
SABER: A Model-Agnostic Postprocessor for Bias Correcting Discharge from Large Hydrologic Models

 , , , ,
, , , ,
Abstract
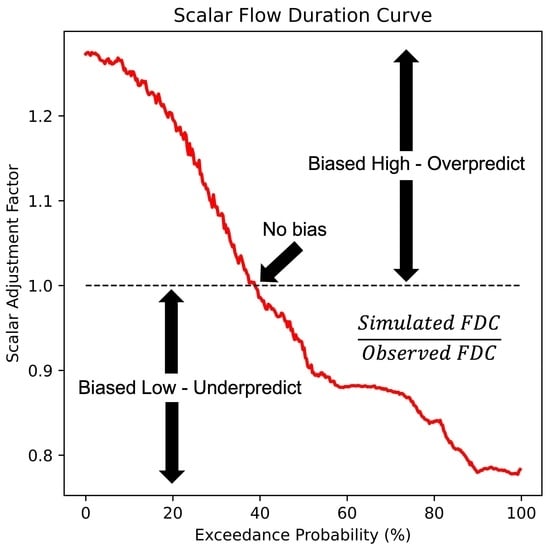
:
1. Introduction
2. Materials and Methods
2.1. Overview
- The subbasins or catchments (vector polygons) in the watershed as used by the hydrologic model. A stream centerlines (vector polylines) dataset is helpful but not essential. Each feature should have the following attributes at minimum:
- A unique identifier (integer or alphanumeric) shared by each subbasin and stream reach pair. Ideally, this number is the identifier used by the hydrologic model, but it can be randomly generated.
- The identifier number of the next subbasin downstream (to facilitate faster network analysis).
- The cumulative drainage area for the subbasin in the same area units reported by the gauges.
- The (x, y) coordinates of the outlet. If the outlet is not easily determined computationally, the centroid of the reach can be substituted.
- Hindcast or simulated historical discharge for each of the subbasins/streams in the model for as long as is available. It should be converted to the same units as the observed discharge, if necessary.
- The location of each available river gauging station (vector points). Each feature should have the following attributes at minimum:
- The name or other unique identifier (integer or alphanumeric) assigned to the gauge.
- The total drainage area upstream of the gauge.
- The ID of the subbasin/stream in the model whose outlet is measured by that gauge. If the gauge does not align with a subbasin’s outlet, the user decides which subbasin it should be applied to by considering its location in relation to the model’s reporting points.
- Observed discharge for each gauge for as long as is available.
2.2. Frequency Matching and Scalar Flow Duration Curves
2.3. Identifying Flow Regime Patterns
2.4. Identifying Spatial Relationships
2.5. Pairing Gauged and Ungauged Subbasins
- Hydraulic connectivity. Choose a gauge for the ungauged basin that is directly upstream or downstream of a gauge on a stream of the same Strahler order. If multiple gauges exist, choose the closest gauge in terms of distance along the stream network. If no matches are found, proceed to the next selection criterion.
- Clustered basin. Choose a gauge from the same FDC cluster as the ungauged basin. If only one gauge exists in the cluster, use that gauge for the ungauged subbasins. If multiple matches are found, proceed to the following criteria to determine which of those gauges is the best fit. If no matches are found, use the following criteria to choose a gauge from all gauges in the watershed.
- Stream order. Choose a gauge from a stream that has the same stream order as the ungauged stream. If no matches are found, look for gauges within one stream order class of the ungauged basin and repeat. If there is one option, use that gauge. If no gauges meet this criterion, skip this step and use the next criterion. If multiple matches are found, use the next selection criterion to choose between those options.
- Drainage area. Choose the gauged subbasin with the drainage area closest to that of the ungauged subbasin. If multiple gauges are within 5% of the target drainage area, proceed to the next selection criterion.
- Proximity. From the remaining possibilities, pick the gauge located closest, in geodesic distance rather than distance along the stream network, to the outlet of the ungauged basin’s outlet.
2.6. Applying Corrections and Statistical Refinements
3. Results
3.1. Case Study Design
3.2. Bias Reduction Statistics
3.3. Spatial Trends in Performance
3.4. Hydrograph Analysis
4. Discussion and Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sood, A.; Smakhtin, V. Global Hydrological Models: A Review. Hydrol. Sci. J. 2015, 60, 549–565. [Google Scholar] [CrossRef]
- Mitchell, K.E. The Multi-Institution North American Land Data Assimilation System (NLDAS): Utilizing Multiple GCIP Products and Partners in a Continental Distributed Hydrological Modeling System. J. Geophys. Res. 2004, 109, D07S90. [Google Scholar] [CrossRef] [Green Version]
- Rodell, M.; Houser, P.R.; Jambor, U.; Gottschalck, J.; Mitchell, K.; Meng, C.-J.; Arsenault, K.; Cosgrove, B.; Radakovich, J.; Bosilovich, M.; et al. The Global Land Data Assimilation System. Bull. Am. Meteorol. Soc. 2004, 85, 381–394. [Google Scholar] [CrossRef] [Green Version]
- National Oceanic and Atmospheric Administration (NOAA). NOAA National Water Model: Improving NOAA’s Water Prediction Services; Weather Ready Nation; National Water Center: Huntsville, AL, USA, 2016. Available online: https://water.noaa.gov/about/nwm (accessed on 26 May 2022).
- Alfieri, L.; Burek, P.; Dutra, E.; Krzeminski, B.; Muraro, D.; Thielen, J.; Pappenberger, F. GloFAS—Global Ensemble Streamflow Forecasting and Flood Early Warning. Hydrol. Earth Syst. Sci. 2013, 17, 1161–1175. [Google Scholar] [CrossRef] [Green Version]
- Ashby, K.; Hales, R.; Nelson, J.; Ames, D.; Williams, G. Hydroviewer: A Web Application to Localize Global Hydrologic Forecasts. Open Water J. 2021, 7, 9. [Google Scholar]
- Souffront Alcantara, M.A.; Nelson, E.J.; Shakya, K.; Edwards, C.; Roberts, W.; Krewson, C.; Ames, D.P.; Jones, N.L.; Gutierrez, A. Hydrologic Modeling as a Service (HMaaS): A New Approach to Address Hydroinformatic Challenges in Developing Countries. Front. Environ. Sci. 2019, 7, 158. [Google Scholar] [CrossRef]
- Qiao, X.; Nelson, E.J.; Ames, D.P.; Li, Z.; David, C.H.; Williams, G.P.; Roberts, W.; Sánchez Lozano, J.L.; Edwards, C.; Souffront, M.; et al. A Systems Approach to Routing Global Gridded Runoff through Local High-Resolution Stream Networks for Flood Early Warning Systems. Environ. Model. Softw. 2019, 120, 104501. [Google Scholar] [CrossRef]
- Alcamo, J.; Döll, P.; Henrichs, T.; Kaspar, F.; Lehner, B.; Rösch, T.; Siebert, S. Development and testing of the WaterGAP 2 global model of water use and availability. Hydrol. Sci. J. 2003, 48, 317–337. [Google Scholar] [CrossRef]
- Pokhrel, Y.; Felfelani, F.; Satoh, Y.; Boulange, J.; Burek, P.; Gädeke, A.; Gerten, D.; Gosling, S.N.; Grillakis, M.; Gudmundsson, L.; et al. Global Terrestrial Water Storage and Drought Severity under Climate Change. Nat. Clim. Chang. 2021, 11, 226–233. [Google Scholar] [CrossRef]
- Barbosa, S.A.; Pulla, S.T.; Williams, G.P.; Jones, N.L.; Mamane, B.; Sanchez, J.L. Evaluating Groundwater Storage Change and Recharge Using GRACE Data: A Case Study of Aquifers in Niger, West Africa. Remote Sens. 2022, 14, 1532. [Google Scholar] [CrossRef]
- Flores-Anderson, A.I.; Griffin, R.; Dix, M.; Romero-Oliva, C.S.; Ochaeta, G.; Skinner-Alvarado, J.; Ramirez Moran, M.V.; Hernandez, B.; Cherrington, E.; Page, B.; et al. Hyperspectral Satellite Remote Sensing of Water Quality in Lake Atitlán, Guatemala. Front. Environ. Sci. 2020, 8, 7. [Google Scholar] [CrossRef]
- Meyer, A.; Lozano, J.L.S.; Nelson, J.; Flores, A. Connecting Space to Village by Predicting Algae Contamination in Lake Atitlán, Guatemala. Open Water J. 2021, 7, 8. [Google Scholar]
- Hosseini-Moghari, S.-M.; Araghinejad, S.; Tourian, M.J.; Ebrahimi, K.; Döll, P. Quantifying the Impacts of Human Water Use and Climate Variations on Recent Drying of Lake Urmia Basin: The Value of Different Sets of Spaceborne and in Situ Data for Calibrating a Global Hydrological Model. Hydrol. Earth Syst. Sci. 2020, 24, 1939–1956. [Google Scholar] [CrossRef] [Green Version]
- Aggett, G.R.; Spies, R. Integrating NOAA-National Water Model Forecasting Capabilities with Statewide and Local Drought Planning for Enhanced Decision Support and Drought Mitigation. In Proceedings of the AGU Fall Meeting, Washington, DC, USA, 10–14 December 2018. [Google Scholar]
- Hirpa, F.A.; Salamon, P.; Beck, H.E.; Lorini, V.; Alfieri, L.; Zsoter, E.; Dadson, S.J. Calibration of the Global Flood Awareness System (GloFAS) Using Daily Streamflow Data. J. Hydrol. 2018, 566, 595–606. [Google Scholar] [CrossRef]
- Müller Schmied, H.; Cáceres, D.; Eisner, S.; Flörke, M.; Herbert, C.; Niemann, C.; Peiris, T.A.; Popat, E.; Portmann, F.T.; Reinecke, R.; et al. The Global Water Resources and Use Model WaterGAP v2.2d: Model Description and Evaluation. Geosci. Model Dev. 2021, 14, 1037–1079. [Google Scholar] [CrossRef]
- Abbasi Moghaddam, V.; Tabesh, M. Sampling Design of Hydraulic and Quality Model Calibration Based on a Global Sensitivity Analysis Method. J. Water Resour. Plann. Manag. 2021, 147. [Google Scholar] [CrossRef]
- Bogner, K.; Kalas, M. Error-Correction Methods and Evaluation of an Ensemble Based Hydrological Forecasting System for the Upper Danube Catchment. Atmos. Sci. Lett. 2008, 9, 95–102. [Google Scholar] [CrossRef]
- Malek, K.; Reed, P.; Zeff, H.; Hamilton, A.; Wrzesien, M.; Holtzman, N.; Steinschneider, S.; Herman, J.; Pavelsky, T. Bias Correction of Hydrologic Projections Strongly Impacts Inferred Climate Vulnerabilities in Institutionally Complex Water Systems. J. Water Resour. Plann. Manag. 2022, 148, 04021095. [Google Scholar] [CrossRef]
- Skoulikaris, C.; Venetsanou, P.; Lazoglou, G.; Anagnostopoulou, C.; Voudouris, K. Spatio-Temporal Interpolation and Bias Correction Ordering Analysis for Hydrological Simulations: An Assessment on a Mountainous River Basin. Water 2022, 14, 660. [Google Scholar] [CrossRef]
- Teutschbein, C.; Seibert, J. Bias Correction of Regional Climate Model Simulations for Hydrological Climate-Change Impact Studies: Review and Evaluation of Different Methods. J. Hydrol. 2012, 456–457, 12–29. [Google Scholar] [CrossRef]
- Zalachori, I.; Ramos, M.-H.; Garçon, R.; Mathevet, T.; Gailhard, J. Statistical Processing of Forecasts for Hydrological Ensemble Prediction: A Comparative Study of Different Bias Correction Strategies. Adv. Sci. Res. 2012, 8, 135–141. [Google Scholar] [CrossRef] [Green Version]
- Ji, X.; Li, Y.; Luo, X.; He, D.; Guo, R.; Wang, J.; Bai, Y.; Yue, C.; Liu, C. Evaluation of Bias Correction Methods for APHRODITE Data to Improve Hydrologic Simulation in a Large Himalayan Basin. Atmos. Res. 2020, 242, 104964. [Google Scholar] [CrossRef]
- Li, W.; Chen, J.; Li, L.; Chen, H.; Liu, B.; Xu, C.-Y.; Li, X. Evaluation and Bias Correction of S2S Precipitation for Hydrological Extremes. J. Hydrometeorol. 2019, 20, 1887–1906. [Google Scholar] [CrossRef]
- Muerth, M.J.; Gauvin St-Denis, B.; Ricard, S.; Velázquez, J.A.; Schmid, J.; Minville, M.; Caya, D.; Chaumont, D.; Ludwig, R.; Turcotte, R. On the Need for Bias Correction in Regional Climate Scenarios to Assess Climate Change Impacts on River Runoff. Hydrol. Earth Syst. Sci. 2013, 17, 1189–1204. [Google Scholar] [CrossRef] [Green Version]
- Müller-Thomy, H. Temporal Rainfall Disaggregation Using a Micro-Canonical Cascade Model: Possibilities to Improve the Autocorrelation. Hydrol. Earth Syst. Sci. 2020, 24, 169–188. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Brown, J.D.; Seo, D.-J. Evaluation of a Nonparametric Post-Processor for Bias Correction and Uncertainty Estimation of Hydrologic Predictions. Hydrol. Process. 2013, 27, 83–105. [Google Scholar] [CrossRef]
- Farmer, W.H.; Over, T.M.; Kiang, J.E. Bias Correction of Simulated Historical Daily Streamflow at Ungauged Locations by Using Independently Estimated Flow Duration Curves. Hydrol. Earth Syst. Sci. 2018, 22, 5741–5758. [Google Scholar] [CrossRef] [Green Version]
- Guo, Q.; Chen, J.; Zhang, X.J.; Xu, C.-Y.; Chen, H. Impacts of Using State-of-the-Art Multivariate Bias Correction Methods on Hydrological Modeling Over North America. Water Resour. Res. 2020, 56, e2019WR026659. [Google Scholar] [CrossRef]
- Maraun, D.; Shepherd, T.G.; Widmann, M.; Zappa, G.; Walton, D.; Gutiérrez, J.M.; Hagemann, S.; Richter, I.; Soares, P.M.M.; Hall, A.; et al. Towards Process-Informed Bias Correction of Climate Change Simulations. Nat. Clim. Chang. 2017, 7, 764–773. [Google Scholar] [CrossRef] [Green Version]
- Ayzel, G.; Kurochkina, L.; Abramov, D.; Zhuravlev, S. Development of a Regional Gridded Runoff Dataset Using Long Short-Term Memory (LSTM) Networks. Hydrology 2021, 8, 6. [Google Scholar] [CrossRef]
- Bomers, A. Predicting Outflow Hydrographs of Potential Dike Breaches in a Bifurcating River System Using NARX Neural Networks. Hydrology 2021, 8, 87. [Google Scholar] [CrossRef]
- Jang, J.-C.; Sohn, E.-H.; Park, K.-H.; Lee, S. Estimation of Daily Potential Evapotranspiration in Real-Time from GK2A/AMI Data Using Artificial Neural Network for the Korean Peninsula. Hydrology 2021, 8, 129. [Google Scholar] [CrossRef]
- Valdés-Pineda, R.; Valdés, J.B.; Wi, S.; Serrat-Capdevila, A.; Roy, T. Improving Operational Short- to Medium-Range (SR2MR) Streamflow Forecasts in the Upper Zambezi Basin and Its Sub-Basins Using Variational Ensemble Forecasting. Hydrology 2021, 8, 188. [Google Scholar] [CrossRef]
- Bustamante, G.R.; Nelson, E.J.; Ames, D.P.; Williams, G.P.; Jones, N.L.; Boldrini, E.; Chernov, I.; Sanchez Lozano, J.L. Water Data Explorer: An Open-Source Web Application and Python Library for Water Resources Data Discovery. Water 2021, 13, 1850. [Google Scholar] [CrossRef]
- GRDC The GRDC—Rationale and Background Information. Available online: https://www.bafg.de/GRDC/EN/01_GRDC/11_rtnle/history.html?nn=201874 (accessed on 5 May 2022).
- WMO Climate Data Catalog Documentation. Available online: https://climatedata-catalogue.wmo.int/documentation (accessed on 5 May 2022).
- USGS Water Data for the Nation. Available online: https://waterdata.usgs.gov/nwis (accessed on 25 May 2022).
- Krabbenhoft, C.A.; Allen, G.H.; Lin, P.; Godsey, S.E.; Allen, D.C.; Burrows, R.M.; DelVecchia, A.G.; Fritz, K.M.; Shanafield, M.; Burgin, A.J.; et al. Assessing Placement Bias of the Global River Gauge Network. Nat. Sustain. 2022. [Google Scholar] [CrossRef]
- Hajdukiewicz, H.; Wyżga, B.; Mikuś, P.; Zawiejska, J.; Radecki-Pawlik, A. Impact of a Large Flood on Mountain River Habitats, Channel Morphology, and Valley Infrastructure. Geomorphology 2016, 272, 55–67. [Google Scholar] [CrossRef]
- Rusnák, M.; Lehotskeý, M. Time-Focused Investigation of River Channel Morphological Changes Due to Extreme Floods. Z. Geomorphol. 2014, 58, 251–266. [Google Scholar] [CrossRef]
- Yousefi, S.; Mirzaee, S.; Keesstra, S.; Surian, N.; Pourghasemi, H.R.; Zakizadeh, H.R.; Tabibian, S. Effects of an Extreme Flood on River Morphology (Case Study: Karoon River, Iran). Geomorphology 2018, 304, 30–39. [Google Scholar] [CrossRef]
- Sanchez, J.L.; Nelson, J.; Williams, G.P.; Hales, R.; Ames, D.P.; Jones, N. A Streamflow Bias Correction and Validation Method for GEOGloWS ECMWF Streamflow Services. In Proceedings of the AGU Fall Meeting Abstracts, Virtual, 1–17 December 2020; Volume 2020. [Google Scholar]
- Sanchez Lozano, J.; Romero Bustamante, G.; Hales, R.; Nelson, E.J.; Williams, G.P.; Ames, D.P.; Jones, N.L. A Streamflow Bias Correction and Performance Evaluation Web Application for GEOGloWS ECMWF Streamflow Services. Hydrology 2021, 8, 71. [Google Scholar] [CrossRef]
- Hales, R.; Sanchez, J.L.; Nelson, J.; Williams, G.P.; Ames, D.P.; Jones, N. A Post-Processing Method to Calibrate Large-Scale Hydrologic Models with Limited Historical Observation Data Leveraging Machine Learning and Spatial Analysis. In Proceedings of the AGU Fall Meeting Abstracts, Virtual, 1–17 December 2020; Volume 2020. [Google Scholar]
- Hales, R. Saber-Bias-Correction. Available online: https://github.com/rileyhales/saber-bias-correction (accessed on 26 May 2022).
- OGC GeoPackage Encoding Standard 1.3. Available online: http://www.opengis.net/doc/IS/geopackage/1.3 (accessed on 5 May 2022).
- Strahler, A.N. Quantitative Analysis of Watershed Geomorphology. Trans. AGU 1957, 38, 913. [Google Scholar] [CrossRef] [Green Version]
- Tarboton, D.G.; Bras, R.L.; Rodriguez-Iturbe, I. On the Extraction of Channel Networks from Digital Elevation. Data Hydrol. Process. 1991, 5, 81–100. [Google Scholar] [CrossRef]
- Olsen, N.L.; Markussen, B.; Raket, L.L. Simultaneous Inference for Misaligned Multivariate Functional Data. J. R. Stat. Soc. C 2018, 67, 1147–1176. [Google Scholar] [CrossRef] [Green Version]
- Berndt, D.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series. KDD Workshop 1994, 359–370. Available online: https://www.aaai.org/Papers/Workshops/1994/WS-94-03/WS94-03-031.pdf (accessed on 26 May 2022).
- Digalakis, V.; Rohlicek, J.R.; Ostendorf, M. A Dynamical System Approach to Continuous Speech Recognition. In Proceedings of the ICASSP 91: 1991 International Conference on Acoustics, Speech, and Signal Processing, Toronto, ON, Canada, 14–17 April 1991; Volume 1, pp. 289–292. [Google Scholar]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, Statistical Laboratory of the University of California, Berkeley, CA, USA, 18 July 1965; University of California Press: Berkeley, CA, USA; Volume 5, pp. 281–298. [Google Scholar]
- Wang, K.; Gasser, T. Alignment of Curves by Dynamic Time Warping. Ann. Statist. 1997, 25, 1251–1276. [Google Scholar] [CrossRef]
- Satopaa, V.; Albrecht, J.; Irwin, D.; Raghavan, B. Finding a “Kneedle” in a Haystack: Detecting Knee Points in System Behavior. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 24 June 2011; Volume 10, pp. 166–171. [Google Scholar]
- Arvai, K.; Blackrobe, P.; Scheffner, J.; Perakis, G.; Schäfer, K.; Milligan, T. Big-O Arvkevi/Kneed: Documentation! Zenodo: Geneva, Switzerland, 2020. [Google Scholar]
- Miller, H.J. Tobler’s First Law and Spatial Analysis. Annals of the Association of American Geographers 2004, 94, 284–289. [Google Scholar] [CrossRef]
- Gumbel, E.J. The Return Period of Flood Flows. Ann. Math. Stat. 1941, 12, 163–190. [Google Scholar] [CrossRef]
- Aureli, F.; Mignosa, P.; Prost, F.; Dazzi, S. Hydrological and Hydraulic Flood Hazard Modeling in Poorly Gauged Catchments: An Analysis in Northern Italy. Hydrology 2021, 8, 149. [Google Scholar] [CrossRef]
- Gámez-Balmaceda, E.; López-Ramos, A.; Martínez-Acosta, L.; Medrano-Barboza, J.P.; Remolina López, J.F.; Seingier, G.; Daesslé, L.W.; López-Lambraño, A.A. Rainfall Intensity-Duration-Frequency Relationship. Case Study: Depth-Duration Ratio in a Semi-Arid Zone in Mexico. Hydrology 2020, 7, 78. [Google Scholar] [CrossRef]
- Hales, R.C.; Nelson, E.J.; Williams, G.P.; Jones, N.; Ames, D.P.; Jones, J.E. The Grids Python Tool for Querying Spatiotemporal Multidimensional Water Data. Water 2021, 13, 2066. [Google Scholar] [CrossRef]
- Rew, R.; Davis, G. NetCDF: An Interface for Scientific Data Access. IEEE Comput. Graph. Appl. 1990, 10, 76–82. [Google Scholar] [CrossRef]
- Roberts, W.; Williams, G.P.; Jackson, E.; Nelson, E.J.; Ames, D.P. Hydrostats: A Python Package for Characterizing Errors between Observed and Predicted Time Series. Hydrology 2018, 5, 66. [Google Scholar] [CrossRef] [Green Version]
- Jackson, E.K.; Roberts, W.; Nelsen, B.; Williams, G.P.; Nelson, E.J.; Ames, D.P. Introductory Overview: Error Metrics for Hydrologic Modelling—A Review of Common Practices and an Open Source Library to Facilitate Use and Adoption. Environ. Model. Softw. 2019, 119, 32–48. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River Flow Forecasting through Conceptual Models Part I—A Discussion of Principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the Mean Squared Error and NSE Performance Criteria: Implications for Improving Hydrological Modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef] [Green Version]
- Kling, H.; Fuchs, M.; Paulin, M. Runoff Conditions in the Upper Danube Basin under an Ensemble of Climate Change Scenarios. J. Hydrol. 2012, 424–425, 264–277. [Google Scholar] [CrossRef]
- Knoben, W.J.M.; Freer, J.E.; Woods, R.A. Technical Note: Inherent Benchmark or Not? Comparing Nash–Sutcliffe and Kling–Gupta Efficiency Scores. Hydrol. Earth Syst. Sci. 2019, 23, 4323–4331. [Google Scholar] [CrossRef] [Green Version]
- Frame, J.; Ullrich, P.; Nearing, G.; Gupta, H.; Kratzert, F. On Strictly Enforced Mass Conservation Constraints for Modeling the Rainfall-Runoff Process. Earth ArXiv 2022. [Google Scholar] [CrossRef]
- Ye, F.; Zhang, Y.J.; Yu, H.; Sun, W.; Moghimi, S.; Myers, E.; Nunez, K.; Zhang, R.; Wang, H.V.; Roland, A.; et al. Simulating Storm Surge and Compound Flooding Events with a Creek-to-Ocean Model: Importance of Baroclinic Effects. Ocean. Model. 2020, 145, 101526. [Google Scholar] [CrossRef]
- NOAA. NOAA National Water Model CONUS Retrospective Dataset. Available online: https://registry.opendata.aws/nwm-archive/ (accessed on 5 May 2022).
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near Real-Time Global 10 m Land Use Land Cover Mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Viscarra Rossel, R.A.; Chen, C.; Grundy, M.J.; Searle, R.; Clifford, D.; Campbell, P.H. The Australian Three-Dimensional Soil Grid: Australia’s Contribution to the GlobalSoilMap Project. Soil Res. 2015, 53, 845. [Google Scholar] [CrossRef] [Green Version]
- Theobald, D.M.; Harrison-Atlas, D.; Monahan, W.B.; Albano, C.M. Ecologically-Relevant Maps of Landforms and Physiographic Diversity for Climate Adaptation Planning. PLoS ONE 2015, 10, e0143619. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yamazaki, D.; Ikeshima, D.; Tawatari, R.; Yamaguchi, T.; O’Loughlin, F.; Neal, J.C.; Sampson, C.C.; Kanae, S.; Bates, P.D. A High-Accuracy Map of Global Terrain Elevations: Accurate Global Terrain Elevation Map. Geophys. Res. Lett. 2017, 44, 5844–5853. [Google Scholar] [CrossRef] [Green Version]
- IDEAM Colombia_Hydrological_Data | CUAHSI HydroShare. Available online: https://www.hydroshare.org/resource/d222676fbd984a81911761ca1ba936bf/ (accessed on 21 May 2022).
- Ashby, K.; Nelson, J.; Ames, D.; Hales, R. Derived Hydrography of World Regions. Available online: http://www.hydroshare.org/resource/9241da0b1166492791381b48943c2b4a (accessed on 13 July 2021).
- Hales, R.; Khattar, R. Geoglows. Available online: https://0-doi-org.brum.beds.ac.uk/10.5281/zenodo.4684667 (accessed on 28 June 2021).
- Hales, R.C.; Ashby, K.; Khattar, R. GEOGloWS Hydroviewer. Available online: https://0-doi-org.brum.beds.ac.uk/10.5281/ZENODO.5038958 (accessed on 28 June 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistic | GES Model Results | SFDC Corrected Results | Freq. Matched Results |
|---|---|---|---|
| n | 109 | 109 | 109 |
| Max. | 10,994.75 | 23,596.18 | 19,984.16 |
| 75% | 129.08 | 29.74 | 4.42 |
| Median | 23.61 | 2.36 | 1.16 |
| 25% | 7.34 | −6.64 | −2.46 |
| Min. | −196.76 | −327.08 | −125.95 |
| Metric | GES Model Results | SFDC Corrected Results | Freq. Matched Results | Target Value |
|---|---|---|---|---|
| ME | 23.61 | 2.36 | 1.16 | 0 |
| MAPE | 258.62 | 92.40 | 88.40 | 0 |
| MAE | 54.86 | 29.80 | 24.40 | 0 |
| NRMSE | 2.10 | 1.24 | 1.12 | 0 |
| KGE | −0.66 | 0.04 | 0.16 | 1 |
| NSE | −8.22 | −0.92 | −0.82 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hales, R.C.; Sowby, R.B.; Williams, G.P.; Nelson, E.J.; Ames, D.P.; Dundas, J.B.; Ogden, J. SABER: A Model-Agnostic Postprocessor for Bias Correcting Discharge from Large Hydrologic Models. Hydrology 2022, 9, 113. https://0-doi-org.brum.beds.ac.uk/10.3390/hydrology9070113
Hales RC, Sowby RB, Williams GP, Nelson EJ, Ames DP, Dundas JB, Ogden J. SABER: A Model-Agnostic Postprocessor for Bias Correcting Discharge from Large Hydrologic Models. Hydrology. 2022; 9(7):113. https://0-doi-org.brum.beds.ac.uk/10.3390/hydrology9070113
Chicago/Turabian StyleHales, Riley C., Robert B. Sowby, Gustavious P. Williams, E. James Nelson, Daniel P. Ames, Jonah B. Dundas, and Josh Ogden. 2022. "SABER: A Model-Agnostic Postprocessor for Bias Correcting Discharge from Large Hydrologic Models" Hydrology 9, no. 7: 113. https://0-doi-org.brum.beds.ac.uk/10.3390/hydrology9070113