Author Contributions
Conceptualization, A.D.R., S.D.S., H.Å., A.F., P.L.H., A.P.N., J.J.O., R.D.P., H.T., R.H.Z., R.J.C., L.M. and P.R.; Data curation, A.D.R., S.D.S., H.Å., A.F., P.L.H., G.C.M., B.J.M., C.N., J.J.O., A.L.P., N.R.S., A.C.S., H.T., N.P.T., R.H.Z., R.J.C., L.M. and P.R.; Formal analysis, A.D.R., S.D.S., H.Å., A.F., P.L.H., C.N., A.P.N., J.J.O., A.L.P., H.T., N.P.T., R.H.Z., R.J.C., L.M. and P.R.; Funding acquisition, P.R.; Investigation, A.D.R., S.D.S., R.H.Z., R.J.C., L.M. and P.R.; Methodology, A.D.R., S.D.S., A.F., P.L.H., G.C.M., B.J.M., J.J.O., A.L.P., N.R.S., H.T., R.H.Z., R.J.C., L.M. and P.R.; Project administration, R.H.Z., R.J.C., L.M. and P.R.; Resources, V.A., M.C., A.H., C.N., R.D.P., A.C.S., S.W. and P.R.; Software, A.D.R., S.D.S., A.F., G.C.M., B.J.M., A.L.P., N.R.S., R.J.C., L.M. and P.R.; Supervision, V.A., M.C., A.H., R.D.P., S.W., R.H.Z., R.J.C., L.M. and P.R.; Validation, A.D.R., S.D.S., R.H.Z., R.J.C., L.M. and P.R.; Visualization, A.P.N. and P.R.; Writing—original draft, A.D.R., S.D.S., N.P.T., R.H.Z., R.J.C. and P.R.; Writing—review and editing, A.D.R., S.D.S., H.Å., V.A., M.C., A.F., A.H., P.L.H., G.C.M., B.J.M., C.N., A.P.N., J.J.O., R.D.P., A.L.P., N.R.S., A.C.S., H.T., N.P.T., S.W., R.H.Z., R.J.C., L.M. and P.R. All authors have read and agreed to the published version of the manuscript.
Abbreviations
17OHP: 17-hydroxy progesterone, BIOT: Biotinidase, C16: palmitoylcarnitine, C3: propionylcarnitine, CH: congenital hypothyroidism, CIT: citrulline, CLIR: Collaborative Laboratory Integrated Reports, DSP, Dual Scatter Plot, FN: false negative, FP: false positive, GAA: Acid α-glucosidase, GALC: galactocerebrosidase, GALT: galactose-1-phosphate uridyl transferase activity, IQR: interquartile range, IRT: immunoreactive trypsinogen, ISNS: International Society for Neonatal Screening, KDE: Kernel density estimation, MS/MS: tandem mass spectrometry, NBS: newborn screening, NICU: neonatal intensive care unit, R4S: Region 4 Stork, RUSP, recommended uniform screening panel, SCT: Single Condition Tool, T4: thyroxine, TRECS: T-cell receptor excision circles, TP: true positive, TSH: thyroid-stimulating hormone, TYR: tyrosine.
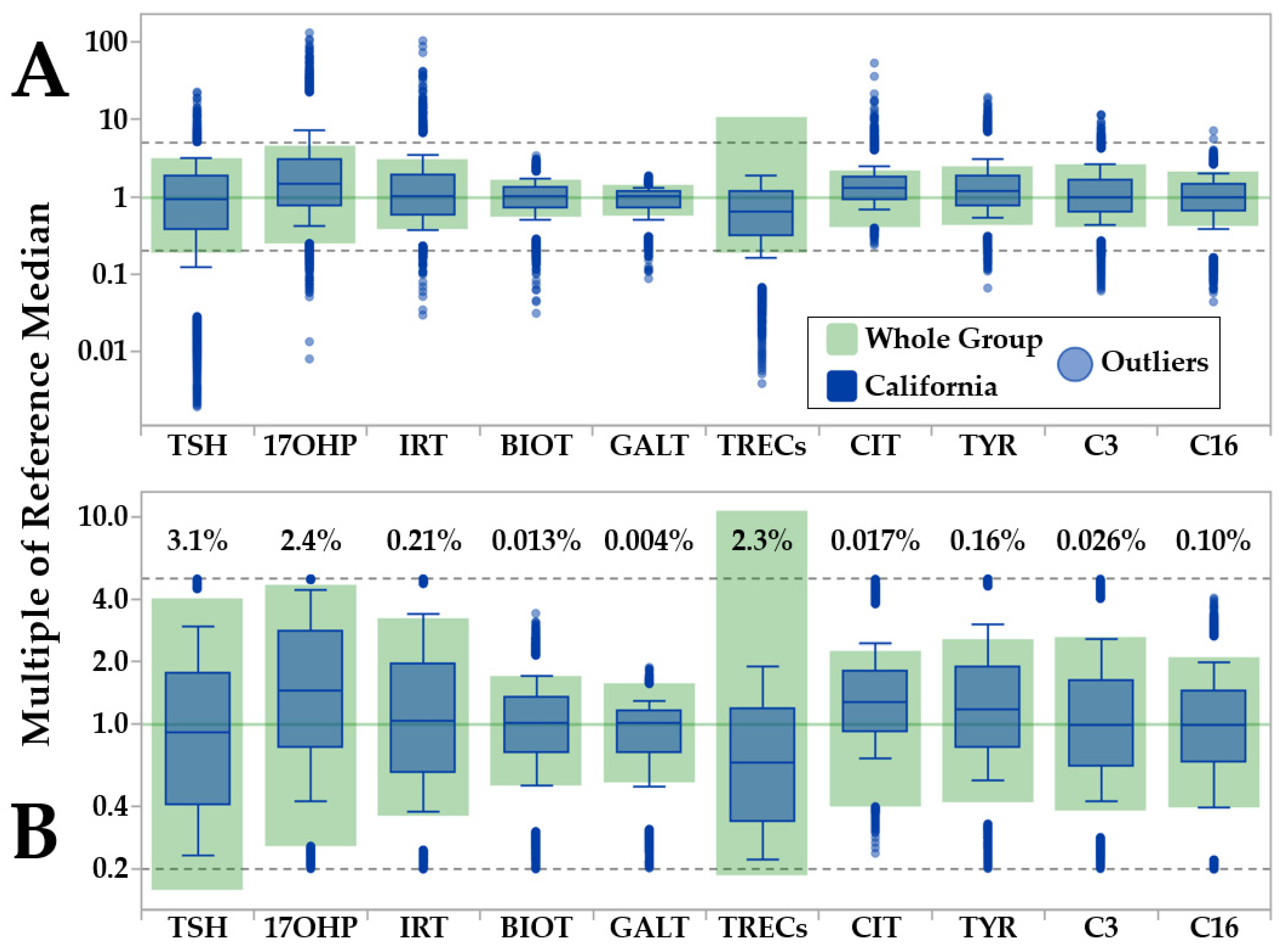
Figure 1.
CLIR Data Validation Tool (pre- and post-outlier removal). Legend: Example of outlier removal by the CLIR Data Validation tool. Color coding is embedded in the top panel. (Panel A): pre-outlier removal comparison between preliminary reference ranges (based on eligible cases) and data from the largest single cohort (California, N = 533,054). (Panel B): post-outlier removal. Percent values above the file ranges refer to the proportion of case results that were removed for each marker.
Figure 1.
CLIR Data Validation Tool (pre- and post-outlier removal). Legend: Example of outlier removal by the CLIR Data Validation tool. Color coding is embedded in the top panel. (Panel A): pre-outlier removal comparison between preliminary reference ranges (based on eligible cases) and data from the largest single cohort (California, N = 533,054). (Panel B): post-outlier removal. Percent values above the file ranges refer to the proportion of case results that were removed for each marker.
Figure 2.
CLIR Reference Review tool (pre- and post-outlier removal by moving percentiles). Legend: Outlier removal by the CLIR Reference Data Review tool for markers TSH and T4. After the Data Validation tool, a first iteration of outlier removal (>99th percentile and <1st percentile; sorted by age panels A and E; sorted by birth weight panels C and G) was performed to transition from the uniform and inevitably flat-lined removal of outliers above and below the multiples of median (MoM) limits to a recognizable biological trend according to the selected covariate. Color coding of locations is embedded in panel B (TSH) and E (T4). Colors are assigned by count in descending order and are not the same for TSH and T4. (Panel A): Overlay of individual points by location and moving percentiles (first iteration) of TSH over one week (168 h) of age at collection in 1-h increments. Percentiles shown in all panels are: 99th percentile (thicker dotted red line), 97.5th percentile, 95th percentile, 90th percentile, 75th percentile, 50th percentile (black continuous line), 25th percentile, 10th percentile, 5th percentile, 2.5th percentile, 1st percentile (thicker dotted red line). (Panel B): Moving percentiles of TSH by age after second iteration of removal of values outside the peripheral percentiles. (Panel C): Overlay of individual points by location and moving percentiles (first iteration, performed after removal of outliers by age) of TSH over the birth weight range 250–5000 g in 25 g increments. (Panel D): Final moving percentiles of TSH by birth weight after the second iteration of removal of values outside the peripheral percentiles. (Panels E–H): T4 percentiles following the same process described in panels A,D.
Figure 2.
CLIR Reference Review tool (pre- and post-outlier removal by moving percentiles). Legend: Outlier removal by the CLIR Reference Data Review tool for markers TSH and T4. After the Data Validation tool, a first iteration of outlier removal (>99th percentile and <1st percentile; sorted by age panels A and E; sorted by birth weight panels C and G) was performed to transition from the uniform and inevitably flat-lined removal of outliers above and below the multiples of median (MoM) limits to a recognizable biological trend according to the selected covariate. Color coding of locations is embedded in panel B (TSH) and E (T4). Colors are assigned by count in descending order and are not the same for TSH and T4. (Panel A): Overlay of individual points by location and moving percentiles (first iteration) of TSH over one week (168 h) of age at collection in 1-h increments. Percentiles shown in all panels are: 99th percentile (thicker dotted red line), 97.5th percentile, 95th percentile, 90th percentile, 75th percentile, 50th percentile (black continuous line), 25th percentile, 10th percentile, 5th percentile, 2.5th percentile, 1st percentile (thicker dotted red line). (Panel B): Moving percentiles of TSH by age after second iteration of removal of values outside the peripheral percentiles. (Panel C): Overlay of individual points by location and moving percentiles (first iteration, performed after removal of outliers by age) of TSH over the birth weight range 250–5000 g in 25 g increments. (Panel D): Final moving percentiles of TSH by birth weight after the second iteration of removal of values outside the peripheral percentiles. (Panels E–H): T4 percentiles following the same process described in panels A,D.
![Ijns 07 00023 g002]()
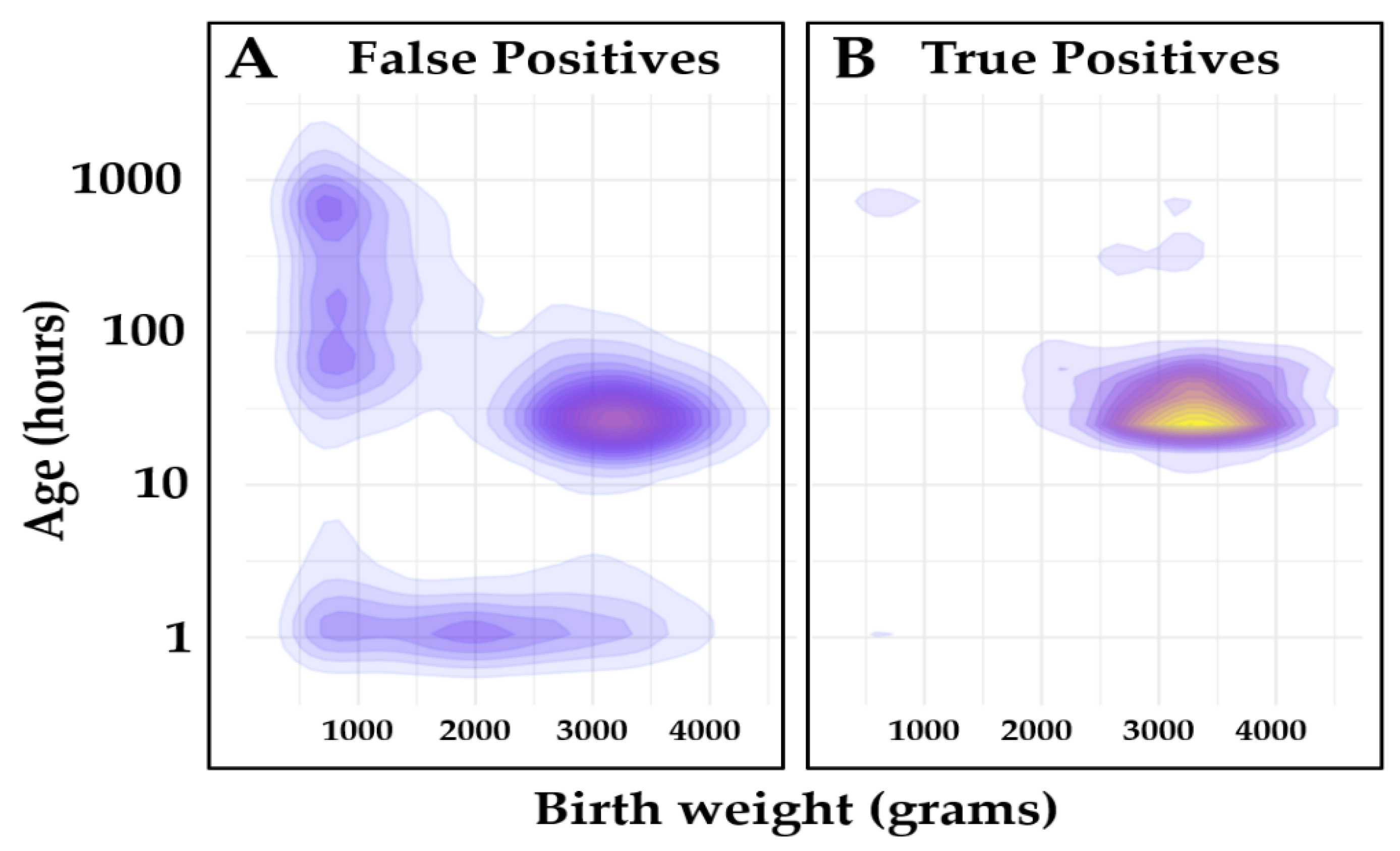
Figure 3.
Covariate distribution of the Validation set. Legend: Covariate density plot of false positive (N = 10,556) and true positive (N = 915) cases from the Validation set. (Panel
A): False positives; (Panel
B): True positives. Kernel density estimation (KDE) function [
31] was used to calculate probability density function of each class, and it was displayed using a contour plot. The unit values are the same as the input unit values. The scale is log10 on the
Y axis and linear on the
X axis of the plot. Color gradients are relative to case count.
Figure 3.
Covariate distribution of the Validation set. Legend: Covariate density plot of false positive (N = 10,556) and true positive (N = 915) cases from the Validation set. (Panel
A): False positives; (Panel
B): True positives. Kernel density estimation (KDE) function [
31] was used to calculate probability density function of each class, and it was displayed using a contour plot. The unit values are the same as the input unit values. The scale is log10 on the
Y axis and linear on the
X axis of the plot. Color gradients are relative to case count.
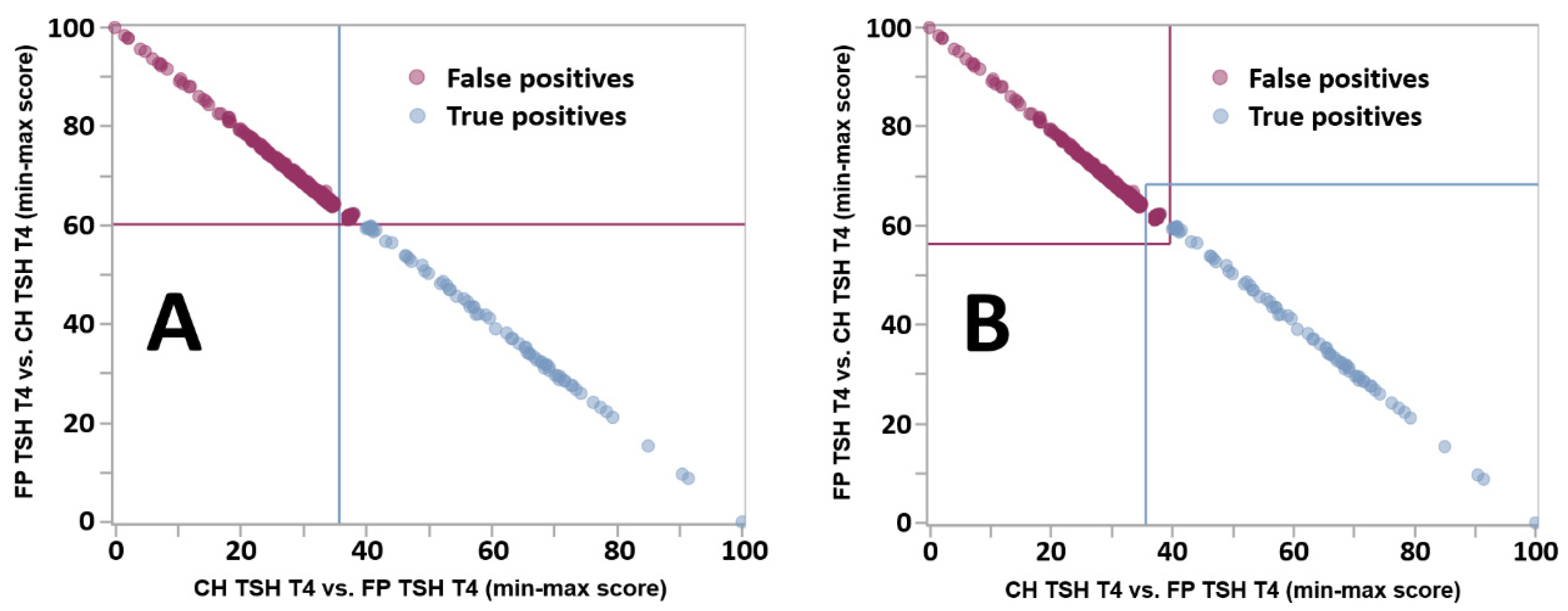
Figure 4.
Improved definition of indeterminate cases by the Dual Scatter Plot. Legend: Dual Scatter Plot customized for location Georgia applied to the differential diagnosis between CH with high TSH and low T4 (CH TSH T4) and false positive cases with the same phenotype (FP TSH T4). The total counts of cases for true positive and false positive cases were 117 and 1360, respectively. The count of Indeterminate cases was 900, 46 (39%) true positives and 854 (63%) false positives. (Panel A): original design. Each plot is divided in four quadrants: Lower right: consistent with CH TSH T4 (light blue circles); Upper right: indeterminate (both conditions are possible); Upper left: consistent with FP TSH T4 (purple circles); Lower left: neither condition. (Panel B): new design. See text for a description of the line drawing.
Figure 4.
Improved definition of indeterminate cases by the Dual Scatter Plot. Legend: Dual Scatter Plot customized for location Georgia applied to the differential diagnosis between CH with high TSH and low T4 (CH TSH T4) and false positive cases with the same phenotype (FP TSH T4). The total counts of cases for true positive and false positive cases were 117 and 1360, respectively. The count of Indeterminate cases was 900, 46 (39%) true positives and 854 (63%) false positives. (Panel A): original design. Each plot is divided in four quadrants: Lower right: consistent with CH TSH T4 (light blue circles); Upper right: indeterminate (both conditions are possible); Upper left: consistent with FP TSH T4 (purple circles); Lower left: neither condition. (Panel B): new design. See text for a description of the line drawing.
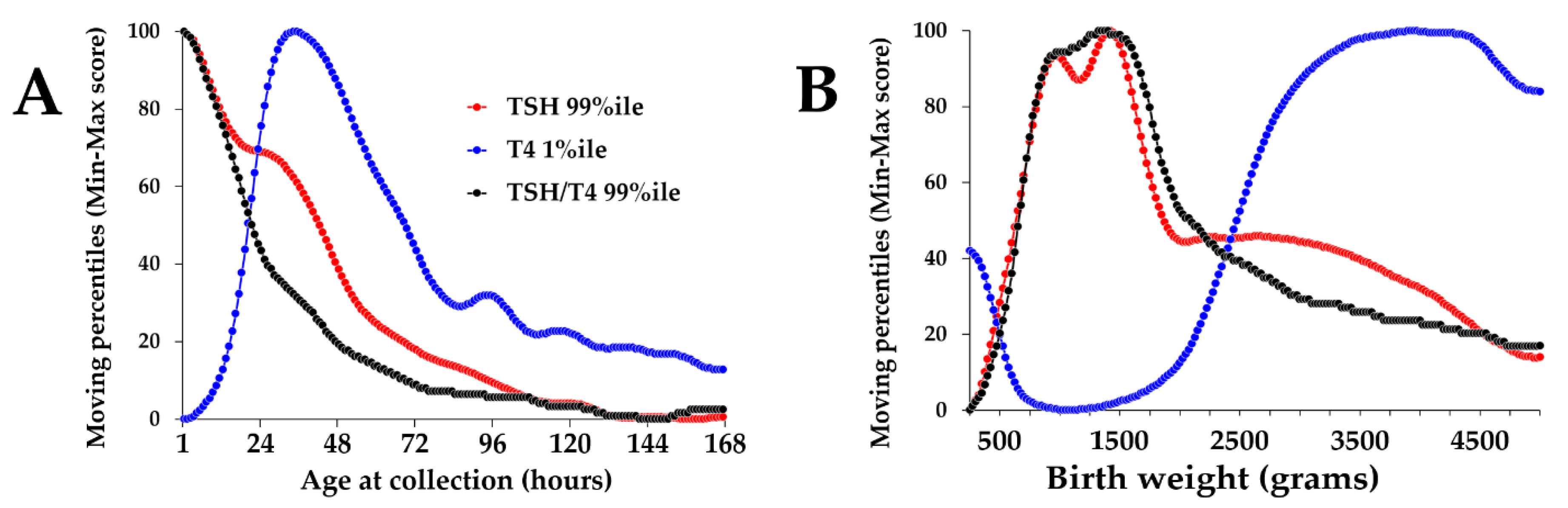
Figure 5.
Normalized moving percentiles of TSH, T4, and the TSH/T4 ratio by age and birth weight. Legend: (Panel A): Normalized moving percentiles by age, range 1–168 h (1 week). Color coding of markers is embedded in the plot. (Panel B): Moving percentiles by birth weight, range 250–5000 g. First occurrence of maximum value: TSH: age 1 h and birth weight 1425 g; T4: age 34 h and birth weight 3825 g; TSH/T4 ratio: age 1 h and birth weight 1325 g.
Figure 5.
Normalized moving percentiles of TSH, T4, and the TSH/T4 ratio by age and birth weight. Legend: (Panel A): Normalized moving percentiles by age, range 1–168 h (1 week). Color coding of markers is embedded in the plot. (Panel B): Moving percentiles by birth weight, range 250–5000 g. First occurrence of maximum value: TSH: age 1 h and birth weight 1425 g; T4: age 34 h and birth weight 3825 g; TSH/T4 ratio: age 1 h and birth weight 1325 g.
Figure 6.
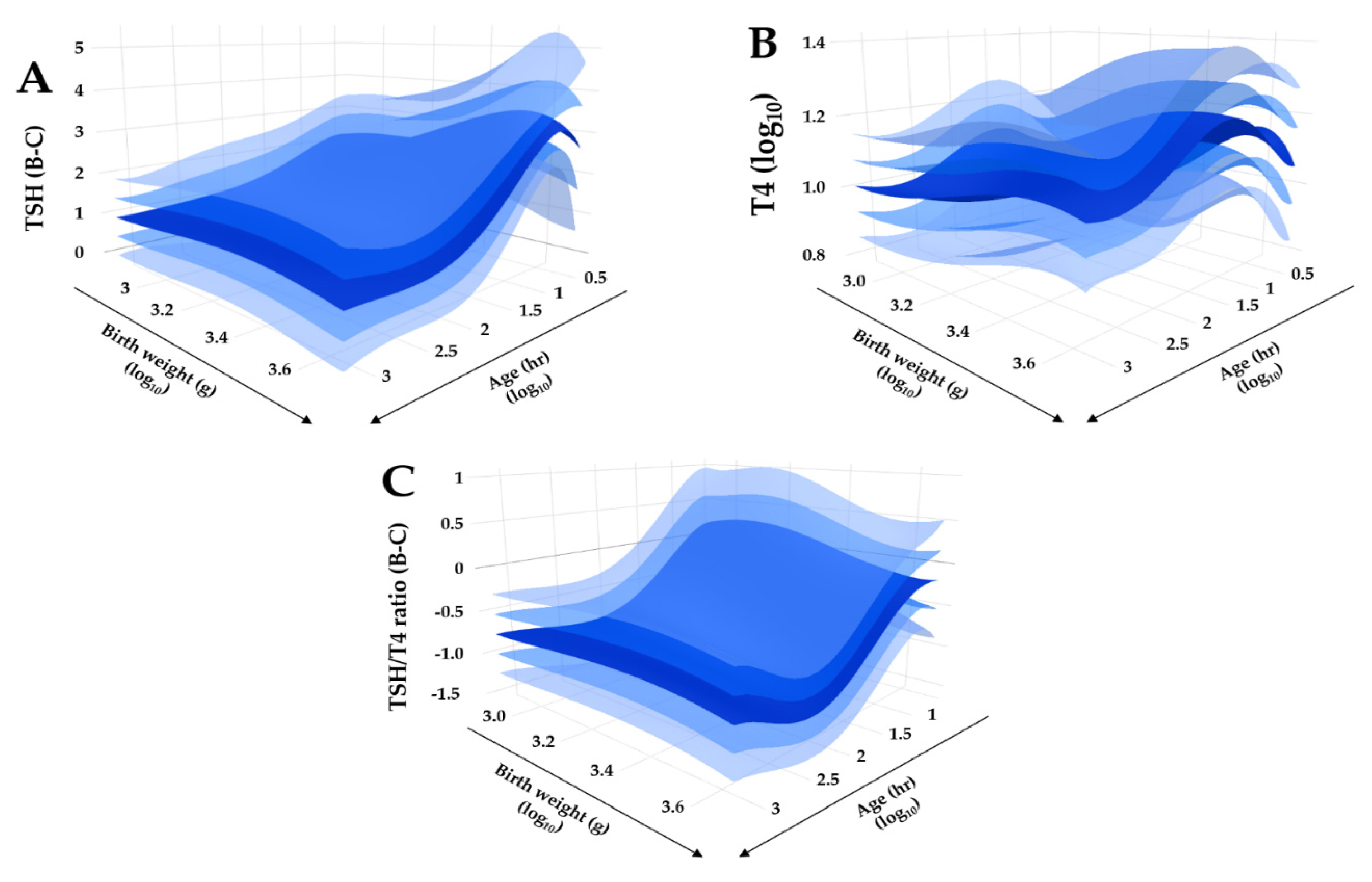
Regression quality control plot of covariate adjusted TSH, T4, and TSH/T4 ratio. Legend: Bi-dimensional plots in a tri-dimensional space of adjusted reference intervals. (Panel A): TSH, Box-Cox transformation; (Panel B): T4, log10 transformation; (Panel C): TSH/T4 ratio, Box-Cox transformation. Primary covariate is age (right lower axis), secondary covariate is birth weight (left lower axis). The dark blue surface represents the median, lighter blue surfaces represent one and two standard deviations above and below the median, respectively.
Figure 6.
Regression quality control plot of covariate adjusted TSH, T4, and TSH/T4 ratio. Legend: Bi-dimensional plots in a tri-dimensional space of adjusted reference intervals. (Panel A): TSH, Box-Cox transformation; (Panel B): T4, log10 transformation; (Panel C): TSH/T4 ratio, Box-Cox transformation. Primary covariate is age (right lower axis), secondary covariate is birth weight (left lower axis). The dark blue surface represents the median, lighter blue surfaces represent one and two standard deviations above and below the median, respectively.
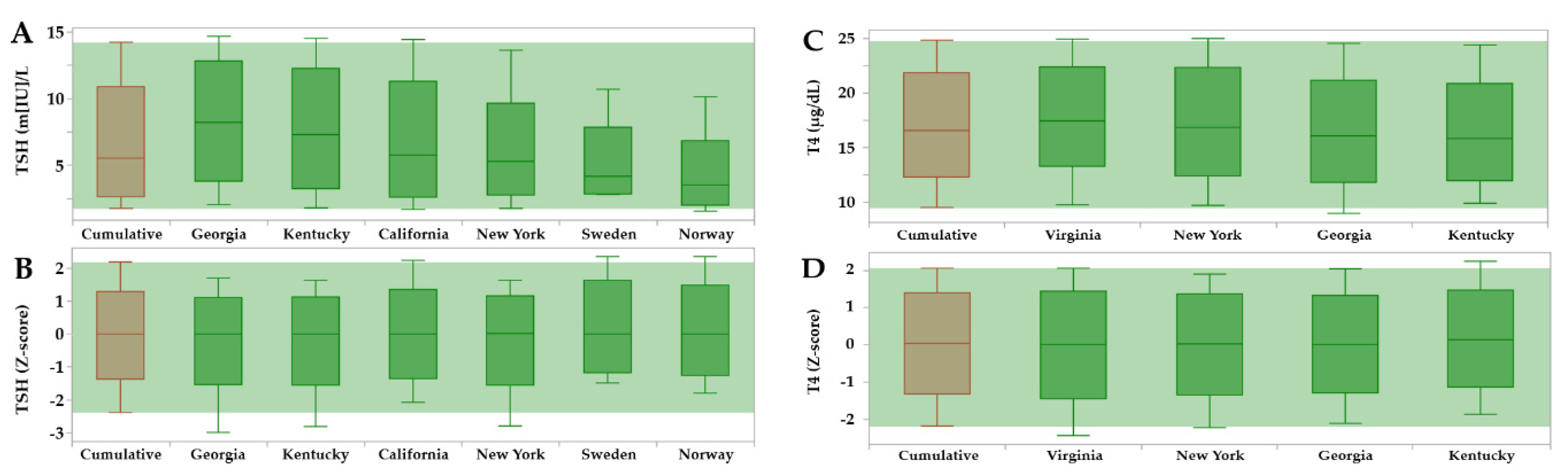
Figure 7.
Reference Range Comparison of TSH and T4 reference ranges in dried blood spots by contributing sites. Legend: The horizontal green band overlays the cumulative peripheral percentiles (brown) on top of the individual sites (dark green). Locations are not aligned vertically because they were sorted left to right in descending order of the median separately in each panel. (Panel A): unadjusted TSH ranges; (Panel B): TSH ranges after adjustment for age (hours), birth weight (grams) and location, expressed as Z-scores; (Panel C): unadjusted T4 ranges; (Panel D): T4 ranges after adjustment for age (hours), birth weight (grams), and location, expressed as Z-scores.
Figure 7.
Reference Range Comparison of TSH and T4 reference ranges in dried blood spots by contributing sites. Legend: The horizontal green band overlays the cumulative peripheral percentiles (brown) on top of the individual sites (dark green). Locations are not aligned vertically because they were sorted left to right in descending order of the median separately in each panel. (Panel A): unadjusted TSH ranges; (Panel B): TSH ranges after adjustment for age (hours), birth weight (grams) and location, expressed as Z-scores; (Panel C): unadjusted T4 ranges; (Panel D): T4 ranges after adjustment for age (hours), birth weight (grams), and location, expressed as Z-scores.
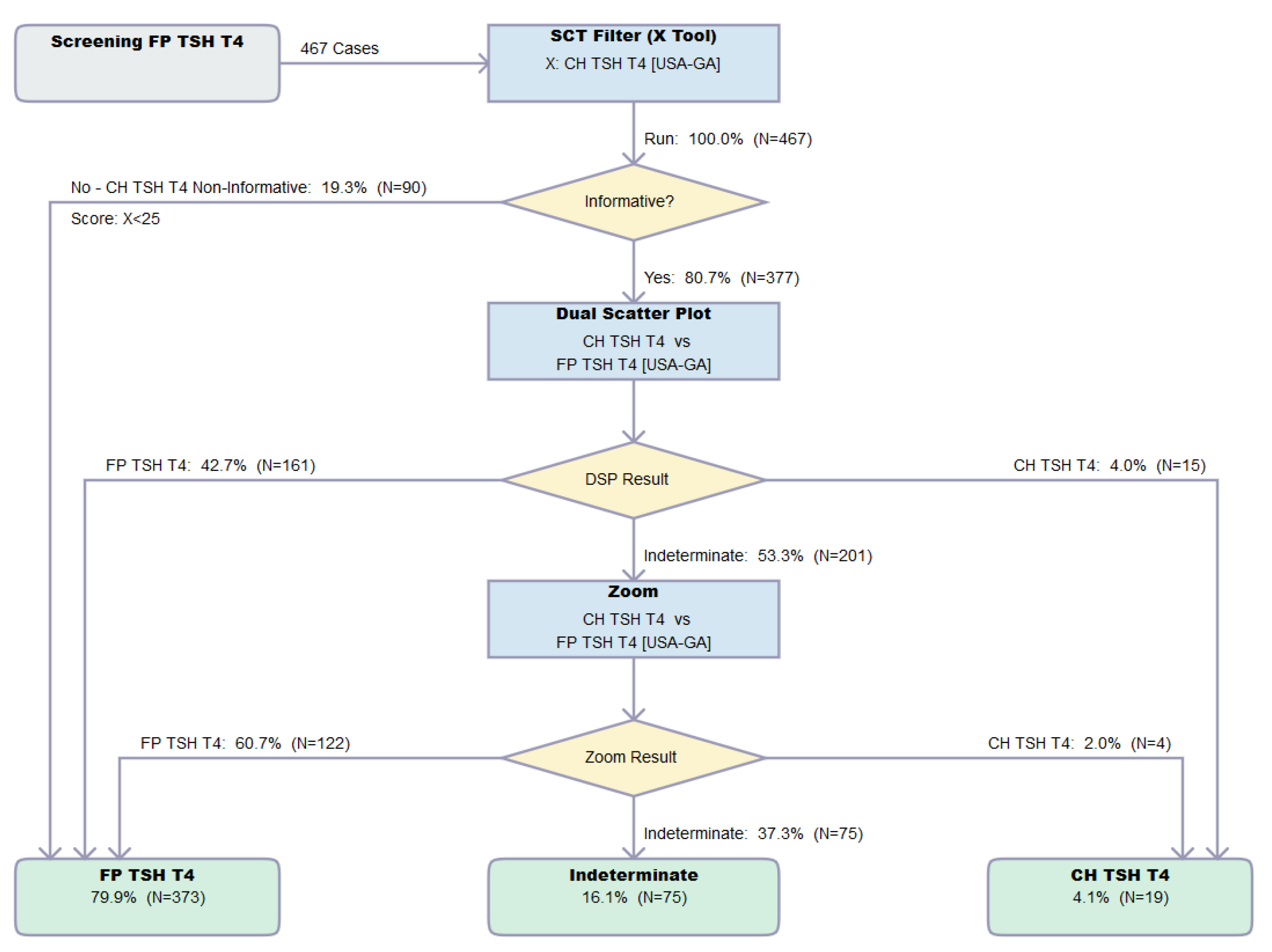
Figure 8.
Result flow of the Dual Scatter Plot Runner. Legend: Resolution by the CLIR Dual Scatter Plot Runner of 467 FP cases with elevated TSH and low T4 from location Georgia (USA-GA). Single Condition Tool is CH TSH T4 version 026 created 1 February 2021, Dual Scatter Plot CH TSH T4 vs. FP TSH T4 version 027 created 1 February 2021. Image is shown unedited as created automatically by the software. Color coding as follows: Grey, start; Blue, process; Yellow: decision; Green, totals.
Figure 8.
Result flow of the Dual Scatter Plot Runner. Legend: Resolution by the CLIR Dual Scatter Plot Runner of 467 FP cases with elevated TSH and low T4 from location Georgia (USA-GA). Single Condition Tool is CH TSH T4 version 026 created 1 February 2021, Dual Scatter Plot CH TSH T4 vs. FP TSH T4 version 027 created 1 February 2021. Image is shown unedited as created automatically by the software. Color coding as follows: Grey, start; Blue, process; Yellow: decision; Green, totals.
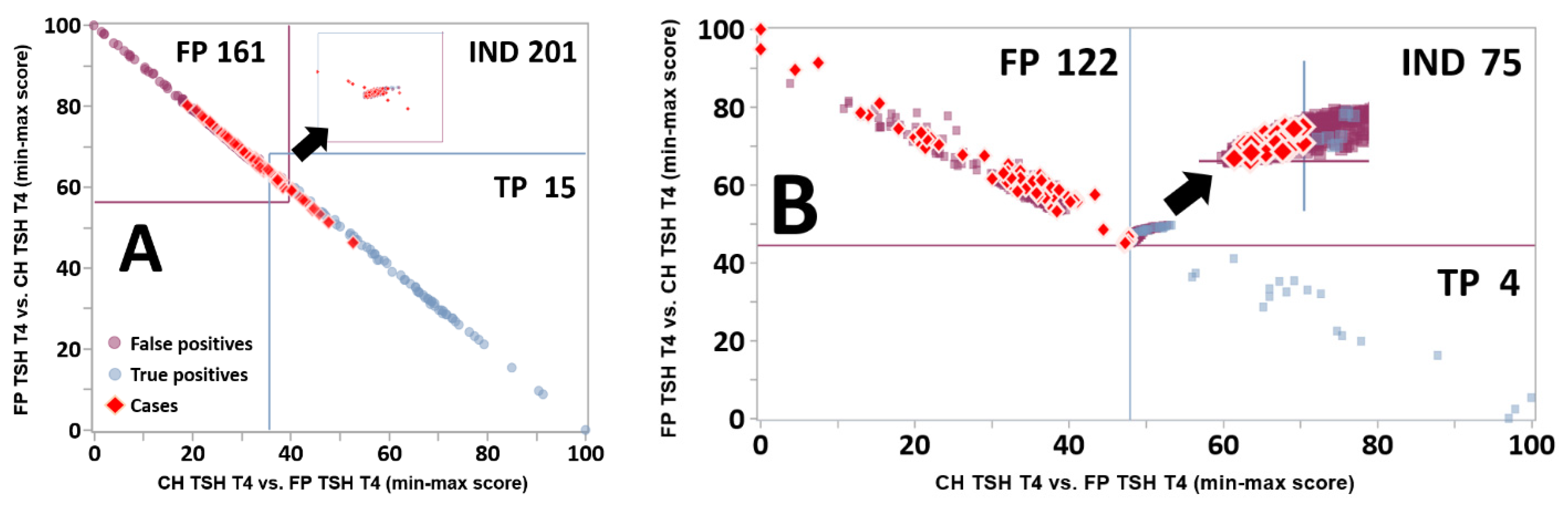
Figure 9.
Resolution of Indeterminate cases by the Zoom Plot. Legend: (Panel
A): Same Dual Scatter Plot for location Georgia as shown in
Figure 4A, overlaid with red diamonds representing individual false positive cases from the Verification cohort (location Georgia, condition FP TSH T4, N = 467). The insert in the top right quadrant is a magnification of the Indeterminate zone. Quadrants are defined as in the legend of
Figure 4. (Panel
B): 900 Indeterminate cases (see
Figure 4) from the Validation cohort overlaid with the 201 Indeterminate cases from Panel A. The insert in the top right quadrant is a magnification of the intersection of the lines.
Figure 9.
Resolution of Indeterminate cases by the Zoom Plot. Legend: (Panel
A): Same Dual Scatter Plot for location Georgia as shown in
Figure 4A, overlaid with red diamonds representing individual false positive cases from the Verification cohort (location Georgia, condition FP TSH T4, N = 467). The insert in the top right quadrant is a magnification of the Indeterminate zone. Quadrants are defined as in the legend of
Figure 4. (Panel
B): 900 Indeterminate cases (see
Figure 4) from the Validation cohort overlaid with the 201 Indeterminate cases from Panel A. The insert in the top right quadrant is a magnification of the intersection of the lines.
Table 1.
First tier markers contributed by participating locations.
Table 1.
First tier markers contributed by participating locations.
| Marker | Unit | California | Norway | Sweden | Georgia | Kentucky | New York | Virginia |
|---|
| TSH | M[UI]/L | + | + 1 | + | + | + | - 2 | - 2 |
| T4 | µg/dL | - | - | - | + | + | + | + |
| IRT | µg/dL | + | - | - | + | + | + | + |
| 17OHP | ng/mL | + | + 3 | + | + | + | + | + |
| C3 | nmol/mL | + 4 | + 4 | + 4 | + 4 | + 5 | + 5 | + 5 |
| C16 | nmol/ml | + 4 | + 4 | + 4 | + 4 | + 5 | + 5 | + 5 |
| CIT | nmol/mL | + 4 | + 4 | + 4 | + 4 | + 5 | + 5,6 | + 5 |
| TYR | nmol/mL | + 4 | + 4 | + 4 | + 4 | + 5 | + 5,6 | + 5 |
| BIOT | ERU | + | + 7 | + 8 | + | - 9 | - 9 | - 9 |
| GALT | U/g[Hb] | + | - | + | + | - 9 | - 9 | - 9 |
| TRECS | copies/µL | + | - | - | - | - | + | - |
| GALC | nmol/mL/hr | - | - | - | - | - | + | - |
| Measured in this study | 10 | 8 | 8 | 10 | 8 | 9 | 7 |
Table 2.
Summary of reference data at the time of submission and after exclusion criteria.
Table 2.
Summary of reference data at the time of submission and after exclusion criteria.
| | California | Norway | Sweden | Georgia | Kentucky | New York | Virginia | Total |
|---|
| Samples submitted | 537,225 | 223,168 | 90,021 | 272,832 | 232,017 | 389,109 | 226,164 | 1,970,536 |
| Covariate errors | 4126 | 1093 | − | 6787 | 5164 | 7173 | 3150 | 27,493 |
| Marker errors | 45 | 259 | − | 78 | 7345 | 2508 | 35 | 10,270 |
| Samples excluded | 4171 | 1352 | − | 6865 | 12,509 | 9681 | 3185 | 37,763 |
| % excluded | 0.8% | 0.6% | 0.0% | 2.5% | 5.4% | 2.5% | 1.4% | 1.9% |
| Samples uploaded | 533,054 | 221,816 | 90,021 | 265,967 | 219,508 | 379,428 | 222,979 | 1,932,773 |
Table 3.
Selection of unit increment by data density for the establishment of moving percentiles.
Table 3.
Selection of unit increment by data density for the establishment of moving percentiles.
| Continuous Covariate | Unit of Measure | Covariate Interval | End of Interval | Proportion of Data (%) a | Unit of Increment |
|---|
| Age at collection | hours | 1–168 | 1 week | 97.70% | 1 |
| 169–552 | 1 month | 1.48% | 6 |
| 553–4380 | 6 months | 0.80% | 24 |
| 4381–8760 | 1 year | 0.01% | n/a |
| Birth weight | grams | 250–5000 | n/a | 99.86% | 25 |
| 5001–10,000 | n/a | 0.14% | n/a |
Table 4.
Classification and distribution of true and false positive cases in the Validation and Verification datasets after application of the same exclusion criteria applied to reference data.
Table 4.
Classification and distribution of true and false positive cases in the Validation and Verification datasets after application of the same exclusion criteria applied to reference data.
| | Abnormal Markers | | | | | | | |
|---|
| | TSH H + T4 L | TSH H | T4 L | Total Counts by Location | |
|---|
| Validation | TP | FP | TP | FP | TP | FP | TP | % a | FP | % a | All | % a | T/F Ratio |
|---|
| California | − | − | 162 | 92 | − | − | 162 | 18% | 92 | 0.90% | 254 | 2% | 1.76 |
| Norway | − | − | 47 | 48 | − | − | 47 | 5% | 48 | 0.50% | 95 | 0.80% | 0.98 |
| Sweden | − | − | 65 | 31 | − | − | 65 | 7% | 31 | 0.30% | 96 | 0.80% | 2.1 |
| Georgia | 122 | 1549 | 98 | 2635 | 39 | 3676 | 259 | 28% | 7860 | 74% | 8119 | 71% | 0.03 |
| Kentucky | 72 | 49 | 47 | 668 | 9 | 232 | 128 | 14% | 949 | 9% | 1077 | 9% | 0.13 |
| New York | 113 | 119 | 43 | 162 | 31 | 747 | 187 | 20% | 1028 | 10% | 1215 | 11% | 0.18 |
| Virginia | 46 | 187 | 12 | 86 | 9 | 275 | 67 | 7% | 548 | 5% | 615 | 5% | 0.12 |
| Total | 353 | 1904 | 474 | 3722 | 88 | 4930 | 915 | 8% | 10,556 | 92% | 11,471 | | |
| Verification | | | | | | | | | | | | | |
| California | − | − | 143 | 82 | − | − | 143 | 31% | 82 | 1.80% | 225 | 4% | 1.74 |
| Norway | − | − | 18 | 31 | − | − | 18 | 4% | 31 | 0.70% | 49 | 1% | 0.58 |
| Sweden | − | − | 60 | 41 | − | − | 60 | 13% | 41 | 0.90% | 101 | 2% | 1.46 |
| Georgia | 30 | 467 | 34 | 996 | 24 | 803 | 88 | 19% | 2266 | 49% | 2354 | 46% | 0.04 |
| Kentucky | 10 | 4 | 8 | 52 | 2 | 71 | 20 | 4% | 127 | 3% | 147 | 3% | 0.16 |
| New York | 46 | 119 | 37 | 161 | 12 | 377 | 95 | 21% | 657 | 14% | 752 | 15% | 0.14 |
| Virginia | 25 | 179 | 3 | 122 | 2 | 1140 | 30 | 7% | 1441 | 31% | 1471 | 29% | 0.02 |
| Total | 111 | 769 | 303 | 1485 | 40 | 2391 | 454 | 9% | 4645 | 91% | 5099 | | |
Table 5.
Resolution of cases by location in the Verification set.
Table 5.
Resolution of cases by location in the Verification set.
| | California | Norway | Sweden | Georgia | Kentucky | New York | Virginia | Totals | |
|---|
| First tier screening | TSH | TSH | TSH | TSH + T4 | TSH + T4 | T4 | T4 | | |
| Second tier test | | | | | | TSH | TSH | | |
| Other markers (ratios) | 9 | 7 | 8 | 8 | 6 | 8 | 6 | 52 | |
| Single condition tools (SCT) | 2 | 2 | 2 | 6 | 6 | 6 | 6 | 30 | |
| Dual scatter plots (DSP) | 1 | 1 | 1 | 3 | 3 | 3 | 3 | 15 | |
| True positive cases | 143 | 18 | 60 | 88 | 20 | 95 | 30 | 454 | |
| Cases resolved as FP by SCT | - | - | - | - | - | - | - | 0 | |
| Cases resolved as FP by DSP | - | - | - | 2 | - | 2 | - | 4 | |
| Cases resolved as FP by Zoom | - | - | - | 4 | - | - | - | 4 | |
| Screens resolved as FP by CLIR | 0 | 0 | 0 | 6 | 0 | 2 | 0 | 8 | |
| % | 0% | 0% | 0% | 7% | 0% | 2% | 0% | 2% | |
| False positive cases | 82 | 31 | 41 | 2732 | 127 | 657 | 1777 | 5447 | |
| Cases resolved as FP by SCT | 4 | 6 | - | 637 | 3 | 17 | 107 | 774 | (40%) |
| Cases resolved as FP by DSP | 3 | - | 5 | 489 | 2 | 133 | 180 | 812 | (42%) |
| Cases resolved as FP by Zoom | 33 | 3 | 8 | 229 | - | 55 | 17 | 345 | (18%) |
| Screens resolved as FP by CLIR | 40 | 9 | 13 | 1355 | 5 | 205 | 304 | 1931 | |
| % | 49% | 29% | 32% | 50% | 4% | 31% | 17% | 35% | |
Table 6.
True positive screening results resolved as false positive by CLIR tools.
Table 6.
True positive screening results resolved as false positive by CLIR tools.
| Case | Site | Tool | Age (Hours) | Birth Weight (Grams) | Gest. Age (Weeks) | Sex | TSH (m[IU]/L | T4 (µg/dL) | Resolution by SCT | Resolution by DSP | Resolution by Zoom |
|---|
| Case 01 | GA | TSH T4 | 1 | 1474 | n/a | Male | 54 | 2.1 | Informative | Indeterminate | FP |
| Case 02 | GA | TSH T4 | 1 | 911 | n/a | Female | 53 | 4.1 | Informative | Indeterminate | FP |
| Case 03 | GA | TSH T4 | 1 | 2535 | n/a | Male | 51 | 6.0 | Informative | Indeterminate | FP |
| Case 04 | GA | TSH T4 | 715 | 540 | n/a | Male | 22 | 1.8 | Informative | Indeterminate | FP |
| Case 05 | GA | T4 | 659 | 669 | n/a | Male | 8 | 4.8 | Informative | FP | - |
| Case 06 | GA | T4 | 1 | 437 | n/a | Female | 13 | 4.6 | NI | - | - |
| Case 07 | NY | TSH T4 | 1 | 3010 | 39 | Male | 23 | 4.6 | Informative | FP | - |
| Case 08 | NY | TSH T4 | 1 | 515 | 30.1 | Male | 34 | 5.3 | Informative | FP | - |


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}