1. Introduction
The Internet of Things (IoT) as an important information network has been widely used in many areas of everyday life such as smart home, smart transportation, smart city, etc. [
1,
2]. Nevertheless, there are a vast quantity of IoT devices worldwide contributing to a significant increase in energy usage, placing additional strain on the global electric grid and exacerbating environmental changes. Efforts have been made to extensively explore technical solutions that promote efficient consumption in order to achieve the objective of green communications and enhance the utilization efficiency of transmission energy [
3]. In recent years, with the increase in IoT devices, device-to-device (D2D) technology has been developed as an emerging technology to enhance spectrum efficiency (SE) and address the growing lack of spectrum resource scarcity [
4]. The D2D technology can be widely used in various scenarios, including IoT [
5], emergency communications [
6], and social networks [
7]. Recent research has shown that D2D technology has remarkable advantages in improving SE and enhancing the user experience [
8].
Green IoT, a novel paradigm emphasizing energy efficiency (EE) to address the environmental impact of IoT technologies for achieving sustainable and environmentally friendly development, is regarded as a prospective research avenue in the IoT domain [
9]. However, as a crucial technology in IoT, the constrained onboard battery capacity hinders the realization of the full potential of D2D communication. Enhancing the system EE of D2D communication through effective resource management remains an ongoing research focus. Furthermore, in some scenarios with long distances or numerous obstacles, the communication between D2D devices can be severely affected. For instance, the authors of [
10] focused on the unmanned aerial vehicle (UAV) location and resource allocation in UAV-assisted D2D communication for industrial IoT, and confirmed that the proposed decomposition-based algorithm can improve the system EE when compared with other benchmarks. The use of intelligent reflecting surfaces (IRSs) offers a promising option to address this issue, which can eliminate interference between D2D pairs and thus enhance EE by reconstructing the wireless communication environment [
11,
12,
13]. Specifically, the IRS consists of multiple electromagnetic reflecting elements that are passive in nature. By altering the amplitude and phase of the incoming signal, it achieves a beamforming gain through reflection [
14]. The deployment of IRS on urban building surfaces presents a significant improvement opportunity for guaranteeing quality of service in base station (BS) coverage blind spots. This improvement is achieved by establishing reflective line-of-sight (LoS) links. Furthermore, the IRS-assisted system offers several advantages over traditional relay systems, including low cost and low power consumption [
15]. Moreover, D2D communications in cellular networks is subject to mutual interference from cellular users and other D2D devices. Using IRS to effectively regulate each reflection element’s amplitude or phase shift coefficient, and resource allocation of the D2D communication network can effectively mitigate the interference [
16]. Unlike traditional approaches like alternating optimization, deep reinforcement learning (DRL) does not require prior knowledge and exhibits lower complexity and better performance. Recently, some research has already applied it to IRS-assisted wireless communication systems. For example, in [
17], the authors introduce the single-agent deep deterministic policy gradient (DDPG) to optimize the passive beamforming of IRS in MISO systems and the authors of [
18] extend this method to IRS-assisted MIMO systems. In [
19], a multi-agent reinforcement learning (MARL)-based scheme was proposed for the joint design of passive beamforming and power control. Furthermore, to address the optimization problem of the mixed action space in IRS-assisted D2D communication networks, the authors of [
20] proposed a novel multi-agent multi-pass deep Q-networks algorithm using centralized training and a decentralized execution (CTDE) framework.
Additionally, considering the UAV’s high mobility, it can act as a relay and be deployed at high altitudes to provide LoS links between ground terminals. The advantages of both IRS and UAV in improving communications and networks have been demonstrated [
21]; many works have started to investigate the potentials of IRS mounted on a UAV, termed aerial UAV-IRS [
22,
23,
24,
25,
26]. Because of the high mobility of the UAV, UAV-assisted communication systems often exhibited time-varying and dynamic characteristics, thereby makes the trajectory optimization and resource allocation for such systems intricate. The rapid advancement in machine learning has brought reinforcement learning to the forefront as a promising solution for tackling these challenges. Consequently, several studies have been dedicated to exploring DRL in UAV-IRS-assisted communication systems. The authors of [
23] employed DDPG and double deep Q-learning network (DDQN) algorithms to tackle the challenge of trajectories and phase shift optimization in an IRS-assisted UAV network, and the numerical results demonstrated that DDPG-based continuous control achieves a better performance. The researchers in [
24] introduced an innovative SWIPT method that involved optimizing resource allocation and a twin delayed DDPG (TD3)-based algorithm was used to obtain the solution to the problem. The authors of [
25] considered the outdated channel state information (CSI) and developed a novel twin-agent DDPG algorithm to optimize radio resource allocation. However, the schemes based on single-agent DRL left out of consideration the interaction between multiple communicating nodes, which leads to poor performance in cooperative tasks such as D2D communication and vehicle communication. In addition, single-agent DRL requires a centralized data center to collect the status information of all agents and carries out centralized training, which results in a significant communication overhead. In contrast, a localized observation-based MARL algorithm has been proposed for communication systems [
26,
27]. It was demonstrated in [
28] that the MARL algorithm can achieve better performance and robustness in UAV-IRS-assisted systems compared to single-agent reinforcement learning.
Furthermore, there are few works that focus on the system EE maximization for UAV-IRS-assisted D2D networks in the downlink scenario. For example, Ref. [
29] considered a multiple UAV-IRS-enhanced anti-jamming D2D communication network and maximized the achievable sum rate by optimizing the IRS mode selection and phase shift, where each UAV is equipped with an IRS as an aerial relay to forward signals from multiple D2D users. In [
30], the authors considered a scenario in which a UAV was equipped with an active IRS-assisted terahertz band D2D communication; the maximum system sum rate was achieved through reasonable power control and beamforming. In [
31], the author proposed a distributed deep learning algorithm for realizing power control and channel selection. However, the previous studies did not take into account the impact caused by the movement of the UAV. Additionally, in [
32], the researchers investigated a D2D communication system in the uplink scenario that utilized UAV-IRS assistance; they further employed a DDQN-based algorithm that optimized both the UAV’s flight trajectory and the IRS’s phase shift. But, in practical applications, D2D communication is usually considered as a distributed cooperative scenario. Using traditional centralized algorithms requires real-time access to global information, inevitably resulting in a significant amount of communication overhead [
33]. In general, there has not been sufficient investigation into the integration of UAV-IRSs into D2D communications for the downlink scenario.
Motivated by the potential advantages and features of UAV-IRS, this paper explores energy-efficient UAV-IRS-assisted D2D systems, where the IRS is mounted on a rotary-wing UAV to serve as an aerial relay. In this paper, we aim to maximize the system’s average EE by jointly optimizing the considered system’s resource management along with the movement of the UAV-IRS. In order to obtain a near-optimal solution, we come up with a multi-agent DRL (MADRL)-based approach. The primary contributions of this paper are the following:
We investigate the downlink of D2D communications assisted by UAV-IRS, in which the BS, the UAV-IRS, and all D2D pairs collaborate to achieve improved EE performance. Specifically, the UAV carries the IRS to establish LoS links between various communication nodes. To maximizing the system EE over time in a changing environment, we formulate an optimization problem that involves optimizing the UAV’s trajectory, the BS’s active beamforming, the IRS’s passive beamforming, and the D2D transmitters’ power control.
To solve the proposed EE maximization problem, we use a Markov Game to model the cooperative task considering each D2D pair, BS, and UAV-IRS. Consequently, the resource allocation and trajectory optimization problem is addressed using multi-agent twin delayed DDPG (MATD3) [
34]. To enhance its learning efficiency, prioritized experience replay (PER) is employed. In addition, the algorithm’s complexity is thoroughly examined.
The availability of the proposed algorithm is validated through simulations, with numerical results demonstrating that the proposed scheme outperforms benchmark schemes in terms of convergence speed and EE performance.
The remaining part of this paper is organized as follows. The system model is presented in
Section 2. The EE maximization optimization problem is formulated in
Section 3. In addition,
Section 4 introduces the MATD3-based algorithm.
Section 5 provides the numerical results of the simulation, while
Section 6 concludes the paper.
2. System Model
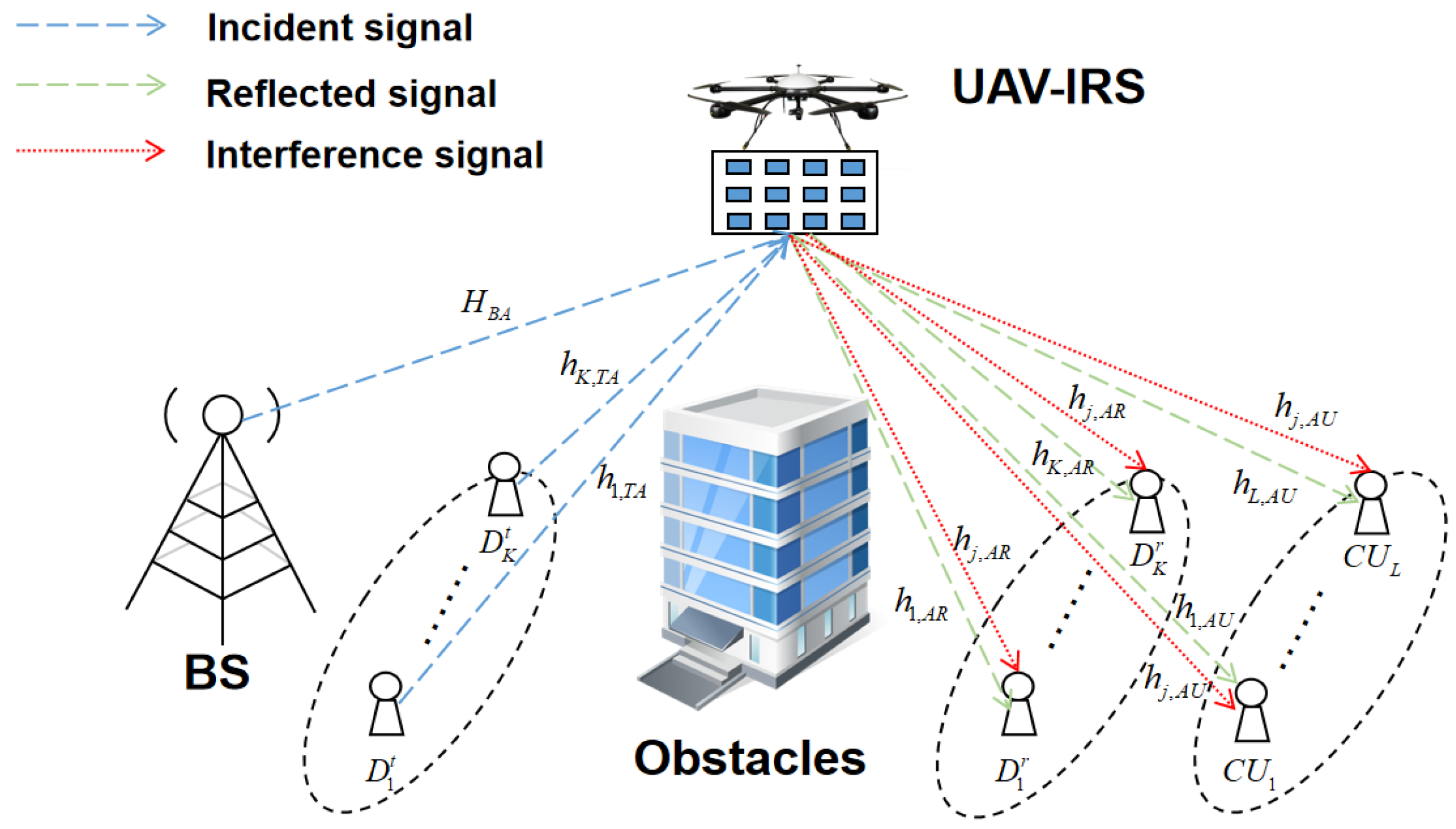
Figure 1 depicts our considered UAV-IRS-assisted D2D communication underlying cellular network in the downlink scenario, including an UAV-IRS, a BS,
L cellular users (CUs), and
K D2D pairs. Specifically, a rotary-wing UAV carries a passive IRS as an aerial relay to forward communication between D2D devices. In addition, we denote the sets of all CUs and D2D pairs as
and
, respectively. Each D2D communication pair includes a transmitter with only one antenna and a receiver with only one antenna, and it is assumed that all D2D communication pairs and CUs share the same spectrum resources. Let
and
represent the
k-th D2D transmitter and the
k-th receiver, respectively. The UAV-IRS has a uniform rectangular array (URA) comprising
reflection elements, while the BS is equipped with a uniform linear array (ULA) consisting of
antennas.
Let
and
represent the coordinates of
and
, respectively. The BS is located at the coordinates
. Furthermore, we make the assumption that the rotary-wing UAV maintains a constant altitude characterized by
. The total time period
T is partitioned into
N equal time slots, represented by
for each slot. Therefore, let
represent the UAV location information at the
n-th time slot. The movement of the UAV must comply with the following restrictions:
where (1a) stands for the mobility constraints of the UAV including start point and end point,
represents the drone’s maximum flying velocity, (1b) sets the constraint for the flying range of the UAV, and (1c) specifies the initial location.
In this paper, it is assumed that the presence of obstacles results in the absence of direct links between any two nodes. The channel coefficients from transmitter to the UAV-IRS, from the UAV-IRS to receiver , from the BS to the UAV-IRS, and from the UAV-IRS to the CU l are denoted by , , , and , respectively. It is presumed that the channels between any ground devices and the UAV-IRS are regarded as LoS links.
Considering that the UAV-IRS-D2D link and the UAV-IRS-CU link may be blocked by obstacles, the path loss between the UAV-IRS and other communication nodes can be modeled as a probabilistic LoS path model [
35]. It can be described as
where
and
are fixed values that vary based on the specific conditions or circumstances, and
is the elevation angle, where
h and
d are the altitude intercept and the projector range between the UAV-IRS and the BS/users. Then, the path loss can be described as
where
is the constant coefficient related to the antenna gain and frequency.
represents the passive beamforming of the IRS, in which
are the amplitude and phase shift coefficients of the
m-th reflection element, respectively. In this paper, the primary focus of the optimization adjustment lies in the phase shift. Therefore, the amplitude coefficient is fixed to a value of one, i.e.,
. The reflected interference channel from other transmitters can be represented as
. Subsequently, the received signal at receiver
is
where
, and
,
represent the active beamforming vector at the BS, the power coefficient of the transmitter
, and the transmit data from the
to
, respectively.
denotes the AWGN noise. The corresponding SINR at
is
where
.
In addition, the signal received at
can be denoted as
where
denotes the AWGN noise at
. Accordingly, the corresponding SINR at
is
where
. Thus, the achievable rate of receiver
and
in the
n-th time slot can be described as
respectively.
The propulsion power consumption of a rotor-craft UAV is modeled as [
36]
where
stands for the UAV’s instantaneous speed in the
n-th time slot;
and
are the constant blade profile power and induced power, respectively;
and
are the constant blade tip speed and mean rotor-induced velocity during hover, respectively;
,
s, and
A are the air density, rotor solidity, and rotor disc area, respectively; and
stands for the fuselage drag ratio.
Considering the energy expenditure of the system circuit and IRS elements, the system EE is expressed as
where
, with
and
being the power consumption of the circuits and the IRS, respectively.
4. The Proposed Solution
In this section, we begin by employing the Markov Game framework to model the optimization problem . Then, we will introduce the various elements of the multi-agent environment. Since a fully decentralized MARL-based algorithm faces the problem of a non-stationary environment and is difficult to converge, a MATD3 approach based on the CTDE framework is adopted.
4.1. Markov Game Formulation
Since the transmitter in each D2D communication pair cannot directly communicate with other transmitters, the formulated problem can be regarded as a Markov Game. In this setting, each communicating node serves as an agent and aims to optimize the long-term cumulative reward by utilizing observations and selecting actions based on its individual policy. Given the non-stationary nature of the environment, it is necessary for all agents to work cooperatively in order to maximize the shared reward. To ensure each communication node works cooperatively, the UAV-IRS, the BS, and each transmitter are considered as agents. Hence, there are agents in the system. Let , , and represent the agents of each transmitter, the BS, and the UAV-IRS, respectively. Thus, the set of all agents can be defined as . The Markov Game for the considered UAV-IRS-assisted D2D communication scenario can be viewed as a tuple , where the set of the observation space and action space of agents are denoted as and , respectively. refers to the probability of all agents performing actions by exploiting the current state and transitioning to the subsequent state, r is the reward function, and is the reward discount factor. In a Markov Game, each agent aim to maximize its own total expected reward . In order to solve the problem of non-stationarity in a multi-agent environment, it is assumed that the policies of all other agents are known. The specific design of observations, actions, and rewards are as follows.
4.1.1. Observation
The observations of
,
, and
are denoted as
,
, and
, respectively. Since each D2D transmitter only knows its local observations and partial interference information, to simplify the analysis process, it is assume that the CSI can be obtained by adopting the channel estimation method that is used in [
37,
38]. The observation
contains the CSI between
and
, and the interference information from other D2D transmitters and the BS at the
-th time slot, which can be represented as
Similarly, the observation of the BS contains the CSI between the BS and CUs, and the interference channel information from D2D transmitters and the BS at the
-th time slot, and can be expressed as
Additionally, the observation
contains the UAV trajectory and the CSI from the UAV-IRS to other devices at the
th time slot, and is given as
4.1.2. Action Space
For agent , the action includes the power allocation coefficient of the k-th transmitter. For agent , the action includes the active beamforming vector for all CUs. For agent , the action contains the passive phase shift matrix and the UAV’s trajectory.
4.1.3. Reward Function
Considering our objective of improving the average EE, the reward function can be formulated as follows:
where
are the penalties when the constraints are not satisfied. Let
and
denote the QoS constraint penalty; Let
and
denote the maximum transmit power constraint penalty, respectively, in which
; the UAV’s trajectory constraint penalty is defined as
. The non-negative constants
represent the weight coefficients used to balance the different penalty functions.
4.2. MATD3 Approach
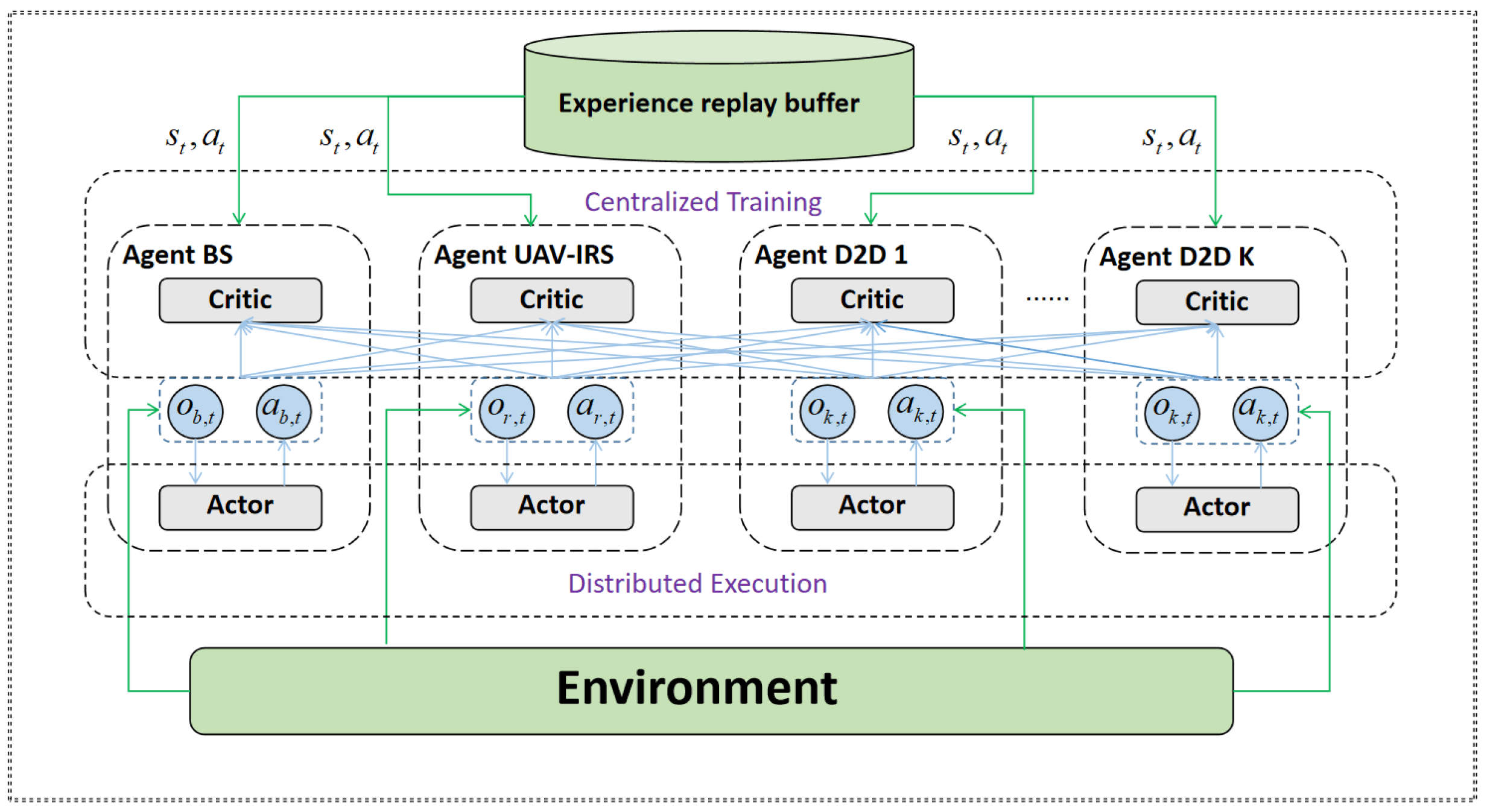
MATD3 is a multi-agent extended version of the single-agent TD3, which adopts the mode of the CTDE framework in the training process. As demonstrated in
Figure 2, each agent first obtains the local observation
and feeds it into the actor network. Then, each agent obtains the action
to execute according to its own policy
at the time slot
n, and interacts with the environment to obtain a new observation
and store
in the experience buffer pool
D. Subsequently, the critic network of each agent incorporates the global state, which encompasses the observations and actions of all other agents.
Unlike multi-agent DDPG (MADDPG), MATD3 integrates two techniques: clipped double Q-learning (CDQ) and target policy smoothing. In the MATD3 algorithm, the training of the critic network is performed centrally, and input to the critic network includes both the observed states and the actions taken by other agents. The centralized training process assumes training taking place in the UAV-IRS, during which all communication nodes upload channel state information while forwarding data through UAV-IRS. The CDQ-learning technique is utilized to mitigate the issue of Q-value overestimation. Specifically, each agent comprises an evaluated actor network, two evaluated critic networks, a target actor network, and two target critic networks. Each evaluated actor network outputs action with the local observation and the network parameter . The evaluated critic networks output the Q values and to evaluate the action of the actor network with the local observation and the action . Specifically, the centralized Q value is the minimum value between and . During the training phase, a mini-batch of data is utilized to update the critic network parameter by minimizing the temporal difference (TD) error. Differently from the single-agent TD3, the critic input of each agent on MATD3 has additional information, such as the actions and observations of other agents, in addition to its own state–action information. TD3 adopts the target network approach to fix the Q-network in the TD target.
The target value y can be computed through
where
is the clipped Gaussian noise and
c is a variable parameter.
The evaluated critic network is updated through minimizing the loss function:
The evaluated actor network of each agent is updated through gradient descent:
The target network parameters
,
and
are updated by
4.3. Prioritized Experience Replay
The technique of classical experience replay involves randomly selecting samples from the experience replay buffer in a uniform manner. This is carried out to reduce the correlation between the samples. However, the importance of experience is ignored. In the case of sparse rewards, agents receive a reward only after executing multiple correct actions, resulting in limited transitions to encourage proper learning. Therefore, using random sampling of experiences in this scenario can result in reduced learning efficiency. Prioritized experience replay is adopted to solve such problems [
39], which is an improved method of the experience replay buffer. It determines the order in which experience samples are extracted by introducing a priority and replay probability. Based on priority, high-priority experience samples are more likely to be extracted and used for training the agent.
In this paper, proportional prioritization is adopted to restore the priority of a transition, which can be expressed as follows:
where
is the TD error and
is a small fixed value to avoid the probability of zero. The TD error represents the difference between the current Q value and the Q value that should be pursued in the next step, and higher TD errors will be assigned a higher priority. Thus, the sampling probability can be defined as follows:
where
is the hyperparameter that regulates the degree of priority.
Due to the introduction of bias through PER, which alters the data distribution, it becomes necessary to employ importance sampling to mitigate the impact. The weights for importance sampling can be defined as follows:
where
is the hyperparameter that regulates the degree of bias introduced by PER and
corresponds to the number of existing transitions in the experience replay pool. Consequently, Equation (16) can be reconstructed as the loss function:
Algorithm 1 outlines the training process of the optimization for resource allocation and trajectory using MATD3.
| Algorithm 1: Joint resource allocation and trajectory using MATD3 |
![Drones 08 00122 i001]() |
4.4. Complexity Analysis
The time computation complexity depends on the network operations between two layers. Since our proposed algorithm includes two actor networks and four critic networks, its complexity is given by , in which the -th and the -th are the number of operations of the l-th actor and the u-th critic network layers, respectively; represents the number of layers in the actor network, while represents the number of layers in the critic network. For the online execution phase, the time complexity of each actor network is .
5. Simulation Results
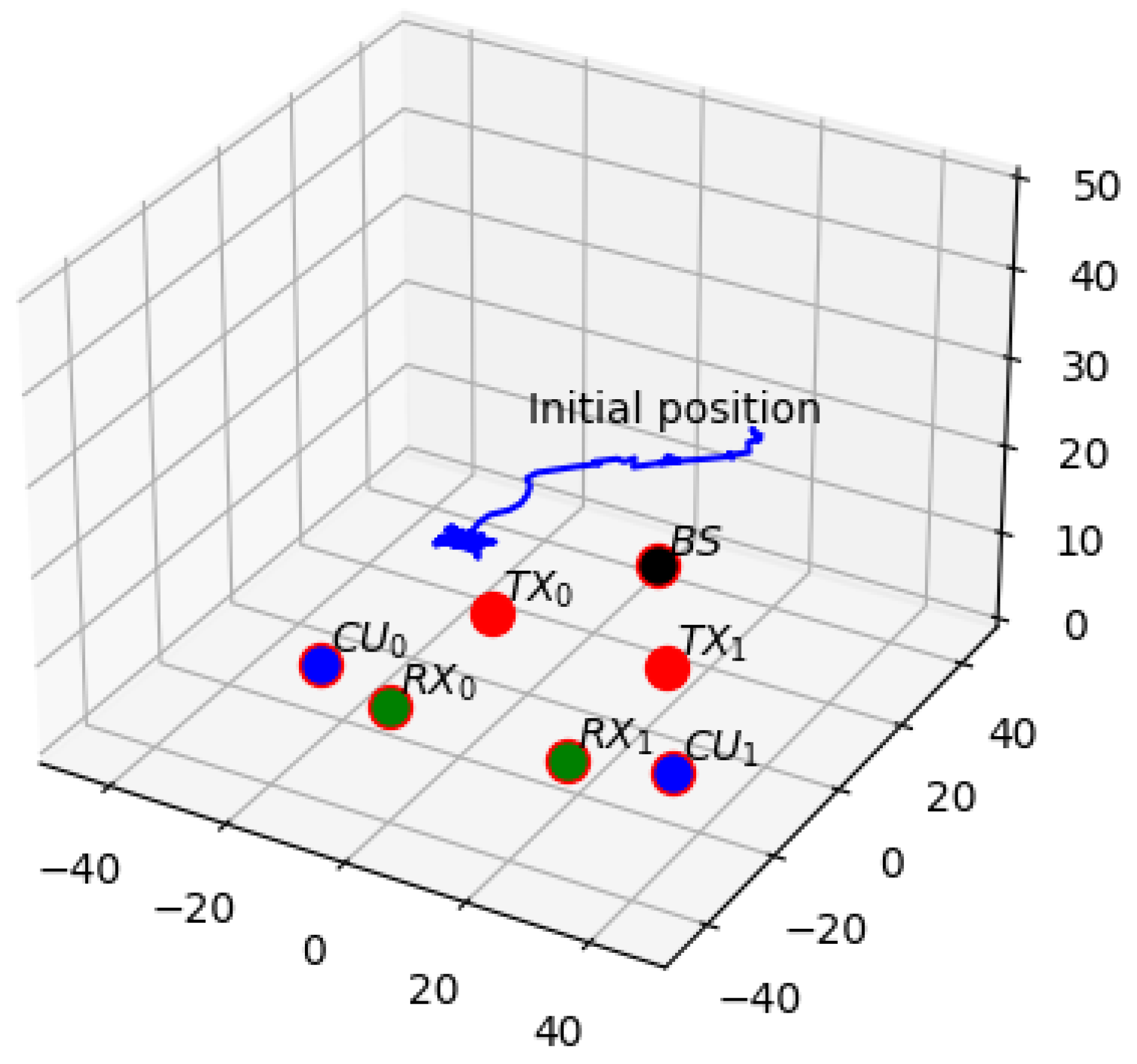
In this section, we validate the efficacy of the proposed algorithm in optimizing resource allocation and designing the UAV trajectory. It is assumed that the UAV maintains a constant altitude of
throughout the flight. For comparison, we compare the system EE performance under fixed position and random trajectory. The UAV-IRS’s initial position is configured as (25 m, 25 m, 25 m), while the location of the BS is fixed at (0 m, 30 m, 5 m). Moreover, the position of the UAV in the fixed position scheme is consistent with the initial position of the proposed scheme. All CUs and D2D pairs are located around the initial UAV position. The simulation platform is based on AMD Ryzen 7735H, NVIDIA GeForce RTX4060, python3.7.4 and Torch-1.12.1. Each agent’s actor and critic networks are built with three fully connected layers, comprising 512, 256, and 128 neural units, respectively. The energy consumption model parameters of the rotary-wing UAV are set based on [
36]. Formal verification is crucial in IoT systems to ensure safety, security, and reliability by detecting errors, verifying complex interactions, and enhancing trust in the system’s performance, scalability, and compliance with specifications [
40,
41]. In order to reduce the complexity of the experiment and considering that we currently only have a single drone, we have not yet addressed the issues of safe drone operation and carried out formal verification. For the relevant parameters of the probabilistic path loss model, we set
[
35]. According to [
42], the total energy consumption of the system’s circuit power and the IRS is set as
. For the hidden layer, the Relu activation function is applied and, for the output layer of actor networks, the Tanh activation function is employed. The number of training episodes is set as 5000 and each episode has 200 time steps. In this paper, each time step is treated as a time slot. Additional simulation parameters can be found in
Table 1 [
36,
43].
Figure 3 illustrates the trajectory of the UAV after optimization. Obviously, the UAV will fly to a fixed area and fluctuate in a small range after the optimization. When it flies to the center of the map, the UAV hovers at the center of all users to enhance the average system EE while meeting the QoS constraints of all users.
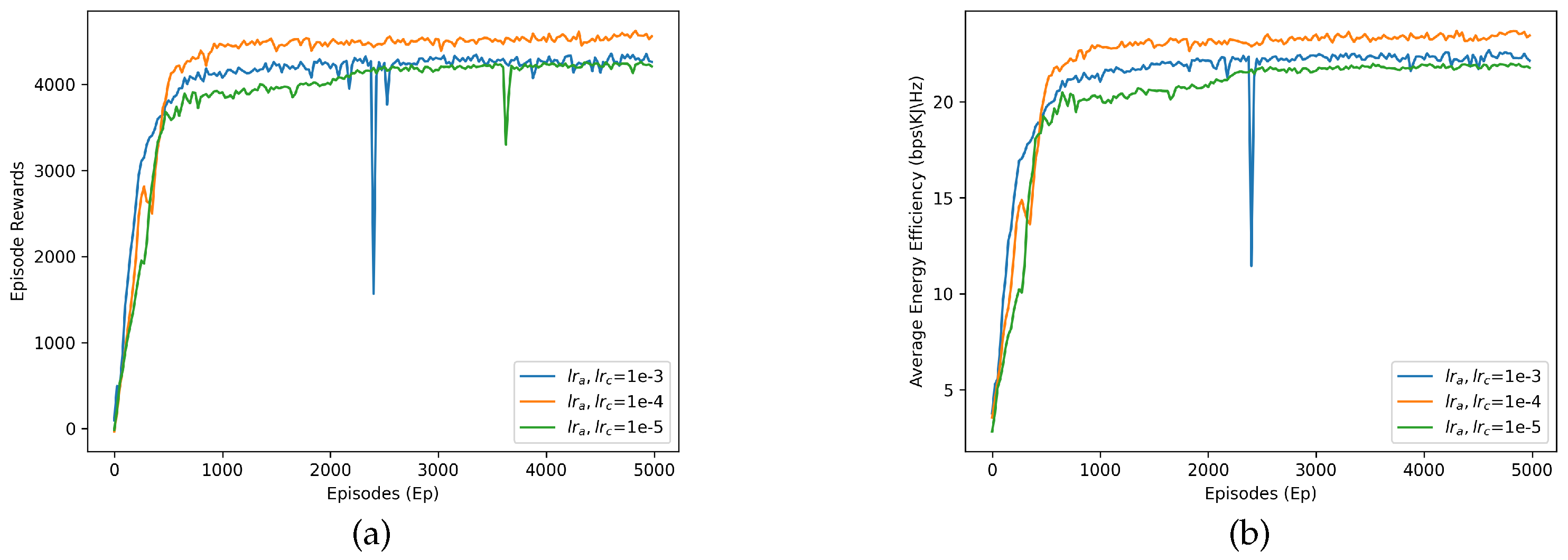
Figure 4a shows the episode return variation during training with different learning rate settings. Observing the learning process under different learning rate settings, it becomes apparent that the MATD3-based algorithm gradually converges. Obviously, the learning curve tends to converge after 1000 episodes. Specifically, the proposed algorithm at the learning rate of 0.0001 converges faster and obtains a better performance than the proposed algorithm at the learning rate of 0.001 and 0.00001. The reason behind this is that the excessively large learning rate may result in excessively large weight updates, thereby causing the loss to become too small and missing the optimal solution. Furthermore, a too small learning rate also leads to poor performance, since it results in tiny updates to the parameter, making it difficult for the algorithm to effectively learn the characteristics of the environment and the reward function.
Figure 4b illustrates the average EE versus episodes with the same parameter setting. This proves that the reward setting is consistent with our optimization goal. Finally, the proposed algorithm is superior when examining the converged average EE with the learning rate being set to 0.0001.
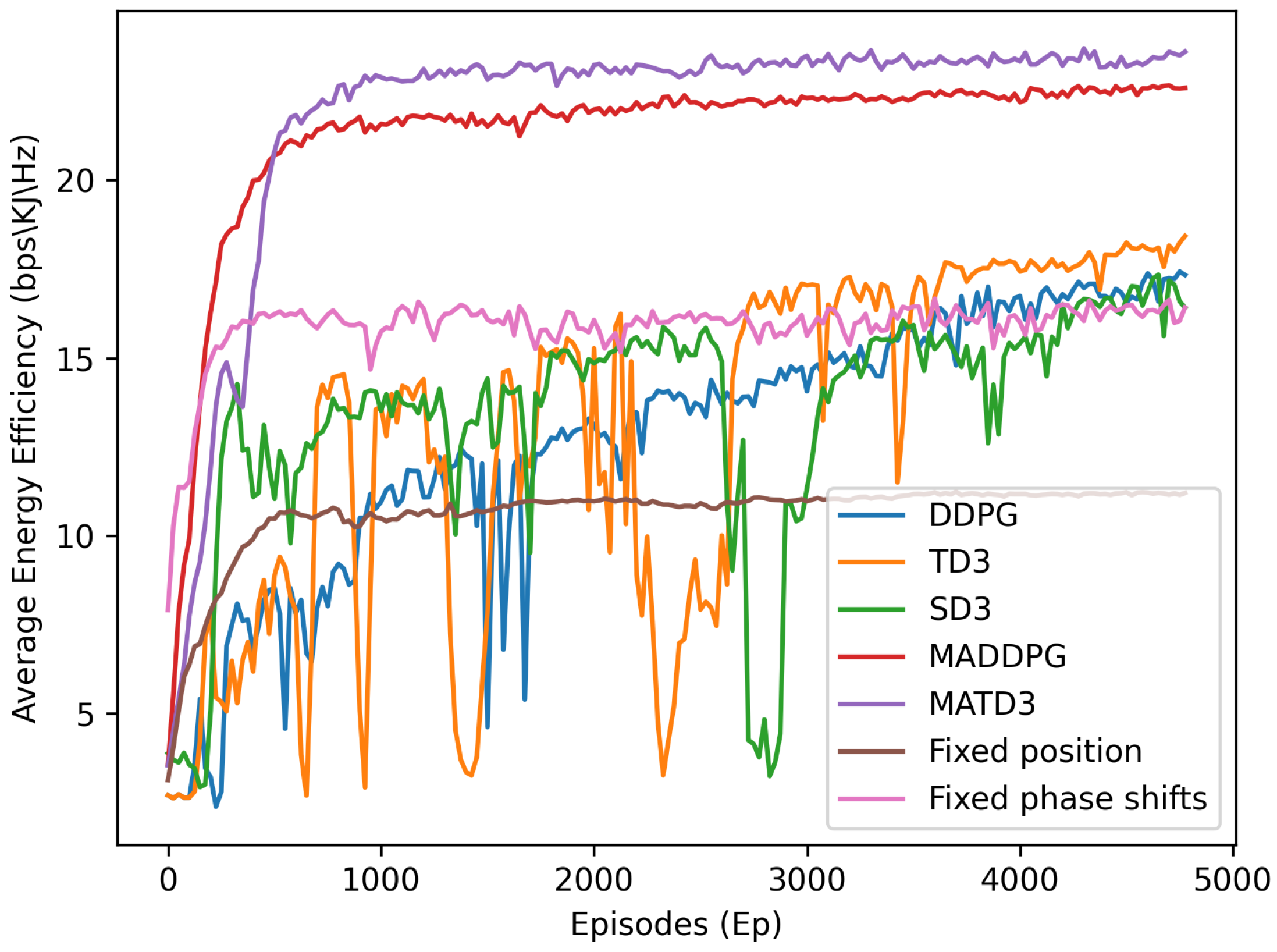
Figure 5 demonstrates the average EE versus the number of episodes of different schemes with
. The benchmark schemes include DDPG, TD3, SD3 [
44], MADDPG, MATD3 with fixed UAV position, and MATD3 with fixed phase shifts. The state input of all single-agent algorithms (DDPG, TD3, SD3) is set to global state information. The EE improvement achieved by simultaneously optimizing the resource allocation and the UAV trajectory is clearly superior to that of the fixed position and the fixed phase shift schemes. The main reason is that the reflective surface in the fixed position is difficult to meet the rate constraint of all users, and another reason is that the UAV-IRS requires greater energy consumption to sustain a hover state and maintain a fixed position, compared to maintaining a flight state. It can also be observed that the MATD3-based scheme surpasses the MADDPG-based scheme and all single-agent-based schemes; the DDPG-based scheme performs the worst due to the presence of high input dimensions. Furthermore, since MATD3 introduces dual Q-value networks, it increases the complexity of the training process and then results in a slower convergence speed compared to the MADDPG-based scheme.
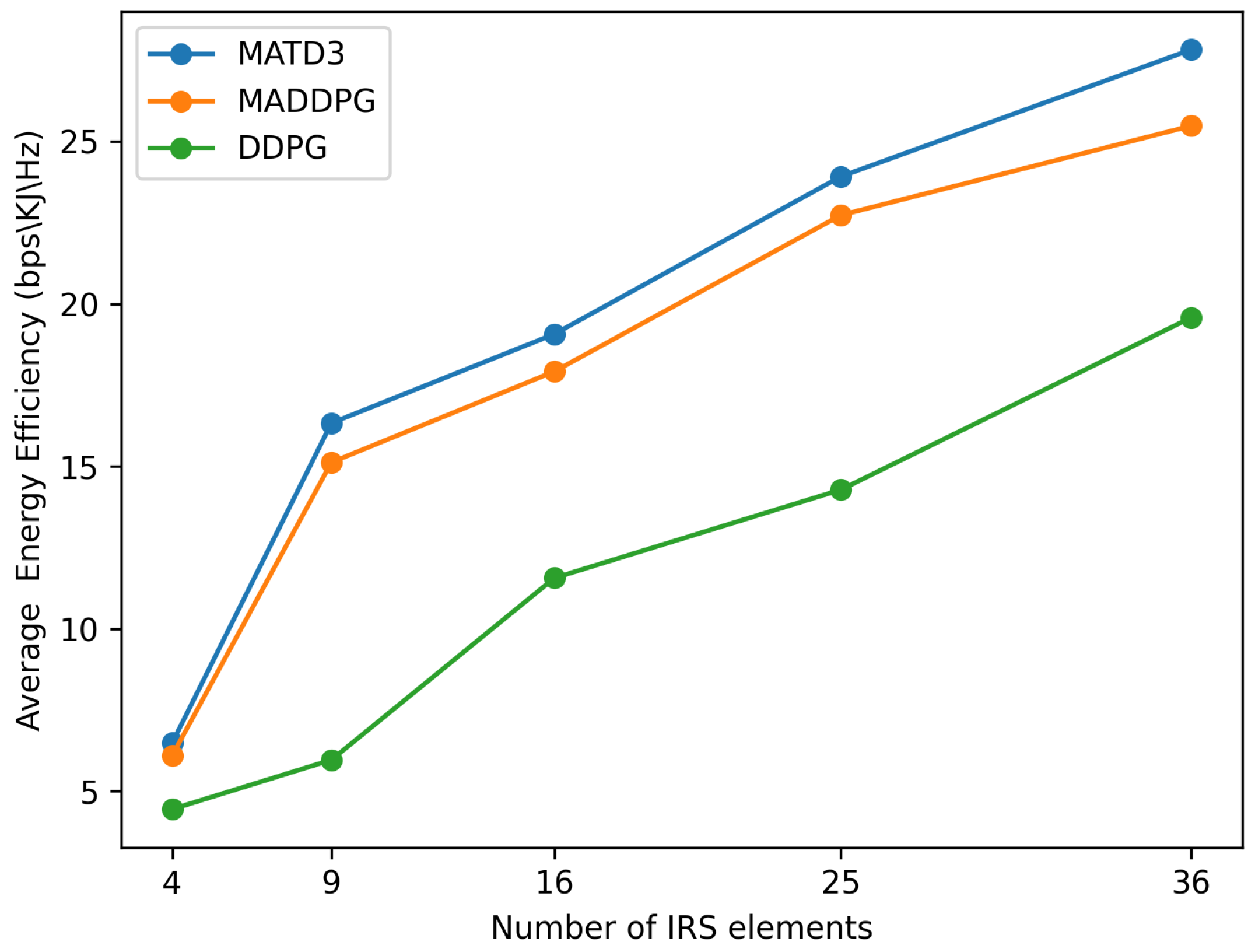
Furthermore,
Figure 6 illustrates the correlation between the number of elements (
M) in the IRS and the average EE. It can be observed that increasing
M can enhance the system EE when it is small; however, the EE performance gain becomes smaller and smaller when
M is very large. This is due to the increased dimensionality of the action space, which requires more time for the algorithm to achieve convergence. In the comparison, it is evident that the proposed MATD3-based approach obtains a higher EE than the other two benchmarks in the case of more IRS elements.
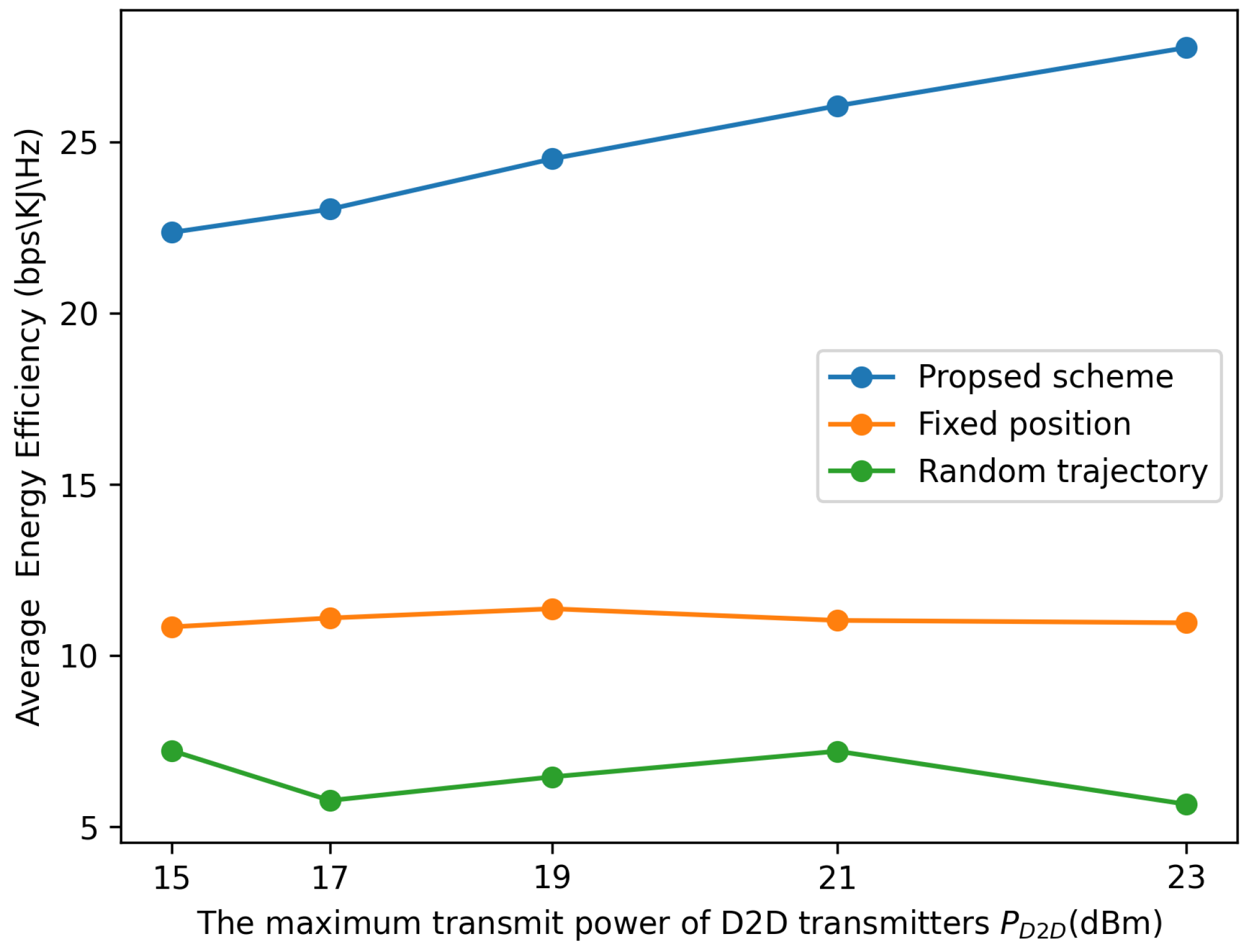
Figure 7 illustrates the relationship between the system’s average EE and the maximum transmit power constraint,
, under various schemes. Specifically, in the fixed position method, without optimizing the movement, the UAV is fixed at a fixed location and during the entire time period. In the random trajectory method, without optimizing the trajectory, the UAV moves randomly. The average EE of the proposed scheme gradually improves with an increase in the maximum transmit power budget,
, as illustrated in
Figure 7. This improvement can be attributed to the increase in the system sum rate achieved by allocating more transmit power. It can also observed that the random trajectory scheme and fixed position scheme cannot gain improvement by increasing the transmit power. Furthermore, the figure demonstrates that, by deploying the IRS in a flexible manner, the performance of the system EE can be greatly enhanced.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}