Quantifying the Model Risk Inherent in the Calibration and Recalibration of Option Pricing Models


Abstract
:1. Introduction
- Parameter uncertainty (and sensitivity to parameters)—let us call this “Type 0” model risk for short. If model parameters need to be statistically estimated, then they will only be known up to some level of statistical confidence, and this parameter uncertainty induces uncertainty regarding the correctness of the model outputs. Examples of where this type of risk is considered explicitly in the literature include Löffler (2003); Bannör and Scherer (2013) and Kerkhof et al. (2010).
- Inability to fit a model to a full set of simultaneous market observations —this is “calibration error”, let’s call this “Type 1” model risk for short. “Calibration” in this context refers to choosing model parameters in such a way that prices for derivative financial instruments that are implied by the model match market prices at one given point in time. Thus, calibration error on single-time-point (a.k.a. “cross-sectional”) market data means that these data already contradict the model assumptions. The classical example of this is the Black/Scholes implied volatility smile.
- Change in parameters due to recalibration—let us call this “Type 2” model risk for short. Once one moves from one day to the next, this aspect of model risk becomes apparent: in order to again fit the market as closely as possible, it is common practice in the industry to recalibrate models. This recalibration results in model parameters (which the models assume to be fixed) changing from day-to-day, contradicting the model assumptions.
- The “true” dynamics of state variables do not match model dynamics—let us call this violation of model assumptions “Type 3” model risk. The classical example of this is the econometric rejection of the hypothesis that asset prices follow geometric Brownian motion, thus invalidating the key assumption in the seminal model of Black and Scholes (1973). This type of model risk is considered, for example, in Kerkhof et al. (2010), who also relate this to identification risk, which they define as risk that “arises when observationally indistinguishable models have different consequences for capital reserves”. Boucher et al. (2014) present a method for making value-at-risk more robust with respect to this source of model risk by “learning” from the results of model backtesting. Type 3 model risk would impact, in particular, the effectiveness of hedging strategies based on a model, for example Detering and Packham (2016) take the approach of measuring model risk that is based on the residual profit/loss from hedging in a misspecified model.
- Less stringent requirements of an exact fit to market observations (Type 1) allows for less frequent recalibration (Type 2).
- Instead of different model dynamics (Type 3), one could consider a parameterised family of models (Type 2).
- Regime-switching models “legalise” changes in parameters, so Type 2 becomes more like Type 3.
- Adding parameters shifts model risk from Type 1 to Type 2 (or, to a certain extent, to Type 0).
- Adding state variables shifts model risk from Type 2 to Type 3.
2. Quantifying Model Risk by Relative Entropy
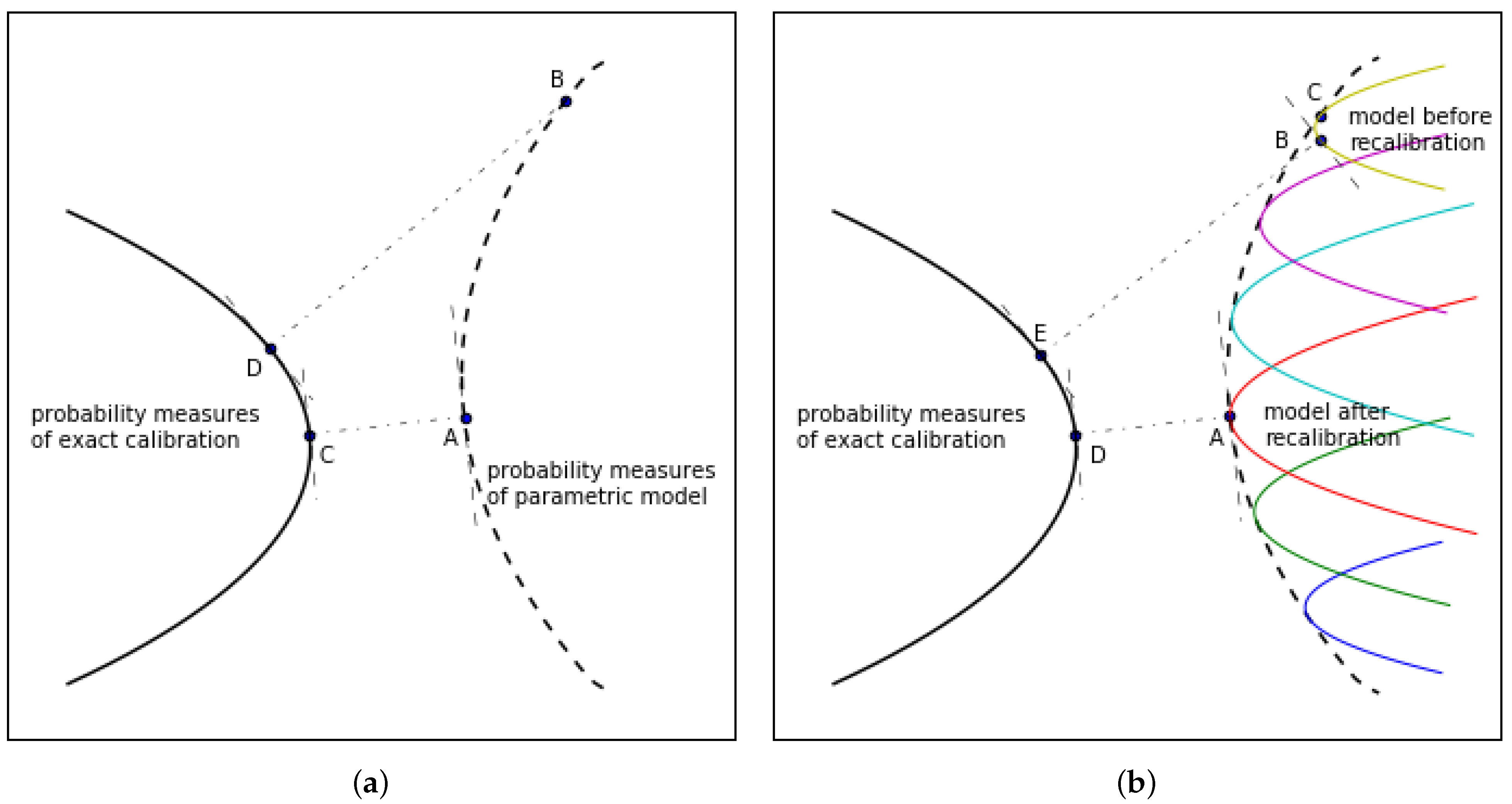
2.1. Quantifying Calibration Error
2.2. Including Model Risk Due to Recalibration
2.3. The Treatment of Latent State Variables
3. Numerical Implementation
- (1)
- Produce from a parametric model that is based on an initial guess of the model parameters (and latent state variables, where required).
- (2)
- Solve, for , via Lagrange multipliers for the constrained problem that minimises .
- (3)
- Solve, for , to obtain model parameters for the that minimises .
- (4)
- Iterate steps 2 and 3: until convergence.
3.1. Step 1
3.2. Step 2
3.3. Steps 3 and 4
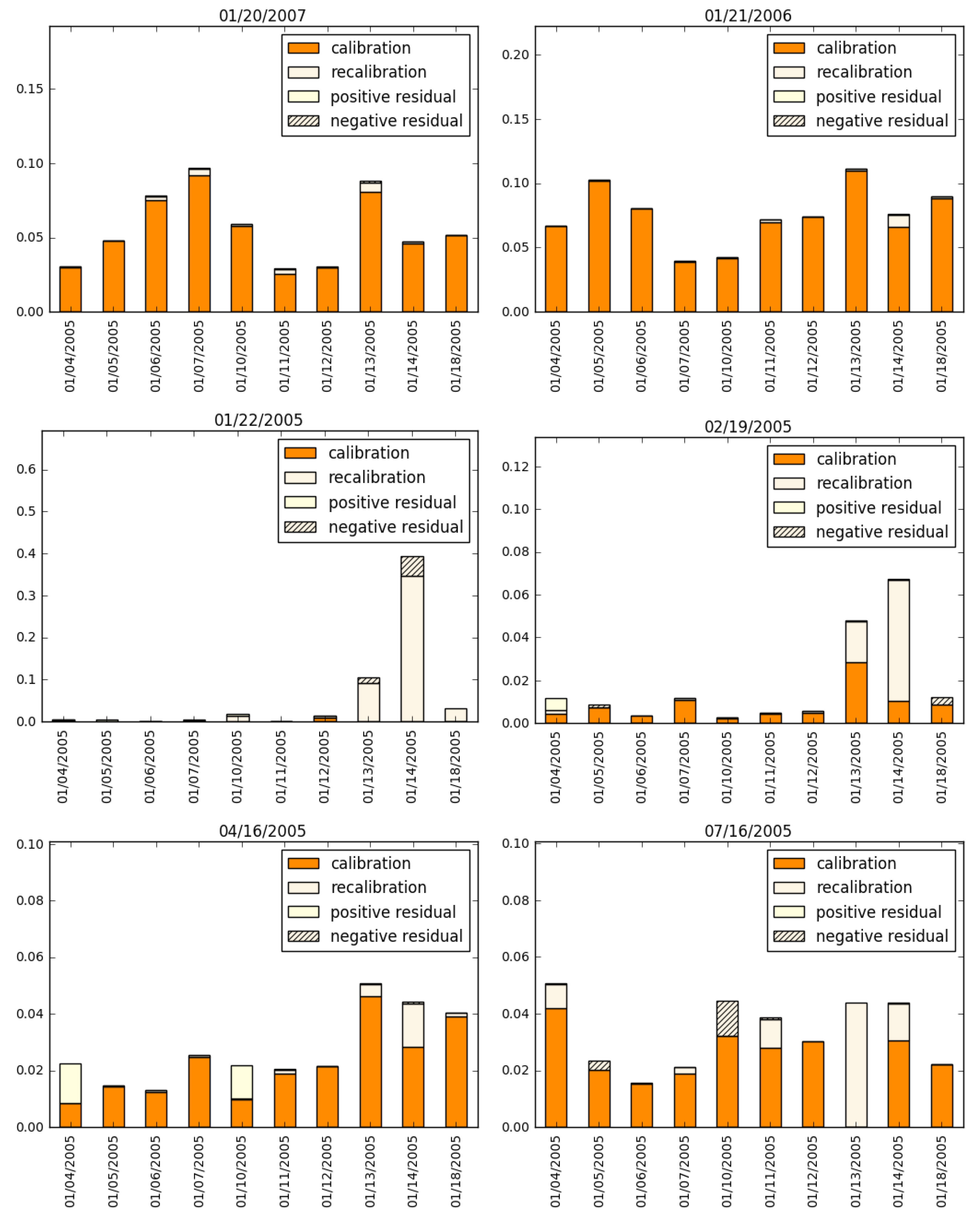
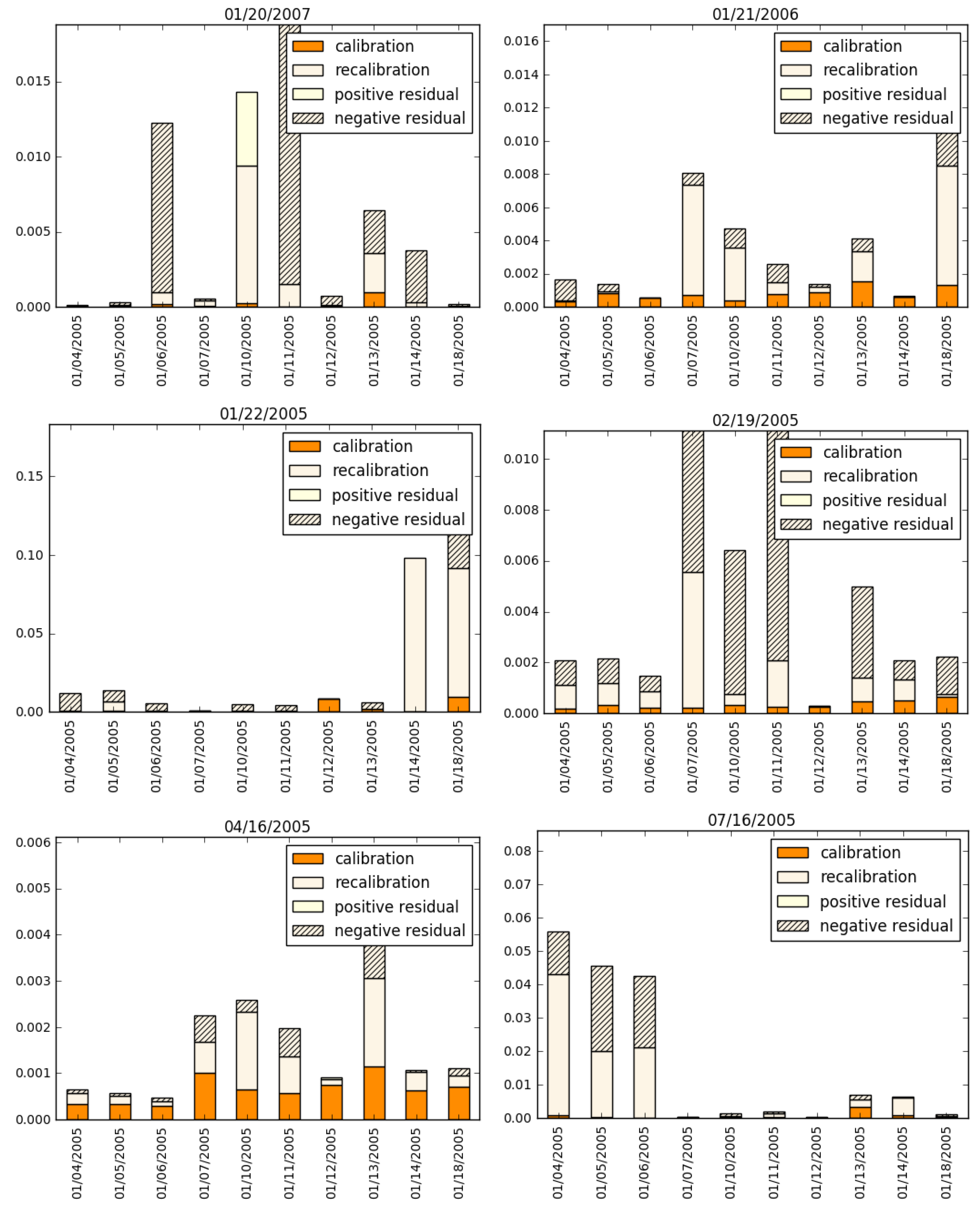
4. Examining the Trade-Off between Calibration Error and Model Risk Due to Recalibration
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Derivation of the Recalibration Model Risk Quantity in the Black/Scholes Model
References
- Ahmadi-Javid, Amir. 2012. Entropic value-at-risk: A new coherent risk measure. Journal of Optimization Theory and Applications 155: 1105–23. [Google Scholar] [CrossRef]
- Ali, Syed Mumtaz, and Samuel D. Silvey. 1966. A general class of coefficients of divergence of one distribution from another. Journal of the Royal Statistical Society: Series B 28: 131–42. [Google Scholar] [CrossRef]
- Bannör, Karl F., and Matthias Scherer. 2013. Capturing parameter risk with convex risk measures. European Actuarial Journal 3: 97–132. [Google Scholar] [CrossRef]
- Bartl, Daniel, Samuel Drapeau, and Ludovic Tangpi. 2020. Computational aspects of robust optimized certainty equivalents and option pricing. Mathematical Finance 30: 287–309. [Google Scholar] [CrossRef] [Green Version]
- Black, Fischer, and Myron Scholes. 1973. The pricing of options and corporate liabilities. Journal of Political Economy 81: 637–54. [Google Scholar] [CrossRef] [Green Version]
- Blanchet, Jose, Lin Chen, and Xun Yu Zhou. 2018. Distributionally robust mean–variance portfolio selection withWasserstein distances. arXiv, arXiv:1802.04885. [Google Scholar]
- Board of Governors of the Federal Reserve System Office of the Comptroller of the Currency. 2011. Supervisory Guidance on Model Risk Management. Technical Report OCC 2011-12 Attachment. Washington D.C.: Office of the Comptroller of the Currency. [Google Scholar]
- Boucher, Christophe M., Jón Danielsson, Patrick S. Kouontchou, and Bertrand B. Maillet. 2014. Risk models–at–risk. Journal of Banking & Finance 44: 72–92. [Google Scholar]
- Box, George E. P., and Norman R. Draper. 1987. Empirical Model–Building and Response Surfaces. Hoboken: Wiley. [Google Scholar]
- Breeden, Douglas T., and Robert H. Litzenberger. 1978. Prices of state-contingent claims implicit in option prices. Journal of Business 51: 621–51. [Google Scholar] [CrossRef]
- Breuer, Thomas, and Imre Csiszár. 2016. Measuring distribution model risk. Mathematical Finance 26: 395–411. [Google Scholar] [CrossRef] [Green Version]
- Buchen, Peter W., and Michael Kelly. 1996. The maximum entropy distribution of an asset inferred from option prices. Journal of Financial and Quantitative Analysis 31: 143–59. [Google Scholar] [CrossRef]
- Cheng, Benjamin, Christina Sklibosios Nikitopoulos, and Erik Schlögl. 2018. Pricing of long-dated commodity derivatives: Do stochastic interest rates matter? Journal of Banking & Finance 95: 148–66. [Google Scholar]
- Csiszár, Imre. 1967. Information-type measures of difference of probability distributions and indirect observations. Studia Scientiarum Mathematicarum Hungarica 2: 299–318. [Google Scholar]
- Cui, Yiran, Sebastian del Baño Rollin, and Guido Germano. 2017. Full and fast calibration of the Heston stochastic volatility model. European Journal of Operational Research 263: 625–38. [Google Scholar] [CrossRef]
- Detering, Nils, and Natalie Packham. 2016. Model risk of contingent claims. Quantitative Finance 16: 1357–74. [Google Scholar] [CrossRef]
- Feng, Yu, and Erik Schlögl. 2018. Model risk measurement under Wasserstein distance. arXiv, arXiv:1809.03641. [Google Scholar] [CrossRef] [Green Version]
- Gatheral, Jim. 2006. The Volatility Surface: A Practitioner’s Guide. Hoboken: John Wiley & Sons. [Google Scholar]
- Glasserman, Paul, and Xingbo Xu. 2014. Robust risk measurement and model risk. Quantitative Finance 14: 29–58. [Google Scholar] [CrossRef]
- Hansen, Lars Peter, and Thomas J. Sargent. 2006. Robustness. Princeton: Princeton University Press. [Google Scholar]
- Heston, Steven L. 1993. A closed–form solution for options with stochastic volatility with applications to bond and currency options. The Review of Financial Studies 6: 327–43. [Google Scholar] [CrossRef] [Green Version]
- Kerkhof, Jeroen, Bertrand Melenberg, and Hans Schumacher. 2010. Model risk and capital reserves. Journal of Banking & Finance 34: 267–79. [Google Scholar]
- Löffler, Gunter. 2003. The effects of estimation error on measures of portfolio credit risk. Journal of Banking & Finance 27: 1427–53. [Google Scholar]
- Merton, Robert C. 1973. Theory of rational option pricing. The Bell Journal of Economics and Management Science 4: 141–83. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Risk Measure | Black-Scholes | Heston | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 Day | 3 Days | 1 Week | 2 Weeks | 1 Quarter | 1 Day | 3 Days | 1 Week | 2 Weeks | 1 Quarter | ||
| Aggregate Model Risk | |||||||||||
| mean | 0.070 | 0.071 | 0.073 | 0.073 | 0.085 | 0.037 | 0.035 | 0.038 | 0.039 | 0.046 | |
| median | 0.045 | 0.047 | 0.047 | 0.051 | 0.057 | 0.005 | 0.005 | 0.005 | 0.006 | 0.010 | |
| Quantile | 99% | 0.474 | 0.427 | 0.471 | 0.455 | 0.462 | 0.508 | 0.462 | 0.512 | 0.503 | 0.649 |
| 95% | 0.212 | 0.221 | 0.221 | 0.212 | 0.251 | 0.173 | 0.169 | 0.177 | 0.177 | 0.185 | |
| 90% | 0.158 | 0.160 | 0.165 | 0.160 | 0.192 | 0.096 | 0.097 | 0.098 | 0.105 | 0.121 | |
| 75% | 0.092 | 0.094 | 0.095 | 0.099 | 0.112 | 0.027 | 0.027 | 0.029 | 0.031 | 0.034 | |
| Calibration Error | |||||||||||
| mean | 0.055 | 0.066 | 0.069 | 0.072 | 0.084 | 0.008 | 0.026 | 0.032 | 0.036 | 0.045 | |
| median | 0.038 | 0.043 | 0.045 | 0.049 | 0.057 | 0.001 | 0.003 | 0.004 | 0.005 | 0.009 | |
| Quantile | 99% | 0.239 | 0.397 | 0.433 | 0.443 | 0.455 | 0.163 | 0.416 | 0.496 | 0.495 | 0.648 |
| 95% | 0.171 | 0.207 | 0.212 | 0.210 | 0.249 | 0.015 | 0.130 | 0.158 | 0.168 | 0.182 | |
| 90% | 0.135 | 0.151 | 0.158 | 0.158 | 0.191 | 0.008 | 0.065 | 0.083 | 0.097 | 0.119 | |
| 75% | 0.075 | 0.087 | 0.091 | 0.096 | 0.111 | 0.003 | 0.012 | 0.019 | 0.026 | 0.034 | |
| Model Risk due to Recalibration | |||||||||||
| mean | 0.024 | 0.009 | 0.005 | 0.002 | 0.001 | 0.057 | 0.019 | 0.011 | 0.006 | 0.001 | |
| median | 0.002 | 0.001 | 0.001 | 0.000 | 0.000 | 0.004 | 0.001 | 0.001 | 0.001 | 0.000 | |
| Quantile | 99% | 0.458 | 0.196 | 0.057 | 0.030 | 0.012 | 0.630 | 0.226 | 0.117 | 0.067 | 0.011 |
| 95% | 0.103 | 0.034 | 0.021 | 0.010 | 0.005 | 0.315 | 0.108 | 0.062 | 0.032 | 0.006 | |
| 90% | 0.056 | 0.020 | 0.011 | 0.006 | 0.002 | 0.164 | 0.052 | 0.031 | 0.016 | 0.004 | |
| 75% | 0.013 | 0.006 | 0.004 | 0.002 | 0.001 | 0.055 | 0.016 | 0.011 | 0.005 | 0.001 | |
| Risk Measure | Black-Scholes | Heston | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 Day | 3 Days | 1 Week | 2 Weeks | 1 Quarter | 1 Day | 3 Days | 1 Week | 2 Weeks | 1 Quarter | ||
| Aggregate Model Risk | |||||||||||
| mean | 0.165 | 0.168 | 0.165 | 0.165 | 0.188 | 0.115 | 0.105 | 0.113 | 0.114 | 0.127 | |
| median | 0.109 | 0.111 | 0.112 | 0.115 | 0.138 | 0.053 | 0.050 | 0.055 | 0.053 | 0.059 | |
| Quantile | 99% | 0.705 | 0.722 | 0.722 | 0.699 | 0.728 | 0.726 | 0.668 | 0.711 | 0.699 | 0.744 |
| 95% | 0.519 | 0.530 | 0.521 | 0.496 | 0.549 | 0.475 | 0.438 | 0.455 | 0.467 | 0.560 | |
| 90% | 0.393 | 0.391 | 0.387 | 0.385 | 0.408 | 0.330 | 0.287 | 0.320 | 0.324 | 0.380 | |
| 75% | 0.219 | 0.223 | 0.214 | 0.215 | 0.256 | 0.145 | 0.137 | 0.142 | 0.153 | 0.157 | |
| Calibration Error | |||||||||||
| mean | 0.125 | 0.155 | 0.158 | 0.162 | 0.187 | 0.055 | 0.083 | 0.103 | 0.107 | 0.126 | |
| median | 0.082 | 0.102 | 0.106 | 0.111 | 0.137 | 0.006 | 0.022 | 0.043 | 0.046 | 0.058 | |
| Quantile | 99% | 0.655 | 0.701 | 0.709 | 0.696 | 0.728 | 0.626 | 0.651 | 0.706 | 0.688 | 0.744 |
| 95% | 0.400 | 0.482 | 0.507 | 0.494 | 0.548 | 0.329 | 0.381 | 0.438 | 0.445 | 0.557 | |
| 90% | 0.295 | 0.359 | 0.362 | 0.379 | 0.408 | 0.172 | 0.250 | 0.298 | 0.306 | 0.375 | |
| 75% | 0.171 | 0.208 | 0.207 | 0.212 | 0.255 | 0.034 | 0.103 | 0.127 | 0.141 | 0.155 | |
| Model Risk due to Recalibration | |||||||||||
| mean | 0.036 | 0.014 | 0.008 | 0.004 | 0.001 | 0.119 | 0.044 | 0.012 | 0.012 | 0.003 | |
| median | 0.004 | 0.002 | 0.001 | 0.001 | 0.000 | 0.043 | 0.016 | 0.003 | 0.003 | 0.001 | |
| Quantile | 99% | 0.405 | 0.172 | 0.091 | 0.050 | 0.010 | 0.757 | 0.255 | 0.087 | 0.077 | 0.012 |
| 95% | 0.173 | 0.066 | 0.035 | 0.018 | 0.004 | 0.543 | 0.187 | 0.056 | 0.064 | 0.011 | |
| 90% | 0.109 | 0.038 | 0.022 | 0.012 | 0.003 | 0.411 | 0.151 | 0.034 | 0.045 | 0.009 | |
| 75% | 0.036 | 0.013 | 0.008 | 0.004 | 0.001 | 0.142 | 0.052 | 0.016 | 0.013 | 0.003 | |
| Risk Measure | Black-Scholes | Heston | |||||||
|---|---|---|---|---|---|---|---|---|---|
| All | 0–0.2 Year | 0.2–0.7 Year | >0.7 Year | All | 0–0.2 Year | 0.2–0.7 Year | >0.7 Year | ||
| Aggregate Model Risk | |||||||||
| mean | 0.070 | 0.041 | 0.066 | 0.109 | 0.037 | 0.039 | 0.024 | 0.046 | |
| median | 0.045 | 0.021 | 0.052 | 0.081 | 0.005 | 0.004 | 0.004 | 0.008 | |
| Quantile | 99% | 0.474 | 0.471 | 0.266 | 0.567 | 0.508 | 0.590 | 0.302 | 0.472 |
| 95% | 0.212 | 0.120 | 0.185 | 0.282 | 0.173 | 0.243 | 0.091 | 0.191 | |
| 90% | 0.158 | 0.081 | 0.143 | 0.213 | 0.096 | 0.074 | 0.066 | 0.142 | |
| 75% | 0.092 | 0.047 | 0.090 | 0.141 | 0.027 | 0.021 | 0.015 | 0.054 | |
| Calibration Error | |||||||||
| mean | 0.055 | 0.026 | 0.057 | 0.087 | 0.008 | 0.012 | 0.004 | 0.007 | |
| median | 0.038 | 0.014 | 0.048 | 0.068 | 0.001 | 0.001 | 0.001 | 0.001 | |
| Quantile | 99% | 0.239 | 0.157 | 0.230 | 0.289 | 0.163 | 0.072 | 0.052 | 0.116 |
| 95% | 0.171 | 0.091 | 0.157 | 0.212 | 0.015 | 0.021 | 0.011 | 0.017 | |
| 90% | 0.135 | 0.062 | 0.126 | 0.181 | 0.008 | 0.006 | 0.007 | 0.010 | |
| 75% | 0.075 | 0.036 | 0.077 | 0.128 | 0.003 | 0.002 | 0.003 | 0.003 | |
| Model Risk due to Recalibration | |||||||||
| mean | 0.024 | 0.020 | 0.013 | 0.038 | 0.057 | 0.062 | 0.048 | 0.060 | |
| median | 0.002 | 0.002 | 0.001 | 0.003 | 0.004 | 0.004 | 0.003 | 0.009 | |
| Quantile | 99% | 0.458 | 0.506 | 0.116 | 0.662 | 0.630 | 0.702 | 0.536 | 0.512 |
| 95% | 0.103 | 0.066 | 0.066 | 0.169 | 0.315 | 0.443 | 0.274 | 0.247 | |
| 90% | 0.056 | 0.030 | 0.042 | 0.102 | 0.164 | 0.223 | 0.127 | 0.160 | |
| 75% | 0.013 | 0.009 | 0.010 | 0.031 | 0.055 | 0.030 | 0.048 | 0.091 | |
| Risk Measure | Black-Scholes | Heston | |||||||
|---|---|---|---|---|---|---|---|---|---|
| All | 0–0.2 Year | 0.2–0.7 Year | >0.7 Year | All | 0–0.2 Year | 0.2–0.7 Year | >0.7 Year | ||
| Aggregate Model Risk | |||||||||
| mean | 0.165 | 0.167 | 0.162 | 0.164 | 0.115 | 0.115 | 0.120 | 0.109 | |
| median | 0.109 | 0.104 | 0.099 | 0.120 | 0.053 | 0.052 | 0.057 | 0.048 | |
| Quantile | 99% | 0.705 | 0.736 | 0.709 | 0.661 | 0.726 | 0.714 | 0.707 | 0.736 |
| 95% | 0.519 | 0.527 | 0.551 | 0.459 | 0.475 | 0.468 | 0.500 | 0.476 | |
| 90% | 0.393 | 0.417 | 0.382 | 0.371 | 0.330 | 0.351 | 0.322 | 0.304 | |
| 75% | 0.219 | 0.221 | 0.216 | 0.218 | 0.145 | 0.149 | 0.155 | 0.136 | |
| Calibration Error | |||||||||
| mean | 0.125 | 0.121 | 0.123 | 0.132 | 0.055 | 0.055 | 0.052 | 0.057 | |
| median | 0.082 | 0.074 | 0.075 | 0.099 | 0.006 | 0.005 | 0.006 | 0.006 | |
| Quantile | 99% | 0.655 | 0.662 | 0.650 | 0.639 | 0.626 | 0.658 | 0.531 | 0.665 |
| 95% | 0.400 | 0.403 | 0.423 | 0.391 | 0.329 | 0.349 | 0.311 | 0.330 | |
| 90% | 0.295 | 0.298 | 0.301 | 0.285 | 0.172 | 0.155 | 0.185 | 0.171 | |
| 75% | 0.171 | 0.162 | 0.160 | 0.176 | 0.034 | 0.031 | 0.034 | 0.034 | |
| Model Risk due to Recalibration | |||||||||
| mean | 0.036 | 0.038 | 0.039 | 0.033 | 0.119 | 0.117 | 0.117 | 0.124 | |
| median | 0.004 | 0.005 | 0.003 | 0.005 | 0.043 | 0.043 | 0.037 | 0.049 | |
| Quantile | 99% | 0.405 | 0.419 | 0.479 | 0.284 | 0.757 | 0.746 | 0.767 | 0.754 |
| 95% | 0.173 | 0.176 | 0.188 | 0.155 | 0.543 | 0.510 | 0.558 | 0.554 | |
| 90% | 0.109 | 0.111 | 0.115 | 0.098 | 0.411 | 0.390 | 0.418 | 0.418 | |
| 75% | 0.036 | 0.038 | 0.032 | 0.036 | 0.142 | 0.144 | 0.137 | 0.146 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Y.; Rudd, R.; Baker, C.; Mashalaba, Q.; Mavuso, M.; Schlögl, E. Quantifying the Model Risk Inherent in the Calibration and Recalibration of Option Pricing Models. Risks 2021, 9, 13. https://0-doi-org.brum.beds.ac.uk/10.3390/risks9010013
Feng Y, Rudd R, Baker C, Mashalaba Q, Mavuso M, Schlögl E. Quantifying the Model Risk Inherent in the Calibration and Recalibration of Option Pricing Models. Risks. 2021; 9(1):13. https://0-doi-org.brum.beds.ac.uk/10.3390/risks9010013
Chicago/Turabian StyleFeng, Yu, Ralph Rudd, Christopher Baker, Qaphela Mashalaba, Melusi Mavuso, and Erik Schlögl. 2021. "Quantifying the Model Risk Inherent in the Calibration and Recalibration of Option Pricing Models" Risks 9, no. 1: 13. https://0-doi-org.brum.beds.ac.uk/10.3390/risks9010013