization of an unbounded differential operator, is very large, and the way to manage convergence without increasing m too much is by diminishing through time-stepping. The main idea is that
is the solution of the differential problem
which corresponds to (5) and (6) for specific B and . In such a way, if we are interested in calculating , a grid can be considered and (12) must be solved from to taking as initial condition. According to [33],
where . Then, is based on considering the recurrence relation
so that this expression can be written just in terms of and not the rest of functions . More precisely,
where can be recursively calculated through
Then, subroutine is adaptive in the sense that, taking an estimate for the error in Krylov iteration, it changes at each step the value or the number m of Krylov iterations to calculate in (15) so that the estimate of the error at the final time is below the given tolerance . Moreover, it chooses one or another possibility in order to minimize the computational cost. The estimate in [8,10] for the error when approximating is taken as the norm of
where is the unit vector originated in the Lanczos process which is orthogonal to all columns of . In phipm.m, they even add this estimation of the error to the approximation in order to be more accurate. More precisely, they take
where is computed through the exponentiation of times the augmented matrix (9) with l substituted by and taking into account that also appears in the result. In such a way, just a matrix of size needs to be exponentiated.
3.2. Application to Our Problem
What we firstly observe when trying to apply standard Krylov subroutines to the formulas which turn up when avoiding order reduction (6) and (7) is that there are two types of terms: those which contain , and those which contain . In the first case, as in the example of Section 2.1, is taken as a continuous function of unit -norm, and therefore its nodal projection is also uniformly bounded on h in the discrete -norm by an amount near 1. However, in the second case, is very big. In fact, the smallest h is to integrate more accurately in space, the biggest those terms are. (These remarks are general for other regular functions although not bounded by 1).
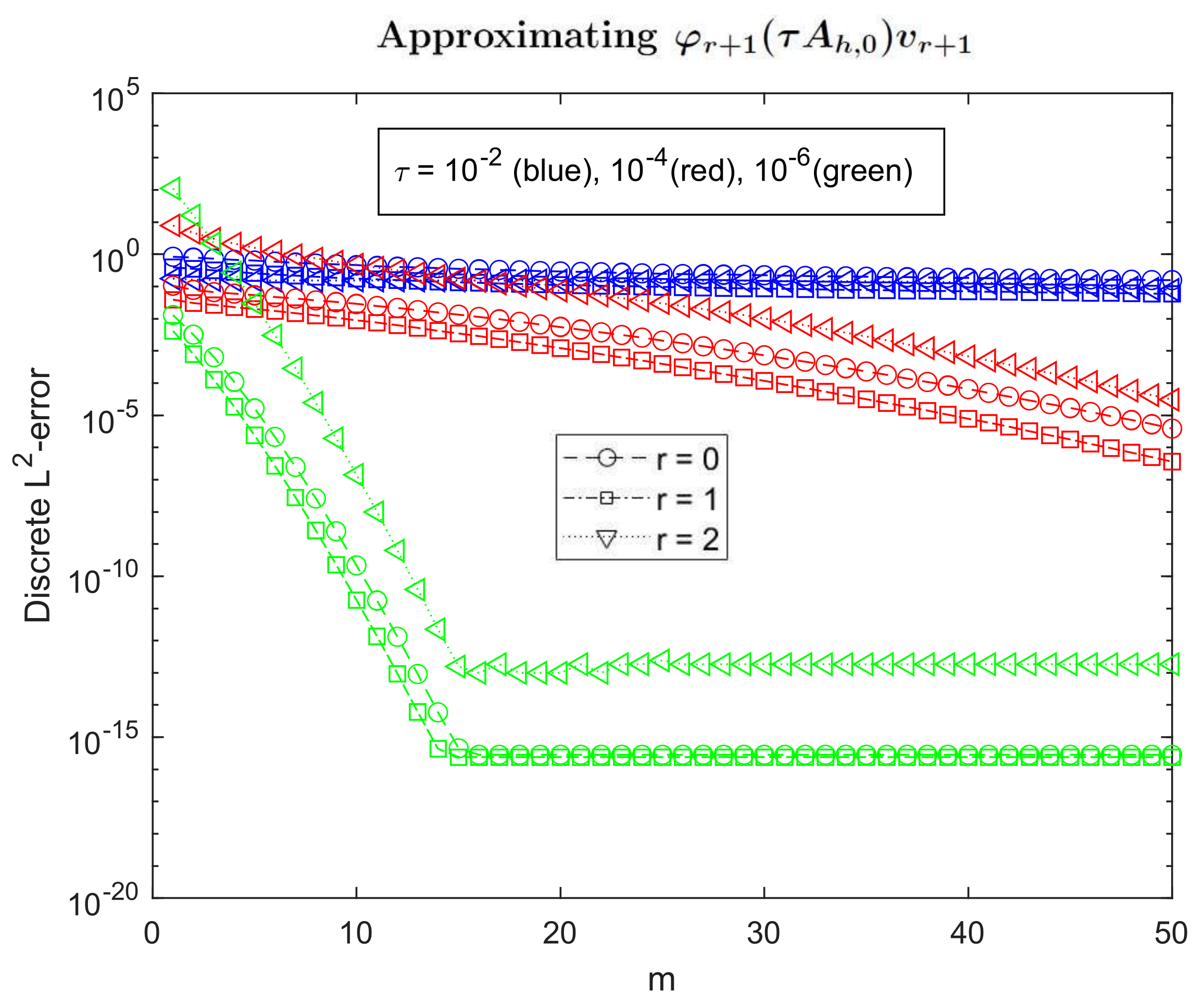
In order to see the convergence with the number of iterations for each type of terms with the standard Krylov method, in Figure 1 we represent the discrete -error against the number of iterations when and . The top figure corresponds to approximating (j = 0,1,2,3), and the bottom one to (j = 1,2,3). (We notice that, in our precise example, for any natural l). Apart from seeing that the size of errors is much bigger in the bottom plot, we can also check in both figures that the smaller is, the quicker the convergence with m. This corroborates the result in [3,5,6], which guarantees superlinear convergence for . We would also like to remark here that Figure 1 also shows that, in spite of the fact that the convergence with m is similar, when the subindex of the function grows, the size of errors is smaller. Regarding the estimate of error (17), that may be due to the fact that evaluated at the eigenvalues of is smaller when l grows. By looking at (14), we notice that the exponential-type functions are smaller near zero when l grows, and the convergence to zero at is also a bit quicker. Look at Figure 2. Moreover, we do have the following result for the first iteration, which implies that the square of the error of the first Krylov iteration is an average of the square of the difference of evaluated at each eigenvalue minus its evaluation on an average of those eigenvalues:
Theorem 1.
If is an orthonormal basis of eigenvectors of B, with corresponding eigenvalues , and is a unit-norm vector, it happens that, for every analytic function defined over an interval which contains the eigenvalues,
Proof.
On the one hand, it is clear that
On the other hand, by Lanczos iteration, . Therefore,
where the fact that is an orthonormal basis of eigenvectors of B has been used in the last equality. Then,
from what the result follows. □
Because of this, the less changes in the interval where the eigenvalues of B stay, the smaller the error will be. Obviously, changes less in the bigger l is, which explains the relative behaviour of these functions in Figure 1.
On the other hand, in order to better understand why the errors when are much bigger and, furthermore, that the smaller is the bigger difference with respect to the case , we can consider the estimation of error (17). We notice that the fact that is much bigger for than for cannot be the only reason to explain the behaviour in Figure 1 since that factor does not depend on . Because of that, we have decided to look into the factor , where is the tridiagonal matrix which turns up after applying Lanczos iteration to . As is a tridiagonal symmetric matrix whose numerical range is contained in that of [31], the eigenvalues of are also contained in the numerical range of , and therefore are negative and less than a value for a certain . Denoting by the diagonal matrix containing the eigenvalues of , it happens that
for some orthogonal -matrix , and it seems that
is liable to behave as , where is the biggest of eigenvalues of . Kaniel–Paige–Saad theory [31] does not give a good bound for when h is small since that bound depends on the distance to the smallest of the eigenvalues of , which is very far from for small h. We notice that, for , while . Because of that, the quotient of the estimation of errors (17) when applying Krylov standard method with , and is approximately
The behaviour of the functions , as plotted in Figure 2, explains that this factor increases from the top to the bottom, i.e., when decreases.
In order to understand what happens when m increases, we have observed that is constant for . Moreover, we represent and in Figure 3. They both seem to converge to the same quantity but, in any case, for the values of (which are considered in Figure 1), is still very big, which explains the different relative behaviour of both plots in Figure 1 also for .
As for the behaviour when h gets smaller, although not shown here for the sake of brevity, it is already well-known that the standard Krylov iteration does not give uniform convergence and, the smaller h is, the bigger m must be to get a given error for the approximation [6,14].
What subroutine phipm.m does in order to calculate (6) is not to apply Krylov iteration to each of the terms in that expression. The more natural seems to choose in (11) as
and the corresponding time-stepping (15) and (16) is performed, where Krylov iteration is just applied to approximate . Doing things that way, Table 1 is obtained. On the one hand, the fact that just the biggest is considered in (6) for Krylov iteration is positive, since the errors are smaller when r grows. On the other hand, from what can be observed at least for , the bigger errors coming from the consideration of the terms on seem to be ameliorated by the factors in (16), since the more terms of that type are considered, the less CPU time the subroutine requires to get a given accuracy.
3.3. Suggestion to Improve the Result with Phipm.m
In order to simplify time-stepping, what we suggest in this section is to apply recurrence (14) to (6) and (7) before attempting to use subroutine phipm.m. More precisely, we take profit of the following result.
Proof.
The proof follows by induction on r. Notice that, for and formula (6), using the first formula of (14) with ,
Then, assuming that (19) is the same as (6), the same equivalence is true for , since
where, for the second equality, has been substituted from its expression when solving from the first formula in (14) with . It is then easy to see that this expression is equivalent to (19) with r changed by .
The proof follows in a similar way for (20). □
Let us now concentrate on (19). Calling subroutine phipm.m just for the last term of this expression, i.e., taking
many calculations in the time-stepping procedure (15) and (16) are avoided and, in some way, calculated just once and for all at the beginning in expression (19). We also notice that each bracket in this expression is approximating () when , with the only remark that, the bigger j is, the more relevant the errors coming from the ill-posedness of numerical differentiation in space may be. Nevertheless, for smaller values of j, those brackets are controlled and, under enough regularity of , do not grow in norm for the values of h, which are usually required for enough accuracy in space. Another important remark is that each of those brackets can be recursively calculated from the previous one just by multiplying by and summing a term like . Therefore, many fewer calculations than those apparent are really necessary.
The results doing things that way for the example in Section 2.1 are shown in Table 2, where the improvement with respect to the results on cpu time in Table 1 are evident. Moreover, for the smallest tolerance, not only the necessary time to achieve a similar error (related to ) is smaller, but we also notice that increasing the value of r, that time is smaller (as it also happened with in Table 1). This seems to suggest that rounding errors due to time-stepping in Table 1 were too important.
In order to better understand why taking bigger r implies that CPU time is smaller, we have applied Krylov iteration to
where
Notice that is the last term in (19) except for the factor and that, in exact arithmetic, when ,
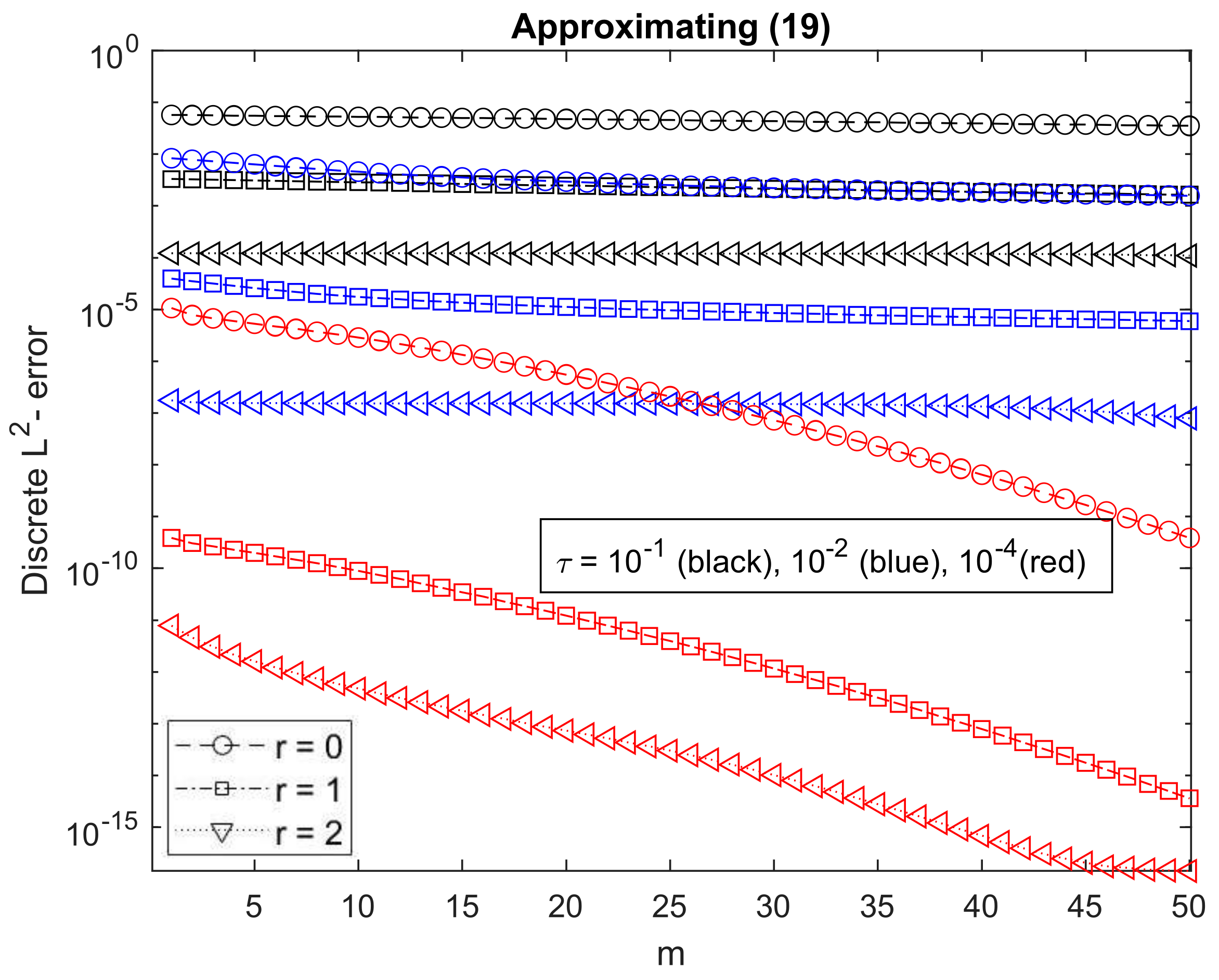
In Figure 4, we again represent the -discrete error against the number of Krylov iterations for different values of . We can again see that the smaller is, the quicker the convergence with m. As for the size of errors, for , they are quite similar to the first plot in Figure 1, and therefore not as big as in the second plot of the same figure. However, for , the errors are quite bigger than the corresponding ones in that first plot and, in any case, bigger than those of . This is due to the fact that can be numerically seen to be of order in spite of the fact of being presumable approximating . This is caused by roundoff errors, since numerical differentiation is a badly posed problem and a sixth-order space derivative is being considered.
On the other hand, the other terms in (19) are exactly calculated except for roundoff. Therefore, the error when calculating the whole expression should be the error which was represented in Figure 4 multiplied by . This explains that, in Figure 5, the errors are so small even for . Moreover, the error is smaller when r increases, not only from to , but also from to (although in a smaller proportion). This is the reason why taking a bigger value of r can decrease the computational cost when using phipm.m to approximate (6).
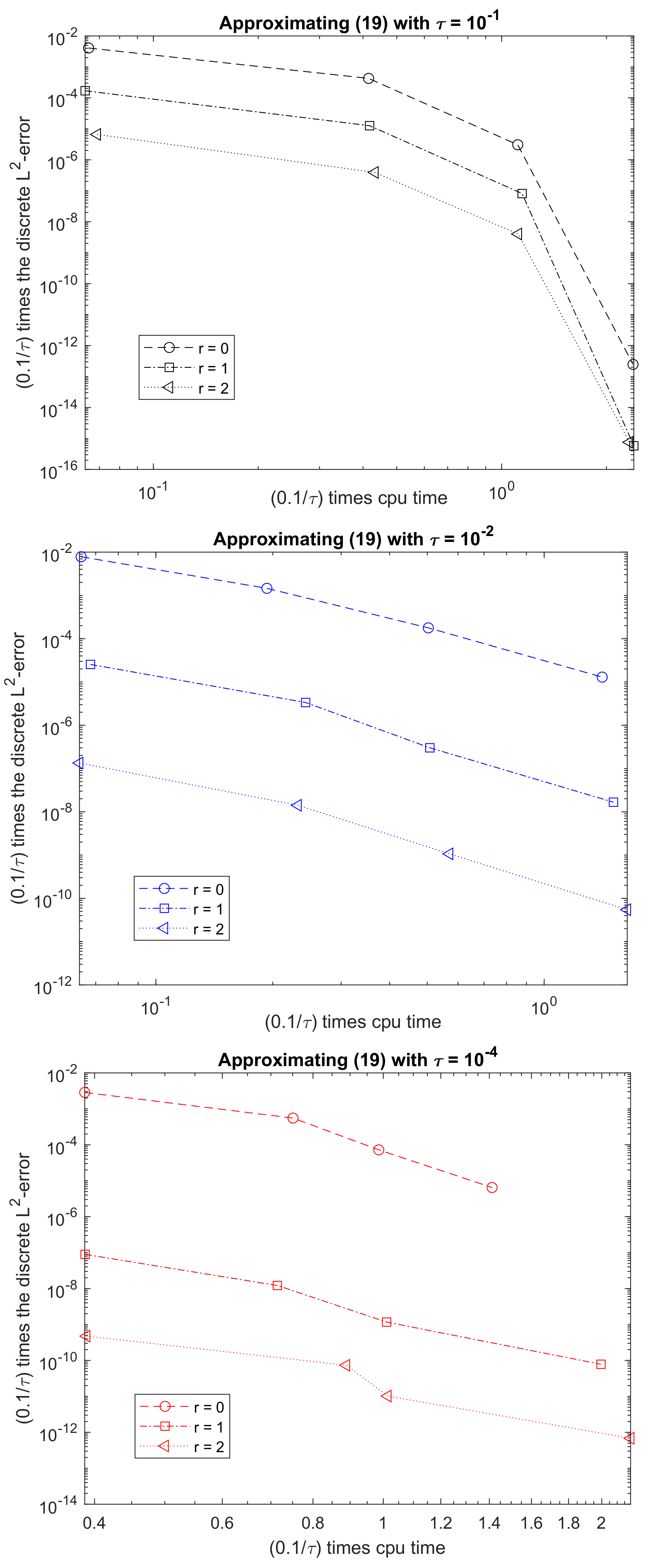
To better illustrate that when trying to approximate (6) with , we represent in Figure 6 times the error when approximating (6) through (19) against times the CPU required to calculate (6) for and different values of m. In such a way, we are implicitly assuming that, in order to approximate (6) with ,
These assumptions are not completely satisfied but, in such a way, we can have an overview of the total cost to calculate (19) for the different values of r. As Figure 6 shows, seems cheaper than and this one cheaper than .
Although not shown here for the sake of brevity, similar arguments apply for the case in which (7) is to be approximated with the same subroutine.
3.4. Modification of Subroutine Phipm.m
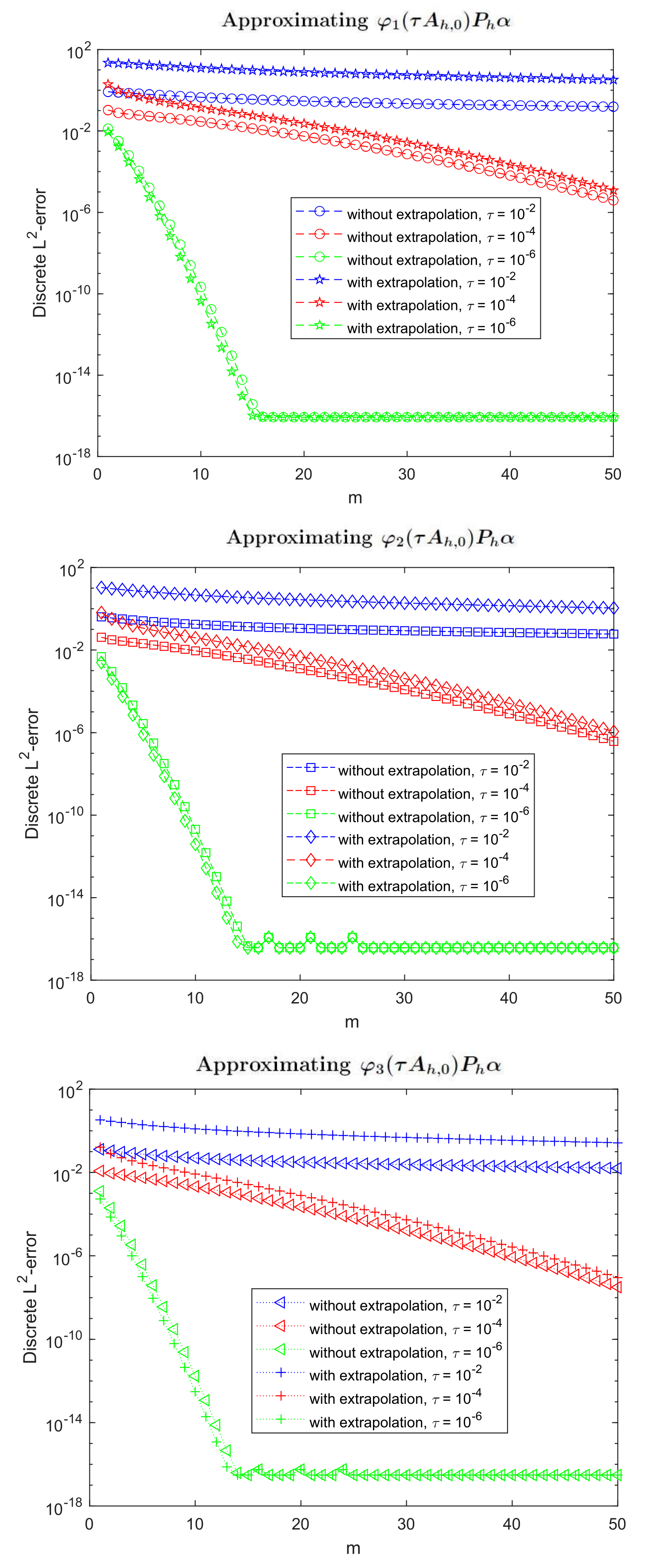
Estimate (17) was originally proposed in [9] in a context where it was reasonable just when . For our purposes, and as it was also stated in [7], that is not useful. In fact, in Figure 7, we represent the discrete -error against the number of Krylov iterations when approximating using the extrapolation (18) and when not using it (8). We can see that, only when is very small so that is near 1, the extrapolation formula improves the standard one. However, in [7], by relating it to the error which is committed when integrating linear systems with the standard Krylov method, the following similar estimate was obtained:
where the difference comes from the subindex in the -function evaluated at , which is now l instead of . Notice that, in such a case, the augmented matrix of size does not need to be calculated, and it is enough to consider that in (9), which just has dimension . As the authors mention in [7], (23) is not the first term of a series for the whole error, but it is just a rough estimate. Therefore, extrapolation has no sense in this case. If we change subroutine phipm.m accordingly, without considering the extrapolation (18) but just (8), and leaving the same adaptive strategy but with the new error estimation (23), the results in Table 3 are obtained when approximating (6), where again expression (19) and the choice (21) are used.
In this table, we can see that the CPU time which is required to achieve a given tolerance is smaller than in Table 2 for . This agrees with the fact that, when the stepsize is not very small, not doing extrapolation is more accurate and cheap than doing it. For the smaller tolerance , the CPU time which is required when is a bit bigger than in Table 2, which may be due to the fact that, in this particular case, the stepsizes which the subroutine has to take are so small that the extrapolation is worth doing. In any case, CPU time continues to diminish from to for both tolerances and, in the same way than in Table 2, it diminishes also for from to .
4. Purely Rational Krylov Method
Exponential methods are in principle constructed so that linear systems do not have to be solved when integrating stiff linear problems with standard implicit methods. For non-linear stiff problems, standard Rosenbrock methods are usually used, which avoid to solve a non-linear problem at each stage by the use of the Jacobian of the problem. In any case, the calculation of this Jacobian at each step can be difficult or expensive and, therefore, this part may be more costly than the one of having to solve a linear system at each stage. Because of this, extended Krylov methods which require the calculation of powers of the inverse of a certain sparse matrix applied over a vector are justified when applied inside exponential methods which aim to solve non-linear problems. More precisely, although the calculations of those terms imply solving linear systems with sparse matrices, its cost may be justified in non-linear problems because the Jacobian of the non-linear function does not need to be calculated. We notice that, if Gaussian elimination for sparse matrices is used, as the matrix is always the same, the LU factorization is done once and for all at the very beginning. Moreover, if multigrid methods are used, the computational cost is just of the order of the number of grid points in the space discretization (the same order of the number of computations which are required when multiplying a sparse matrix times a vector in standard Krylov methods).
Extended Krylov subspace methods for symmetric matrices were described in [11] and estimates of convergence where given in terms of the smallest and biggest of the eigenvalues. In such a way, similarly to standard Krylov methods, they are not uniform convergence estimates on the spacegrid when the matrices come from the discretization of an unbounded operator but, as distinct, those estimates were smaller than those of standard Krylov methods and, in practice, the true error was even much smaller than those estimates. Much better estimates of the error observed in practice were obtained in [16] for both symmetric and nonsymmetric B, although just for the case in which the corresponding Krylov space contains the same number of positive and negative powers of B and for matrix functions, which do not include the exponential-type functions in which we are interested.
In this paper, we will centre on the purely rational Krylov method, which is based on considering as Krylov subspace
for a certain real parameter for which the inverse of exists. An analysis of this method is performed in [14] when the matrix B is substituted by an unbounded operator with a field of values on the left half plane. In such a way, estimates of the error are obtained which are valid for discretizations of such an operator which are independent of the grid size. Furthermore, the bounds of the error which are proved in [14] are smaller when the index of the function grows. More precisely, they decrease like
although in practice, an exponential decay can be observed.
Using both powers of B and has been proven to be advantageous when some powers are bounded. More precisely, in the case that v discretizes a function which vanishes at the boundary and which satisfies that several of the powers of A exist and also vanish at the same boundary, in [13] it is shown that the rate of convergence is quicker ( if is bounded for ) when, in the Krylov subspace, those powers of B are considered as well as those on . Numerically, even a higher order rate of convergence can be observed, which approximates that of the purely rational Krylov method.
In any case, as we are just interested in problems with non-vanishing boundary conditions, we will directly consider the purely rational Krylov method, which is based on constructing iteratively an orthonormal basis of the Krylov subspace (24) through Lanczos iteration.
If we denote by also to the matrix whose columns are that orthonormal basis, the projection onto that space (24) is given by . The approximation to is then given by , where . Therefore,
where
and is calculated through , where is like in (9) with substituted by .
Application to Our Problem
The aim of this section is to apply the purely rational Krylov method just described to our problem in Section 2.1.
In a similar way to Figure 1 and Figure 4 in Section 3.2 for the standard Krylov method, in Figure 8 we represent, for , the error when approximating , and with in (22) against the number of iterations. We have taken now and, as distinct as what happened with the standard Krylov method and not explained in the literature, the convergence with m is now quicker when is bigger and, in any case, exponential from the very beginning () although with a smaller rate when diminishes. Because of this, time-stepping has no sense with this method and the best approach is to apply Krylov iteration directly with the value of in which we are interested in (6).
As for the behaviour for the different values of the index l in , in the same way as with standard Krylov iteration, the errors are smaller when l grows. We notice that, for , this method coincides with standard Krylov iteration and therefore, the explanation for that is given in Theorem 1. On the other hand, the rate of convergence also seems to be more advantageous when l grows, as in accordance with bound (25).
Although not shown here for the sake of brevity, we have also run our experiments with smaller values of the grid size h and we have seen that the errors are very similar. This agrees with the analysis performed for rational Krylov methods in [14], and this behaviour makes this method more interesting than the standard one, which does not show uniform convergence on the space grid size. (Only when calculating , the errors are a bit bigger when h diminishes for the higher values of m, and that is due to the fact that the calculation of is already quite difficult when h is small).
In any case, what is important is the behaviour of the error when approximating (19) against the number of iterations m for the different values of .
That can be observed in Figure 9. We notice that the error now is that of the bottom graph of Figure 8 multiplied by . We restrict here to the case , since the aim is to approximate (6) with that value of . What we can observe in (Figure 8) is that the error is smaller with than with , and also slightly smaller with than with .
5. General Conclusions
- At least for the range of values in which we move in the example of Section 2.1, calculating (6) or (7) with a given required accuracy is likely to be cheaper when r increases, in spite of the fact that, apparently, more terms need to be calculated.
- In the case that having to solve several linear systems at each step with a same matrix is not a drawback for having chosen an exponential method to integrate a problem like (1), we recommend to approximate (6) or (7) by using (19) or (20) and a purely rational Krylov method to calculate the last term there.
- Whenever having to solve several linear systems at each step is a drawback for using exponential methods to integrate a problem like (1), we recommend using the modification of the adaptive subroutine phipm.m, which is described in Section 3.4, although the subroutine phipm.m applied as described in Section 3.3 also gives quite acceptable results, at least in our precise example.
Author Contributions
Conceptualization, B.C.; Data curation, N.R.; Formal analysis, B.C. and N.R.; Investigation, B.C.; Methodology, N.R.; Software, N.R.; Writing—original draft, B.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Ministerio de Ciencia e Innovación and Regional Development European Funds through project PGC2018-101443-B-I00 and by Junta de Castilla y León and Feder through project VA169P20.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Moler, C.; Loan, C.V. Nineteen dubious ways to compute the exponential of a matrix. SIAM Rev. 1978, 20, 801–836. [Google Scholar] [CrossRef]
- Moler, C.; Loan, C.V. Nineteen dubious ways to compute the exponential of a matrix, twenty-five years later. SIAM Rev. 2003, 45, 3–49. [Google Scholar] [CrossRef]
- Druskin, V.L.; Knizhnerman, L.A. Two polynomial methods of calculating functions of symmetric matrices. USSR Comput. Math. Math. Phys. 1989, 29, 112–121. [Google Scholar] [CrossRef]
- Druskin, V.L.; Knizhnerman, L.A. Error bounds in the simple Lanczos procedure for computing functions of symmetric matrices and eigenvalues. Comput. Maths. Math. Phys. 1991, 31, 970–983. [Google Scholar]
- Druskin, V.L.; Knizhnerman, L.A. Krylov subspace approximations of eigenpairs and matrix functions in exact and computer arithmetic. Numer. Linear Algebra Appl. 1995, 2, 205–217. [Google Scholar] [CrossRef]
- Hochbruck, M.; Lubich, C. On Krylov subspace approximations to the matrix exponential operator. SIAM J. Numer. Anal. 1997, 34, 1911–1925. [Google Scholar] [CrossRef]
- Hochbruck, M.; Lubich, C.; Selhofer, H. Exponential Integrators for Large Systems of Differential Equations. SIAM J. Sci. Comput. 1998, 19, 1552–1574. [Google Scholar] [CrossRef] [Green Version]
- Niesen, J.; Wright, W.M. Algorithm 919: A Krylov subspace algorithm for evaluating the φ-functions appearing in exponential integrators. ACM Trans. Math. Softw. 2012, 38, 22. [Google Scholar] [CrossRef] [Green Version]
- Saad, Y. Analysis of some Krylov subspace approximations to the matrix exponential operator. SIAM J. Numer. Anal. 1992, 29, 209–228. [Google Scholar] [CrossRef]
- Sidje, R.B. EXPOKIT: A Software Package for Computing Matrix Exponentials. ACM Trans. Math. Softw. 1998, 24, 130–156. [Google Scholar] [CrossRef]
- Druskin, V.L.; Knizhnerman, L.A. Extended Krylov subspaces: Approximation of the square root and related functions. SIAM J. Matrix Anal. Appl. 1998, 19, 755–771. [Google Scholar] [CrossRef]
- Eshof, J.V.D.; Hochbruck, M. Preconditioning Lanczos approximations to the matrix exponential. SIAM J. Sci. Comput. 2006, 27, 1438–1457. [Google Scholar] [CrossRef] [Green Version]
- Göckler, T.; Grimm, V. Convergence analysis of an extended Krylov subspace method for the approximation of operator functions in exponential integrators. SIAM J. Numer. Anal. 2013, 51, 2189–2213. [Google Scholar] [CrossRef] [Green Version]
- Grimm, V. Resolvent Krylov subspace approximation to operator functions. BIT Numer. Math. 2012, 52, 639–659. [Google Scholar] [CrossRef]
- Jagels, C.; Reichel, L. The extended Krylov subspace method and orthogonal Laurent polynomials. Linear Algebra Its Appl. 2009, 431, 441–458. [Google Scholar] [CrossRef] [Green Version]
- Knizherman, L.; Simoncini, V. A new investigation of the extended Krylov subspace method for matrix function evaluations. Numer. Linear Algebra Appl. 2010, 17, 615–638. [Google Scholar]
- López, L.; Simoncini, V. Analysis of projection methods for rational function approximation to the matrix exponential. SIAM J. Num. Anal. 2006, 44, 613–635. [Google Scholar] [CrossRef] [Green Version]
- Moret, I.; Novati, P. RD-Rational approximations of the matrix exponential. BIT Numer. Math. 2004, 44, 595–615. [Google Scholar] [CrossRef]
- Hochbruck, M.; Ostermann, A. Exponential integrators. Acta Numer. 2010, 29, 209–286. [Google Scholar] [CrossRef] [Green Version]
- Alonso-Mallo, I.; Cano, B.; Reguera, N. Analysis of order reduction when integrating linear initial boundary value problems with Lawson methods. Appl. Numer. Math. 2017, 118, 64–74. [Google Scholar] [CrossRef] [Green Version]
- Cano, B.; Reguera, N. Order reduction and how to avoid it when Lawson methods integrate reaction-diffusion boundary value problems. arXiv 2019, arXiv:1909.12659. [Google Scholar]
- Faou, E.; Ostermann, A.; Schratz, K. Analysis of exponential splitting methods for inhomogeneous parabolic equations. IMA J. Numer. Anal. 2015, 35, 161–178. [Google Scholar] [CrossRef]
- Hochbruck, M.; Ostermann, A. Explicit exponential Runge-Kutta methods for semilinear parabolic problems. SIAM J. Num. Anal. 2005, 43, 1069–1090. [Google Scholar] [CrossRef] [Green Version]
- Alonso-Mallo, I.; Cano, B.; Reguera, N. Avoiding order reduction when integrating linear initial boundary value problems with Lawson methods. IMA J. Numer. Anal. 2017, 37, 2091–2119. [Google Scholar] [CrossRef] [Green Version]
- Alonso-Mallo, I.; Cano, B.; Reguera, N. Avoiding order reduction when integrating linear initial boundary value problems with exponential splitting methods. IMA J. Numer. Anal. 2018, 38, 1294–1323. [Google Scholar] [CrossRef]
- Alonso-Mallo, I.; Cano, B.; Reguera, N. Avoiding order reduction when integrating reaction-diffusion boundary value problems with exponential splitting methods. J. Comput. Appl. Math. 2019, 357, 228–250. [Google Scholar] [CrossRef] [Green Version]
- Cano, B.; Moreta, M.J. Exponential quadrature rules without order reduction for integrating linear initial boundary value problems. SIAM J. Num. Anal. 2018, 56, 1187–1209. [Google Scholar] [CrossRef]
- Cano, B.; Moreta, M.J. How to Avoid Order Reduction When Explicit Runge-Kutta Exponential Methods Integrate Nonlinear Initial Boundary Value Problems; Submitted for Publication.
- Cano, B.; Reguera, N. Avoiding order reduction when integrating nonlinear Schrödinger equation with Strang method. J. Comp. Appl. Math. 2017, 316, 86–99. [Google Scholar] [CrossRef] [Green Version]
- Cano, B.; Reguera, N. How to Avoid Order Reduction When Lawson Methods Integrate Nonlinear Initial Boundary Value Problems. Submitted for Publication.
- Golub, G.H.; van Loan, C.F. Matrix Computations, 4th ed.; The Johns Hopkins University Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Higham, N.J. The scaling and squaring method for the matrix exponential revisited. SIAM J. Matrix Anal. Appl. 2005, 26, 1179–1193. [Google Scholar] [CrossRef]
- Skaflestad, B.; Wright, W. The scaling and modified squaring method for matrix functions related to the exponential. Appl. Numer. Math. 2009, 59, 783–799. [Google Scholar] [CrossRef]
Figure 1.
Discrete -error against number of Krylov iterations when approximating (top) and (bottom) through standard Krylov method for different values of , and fixed .
Figure 1.
Discrete -error against number of Krylov iterations when approximating (top) and (bottom) through standard Krylov method for different values of , and fixed .

Figure 2.
(continuous line), (dashed line), (dash-dotted line), (dotted line).

Figure 3.
against number of iterations for and both , .

Figure 4.
Discrete -error against number of Krylov iterations when approximating for in (22), different values of , and fixed .
Figure 4.
Discrete -error against number of Krylov iterations when approximating for in (22), different values of , and fixed .

Figure 5.
Discrete -error against number of Krylov iterations when approximating (19) for the data in Section 2.1 for different values of , and fixed .
Figure 5.
Discrete -error against number of Krylov iterations when approximating (19) for the data in Section 2.1 for different values of , and fixed .

Figure 6.
times the discrete -error against times CPU time when approximating (19) for the data in Section 2.1 for (), () and (), and fixed .
Figure 6.
times the discrete -error against times CPU time when approximating (19) for the data in Section 2.1 for (), () and (), and fixed .

Figure 7.
Discrete -error against number of Krylov iterations when approximating for the data in Section 2.1 for different values of with extrapolation (18) and without it, (top), (middle), (bottom), ().
Figure 7.
Discrete -error against number of Krylov iterations when approximating for the data in Section 2.1 for different values of with extrapolation (18) and without it, (top), (middle), (bottom), ().

Figure 8.
Discrete -error against number of Krylov iterations when approximating , , for the data in Section 2.1 through purely rational Krylov methods for different values of , , and fixed .
Figure 8.
Discrete -error against number of Krylov iterations when approximating , , for the data in Section 2.1 through purely rational Krylov methods for different values of , , and fixed .

Figure 9.
Discrete -error against number of Krylov iterations when approximating (6) for the data in Section 2.1 through (19) using purely rational Krylov method for , and fixed
Figure 9.
Discrete -error against number of Krylov iterations when approximating (6) for the data in Section 2.1 through (19) using purely rational Krylov method for , and fixed


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
CPU time to calculate (6) for the data in Section 2.1 with subroutine phipm.m.
Table 1.
CPU time to calculate (6) for the data in Section 2.1 with subroutine phipm.m.
| 6.5e-01 | 5.5e-01 | 5.1e-01 | 4.4e-01 | |
| 1.4e+00 | 1.6e+00 | 1.8e+00 | 2.1e+00 |
Table 2.
CPU time to calculate (6) for the data in Section 2.1 using formula (19) and subroutine phipm.m just for the last term.
Table 2.
CPU time to calculate (6) for the data in Section 2.1 using formula (19) and subroutine phipm.m just for the last term.
| 4.9e-01 | 4.2e-01 | 3.9e-01 | |
| 8.1e-01 | 6.5e-01 | 5.8e-01 |
Table 3.
CPU time to calculate (6) for the data in Section 2.1 using formula (19) and a modification of subroutine phipm.m (with error estimate (23) and without extrapolation) just for the last term.
Table 3.
CPU time to calculate (6) for the data in Section 2.1 using formula (19) and a modification of subroutine phipm.m (with error estimate (23) and without extrapolation) just for the last term.
| 3.9e-01 | 3.4e-01 | 3.5e-01 | |
| 1.0e+00 | 5.9e-01 | 5.3e-01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cano, B.; Reguera, N. Why Improving the Accuracy of Exponential Integrators Can Decrease Their Computational Cost? Mathematics 2021, 9, 1008. https://0-doi-org.brum.beds.ac.uk/10.3390/math9091008
AMA Style
Cano B, Reguera N. Why Improving the Accuracy of Exponential Integrators Can Decrease Their Computational Cost? Mathematics. 2021; 9(9):1008. https://0-doi-org.brum.beds.ac.uk/10.3390/math9091008
Chicago/Turabian StyleCano, Begoña, and Nuria Reguera. 2021. "Why Improving the Accuracy of Exponential Integrators Can Decrease Their Computational Cost?" Mathematics 9, no. 9: 1008. https://0-doi-org.brum.beds.ac.uk/10.3390/math9091008
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.