
An Exploratory Study on a Reinforcement Learning Prototype for Multimodal Image Retrieval Using a Conversational Search Interface


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Motivation
- Rule-based systems, which are inflexible and prone to error, and users must learn how to use them [5].
Research Question
- Exploratory Research Question: “How can reinforcement learning be used for improving the search experience of the user?”
- Comparative Research Question: “Are multiple interactive usability metrics associated, and do they follow a consistent pattern based on user reactions when using the multimodal interface?”
2. Literature Review
2.1. Search Interface
2.2. Conversational Search
2.3. Image Search
2.4. Conversational Search Interface
2.5. Conversational Search Evaluation
3. Prototype Multi-View Interface for Conversational Image Search
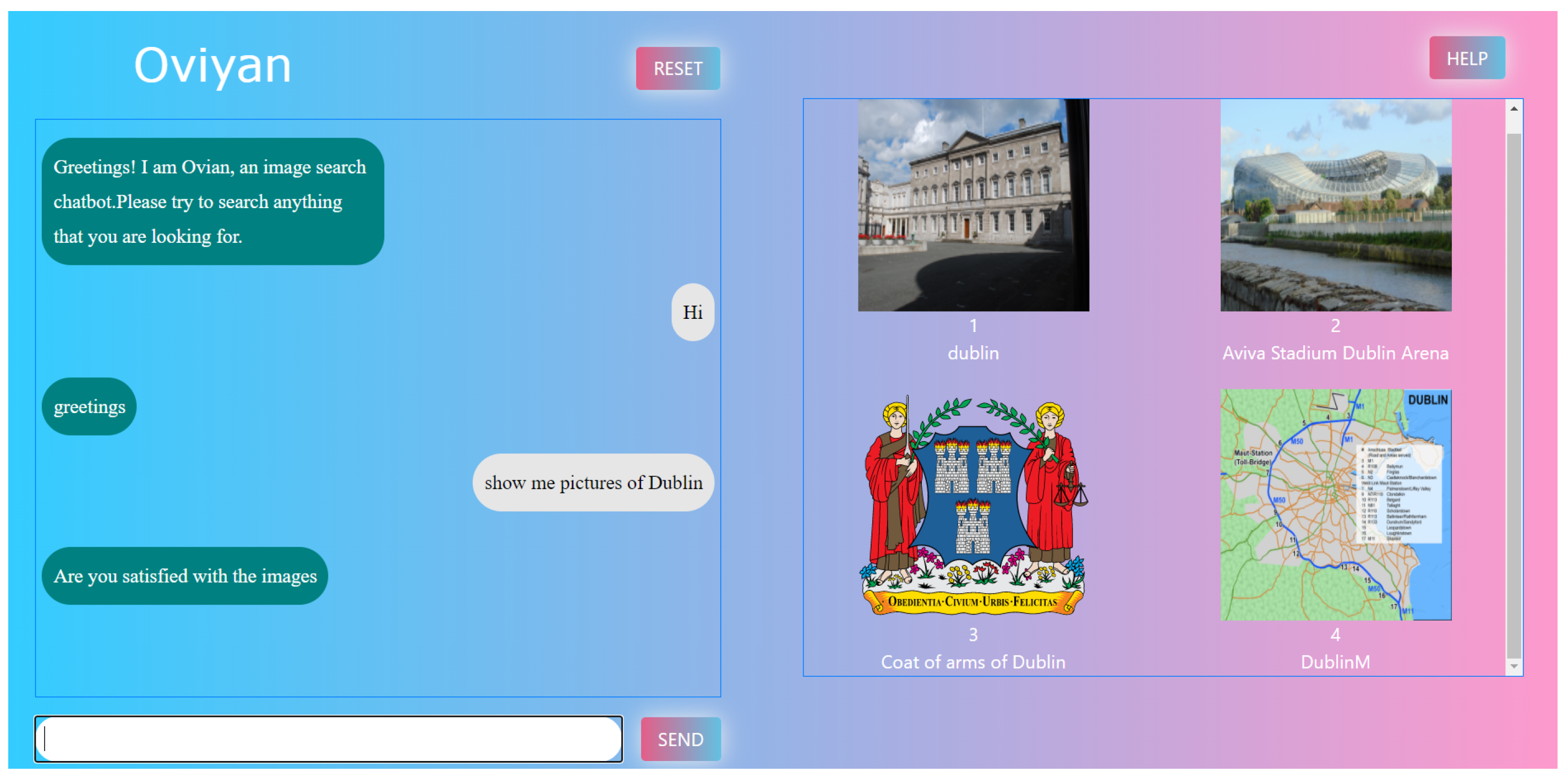
- Chat Display—Shows the conversational dialogue between the agent and the user. This is the place which shows the text that went to and fro between the user and the agent.
- Chat Box—The user enters the input text here. The text provided here is used by the agent to provide the results.
- Image/Video Box—This is the place where the retrieved images and videos are displayed. The agent shows four images and videos each time and the numbering of the images is also provided inside this box.
- Send Button—This button can be used either by pressing the enter button or by a mouse click. This is how the user provides the input text to the agent.
- Query Expansion: Query expansion was carried out by asking the user to select more than one image from the resultant image. The labels of the selected images are retrieved and provided as input to the entity extraction module, and the Wikipedia search API and image results were provided to the user.
- User Feedback: User feedback is carried out by the chatbot where the agent asks the user whether he is happy with the results provided. If the user enters no, he is provided with more similar results. If the user enters yes, he is provided with an option to do query expansion.
3.1. System Implementation
- Web interface: The web interface has been developed using Flask, an extensible web micro framework for building web applications with Python, HTML, CSS, and Bootstrap.
- Logical System: The logical system is responsible for the conversation and the image search management. The keyword from the input message is extracted and given as input to the Wikipedia API for searching images.
- Operations: The conversation accepts the following commands from the user.
- -
- Any text with the entity or keyword about which the user needs pictures.
- -
- Yes/No—This response is accepted by the bot from the user as a feedback on the image if it is relevant.
- -
- 1,2,3,4—the number of the image that is relevant to the one the user is looking for. This helps the search agent to come up with better images based on the user preference.
- -
- Get video—This message is received by the bot and four videos are displayed to the end user using the YouTube API.
- -
- End—This message is acknowledged by the chat bot that the user is satisfied with this input and looking to proceed for next topic.
3.2. Dialogue Strategy and Taxonomy
- Phase 1: In this initial phase, the chat-bot will try to greet the user and ascertain the query request using causal conversation.
- Phase 2: This phase begins when the user starts asking questions to the chatbot. The chatbot attempts to collect feedback from the user about the provided image results. If the user is not satisfied with the image, then the chatbot will try to show a more appropriate image.
- Phase 3: This phase begins at the end of phase 2, wherein the chatbot tries to end the conversation by asking the user to reply ’End’ to stop the loop and proceed to the next query.
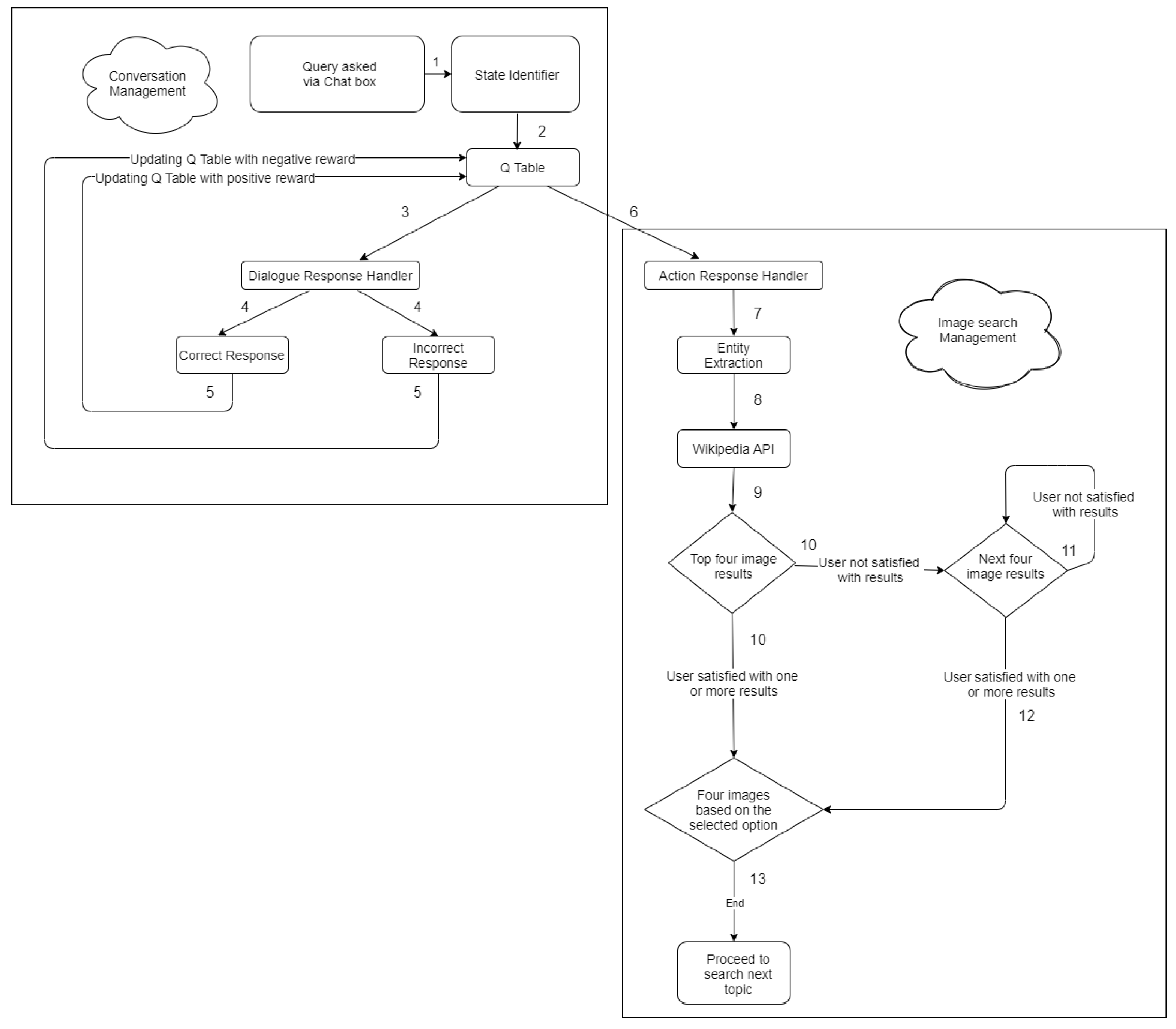
3.3. System Workflow
3.3.1. Conversation Management
3.3.2. Image Search Management
- The Gensim library is used to remove the stop-words from the input string.
- The Spacy library uses the en_core_web_sm model to extract the nouns as keywords from the input string.
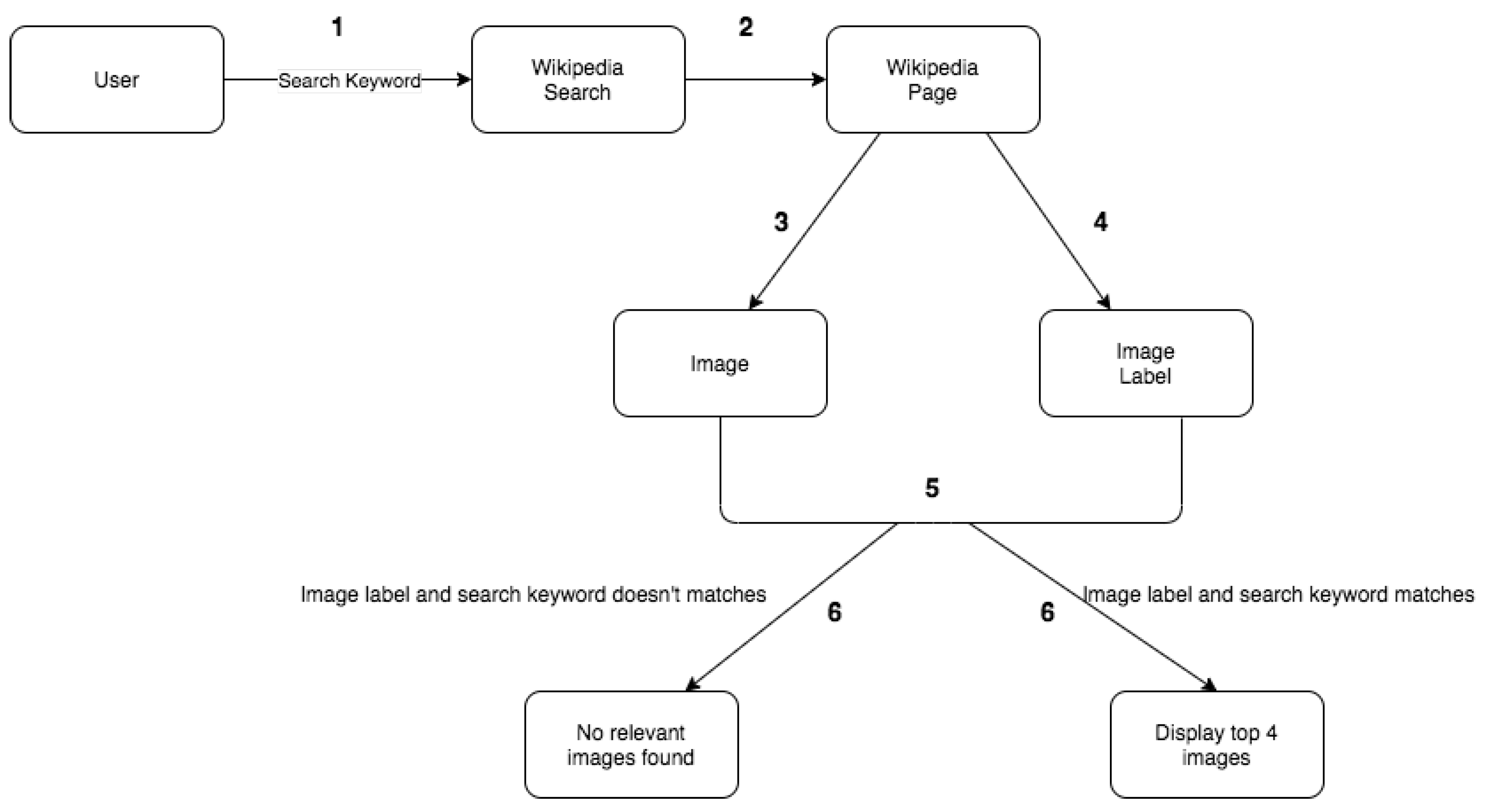
- Image search algorithm:Our prototype conversational agent adopts a logic-based system to filter out images from the collection of images provided through the Wikipedia API. From the user input, the search keyword is extracted and used as input to the Wikipedia search API, which retrieves all the Wikipedia page titles based on the search keyword. These titles are then used as input to retrieve relevant Wikipedia pages. Then the images from these pages are extracted along with their labels and compared with the search keyword. If it matches, then the first twenty images are used for display purpose to the user. The entire flow has been shown graphically in Figure 3. We have taken care of all the exceptions that might occur during the search process. The algorithmic flow of the image search logic is as shown in Algorithm 1.
- User navigation:To make the experience for the user to be more lively, both the conversation tab and the image search tab work together seamlessly. Whenever the user interacts with the chatbot through the conversation tab, he/she will be able to view the image results immediately on the image search tab, which makes it convenient for the user to adapt to the working of the chatbot. The numbering of the images greatly helps the user to specify the images which they are more interested in. To incorporate this methodology, the query expansion concept has been applied on the images fetched from the Wikipedia API.
- User Relevance Feedback:In the study, it was evident that sometimes the user is not able to find the most appropriate image on the first search. Hence, to help them in finding the image of interest, we have implemented the feedback mechanism, wherein the chatbot will record the number of the image that is of interest to the user, and once again search the images based on the new keyword from the image selected by the user.
| Algorithm 1. Image search. |
|
4. Reinforcement Learning Modelling
- State: In the conversational environment created, the state can be described as the possible replies that the user can provide during a conversation. The “Ovian” environment contains five states. They are:
- -
- Greeting;
- -
- Question;
- -
- Affirmative response;
- -
- Video query;
- -
- Negation,1,2,3,4;
- -
- End.
- Actions: In the conversational environment created, the action can be described as the possible replies that the agent can provide during a conversation. The “Ovian” environment contains five Actions. They are:
- -
- Greeting.
- -
- Are you satisfied with the images?
- -
- If you want more specific search results, enter the image number/numbers? Reply with “end” to complete this search.
- -
- Sorry, I am unable to find anything relevant to this topic. Please try any other topic.
- -
- Thank you for your insight. Please continue with your search.
- Rewards: Reward functions define how the conversational agent ought to behave. In other words, they have the regulating content, stipulating what you want the agent to accomplish. In general, a positive reward is provided to encourage certain agent actions, and a negative reward to discourage other actions. A well-designed reward function leads the agent to maximize the expectation of the long-term reward. In any environment, both continuous or discrete reward values can be provided. In this prototype, if the agent behaves as per the expectation, then a positive reward of 10 is provided, and if the agent behaves not as expected, then a negative reward of 10 is provided. The rewards were provided based on the expectation of the way the conversation agent should work. For example, if the user greets the agent, the expectation of the agent is to greet the user back. If the expectation is satisfied, then the reward +10 is granted and if the expectation is not satisfied then the reward −10 is granted.
- Q-table: Q-Table is just a fancy name for a simple lookup table where we determine the maximum anticipated future rewards for action at each state. Each Q-table score will be the maximum expected future reward that the agent will earn if it takes that action at that state. The rewards collected in each step are accumulated and it is used to enrich the Q-table during the training or the learning phase. When the learning phase is completed, the reinforcement model uses the enriched table to choose the action for that state.
4.1. Training Phase
4.1.1. Open-AI Gym
4.1.2. Implementation Phase
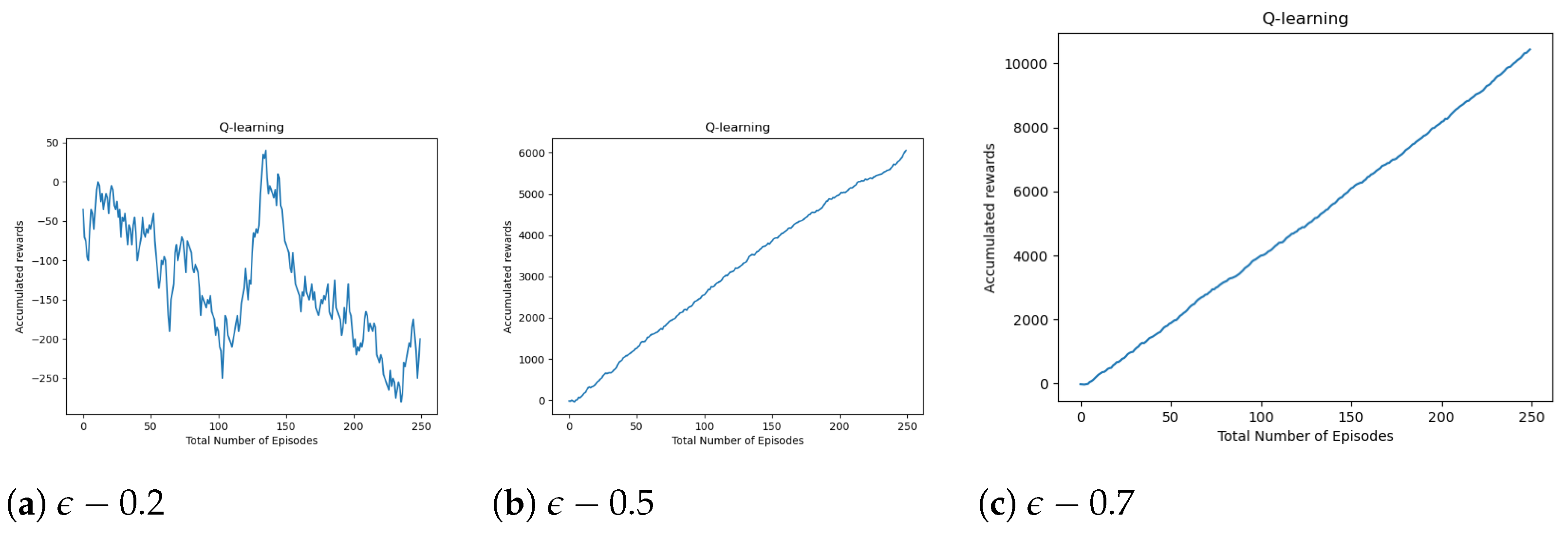
4.1.3. Empirical Model Evaluation
5. Experimental Procedure and User Evaluation
5.1. Questionnaire
- Basic Demography Survey: Subjects entered their assigned user ID, age, occupation, task ID to be undertaken.
- Post-Search Usability Survey: Post-search feedback from the user including three metrics: SUS, CUQ, and UEQ.
5.1.1. Chatbot Usability Questionnaire
5.1.2. System Usability Scale
5.2. User Experience Questionnaire
6. Results and Analysis
6.1. Findings
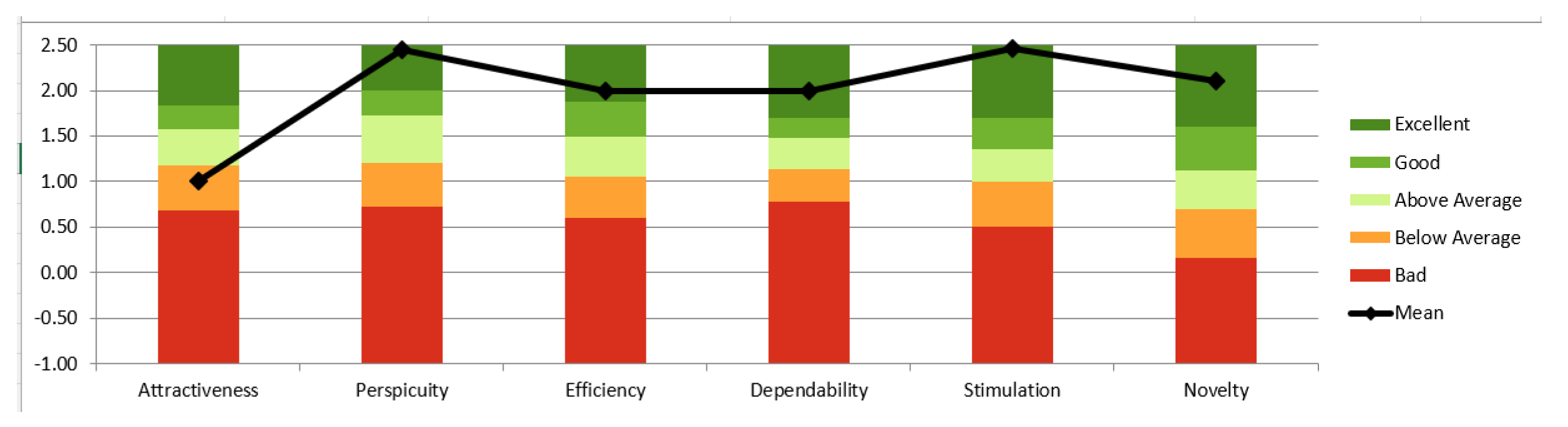
- How can reinforcement learning be used for improving the search experience of the user?In this study, we used the basic model of reinforcement learning using Q-learning algorithm. We evaluated the model empirically during training and quantitatively through user evaluation during testing. The scores obtained on all three metrics (SUS, CUQ, and UEQ) by testing the trained interface have outperformed the baseline scores discussed in the section. The score indicated the potential of reinforcement techniques on the conversational search concepts. Based on the score obtained by the user study and observing the positive high correlation (as shown in the scatter plot) among the metrics, we can infer that Q-learning technique in a conversational setting could be a potential approach in complex information-seeking tasks.
- Are multiple interactive usability metrics associated, and do they follow a consistent pattern based on user reactions when using the multimodal interface?Based on the input supplied by users after using the search interface, this graph (Figure 8) depicts the similarity of the responses mentioned by users. This confirms that consumers have comparable experiences after interacting with the UI. As seen in Figure 8, all of the responses are significantly connected and highly related. After analysing the scores of different metrics, it was possible to infer that users had a very pleasant experience when looking for information, and the hybrid approach proved beneficial with the picture retrieval system. This suggests an intriguing conclusion for further investigation. This interface might be further tested based on the user’s cognitive load and knowledge expansion while using this interface for searching.
6.2. Learnings
- Possibility of using a Reinforcement learning for the incremental search processThis knowledge is derived from our examination of RQ1. As observed from the metrics evaluation score, the users who used this system have reported better interactive and usability experiences while seeking information on the cognitive complex task. Searching for images to satisfy the information need has enhanced the difficulty of the task by limiting the information mode and space. Users can only satisfy their information requirements by solely relying on the images provided by the search interface. Including all these challenges, the users’ observations were positive and this directed to the potential of using a Q-learning-based reward system in the process of search, which can capture the user’s search behaviour.
- Combination of Images and VideosThis understanding stems from our consideration of RQ1 and RQ2. As mentioned earlier, this interface is restricted to image search and video search to satisfy user’s information needs. Based on the user evaluation, they find it rather interesting to fulfil their needs from the video and images without reading through long documents. Satisfying information needs through long documents can increase the cognitive load while accessing too much information. Image search could be used to reduce the cognitive load during the search, which needs to be further investigated. Based on the feedback in this investigation, the initial results have pointed in the same directions.
- Conversational Search Problems and its Potential SolutionsThis comprehension arises from our examination of RQ1 and RQ2. The common problem faced by researchers who are working in the area of conversational search is the lack of availability of a data set that can completely capture the user’s search behaviour. Creating a similar dataset is very expensive in terms of effort and time. Another challenge is dealing with high language models, which can capture contextual meaning, but not the patterns of user behaviour. The study conducted by Kaushik et al. [1,2] clearly indicated the factors considered during conversational search, which in general are missing in the heavy language models. In contrast, the approach mentioned in this paper is not completely dependent on heavy language models or huge data sets, but rather provides unique and novel solutions to capture user behaviour using reinforcement learning techniques. This could also encourage researchers to think about the concept of Explainability when dealing with conversational search bots.
7. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kaushik, A. Dialogue-Based Information Retrieval. European Conference on Information Retrieval; Springer: Berlin, Germany, 2019; pp. 364–368. [Google Scholar]
- Kaushik, A.; Jones, G.J. A Conceptual Framework for Implicit Evaluation of Conversational Search Interfaces. Mixed-Initiative ConveRsatiOnal Systems workshop at ECIR 2021. arXiv 2021, arXiv:2104.03940. [Google Scholar]
- Radlinski, F.; Craswell, N. A theoretical framework for conversational search. In Proceedings of the 2017 Conference on Conference Human Information Interaction and Retrieval, Oslo, Norway, 7–11 March 2017; ACM: New York, NY, USA, 2017; pp. 117–126. [Google Scholar]
- Kaushik, A.; Jones, G.J.F. Exploring Current User Web Search Behaviours in Analysis Tasks to be Supported in Conversational Search. In Proceedings of the Second International Workshop on Conversational Approaches to Information Retrieval (CAIR’18), Ann Arbor, MI, USA, 8–12 July 2018; Volume 16, pp. 453–456. [Google Scholar]
- Kaushik, A.; Bhat Ramachandra, V.; Jones, G.J.F. An Interface for Agent Supported Conversational Search. In Proceedings of the 2020 Conference on Human Information Interaction and Retrieval, Vancouver, BC, Canada, 14–18 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 452–456. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Chu, W.W. Knowledge-based query expansion to support scenario-specific retrieval of medical free text. Inf. Retr. 2007, 10, 173–202. [Google Scholar] [CrossRef] [Green Version]
- Brandtzaeg, P.B.; Følstad, A. Chatbots: User changing needs and motivations. Interactions 2018, 25, 38–43. [Google Scholar] [CrossRef] [Green Version]
- Arora, P.; Kaushik, A.; Jones, G.J.F. DCU at the TREC 2019 Conversational Assistance Track. In Proceedings of the Twenty-Eighth Text REtrieval Conference, Gaithersburg, MD, USA, 13–15 November 2019; Voorhees, E.M., Ellis, A., Eds.; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2019; Volume 1250. [Google Scholar]
- Kaushik, A.; Loir, N.; Jones, G.J. Multi-View Conversational Search Interface Using a Dialogue-Based Agent; Springer International Publishing: Cham, Switzerland, 2021. [Google Scholar]
- Kaushik, A. Examining the Potential for Enhancing User Experience in Exploratory Search using Conversational Agent Support. Ph.D. Thesis, Dublin City University, Dublin, Ireland, 2021. [Google Scholar]
- Sharma, M.; Kaushik, A.; Kumar, R.; Rai, S.K.; Desai, H.H.; Yadav, S. Communication is the universal solvent: Atreya bot—An interactive bot for chemical scientists. arXiv 2021, arXiv:2106.07257. [Google Scholar] [CrossRef]
- Dalton, J.; Xiong, C.; Callan, J. CAsT 2019: The Conversational Assistance Track overview. In Proceedings of the Twenty-Eighth Text REtrieval Conference, TREC, Gaithersburg, MD, USA, 13–15 November 2019; pp. 13–15. [Google Scholar]
- Dalton, J.; Xiong, C.; Callan, J. TREC CAsT 2019: The Conversational Assistance Track Overview. arXiv 2020, arXiv:2003.13624. [Google Scholar]
- Sunayama, W.; Osawa, Y.; Yachida, M. Search interface for query restructuring with discovering user interest. In Proceedings of the International Conference on Knowledge-Based Intelligent Electronic Systems, Proceedings, KES, Adelaide, SA, Australia, 31 August–1 September 1999; pp. 538–541. [Google Scholar]
- Sandhu, A.K.; Liu, T. Wikipedia search engine: Interactive information retrieval interface design. In Proceedings of the 2014 3rd International Conference on User Science and Engineering: Experience, Engineer, Engage, i-USEr 2014, Shah Alam, Malaysia, 2–5 September 2015; pp. 18–23. [Google Scholar]
- Negi, S.; Joseph, S.; Alemao, C.; Joseph, V. Intuitive User Interface for Enhanced Search Experience. In Proceedings of the 2020 3rd International Conference on Communication Systems, Computing and IT Applications, Mumbai, India, 3–4 April 2020; pp. 115–119. [Google Scholar]
- Hearst, M.; Tory, M. Would You Like A Chart with That? Incorporating Visualizations into Conversational Interfaces. In Proceedings of the 2019 IEEE Visualization Conference, Vancouver, BC, Canada, 20–25 October 2019; pp. 36–40. [Google Scholar]
- Bai, T.; Ge, Y.; Guo, S.; Zhang, Z.; Gong, L. Enhanced Natural Language Interface for Web-Based Information Retrieval. IEEE Access 2020, 9, 4233–4241. [Google Scholar] [CrossRef]
- Schneider, D.; Stohr, D.; Tingvold, J.; Amundsen, A.B.; Weil, L.; Kopf, S.; Effelsberg, W.; Scherp, A. Fulgeo-towards an intuitive user interface for a semantics-enabled multimedia search engine. In Proceedings of the 2014 IEEE International Conference on Semantic Computing, Newport Beach, CA, USA, 16–18 June 2014; pp. 254–255. [Google Scholar]
- Uribe, S.; Álvarez, F.; Menéndez, J.M. Personalized adaptive media interfaces for multimedia search. In Proceedings of the 2011 International Conference on Computational Aspects of Social Networks, Salamanca, Spain, 19–21 October 2011; pp. 195–200. [Google Scholar]
- Shuoming, L.; Lan, Y. A study of meta search interface for retrieving disaster related emergencies. In Proceedings of the 9th International Conference on Computational Intelligence and Security, Emeishan, China, 14–15 December 2013; pp. 640–643. [Google Scholar]
- Kanapala, A.; Pal, S.; Pamula, R. Design of a meta search system for legal domain. In Proceedings of the 2017 4th International Conference on Advanced Computing and Communication Systems, Coimbatore, India, 6–7 January 2017; pp. 1–5. [Google Scholar]
- Dey, S.; Abraham, S. Personalised and domain specific user interface for a search engine. In Proceedings of the 2010 International Conference on Computer Information Systems and Industrial Management Applications, Krakow, Poland, 8–10 October 2010; pp. 524–529. [Google Scholar]
- Heck, L.; Hakkani-Tür, D.; Chinthakunta, M.; Tur, G.; Iyer, R.; Parthasacarthy, P.; Stifelman, L.; Shriberg, E.; Fidler, A. Multi-Modal Conversational Search and Browse. In Proceedings of the First Workshop on Speech, Language and Audio in Multimedia, Marseille, France, 22–23 August 2013; pp. 6–20. [Google Scholar]
- Fergencs, T.; Meier, F. Engagement and Usability of Conversational Search—A Study of a Medical Resource Center Chatbot. In International Conference on Information; Springer: Cham, Switzerland, 2021; pp. 1–8. [Google Scholar]
- Fernes, S.; Gawas, R.; Alvares, P.; Femandes, M.; Kale, D.; Aswale, S. Survey on Various Conversational Systems. In Proceedings of the International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–8. [Google Scholar]
- Anand, A.; Cavedon, L.; Joho, H.; Sanderson, M.; Stein, B. Conversational Search (Dagstuhl Seminar 19461). Dagstuhl Rep. 2020, 9, 34–83. [Google Scholar] [CrossRef]
- Grycuk, R.; Scherer, R. Software Framework for Fast Image Retrieval. In Proceedings of the International Conference on Methods and Models in Automation and Robotics(MMAR), Miedzyzdroje, Poland, 26–29 August 2019; pp. 588–593. [Google Scholar]
- Pawaskar, S.K.; Chaudhari, S.B. Web image search engine using semantic of Images’s meaning for achieving accuracy. In Proceedings of the International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT), Pune, India, 9–10 September 2016; pp. 99–103. [Google Scholar]
- Munjal, M.N.; Bhatia, S. A Novel Technique for Effective Image Gallery Search using Content Based Image Retrieval System. In Proceedings of the International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 25–29. [Google Scholar]
- Nakayama, K.; Nakayama, K.; Pei, M.; Erdmann, M.; Ito, M.; Shirakawa, M.; Hara, T.; Nishio, S. Wikipedia as a Corpus for Knowledge Extraction. Wikipedia Min. 2018, 1–8. [Google Scholar]
- Lerman, K.P.A.; Wong, C. Personalizing Image Search Results on Flickr. AAAI07 Workshop Intell. Inf. Pers. 2007, 12. [Google Scholar]
- Xu, W.; Zhang, Y.; Lu, J.; Li, R.; Xie, Z. A Framework of Web Image Search Engine. In Proceedings of the 2009 International Joint Conference on Artificial Intelligence, Hainan, China, 25–26 April 2009; pp. 522–525. [Google Scholar]
- Smelyakov, K.; Sandrkin, D.; Ruban, I.; Vitalii, M.; Romanenkov, Y. Search by Image. New Search Engine Service Model. In Proceedings of the International Scientific-Practical Conference Problems of Infocommunications, Science and Technology (PIC S T), Kharkiv, Ukraine, 9–12 October 2018; pp. 181–186. [Google Scholar]
- Kia, O.M.; Neshati, M.; Alamdari, M.S. Open-Domain question classification and completion in conversational information search. In Proceedings of the International Conference on Information and Knowledge Technology (IKT), Tehran, Iran, 22–23 December 2020; pp. 98–101. [Google Scholar]
- Bellini, V.; Biancofiore, G.M.; Di Noia, T.; Di Sciascio, E.; Narducci, F.; Pomo, C. GUapp: A Conversational Agent for Job Recommendation for the Italian Public Administration. In Proceedings of the IEEE Conference on Evolving and Adaptive Intelligent Systems (EAIS), Bari, Italy, 27–29 May 2020; pp. 1–7. [Google Scholar]
- Lauren, P.; Watta, P. A Conversational User Interface for Stock Analysis. In Proceedings of the IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5298–5305. [Google Scholar]
- McTear, M.F. The Rise of the Conversational Interface: A New Kid on the Block? Future and Emerging Trends in Language Technology. In Proceedings of the International Workshop on Future and Emerging Trends in Language Technology, Seville, Spain, 30 November–2 December 2016; pp. 38–49. [Google Scholar]
- Atiyah, A.; Jusoh, S.; Alghanim, F. Evaluation of the Naturalness of Chatbot Applications. In Proceedings of the Third International Workshop on Conversational Approaches to Information Retrieval (2020), Amman, Jordan, 9–11 April 2019; p. 7. [Google Scholar]
- Balog, K.; Flekova, L.; Hagen, M.; Jones, R.; Potthast, M.; Radlinski, F.; Sanderson, M.; Vakulenko, S.; Zamani, H. Common Conversational Community Prototype: Scholarly Conversational Assistant. Informaion retrieval. arXiv 2020, arXiv:2001.06910. [Google Scholar]
- Forkan, A.R.M.; Jayaraman, P.P.; Kang, Y.B.; Morshed, A. ECHO: A Tool for Empirical Evaluation Cloud Chatbots. In Proceedings of the 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing, Melbourne, VIC, Australia, 11–14 May 2020; pp. 669–672. [Google Scholar]
- Atiyah, A.; Jusoh, S.; Alghanim, F. Evaluation of the Naturalness of Chatbot Applications. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology, Amman, Jordan, 9–11 April 2019; pp. 359–365. [Google Scholar]
- Hidayatin, L.; Rahutomo, F. Query Expansion Evaluation for Chatbot Application. In Proceedings of the ICAITI 2018—1st International Conference on Applied Information Technology and Innovation: Toward A New Paradigm for the Design of Assistive Technology in Smart Home Care, Padang, Indonesia, 3–5 September 2018; pp. 92–95. [Google Scholar]
- SUS: A Quick and Dirty Usability Scale. Available online: https://www.researchgate.net/publication/228593520_SUS_A_quick_and_dirty_usability_scale (accessed on 5 August 2021).
- Holmes, S.; Moorhead, A.; Bond, R.; Zheng, H.; Coates, V.; McTear, M. Usability testing of a healthcare chatbot: Can we use conventional methods to assess conversational user interfaces. In Proceedings of the 31st European Conference on Cognitive Ergonomics: “Design for Cognition”, Belfast, UK, 10–13 September 2019; pp. 207–214. [Google Scholar]
- Abd-Alrazaq, A.; Safi, Z.; Alajlani, M.; Warren, J.; Househ, M.; Denecke, K. Technical Metrics Used to Evaluate Health Care Chatbots: Scoping Review. J. Med. Internet Res. 2020, 22, 1–10. [Google Scholar] [CrossRef]
- Kocabalil, A.B.; Laranjo, L.; Coiera, E. Measuring user experience in conversational interfaces: A comparison of six questionnaires. In Proceedings of the 32nd International BCS Human Computer Interaction Conference, Belfast, UK, 2–6 July 2018. [Google Scholar]
- Sensuse, D.I.; Dhevanty, V.; Rahmanasari, E.; Permatasari, D.; Putra, B.E.; Lusa, J.S.; Misbah, M.; Prima, P. Chatbot Evaluation as Knowledge Application: A Case Study of PT ABC. In Proceedings of the 2019 11th International Conference on Information Technology and Electrical Engineering, Pattaya, Thailand, 10–11 October 2019. [Google Scholar]
- Denecke, K.; Vaaheesan, S.; Arulnathan, A. A Mental Health Chatbot for Regulating Emotions (SERMO)—Concept and Usability Test. IEEE Trans. Emerg. Top. Comput. 2020, 9, 1170–1182. [Google Scholar] [CrossRef]
- Supriyanto, A.P.; Saputro, T.S. Keystroke-level model to evaluate chatbot interface for reservation system. In Proceedings of the International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Bandung, Indonesia, 18–20 September 2019; pp. 241–246. [Google Scholar]
- Bailey, P.; Moffat, A.; Scholer, F.; Thomas, P. UQV100: A Test Collection with Query Variability. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; ACM: New York, NY, USA, 2016; pp. 725–728. [Google Scholar] [CrossRef]
- Krathwohl, D.R. A revision of Bloom’s taxonomy: An overview. Theory Into Pract. 2002, 41, 212–218. [Google Scholar] [CrossRef]
- Grant, D.A. The latin square principle in the design and analysis of psychological experiments. Psychol. Bull. 1948, 45, 427. [Google Scholar] [CrossRef] [PubMed]
- Hoy, M.B. Alexa, Siri, Cortana, and More: An Introduction to Voice Assistants. Med. Ref. Serv. Q. 2018, 37, 81–88. [Google Scholar] [CrossRef] [PubMed]
- Trippas, J.R.; Spina, D.; Cavedon, L.; Joho, H.; Sanderson, M. Informing the Design of Spoken Conversational Search: Perspective Paper. In Proceedings of the 2018 Conference on Human Information Interaction & Retrieval, New Brunswick, NJ, USA, 11–15 March 2018; ACM: New York, NY, USA, 2018; pp. 32–41. [Google Scholar] [CrossRef]
- Trippas, J.R.; Spina, D.; Cavedon, L.; Sanderson, M. How Do People Interact in Conversational Speech-Only Search Tasks: A Preliminary Analysis. In Proceedings of the 2017 Conference on Conference Human Information Interaction and Retrieval, Oslo, Norway, 7–11 March 2017; ACM: New York, NY, USA, 2017; pp. 325–328. [Google Scholar] [CrossRef]
- Ghosh, D.; Foong, P.S.; Zhang, S.; Zhao, S. Assessing the Utility of the System Usability Scale for Evaluating Voice-based User Interfaces. In Proceedings of the Sixth International Symposium of Chinese CHI, Montreal, QC, Canada, 21–22 April 2018; ACM: New York, NY, USA, 2018; pp. 11–15. [Google Scholar] [CrossRef]
- Avula, S.; Chadwick, G.; Arguello, J.; Capra, R. SearchBots: User Engagement with ChatBots during Collaborative Search. In Proceedings of the 2018 Conference on Human Information Interaction&Retrieval, New Brunswick, NJ, USA, 11–15 March 2018; ACM: New York, NY, USA, 2018; pp. 52–61. [Google Scholar]
- Avula, S. Wizard of Oz: Protocols and Challenges in Studying Searchbots to Support Collaborative Search. In Proceedings of the SIGIR 2nd International Workshop on Conversational Approaches to Information Retrieval, Ann Arbor, MI, USA, 12 July 2018; pp. 111–116. [Google Scholar]
- Kaushik, A.; Bhat Ramachandra, V.; Jones, G.J.F. DCU at the FIRE 2020 Retrieval from Conversational Dialogues (RCD) task. In Proceedings of the FIRE 2020 Proceeding, Hyderabad, India, 16–20 December 2019. [Google Scholar]
- Avula, S.; Arguello, J.; Capra, R.; Dodson, J.; Huang, Y.; Radlinski, F. Embedding Search into a Conversational Platform to Support Collaborative Search. In Proceedings of the 2019 Conference on Human Information Interaction and Retrieval, Glasgow, UK, 10–14 March 2019; pp. 15–23. [Google Scholar]
- Trippas, J.R.; Spina, D.; Cavedon, L.; Sanderson, M. Crowdsourcing User Preferences and query Judgments for Speech-Only Search. In Proceedings of the 1st SIGIR Workshop on Conversational Approaches to Information Retrieval, Tokyo, Japan, 7–11 August 2017. [Google Scholar]
- Kiesel, J.; Bahrami, A.; Stein, B.; Anand, A.; Hagen, M. Toward Voice Query Clarification. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1257–1260. [Google Scholar] [CrossRef]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaushik, A.; Jacob, B.; Velavan, P. An Exploratory Study on a Reinforcement Learning Prototype for Multimodal Image Retrieval Using a Conversational Search Interface. Knowledge 2022, 2, 116-138. https://0-doi-org.brum.beds.ac.uk/10.3390/knowledge2010007
Kaushik A, Jacob B, Velavan P. An Exploratory Study on a Reinforcement Learning Prototype for Multimodal Image Retrieval Using a Conversational Search Interface. Knowledge. 2022; 2(1):116-138. https://0-doi-org.brum.beds.ac.uk/10.3390/knowledge2010007
Chicago/Turabian StyleKaushik, Abhishek, Billy Jacob, and Pankaj Velavan. 2022. "An Exploratory Study on a Reinforcement Learning Prototype for Multimodal Image Retrieval Using a Conversational Search Interface" Knowledge 2, no. 1: 116-138. https://0-doi-org.brum.beds.ac.uk/10.3390/knowledge2010007