Quasi-Concavity for Gaussian Multicast Relay Channels


1
Independent Researcher, Amalienstr. 49A, 80799 Munich, Germany
2
Institute for Communications Engineering, Technical University of Munich, 80333 Munich, Germany
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(2), 109; https://0-doi-org.brum.beds.ac.uk/10.3390/e21020109
Submission received: 6 January 2019
/
Revised: 21 January 2019
/
Accepted: 22 January 2019
/
Published: 24 January 2019
(This article belongs to the Special Issue Information Theory for Data Communications and Processing)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Standard upper and lower bounds on the capacity of relay channels are cut-set (CS), decode-forward (DF), and quantize-forward (QF) rates. For real additive white Gaussian noise (AWGN) multicast relay channels with one source node and one relay node, these bounds are shown to be quasi-concave in the receiver signal-to-noise ratios and the squared source-relay correlation coefficient. Furthermore, the CS rates are shown to be quasi-concave in the relay position for a fixed correlation coefficient, and the DF rates are shown to be quasi-concave in the relay position. The latter property characterizes the optimal relay position when using DF. The results extend to complex AWGN channels with random phase variations.
1. Introduction
A multicast relay channel (MRC) is an information network with a source node, a relay node, and two or more destination nodes, and where one message originating at the source should be received reliably at the destinations. We consider additive white Gaussian noise (AWGN) MRCs and show that certain information rate expressions are quasi-concave in the receiver signal-to-noise ratios (SNRs), the squared source-relay correlation coefficient, and the relay position. In particular, we study cut-set (CS), decode-forward (DF), and quantize-forward (QF) rates. Quasi-concavity suggests that efficient algorithms can optimize signaling and the relay position. However, the main motivation of this work is not practicality, but simply to provide better understanding of the problem.
Relay positioning has been studied by many authors, with a focus on rate enhancement (e.g., [1,2]), range extension (e.g., [3,4]), and outage probability (e.g., [1,5,6]). We study the problem of placing a relay to maximize the multicast rate by extending results of [7,8,9,10]. A preliminary version of this paper without proofs appeared in [11]. Our focus is on real alphabet channels. However, our main results also apply to complex alphabet channels if there are random phase variations so that beamforming is not useful.
This paper is organized as follows. Section 2 presents the MRC model and reviews the CS, DF, and QF rates. Section 3 develops quasi-concavity results in the squared source-relay correlation coefficient and the channel SNRs. Section 4 introduces a distance dependence for the channel gains and shows that the CS rate is quasi-concave in the relay position when is fixed. We further show that the DF rate is quasi-concave in the relay position. Section 5 illustrates quasi-concavity for one-, two-, and three-dimensional networks, and compares the performance of two DF strategies. Section 6 discusses complex AWGN channels and a sum (source plus relay) power constraint. Section 7 concludes the paper. Appendix A and Appendix B review useful results on concavity and quasi-concavity, and prove a few new results.
2. Model and Information Rates
2.1. Model
An MRC has three types of nodes:
- a source node s that generates a message W and transmits the symbols ;
- a relay node r that receives and forwards symbols and , respectively, for ;
- destination nodes where node j receives and estimates W as .
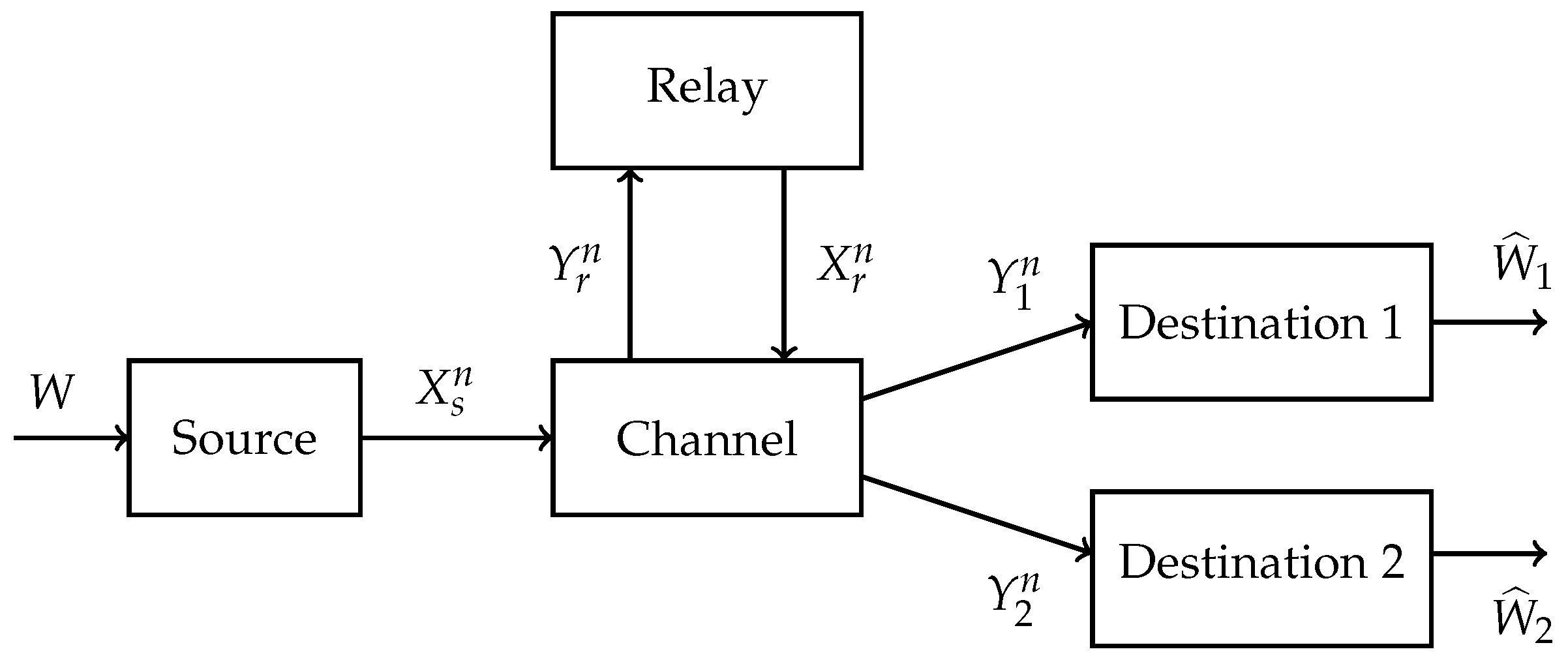
We denote the destination node set as . The classic relay channel has and Figure 1 shows an MRC with .
A memoryless MRC has a function and a noise random variable so that for every time instant the channel outputs are given by
The noise is statistically independent of and , and the noise variables at different times are statistically independent.
An encoding strategy for M messages has
- W uniformly distributed over ;
- an encoding function such that ;
- relay functions with , where ;
- decoding functions such that , .
The error probability at destination j is . The multicast rate is bits/use. The rate R is achievable if, for any and sufficiently large n, there is an encoding strategy with for all . The capacity C is the supremum of the achievable rates.
2.2. Information Rates
The following bounds were given in [12] for the relay channel (). Their extensions to MRCs are straightforward.
- CS Rate: whereand where the maximization is over all .
- Direct-Transmission (DT) Rate: whereand where the maximization is over all and .
- DF Rate: whereand where the maximization is over all .
- QF Rate: wherewhere is an auxiliary random variable, and where the maximization is over all such that and are independent and forms a Markov chain.
2.3. Real Alphabet AWGN MRC
The real alphabet AWGN MRC has real channel symbols and
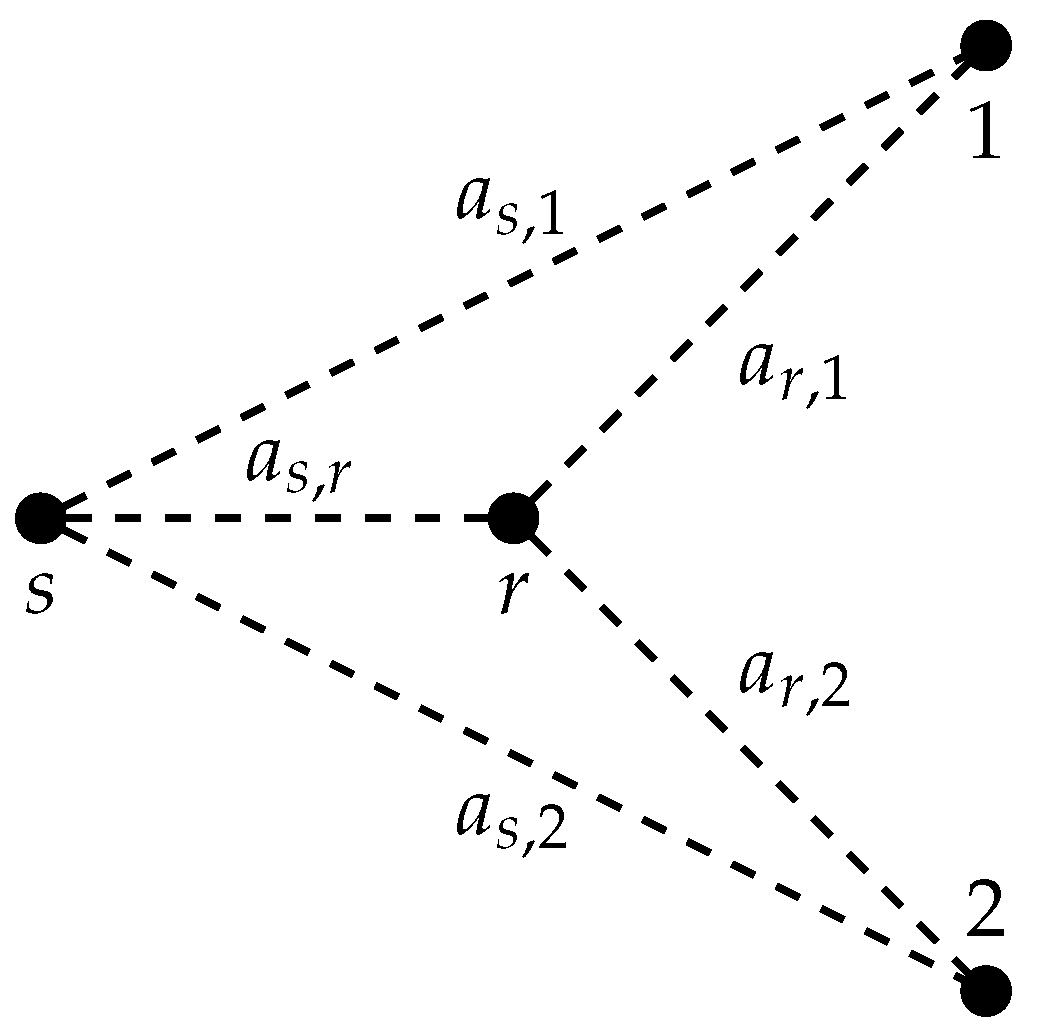
where . The , , and are channel gains between the nodes (see Figure 2). We later relate these gains to distances between the nodes. The and , , are independent and identically distributed Gaussian random variables with zero mean and unit variance. We may alternatively write (5) and (6) in vector form as
where , , , and
We consider individual average block power constraints
The SNR and the capacity of the link from node u (with transmit power ) to node v are the respective
We simplify the above rate bounds for the AWGN MRC.
- CS Rate:where the correlation coefficient satisfies . One can restrict attention to non-negative .
- DT Rate:
- DF Rate:One can again restrict attention to non-negative .
- QF Rate: Optimizing seems difficult. Instead, we choose and to be zero-mean Gaussian with variances and , respectively. We further choose where is zero-mean Gaussian with variance . Optimizing gives (see [13], pp. 336–337)
3. Quasi-Concavity in SNRs and
3.1. CS Rate
We consider two characterizations of . First, let be the second row of , let be the covariance matrix of (see Appendix A), and let be the determinant of the square matrix . The CS rate (12) can be expressed as the maximum of
over the convex set of with diagonal entries and . The first logarithm in (16) is clearly concave in . The second logarithm is concave in (see Appendix A) and is linear in . To prove the latter claim, observe that
where and is the identity matrix. Hence is concave in (the convex set of) because it is the minimum of concave functions.
Suppose next that we wish to consider and the SNRs individually rather than via . Define the vector
and the functions
We establish the following results. We restrict attention to and positive .
Lemma 1.
and are concave in ρ, concave in , and quasi-concave in .
Proof.
Concavity with respect to is established by observing that is linear in , and is linear in which is concave in .
Consider next concavity with respect to . The Hessian of with respect to has only one non-zero eigenvalue
Thus, is concave in for non-negative and positive . The function is linear in , and thus concave in .
Now consider quasi-concavity with respect to . Substituting into the fifth function of Lemma A6 in Appendix B, we find that is quasi-concave in . For the , observe that is quasi-concave for non-negative , see the first function of Lemma A6. This implies (see (A7))
for , and where . Substituting and for , we find that is quasi-concave in . ☐
Theorem 1.
is concave in ρ, concave in , and quasi-concave in .
Proof.
involves taking logarithms and minima of (quasi-) concave functions. The results thus follow by applying Lemma 1 above and Lemma A5, Parts 2 and 3, in Appendix B. ☐
Corollary 1.
Consider as a function of . Then is quasi-concave in .
Proof.
The proof follows from the proof of Theorem 1 and because is a linear function of . ☐
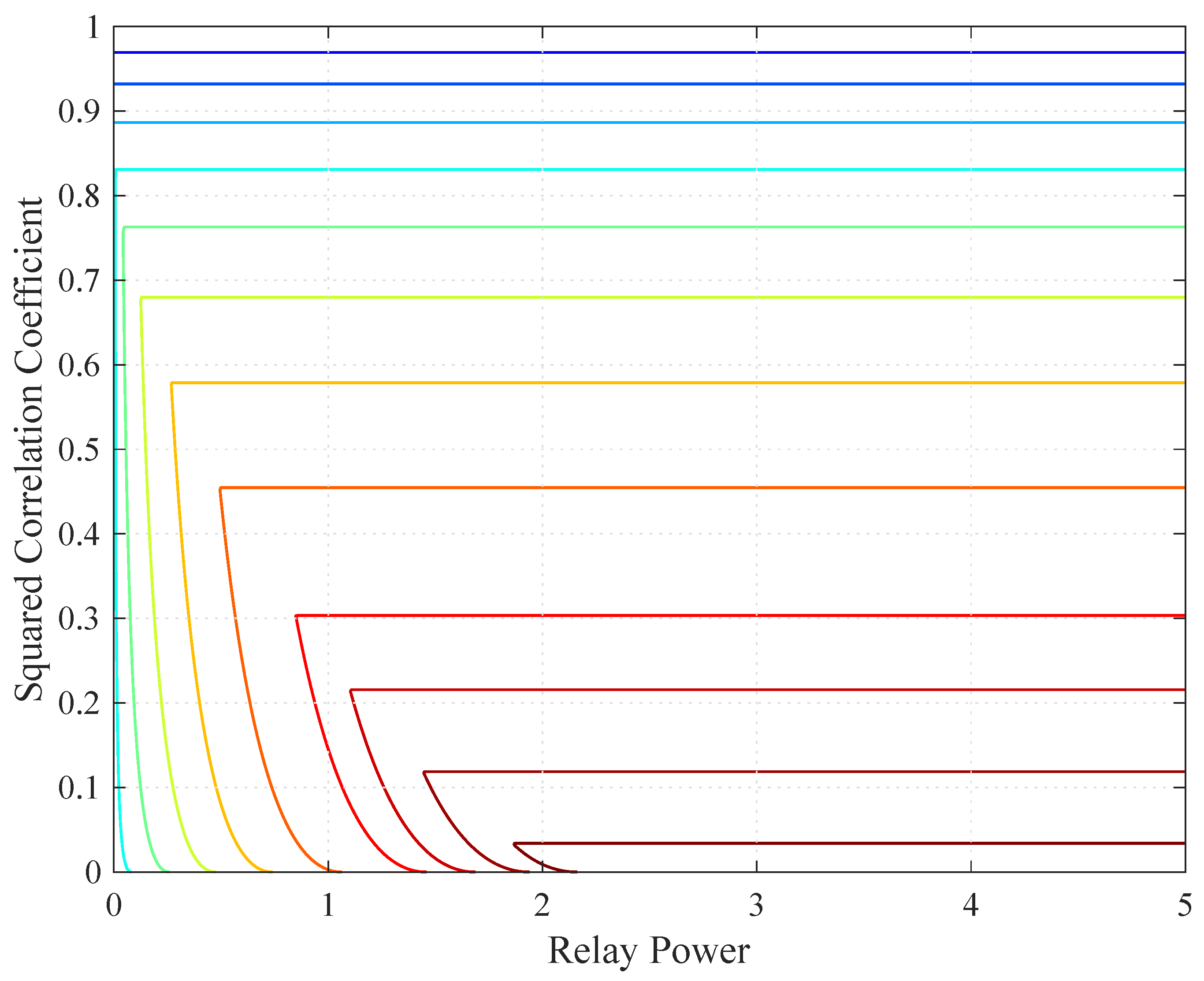
To illustrate the quasi-concavity, consider one relay and the channel gains , , and . This scenario corresponds to the geometry in Section 5.1 with . Figure 3 shows a contour plot of when . Observe that the contour lines form convex regions, as predicted by Corollary 1.
3.2. DF Rate
Consider the functions
As above, we restrict attention to and positive .
Theorem 2.
is concave in ρ, concave in , and quasi-concave in .
Proof.
The proof is similar to that of Theorem 1. ☐
Corollary 2.
is quasi-concave in .
Proof.
See the proof of Corollary 1. ☐
3.3. DT Rate
The DT rate (13) is clearly concave in and .
3.4. QF Rate
Consider the functions
We establish the following results. We restrict attention to non-negative .
Lemma 2.
is quasi-concave in .
Proof.
Substitute into the second function of Lemma A6 in Appendix B, and apply Lemma A5, Part 1. ☐
Theorem 3.
is quasi-concave in if the , , are held fixed.
Proof.
Apply Lemma 2 above and Lemma A5, Parts 2 and 3, in Appendix B. ☐
4. Quasi-Concavity in Relay Position
Suppose the channel gain for the node pair is
where is a “fading” gain, is the Euclidean distance between the positions and of nodes i and j, respectively, and is a path-loss exponent. We thus have
We establish quasi-concavity results in and , where is the position of the relay node.
4.1. CS Rate
Consider the functions (19)–(21) but relabeled as , , and to emphasize the dependence on the considered parameters. We again consider and positive .
Lemma 3.
and are quasi-concave in for fixed ρ. Furthermore, is quasi-concave in .
Proof.
Consider the functions
which are quasi-linear in for fixed since they are decreasing in . However, is a convex function of for , and thus Lemma A5, Part 5, in Appendix B establishes that is quasi-concave in for fixed . Similarly, is a convex function of for , and we find that is quasi-concave in for fixed .
Next, substitute and into the third function of Lemma A6, and use Lemma A5, Part 1, to show that is quasi-concave in . However, is decreasing in and is convex in , so Lemma A5, Part 5, establishes that is quasi-concave in . ☐
Unfortunately, is quasi-convex (and not quasi-concave) in . To see this, substitute and into the fourth function of Lemma A6. Quasi-concavity would have been useful since it would have permitted using Lemma A5, Parts 2 and 4, to establish the quasi-concavity of
However, we have been unable to prove this, and our numerical results suggest that is not quasi-concave in . Nevertheless, Lemma 3 suffices to establish an intermediate result which is useful in Section 5 when we study .
Theorem 4.
is quasi-concave in for fixed ρ, .
Proof.
is the minimum of functions that are quasi-concave in . Lemma A5, Part 2, thus establishes the theorem. ☐
4.2. DF Rate
The quasi-convexity of relaxes for the DF rate (25). Consider the negative of the fourth function of Lemma A6 in Appendix B with :
This function is quasi-linear in since both its superlevel and sublevel sets are convex. This result implies the following theorem. We again consider the functions (24)–(25) but relabeled as and . We further define
As above, we consider and positive .
Theorem 5.
is quasi-concave in , and is quasi-concave in .
Proof.
is quasi-linear in and decreasing in . Furthermore, is convex in , and thus Lemma A5, Part 5, in Appendix B establishes that is quasi-concave in . is therefore quasi-concave in , as it is the minimum of quasi-concave functions (see Lemma A5, Part 2). Furthermore, is concave in by Lemma A5, Part 4. ☐
5. DF Performance
This section presents numerical results for the DF strategy and compares them to results from [7,8,9]. We consider 1-, 2-, and 3-dimensional MRCs with different numbers N of destination nodes. For simplicity, we consider the low SNR or broadband regime where
In other words, we consider the CS and DF rates without the logarithms. This approach is valid not only in the limit of low SNR, but more generally because we proved our quasi-concavity results without taking logarithms. Furthermore, in the low SNR regime the rates of full-duplex and half-duplex transmission are the same under a block power constraint.
We choose , , and for all node pairs . We study both coherent transmission where is optimized and non-coherent transmission with . The rates are in nats/channel use. Alternatively, suppose we use sync pulses sampled at samples per second, where W is the (one-sided) signal bandwidth. Suppose further that the (one-sided) noise power spectral density is 1 Watt/Hz. Then at low SNR the rates in nats/channel use are the same as the rates in nats/sec.
5.1. One Dimension
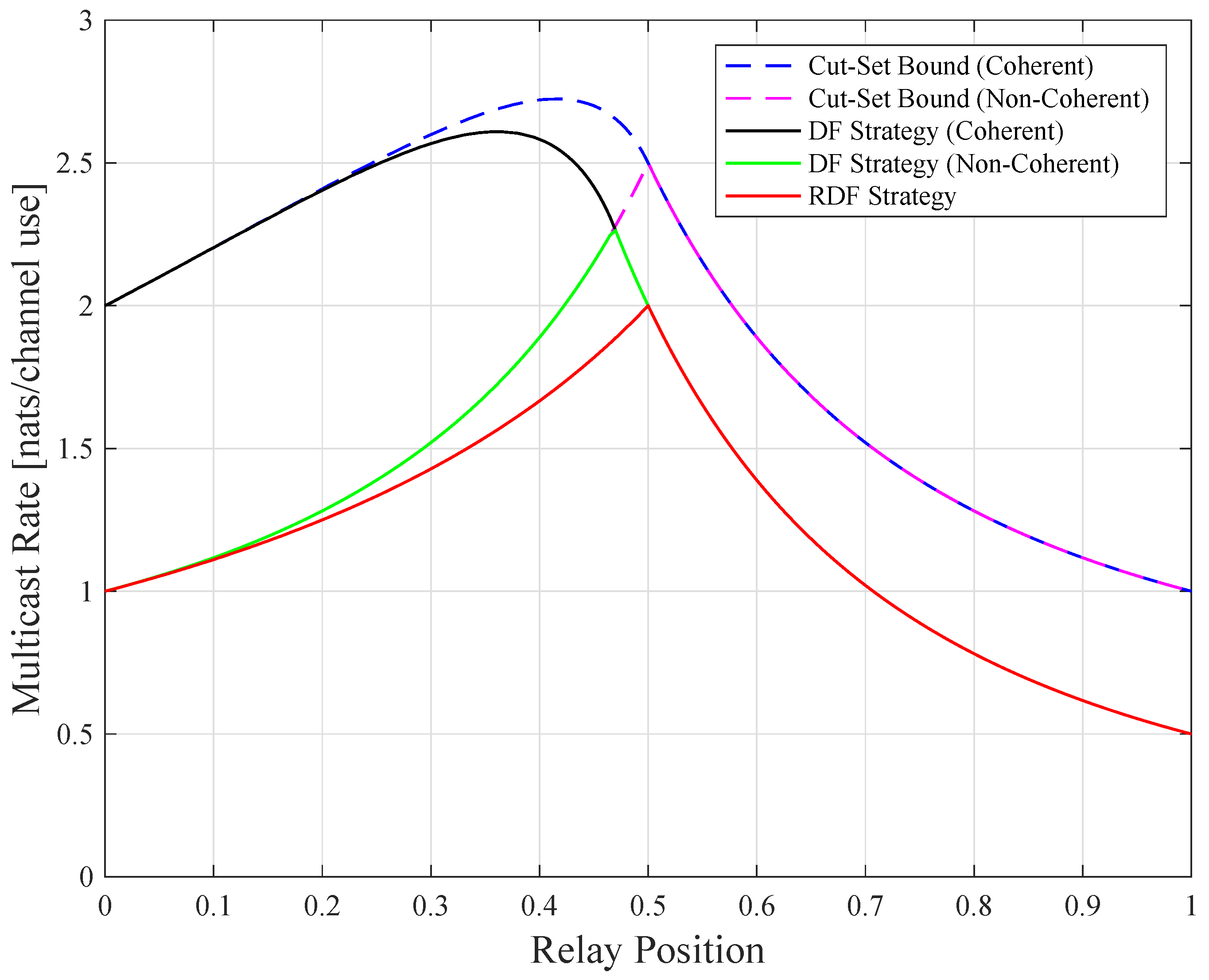
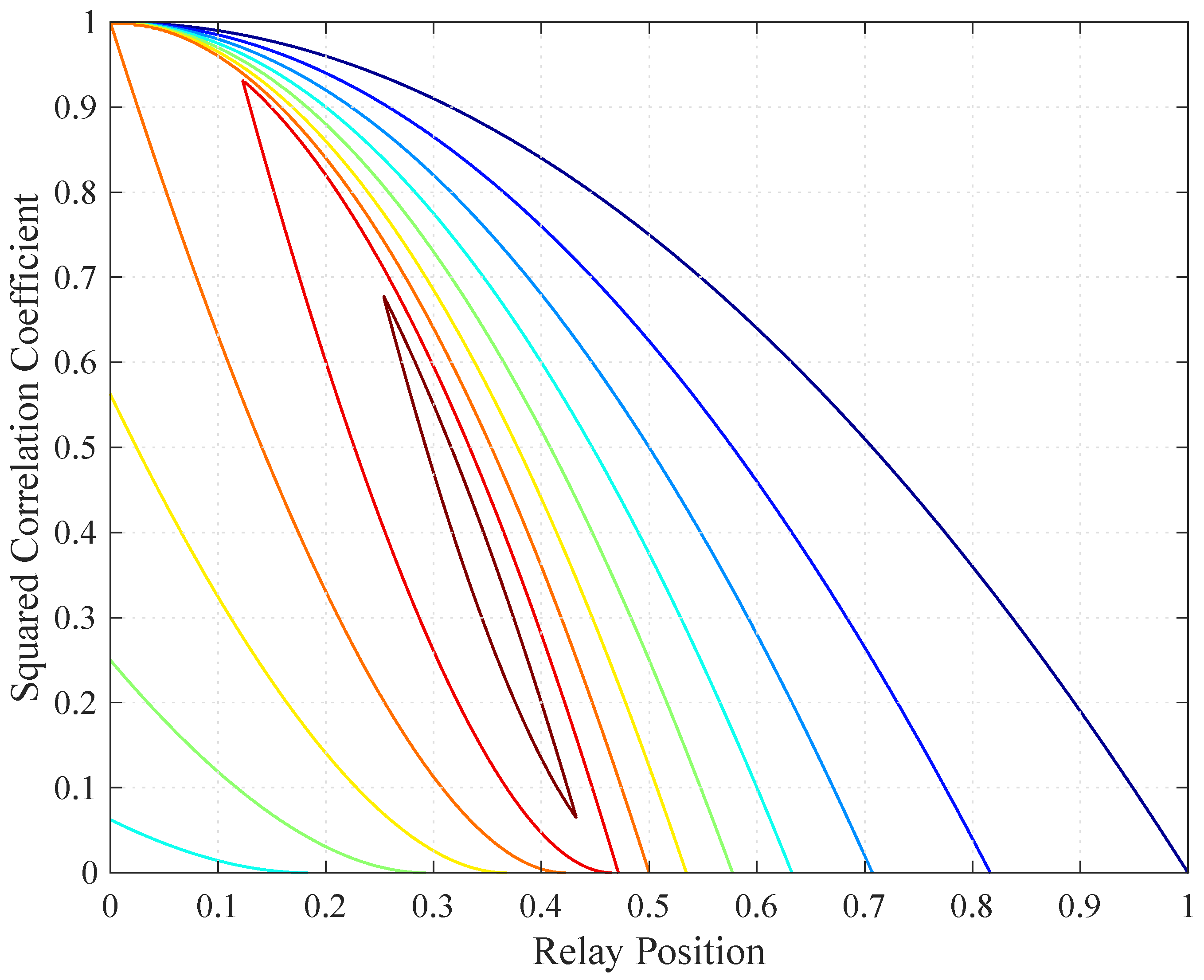
Consider a relay channel () where the source is at the origin () and the destination is at point 1 (). Figure 4 shows the low SNR CS rates, DF rates, and the routing-based DF (RDF) rates developed in [7], which are given by
Observe that all curves are quasi-concave (but not concave) in . Theorems 4 and 5 predict the quasi-concavity for all curves except for the coherent CS rates. Observe also that the curves for the coherent and non-coherent rates merge for relay positions exceeding a certain value ( and for the respective CS and DF rates). The reason for this behavior is that is optimal for the coherent CS and DF rates beyond these positions, see the curve in [1] (Figure 16). Furthermore, the non-coherent CS rates coincide with the non-coherent DF rates for a large range of .
The best relay positions for the two strategies are different. For example, maximizes while the maximizing is closer to the source. This is because when the source transmits, the relay and the destination listen, and the destination “collects” information. The relay can thus be positioned closer to the source while maintaining the same information rate from the source to the relay, and from the source-relay pair to the destination. At the optimal positions, we compute nats/sec and nats/sec, so the DF gain is ≈13%.
Finally, we illustrate that is quasi-concave in in Figure 5. The contour lines form convex regions, as predicted by Theorem 5.
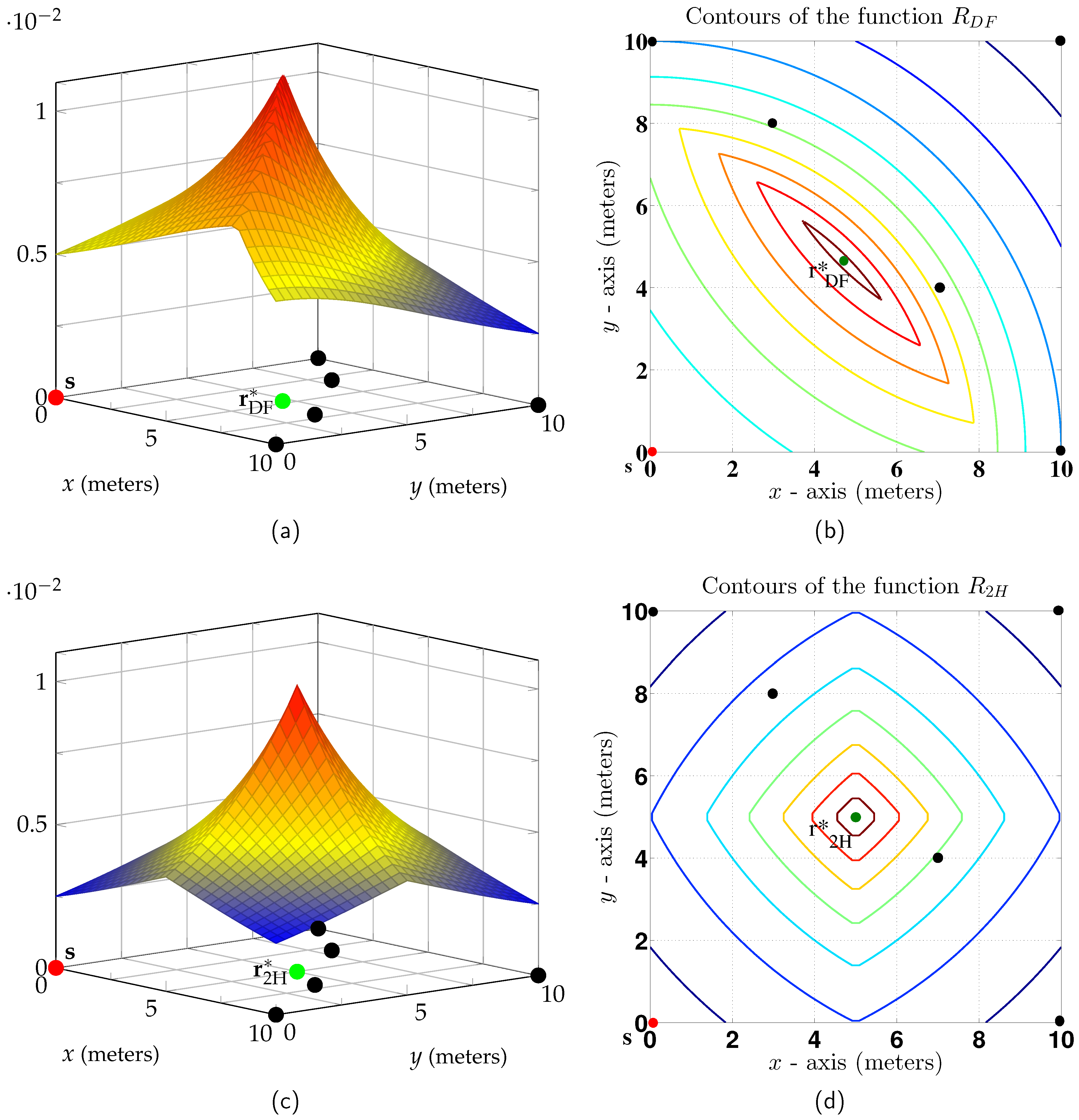
5.2. Two Dimensions
Consider destinations positioned on a square in the two-dimensional Euclidean plane with the source node at the origin. Figure 6a plots the node positions as circles, and the non-coherent as a function of the relay position. The best relay position is shown by a circle labeled and the corresponding rate is nats/sec. Figure 6c plots the low SNR two-hop rate
as a function of the relay position. The best relay position is shown by a circle labeled and the corresponding two-hop rate is nats/sec. The non-coherent DF gain is thus ≈10%.
Figure 6b,d shows contour plots for and . The contours form convex regions, as predicted by Theorem 5. Again, the relay position maximizing lies closer to the source than the relay position maximizing .
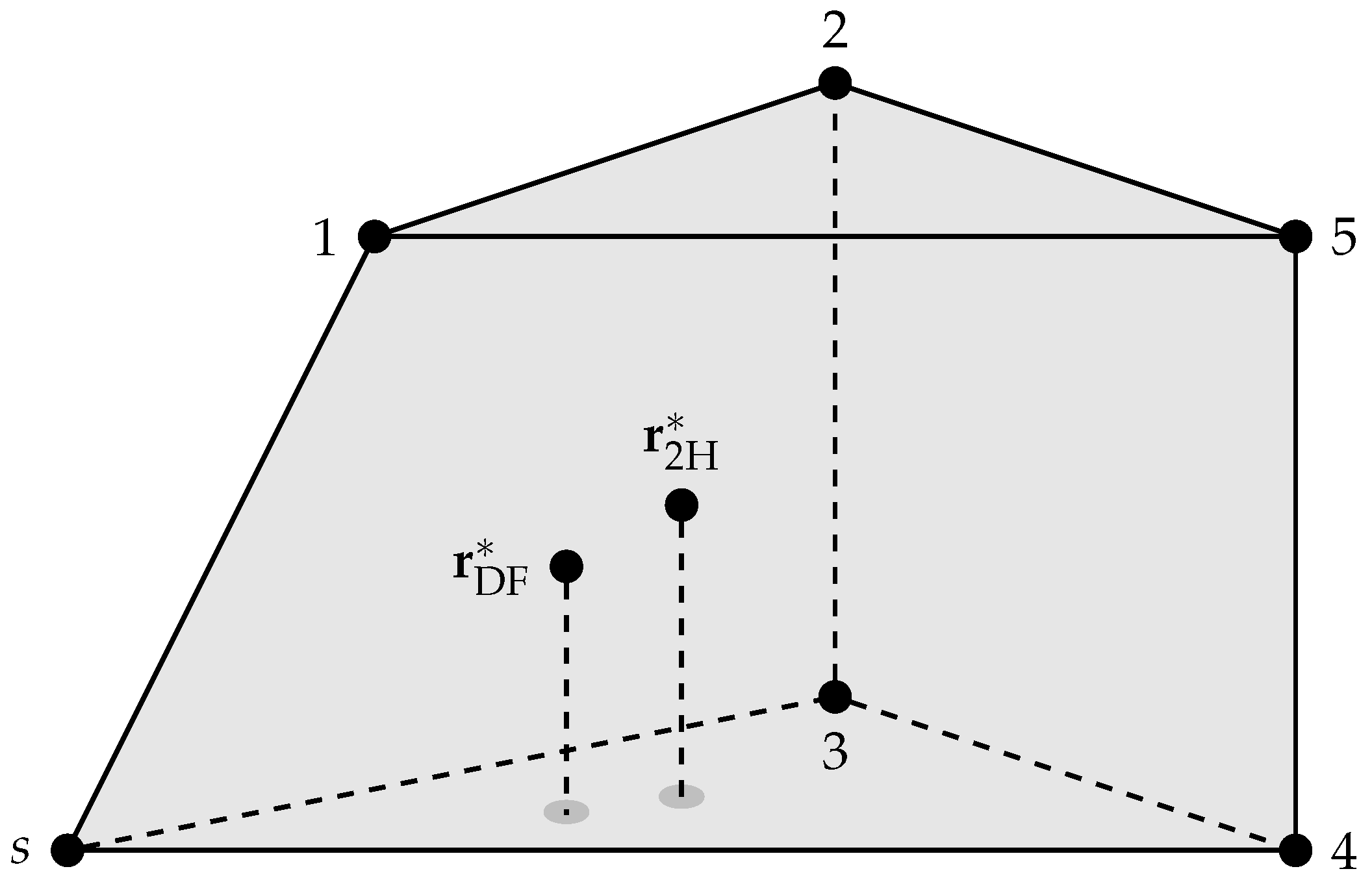
5.3. Three Dimensions
Consider destinations positioned in 3-dimensional Euclidean space as in Figure 7. The figure also shows the convex hull (a polyhedron) of the points. The points and denote the relay positions that maximize the non-coherent and , respectively. We remark that and remain unchanged if more destinations are positioned inside the polyhedron. This is because the points in the polyhedron receive at least the same rate as the worst of the five nodes at the corner points.
6. Discussion
6.1. Complex AWGN Channels
For complex-alphabet AWGN channels, we could replace (5) and (6) by adding phases for and as follows:
where the noise variables and , , are independent, identically distributed, circularly symmetric, complex, Gaussian random variables with zero mean and unit variance. The distance dependence of can be chosen as in (28) and the phase dependence as
where is the wavelength, c is the speed of light, and is the carrier frequency.
For example, the DF rate (14), normalized by the number of real dimensions, is
where the complex correlation coefficient satisfies . Observe that for a classic relay channel, with destination, one can choose to make real and non-negative, as for real alphabet AWGN channels. However, for one must choose complex in general. Furthermore, the quasi-concavity in will not be valid in general because the phases change with , and we cannot optimize for each destination node separately. However, we remark that this effect is “local" in the sense that for large carrier frequencies the phase variations are sensitive to changes in . A pragmatic approach would then be to optimize for non-coherent transmission () even if beamforming is permitted. Furthermore, if the channel exhibits random phase variations, then the best approach is to choose (see [1], Figure 18) in which case we have quasi-concavity for both the CS and DF rates. Finally, we remark that it might be interesting to consider quasi-concavity in the correlation coefficients for problems where the source and relay have sufficiently many antennas to overcome the problem outlined above.
6.2. Sum-Power Constraint
For some applications, it is interesting to consider a sum-power constraint
As is usually done, we set and consider , as a new optimization parameter. One might now hope that or are quasi-concave in for fixed , or at least for . Unfortunately, we have found counterexamples that show this is not the case. The rate functions do seem to have interesting properties, however, and these deserve further exploration.
7. Conclusions
Various quasi-concavity results were established for AWGN MRCs. In particular, the CS rates are quasi-concave in the relay position for a fixed correlation coefficient (Theorem 4) and the DF rates are quasi-concave in the relay position (Theorem 5).
Author Contributions
Both authors conceived the problem and solution and wrote the paper.
Funding
This research was funded by the German Ministry of Education and Research in the framework of an Alexander von Humboldt Professorship.
Acknowledgments
The authors thank the reviewers for their comments that helped to improve the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Covariance Matrices and Concavity
The covariance matrix of a real-valued random column vector is
A useful property of covariance matrices is as follows (see [14], p. 684). If is a principal minor of , then the following function is concave in :
Appendix B. Concave and Quasi-Concave Functions
We review results on quasi-concavity, and then establish quasi-concavity for several functions.
Appendix B.1. Definitions
Consider the following sets. The domain of a real-valued function is the set of arguments for which f is defined. The hypograph and hypergraph of f are the respective
The superlevel and sublevel sets of f with respect to are the respective
Concave and quasi-concave functions can be defined via the convexity of these sets. Recall that a set , , is convex if for any two points and in and for any satisfying we have
where . Suppose that is convex. The function f is concave over if and only if its hypograph is convex. Similarly, f is convex over if and only if is convex. The function f is quasi-concave over if and only if all its superlevel sets are convex, and f is quasi-convex over if and only if all its sublevel sets are convex. A function that is quasi-convex and quasi-concave is called quasi-linear. For example, any non-increasing or non-decreasing function is quasi-linear.
Appendix B.2. Basic Properties
Two properties of concave and quasi-concave functions are as follows; these properties are often used as the definitions of such functions. Similar properties exist for convex and quasi-convex functions.
Lemma A1.
The function f is concave if and only if
for all and in and for all .
Lemma A2.
The function f is quasi-concave if and only if
for all and in and for all .
The next two properties assume that f is twice differentiable and that is convex. Let and be the respective Hessian and bordered Hessian of f at .
Lemma A3.
(see [15], Section 3.1.4) f is concave if and only if is negative semidefinite for all .
Lemma A4.
(see [16], p. 771) f is quasi-concave on the open and convex set if the determinants of the respective second to nth leading principal minors of satisfy for and for all .
Appendix B.3. Compositions Preserving Quasi-Concavity
The following compositions preserve quasi-concavity.
Lemma A5.
Suppose f and , , are quasi-concave, then so are the functions
- 1.
- , where and ;
- 2.
- ;
- 3.
- where f is quasi-concave and g is non-decreasing;
- 4.
- where is a convex set;
- 5.
- where g is convex and is non-increasing in for fixed .
Proof.
Properties 1)–4) are standard (see [15], Section 3.4). For property 5), observe that
where follows because and is non-increasing in . Step follows because f is quasi-concave. ☐
Appendix B.4. Examples of Quasi-Concave Functions
We establish quasi-concavity for several useful functions.
Lemma A6.
The following functions are quasi-concave for with non-negative entries.
- 1.
- 2.
- for a positive constant k
- 3.
- for positive constants
- 4.
- for positive constants , and
Furthermore, the following function is quasi-concave for with non-negative entries.
- 5.
Proof.
We consider positive , and we use bordered Hessians and the derivatives of their kth leading principal minors, . The results extend to non-negative by using continuity at zero values, except for the third and fourth functions where makes the functions undefined.
- We have and for
- We have and for
- We have and for
- If , we have and for
- We have , and for
☐
References
- Kramer, G.; Gastpar, M.; Gupta, P. Cooperative strategies and capacity theorems for relay networks. IEEE Trans. Inf. Theory 2005, 51, 3037–3063. [Google Scholar] [CrossRef]
- Lin, B.; Ho, P.-H.; Xie, L.-L.; Shen, X.; Tapolcai, J. Optimal relay station placement in broadband wireless access networks. IEEE Trans. Mob. Comput. 2010, 9, 259–269. [Google Scholar] [CrossRef]
- Aggarwal, V.; Bennatan, A.; Calderbank, A.R. Calderbank. On maximizing coverage in Gaussian relay channels. IEEE Trans. Inf. Theory 2009, 55, 2518–2536. [Google Scholar] [CrossRef]
- Joshi, G.; Karandikar, A. Optimal relay placement for cellular coverage extension. In Proceedings of the Seventeenth National Conference on Communications, Bangalore, India, 28–30 January 2011; pp. 1196–1200. [Google Scholar]
- Lee, J.; Wang, H.; Andrews, J.G.; Hong, D. Outage probability of cognitive relay networks with interference constraints. IEEE Trans. Wirel. Commun. 2011, 10, 390–395. [Google Scholar] [CrossRef]
- Chen, X.; Song, S.H.; Letaief, K.B. Relay position optimization improves finite-SNR diversity gain of decode-and-forward MIMO relay systems. IEEE Trans. Commun. 2012, 60, 3311–3321. [Google Scholar] [CrossRef]
- Thakur, M.; Fawaz, N.; Médard, M. Optimal relay location and power allocation for low-SNR broadcast relay channels. In Proceedings of the 30th IEEE International Conference on Computer Communications (INFOCOM 2011), Shanghai, China, 10–15 April 2011; pp. 2822–2830. [Google Scholar]
- Thakur, M.; Fawaz, N.; Médard, M. On the geometry of wireless network multicast in 2-D. In Proceedings of the 2011 IEEE International Symposium on Information Theory, Saint Petersburg, Russian, 31 July–5 August 2011; pp. 1628–1632. [Google Scholar]
- Thakur, M.; Fawaz, N.; Médard, M. Reducibility of joint relay positioning and flow optimization problem. In Proceedings of the 2012 IEEE International Symposium on Information Theory, Boston, MA, USA, 1–6 July 2012; pp. 1117–1121. [Google Scholar]
- Thakur, M.; Kramer, G. Relay Positioning for Multicast Relay Networks. In Proceedings of the 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 1954–1958. [Google Scholar]
- Thakur, M.; Kramer, G. Quasi-concavity for Gaussian multicast relay channels. In Proceedings of the 2015 IEEE International Symposium on Information Theory, Hong Kong, China, 14–19 June 2015; pp. 2867–2869. [Google Scholar]
- Cover, T.M.; El Gamal, A. Capacity theorems for the relay channel. IEEE Trans. Inf. Theory 1979, 25, 572–584. [Google Scholar] [CrossRef]
- Kramer, G.; Maric, I.; Yates, R.D. Cooperative Communications. Found. Trends Netw. 2006, 1, 271–425. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2006. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: New York, NY, USA, 2004. [Google Scholar]
- Bazaraa, M.S.; Sherali, H.D.; Shetty, C.M. Nonlinear Programming; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
Figure 1.
Multicast relay channel (MRC) with two destinations.

Figure 2.
AWGN MRC with two destinations.

Figure 3.
Contour plot of when .

Figure 4.
Relay channel rates for low signal-to-noise ratio (SNR) and .

Figure 5.
Contour plot of in (37).

Figure 6.
(a) for ; (b) contour plot; (c) for the same network; (d) contour plot.

Figure 7.
destination geometry in three dimensions.

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Thakur, M.; Kramer, G. Quasi-Concavity for Gaussian Multicast Relay Channels. Entropy 2019, 21, 109. https://0-doi-org.brum.beds.ac.uk/10.3390/e21020109
AMA Style
Thakur M, Kramer G. Quasi-Concavity for Gaussian Multicast Relay Channels. Entropy. 2019; 21(2):109. https://0-doi-org.brum.beds.ac.uk/10.3390/e21020109
Chicago/Turabian StyleThakur, Mohit, and Gerhard Kramer. 2019. "Quasi-Concavity for Gaussian Multicast Relay Channels" Entropy 21, no. 2: 109. https://0-doi-org.brum.beds.ac.uk/10.3390/e21020109
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.