
Evaluation of Policy Effectiveness by Mathematical Modeling for the Opioid Crisis with Spatial Study and Trend Analysis


Abstract
:1. Introduction
2. Methods
2.1. Data Source and Preprocessing
2.2. EWM-RSR Evaluation Model
2.2.1. Spread Index of the Model
2.2.2. Calculation Steps
- Step 1.
- The RSR frequency distribution table was prepared. The frequency of each group f was listed. The cumulative frequency of each group was calculated;
- Step 2.
- The range of ranking and average value of RSRs of each group were determined;
- Step 3.
- The cumulative frequency was determined. The last item of the cumulative frequency was corrected, denoted as ;
- Step 4.
- The cumulative frequency to was converted, where was the standard normal distribution u corresponding to the cumulative frequency plus five.
2.3. Autoregressive Model
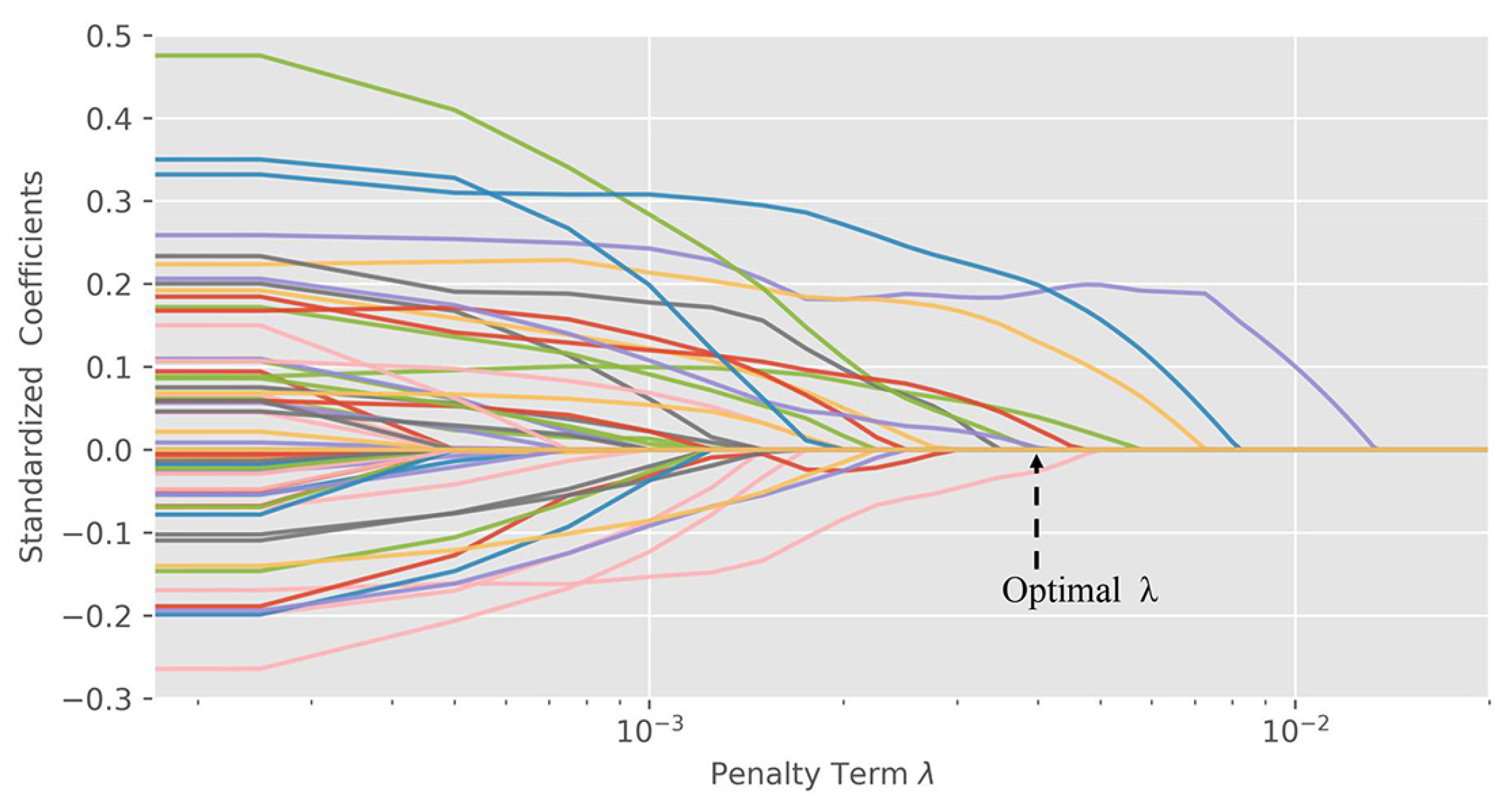
2.4. Important Variables Search with LASSO Regression
2.4.1. Normalization of the Indicators
2.4.2. LASSO Model
3. Results and Discussion
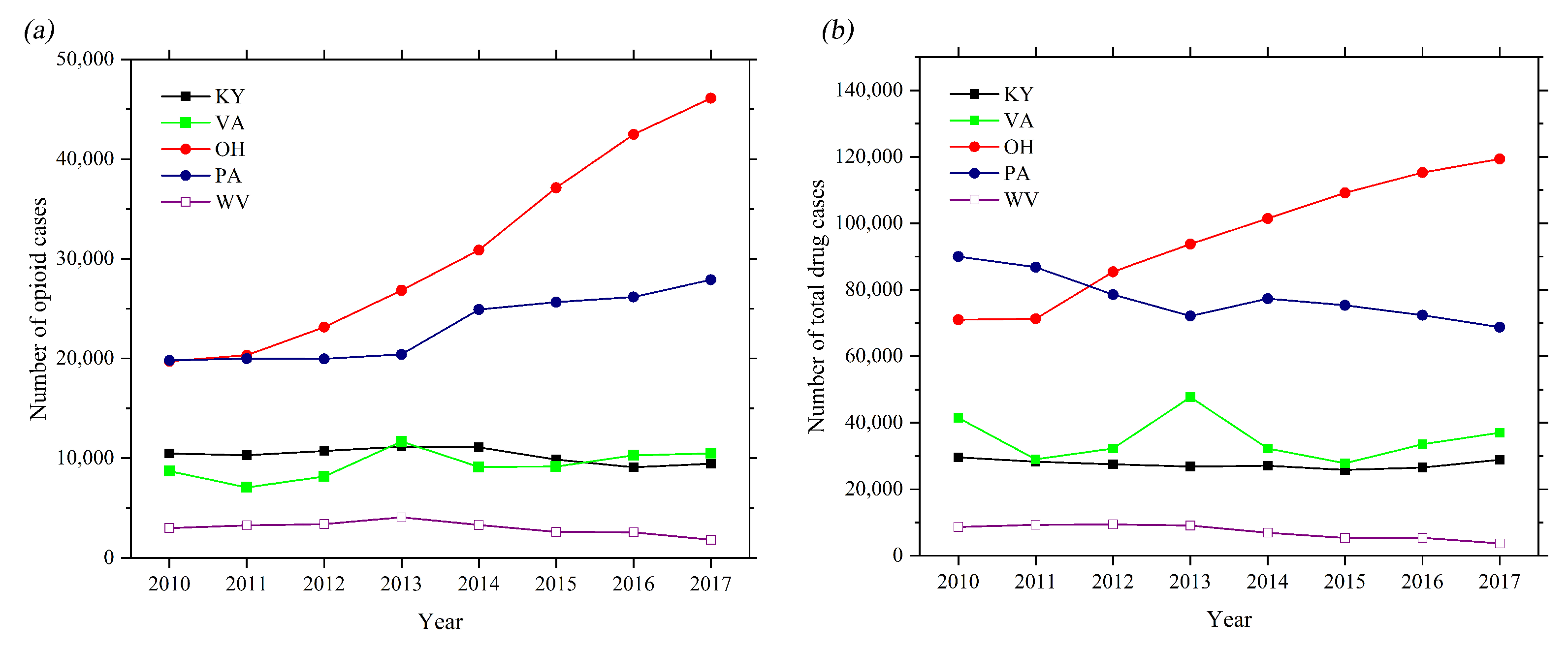
3.1. Trend Analyses of the Amount of Drugs of Five States
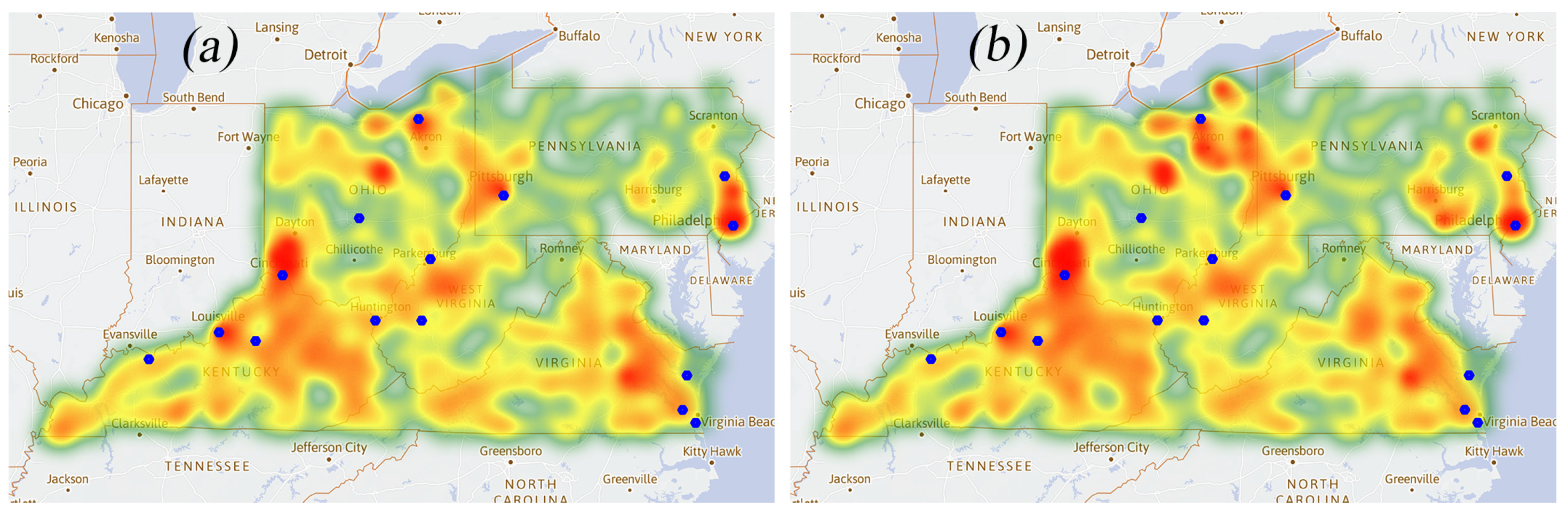
3.2. Heat Maps of the Opioid Cases
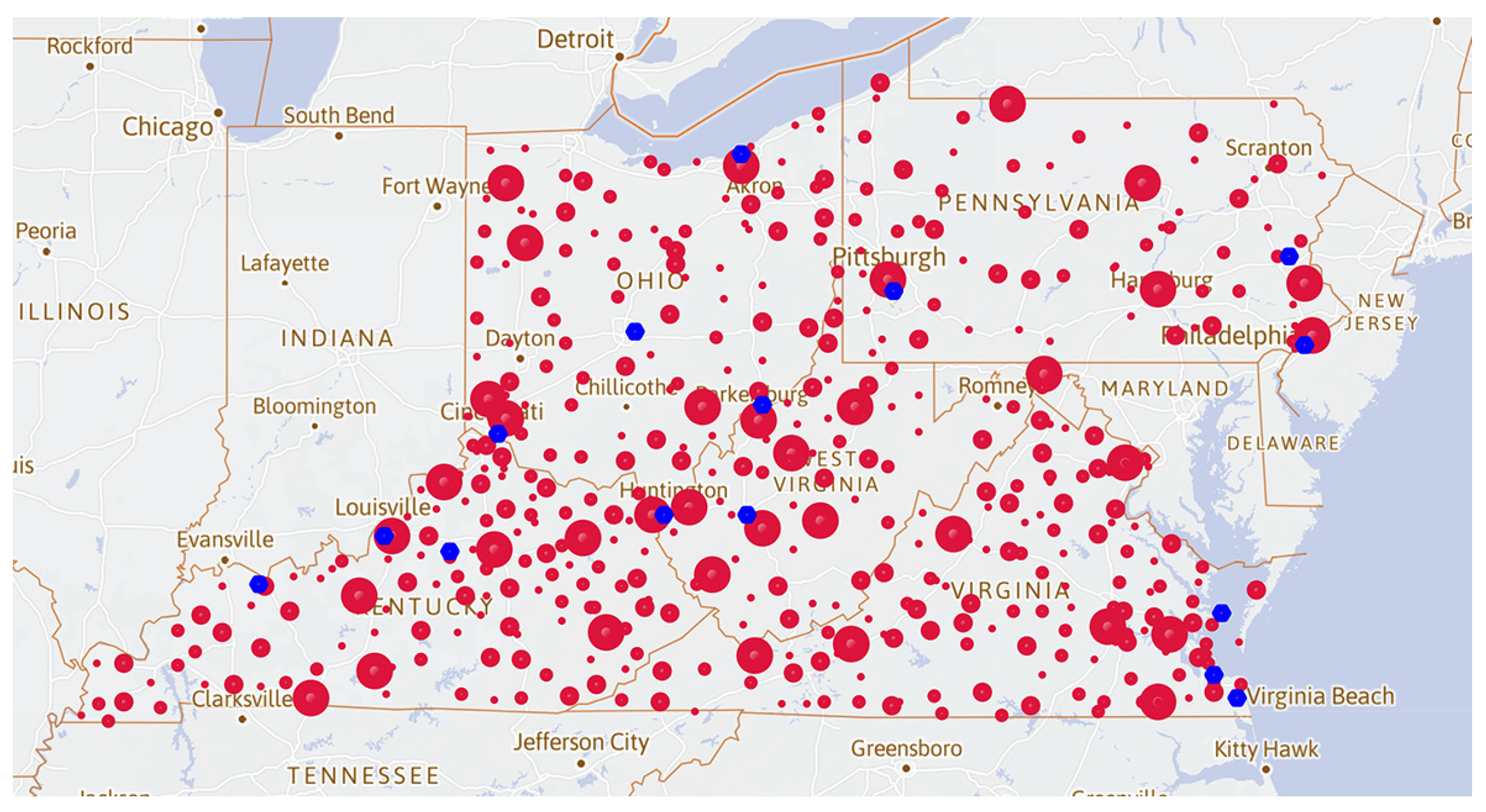
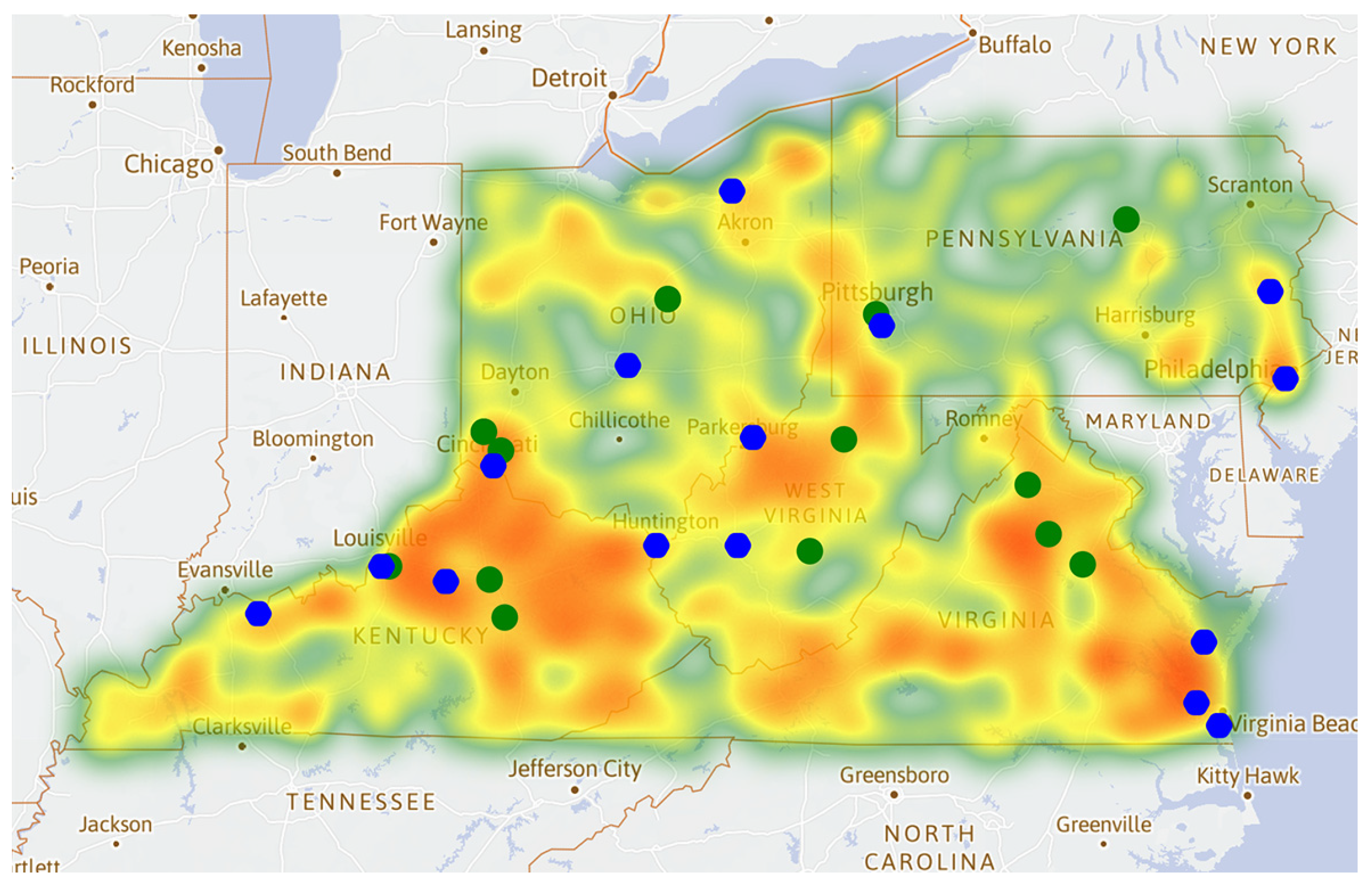
3.3. Advantage Point Distribution Map of the Opioid Cases
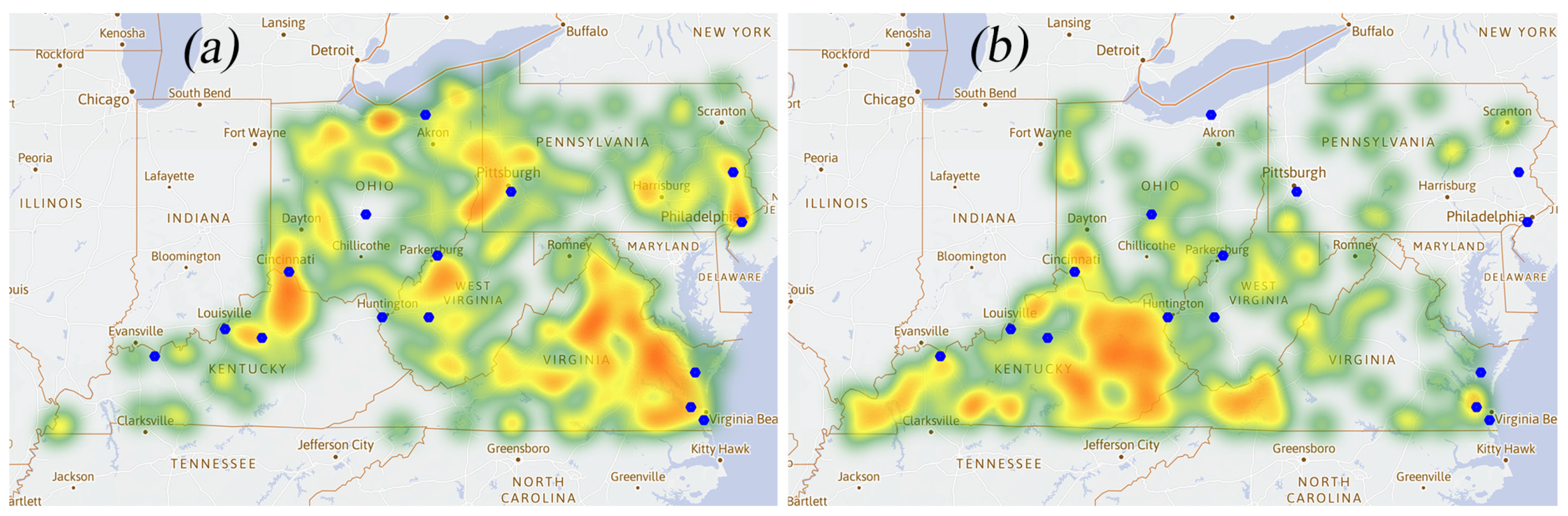
3.4. Heat Map of
3.5. Application of the EWM-RSR Model
3.6. Application of the AR Model
3.7. Application of the Comprehensive Evaluation Model
3.8. Model Modification with the LASSO Regression Method
3.9. Simulation and Estimation of Policy Effectiveness
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Florence, C.S.; Zhou, C.; Luo, F.; Xu, L. The Economic Burden of Prescription Opioid Overdose, Abuse, and Dependence in the United States, 2013. Med. Care 2016, 54, 901–906. [Google Scholar] [CrossRef] [PubMed]
- Wilson, N.; Kariisa, M.; Seth, P.; Smith, H., IV; Davis, N.L. Drug and Opioid-Involved Overdose Deaths—United States, 2017–2018. MMWR Morb. Mortal. Wkly. Rep. 2020, 69, 290–297. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ruhm, C.J. Geographic Variation in Opioid and Heroin Involved Drug Poisoning Mortality Rates. Am. J. Prev. Med. 2017, 53, 745–753. [Google Scholar] [CrossRef]
- Paulozzi, L.J.; Xi, Y. Recent changes in drug poisoning mortality in the United States by urban-rural status and by drug type. Pharmacoepidemiol. Drug Saf. 2008, 17, 997–1005. [Google Scholar] [CrossRef]
- Cordes, J. Spatial Trends in Opioid Overdose Mortality in North Carolina: 1999–2015. Southeast. Geogr. 2018, 58, 193–211. [Google Scholar] [CrossRef]
- Cerda, M.; Ransome, Y.; Keyes, K.M.; Koenen, K.C.; Tardiff, K.; Vlahov, D.; Galea, S. Revisiting the role of the urban environment in substance use: The case of analgesic overdose fatalities. Am. J. Public Health 2013, 103, 2252–2260. [Google Scholar] [CrossRef]
- Mair, C.; Sumetsky, N.; Burke, J.G.; Gaidus, A. Investigating the Social Ecological Contexts of Opioid Use Disorder and Poisoning Hospitalizations in Pennsylvania. J. Stud. Alcohol Drugs 2018, 79, 899–908. [Google Scholar] [CrossRef]
- Kulldorff, M. SaTScan User Guide; Martin Kulldorff and Information Management Services Inc.: Boston, MA, USA, 2021. [Google Scholar]
- Basak, A.; Cadena, J.; Marathe, A.; Vullikanti, A. Detection of Spatiotemporal Prescription Opioid Hot Spots With Network Scan Statistics: Multistate Analysis. JMIR Public Health Surveill. 2019, 10, e12110. [Google Scholar] [CrossRef] [PubMed]
- Romeiser, J.L.; Labriola, J.; Meliker, J.R. Geographic patterns of prescription opioids and opioid overdose deaths in New York State, 2013–2015. Drug Alcohol Depend. 2019, 195, 94–100. [Google Scholar] [CrossRef]
- Pesarsick, J.; Gwilliam, M.; Adeniran, O.; Rudisill, T.; Smith, G.; Hendricks, B. Identifying high-risk areas for nonfatal opioid overdose: A spatial case-control study using EMS run data. Ann. Epidemiol. 2019, 36, 20–25. [Google Scholar] [CrossRef]
- Phalen, P.; Ray, B.; Watson, D.P.; Huynh, P.; Greene, M.S. Fentanyl related overdose in Indianapolis: Estimating trends using multilevel Bayesian models. Addict. Behav. 2018, 86, 4–10. [Google Scholar] [CrossRef]
- Heavey, S.C.; Delmerico, A.M.; Burstein, G.; Moore, C.; Wieczorek, W.F.; Collins, R.L.; Chang, Y.P.; Homish, G.G. Descriptive Epidemiology for Community-wide Naloxone Administration by Police Officers and Firefighters Responding to Opioid Overdose. J. Community Health 2018, 43, 304–311. [Google Scholar] [CrossRef]
- Pear, V.A.; Ponicki, W.R.; Gaidus, A.; Keyes, K.M.; Martins, S.S.; Fink, D.S.; Rivera-Aguirre, A.; Gruenewald, P.J.; Cerda, M. Urban-rural variation in the socioeconomic determinants of opioid overdose. Drug Alcohol Depend. 2019, 195, 66–73. [Google Scholar] [CrossRef] [PubMed]
- Linton, S.L.; Jennings, J.M.; Latkin, C.A.; Gomez, M.B.; Mehta, S.H. Application of space-time scan statistics to describe geographic and temporal clustering of visible drug activity. J. Urban Health Bull. N. Y. Acad. Med. 2014, 91, 940–956. [Google Scholar] [CrossRef] [Green Version]
- Neil, D.B.; Herlands, W. Machine Learning for Drug Overdose Surveillance. J. Technol. Hum. Serv. 2018, 36, 8–14. [Google Scholar] [CrossRef] [Green Version]
- Stopka, T.J.; Jacque, E.; Kelso, P.; Guhn-Knight, H.; Nolte, K.; Hoskinson, R., Jr.; Jones, A.; Harding, J.; Drew, A.; VanDonsel, A.; et al. The opioid epidemic in rural northern New England: An approach to epidemiologic, policy, and legal surveillance. Prev. Med. 2019, 128, 105740. [Google Scholar] [CrossRef]
- Davis, C.S.; Carr, D. Legal changes to increase access to naloxone for opioid overdose reversal in the United States. Drug Alcohol Depend. 2015, 157, 112–120. [Google Scholar] [CrossRef] [PubMed]
- Cataife, G.; Dong, J.; Davis, C.S. Regional and temporal effects of naloxone access laws on opioid overdose mortality. Substance Abuse 2020. [Google Scholar] [CrossRef] [PubMed]
- Hedegaard, H.; Bastian, B.A.; Trinidad, J.P.; Spencer, M.R.; Warner, M. Regional Differences in the Drugs Most Frequently Involved in Drug Overdose Deaths: United States, 2017. National vital statistics reports: From the Centers for Disease Control and Prevention, National Center for Health Statistics. Natl. Vital Stat. Syst. 2019, 68, 1–16. [Google Scholar]
- West, N.A.; Severtson, S.G.; Green, J.L.; Dart, R.C. Trends in abuse and misuse of prescription opioids among older adults. Drug Alcohol Depend. 2015, 149, 117–121. [Google Scholar] [CrossRef]
- Han, D.H.; Lee, S.; Seo, D.C. Using machine learning to predict opioid misuse among U.S. adolescents. Prev. Med. 2020, 130, 105886. [Google Scholar] [CrossRef] [PubMed]
- Boslett, A.J.; Denham, A.; Hill, E.L.; Adams, M.C.B. Unclassified drug overdose deaths in the opioid crisis: Emerging patterns of inequity. J. Am. Med. Inform. Assoc. JAMIA 2019, 26, 767–777. [Google Scholar] [CrossRef] [Green Version]
- Burke, D.S. Forecasting the opioid epidemic. Science 2016, 354, 529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jalal, H.; Buchanich, J.M.; Sinclair, D.R.; Roberts, M.S.; Burke, D.S. Age and generational patterns of overdose death risk from opioids and other drugs. Nat. Med. 2020, 26, 699–704. [Google Scholar] [CrossRef]
- Wang, Z.; Dang, S.; Xing, Y.; Li, Q.; Yan, H. Applying Rank Sum Ratio (RSR) to the Evaluation of Feeding Practices Behaviors, and Its Associations with Infant Health Risk in Rural Lhasa, Tibet. Int. J. Environ. Res. Public Health 2015, 12, 15173–15181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Breunig, M.M.; Kriegel, H.-P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. ACM Sigmod Rec. 2000, 29, 93–104. [Google Scholar] [CrossRef]
- Ohtsu, K.; Peng, H.; Kitagawa, G. Time Series Modeling for Analysis and Control; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Kubat, M. An Introduction to Machine Learning; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Jalal, H.; Buchanich, J.M.; Roberts, M.S.; Balmert, L.C.; Zhang, K.; Burke, D.S. Changing dynamics of the drug overdose epidemic in the United States from 1979 through 2016. Science 2018, 361. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | County | |||||
|---|---|---|---|---|---|---|
| OH | 39,061 | 0.37 | 3490.25 | 0.106 | 0.881 | 1.064 |
| 39,113 | 0.32 | 885.25 | 0.102 | 0.742 | 0.964 | |
| 39,017 | 0.36 | 426 | 0.086 | 0.42 | 0.908 | |
| PA | 42,003 | 0.48 | 1210.25 | 0.111 | 0.846 | 1.11 |
| 42,081 | 0.35 | 110 | 0.175 | 0.672 | 0.995 | |
| KY | 21,151 | 0.57 | 92.5 | 0.054 | 0.49 | 1.085 |
| 21,067 | 0.38 | 93.75 | 0.099 | 0.66 | 0.989 | |
| 21,111 | 0.37 | 86.25 | 0.115 | 0.897 | 0.934 | |
| VA | 51,187 | 0.52 | 36.5 | 0.098 | 0.418 | 1.072 |
| 51,177 | 0.39 | 97.25 | 0.125 | 0.44 | 0.979 | |
| 51,047 | 0.33 | 47.75 | 0.19 | 0.442 | 0.927 | |
| WV | 54,067 | 0.5 | 29.25 | 0.084 | 0.664 | 0.987 |
| 54,033 | 0.47 | 31.25 | 0.236 | 0.546 | 0.89 |
| State | County | ||||
|---|---|---|---|---|---|
| OH | 39,035 | 0.844 | 1.193 | 2 | 1 |
| 39,085 | 0.872 | 1.000 | 2 | 1 | |
| PA | 42,101 | 0.887 | 1.053 | 2 | 1 |
| KY | 21,059 | 0.592 | 1.007 | 3 | 2 |
| 21,107 | 0.504 | 0.951 | 3 | 2 | |
| 21,227 | 0.474 | 1.107 | 4 | 3 | |
| VA | 51,041 | 0.832 | 1.108 | 2 | 1 |
| 51,121 | 0.671 | 1.226 | 3 | 2 | |
| 51,047 | 0.634 | 1.041 | 3 | 2 | |
| WV | 54,107 | 0.833 | 1.028 | 2 | 1 |
| Coefficient | Explanation | ||
|---|---|---|---|
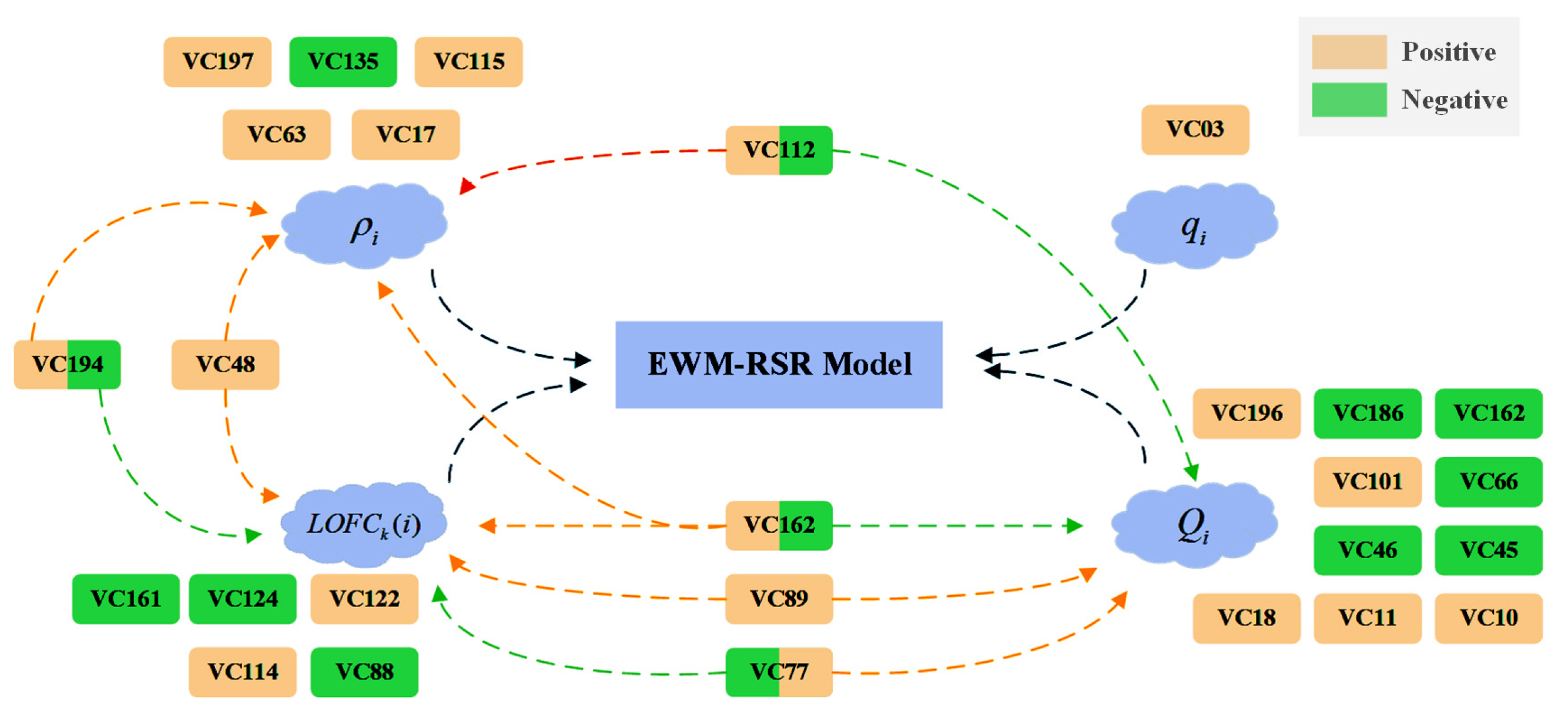
| VC112 | 0.18404 | The health of people who live out of a nursing home or institutions with medical instructions is not guaranteed. It is possible for them to access opioids through illegal channels. The disabled people may use opioids to alleviate physical or mental suffering which leads to opioid addiction. | |
| VC115 | 0.16771 | ||
| VC03 | 0.24625 | If the proportion of drug users to the total population is fixed, a larger total number of households leads to more drug users. | |
| VC101 | 0.12905 | Veterans should develop a certain degree of self-control through intensive training. They have a certain understanding of the harm of opioids. The increase in the proportion can lead to a less rapid growth of opioid usage. | |
| VC112 | −0.25485 | The healthcare of disabled civilians is not guaranteed for those who live out of a nursing home or institutions with medical instructions. The percentage of the population is relatively small among drug users due to finances and health conditions. They are less favored for opioids. | |
| VC114 | 0.50514 | People with disabilities are more likely to be exposed to opioids. Without appropriate medical guidance, the possibility of misuse or opioid abuse is high. The more people there are with disabilities in a county, the more likely it is to have opioid use. Therefore, a higher proportion of the disabled population leads to more opioid cases in the county, and a greater advantage ratio of the county relative to surrounding counties. | |
| VC122 | 0.23481 | If a county has a small population flow range, the number of drug users may increase due to a gathering of drug users. As a result, the county may develop a greater advantage ratio of the county to surrounding counties. |
| Simulation Degree | Period | RSR | RSR |
|---|---|---|---|
| Base | N/A | 0.60846 | N/A |
| 10% | 1 | 0.60589 | 0.00257 |
| 2 | 0.60461 | 0.00128 | |
| 3 | 0.60207 | 0.00254 | |
| 4 | 0.6008 | 0.00127 | |
| 5 | 0.59578 | 0.00502 | |
| 20% | 1 | 0.60461 | 0.00385 |
| 2 | 0.6008 | 0.00381 | |
| 3 | 0.59205 | 0.00875 | |
| 4 | 0.58225 | 0.0098 | |
| 5 | 0.58104 | 0.00121 | |
| 50% | 1 | 0.59081 | 0.01765 |
| 2 | 0.57383 | 0.01698 | |
| 3 | 0.56671 | 0.00712 | |
| 4 | 0.56553 | 0.00118 | |
| 5 | 0.56435 | 0.00118 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, J.; Ren, S.; Huang, X.; Peng, K.; Chen, Z. Evaluation of Policy Effectiveness by Mathematical Modeling for the Opioid Crisis with Spatial Study and Trend Analysis. Healthcare 2021, 9, 585. https://0-doi-org.brum.beds.ac.uk/10.3390/healthcare9050585
Pan J, Ren S, Huang X, Peng K, Chen Z. Evaluation of Policy Effectiveness by Mathematical Modeling for the Opioid Crisis with Spatial Study and Trend Analysis. Healthcare. 2021; 9(5):585. https://0-doi-org.brum.beds.ac.uk/10.3390/healthcare9050585
Chicago/Turabian StylePan, Jiaji, Shen Ren, Xiuxiang Huang, Ke Peng, and Zhongxiang Chen. 2021. "Evaluation of Policy Effectiveness by Mathematical Modeling for the Opioid Crisis with Spatial Study and Trend Analysis" Healthcare 9, no. 5: 585. https://0-doi-org.brum.beds.ac.uk/10.3390/healthcare9050585