Amplitude Constrained MIMO Channels: Properties of Optimal Input Distributions and Bounds on the Capacity †



1
Department of Electrical Engineering, Princeton University, Princeton, NJ 08544, USA
2
Department of Electrical Engineering, Technion-Israel Institute of Technology, Technion City, Haifa 32000, Israel
*
Authors to whom correspondence should be addressed.
†
Parts of the material in this paper were presented at the 2017 IEEE Global Communications Conference (Singapore, 4–8 December 2017).
Entropy 2019, 21(2), 200; https://0-doi-org.brum.beds.ac.uk/10.3390/e21020200
Submission received: 21 January 2019
/
Revised: 6 February 2019
/
Accepted: 13 February 2019
/
Published: 19 February 2019
(This article belongs to the Special Issue Information Theory for Data Communications and Processing)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In this work, the capacity of multiple-input multiple-output channels that are subject to constraints on the support of the input is studied. The paper consists of two parts. The first part focuses on the general structure of capacity-achieving input distributions. Known results are surveyed and several new results are provided. With regard to the latter, it is shown that the support of a capacity-achieving input distribution is a small set in both a topological and a measure theoretical sense. Moreover, explicit conditions on the channel input space and the channel matrix are found such that the support of a capacity-achieving input distribution is concentrated on the boundary of the input space only. The second part of this paper surveys known bounds on the capacity and provides several novel upper and lower bounds for channels with arbitrary constraints on the support of the channel input symbols. As an immediate practical application, the special case of multiple-input multiple-output channels with amplitude constraints is considered. The bounds are shown to be within a constant gap to the capacity if the channel matrix is invertible and are tight in the high amplitude regime for arbitrary channel matrices. Moreover, in the regime of high amplitudes, it is shown that the capacity scales linearly with the minimum between the number of transmit and receive antennas, similar to the case of average power-constrained inputs.
1. Introduction
While the capacity of a multiple-input multiple-output (MIMO) channel with an average power constraint is well understood [1], there is surprisingly little known about the capacity of the more practically relevant case in which the channel inputs are subject to amplitude constraints. Shannon was the first who considered a channel that is constrained in its amplitude [2]. In that paper, he derived corresponding upper and lower bounds and showed that in the low-amplitude regime, the capacity behaves as that of channel with an average power constraint. The next major contribution to this problem was a seminal paper of Smith [3] published in 1971. Smith showed that, for the single-input single-output (SISO) Gaussian noise channel with an amplitude-constrained input, the capacity-achieving inputs are discrete with finite support. In [4], this result is extended to peak-power-constrained quadrature Gaussian channels. Using the approach of Shamai [4], it is shown in [5] that the input distribution that achieves the capacity of a MIMO channel with an identity channel matrix and a Euclidian norm constraint on the input vector is discrete. Even though the optimal input distribution is known to be discrete, very little is known about the number or the optimal positions of the corresponding constellation points. To the best of our knowledge, the only case for which the input distribution is precisely known is considered in [6], where it is shown for the Gaussian SISO channel with an amplitude constraint that two point masses are optimal if amplitude values are smaller than and three for amplitude values of up to . Finally, it has been shown very recently that the number of mass points in the support of the capacity-achieving input distribution of a SISO channel is of the order with A the amplitude constraint.
Based on a dual capacity expression, in [7], McKellips derived an upper bound on the capacity of a SISO channel that is subject to an amplitude constraint. The bound is asymptotically tight; that is, for amplitude values that tend to infinity. By cleverly choosing an auxiliary channel output distribution in the dual capacity expression, the authors of [8] sharpened McKellips’ upper bound and extended it to parallel MIMO channels with a Euclidian norm constraint on the input. The SISO version of the upper bound in [8] has been further sharpened in [9] by yet another choice of auxiliary output distribution. In [10], asymptotic lower and upper bounds for a MIMO channel are presented and the gap between the bounds is specified.
In this work, we make progress on this open problem by deriving several new upper and lower bounds that hold for channels with arbitrary constraints on the support of the channel input distribution and then apply them to the practically relevant special case of MIMO channels that are subject to amplitude-constraints.
1.1. Contributions and Paper Organization
The remainder of the paper is organized as follows. The problem is stated in Section 2. In Section 3, we study properties of input distributions that achieve the capacity of input-constrained MIMO channels. The section reviews known results on the structure of optimal input distributions and presents several new results. In particular, Theorem 3 shows that the support of a capacity-achieving input distribution must necessarily be a small set both topologically and measure theoretically. Moreover, Theorem 8 characterizes conditions on the channel input space as well as on the channel matrix such that the support of the optimal input distribution is concentrated on the boundary of the channel input space.
In Section 4, we derive novel upper and lower bounds on the capacity of a MIMO channel that is subject to an arbitrary constraint on the support of the input. In particular, three families of upper bounds are proposed, which are based on: (i) the maximum entropy principle (see the bound in Theorem 9); (ii) the dual capacity characterization (see the bound in Theorem 10); and (iii) a relationship between mutual information and the minimum mean square error that is known as the I-MMSE relationship (see the bound in Theorem 11). On the other hand, Section 4 provides three different lower bounds. The first one is given in Theorem 12 and is based on the entropy power inequality. The second one (see Theorem 13) is based on a generalization of the celebrated Ozarow–Wyner bound [11] to the MIMO case. The third upper bound (see Theorem 14) is based on Jensen’s inequality and depends on the characteristic function of the channel input distribution.
In Section 5, we evaluate the performance of our bounds by studying MIMO channels with invertible channel matrices. In particular, Theorem 17 states that our upper and lower bounds are within bits, where is the packing efficiency and n the number of transmit and receive antennas. For diagonal channel matrices, it is then shown (see Theorem 18) that the Cartesian product of simple pulse-amplitude modulation (PAM) constellations achieves the capacity to within bits.
Section 6 is devoted to MIMO channels with arbitrary channel matrices. It is shown that, in the regime of high amplitudes, similar to the case of average power-constrained channel inputs, the capacity scales linearly with the minimum of the number of transmit and receive antennas.
1.2. Notation
Vectors are denoted as bold lowercase letters, random vectors as bold uppercase letters, and matrices as bold uppercase sans serif letters (e.g., , , ). For any deterministic vector , , we denote the Euclidian norm of by . For some random and any , we define
where denotes the support of . Note that for , the quantity in Equation (1) defines a norm and for we simply have .
The norm of a matrix is defined as
whereas is denoting its trace. The identity matrix is represented as .
Let be a subset of . Then,
denotes its volume. Moreover, the boundary of is denoted as .
Let . We define an n-dimensional ball or radius centered at as the set
Recall that, for any and ,
where denotes the gamma function.
For any matrix and some , we define
Note that for an invertible , we have
with the determinant of . We define the maximum and minimum radius of a set that contains the origin as
For a given vector , we define
and the smallest box containing a given set as
respectively.
The entropy of any discrete random object is denoted as , whereas (i.e., the differential entropy) is used whenever is continuous. The mutual information between two random objects and is denoted as and denotes the multivariate normal distribution with mean vector and covariance matrix . Finally, , for any base , , , denotes the Q-function, and the Kronecker delta, which is one for and zero otherwise.
2. Problem Statement
Consider a MIMO system with transmit and receive antennas. The corresponding -dimensional channel output for a single channel use is of the form
for some fixed channel matrix (considering a real-valued channel model is without loss of generality). Here and hereafter, we assume is independent of the channel input and is known to both the transmitter and the receiver.
Now, let be a convex and compact channel input space that contains the origin (i.e., the length- zero vector) and let denote the cumulative distribution function of . As of the writing of this paper, the capacity
of this channel is unknown and we are interested in finding novel lower and upper bounds. Even though most of the results in this paper hold for arbitrary convex and compact , we are mainly interested in the two important special cases:
- (i)
- per-antenna amplitude constraints, i.e., for some given ; and
- (ii)
- -dimensional amplitude constraint, i.e., for some given .
3. Properties of an Optimal Input Distribution
Unlike the special cases of real and complex-valued SISO channels (i.e., ), the structure of the capacity-achieving input distribution, denoted as , is in general not known. To motivate why in this paper we are seeking for novel upper and lower bounds on the capacity (Equation (2)) instead of trying to solve the optimization problem directly, in this section we first summarize properties optimal input distributions must posses, which demonstrate how complicated the optimization problem actually is. Note that, whereas an optimal input distribution always exists, it does not necessarily need to be unique.
3.1. Necessary and Sufficient Conditions for Optimality
To study properties of an optimal input distribution, we need the notion of a point of increase of probability distribution.
Definition 1.
(Points of Increase of a Distribution) A point , , is said to be a point of increase of a given probability distribution if for any open set containing , .
The following result provides necessary and sufficient conditions for the optimality of a channel input distribution.
Theorem 1.
Let be some given channel input distribution and let denote the set of points of increase of . Then, the following holds:
- is unique and symmetric if is left invertible [18].
3.2. General Structure of Capacity-Achieving Input Distributions
Theorem 1 can be used to find general properties of the support of a capacity-achieving input distribution, which we will do in this subsection.
Remark 2.
Fully characterizing an input distribution that achieves the capacity of a general MIMO channel with per-antenna or an -dimensional amplitude constraint is still an open problem. To the best of our knowledge, the only general available for showing that discrete channel inputs are optimal was developed by Smith in [3] for the amplitude and variance-constrained Gaussian SISO channel. Since then, it has been useful to also characterize the optimal input distribution of several other SISO channels (see, for instance, [4,20,21,22,23,24]). The method relies on the following series of steps:
- Towards a contradiction, it is assumed that the set of points of increase is infinite.
- The assumption in Step 1 is then used to establish a certain property of the function on the input space . For example, by showing that has an analytic continuation to . Then, by means of the Identity Theorem of complex analysis and the Bolzano–Weierstrass Theorem [25], Smith was able to show that must be constant.
- By using either the Fourier or Laplace transform of together with the property of established in Step 2, a new a property of the channel output distribution is established. For example, Smith was able to show that must be constant.
- A conclusion out of Step 3 is used to reach a contradiction. The contradiction implies that must be finite. For example, to reach a contradiction, Smith was using the fact that the channel output distribution results from a convolution with a Gaussian probability density, which cannot be constant.
Remark 3.
Under the restriction that the output space, , of a Gaussian SISO channel is finite and the channel input space, , is subject to an amplitude constraint, Witsenhausen has shown in [26] that the capacity-achieving input distribution is discrete with the number of mass points bounded as . The approach of Witsenhausen, however, does not use the variational technique of Smith and relies on arguments from convex analysis instead.
According to Remark 2, assuming in the MIMO case that is of infinite cardinality does not help (or at least it is not clear how this assumption should be used) in showing that the capacity-achieving input distribution is discrete and finite. However, by using the weaker assumption that contains a non-empty open subset in conjunction with the following version of the Identity Theorem, we can show that the support of the optimal input distribution is a small set in a certain topological sense.
Theorem 2.
(Identity Theorem for Real-Analytic Functions [27]) For some let be a subset of and be two real-analytic functions that agree on a set . Then, f and g agree on if one of the following two conditions is satisfied:
- (i)
- is an open set.
- (ii)
- is a set of positive Lebesgue measure.
Furthermore, for , it suffices for to be an arbitrary set with an accumulation point.
We also need the definitions of a dense and a nowhere dense set.
Definition 2.
(Dense and Nowhere Dense Sets) A subset is said to be dense in the set if every element either belongs to or is an accumulation point of . A subset is said to be nowhere dense if for every nonempty open subset , the intersection is not dense in .
With Theorem 2 at our disposal, we are now able to prove the following result on the structure of the support of the optimal input distribution.
Theorem 3.
The set of points of increase of an optimal input distribution is a nowhere dense subset of that is of Lebesgue measure zero.
Proof.
It is not difficult to show that is a real-analytic function on ([18] Proposition 5). Now, in order to prove the result, we follow a series of steps similar to those outlined in Remark 2. Towards a contradiction, assume that the set of points of increase of is not a nowhere dense subset of . Then, according to Definition 2, there exists an open set such that is dense in .
By using the KKT condition in Equation (3b), we have that is constant on the intersection . Thus, as is dense in , it follows by the properties of continuous functions (real-analytic functions are continuous) that is also constant on . Moreover, as is an open set, Theorem 2 implies that must also be constant on . This, however, leads to a contradiction as cannot be constant on all of , which can be shown by taking the Fourier transform of and solving for the probability density of the channel output (the reader is referred to [3] for details). Therefore, we conclude that is a nowhere dense subset of .
Showing that has Lebesgue measure zero follows along similar lines by assuming that is a set of positive measure. Then, Property (ii) of Theorem 2 can be used to conclude that must be zero on all of . This again leads to a contradiction, which implies that must be of Lebesgue measure zero. □
Remark 4.
Note that if for some and is orthogonally equivariant (i.e., it only depends on ), then can be written as a union of concentric spheres. That is,
with for some . To see this, let
and observe that if , then . Combining this with the symmetry of the function , we have that (We know that it is abuse of notation to use the same letter for the functions and even if they are different. It is an attempt to say in a compact way that g is orthogonally equivariant.)
Moreover, this implies that
where is possibly of infinite cardinality. In fact, has finite cardinality. To see this, note that, if is real-analytic, then so is . However, as is a non-zero real-analytic function on , it can have at most finitely many zeros on an interval.
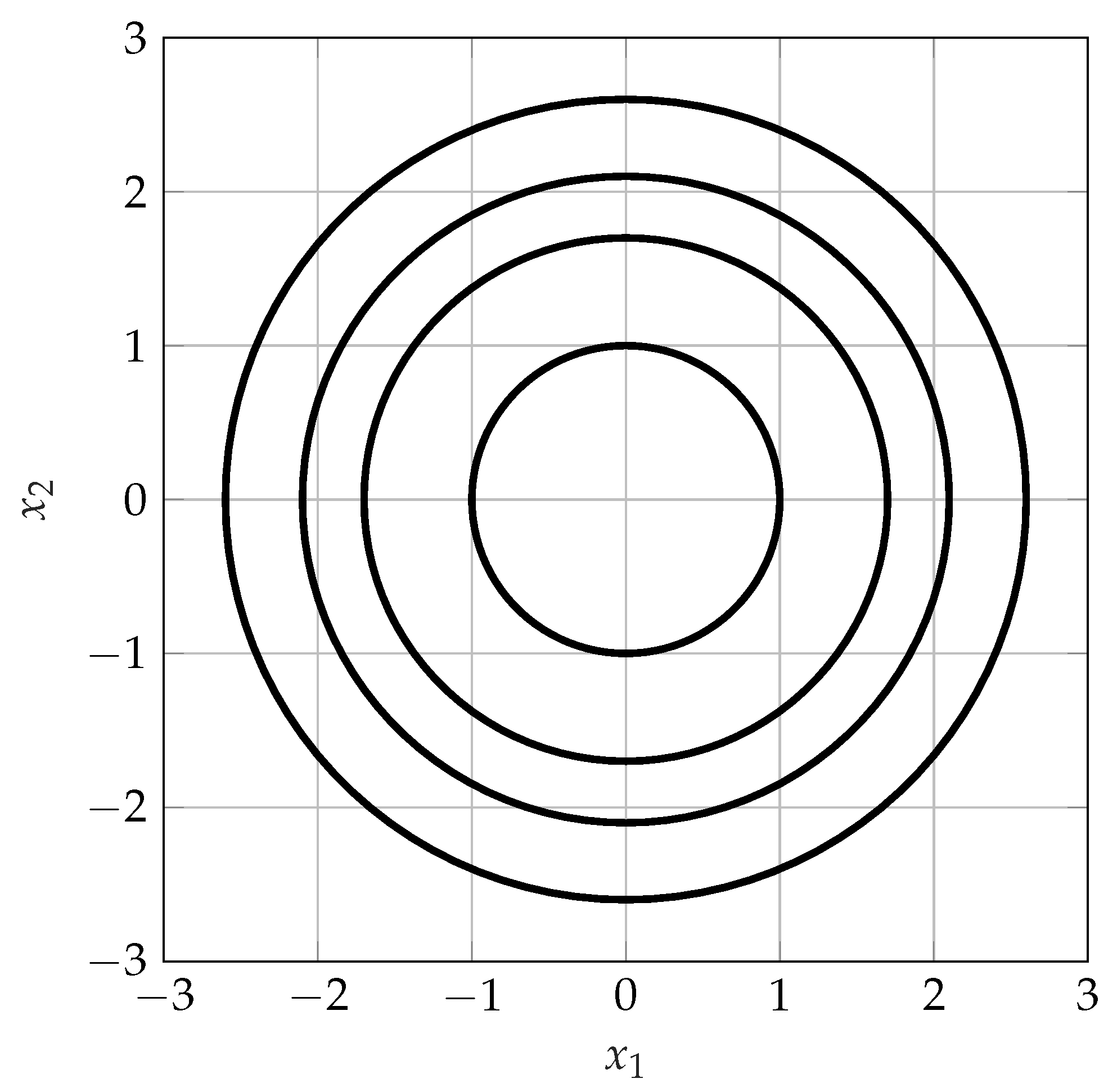
As an example consider the special case with . Then, the union in Equation (4) implies that the cardinality of is uncountable and that discrete inputs are in general not optimal. Therefore, Theorem 3 can generally not be improved in the sense that for , statements about the cardinality of cannot be made. Note, however, that the magnitude of is discrete. An example of the corresponding optimal input distribution for the case of is given in Figure 1.
Even though Theorem 3 does not allow us to conclude that the optimal input distribution of an arbitrary MIMO channel is discrete and finite, for the special case of a SISO channel we have the following partial result.
Theorem 4.
(Optimal Input Distribution of a SISO Channel [3,6,28]) For some fixed and , consider the SISO channel with input space . Let be an input distribution that achieves the capacity, , of that channel. Then, satisfies the following properties:
- is unique.
- is symmetric.
- is discrete with the number of mass points being of the order .
- contains probability mass points at .
Moreover, binary communication with mass points at is optimal if and only if , where .
Theorem 4 can now be used to also address the special cases of multiple-input single output (MISO) and single-input multiple output (SIMO) channels.
Theorem 5.
Let be a MISO channel with channel matrix and some optimal input . Then, the distribution of is discrete with finitely many mass points. On the other hand, let be a SIMO channel with channel matrix . Then, the optimal input has a discrete distribution with finitely many mass points.
Proof.
For the MISO case, the capacity can expressed as
Using Theorem 5 we have that the maximizing distribution in Equation (5) , where , is discrete with finitely many mass points.
For the SIMO case, the channel input distribution is discrete as a SIMO channel can be transformed into a SISO channel. Thus, let be finite. Then, the capacity of the SIMO channel can be expressed as
Again, it follows from Theorem 5 that the mutual information in Equation (6) is maximized by a channel input distribution, , that is discrete with finitely many mass points. This concludes the proof. □
Remark 5.
Note that in the MISO case, we do not claim to be discrete with finitely many points. To illustrate the difficulty, let so that
As and can be arbitrarily correlated, we cannot rule out cases in which and , with D a discrete random variable and X of arbitrary distribution. Clearly the distribution of is not discrete.
Note that in general it can be shown that the capacity-achieving input distribution is discrete if the optimization problem in Equation (2) can be reformulated as an optimization over one dimensional distributions. This, for example, has been done in [5] for parallel channels with a total amplitude constraint.
3.3. Properties of Capacity-Achieving Input Distributions in the Small (But Not Vanishing) Amplitude Regime
In this subsection, we study properties of capacity-achieving input distribution in the regime of small amplitudes. To that end, we will need the notion of a subharmonic function.
Definition 3.
(Subharmonic Function) Let f be a real-valued function that is twice continuously differentiable on an open set . Then, f is subharmonic if on , where denotes the Laplacian (if f is twice differentiable, its Laplacian is given by ).
We use the following Theorem, which states that a subharmonic function always attains its maximum on the boundary of its domain.
Theorem 6.
(Maximum Principle of Subharmonic Functions [29]) Let be a connected open set. If is subharmonic and attains a global maximum in the interior of , then f is constant on .
In addition to Theorem 6, we need the following result that has been proven in [30].
Lemma 1.
Let the likelihood function of the output of a MIMO channel be defined as
and let denote the Hessian matrix of . Then, the Laplacian (or the trace of ) is given by
Theorem 7.
Suppose that . Then, is a subharmonic function for every .
Proof.
Let be arbitrary and observe that
With this expression in hand, the Laplacian of with respect to can be bounded from below as follows:
where follows from Equation (7) and the chain rule for the Hessian; from using the well-known inequality
that holds for and positive semi-definite; and from using the inequality
Thus, according to the assumption that , the right-hand side of Equation (8) is nonnegative, which proves the result. □
Now, knowing that is a subharmonic function allows us to characterize the support of an optimal input distribution of a MIMO channel provided that the radius of the channel input space, , is sufficiently small.
Theorem 8.
Let be a capacity-achieving input distribution and . Then, .
Proof.
From the KKT conditions in Equation (3), we know that, if , then is a maximizer of . According to Theorem 7, we also know that is subharmonic. Hence, from the Maximum Principle of Subharmonic Functions (i.e., Theorem 6), it follows . □
Combining Theorem 8 with the observations made in Remark 4 leads to the following corollary.
Corollary 1.
Let and . Then,
where denotes a sphere of radius A.
We conclude this section by noting that for the special case with , the exact value of A such that has been characterized in terms of an integral equation in [31], which is approximately equal to .
4. Upper and Lower Bounds on the Capacity
The considerations in the previous section have shown that characterizing the structure of an optimal channel-input distribution is a challenging question in itself that we could only partially answer. A full characterization, however, is a necessary prerequisite to narrow down the search space in Equation (2) to one that is tractable. Except for some special cases (i.e., special choices of ), optimizing over the most general space of input distributions that consists of all continuous -dimensional probability distributions with , is prohibitive (Note that Dytso et al. [32] summarized methods of how to optimize functionals over the space of probability distributions that are constrained in there support). Thus, up to the writing of this paper, there is little hope in being able to solve the problem in Equation (2) in full generality so that in this section we are proposing novel lower and upper bounds on the capacity . Nevertheless, these bounds will allow us to better understand how the capacity of such MIMO channels behaves.
Towards this end, in Section 4.1, we provide four upper bounds. The first is based on an upper bound on the differential entropy of a random vector that is constraint in its pth moment, the second and third bounds are based on duality arguments, and the fourth on the relationship between mutual information and the minimum mean square error (MMSE), I-MMSE relationship for short, known from [33]. The three lower bounds proposed in Section 4.2, on the other hand, are based on the celebrated entropy power inequality, a generalization of the Ozarow–Wyner capacity bound taken from [11], and on Jensen’s inequality.
4.1. Upper Bounds
Lemma 2.
(Maximum Entropy Under pth Moment Constraint) Let and be arbitrary. Then, for any such that and , we have
where
Theorem 9.
(Moment Upper Bound) For any channel input space and any fixed channel matrix , we have
where is chosen such that .
Proof.
Expressing Equation (2) in terms of differential entropies results in
where follows from Lemma 2 with the fact that ; and from the monotonicity of the logarithm.
Now, notice that is linear in and therefore it attains its maximum at an extreme point of the set (i.e., the set of all cumulative distribution functions of ). As a matter of fact [26], the extreme points of are given by the set of degenerate distributions on ; that is, . This allows us to conclude
Observe that the Euclidian norm is a convex function, which is therefore maximized at the boundary of the set . Combining this with Equation (9) and taking the infimum over completes the proof. □
The following Theorem provides two alternative upper bounds that are based on duality arguments.
Theorem 10.
(Duality Upper Bounds) For any channel input space and any fixed channel matrix
where
and
where such that .
Proof.
Using duality bounds, it has been shown in [8] that for any centered n-dimensional ball of radius
where .
Now, observe that
where follows from enlarging the optimization domain; and from using the upper bound in Equation (12). This proves Equation (10).
To show the upper bound in Equation (11), we proceed with an alternative upper bound to Equation (13):
where the (in)equalities follow from: enlarging the optimization domain; single-letterizing the mutual information; choosing individual amplitude constraints such that ; and using the upper bound in Equation (12) for . This concludes the proof. □
As mentioned at the beginning of the section, another simple technique for deriving upper bounds on the capacity is to use the I-MMSE relationship [33]
For any , the quantity is known as the MMSE of estimating from the noisy observation . An important fact that will be useful is that the conditional expected value is the best estimator in the sense that it minimizes the mean square error over all measurable functions ; that is, for any and
Theorem 11.
(I-MMSE Upper Bound) For any channel input space and any fixed channel matrix
Proof.
Fix some and observe that
where the (in)equalities follow from: using that for any fixed ; using the I-MMSE relationship in Equation (14); and using the property that conditional expectation minimizes mean square error (i.e., (15)).
Now, notice that
where follows from (the same argument was used in the proof of Theorem 9); and from the definition of .
Since is arbitrary, we can choose it to minimize the upper bound in Equation (16). Towards this end, we need the following optimization result
which is easy to show. Combining Equation (16) with Equation (17), we obtain the following upper bound on the capacity
This concludes the proof. □
Corollary 2.
For any channel input space and any fixed channel matrix
Proof.
The corollary follows by upper bounding Equation (16) using the fact that . □
Remark 6.
In the proof of Theorem 11, instead of using sub-optimal estimators and , we could have used an optimal linear estimator of the form , where denotes the cross-covariance matrix between and and the covariance matrix of . This choice would result in the capacity upper bound
with the covariance matrix of the channel input. While Equation (18) is a valid upper bound, as of the writing of this paper, it is not clear how to perform an optimization over covariance matrices of random variables with bounded support. One possibility to avoid this is to use the inequality between arithmetic and geometric mean and bound the determinant by the trace:
In Section 5, we present a comparison of the upper bounds of Theorems 9–11 by means of a simple example.
4.2. Lower Bounds
A classical approach to bound a mutual information from below is to use the entropy power inequality (EPI).
Theorem 12.
(EPI Lower Bounds) For any fixed channel matrix and any channel input space with absolutely continuous, we have
Moreover, if , invertible, and uniformly distributed over , then
Proof.
To show the lower bound in Equation (21), all we need is to recall that
which is maximized for uniformly distributed over . However, if is uniformly drawn from , we have
which completes the proof. □
The considerations in Section 3 suggest that a channel input distribution that maximizes Equation (2) might be discrete. Therefore, there is a need for lower bounds that unlike the bounds in Theorem 12 rely on discrete inputs.
Theorem 13.
(Ozarow–Wyner Type Lower Bound) Let be a discrete random vector of finite entropy, a measurable function, and . Furthermore, let be a set of continuous random vectors, independent of , such that for every we have , , and
for all , . Then,
where
with
and as defined in Lemma 2, respectively.
Proof.
The proof is identical to ([11] Theorem 2). To make the manuscript more self-contained, we repeat it here.
Let and be statistically independent. Then, the mutual information can be lower bounded as
Interestingly, the bound of Theorem 13 holds for arbitrary channels and is therefore not restricted to MIMO channels. The interested reader is referred to [11] for details.
We conclude the section by providing a lower bound that is based on Jensen’s inequality and holds for arbitrary inputs.
Theorem 14.
(Jensen’s Inequality Lower Bound) For any channel input space and any fixed channel matrix , we have
with
where is an independent copy of and denotes the characteristic function of .
Proof.
To show the lower bound, we follow an approach of Dytso et al. [34]. Note that by Jensen’s inequality
Now, evaluating the integral in Equation (27) results in
where follows from the independence of and and Tonelli’s Theorem ([35] Chapter 5.9); from completing a square; and from the fact that . Combining Equation (27) with Equation (28) and subtracting completes the proof of the first version of the bound.
To show the second version, observe that
where follows from Parseval’s identity ([35] Chapter 9.5) by noting that is a characteristic function of and is a characteristic function of ; from using the property that the characteristic function of a sum of random vectors is equal to the product of its characteristic functions; from using the fact that a characteristic function is a linear transformation; from using that and have the same characteristic function; and from the fact that the characteristic function is Hermitian. This completes the proof. □
Remark 7.
As is evident from our examples in the following sections, in many cases, the Jensen’s inequality lower bound of Theorem 14 performs remarkably well. The bound, however, is also useful for MIMO channels that are subject to an average power constraint. For example, evaluating Equation (26) with results in
Note that this bound is within bits of the capacity of the power-constrained channel.
In Section 3, we discuss that the distributions that maximize mutual information in -dimensions are typically singular, which means that they are concentrated on a set of Lebesgue measure zero. Singular distributions generally do not have a probability density, whereas the characteristic function always exists. This is why the version of Jensen’s inequality lower bound in Theorem 14 that is based on the characteristic function of the channel input is especially useful for amplitude-constrained MIMO channels.
5. Invertible Channel Matrices
Consider the symmetric case of antennas with being invertible. In this section, we evaluate some of the lower and upper bounds proposed in the previous section for the special case of being also diagonal and then characterize the gap to the capacity for arbitrary invertible channel matrices.
5.1. Diagonal Channel Matrices
Suppose the channel inputs are subject to per-antenna or an n-dimensional amplitude constraint. Then, the duality upper bound of Theorem 10 takes on the following form.
Theorem 15.
(Upper Bounds) Let be fixed. If for some , then
Moreover, if for some , then
Proof.
For an arbitrary channel input space , the EPI lower bound of Theorem 12 and Jensen’s inequality lower bound of Theorem 14 take on the following form.
Theorem 16.
(Lower Bounds) Let be fixed and arbitrary. Then,
with
where and ,
Moreover,
Proof.
For some given values , , let the ith component of be independent and uniformly distributed over the interval . Thus, the expected value appearing in the bound of Theorem 14 can be written as
Now, if is an independent copy of , it can be shown that the expected value at the right-hand side of Equation (34) is of the explicit form
with as defined in Equation (32). Finally, optimizing over all results in the bound (31). The bound in Equation (33) follows by inserting into Equation (21), which concludes the proof. □
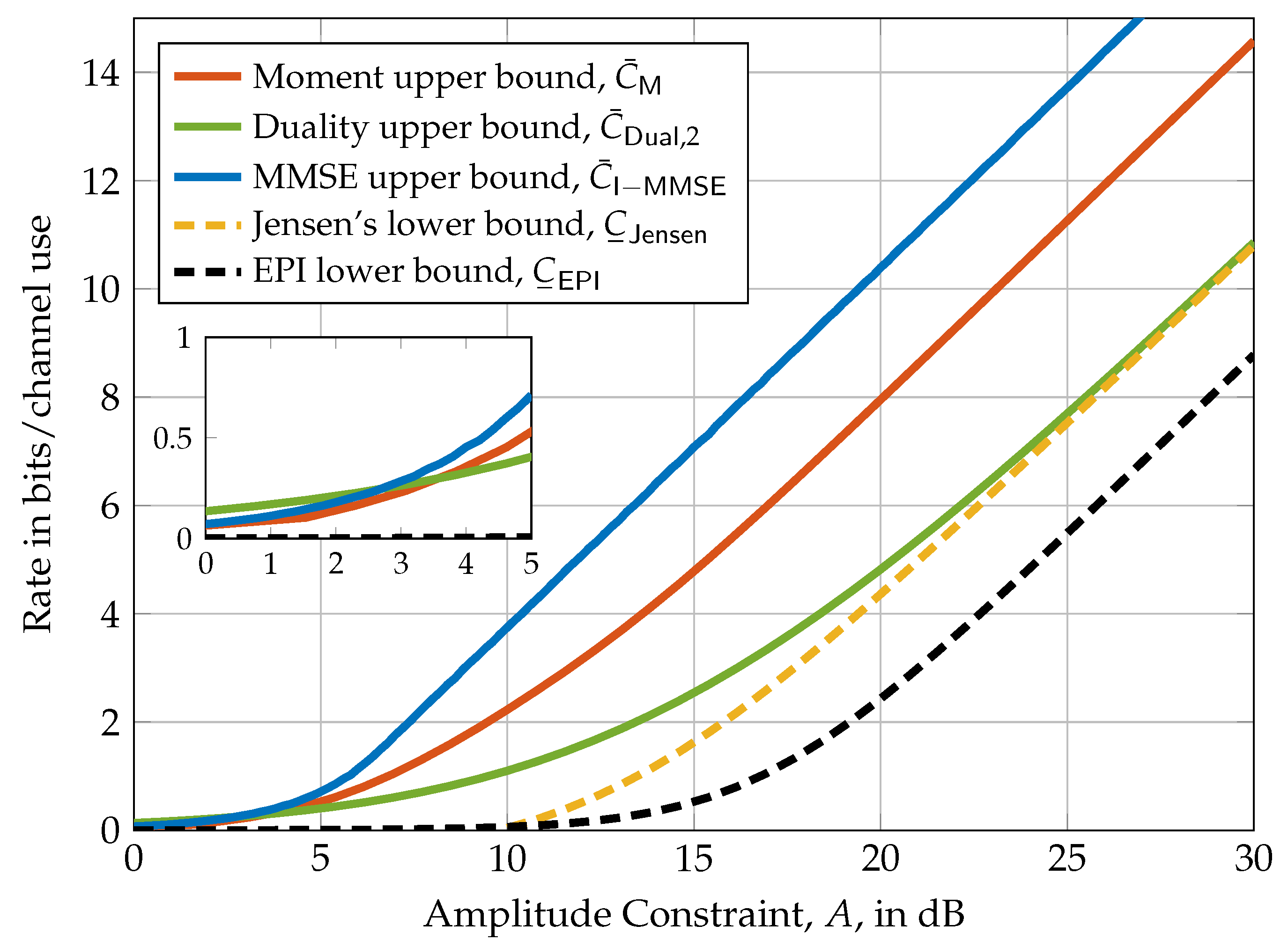
In Figure 2, the upper bounds of Theorems 9 and 15 and the lower bounds of Theorem 16 are depicted for a diagonal MIMO channel with per-antenna amplitude constraints. It turns out that the moment upper bound and the EPI lower bound perform well in the small amplitude regime while the duality upper bound and Jensen’s inequality lower bound perform well in the high amplitude regime. Interestingly, for this specific example, the duality upper bound and Jensen’s lower bound are asymptotically tight.
5.2. Gap to the Capacity
Our first result provides and upper bound to the gap between the capacity in Equation (2) and the lower bound in Equation (21).
Theorem 17.
Let be of full rank and
Then,
Proof.
For notational convenience, let the volume of an n-dimensional ball of radius be denoted as
Now, observe that, by choosing , the upper bound of Theorem 9 can further be upper bounded as
where follows since ; and since . Therefore, the gap between Equation (21) and the moment upper bound of Theorem 9 can be upper bounded as follows:
where is due to the fact that is the radius of an n-dimensional ball; follows from the inequality for and ; and follows from using Stirling’s approximation to obtain . □
The term is referred to as the packing efficiency of the set . In the following proposition, we present the packing efficiencies for important special cases.
Proposition 1.
(Packing Efficiencies) Let be of full rank, , and . Then,
Proof.
The packing efficiency in Equation (35) follows immediately. Note that
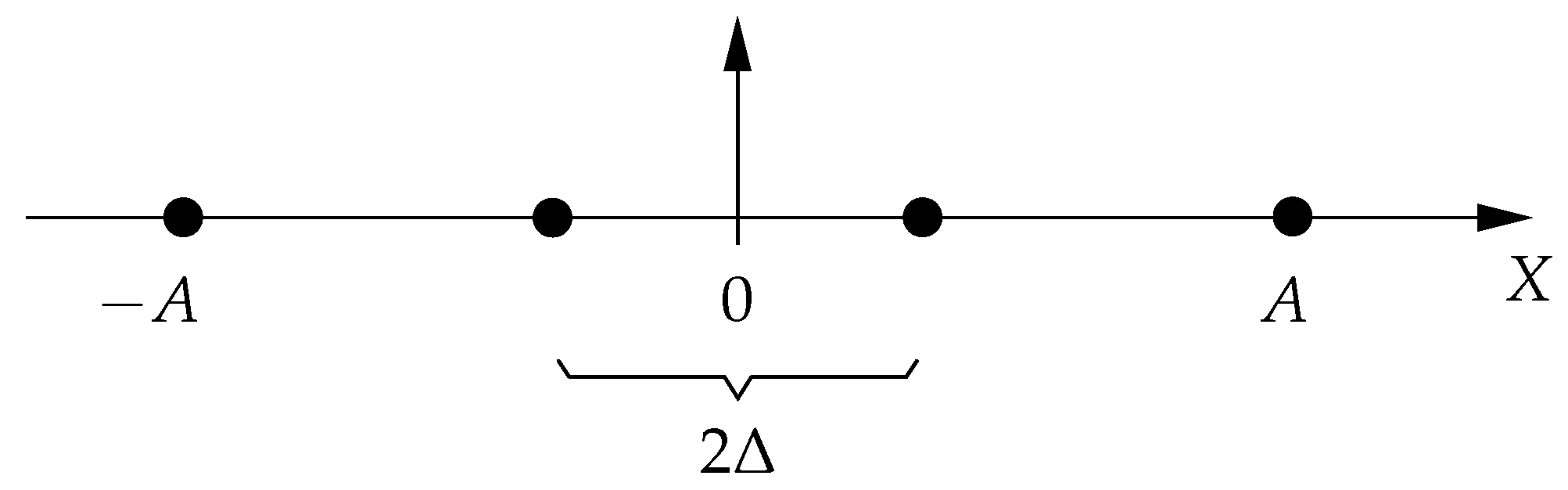
We conclude this section by characterizing the gap to the capacity when is diagonal and the channel input space is the Cartesian product of n PAM constellations. In this context, refers to the set of equidistant PAM-constellation points with amplitude constraint (see Figure 3 for an illustration), whereas means that X is uniformly distributed over [11].
Theorem 18.
Let be fixed and . Then, if , , for some given , it holds that
where and
Moreover, if , , for some given , it holds that
where .
Proof.
Since the channel matrix is diagonal, letting the channel input be such that its elements , , are independent, we have that
Let with and observe that half the Euclidean distance between any pair of adjacent points in is equal to (see Figure 3), . To lower bound the mutual information , we use the bound of Theorem 13 for and . Thus, for some continuous random variable U that is uniformly distributed over the interval and independent of , we have that
Now, note that the entropy term in Equation (41) can be lower bounded as
where we have used that for every . On the other hand, the last term in Equation (41) can be upper bounded by upper bounding its argument as follows:
where follows from using that and U are independent and ; from using the estimator ; and from . Combining Equations (41), (42), and (43) results in the gap in (39).
The proof of the capacity gap in Equation (40) follows along similar lines, which concludes the proof. □
We are also able to determine the gap to the capacity for a general invertible channel matrix.
Theorem 19.
For any and any invertible
Proof.
Let be uniformly distributed over a set constructed from an n-dimensional cubic lattice with the number of points equal to , where is chosen such that , and scaled such that it is contained in the input space . Note that the minimum distance between point in are given by
Now, we compute the difference between the moment upper bound of Theorem 9 and the Ozarow–Wyner lower bound of Theorem 13:
where follows from Theorem 9 by choosing ; and by using the bound for . The next step in the proof consists in bounding the term, which requires to upper bound the terms in Equations (23) and (24) individually. Towards this end, choose and let be a random vector that is uniformly distributed over a ball of radius . Thus, for (23) it follows
where follows by choosing : by using , where is the radius of an n-dimensional ball; from dropping the floor function in the expression for the minimum distance, i.e.,
follows by expanding using that ; and from using the bound .
On the other hand, the term can be bounded from above as follows ([36] Appendix L):
Combining these two bounds with the one in (44) provides the result. □
6. Arbitrary Channel Matrices
For an arbitrary MIMO channel with an average power constraint, it is well known that the capacity is achieved by a singular value decomposition (SVD) of the channel matrix (i.e., ) along with considering the equivalent channel model
where , , and , respectively.
To provide lower bounds for channels with amplitude constraints and SVD precoding, we need the following lemma.
Lemma 3.
For any given orthogonal matrix and constraint vector , there exists a distribution of such that is uniformly distributed over . Moreover, the components of are mutually independent with uniformly distributed over , .
Proof.
Suppose that is uniformly distributed over ; that is, the density of is of the form
Since is orthogonal, we have and by the change of variable Theorem for
Therefore, such a distribution of exists. □
Theorem 20.
(Lower Bounds with SVD Precoding) Let be fixed, , and for some . Furthermore, let , , be the ith singular value of . Then,
and
where
with and φ as defined in Equation (32).
Proof.
Performing the SVD, the expected value in Theorem 14 can be written as
By Lemma 3, there exists a distribution such that the components of are independent and uniformly distributed. Since is a diagonal matrix, we can use Theorem 16 to arrive at Equation (45).
Remark 8.
Notice that choosing the optimal for the lower bound in Equation (45) is an amplitude allocation problem, which is reminiscent of waterfilling in the average power constraint case. It would be interesting to study whether the bound in Equation (45) is connected to what is called mercury waterfilling in [37,38].
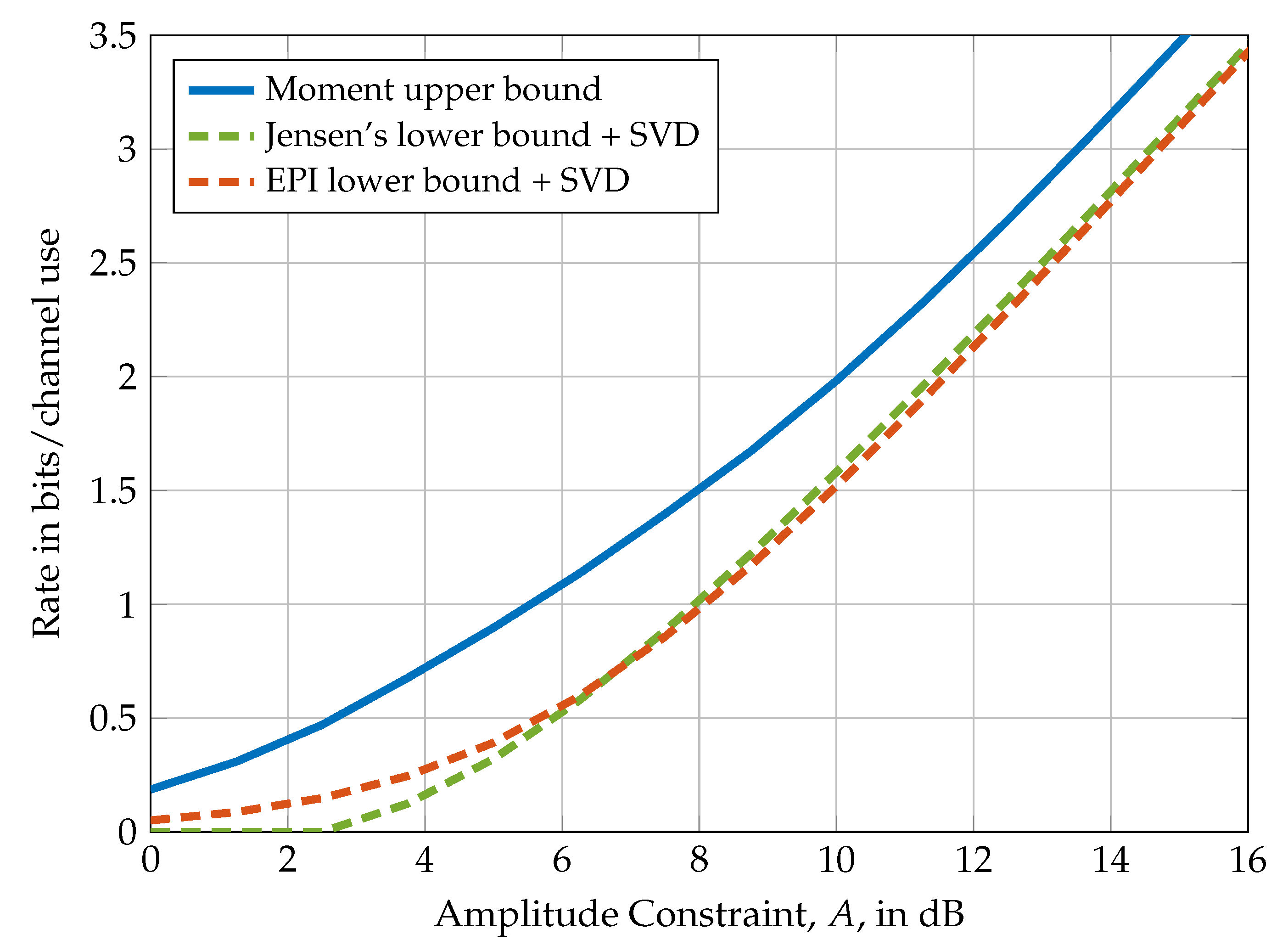
In Figure 4, the lower bounds of Theorem 20 are compared to the moment upper bound of Theorem 2 for the special case of a MIMO channel. Similar to the example presented in Figure 2, the EPI lower bound performs well in the low amplitude regime, while Jensen’s inequality lower bound performs well in the high amplitude regime.
We conclude this section by showing that for an arbitrary channel input space , in the large amplitude regime the capacity pre-log is given by .
Theorem 21.
Let be arbitrary and fixed. Then,
Proof.
Notice that there always exists and such that . Thus, without loss of generality, we can consider , , for sufficiently large . To prove the result, we therefore start with enlarging the constraint set of the bound in Equation (11):
where and . Therefore, by using the upper bound in Equation (11), it follows that
Moreover,
Next, using the EPI lower bound in Equation (46), we have that
This concludes the proof. □
7. The SISO Case
In this section, we apply the upper and lower bounds presented in the previous sections to the special case of a SISO channel that is subject to an amplitude constraint (i.e., for some ) and compare them with the state-of-the art. More precisely, we are interested in upper and lower bounds to the capacity
Without loss of generality, we assume in all that follows.
7.1. Upper and Lower Bounds
As a starting point for our comparisons, the following Theorem summarizes bounds on the capacity (47) that are known from the literature. The bounds are all based on the duality approach that we generalize in Section 4 to the MIMO case.
Theorem 22.
(Known Duality Upper Bounds) Let be arbitrary. Then, the following are valid upper bounds to the capacity of the amplitude-constrained SISO channel defined in Equation (47).
Now, we apply the moment upper bound of Theorem 9 to the SISO case.
Theorem 23.
(Moment Upper Bound) Let be arbitrary. Then,
where the expected value is of the explicit form
with being the confluent hypergeometric function of the first kind ([39] Chapter 13).
Proof.
First, note that . Then, by using the expression for the raw absolute moment of a Gaussian distribution given in [40], we have that
The proof is concluded by observing that is an increasing function in a. □
The following theorem establishes the EPI and the Jensen lower bound of Section 4.2 assuming the channel input symbols are uniformly distributed.
Theorem 24.
(Lower Bounds with Uniform Inputs) Let be arbitrary and the channel input X be uniformly distributed over . Then,
and
Proof.
Restricting the channel inputs to be discrete allows for another set of lower bounds on Equation (47).
Theorem 25.
(Lower Bounds with Discrete Inputs) Let be arbitrary, equally likely, and with . Then,
and
Proof.
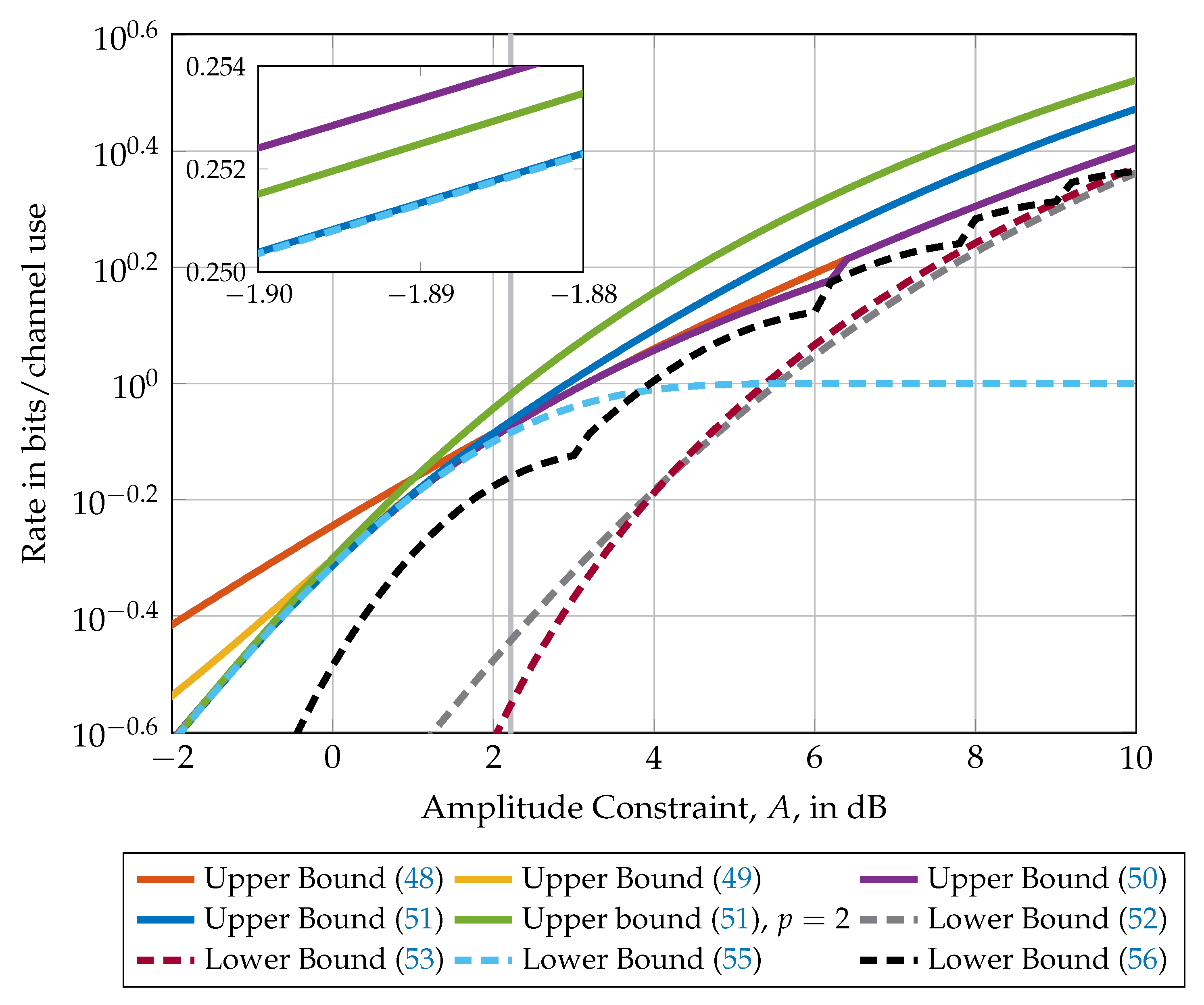
Figure 5 compares the upper and lower bounds presented in this section in dependency of the amplitude constraint A. Observe that for values of A smaller than ≈1.665 (i.e., to the left of the gray vertical line), the lower bound (55) is in fact equal to the capacity. Up to constraints of , the moment upper bound in Equation (51) is the best after which the bound in Equation (50) becomes the tightest. The best lower bound for constraint values smaller than is the bound in Equation (56) after which the lower bound in Equation (53) becomes the tightest. Note that all lower and upper bounds are asymptotically tight (i.e., for ).
7.2. High and Low Amplitude Asymptotics
In this subsection, we study how the capacity in Equation (47) behaves in the high and low amplitude regimes. To this end, we need the following expression
which is either the capacity of a SISO channel with an average power constraint or the moment bound in Equation (51) evaluated for .
Theorem 26.
(SISO High and Low Amplitude Asymptotics) It holds
and
Proof.
The capacity of an amplitude-constrained SISO channel in the regime of low amplitudes (i.e., for amplitudes smaller than ) was given by Guo et al. [41]
Now, observe that
Therefore, the limit in Equation (58) is given by
The limit in Equation (59) follows from comparing the EPI lower bound in (52) with the McKellips upper bound given in Equation (48).
Finally, to show Equation (60), observe that
This concludes the proof. □
8. Conclusions
In this work, we studied the capacity of MIMO channels with bounded input spaces. Several new properties of input distributions that achieve the capacity of such channels have been provided. In particular, it is shown that the support of a capacity-achieving channel input distribution is a set that is small in a topological and measure theoretical sense. In addition to that, it is shown that, if the radius of the underlying channel input space, , is small enough, then the support of a corresponding capacity-achieving input distribution must necessarily be a subset of the boundary of . As the considerations on the input distribution have demonstrated that determining the capacity is a very challenging problem, we proposed several new upper and lower bounds that are shown to be tight in the high amplitude regime. An interesting future direction would be to study generalizations of our techniques to wireless optical MIMO channels [42] and other channels such as the wiretap channel [43].
Author Contributions
All authors contributed equally to this work.
Funding
This work was supported in part by the U. S. National Science Foundation under Grants CCF-093970 and CCF-1513915, by the German Research Foundation (DFG) under Grant GO 2669/1-1, and by the European Union’s Horizon 2020 Research And Innovation Programme, grant agreement No. 694630.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Telatar, I.E. Capacity of multi-antenna Gaussian channels. Eur. Trans. Telecommun. 1999, 10, 585–595. [Google Scholar] [CrossRef]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27. [Google Scholar] [CrossRef]
- Smith, J.G. The information capacity of amplitude-and variance-constrained scalar Gaussian channels. Inf. Control 1971, 18, 203–219. [Google Scholar] [CrossRef]
- Shamai (Shitz), S.; Bar-David, I. The capacity of average and peak-power-limited quadrature Gaussian channels. IEEE Trans. Inf. Theory 1995, 41, 1060–1071. [Google Scholar] [CrossRef]
- Rassouli, B.; Clerckx, B. On the capacity of vector Gaussian channels with bounded inputs. IEEE Trans. Inf. Theory 2016, 62, 6884–6903. [Google Scholar] [CrossRef]
- Sharma, N.; Shamai (Shitz), S. Transition points in the capacity-achieving distribution for the peak-power limited AWGN and free-space optical intensity channels. Probl. Inf. Transm. 2010, 46, 283–299. [Google Scholar] [CrossRef]
- McKellips, A.L. Simple tight bounds on capacity for the peak-limited discrete-time channel. In Proceedings of the 2004 IEEE International Symposium on Information Theory (ISIT), Chicago, IL, USA, 27 June–2 July 2004; p. 348. [Google Scholar]
- Thangaraj, A.; Kramer, G.; Böcherer, G. Capacity Bounds for Discrete-Time, Amplitude-Constrained, Additive White Gaussian Noise Channels. Available online: https://arxiv.org/abs/1511.08742 (accessed on 15 February 2019).
- Rassouli, B.; Clerckx, B. An Upper Bound for the Capacity of Amplitude-Constrained Scalar AWGN Channel. IEEE Commun. Lett. 2016, 20, 1924–1926. [Google Scholar] [CrossRef]
- ElMoslimany, A.; Duman, T.M. On the Capacity of Multiple-Antenna Systems and Parallel Gaussian Channels With Amplitude-Limited Inputs. IEEE Trans. Commun. 2016, 64, 2888–2899. [Google Scholar] [CrossRef]
- Dytso, A.; Goldenbaum, M.; Poor, H.V.; Shamai (Shitz), S. A Generalized Ozarow-Wyner Capacity Bound with Applications. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 1058–1062. [Google Scholar]
- Dytso, A.; Goldenbaum, M.; Shamai (Shitz), S.; Poor, H.V. Upper and Lower Bounds on the Capacity of Amplitude-Constrained MIMO Channels. In Proceedings of the 2017 IEEE Global Communications Conference (GLOBECOM), Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Cao, P.L.; Oechtering, T.J. Optimal transmit strategy for MIMO channels with joint sum and per-antenna power constraints. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Loyka, S. The Capacity of Gaussian MIMO Channels Under Total and Per-Antenna Power Constraints. IEEE Trans. Commun. 2017, 65, 1035–1043. [Google Scholar] [CrossRef]
- Loyka, S. On the Capacity of Gaussian MIMO Channels under the Joint Power Constraints. Available online: https://arxiv.org/abs/1809.00056 (accessed on 15 February 2019).
- Tuninetti, D. On the capacity of the AWGN MIMO channel under per-antenna power constraints. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 2153–2157. [Google Scholar]
- Vu, M. MISO capacity with per-antenna power constraint. IEEE Trans. Commun. 2011, 59, 1268–1274. [Google Scholar] [CrossRef]
- Chan, T.H.; Hranilovic, S.; Kschischang, F.R. Capacity-achieving probability measure for conditionally Gaussian channels with bounded inputs. IEEE Trans. Inf. Theory 2005, 51, 2073–2088. [Google Scholar] [CrossRef]
- Csiszar, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Abou-Faycal, I.C.; Trott, M.D.; Shamai, S. The capacity of discrete-time memoryless Rayleigh-fading channels. IEEE Trans. Inf. Theory 2001, 47, 1290–1301. [Google Scholar] [CrossRef]
- Fahs, J.; Abou-Faycal, I. On properties of the support of capacity-achieving distributions for additive noise channel models with input cost constraints. IEEE Trans. Inf. Theory 2018, 64, 1178–1198. [Google Scholar] [CrossRef]
- Gursoy, M.C.; Poor, H.V.; Verdú, S. The noncoherent Rician fading channel-part I: Structure of the capacity-achieving input. IEEE Trans. Wireless Commun. 2015, 4, 2193–2206. [Google Scholar] [CrossRef]
- Katz, M.; Shamai, S. On the capacity-achieving distribution of the discrete-time noncoherent and partially coherent AWGN channels. IEEE Trans. Inf. Theory 2004, 50, 2257–2270. [Google Scholar] [CrossRef]
- Ozel, O.; Ekrem, E.; Ulukus, S. Gaussian wiretap channel with amplitude and variance constraints. IEEE Trans. Inf. Theory 2015, 61, 5553–5563. [Google Scholar] [CrossRef]
- Bak, J.; Newman, D.J. Complex Analysis; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Witsenhausen, H.S. Some Aspects of Convexity Useful in Information Theory. IEEE Trans. Inf. Theory 1980, 26, 265–271. [Google Scholar] [CrossRef]
- Krantz, S.G.; Parks, H.R. A Primer of Real Analytic Functions; Springer Science & Business Media: New York, NY, USA, 2002. [Google Scholar]
- Dytso, A.; Yagli, S.; Poor, H.V.; Shamai (Shitz), S. Capacity Achieving Distribution for the Amplitude Constrained Additive Gaussian Channel: An Upper Bound on the Number of Mass Points. Available online: https://arxiv.org/abs/1901.03264 (accessed on 15 February 2019).
- Ransford, T. Potential Theory in the Complex Plane; London Mathematical Society Student Texts; Cambridge University Press: Cambridge, UK, 1995; Volume 28. [Google Scholar]
- Hatsell, C.; Nolte, L. Some geometric properties of the likelihood ratio (Corresp.). IEEE Trans. Inf. Theory 1971, 17, 616–618. [Google Scholar] [CrossRef]
- Dytso, A.; Poor, H.V.; Shamai (Shitz), S. On the Capacity of the Peak Power Constrained Vector Gaussian Channel: An Estimation Theoretic Perspective. Available online: https://arxiv.org/abs/1804.08524 (accessed on 15 February 2019).
- Dytso, A.; Goldenbaum, M.; Poor, H.V.; Shamai (Shitz), S. When are Discrete Channel Inputs Optimal?—Optimization Techniques and Some New Results. In Proceedings of the 2018 Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 21–23 March 2018; pp. 1–6. [Google Scholar]
- Guo, D.; Shamai, S.; Verdú, S. Mutual information and minimum mean-square error in Gaussian channels. IEEE Trans. Inf. Theory 2005, 51, 1261–1282. [Google Scholar] [CrossRef]
- Dytso, A.; Tuninetti, D.; Devroye, N. Interference as Noise: Friend or Foe? IEEE Trans. Inf. Theory 2016, 62, 3561–3596. [Google Scholar] [CrossRef]
- Resnick, S.I. A Probability Path; Springer Science & Business Media: New York, NY, USA, 2013. [Google Scholar]
- Dytso, A.; Bustin, R.; Tuninetti, D.; Devroye, N.; Shamai (Shitz), S.; Poor, H.V. On the Minimum Mean p-th Error in Gaussian Noise Channels and its Applications. IEEE Trans. Inf. Theory 2018, 64, 2012–2037. [Google Scholar] [CrossRef]
- Lozano, A.; Tulino, A.M.; Verdú, S. Optimum power allocation for parallel Gaussian channels with arbitrary input distributions. IEEE Trans. Inf. Theory 2006, 52, 3033–3051. [Google Scholar] [CrossRef]
- Pérez-Cruz, F.; Rodrigues, M.R.; Verdú, S. MIMO Gaussian channels with arbitrary inputs: Optimal precoding and power allocation. IEEE Trans. Inf. Theory 2010, 56, 1070–1084. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, 9th dover printing ed.; Dover Publications: New York, NY, USA, 1964. [Google Scholar]
- Winkelbauer, A. Moments and Absolute Moments of the Normal Distribution. Available online: https://arxiv.org/abs/1209.4340 (accessed on 15 February 2019).
- Guo, D.; Wu, Y.; Shamai, S.; Verdú, S. Estimation in Gaussian Noise: Properties of the Minimum Mean-Square Error. IEEE Trans. Inf. Theory 2011, 57, 2371–2385. [Google Scholar]
- Moser, S.M.; Mylonakis, M.; Wang, L.; Wigger, M. Asymptotic Capacity Results for MIMO Wireless Optical Communication. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 536–540. [Google Scholar]
- Dytso, A.; Egan, M.; Perlaza, S.; Poor, H.V.; Shamai (Shitz), S. Optimal Inputs for Some Classes of Degraded Wiretap Channels. In Proceedings of the 2018 IEEE Information Theory Workshop (ITW), Guangzhou, China, 25–29 November 2018; pp. 1–5. [Google Scholar]
Figure 1.
An example of a support of an optimal input distribution for the special case .

Figure 2.
Comparison of the upper and lower bounds of Theorems 9, 11, 15, and 16 evaluated for a MIMO system with per-antenna amplitude constraints (i.e., ) and channel matrix . The nested figure represents a zoom into the region to visualize the differences between the bounds at small amplitude constraints.
Figure 2.
Comparison of the upper and lower bounds of Theorems 9, 11, 15, and 16 evaluated for a MIMO system with per-antenna amplitude constraints (i.e., ) and channel matrix . The nested figure represents a zoom into the region to visualize the differences between the bounds at small amplitude constraints.

Figure 3.
Example of a pulse-amplitude modulation constellation with points and amplitude constraint A (i.e., ), where denotes half the Euclidean distance between two adjacent constellation points. In the case N is odd, 0 is a constellation point.
Figure 3.
Example of a pulse-amplitude modulation constellation with points and amplitude constraint A (i.e., ), where denotes half the Euclidean distance between two adjacent constellation points. In the case N is odd, 0 is a constellation point.

Figure 4.
Comparison of the upper bound in Theorem 2 with the lower bounds of Theorem 20 for a MIMO system with amplitude constraints (i.e., ) and channel matrix .
Figure 4.
Comparison of the upper bound in Theorem 2 with the lower bounds of Theorem 20 for a MIMO system with amplitude constraints (i.e., ) and channel matrix .

Figure 5.
Comparison of upper and lower bounds on the capacity of a SISO channel with amplitude constraint A. The capacity of this channel is known for amplitudes smaller than only (i.e., to the left of the gray vertical line) and unknown elsewhere. The nested figure represents a zoom into the region to highlight the differences between the Moment upper bound (51), the Rassouli–Clerckx upper bound in Equation (50), and the lower bound with binary inputs in Equation (56).
Figure 5.
Comparison of upper and lower bounds on the capacity of a SISO channel with amplitude constraint A. The capacity of this channel is known for amplitudes smaller than only (i.e., to the left of the gray vertical line) and unknown elsewhere. The nested figure represents a zoom into the region to highlight the differences between the Moment upper bound (51), the Rassouli–Clerckx upper bound in Equation (50), and the lower bound with binary inputs in Equation (56).

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Dytso, A.; Goldenbaum, M.; Poor, H.V.; Shamai, S. Amplitude Constrained MIMO Channels: Properties of Optimal Input Distributions and Bounds on the Capacity. Entropy 2019, 21, 200. https://0-doi-org.brum.beds.ac.uk/10.3390/e21020200
AMA Style
Dytso A, Goldenbaum M, Poor HV, Shamai S. Amplitude Constrained MIMO Channels: Properties of Optimal Input Distributions and Bounds on the Capacity. Entropy. 2019; 21(2):200. https://0-doi-org.brum.beds.ac.uk/10.3390/e21020200
Chicago/Turabian StyleDytso, Alex, Mario Goldenbaum, H. Vincent Poor, and Shlomo Shamai (Shitz). 2019. "Amplitude Constrained MIMO Channels: Properties of Optimal Input Distributions and Bounds on the Capacity" Entropy 21, no. 2: 200. https://0-doi-org.brum.beds.ac.uk/10.3390/e21020200
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.